
© JL, 123RF.com
Dank leistungsfähiger Hardware arbeiten moderne Hauptspeicher-Datenbanken, ohne auf Massenspeicher zugreifen zu müssen. Damit erledigen sie sowohl Transaktionen als auch Auswertungen mit hoher Geschwindigkeit und verändern nebenbei den Datenbank-Markt.
Hauptspeicher-Datenbanksysteme(In-Memory-DBMS) gibt es schon länger, zum Beispiel Times Ten von Oracle [1] und Solid DB von IBM [2]. Darunter versteht man Datenbanksysteme, die den gesamten Datenbestand im Hauptspeicher halten, also keine Seiten zwischen Hauptspeicher-Puffer und Plattenspeicher hin und her tauschen, wie dies bei herkömmlichen relationalen Datenbanksystemen der Fall ist. Die bisherigen Hauptspeicher-Datenbanksysteme waren allerdings eher Nischenprodukte für spezielle Anwendungen.
Speicher satt
Dies hat sich durch den Fortschritt im Hardwarebereich geändert: Heute gibt es Server mit mehr als 1 Terabyte RAM und vielen Rechenkernen, außerdem sind neue Algorithmen und Datenstrukturen für Hauptspeicher-effiziente Datenverarbeitung im Einsatz: Cache-effiziente Datensatzstrukturen wie PAX oder Column-Stores, Kompression und Cache-effiziente Indexstrukturen.
Die Bedeutung der Hauptspeicher-DBMS wird sicher noch steigen, wie die folgende Überlegung nahelegt: Unternehmen können heute relativ kostengünstige Server mit einer Hauptspeicher-Kapazität über 1 TByte für etwa 50000 Euro erwerben. Solche Server besitzen Mehrkernprozessoren, sodass sie viele Threads parallel ausführen können. Die Kapazität reicht aus, um die transaktionalen Daten selbst großer Unternehmen zu speichern – hierbei geht es nicht um Multimedia-Daten, sondern um die Daten für geschäftskritische Buchungsvorgänge.
Als Beispiel betrachte man die Bestelldaten eines Handelsunternehmens wie Amazon. Im Jahr 2011 hat Amazon einen Umsatz von etwa 40 Milliarden Euro erwirtschaftet [3]. Bei einem durchschnittlichen Produktpreis von etwa 20 Euro speichert der Händler also 2 Milliarden Bestellpositionen, von denen sich jede typischerweise in weniger als 100 Byte repräsentieren lässt. Also ergibt sich ein Speichervolumen von etwa 200 GByte – was problemlose in 1 TByte Arbeitsspeicher passt. Hierbei sind andere Relationen (Kunden, Produkte et cetera) vernachlässigt, aber auch die Komprimierungsmöglichkeiten. Alternativ ließe sich für große Unternehmen eine verteilte, partitionierte Datenbank innerhalb eines Clusters konfigurieren.
Thema für Start-ups
Die technologischen Verbesserungen der Server haben viele Start-up-Unternehmen im Bereich der Hauptspeicher-DBMS auf den Plan gerufen: Volt DB, Clustrix, Akiban, DB Shards, Nimbus DB, Scale DB, Lightwolf und Electron DB, um die bekannteren zu nennen.
Oft verwenden diese Neuentwicklungen Open-Source-Datenbanksysteme wie MySQL oder PostgreSQL als Grundlage für ihre Hauptspeicher-Optimierungen. Neben den kommerziellen Enterprise-Editionen bieten die Hersteller meist auch eine freie Version an, die aber geringere Funktionalität aufweist. Volt DB [4] etwa ist in einer GPLv3-lizenzierten Community-Version erhältlich. Auch die großen Unternehmen wie SAP (New DB/Hana, [5]) und IBM (Isao/Blink, [6]) investieren in dieser Richtung.
Die bisherigen Hauptspeicher-Datenbanksysteme waren jeweils für ein bestimmtes Benutzungsparadigma konzipiert: entweder für das Online Transaction Processing (OLTP), die effiziente Transaktionsverarbeitung, oder für das Online Analytical Processing (OLAP), die effiziente Anfrageauswertung. Es gibt aber überzeugende Argumente, wie vom SAP-Gründer Hasso Plattner erläutert [7], dass diese Zweiteilung der Daten keine hinreichende Unterstützung für die so genannte Echtzeit-Entscheidungsunterstützung (Real Time Business Intelligence) bietet.
Paradigmen sprengen
Die derzeit übliche Datenbank-Architektur sieht vor, dass transaktionale Daten primär in einem OLTP-Datenbanksystem verwaltet werden, in dem sie auf dem neuesten Stand vorliegen. Ein Extract-Transform-Load-Prozess (ETL) lädt sie aus diesem in ein OLAP-System (Data Warehouse). Dies kann aber aus Belastungsgründen nur periodisch erfolgen, beispielsweise jede Nacht. In den bisherigen Systemen war es aus Leistungsgesichtspunkten nicht möglich, OLAP-Anfragen direkt auf den Daten des OLTP-Systems auszuführen.
Dies ändert sich durch die aufkommenden Hauptspeicher-DBMS. Solche Systeme werden als hybride OLTP&OLAP-Datenbanken bezeichnet. Sie vereinigen die besten Eigenschaften beider Welten, wie dies Abbildung 1 skizziert. Sie sollten im Transaktionsdurchsatz so gut sein wie dedizierte OLTP-Datenbanken (etwa Volt DB) und in der Anfragebearbeitung mit dedizierten OLAP-Engines wie etwa den Column-Stores Monet DB [8], Vertica, Vector Wise oder dem IBM-System Isao/Blink mithalten.
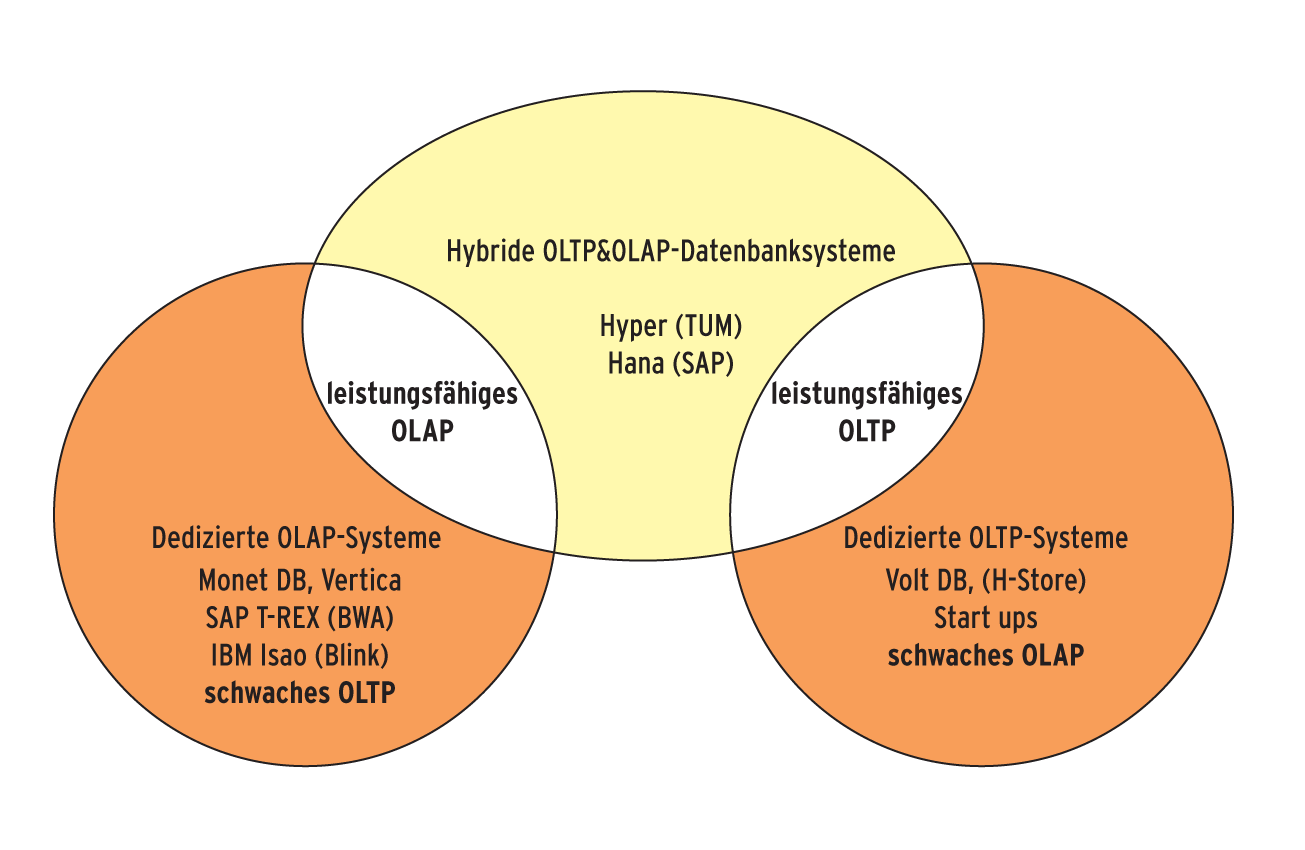
Abbildung 1: Hauptspeicher-Datenbanken im Überblick: Sie sind meist für OLAP (links) oder OLTP (rechts) optimiert. Nur wenige bieten das Beste aus beiden Welten (Mitte).
Das von SAP entwickelte Hana sowie das an der Technischen Universität München realisierte Hyper [9] sind die wohl bekanntesten Vertreter dieser hybriden Systeme, die für die so genannte Operational Business Intelligence entwickelt wurden. Hyper ist ein modernes Hauptspeicher-Datenbanksystem, das die Hardware-unterstützte virtuelle Speicherverwaltung des Betriebssystems für die Datenverwaltung und die Synchronisation zwischen OLTP-Transaktionen und OLAP-Anfragen ausnutzt.
Die Datenverwaltung “in-core” bildet die relationalen Daten direkt, also ohne Indirektion durch eine DBMS-kontrollierte Puffer- und Seitenverwaltung, auf den virtuellen Adressraum des OLTP-Prozesses ab. Dieser kann Transaktions-konsistente Snapshots der Datenbank anlegen, indem er einen neuen OLAP-Prozess abspaltet, unter Linux mit dem Systemaufruf »fork()« .
Der Copy-on-Write-Mechanismus des Gespanns von Betriebssystem und Prozessor sorgt für die Konsistenzerhaltung dieses Snapshots, indem er Seiten mit sich ändernden Datenobjekten repliziert. Dieses Snapshot-Verfahren entspricht dem Schattenspeicher-Konzept, das Lorie 1977 bei IBM erfunden hat – mit dem Unterschied, dass die virtuellen Speicher-Snapshots keinen der damaligen Nachteile haben: Die Speicherfragmentierung ist im Hauptspeicher kein Problem und die ursprünglich aufwändige Verwaltung der Schattenkopien ist im Hyper-Ansatz durch die eingebaute Prozessorunterstützung hocheffizient.
Daneben erlaubt die virtuelle Speicherverwaltung beliebig viele (zeitlich versetzte) Schattenkopien zu unterhalten. Das macht es möglich, mit Hyper ein Datenbanksystem zu realisieren, das die Vorteile der OLTP- und der OLAP-Datenbanken vereint: Im Transaktionsdurchsatz erzielt Hyper Werte vergleichbar oder besser als die dedizierten OLTP-Systeme (etwa Volt DB) und in der OLAP-Anfragebearbeitung ist Hyper vergleichbar mit dedizierten Column-Stores wie Monet DB oder Vector Wise [10]. (mhu)
Infos
- Times Ten: http://www.oracle.com/timesten/
- Solid DB: http://www-01.ibm.com/software/data/soliddb/
- Amazon.com, Annual Report 2011: http://phx.corporate-ir.net/phoenix.zhtml?c=97664&p=irol-reportsannual
- Volt DB: http://voltdb.com
- SAP Hana: http://www.sap.com/germany/plattform/in-memory-computing/index.epx
- Blink: http://www.almaden.ibm.com/cs/projects/blink/
- Hasso Plattner, Alexander Zeier, “In-Memory Data Management: An Inflection Point for Enterprise Applications”: Springer, Berlin 2011
- Monet DB: http://www.monetdb.org
- Hyper: http://www3.in.tum.de/research/projects/HyPer/
- Alfons Kemper, Thomas Neumann, “HyPer – Hybrid OLTP&OLAP High Performance Database System”: Technical Report, TUM-I1010, 2010; http://www3.in.tum.de/research/projects/HyPer/HyperTechReport.pdf





