
Red Hats neues Flaggschiff heißt Advanced Server. Mit Zertifizierungen großer Softwarehäuser und Enterprise-Features wie Clustering und Hochverfügbarkeit empfiehlt es sich für den anspruchsvolleren Kunden. Jedoch: Trotz Versionsnummer 2.1 ist es ein Erstlingswerk – und das merkt man.
Früher gab es Red Hat für Oracle oder auch Red Hat für SAP jeweils als separates Produkt, vom entsprechenden Softwarehersteller – neudeutsch ISV (Independend Service Vendor) – zertifiziert. Damit diese Liste nicht irgendwann gegen unendlich geht, haben die Marketingfachleute in Raleigh den Advanced Server ersonnen. Diesem Produkt wollen in den nächsten Wochen mindestens 20 ISVs ihre Unbedenklichkeits-Testate ausstellen, unter ihnen die IBM Software Group, der Applikation-Server-Spezialist BEA und die SAP. Zudem will Red Hat noch verschiedene Hardwarehersteller mit ins Boot holen.
Wie der SuSE Linux Enterprise Server gezeigt hat, rechtfertigen allein schon solche Zertifikate einen hohen Preis. Red Hat hat aber im Gegensatz zur Konkurrenz auch technisch draufgesattelt und wirbt vor allem mit guter Skalierbarkeit auf SMP-Maschinen, Cluster-Unterstützung, Load Balancing mittels Piranha sowie Hochverfügbarkeit. Dem technischen Anspruch entsprechend lag unser Testschwerpunkt daher auf der Cluster-Einrichtung sowie der Hochverfügbarkeitslösung Two-Node-Failover.
Mit der (Hoch-)Verfügbarkeit der Distribution selbst war es nicht so gut bestellt: Red Hat hat es bis weit nach Redak- tionsschluss nicht geschafft, ein fertig konfektioniertes Produkt ins Testlabor zu schicken. Unser Test bezieht sich also lediglich auf die CDs, die Red Hat schließlich als ISO-Images auf dem FTP-Server der Redaktion ablegte.
Installation
Die Installation des Advanced Servers unterscheidet sich kaum von der Professional 7.3, Red Hat verwendet für beide Distributionen das gleiche grafische Installationsprogramm. Die Auswahlseite enthält jetzt zusätzlich die Advanced- Server-Option, im Gegensatz zu verschiedenen Server- und Workstation-Varianten der Professional-Ausgabe.
Die Sprachanpassung ist befriedigend, hin und wieder tauchen trotz deutscher Einstellung englische Meldungen auf. Das ist kein Beinbruch, beim Advanced Server handelt es sich schließlich um eine internationale Distribution, die auch nur mit englischsprachiger Dokumentation ausgeliefert wird. Red Hat unterstellt den Admins ausreichende Englischkenntnisse.
Die Installation im Text-Modus hat sich gegenüber der Professional 7.3 oder älteren Red-Hat-Distributionen nicht verändert, allerdings hat sich ein Fehler in die Tastaturbelegung eingeschlichen: Es ist nicht möglich, ein ö einzugeben, wohl aber ä, ü und ß.
Bei der Installation auf einem Cluster ist die Firewall-Einrichtung komplexer als auf einem Einzelrechner. Die Standardeinstellung während der Installation (mittlere Sicherheitsstufe, keine Dienste oder nur DHCP freigegeben) ist dafür nicht geeignet, sie legt der späteren Cluster-Konfiguration Steine in den Weg. Wir empfehlen zunächst keine Firewall zu aktivieren, sondern die auf den Cluster angepassten Regeln nachträglich von Hand einzutragen.
Red Hat setzt in den eigenen Distributionen auf Gnome als grafischem Frontend, KDE steht optional zur Verfügung. In der Praxis werden die meisten Server aus der Ferne bedient, ein grafischer Desktop ist hier überflüssig. Für eine reine Konsolen-Umgebung genügt es, das Gnome-Paket während der Installation abzuwählen.
Umfangreiche Hardware
Die Dokumentation beschreibt einen Zwei-Knoten-Failover als eine der typischen Anwendungen für Advanced Server 2.1. Dieses Szenario sollte der Test nachvollziehen. Der Cluster für unser Testsystem umfasste zwei Dual-Athlon-Rechner mit 1,533 respektive 1,666 GHz Taktfrequenz, jeweils ausgerüstet mit einem Adaptec 29160 U160-SCSI-Controller. Die Installation des Red-Hat-Systems erfolgte auf den internen Festplatten der beiden Rechner.
Die Unterstützung dieser Hardware gab wenig Anlass zu Klagen, allerdings wurde das RAID-0 eines Promise Fasttrack 100 als zwei separate Festplatten erkannt. Ein bestehender RAID-Verbund müsste daher aufgelöst oder durch ein Software-RAID ersetzt werden. Auch gab es Probleme mit dem APIC des Asus- Boards A7M266-D im ersten Rechner. Bei der Initialisierung blieb der Kernel stets hängen, aber der Boot-Parameter »noapic« sorgte für Abhilfe.
SCSI auf zwei Kanälen
Die Daten der Cluster-Dienste lagerten auf einem Easy-RAID X12 von Starline Computer[2]. Das mit einem Dual-Channel-SCSI-Host-Controller ausgestattete SCSI-IDE-RAID-System (Abbildung 1) war mit zwölf Festplatten à 120 GByte bestückt, von denen allerdings nur vier zum Einsatz kamen: Bei 1,44 TByte Gesamtkapazität war kein Zugriff auf das Gerät möglich, Linux beschwerte sich über einen Lesefehler auf »/dev/sda«. Um beiden Rechnern gleichzeitigen Zugriff auf alle Partitionen des RAID zu ermöglichen, wurden die vier Platten als ein großes Share konfiguriert.
Alternativ unterstützt Red Hat auch Fiberchannel-Systeme, die wiederum für den parallelen Zugriff konfiguriert werden müssen. NAS-Lösungen bleiben derzeit noch außen vor, die Cluster-Konfiguration akzeptiert keine Netzlaufwerke.

Abbildung 1: Der Betrieb als Zwei-Node-Failover-Cluster erfordert ein Dual-Channel SCSI-RAID oder eine Fiberchannel-Lösung, auf die beide Nodes gleichzeitig zugreifen können.
Network Power-Switch
Red Hat empfiehlt im “Cluster Manager Installation and Administration Guide”[3] den Einsatz eines Power-Switches, der bei Ausfall eines Nodes den fehlerhaften Rechner komplett abschalten kann. Damit will Red Hat die Blockade des gemeinsamen RAID-Systems verhindern. Für den Test stellte uns APC den Master Switch AP9212 (Abbildung 3) mit acht schaltbaren Ausgängen zur Verfügung. Der Power-Switch wurde per Netzwerk angebunden, seine serielle Schnittstelle blieb unbenutzt.
Die Cluster-Software konnte den Power- Switch jedoch nicht ganz astrein ansteuern: Statt einen ausgefallenen Rechner mittels »Immediate Off« auszuschalten, löste sie im Test lediglich einen »Immediate Reboot« aus, der den Rechner nur für wenige Sekunden ab- und dann wieder einschaltet.
Je nach BIOS-Konfiguration versucht der Computer danach einen Neustart, wobei ein beschädigter SCSI-Controller das RAID-System tatsächlich blockieren könnte. Da die Software keinen erneuten Abschalten-Befehl sendet, bliebe der Cluster insgesamt stehen.

Abbildung 3: Acht Stromanschlüsse kann der Master Switch AP9212 einzeln schalten. Über den eingebauten Webserver – mit SNMP oder einfach per Telnet – hat der Admin Zugang zur Management-Software.
Cluster-Installation
Die Konfiguration der Cluster-Software mit dem Konsolen-Tool »cluconfig« ist im Cluster-Guide sehr ausführlich beschrieben. An manchen Stellen hat die Software zwar das Handbuch überholt, stellt den Administrator aber nicht vor größere Hürden.
Die Beispiel-Konfigurationen sollte er allerdings nicht unüberlegt übernehmen. So empfiehlt der Cluster-Guide bei der Apache-Konfiguration auf Seite 126, die Option »Relocate when preferred member joins the cluster« zu aktivieren. Der Guide erwähnt aber nicht, dass dieser Umzug alle bestehenden Verbindungen kappt. Wenn der primäre Knoten nach einem Ausfall in den Cluster-Verbund zurückkehrt, brechen daher alle Downloads ab.
Für den Austausch nicht näher genannter Status-Informationen verwenden beide Nodes zwei Quorum-Partitionen. Das sind zwei etwa 10 MByte große Partitionen, die als Raw-Devices ohne Pufferung gemountet sind. Sie enthalten Status-Informationen über beide Cluster-Knoten und über die laufenden Dienste. Damit auch einzelne Dienste redundant laufen können, benötigen sie für ihre Nutzdaten jeweils eine separate Partition auf dem RAID. Der Node, der den Prozess besitzt, mountet dessen Partition.
Verbindungs-Unterbrechungen
Für den Test konfigurierten wir den Cluster als Active-Active. Ein Rechner bot ein NFS-Laufwerk als primären Knoten an, der andere einen Apache-Webserver. Im Falle des Falles übernimmt in dieser Konstellation der jeweils andere Rechner den ausgefallenen Service. Die Failover-Philosophie ist, die Dienste des ausgefallenen Knotens möglichst schnell wieder verfügbar zu machen, nicht jedoch, die bestehenden Verbindungen unbedingt aufrechtzuerhalten. Nur bei Diensten mit verbindungslosen Protokollen (etwa NFS) konnten die Clients meist unbehelligt weiterarbeiten.
Beim Umschalten wird die IP-Adresse des Cluster-Dienstes dem jeweils anderen Rechner zugewiesen. Per IP-Aliasing wird die Adresse an das Netzwerk-Device gebunden, das für das Subnetz zuständig ist. Entsprechend ändert sich die Hardware-Adresse des Clusters, was bei der Konfiguration eines Switches oder Routers berücksichtigt werden muss. Damit verbunden ist auch die Einschränkung, dass jeder redundant laufende Dienst eine eigene IP benötigt.
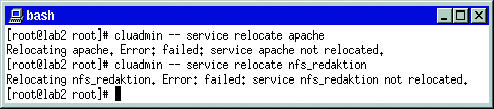
Abbildung 2: Bei unterbrochenem Netzwerk lassen sich Dienste nicht übertragen und sind damit nicht mehr verfügbar.
Unerhörter Heartbeat
Für den Cluster-Betrieb muss mindestens ein Heartbeat Channel eingerichtet werden. Über diese Leitungen sollen die Knoten das Antwortverhalten ihres Gegenübers beobachten, falls dieser die Zeitstempel in der Quorum-Partition nicht mehr aktualisiert.
In der Advanced-Server-Version 2.1 hat der Heartbeat Channel noch keine Funktion. Einzig die Status-Ausgaben von »clustat« respektive »cluadmin« (Abbildung 4) zeigen, ob der Heartbeat Channel online oder offline ist. Aktionen für den jeweiligen Fall lassen sich nicht definieren, auch eine skriptgerechte Abfrage war nicht zu finden. Laut Red Hat wurde dieses Feature auf die nächste Version verschoben.
Die Cluster-Software bietet keine Möglichkeit, beim Ausfall von Diensten oder Geräten eigene Aktionen anzustoßen. Nur über die Status-Funktion im Startskript des Dienstes lässt sich eine Kontrollfunktion implementieren: In einem einstellbaren Zeitintervall ruft die Cluster-Software das Startskript mit dem Parameter »status« auf. Der Cluster-Manager entscheidet dann anhand des Rückgabewerts über den Neustart des Dienstes. Welche Details die Status-Abfrage checkt, liegt in der Hand des Administrators. So prüft das Apache-Skript standardmäßig, ob der Daemon noch läuft.
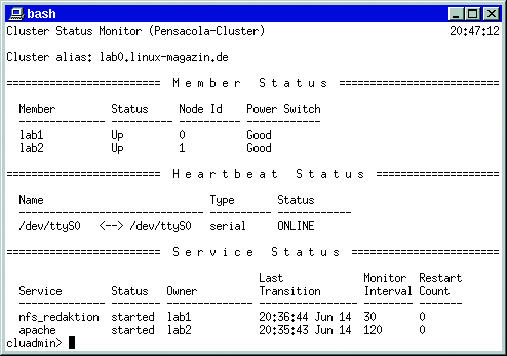
Abbildung 4: Der Zustand des Clusters kann mittels »clustat« oder interaktiv mit »cluster status« von »cluadmin« aus abgerufen werden. In der Service-Sektion ist die Verteilung der Dienste auf die Cluster-Nodes zu sehen.
Ganz oder gar nicht
Einen »relocate« hat ein fehlgeschlagener Status-Check allerdings nicht zur Folge. Entdeckt das Skript einen Fehler, der einen Wechsel auf das Ersatzsystem erzwingt, muss es die Aktion selbst durch »cluadmin — service relocate Dienst« einleiten. Den Komplettausfall eines Knotens fing die Cluster-Software problemlos ab, je nach Dienst mussten die Clients lediglich den Datentransfer wiederholen.
Als unerwartet problematisch entpuppte sich aber der Ausfall einer Teilkomponente. Während der betroffene Knoten nach Unterbrechung der SCSI-Verbindung sauber rebootete, erwies sich ein abgeklemmtes Netzwerkkabel als unlösbares Problem. Trotz funktionierender Heartbeat-Leitung und SCSI-Anbindung war es ohne Netzwerkverbindung zwischen den beiden Knoten nicht möglich, einen Dienst auf den Reserverechner zu verlegen: »cluadmin« meldete stets einen Fehler (Abbildung 2). Die Abbildungen 6 und 7 zeigen die Versuche, den Service von der Rechnerkonsole aus zu übertragen.
Auf der Suche nach den Ursachen stellten wir mit »tcpdump« fest, dass sich »clupowerd« über Port 4004 per TCP/IP munter mit seinem Nachbarn unterhält. Der Daemon ist offensichtlich für Power- Switches zuständig, was den Status »unknown« bei unterbrochener Netzwerkverbindung in Abbildung 5 erklärt.
Beim »relocate« eines Dienstes beobachteten wir zudem eine Kommunikation zwischen beiden Knoten auf Port 4002, auf dem der Cluster Service Manager »clusvmgr« lauscht. Offenbar wird über diese Verbindung die Dienst-Übernahme ausgehandelt – was bei unterbrochener Netzwerkverbindung natürlich schief geht. Letzte Gewissheit wird nur ein Blick in die Sourcen bringen, da keines der Cluster-Tools Manpages hat oder anderweitig dokumentiert ist. Selbst der Hilfe-Parameter »–help« funktioniert nur in den seltensten Fällen.
Die von Red Hat beworbene Failover-Lösung funktioniert also nur beim Totalausfall eines Systems, was nicht unserer Vorstellung von High Availability entspricht. Die einzige Lösung scheint ein Skript zu sein, das per Power-Switch das eigene System hart ausschaltet. Oder wie ein Ex-Kollege es ausdrückte: “Dann brauchen wir noch einen Aufpasser, der den Computer mit der Schrotflinte erschießt, wenn was kaputtgeht.”
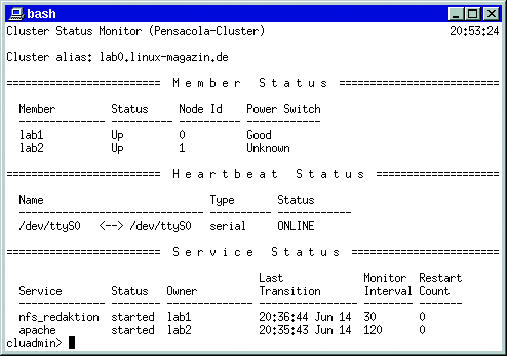
Abbildung 5: Obwohl lediglich die Netzwerk-Verbindung zum zweiten Cluster-Knoten unterbrochen wurde, ist der Status des Power-Switches »unknown«. Dieser Effekt tritt auch ohne konfigurierten Power-Switch auf.
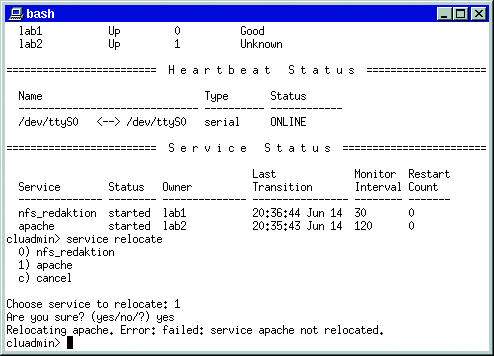
Abbildung 6: Nach einer Unterbrechung der Netzwerkverbindung zu »lab2« ist es selbst manuell nicht mehr möglich, Apache auf den noch unversehrten Rechner zu übertragen.
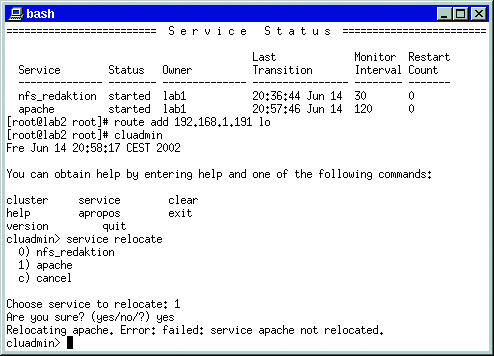
Abbildung 7: Beim Verlegen eines Dienstes versucht die Cluster-Software eindeutig, den anderen Knoten über Ethernet zu erreichen. Schon eine falsche Route legt den Cluster lahm.
Fazit
Red Hat liefert mit dem Advanced Server 2.1 eine bewährte Linux-Distribution, die von vielen Software- und Hardware-Lieferanten zertifiziert werden soll. Wer darauf angewiesen und treuer Red-Hat-Kunde ist, wird also nicht an Red Hats neuem Flaggschiff vorbeikommen. Die High-Availability-Eigenschaften konnten uns jedoch nicht überzeugen: Der Cluster kann nur zwei Knoten enthalten und deckt trotzt hohen Aufwands an zusätzlicher Hardware offensichtlich nur eine Fehlersituation ab: den Komplettausfall eines Servers.
Red Hat Advanced Server 2.1 |
|
Lieferumfang: 4 CDs, 2 Handbücher (englisch) Support: 1 Jahr Red Hat Network und Maintenance Basis: 1 Jahr Installations- und Konfigurations-Support Standard: 1 Jahr Komplett-Support, 4 Stunden Reaktionszeit an Werktagen Premium: 1 Jahr Komplett-Support, 1 Stunde Reaktionszeit (24×7) Preis: 1040 Euro/800 Dollar (Basis) 1970 Euro/1500 Dollar (Standard) 3250 Euro/2500 Dollar (Premium) |

Infos |
|
[1] Red Hat Deutschland: [www.redhat.de] [2] Starline Computer, Easy-RAID X12: [www.starline.de/produkte/easyraid/asyraid_x12/easyraid_x12.htm] [3] Cluster-Guide: [www.redhat.com/docs/manuals/advserver/RHLAS-2.1–Manual/cluster-manager] |





