
© maridav, 123Rf
Macht ein Clusterknoten schlapp, startet die HA-Software Pacemaker bekanntermaßen die dabei mitgerissenen Dienste auf einem anderen Knoten neu. Wenig bekannt ist des Schrittmachers Dienste-Monitoring, mit dessen Hilfe der Clustermanager hängenden Diensten einzeln auf die Beine hilft.
Pacemaker hat sichzur unangefochtenen Standard-HA-Lösung auf Linux-Systemen entwickelt. Fällt einer von zwei Knoten eines Clusters aus, startet Pacemaker die ausgefallenen Dienste auf dem anderen Clusterknoten neu. Wer Pacemaker allerdings nur zu solchen Failover-Zwecken einsetzt, bringt sich um den Nutzen der besten Features. Dass der Schrittmacher auch abgestürzten Applikationen automatisch wieder auf die Beine helfen kann, ist vielen Admins erstaunlicherweise bis heute unbekannt.
Mehr als nur Umschalten
Es gibt weitaus mehr Gründe dafür, dass ein Dienst nicht mehr läuft, als nur den Ausfall des Servers, der den Dienst bis dahin beheimatet hatte. Applikationen stürzen ab oder werden vom Kernel mangels Arbeitsspeicher (OOM, Out of Memory) in die Knie gezwungen.
Admins rücken solchen Problemen üblicherweise mit umfangreichem Monitoring zu Leibe. Ein nicht mehr laufender Service produziert eine Warnung in Nagios, Icinga & Co. und informiert so den Systembetreuer. Bis dieser allerdings in der Lage ist, das Problem zu lösen, vergeht in der Regel eine gewisse Zeit. Währenddessen ist der abgestürzte Dienst nicht verfügbar – obwohl die restlichen Dienste des Clusters wie gewohnt weiterlaufen, bleibt der Failover also aus.
Das war der Grund für die Entwickler, dem Pacemaker mehr als das bloße Umschalten zwischen zwei Clusterknoten beizubringen. Der Schrittmacher kennt einfaches Monitoring, das in vielen Fällen ausreicht, um ein Problem in den Griff zu kriegen, etwa indem es ein abgestürztes Programm neu startet.
Dabei kommuniziert Pacemaker nicht direkt mit den Diensten. Trägt der Admin beispielsweise seinem Clustermanager auf, dass der Webserver zu starten ist, dann wird Pacemaker Apache nicht direkt aufrufen. Diese Aufgabe erledigen die so genannten Resource Agents: Sie bilden die Schnittstelle zwischen Dienst und Cluster-Schrittmacher. Ein typischer Agent ist ein Shellskript, spezifisch für ein bestimmtes Programm.
Ressourcen-Agenten kennen drei Argumente, die ihnen der Clustermanager beim Aufruf mit auf den Weg geben kann: »start« , »stop« und »monitor« . Pacemaker ruft die Agents mit diesen Parametern auf und erwartet, dass sie entsprechend funktionieren: »start« sollte einen Dienst starten, »stop« sollte ihn beenden und »monitor« informiert Pacemaker darüber, ob ein Dienst noch läuft oder nicht.
Agenten-Klassen
Die Resource Agents für Pacemaker sind in drei Kategorien eingeteilt: LSB-Agenten, also normale Init-Skripte nach LSB-Standard. Daneben gibt es die Heartbeat-Agenten, die aber als veraltet gelten. Die Kategorie der OCF-Agenten bildet die Königsklasse: Diese Agents sind für den Einsatz mit Pacemaker konzipiert und erlauben es in vielen Fällen, Parameter für die Konfiguration eines Dienstes direkt aus der Clusterkonfiguration anzugeben. Allen genannten Klassen ist gemein, dass sie die drei Optionen zum Starten, Beenden und Überwachen von Diensten kennen müssen.
Bevor der Admin die eigene Pacemaker-Installation auf Monitoring trimmt, sollte er testen, ob jeder Resource Agent diese Parameter tatsächlich beherrscht. Denn während bei OCF-Agenten diese Parameter praktisch immer funktionieren, sieht es bei den Init-Skripten bisweilen düster aus: Insbesondere auf Debian-Systemen finden sich diverse, die den »monitor« -Parameter nicht verstehen und daher eine Fehlermeldung ausgeben.
Falsch verstanden
Für den Clustermanager ist das fatal, denn aufgrund der Fehlermeldung vermutet er, der Dienst laufe nicht. Versucht er im Anschluss den Dienst zu starten, führt das meist zu einem Chaos im Cluster. Der Aufruf eines Init-Skripts mit dem »monitor« -Kommando bringt dem Admin bereits vorher beruhigende Gewissheit. Gibt der Agent einen plausiblen Wert zurück, ist das Init-Skript fit für den Monitoring-Einsatz in Pacemaker.
Wenn klar ist, dass alle Agents in einem Pacemaker-Setup den Parameter »monitor« kennen, spricht nichts dagegen, die Funktion tatsächlich auch in der Pacemaker-Konfiguration zu verwenden. Als bevorzugtes Tool, um das Clustersetup anzupassen, gilt die CRM-Shell (Abbildung 1), sie lässt sich auf Pacemaker-Systemen durch den Aufruf von »crm configure« in der Bash starten.
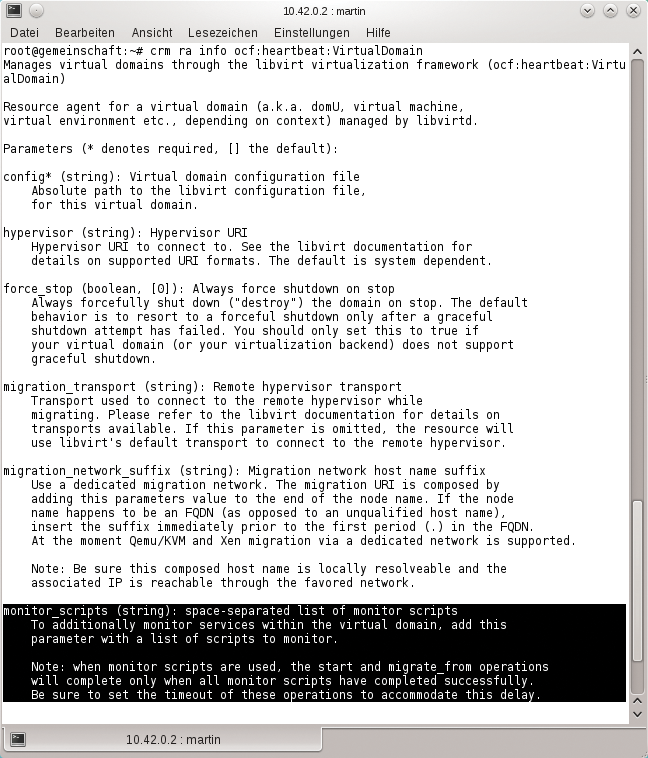
Der Befehl führt unmittelbar in das »configure« -Menü. Es schadet nicht, zuvor sicherzustellen, dass in der Umgebungsvariablen »$EDITOR« tatsächlich der Kommandozeilen-Editor der eigenen Präferenz steht. Denn der nächste Befehl auf der CRM – »edit« – startet diesen Editor und lädt die existierende Clusterkonfiguration.
Primitive-Monitoring
Das Monitor-Feature bezieht sich jeweils auf einfache Ressourcen, in Pacemaker-Sprech Primitives genannt. Im Falle einer vorhandenen Konfiguration finden sich in der CRM-Konfiguration vermutlich mehrere Ressourcen dieses Typs. Sie unterstützen jeweils zwei Arten von Konfigurationseinstellungen: Parameter, die über den Resource Agent unmittelbar auf die Eigenschaften des jeweiligen Programms Einfluss nehmen, und Operationen. Erstere werden in der Konfiguration einer »primitive« -Ressource mit dem Schlüsselwort »params« eingeleitet.
Zusätzlich gibt es das Keyword »op« , das die so genannten Operations einleitet. Über diese legt der Administrator fest, wie Pacemaker mit bestimmten Ressourcen umgehen soll. Drei Operationen gehören zum Standardrepertoire: Über »start« und »stop« stellt der Clusteradmin Toleranzwerte für die Timeouts beim Starten und beim Stoppen ein. Die dritte ist die »monitor« -Operation (Abbildung 2). Sie bringt Pacemaker dazu, den Resource Agent für diese Ressource regelmäßig mit dem »monitor« -Befehl aufzurufen und aus den Resultaten Rückschlüsse zu ziehen.
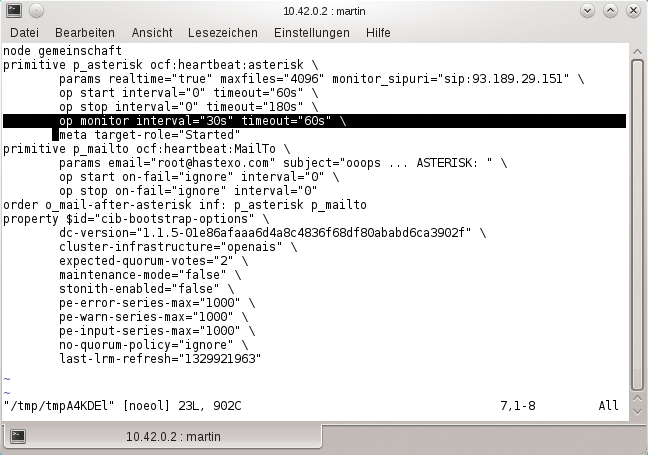
Um das Monitoring für eine »primitive« -Ressource zu aktivieren, ist die folgende Zeile in deren Konfiguration notwendig:
op monitor interval="60s" timeout="30s"
Diese Operation veranlasst Pacemaker jede Minute zu testen, ob der Dienst noch läuft. Bekommt der Clustermanager nach 30 Sekunden keinen Rückgabewert vom aufgerufenen Programm, gilt die Operation als gescheitert und Pacemaker initiiert einen Neustart der Ressource. Das Gleiche tut er, sollte der Test einer Ressource ergeben, dass diese nicht läuft. Außerdem setzt der Schrittmacher in diesem Falle den »failcount« der Ressource um 1 hoch, loggt also mit, dass die Ressource abgestürzt ist.
Sonderfall DRBD
Häufig kombinieren Admins Pacemaker mit DRBD. Die Lösung für replizierten Storage nimmt in Pacemaker eine Sonderrolle ein: Sie nutzt die Master-Slave-Ressourcen, sodass sie auf beiden Knoten eines Clusters DRBD verwalten kann, egal ob sich eine DRBD-Ressource gerade im »Primary« – oder »Secondary« -Modus befindet.
Das Master-Slave-Setup findet sich in der Pacemaker-Konfiguration in Gestalt einer »ms« -Regel, die eine Referenz auf die eigentliche DRBD-»primitive« -Ressource hält. Um zu funktionierenden Monitoring-Operationen zu gelangen, gilt es, einen Sonderfall zu beachten: Die »monitor« -Operation für eine »primitive« -Ressource, auf die eine »ms« -Regel verweist, sieht folgendermaßen aus:
op monitor interval="30s" role="Slave" op monitor interval="25s" role="Master"
Für die Rollen »Master« und »Slave« sind also jeweils eigene Operationen für »monitor« notwendig. Sinnvoll ist es, die »Master« -Rolle etwas häufiger zu prüfen als die »Slave« -Rolle. Keinesfalls dürfen die beiden Intervalle identisch sein, denn dann würde die »monitor« -Operation nicht funktionieren.
Thresholds
Pacemaker kennt ein Konzept namens Migration Threshold. Gemeint ist der Vorgang, eine Ressource auf einem Clusterknoten nach einem Absturz nicht mehr zu starten, wenn ihr dort bereits eine bestimmte Anzahl von Abstürzen nachgewiesen ist. In einem solchen Falle würde der Clustermanager dann sein Glück auf einem anderen Clusterknoten versuchen.
Das Feature ist praktisch für verschiedene Dienste, zum Beispiel Datenbanken: Stürzt MySQL auf einem Server mehrere Male ab, weil der RAM der Maschine kaputt ist, bringt es nichts, die Datenbank dort wieder und wieder zu starten. Über den »migration-threshold« -Parameter lässt sich der Vorgang abkürzen. Doch bevor der Threshold-Parameter selbst ins Spiel kommt, ist auf der CRM-Shell in dem »configure« -Abschnitt noch der Block mit »property« um die folgende Zeile zu erweitern:
cluster-recheck-interval="5m"
Dies sorgt dafür, dass der Clustermanager nicht nur bei irgendwelchen Ereignissen eingreift, sondern dass er regelmäßig alle 5 Minuten den Zustand des gesamten Clusters überprüft – Monitor-Anweisungen ausgenommen, die ihre eigenen Intervalle haben.
Um für eine Ressource dann den Threshold zu aktivieren, braucht die Ressource noch den folgenden Eintrag:
meta migration-threshold=2 failure-timeout=60s
In diesem Falle würde Pacemaker den Dienst nach zwei Abstürzen auf einen anderen Clusterknoten verschieben und es nach 60 Sekunden dem Dienst wieder erlauben, auf dem ursprünglichen Clusterknoten zu laufen. Statt »60s« ist hier auch die Angabe von Minuten möglich. »1440m« würde dafür sorgen, dass die Ressource einen ganzen Tag nicht auf dem kaputten Knoten laufen darf, es sei denn, der Admin greift händisch ein.
Licence to kill
Die meisten Resource Agents überprüfen beim Aufruf mit »monitor« nur oberflächlich, ob ein Programm läuft. Meist schauen sie nach, ob ein entsprechender Prozess in der Prozesstabelle zu finden ist und ob dieser auf »kill -0« noch reagiert. Nicht selten erfüllen Applikationen zwar diese beiden Bedingungen, funktionieren aber trotzdem nicht mehr richtig.
Beispiele sind virtuelle Maschinen, deren »kvm« -Prozess zwar noch läuft, die aber auf »ping« nicht mehr antworten, sowie Asterisk, das nicht mehr reagiert, obwohl der Prozess noch läuft. Die Autoren von Resource Agents müssen sich um diese Probleme selbst kümmern. Für die beiden angegebenen Beispiele ist das passiert: Sowohl »ocf:heartbeat:VirtualDomain« als auch »ocf:heartbeat:asterisk« bieten erweiterte Testmechanismen, um Fehlurteilen vorzubeugen.
Monitor-Skripte
Der Virtual-Domain-Agent erledigt das über den Parameter »monitor_scripts« in der CRM-Konfiguration. Hier gibt der Admin eine Liste von Skripten an, die Pacemaker während der »monitor« -Operation aufruft, jeweils getrennt durch ein Komma. Falls der Clusteradmin hier externe Skripte angibt, bezieht der Resource Agent deren Rückgabewerte in das Ergebnis von »monitor« ein.
Zusatzskripte (Abbildung 3) können beliebige Funktionen testen. Empfehlenswert ist etwa ein Skript, das »ping« mit der IP der virtuellen Maschine aufruft und 0 zurückliefert, falls diese auf Pings antwortet, oder 1, falls nicht.
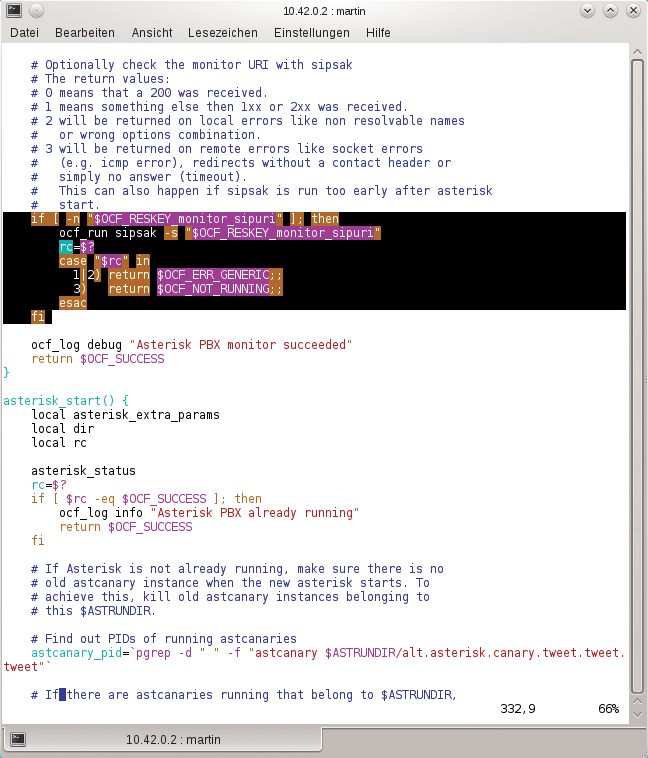
Abbildung 3: Soll der Resource Agent mehr können, als das Vorhandensein eines Prozesses zu testen, müssen RA-Autoren dies in die Skripte einbauen.
Der spezialisierte Asterisk-Agent »ocf:heartbeat:asterisk« kennt eine sehr ähnliche Funktion. Ist auf dem Zielsystem das Programm »sipsak« installiert und definiert der Admin in der CRM-Konfiguration den Parameter
monitor_sipuri="sip:IP."
dann schickt der Agent bei jedem Monitoring-Aufruf einen SIP-Request an den Asterisk-Server. Kommt auf den Request eine brauchbare Antwort, gilt die Operation als erfolgreich abgeschlossen. Andernfalls markiert Pacemaker den Vorgang als »failed« und spielt das übliche Programm ab.
Übrigens: Hat der Admin nach dem Fehlschlagen einer Monitor-Operation die Ursache für das Problem beseitigt, hilft der Befehl »crm resource cleanup Name_der_Ressource« auf der Bash, um den »Failcount« der Ressource auf 0 zurückzusetzen. Das stellt die Ausgangssituation wieder her (Abbildung 4).
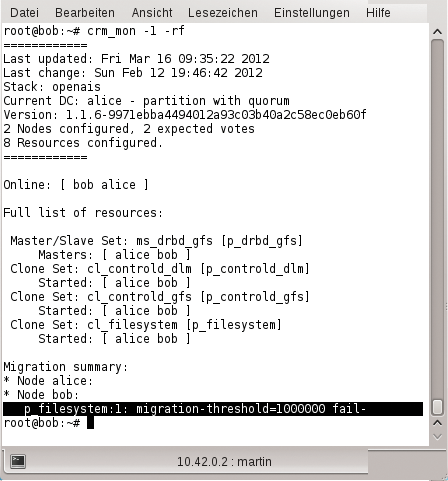
Agenten erweitern
Wenn ein Resource Agent in der eigenen Clusterkonfiguration ab Werk nicht mit aufgebohrten Monitor-Features ausgestattet ist, dann ist das auch kein Beinbruch. In der Regel lassen sich die Agenten nämlich sehr leicht um solche Features erweitern. LSB-Agenten liegen üblicherweise im Verzeichnis »/etd/init.d« , Heartbeat-Agenten in »/etc/ha.d/resources.d« und OCF-Agenten finden sich in »/usr/lib/ocf/resource.d« .
Um einen Agent zu erweitern, ist nur die richtige Datei zu finden und anzupassen; Shellprogrammierung dürfte für die meisten Admins kein unüberwindbares Hindernis sein. Sie müssen nur die Funktion finden, die der Agent beim Aufruf mit »monitor« bemüht – dort ist der richtige Platz für den zusätzlichen Code.
Lesen bildet
Wer sich detailliert mit dem Bearbeiten von Resource Agents befassen will, sollte sich zwei Dokumente zu Gemüte führen: Einerseits die Anleitung für die Entwickler von OCF-Agents [1] und andererseits einen Artikel im Admin-Magazin, der das Erstellen eines OCF-Agenten von Anfang bis Ende beschreibt [2].
Infos
- OCF Resource Agents Developer’s Guide: http://www.linux-ha.org/doc/dev-guides/ra-dev-guide.html
- Martin Gerhard Loschwitz, “Agentenausbildung”: Admin-Magazin 01/2012, http://www.admin-magazin.de/Das-Heft/2012/01/HA-Serie-Teil-8-OCF-Agenten-selbst-programmieren





