
© Dmitriy Shironosov, 123RF.com
Ein menschlicher Beobachter sieht vieles intuitiv, erfasst zum Beispiel auf einer Karte die Ballungszentren einer zweidimensionalen Punktemenge auf einen Blick. Künstliche Intelligenz tut sich dabei normalerweise schwerer. Das relativ simple K-means-Verfahren jedoch liefert überraschend brauchbare Ergebnisse.
Der Naturfreund, der sich mit Hilfe des vorigen Perl-Snapshots eine Landkarte mit den amerikanischen Nationalparks generieren ließ [2], mag sich in einem zweiten Schritt fragen, wie er die verschiedenen Attraktionen möglichst Ressourcen-schonend abklappert. Abbildung 1 offenbart, dass sich die Parks in einigen Gegenden häufen. Ein Tourist erfährt und erwandert sich so vielleicht ein Dutzend Naturschauspiele auf einmal, mit nur einer Flugreise in die USA.
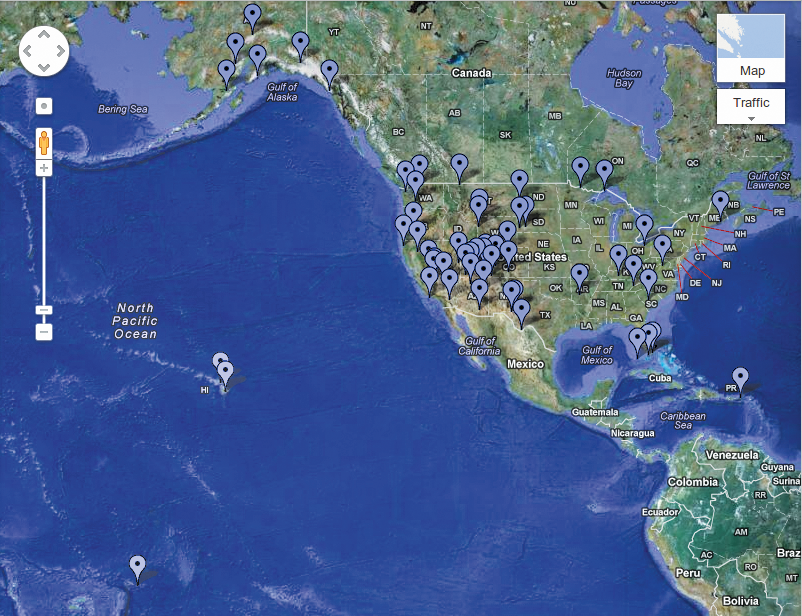
Abbildung 1: Amerikanische Nationalparks häufen sich in bestimmten Gegenden. Mit welcher Route klappern Reisende die meisten ab?
Unschlagbares Gehirn
Das menschliche Gehirn erfasst die sich ballenden Reißnägel auf der Landkarte ohne Anstrengung. In Sekundenbruchteilen steht fest, dass sich die meisten Nationalparks im Westen der kontinentalen Vereinigten Staaten häufen. Ein Computer hat nicht solch einen Überblick. Die Häufungen, so genannte Cluster, errechnet er sich mühevoll. Das Buch “Data Analysis With Open Source Tools” [3] erläutert die Implementierung einer Reihe von mehr oder weniger Erfolg versprechenden Verfahren. Allerdings sind auch sie allesamt dem menschlichen Gehirn unterlegen.
Wer dennoch nach automatischen Lösungen sucht, kommt nicht umhin einen halbwegs funktionierenden Algorithmus zu programmieren. Die Clustering Library [4] implementiert die gängigsten. Das CPAN-Modul Algorithm::Cluster setzt ein Perl-Interface auf die Bibliothek. Die auf dem CPAN verfügbare und dem Modul beiliegende Dokumentation ist allerdings sehr dürftig. Dafür geht die unter [4] genannte PDF-Datei zur Clustering Library ab Seite 47 ausführlich auf die Benutzung des Algorithm::Cluster und der darin verwendeten Algorithmen ein.
Ausgangspunkt für die Berechnungen ist die XML-Datei mit den Geodaten amerikanischer Nationalparks aus dem vorigen Snapshot [2]. Die Datei entstand auf zwei Arten: Einmal mit Hilfe des Webservice auf http://microform.at und einmal mit dem handgeschriebenen Skript »Scraper« . In beiden Fällen fußt das Ergebnis auf frei erhältlichen Wikipedia-Daten. Abbildung 2 zeigt die aus dem Mikroformat extrahierten Daten der Wiki-Seite.

Abbildung 2: Die von Microform.at generierte XML-Datei enthält die Daten der Mikroformate aus der Wiki-Seite zu den amerikanischen Nationalparks.
Ziel des heutigen Snapshots ist es, diese XML-Daten einzulesen, damit sie ein Clusteralgorithmus in eine gruppierte Ausgabe mit geografisch zusammenliegenden Nationalparks umwandelt.
Cluster und Zentroide
Das gängigste Verfahren zum Finden von dichten Stellen in Punkthaufen nennt sich K-means. Es setzt voraus, dass man ungefähr weiß, wie viele verschiedene Cluster der Algorithmus aufstöbern soll. Das ist nicht immer gegeben, aber im vorliegenden Fall liegt es nahe, etwa ein Dutzend Cluster vorzugeben. Denn abzüglich der drei verstreuten Inselgruppen sowie Alaskas, bleiben acht Zonen auf dem US-Festland übrig. Das sollte eine brauchbare Gruppierung ermöglichen, ohne dass die Parks eines Clusters zu weit auseinander liegen.
Der K-means-Algorithmus setzt zunächst willkürlich für jeden gesuchten Cluster so genannte Zentroide fest. Diese Punkte liegen am Anfang noch zufällig im Raum. Später avancieren sie zu Mittelpunkten der Cluster. Es zahlt sich aus, sie mit Bedacht zu platzieren, denn das Verfahren ist nicht stabil: Unterschiedliche Anfangsbedingungen führen zu verschiedenen Resultaten, manche Startpunkte verursachen gar einen Kollaps. Für den Anfang reicht dennoch eine zufällige Verteilung (Abbildung 3).
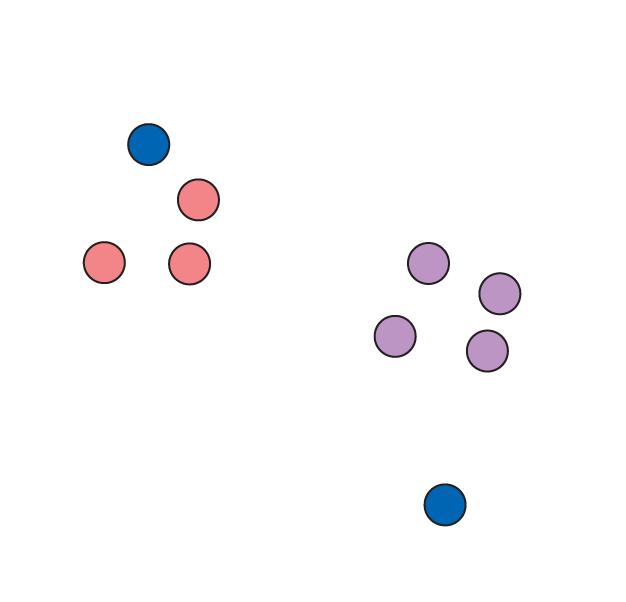
Abbildung 3: Am Anfang gibt es nur Punkte und die blau dargestellten Zentroiden. Der K-Means-Algorithmus startet mit n zufälligen Zentroiden …
Im Anschluss berechnet ein Programm für jeden der n Nationalparks die Distanz zu jedem der k Zentroide. Es ordnet jeden Park dem am nächsten gelegenen Zentroiden zu, baut also einen Cluster aus diesen Parks (Abbildung 4). Aus den geografischen Daten der Parks eines Clusters lässt sich nun deren Gravitationsmittelpunkt berechnen. Der Algorithmus verschiebt den Zentroiden in diesen Mittelpunkt (Abbildung 5).
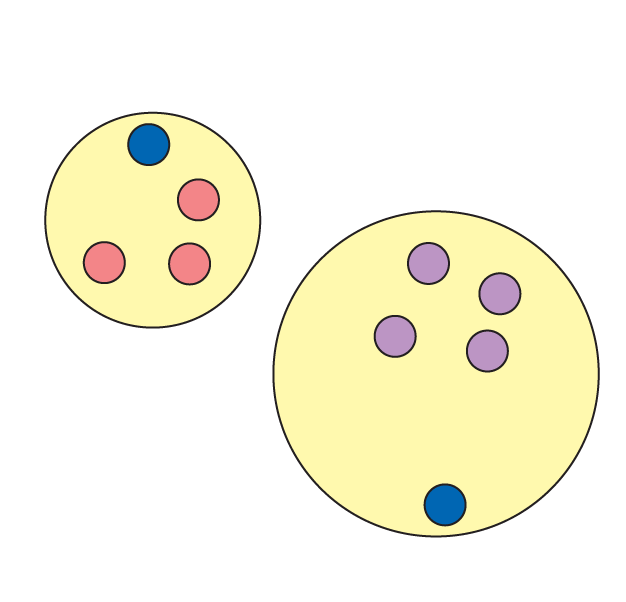
Abbildung 4: … und weist die Punkte dem jeweils nächstgelegenen Zentroiden zu. So entstehen Cluster mit je einem eigenen Zentroiden.
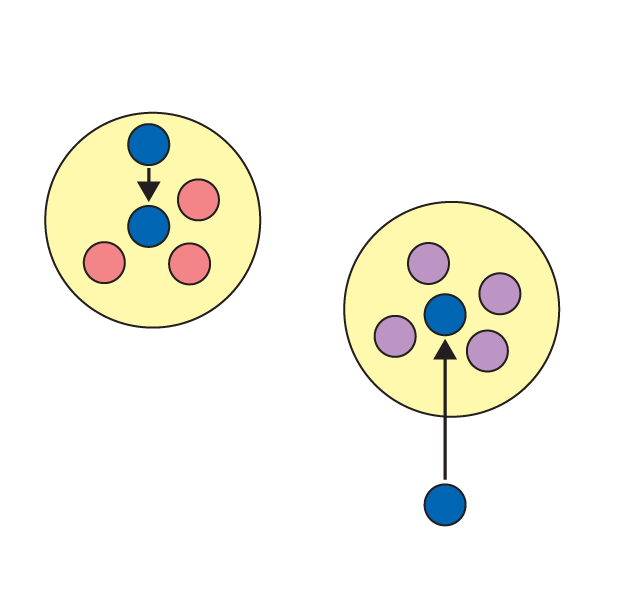
Abbildung 5: Das Skript berechnet aus den geografischen Daten den Gravitationsmittelpunkt der Cluster und schiebt die Zentroiden dorthin.
Dieses Verfahren wiederholt der Algorithmus so lange, bis ein stabiler Zustand erreicht ist. Es kommt vor, dass er vorläufig gebildete Cluster nach einigen Durchgängen wieder auflöst, oder umgekehrt, dass er getrennte Cluster zu einem einzigen verschmilzt. Abbildung 6 zeigt die Gruppierung der Nationalparks als Ausgabe des Skripts in Listing 1.
Listing 1
k-means-cluster
01 #!/usr/local/bin/perl -w
02 use strict;
03 use XML::Simple qw( XMLin );
04 use Algorithm::Cluster qw/kcluster/;
05
06 my $file = "microformat.xml";
07
08 my $data = XMLin( $file );
09
10 binmode STDOUT, ":utf8";
11
12 my $placemarks =
13 $data->{ Folder }->{ Placemark };
14
15 my $coords = [];
16 my $mask = [];
17 my $weights = [ 1, 1 ];
18 my @names = ();
19
20 for my $name ( keys %$placemarks ) {
21
22 my $latlong = $placemarks->{ $name }->
23 { Point }->{ coordinates };
24
25 my( $lon, $lat ) = split ',', $latlong;
26
27 push @$coords, [ $lon, $lat ];
28 push @names, $name;
29 push @$mask, [ 1, 1 ];
30 }
31
32 my %params = (
33 nclusters => 12,
34 transpose => 0,
35 npass => 100,
36 method => 'a',
37 dist => 'e',
38 data => $coords,
39 mask => $mask,
40 weight => $weights,
41 );
42
43 my ($clusters, $error, $found) =
44 kcluster( %params );
45
46 my @by_cluster = ();
47
48 for( my $i = 0; $i < scalar @$clusters;
49 $i++ ) {
50
51 my $id = $clusters->[ $i ];
52 push @{ $by_cluster[ $id ] },
53 [ $names[ $i ],
54 @{ $coords->[ $i ] } ];
55 }
56
57 for my $cluster ( @by_cluster ) {
58 print "Cluster: \n";
59 for my $park ( @$cluster ) {
60 print " @$park\n";
61 }
62 }
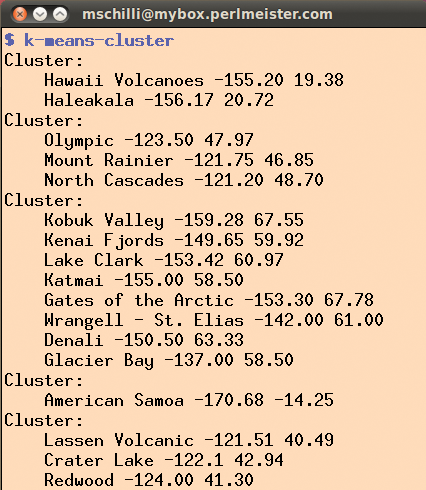
Abbildung 6: Der K-means-Cluster-Algorithmus gruppiert die Parks nach Gegenden.
Wenig überraschend enthält der erste Cluster die beiden auf den hawaiianischen Inseln Big Island und Kauai liegenden Vulkan-Parks. Im nächsten Cluster liegen drei Parks im Bundesstaat Washington. Der dritte Cluster listet die acht Parks im kalten Alaska, der vierte die Insel Samoa und der fünfte schließlich drei in Nordkalifornien.
Bibliothek mit Perl-Wrapper
Statt den Algorithmus von Hand zu programmieren, bietet es sich an, das CPAN-Modul Algorithm::Cluster zu verwenden, das auf der eingangs erwähnten Clustering Library aufbaut und neben K-means auch noch weitere Verfahren kennt. Einem Anwendungsskript bleibt nur noch, die erforderliche Reihe von Datenstrukturen zur Eingabe zu lotsen und von einer Bibliotheksfunktion zurückkommende Daten zu interpretieren.
Das Skript in Listing 1 zieht sich in den Zeilen 3 und 4 die beiden CPAN-Module XML::Simple und Algorithm::Cluster herein. Beide lassen sich mit einer CPAN-Shell ohne Probleme installieren. Die XML-Datei liegt als »microformat.xml« vor: Zeile 8 liest sie durch die aus XML::Simple exportierte Funktion »XMLin« ein. Ausgaben auf ein auf UTF-8 eingestelltes Terminal erfordern die »binmode« -Anweisung aus Zeile 10, sonst meckert das Skript nämlich beim Haleakalã-Nationalpark auf Hawaii wegen seines Sonderzeichens.
Die aus Algorithm::Cluster exportierte Funktion »kcluster()« führt die K-means-Berechnung auf Punkten mit Koordinaten durch, die das Skript über den Parameter »data« als Referenz auf einen Array hereinreicht, der wiederum Punkte-Arrays referenziert. Die Funktion gibt eine Referenz auf einen Array zurück, der für jeden Punkt die zugehörige Cluster-ID angibt. Dabei kommt das Ergebnis in der gleichen Reihenfolge zurück, wie die Punkte vorher hereinwanderten: Enthielt »data« vorher zehn Punkte, ist das Ergebnis eine Referenz auf einen Array mit zehn Elementen, die aus Integerwerten von 0 bis n-1 bestehen, n ist die Zahl der vorher mit »nclusters« festgelegte Anzahl gewünschter Cluster.
Damit das Skript später weiß, welches Element im Ergebnis-Array zu welchem Nationalpark gehört, schiebt Zeile 28 die Namen der Parks in der gleichen Reihenfolge auf einen weiteren Array »@names« . Kommt das Ergebnis zurück, muss die For-Schleife ab Zeile 48 nur noch über alle Index-Werte des Array laufen – anfangend bei 0 bis n-1 – und ruft den zugehörigen Namen aus »@names« mit dem gleichen Index ab. Der Ergebnis-Array namens »@by_cluster« listet dann für jeden Cluster die Parks mit deren Namen und Geokoordinaten auf.
Der Wert für »npass« ist auf 100 gesetzt (Zeile 35), also lässt »kcluster()« das Verfahren 100-mal laufen und erhält so hoffentlich ein stabiles Ergebnis. Die Funktion erwartet als Eingabe auch noch eine Referenz auf einen Array »mask« , der wie die Punkte-Koordinaten in Zweierreihen vorliegt. Er gibt mit »1« an, dass der Wert an dieser Stelle tatsächlich existiert. Wäre ein Wert auf 0 gesetzt, gäbe dies ein Loch im Daten-Array an, über das der Algorithmus hinwegginge.
Der Parameter »method« gibt mit »a« vor, dass zur Zentroid-Bestimmung das arithmetische Mittel der Koordinaten zu wählen ist. Mit »m« könnte man stattdessen auch den Median wählen. Die Gewichte der einzelnen Punkte zur Abstandsbestimmung setzt der Parameter »weights« mit »1,1« auf gleiche Werte.
Wie berechnet das Skript nun die Abstände zwischen den einzelnen Punkten im zweidimensionalen Raum? Hier schummelt der Algorithmus etwas. Denn er interpretiert die aus der Wikipedia-Information stammenden geografischen Längen- und Breitengrade einfach als die x/y-Koordinaten in einem orthogonalen System. Der Parameter »dist« legt mit »e« die euklidische Distanz fest. Die Funktion errechnet also einfach den Abstand zweier Punkte in einem zweidimensionalen Koordinatensystem.
Das ist für die Clusterbestimmung gut genug, obwohl die geografische Breite und Länge natürlich keine x/y-Koordinaten sind. Wer’s genau wissen möchte, rechnet mit dem CPAN-Modul Geo::Distance die genaue Distanz zweier als Länge und Breite vorliegender Koordinatenpunkte auf der Erdoberfläche aus und verwendet statt der Funktion »kcluster()« die ebenfalls von Algorithm::Cluster bereitgestellte Funktion »kmedoids()« . Letztere erwartet allerdings laut Anleitung eine Abstandsmatrix aller Punkte untereinander und arbeitet nicht mit künstlichen Zentroiden-Punkten. Stattdessen wählt sie einen einzelnen Nationalpark in einem Cluster als ungefähren Mittelpunkt.
Ich weiß, was du kaufst
Daten in Clustern zusammenfassen findet in allerlei Systemen mit künstlicher Intelligenz Anwendung. Der Internethändler Amazon etwa weiß, welche weiteren Produkte ein Kunde wahrscheinlich kauft, weil er Kunden ähnlichen Verhaltens in Cluster steckt. Statt mit Mengen von Punkten arbeitet dieses System mit vieldimensionalen Vektoren – jedes Produkt belegt ein Element. Die Cluster sind spärlich gefüllt, da jeder Kunde wenig aus der Gesamtpalette kauft. Ausgefuchste Verfahren jonglieren mit diesen Daten jedoch gekonnt und treffen erstaunlich präzise Vorhersagen. (ake)
Online PLUS
In einem Screencast demonstriert Michael Schilli das Beispiel: http://https://www.linux-magazin.de/plus/2012/11http://]
Infos
- Listings zu diesem Artikel:ftp://www.linux-magazin.de/pub/listings/magazin/2012/11/Perl
- Michael Schilli, “Ausgezeichnet zu Fuß”: Linux-Magazin 10/12, S. 94
- Philipp K. Janert, “Data Analysis With Open Source Tools”: O’Reilly 2012
- Clustering Library: http://bonsai.hgc.jp/~mdehoon/software/cluster/software.htm
Der Autor

Michael Schilli arbeitet als Software-Engineer bei Yahoo in Sunnyvale, Kalifornien. In seinen seit 1997 erscheinenden Snapshots forscht er jeden Monat nach praktischen Anwendungen der Skriptsprache Perl. Unter mailto:mschilli@perlmeister.com beantwortet er gerne Fragen.





