
© Phongphanich Limprasutr, 123RF
Datenmengen im Petabyte-Bereich verarbeiten Unternehmen wie Google und Facebook nach dem Map-Reduce-Verfahren. Für bestimmte Analysen dient es als kraftvolle Alternative zu SQL-Datenbanken, und mit Apache Hadoop existiert eine Open-Source-Implementierung.
Gigantische Datenmengen sind in Zeiten von Google und Facebook nicht mehr ungewöhnlich. So saß Facebook bereits 2010 auf einem Datenberg von 21 Petabyte, ein Jahr später waren es bereits 30 Petabyte [1]. Würde man diese Daten auf 1-Terabyte-Festplatten speichern und die Festplatten übereinanderstapeln, entstünde ein Turm, der doppelt so hoch ist wie das Empire State Building in New York.
Automatisch verteilt
Das Beispiel verdeutlicht, dass die Verarbeitung und Analyse dieser Daten schon aufgrund der schieren Menge verteilt auf mehrere Rechner erfolgen sollte. Seit je ist jedoch gerade diese Art der Verarbeitung sehr anspruchsvoll und viel Zeit wird darauf verwendet, immer wieder auftretende Probleme wie die Parallelisierung, die Verteilung der Daten auf die Rechenknoten und insbesondere die Behandlung von Fehlern während der Verarbeitung zu lösen. Um seine Entwickler von diesen wiederkehrenden Aufgaben zu befreien, hat Google das Map-Reduce-Framework entwickelt.
Die Idee beruht auf der Erkenntnis, dass die meisten datenintensiven Programme bei Google konzeptuell sehr ähnlich sind. Aus den Gemeinsamkeiten entstand eine allgemeine Abstraktionsschicht, die den Datenfluss in zwei Hauptphasen teilt: die Map- und die Reduce-Phase [2]. Ähnlich wie in der funktionalen Programmierung können die Berechnungen innerhalb der Map-Phase parallel auf mehreren Rechnern ablaufen. Gleiches gilt auch für die Reduce-Phase, sodass sich Map-Reduce-Anwendungen massiv parallelisiert in einem Rechnernetzwerk (Cluster) betreiben lassen.
Die automatische Parallelisierung größerer Berechnungen erklärt jedoch noch nicht die Popularität von Map-Reduce in Unternehmen wie Adobe, Ebay, Twitter & Co. Sicherlich hat es geholfen, dass mit Apache Hadoop [3] eine Open-Source-Implementierung von Map-Reduce existiert. Noch wichtiger dürfte allerdings gewesen sein, dass Hadoop auf Standardhardware installierbar ist und sehr gute Skalierungseigenschaften besitzt. Auf diese Weise lässt sich ein Map-Reduce-Cluster kosteneffizient betreiben und durch den Kauf zusätzlicher Rechner dynamisch erweitern.
Ebenso attraktiv ist es auch, gar keinen eigenen Map-Reduce-Cluster zu betreiben, sondern vorhandene Cloudkapazitäten zu nutzen. Amazon beispielsweise vermietet unter dem Namen “Amazon Elastic MapReduce” einen an die Anforderungen anpassbaren Cluster.
Dateisystem und Framework
Den Grundpfeiler eines Map-Reduce-Systems bildet ein verteiltes Dateisystem, dessen prinzipielle Funktionsweise schnell erklärt ist: Es teilt große Dateien in gleichgroße Blöcke, die verteilt im Cluster gespeichert werden. Da bei größeren Clustern immer mal Rechner ausfallen, legt das verteilte Dateisystem jeden Block mehrfach (im Regelfall dreimal) auf verschiedenen Rechnern ab.
Die Idee hinter Map-Reduce beruht darauf, eine alternierende Folge so genannter Map- und Reduce-Funktionen, die der Benutzer selbst implementiert, auf die Eingabedaten anzuwenden. Die parallele Ausführung dieser Funktionen und die damit verbundenen Schwierigkeiten übernimmt das Framework automatisch. Eine Iteration läuft in drei Phasen ab: Map-, Shuffle- und Reduce-Phase (siehe Abbildung 1).
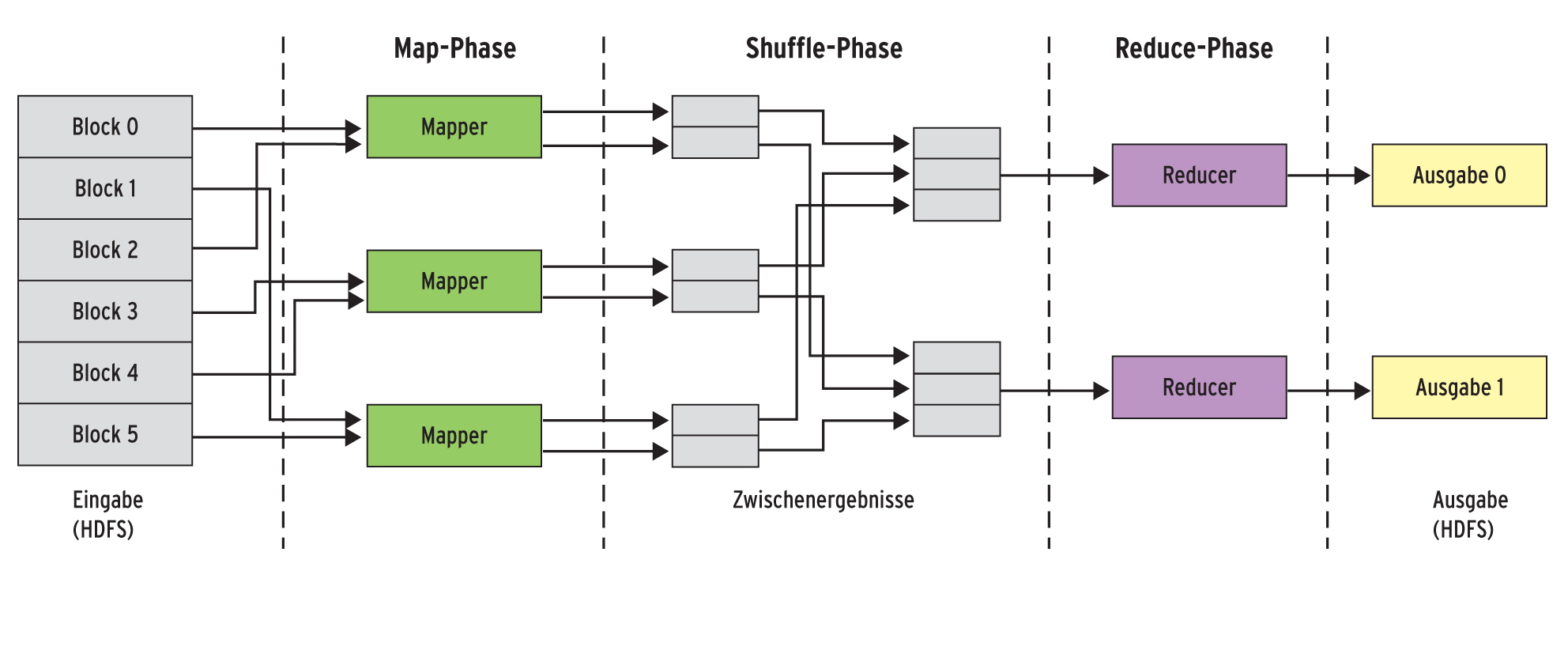
Abbildung 1: Das Map-Reduce-Framework unterteilt die Datenverarbeitung in die Map-, Shuffle- und Reduce-Phase (von links nach rechts). Das Abarbeiten erfolgt weitgehend parallelisiert auf mehreren Rechenknoten. Dabei nutzt die Map-Phase die verteilte Speicherung der Blöcke im Dateisystem HDFS.
Die Map-Phase wendet die Map-Funktion auf alle Einträge der Eingabe an. Dazu starten auf den Rechnern im Cluster die so genannten Mapper, deren Aufgabe es ist, diejenigen Blöcke der Eingabedatei zu verarbeiten, die jeweils lokal auf dem Rechner liegen. Die Berechnungen laufen folglich dort ab, wo die Daten auch gespeichert sind (Daten-Lokalität). Da es keine Abhängigkeiten zwischen verschiedenen Mappern geben darf, können sie parallel und unabhängig voneinander arbeiten.
Sollte ein Rechner im Cluster ausfallen, kann ein anderer Computer, der über eine Replikation des entsprechenden Blocks verfügt, die verloren gegangenen oder noch nicht berechneten Map-Ergebnisse neu berechnen.
Paarweise
Ein Mapper verarbeitet den Inhalt eines Blocks zeilenweise, wobei er jede Zeile als ein Schlüssel-Wert-Paar interpretiert. Die eigentliche Map-Funktion wird für jedes dieser Paare einzeln aufgerufen und erzeugt daraus eine beliebig große Liste an neuen Schlüssel-Wert-Paaren:
map: (key, value) list(key', value')
Die Shuffle-Phase sortiert die Ergebnis-Paare der Map-Phase zunächst lokal nach ihren Schlüsseln. Anschließend ordnet Map-Reduce sie abhängig von ihrem Schlüssel einem so genannten Reducer zu. Dabei stellt das Framework sicher, dass alle Paare mit dem gleichen Schlüssel auch denselben Reducer zugeordnet bekommen.
Jetzt gibt’s Traffic
Da die Ausgabe der Map-Phase beliebig über den Cluster verteilt sein kann, muss das System in der Shuffle-Phase die Ausgaben der Map-Phase größtenteils über das Netzwerk zu dem entsprechenden Reducer übertragen. Daher gehen bei diesem Schritt häufig große Datenmengen übers Netzwerk. Der Reducer fasst schließlich alle Paare mit gleichem Schlüssel zusammen und bildet aus den Werten eine sortierte Liste. Der Schlüssel zusammen mit der sortierten Liste der Werte bildet dann die Eingabe für die Reduce-Funktion.
Die Reduce-Funktion verdichtet typischerweise die Liste der Werte zu einer kürzeren Liste, beispielsweise indem sie die Werte aggregiert. Nicht selten liefert sie daher auch nur einen einzelnen Wert als Ausgabe. Allgemein betrachtet erzeugt die Reduce-Funktion jedoch genau wie die Map-Funktion eine beliebig große Liste an Schlüssel-Wert-Paaren:
reduce: (key, List(values))list(key', value')
Die Ausgabe der Reduce-Phase lässt sich bei Bedarf wiederum als Eingabe für eine weitere Map-Reduce-Iteration verwenden.
Als passendes Anschauungsbeispiel für den Map-Reduce-Einsatz eignet sich eine Websuchmaschine. Für ein solches System ist es besonders wichtig, die Relevanz einer Seite im Netz möglichst gut einschätzen zu können.
Pagerank berechnen
Eines von vielen Kriterien ist dabei die Anzahl anderer Seiten, die auf eine Seite im Netz verlinken. Vereinfacht dargestellt bildet diese Annahme auch die Grundidee hinter dem Pagerank-Algorithmus, mit dessen Hilfe Google die Relevanz einer Seite im Netz einschätzt. Dazu durchsucht Google fortlaufend das Web nach neuen Informationen und speichert dabei unter anderem die Verlinkungen zwischen den Seiten. Wer sich die Anzahl der Seiten und Links im Netz vorstellt, versteht sofort, wieso die parallelisierte Berechnung des Pagerank-Algorithmus eine der ersten Anwendungen von Map-Reduce bei Google war.
In Abbildung 2 ist die Berechnung der Anzahl eingehender Links für eine Seite mit Hilfe von Map-Reduce schematisch dargestellt. Die Eingabe besteht hier aus einer Menge von »(A,B)« -Paaren, die jeweils einem Link von Seite A nach Seite B entsprechen. Sie ist in zwei Blöcke mit jeweils sechs Einträgen unterteilt – in der Praxis umfasst die Eingabe natürlich sehr viel mehr Blöcke.
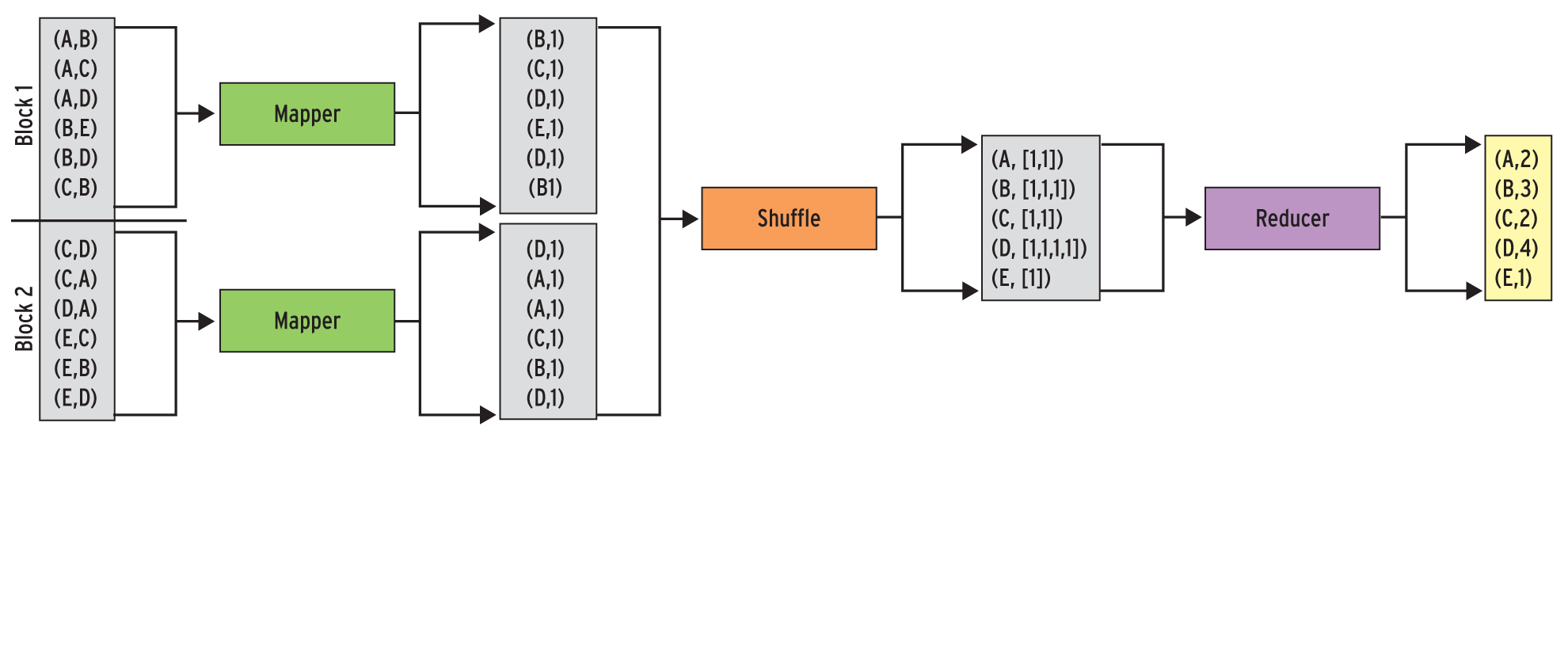
Abbildung 2: Schematischer Ablauf einer Map-Reduce-Berechnung. Der Mapper (links) wendet eine Funktion auf alle Schlüssel-Wert-Paare an, Shuffle sortiert sie nach dem Schlüssel und der Reducer (rechts) errechnet zu jedem der Schlüssel ein Ergebnis.
Jeden Block der Eingabe weist das Framework einem Mapper zu, der die Map-Funktion auf jeden Eintrag aus dem Block anwendet. Um die Anzahl der Seiten zu zählen, die auf eine bestimmte Seite verlinken, bietet es sich an, das Ziel des Links (zweiter Wert im Eingabe-Paar) als Schlüssel für die Ausgabe der Map-Funktion zu verwenden, da im weiteren Verlauf alle Paare mit dem gleichen Schlüssel zusammengefasst werden. Als Wert für die Ausgabe der Map-Funktion dient die Zahl 1, die signalisiert, dass es einen Link auf die entsprechende Seite gibt (Listing 1).
Listing 1
Map-Funktion (Pseudocode)
01 method Map(source,target) 02 emit(target,1) 03 end
Sortieren und aggregieren
Die Shuffle-Phase fasst alle Ausgaben der Map-Phase mit identischem Schlüssel zusammen, sortiert und verteilt sie auf die Reducer. Folglich gibt es für jede verlinkte Seite genau ein Paar mit der entsprechenden Seite als Schlüssel und einer Liste von Einsen als Wert. Der Reducer wendet dann die Reduce-Funktion auf jedes dieser Paare an. In diesem Fall muss sie einfach die Einsen in der Liste summieren (Listing 2).
Listing 2
Reduce-Funktion (Pseudocode)
01 method Reduce(target,counts[c1,c2,...]) 02 sum <- 0 03 for all c in counts[c1,c2,...] do 04 sum <- sum + c 05 end 06 emit(target,sum) 07 end
Beim Betrachten des schematischen Ablaufs fällt schnell auf, dass ein Mapper durchaus mehrere Schlüssel-Wert-Paare für eine Seite erzeugen kann. In der Ausgabe des Mappers für Block 1 kommt beispielsweise gleich zweimal das Paar »(B,1)« vor, denn in Block 1 gibt es zwei Links auf Seite B.
Auffällig ist zudem, dass erst der Reducer die Werte aggregiert. Abhilfe schaffen im Hadoop-Framework so genannte Combiner, die die Ausgaben eines Mappers aufbereiten, bevor sie über das Netzwerk zum Reducer geschickt werden, um so die Menge der übertragenen Daten zu reduzieren.
In diesem Beispiel kann der Combiner einfach alle Ausgaben eines Mappers bezüglich einer Seite zusammenfassen und summieren (siehe Abbildung 3). Combiner lassen sich aber nicht immer sinnvoll in den Ablauf integrieren und sind daher optional. Der Benutzer muss jeweils für seinen konkreten Anwendungsfall entscheiden, ob ein Combiner eine Verbesserung bringt oder nicht.
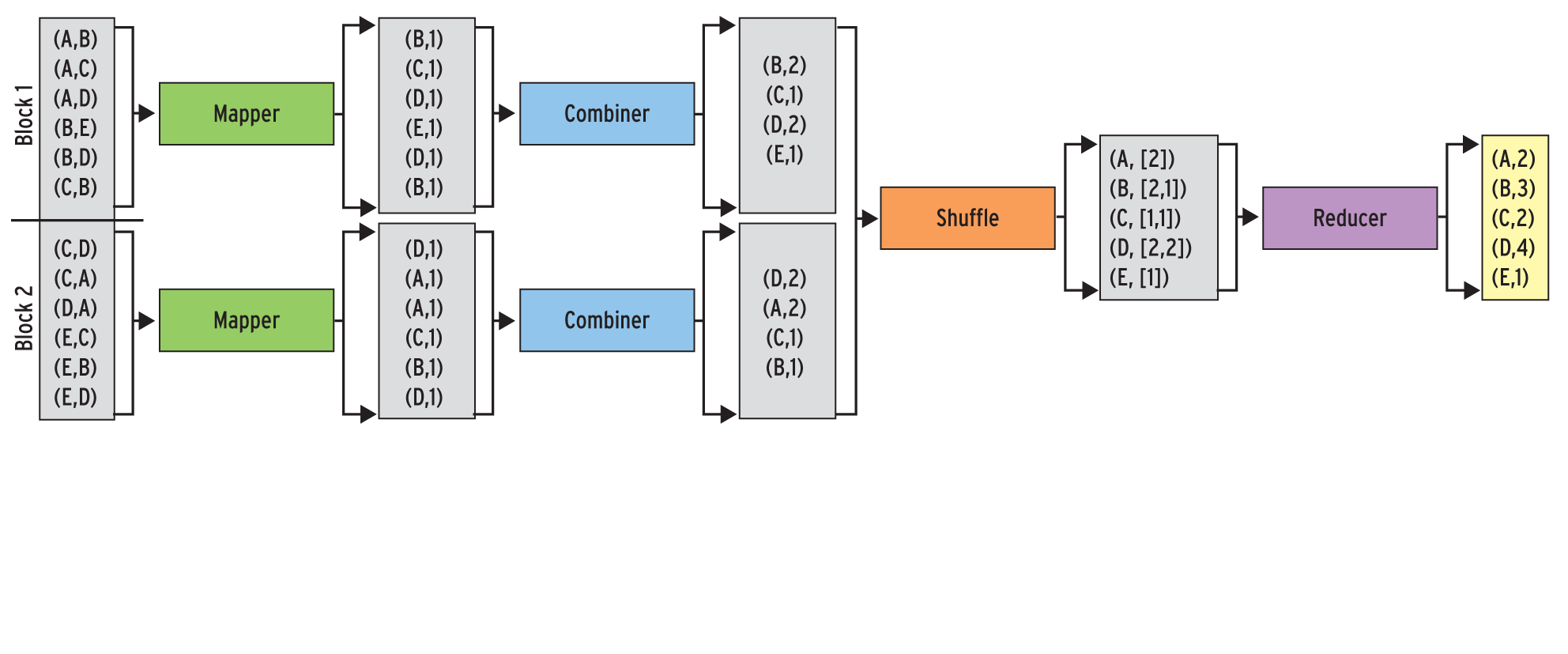
Abbildung 3: Der Einsatz so genannter Combiner ist optional. Vor allem bei arithmetischen Operationen kann er jedoch die Auslastung des Netzwerks verringern, indem er die große Anzahl von Zwischenergebnissen auf wenige Elemente reduziert.
Freie Implementierung
Das Projekt Apache Hadoop [3] ist eine Open-Source-Implementierung von Googles verteiltem Dateisystem Google File System (GFS, [4]) und dem Map-Reduce-Framework. Zu den wichtigsten Unterstützern, die das Projekt über Jahre hinweg maßgeblich vorangetrieben haben, zählt in erster Linie Yahoo. Heute beteiligen sich viele weitere namhafte Unternehmen wie Facebook und IBM sowie eine aktive Community an der Weiterentwicklung. Über die Jahre sind viele angegliederte Projekte entstanden, die das klassische Framework um zusätzliche Features erweitern (siehe Kasten “Das Hadoop-Ökosystem”).
Das Hadoop-Ökosystem
Zum Hadoop-Ökosystem gehören zahlreiche Erweiterungen, die unterschiedliche Anwendungsszenarien abdecken:
Pig [5] ist ein von Yahoo entwickeltes System, das Datenanalysen im Map-Reduce-Framework vereinfacht. Der Benutzer schreibt seine Anfragen in der Datentransformationssprache Pig Latin, die einen inkrementellen und prozeduralen Stil gegenüber dem deklarativen Ansatz von SQL favorisiert. Die Pig-Latin-Programme lassen sich automatisch in eine Reihe von Map-Reduce-Iterationen übersetzen, sodass der Entwickler keine Map- und Reduce-Funktionen von Hand implementieren muss.
Hive [6] ist ein von Facebook entwickeltes verteiltes Data Warehouse. Im Gegensatz zu Pig Latin folgt die Anfragesprache von Hive dem deklarativen Stil von SQL. Das Ausführen erfolgt auch hier über eine automatische Abbildung auf das Map-Reduce-Framework.
Hbase [7] ist eine spaltenorientierte No-SQL-Datenbank, die auf HDFS basiert. Wie es bei No-SQL-Datenbanken üblich ist, eignet sich Hbase im Gegensatz zu HDFS auch gut für wahlfreie Lese- und Schreibzugriffe (Random Access).
Das Hadoop Distributed Filesystem (HDFS) folgt dem Vorbild des Google File System. Die Architektur entspricht dem klassischen Master-Slave-Prinzip, bei dem ein Rechner im Cluster (»NameNode« ) die Verwaltung übernimmt und die restlichen Rechner (»DataNode« ) die eigentliche Speicherung der Datenblöcke. Jeder Datenblock ist dabei auf mehreren Rechnern gespeichert, was neben der Ausfallsicherheit auch die Datenlokalität verbessert, denn in einem großen Cluster ist die Bandbreite des Netzwerks eine knappe Ressource.
Möglichst lokal
Um das Netzwerk zu entlasten, verteilt Hadoop die Berechnungen in der Map-Phase so auf die Rechner, dass möglichst viele Daten lokal gelesen werden können. Entwickelt und optimiert wurde HDFS insbesondere zur effizienten Unterstützung von Write-once/read-many-Zugriffsmustern bei großen Dateien. Daher haben die Entwickler vor allem Wert auf einen hohen Datendurchsatz gelegt, was sich allerdings negativ auf die Latenz auswirkt. Konsequenterweise unterstützt HDFS keine Änderungen an den gespeicherten Dateien.
Die Map-Reduce-Implementierung in Hadoop folgt ebenfalls der Master-Slave-Architektur: Der »JobTracker« koordiniert den Ablauf und weist den einzelnen Task-Trackern ihre Teilaufgaben zu. Ein »TaskTracker« kann dabei sowohl die Aufgabe eines Mappers als auch die eines Reducers übernehmen.
Pluspunkt Skalierung
Die wichtigste Eigenschaft von Map-Reduce ist die lineare Skalierbarkeit des Systems. Vereinfacht gesagt: Die Berechnungsdauer einer Map-Reduce-Anwendung halbiert sich in etwa, wenn man die Größe des Clusters verdoppelt. In der Praxis hängt das tatsächliche Skalierungsverhalten natürlich von vielen Faktoren wie beispielsweise der Art des zu lösenden Problems ab. Hinweise für den Einsatz des Framework gibt der Kasten “Hadoop in der Praxis”.
Hadoop in der Praxis
Neben der offiziellen Hadoop-Distribution von Apache [3] ist vor allem “Cloudera’s Distribution Including Apache Hadoop” (CDH) weit verbreitet. Auf der Webseite von Cloudera [8] gibt es unter anderem fertig konfigurierte Systemabbilder für diverse virtuelle Maschinen zum Herunterladen.
Tutorials: Eine umfassende Einführung in Hadoop findet sich in Tom Whites Buch “Hadoop: The Definitive Guide” [9]. Auf den Webseiten von Cloudera gibt es außerdem einige Schritt-für-Schritt-Beispiele mit kleinen Datensätzen.
Programmiersprache: Hadoop ist in Java implementiert, weshalb auch die Map- und Reduce-Funktionen in der Regel in Java umgesetzt werden. Es gibt aber auch Möglichkeiten, andere Sprachen wie beispielsweise Python oder C++ einzubinden.
Java-API: Seit der Hadoop-Version 0.20 gibt es ein neues Map-Reduce-API für Java. Die Klassen des alten API finden sich im Java-Package »org.apache.hadoop.mapred.*« , die neuen im Package »org.apache.hadoop.mapreduce.*« . Viele verfügbaren Beispiele verwenden noch das alten API. Dennoch empfiehlt es sich für Neueinsteiger, gleich auf die neue Schnittstelle zu setzen. Es gilt zu beachten, dass in einem Map-Reduce-Programm nicht beide Versionen gemeinsam zum Einsatz kommen dürfen.
Neben der Skalierbarkeit besitzt Hadoop weitere Eigenschaften, die das Entwickeln von verteilten Anwendungen erleichtern. Beispielsweise fängt es Hardware-Ausfälle automatisch ab und führt fehlgeschlagene Teilaufgaben erneut aus. Außerdem startet es Teilaufgaben gegen Ende der Berechnung mehrfach, um zu verhindern, dass vereinzelte Ausreißer den Gesamtablauf unnötig verzögern. Dieses Vorgehen ist als spekulative Ausführung bekannt.
Die automatische Parallelisierung der Ausführung durch Hadoop bedeutet allerdings nicht, dass man sich hierzu keine Gedanken mehr machen sollte. Der Entwickler muss das zu lösende Problem in einer recht starre Folge von Map- und Reduce-Phasen abbilden, was oftmals sehr schwierig oder gar unmöglich ist. Dieses doch relativ unflexible Schema ist daher auch einer der Haupt-Kritikpunkte an Map-Reduce.
Map-Reduce vs. SQL
Große Datenbestände zu verwalten und zu analysieren gilt als klassische Domäne von relationalen Datenbanken, die mit SQL eine deklarative Anfragesprache besitzen. Bedeutet nun der breite Einsatz von Map-Reduce, dass relationale Datenbanken überflüssig werden? Diese Frage lässt sich nur von Fall zu Fall beantworten. Die folgenden Aspekte können als Orientierungshilfe dienen:
Datengröße: Map-Reduce eignet sich gut für sehr große Datenmengen, die die Verarbeitungskapazität eines einzelnen Servers sprengen. Um mit relationalen Datenbanken in vergleichbare Dimensionen vorzustoßen, muss die Anfragebearbeitung ebenfalls parallelisiert erfolgen. Das ist zwar möglich, doch skalieren diese Ansätze typischerweise nicht linear mit der Anzahl verwendeter Rechner.
Zugriffsmuster: Eine der Ideen hinter Map-Reduce ist es, Daten in großen Blöcken sequenziell zu verarbeiten, um die Leserate zu optimieren. Im Gegensatz dazu lassen sich Anfragen, die nur einen Teil der Daten betreffen, mit Hilfe von Indexen bei relationalen Datenbanken effizienter beantworten. Soll Map-Reduce eine solche Anfrage bearbeiten, muss es den gesamten Datensatz lesen.
Datenrepräsentation: Eine der Annahmen von relationalen Datenbanken ist, dass Daten eine inhärente Struktur (ein Schema) besitzen. Diese Struktur nutzen die Anwender, um eine möglichst redundanzfreie Speicherung der Daten in verschiedenen Tabellen zu erreichen. Für Anfragen bedeutet dies jedoch, dass sie oft Informationen aus verschiedenen Tabellen kombinieren müssen. Map-Reduce kennt das Konzept eines Schemas nicht, sondern überlässt es dem Benutzer, während der Map-Phase die Daten in die gewünschte Form für die Reduce-Phase zu konvertieren. Das hat den Vorteil, dass sich Map-Reduce universeller einsetzen lässt als relationale Datenbanken.
Ad-hoc-Anfragen: Eine der großen Stärken von relationalen Datenbanken ist die deklarative Anfragesprache SQL. Bei Map-Reduce dagegen muss der Programmierer jede Aufgabe individuell lösen.
Koexistenz
Diese Liste ließe sich noch erweitern. Ein wichtiger Punkt für die Entscheidung einer Firma wird sicherlich auch die Frage der Nachhaltigkeit und Langlebigkeit von Hadoop sein. Relationale Datenbanken sind fest etabliert und viele Firmen besitzen ausreichend Know-how, um ihre Bedürfnisse ausreichend abbilden zu können. Zu erwarten ist daher eine Koexistenz, bei der sich die beiden Ansätze gegenseitig ergänzen.
Fazit
Aus der ursprünglichen Idee von Google, die Komplexität einer verteilten Anwendung zu reduzieren, hat sich mit Apache Hadoop ein reichhaltiges Ökosystem an vielfältigen Werkzeugen zur Datenverarbeitung entwickelt. Insbesondere wegen seiner hervorragenden Skalierungseigenschaften, eingebauter Fehlertoleranz und vieler Automatismen erweist sich Apache Hadoop bei der Arbeit in zahlreichen Unternehmen und Forschungsgruppen als essenziell.
Das bedeutet keinesfalls, dass klassische Datenverarbeitungssysteme wie relationale Datenbanken überflüssig werden. Wenn es aber darum geht, das ständig wachsende digitalisierte Wissen der Welt zu verarbeiten, werden skalierende Systeme wie Hadoop in Zukunft weiter an Bedeutung gewinnen. (mhu)
Infos
- Paul Yang, “Moving an Elephant: Large Scale Hadoop Data Migration at Facebook”: https://www.facebook.com/10150246275318920
- Dean, J., Ghemawat, S., “MapReduce: Simplified Data Processing on Large Clusters”: In Operating Systems Design and Implementation (OSDI), 2004, S. 137-150
- Apache Hadoop: http://hadoop.apache.org
- Ghemawat, S., Gobioff, H., Leung, S.T.: “The Google File System”: In Scott, M.L., Peterson, L.L., eds.: Symposium on Operating Systems Principles (SOSP), ACM (2003), S. 29-43
- Pig: http://pig.apache.org
- Hive: http://hive.apache.org
- Hbase: http://hbase.apache.org
- CDH von Cloudera: http://www.cloudera.com
- White, T., “Hadoop – The Definitive Guide”: 2edn., O’Reilly, 2011





