
© ktsdesign, 123RF.com
Programmierbare Logikbausteine haben das Entwerfen digitaler Schaltungen dramatisch vereinfacht. Noch ohne Lötkolben können Profis und Hobbybastler ihr Werk gemeinsam mit der darauf laufenden Software testen. Hardwarebeschreibungs-Sprachen, freie Tools und Erweiterungen machen die Simulation möglich.
Elektronikbastler früherer Jahre, die nächtens die Chips der 7400er-TTL-Reihe verlöteten, bis der elektronische Würfel endlich lief, erinnern sich an die kleine Revolution, die mit dem Aufkommen zur programmierbaren Logik Einzug hielt: Ein GAL- (Generic Array Logic) oder PAL-Chip (Programmable Array Logic) sparte jede Menge Chips und deren elektrische Verbindungen untereinander ein.
Fast wichtiger noch war, dass beim Prototyping kleine Schaltungsänderungen kein Redesign der Leiterplatte mehr erforderlich machten – es reichte, den Chip umzuprogrammieren. Das Erstellen der Arrays passierte mit PC-Tools, oder der Elektroniker benutzte eine Sprache, mit der er die Logik bis zum Erschöpfen der Chip-Ressourcen frei programmierte.
Heute lächeln Entwickler darüber, weil sie mit CPLDs (Complex Programmable Logic Devices) oder FPGAs (Field Programmable Gate Array, siehe Kasten “Programmable Logic Devices (PLDs)”) arbeiten, die das Entwerfen komplexer digitaler Hardware per Beschreibungssprache, der Hardware Description Language (HDL), ermöglichen. Zwei Sprachen dominieren: Verilog [1] und VHDL ([2], Very High Speed Integrated Circuit Hardware Description Language), wobei in Europa letztere den Vorzug genießt.
Des Herausragende an diesen Sprachen ist aber, dass sie fürs Simulieren konzipiert sind. Wer schon mit dem Qemu-Emulator eine andere Prozessorarchitektur wie ARM emuliert hat, kennt das Prinzip: Qemu bildet eine CPU auf dem Heimrechner inklusive Bildschirm und Datenspeicher nach. Das Gleiche tun VHDL und Verilog generisch: Die in der HDL beschriebene Hardware simuliert das entsprechende Tool takt- und zeitgenau virtuell und hilft die Funktion mit nachgeahmten externen Stimuli (die Testbench) auf ihre Funktion zu prüfen.
Programmable Logic Devices (PLDs)
Ein Complex Programmable Logic Device (CPLD) besteht aus Blöcken, die ein PLA, Ein- und Ausgangsblöcke sowie eine programmierbare Rückkopplung enthalten. Der Programmierer des Bausteins kann die Blöcke untereinander verbinden (Flashzellen). In der Regel sitzt hinter jedem I/O-Pin ein Flipflop.
Ein Field Programmable Gate Array (FPGA, Abbildung 1) besteht ähnlich wie ein CPLD aus untereinander vernetzten Blöcken, die komplexer als bei CPLDs ausfallen (Flipflops und Lookup-Tabellen). Die Blöcke untereinander sind gegenüber dem CPLD feinmaschiger und mit SRAM-Technik verschaltet. Viele FPGAs stellen für den Programmierer zudem fertige Funktionsblöcke wie RAM, PLLs oder CPU-Kerne bereit.

Abbildung 1: Ein FPGA-Chip der Firma Altera (Quelle: Wikipedia).
Ein- und Ausgabe simulieren
Ein elektronisches Element kann man zunächst von außen schematisch als Block mit Ein- und Ausgängen betrachten, wie es das Beispiel einer kleinen CPU in Abbildung 2 skizziert. Ein beinahe überall existierender Eingang ist der Clock-Pin, also der Takt-Eingang. Das typische synchrone Design arbeitet generell mit einem Masterclock. Ein asynchrones Design hingegen evaluiert beliebige Eingänge wie auch momentane interne Zustände und erzeugt davon abhängige Ausgangssignale. Synchrone Designs sind weniger fehleranfällig und besser zu handhaben. Für eine einfache Simulation bedarf es
- einer Beschreibung des synchronen Masterclock-Signals »clk« und
- einer dazu möglicherweise synchrone Signalfolge oder auch Wellenform (des Stimulus).
Die einfache Simulation liefert als Resultat logischerweise wiederum eine Wellenform. Was dem Elektroniker sein Oszilloskop oder Logikanalyzer, ist für den mit der Simulation beauftragten HDL-Programmierer schlichtweg die Software, die aus der Simulation generierten Wellenform Daten visualisiert. Die extern eingespeisten Signale, wie Clock, sind für die Simulation Teil der Testbench.
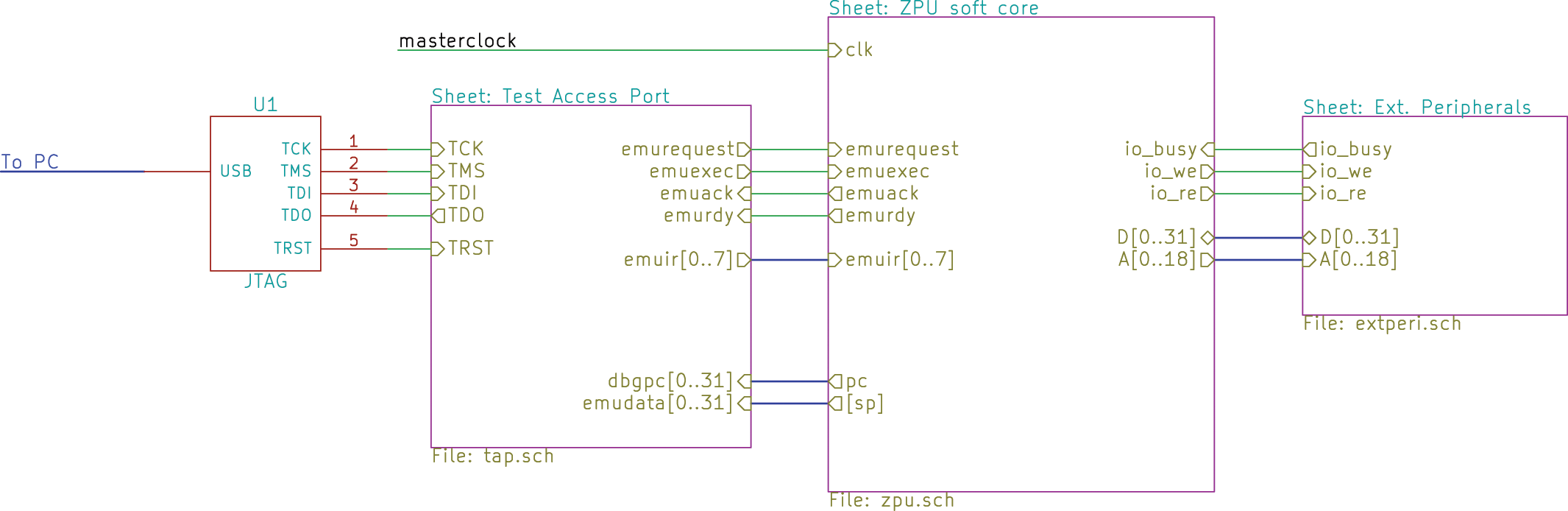
Abbildung 2: Das Blockschema einer einfachen CPU, die es zu simulieren gilt.
Einfach zusammenstöpseln
Die TTL-Digitalbausteine mit ihren Gattern früherer Epochen finden heute in einzelnen oder zu einer Entity gruppierten funktionalen HDL-Beschreibungen ihre Entsprechung. Komplexere Bauteile, oft als Cores bezeichnet, sind auf verschiedenen Webseiten wie Opencores.org frei verfügbar. Der Computerbastler, der einfach mal gerne mehr über die Materie lernen möchte, kann sich also die einzelnen Bausteine herunterladen, sie virtuell mit Hilfe der HDL zusammenstöpseln und die Funktion der Hardware mit Hilfe der Simulation verstehen lernen.
Sobald die funktioniert und auch das Vertrauen in die simulierte Umgebung vorherrscht, wächst die Begehrlichkeit das Design auch auf Hardware mit echten Signalen laufen zu lassen – sei es als einfache PWM-Steuerung für die Regenbogen-Sauna-Beleuchtung oder als eigenen Crypto-Beschleuniger. Dazu fehlen noch die eigentlichen Simulations- und Synthesewerkzeuge. Für den Linux-User existiert seit Jahren eine ordentliche Auswahl an kostenlosen oder freien Tools in beiden Sprachenwelten. Tabelle 1 zeigt die für Einsteiger und Kostenbewusste relevanten Softwarepakete.
Tabelle 1
Linux-Simulationswerkzeuge
|
Name |
HDL-Sprachensupport |
Lizenz |
Internet |
|---|---|---|---|
|
GHDL |
VHDL |
GPL |
|
|
Freehdl |
VHDL |
GPL |
|
|
Icarus |
Verilog |
Open Source |
|
|
Mentor Graphics Modelsim |
VHDL, Verilog |
proprietär |
|
|
Xilinx Isim (Webpack) |
VHDL, Verilog |
proprietär |
Mit GHDL und GTK Wave
GHDL als VHDL-Simulator und GTK Wave [3] als Wellenform-Display sind in den meisten Linux-Distributionen vorhanden. Unter allen Debian-basierten Linuxen geht die Installation entsprechend schnell von Statten: »apt-get install ghdl gtkwave« .
Das Arbeitsprinzip der Simulation: Die Digitalbausteine in Form von HDL-Modulen importiert der Benutzer ähnlich wie Programmierer eine C-Bibliothek per Kommandozeilen-Direktive in eine Arbeitsdatei, die dann der GCC-Kompilierlauf der Simulation schlichtweg in Objektdateien übersetzt und in ein ausführbares Binärfile linkt. Rein gehen VHDL-Sourcen, raus kommt ein Programm – die Simulation.
Per Kommandozeile ausgeführt, arbeitet diese die in der Testbench vorgeschriebenen Stimuli ab und bildet entsprechend dieser virtuellen Ein- und Ausgaben die virtuelle Hardware in ihrer Funktion nach. Sie endet – je nach Programmierung der Testbench – entweder von selbst oder nach der per »–stop-time« -Option spezifizierten Simulationsdauer; gemeint ist die simulierte Zeit, nicht die Echtzeit.
Virtueller LED-Blinker
Was des typischen Programmierers “Hello World”, ist dem HDL-Hacker sein “Blinky”, ein einfacher LED-Blinker. Das folgende Beispiel soll also schlicht einen Pin an- und ausschalten. Das ist eigentlich sehr unspannend, da der Masterclock die An-Aus-Funktion ja schon vorher bereitstellt. Deswegen soll etwas Würze in Form zweier Enable-Eingänge und eines Zählers hinzukommen.
Bedingung ist, dass der Zähler nur dann arbeiten soll, wenn »en0« und »en1« High, also 1 sind. Sobald der Zähler einen gewissen Stand erreicht, soll die Simulation über das Sigterm-Signal enden. Die HDL-Datei »blink.vhdl« in Listing 1 gibt dieses Design wieder (alle Listings und erwähnten Dateien gibt es vollständig unter [4]). Es besteht aus drei Prozessen (»process« ):
- »masterclock« , dem virtuellen Clock-Stimulus,
- »uut« , Unit Under Test, einer kleinen synchronen Zählereinheit und
- »stimulus« , der Simulation der externen Enable-Pins »en0« und »en1« .
VHDL-Programmierer wissen, dass jeder »process« ähnlich wie ein Unix-Prozess logisch parallel zu anderen abläuft. Was wie Argumente einer Funktion aussieht, ist die für die Simulation bedeutsame Sensitivity-List: Der Prozess wird abgearbeitet, wenn sich ein Signal in der Sensitivity-Liste ändert. Hat der Prozess gar keine Liste, betrachtet man ihn als Generator eines Signals (Stimulus). Die Zeilen 13 bis 26 von Listing 1 zeigen eine typische Masterclock-Erzeugung, den wichtigsten Stimulus.
Dieser Prozess invertiert jede Mikrosekunde das »clk« -Signal, welches mit einem definierten Wert initialisiert sein muss. Daraus resultiert ein An-Aus-Signal mit der Frequenz von 500 kHz. Die Wait-Anweisung ist das Analogon zum »usleep()« -Aufruf in Linux, aber auf die simulierte(!) Zeit bezogen, es wird keine echte Zeit gewartet. Länger wartende wait-Statements verlangsamen darum die Simulation auf dem Rechner nicht.
Der »uut« -Process ab Zeile 28 bildet den Kern der Logik des simplen Beispiels. Bei jeder steigenden Flanke inkrementiert er den Zähler, sofern die beiden Enable-Eingänge High sind. Als Drittes steht der Stimulus an, der parallel zum Clock und der Simulation der »uut« die Enable-Eingänge manipuliert. Auch dieser Prozess ab Zeile 41 ist einigermaßen selbsterklärend.
Neben einiger Library-Anweisungen im Kopf von Listing 1 findet sich auch die Deklaration der »entity« namens »blinky« . Sie steht für den beschriebenen Baustein mit seinen Ein- und Ausgängen, letztere fasst eine »port« -Deklarationsanweisung zusammen. Eine Top-Level-Entity einer Simulation braucht gewöhnlich keine Ein- und Ausgänge, hat hier also keinen »port« -Deklarationsblock. Die »architecture« -Anweisung kapselt per »behaviour« die eigentliche Beschreibung des Verhaltens.
Listing 1
blink.vhdl (Auszug)
01 library ieee; 02 use ieee.std_logic_1164.all; 03 use ieee.numeric_std.all; -- Unsigned 04 05 entity blinky is end blinky; 06 architecture behaviour of blinky is 07 signal clk : std_logic := '0'; 08 signal en0, en1 : std_logic := '0'; 09 signal sigterm : std_logic := '0'; 10 signal counter : unsigned(7 downto 0) := x"00"; 11 begin 12 13 masterclock: 14 process 15 begin 16 wait for 5 us; 17 clkloop : loop 18 wait for 1 us; 19 clk <= not clk; 20 if sigterm = '1' then 21 exit; 22 end if; 23 end loop clkloop; 24 wait for 5 us; 25 wait; 26 end process; 27 28 uut: 29 process (clk) 30 begin 31 if rising_edge(clk) then 32 if counter = 15 then 33 sigterm <= '1'; 34 end if; 35 if en0 = '1' and en1 = '1' then 36 counter <= counter + 1; 37 end if; 38 end if; 39 end process; 40 41 stimulus: 42 process 43 begin 44 wait for 6 us; 45 en0 <= '1'; 46 wait for 7 us; 47 en0 <= '0'; 48 en1 <= '1'; 49 wait for 7 us; 50 en0 <= '1'; 51 wait; 52 end process; 53 end behaviour;
Die Blink-Simuation
Nun ist GHDL mit der Simulation dran. Das Makefile aus [4] erledigt das Bauen der Simulation automatisch, aber zum Verständnis seien hier die einzelnen Kommandos aufgeführt: Zunächst importiert
ghdl -i blink.vhdl
die VHDL-Datei in die Arbeitsumgebung und erzeugt die Standard-Arbeitsdatei »work-obj93.cf« . Der Befehl
ghdl -m blinky
baut die Top-Level-Entity »blinky« fertig. Als Resultat ist ein ausführbares Programm mit Namen der Top-Level-Entity, also »blinky« , entstanden. Das Kommando
./blinky --wave=test.ghw
lässt die Simulation rennen und erzeugt gleich eine Wellenform per »–wave« . Die Simulation sollte sich nach einem Sekundenbruchteil beenden. Die resultierende »test.ghw« lässt sich nun mit GTK Wave untersuchen:
gtkwave test.ghw view.sav
Die Datei »view.sav« bereitet der Anwender vor diesem Schritt mit der Konfiguration der Wellenformanzeige vor. Existiert sie nicht, zeigt GTK Wave nichts an und der Benutzer muss sich sein Wellenformen-Menü über die Auswahl im SST-Fenster (siehe Abbildung 3) zusammenklicken.
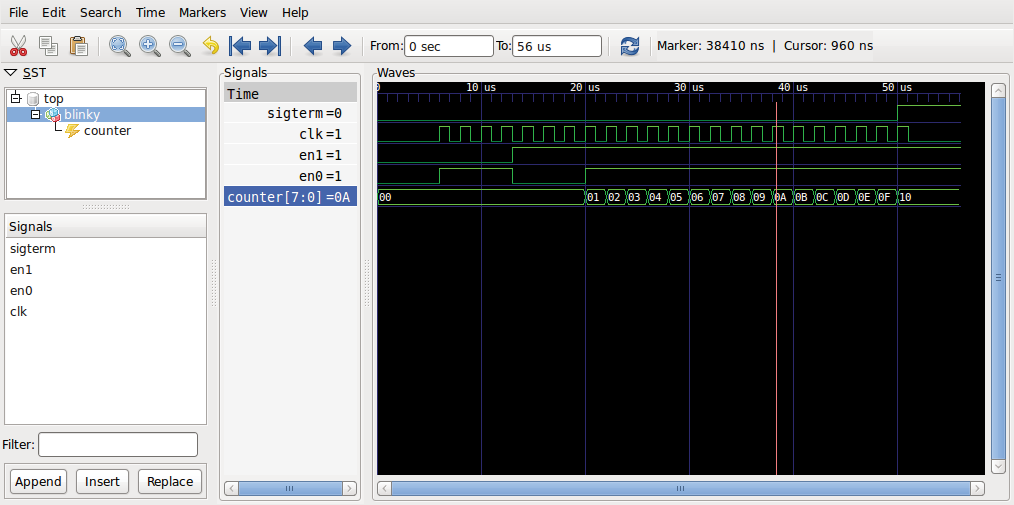
Abbildung 3: Die Wellenformanzeige der »blinky«-Simulation.
Tückische Flanken
Seltsam erscheint im ersten Moment, dass der Zähler bis 16 (hexadezimal 0x10) zählt, bevor die Simulation endet. Die Parallelität der Prozesse beinhaltet offenbar Tücken: Die Abfrage, ob der »counter« gleich 15 ist, passiert nämlich wegen der Sensitivität des »uut« -Process nicht unmittelbar nach dem Sprung des Counters auf 15, sondern erst bei der nächsten steigenden Flanke von »clk« ! Zur Demonstration zieht der folgende Code die Abfrage aus »uut« heraus und setzt sie in einen neuen »process« , der sensitiv auf Änderungen der »counter« -Variable reagiert:
process (counter) begin if counter = 15 then sigterm <= '1'; end if; end process;
Dieser Prozess gilt prinzipiell als asynchron, da sich nicht unbedingt voraussetzen lässt, dass sich »counter« synchron zum Clock ändert – dafür hatte das Beispiel ja die Eingänge »en0« und »en1« geschaffen. Aber er sorgt dafür, dass sofort beim Erreichen des Zählerwerts 15 die »sigterm« -Leitung auf High-Pegel geht.
Elektrische Hasardeure
Die Simulation scheint mit diesem Design zu funktionieren – leider tut sie das in der Praxis nicht, denn hier manifestiert sich die nächste Stolperfalle: Implementiert der Entwickler ein derart asynchrones Element in Hardware, bekommen elektrische Laufzeitunterschiede eine Bedeutung. Sobald die einzelnen Bit-Werte des Counter zu unterschiedlichen Zeiten am Komparator (»counter = 15« ) eintreffen, treten gerade bei Zählern tückische Artefakte auf: Kurzzeitig enthält der Zähler einen anderen Wert, wenn beispielsweise Bit 0 schon den neuen Wert, Bit 3 aber noch den alten hat.
Abbildung 4 demonstriert den Effekt dieser Verzögerung, welche die gegenüber »blink.vhdl« leicht modifizierte Datei »blink2.vhdl« über den »delayed_counter« simuliert: Beim Sprung von 13 (0x0d) nach 14 tritt, wie sich im Zoom sehen lässt, kurzzeitig der Wert 0x0f, also 15, auf. Der erzeugt über den asynchronen Prozess bereits die »sigterm=1« -Bedingung oder einen so genannten Glitch im Signal. Wenn ein »process« flankensensitiv auf »sigterm« reagiert, kann der Glitch ein ungewolltes Ereignis auslösen, ein Fehler, der schwer zu finden ist. Im vorliegenden Fall würde die »sigterm« -Bedingungen unter Umständen verfrüht ausgelöst. (Die Tatsache, daß der obige »process« weitsichtig »sigterm« auf 0 setzt, wenn der Zähler nicht gleich 15 ist, verhindert ein solches Verhalten.)
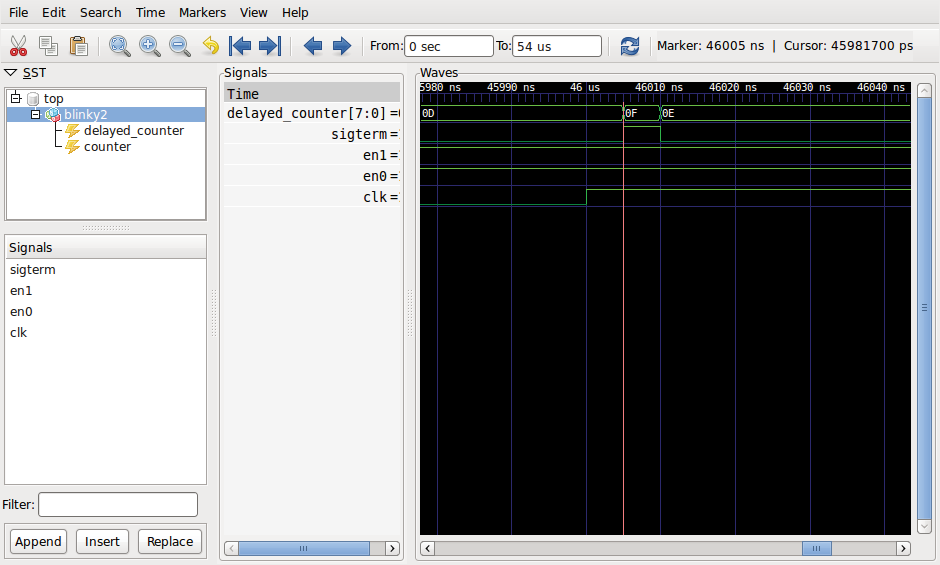
Abbildung 4: Laufzeitunterschiede, wie sie in der Praxis vorkommen, verursachen hier einen »sigterm«-Glitch.
Darum ist es ratsam, synchrone Designs zu verwenden und asynchron generierte Signale immer mit synchronen, also »clk« -sensitiven Prozessen abzufragen. Auch die von Herstellern programmierbarer Hardware angebotenen Synthese-Werkzeuge, die aus der HDL die ausführbaren Bitstreams für ihre Hardware generieren, geben zu dem Thema Warnungen aus.
Die letzte praktische Unzulänglichkeit der Beispiel-Simulation ist, dass das simulierte Lämpchen viel zu schnell flackert. Wer sich nach diesem Artikel besser auskennt, kann als Übung den schnellen Masterclock zu einem langsameren Blink-Takt herunterdividieren.
ZPU – eine Softcore-CPU
So simpel das Beispiel eben war, so komplex kann das folgende werden: Eine vollständig in VHDL definierte CPU. Der Zusatz “Softcore” mag als etwas unglückliches Attribut gelten, da Google zu dem Begriff einen ganzen Strauß unterschiedlichster Dinge ausspuckt. Hier ist damit gemeint, dass der Elektronikentwickler eine CPU aus programmierbaren Gattern in der Hardware bildet. Für die Simulation ist das Attribut sowieso gegenstandslos, da es nur um Software geht.
Beim Recherchieren auf Opencores.org tritt schnell die Frage auf, welche CPU die richtige Wahl ist. Die lässt sich nicht allgemein beantworten, aber mit einer wenig resourcenhungrigen Implementierung tut sich die Simulation natürlich leichter. Die Wahl für das zweite Beispiel fällt deswegen auf die ZPU [5] von Øyvind Harboe, genauer, der durch Salvador E. Tropea verbesserten Variante namens Zealot. Die enthält bereits eine Testbench, lässt sich also gleich nach dem Auspacken durchsimulieren. Der schnellste Weg zu einem Ergebnis ist, die fertige Makefile-Konfiguration aus der Sammlung der Simulationsdateien [4] zu benutzen und im Verzeichnis »zpu« das Kommando »make« auszuführen.
Steht die Internetverbindung und sind die gängigen Entwicklungstools zugegen, klont Make zunächst das ZPU-Git-Repository und baut anschließend die Simulation als Programm mit dem Namen »small1_tb« . Das Programm für die ZPU – der Bootloader – befindet sich binär kodiert in der Datei »hello_dbram.vhdl« . Die entsteht optional im Zuge von »make« aus einer Hello-World-C-Quelldatei aus dem Git-Repository unter Zuhilfenahme des ZPU-Elf-GCC-Crosscompilers und eines separaten Tools, das vom binären ELF-Format in die Initialisierungswerte des Block-RAM konvertiert. Der eben benötigte ZPU-Elf-GCC lässt sich separat installieren oder aus der GCC-Sourcedistribution selbst bauen.
Wer jetzt die Simulation »small1_tb« ausführt, startet das minimale ZPU-System und führt sogleich den ROM-Code aus. Das eingebaute Trace-Modul schreibt zeitgleich die ausgeführten Assembler-Kommandos in die Datei »small1_trace.log« . Spannend wird die Sache, wenn der Anwender mit der »–wave« -Option wiederum eine komplette Wellenform ausgibt und GTK Wave das Verhalten der einzelnen Signale inspiziert.
Mit der Technik, die eine kleine CPU in ein bestehendes Design integriert, lassen sich bereits komplexe, in Software beschriebene Abläufe durchsimulieren und Szenarien im Detail debuggen – zumindest, was logische Designfehler angeht. Ein Wermutstropfen bleibt: Der Programmablauf ist im ROM statisch kodiert, bei jeder Änderung des Programms muss der Entwickler die Simulation neu bauen und erneut starten, was keine Grundlage für eine effiziente interaktive Simulation ist.
Die Co-Simulation
Wie beschrieben, besitzt die typische Testbench zunächst einen statischen Charakter: Der Entwickler denkt sich einige Testszenarien aus, denen die konstruierte Hardware genügen muss, und schreibt sie in die Hardwarebeschreibung der Testbench. Eine gute Testbench verifiziert die korrekte Reaktion auf die abgewickelten Szenarien selbst und gibt ein »OK« oder eine Fehlermeldung aus.
Meistens bedenkt der Entwickler jedoch seltene Szenarien nicht, beispielsweise “Ein genervter User hämmert hochfrequent auf die [OK]-Taste des Ticketautomaten”. Da die meiste Hardware schlussendlich mit Software kooperiert und spätestens bei der Inbetriebnahme der Hardware mit dem entsprechenden Treiber die interessanten Fehler auftreten, stellt sich die Frage, ob die Software nicht gleich mit der Simulation sprechen kann.
Dazu ist im VHDL-Standard (wie auch in Verilog) eine Erweiterung vorgesehen: Unter der Abkürzung VHPI finden sich dort Spezifikationen und Verweise auf einige kommerzielle Werkzeuge, die für den Hobbyanwender finanziell außerhalb des Vernünftigen liegen. Glückliches Open-Source-Land: GHDL besitzt eine solche auch – wenn auch spärlich dokumentiert. Freie-Software-Benutzer sind solchen Kummer gewohnt und schauen in die Source. GHDL widersetzt sich diesem Ansinnen etwas, weil es nicht in C geschrieben, sondern in Ada 95, aus der sich VHDL übrigens ableitet. Aber keine Angst: Wer bisher fremden C-Code verstanden hat, wird auch dem Konzept dieser Sprache in vernünftiger Zeit auf die Schliche kommen.
Solche Hacktivitäten sind aber gar nicht erforderlich: Der Entwickler kann nämlich aus VHDL über eine C-aufrufkompatible API-Routinen aufrufen, damit also beispielsweise die obigen Signale aus dem »stimulus« -Prozess auch mit einem C-Modul generieren. Dazu muss er einen Funktionen-Stumpf (Stub) im Sinne eines Prototyps innerhalb VHDL deklarieren.
Externe C-Routinen in GHDL deklarieren
Die Deklaration eines VHPI-Stub (VHDL Procedural Interface) geht relativ einfach: Wie bei einem Library-Header definiert der VHDL-Programmierer ein »package« , das einen Satz von Funktionen oder Prozeduren enthält. Im Gegensatz zu Prozessen ähneln Funktionen in VHDL denen in C: Sie erwarten eine Anzahl von Argumenten und liefern einen Rückgabewert. Letzterer bildet zugleich den Unterschied zur Prozedur, die liefert keinen Wert zurück, außer über ein mit dem Stichwort »out« versehenes Argument (einen Pointer). Eine als »procedure« implementierte C-Funktion folgt deshalb typischerweise dem Stil »void cfunc(…)« .
Am Beispiel einer abstrakten Funktion lässt sich gut sehen, wie das Wrapping einer C-Funktion über einen Stub von Statten geht. Innerhalb des Package bedarf es zweier Deklarationen. Die erste stellt den Prototypen der Routine dar:
procedure regmap_read(addr : regaddr_t; data : out byte_t); attribute foreign of regmap_read : procedure is "VHPIDIRECT sim_regmap_read";
Diese Deklaration veranlasst GHDL einen Funktionenstumpf mit dem Symbol »sim_regmap_read« zu reservieren, den »regmap_read« mit geeigneten Parametern von VHDL aus aufruft. In C implementiert der Benutzer die passende Funktion
void sim_regmap_read(regaddr_t_ghdl address,byte_t_ghdl data)
Innerhalb des Package-Body folgt der eigentliche Stub:
procedure regmap_read(addr : regaddr_t; data : out byte_t) is begin assert false report "VHPI" severity failure; end procedure;
Der Stub ist eine leere Funktion, die eine Fehlerbedingung hervorrufen würde, falls die C-Schnittstelle fehlt. Das »assert« -Statement dürfte auch entfallen, aber der Standard schlägt es so vor. Da die Schreibarbeit beim Wrappen vieler Funktionen etwas aufwändig geraten kann, liegt es nahe, ein paar C-Preprozessor-Tricks zu implementieren, die C-Funktionen mit Hilfe eines Einzeilers semi-automatisch wrappen.
Ist noch die Frage zu klären, wie man Daten zwischen den verschiedenen Sprachen austauscht – die Welt der Hardware dreht sich um logische Pegel, Leitungen, Busse, Flags und so weiter, im C-Universum sind dagegen »long int« , Strings und Floats obligatorisch. Vollständig kompatibel zueinander bekommt man die Datentypen beider Welten zwar nicht, aber ausreichend konvertiert. Die obige Definition von »byte_t_ghdl« entpuppt sich nicht als »unsigned char« , sondern als »char *« – also als String.
Beim Blick auf die VHDL-Welt wird auch schnell klar warum: Ein Byte entspricht im Hardwareland acht Leitungen, die unter Umständen nicht nur Low- und High-Werte, sondern auch einen hochohmigen (Tristate), undefinierten oder ungültigen Zustand einnehmen können. Deshalb ist pro Ein-Bit-Signal (ein »std_logic« -Datentyp) jeweils ein »char« reserviert, ein Array aus 8 Bits manifestiert sich in einem »char[8]« . Die möglichen Werte für ein »std_logic« -Char zeigt Listing 2 (entnommen aus »ghdlex/ghpi.h« [6]).
Das Ganze ist weniger komplex als es den Anschein hat, denn es gibt Beispiel-Quellcode und die kleine Bibliothek Ghdlex [6] mit einem Satz fertiger Funktionen zum Datenaustausch zwischen VHDL und C-Routinen sowie die nötige Dokumentation via Doxygen. Darin sind auch die erwähnten Präprozessor-Tricks mit CPP abgehandelt. Die Inspiration zu dieser Erweiterung beruht stark auf der Arbeit von Yann Guidon, der für eine französische Linux-Zeitschrift zu dem Thema einige Beiträge [7] verfasst hat.
Listing 2
Wertebereich für std_logic
01 #define UNDEFINED 0 ///< Undefined; VHDL: 'U' 02 #define INVALID_X 1 ///< Invalid; VHDL: 'X' 03 #define LOW 2 ///< Low; VHDL: '0' 04 #define HIGH 3 ///< High; VHDL: '1' 05 #define TRISTATE 4 ///< High Z; VHDL: 'Z'
Der Datenaustausch über Linux-Pipes
Angenommen, ein Entwickler besitzt bereits ein komplettes Design, das im Wesentlichen aus einem simplen Prozessor besteht, der einfache Kommandos über eine serielle Schnittstelle entgegennimmt und Signalzustände oder Messwerte ausgibt. Nach der Prototypenphase entfällt die serielle Konsole natürlich zu Gunsten einer Software zum Fernsteuern. Bevor er überhaupt die Hardware entwirft, kann der Entwickler das Design mit der so genannten Co-Simulations-Methode schon verifizieren. Dazu muss er die Fernsteuer-Software in den Prozess einbinden.
Die einfachste Methode des Datenaustausch zwischen Unix-Prozessen sind bekanntlich Pipes. Eine Named Pipe ist mit »mkfifo /tmp/sim_fromuser« schnell angelegt. Mit »cat« oder der projektierten Steuersoftware lässt sich nun die Pipe vom Terminal aus live mit Kommandobytes füttern. Die VHDL-Seite braucht nur zeitgleich aus der Pipe zu lesen. Dazu implementiert »pipe.c« aus der Ghdlex-Library die Funktion »sim_pipe_in()« . Die Schnittstelle zu VHDL bildet ein »std_logic« -Vektor (ein »char *« auf der C-Seite) für die Daten und ein weiterer »std_logic« -Vektor für die Flags, die signalisieren, ob Daten verfügbar oder Fehler aufgetreten sind.
Der einfachste Test, ob eine Schnittstelle funktioniert, ist der einfache Loopback, wie im Simulationsbeispiel »simpipe.vhdl« implementiert. Dazu legt der Entwickler eine weitere Pipe namens »/tmp/sim_touser« wie oben an, baut das Simpipe-Beispiel mit »make« und führt es aus. Auf einer anderen Konsole horcht er an der Ausgabe-Pipe:
cat /tmp/sim_touser
Auf einer dritten Konsole schreibt er Daten in die Eingabe-Pipe:
cat >/tmp/sim_fromuser
Alles, was der Bediener eintippt und mit [Return] abschließt, kommt wieder auf den Bildschirm zurück. Gleichzeitig gibt die Simulation die Ascii-Codes als Hex-Werte aus. Das ist nicht besonders spannend, aber eine brauchbare Basis für einen simplen Datenaustausch.
Das Unschöne an den Pipes ist allerdings, dass sie nicht unter allen Systeme bidirektional oder nicht immer voll-duplex arbeiten. Das obige Beispiel benutzt jeweils ein Fifo für die Eingabe (softwareseitiges Schreiben) und die Ausgabe (softwareseitiges Lesen). Ist ein richtiges virtuelles Evaluierungsboard mit Tastern oder gar einem kleinen Bildschirm zu simulieren, lässt sich die Lösung mit unter Umständen mehrfach erforderlichen named Pipes schlecht handhaben. Dazu kommt, dass Pipes nicht besonders portabel sind, sich also je nach Betriebssystem die Befehle zur Erzeugung unterscheiden.
Distributed Simulation mit Netpp
Die Ghdlex-Library bietet noch eine weitere Möglichkeit, nämlich übers lokale Netzwerk verteilt mit einer virtuellen Hardware zu kommunizieren. Die Ghdlex-Entwickler nennen den Mechanismus Network Property Protocol [8]. Netpp wurde ursprünglich als Bibliothek zur einfachen Hardwarebeschreibung entwickelt und später analog zu diversen RPC-Protokollen erweitert.
Die eigentliche Leistung von Netpp besteht darin, eine Hardware in XML zu beschreiben und daraus Quellcode wie C oder VHDL zu generieren. Einige Anwender bauen damit per GNU Make die komplette Firmware des Geräts. Die lässt sich als Slave-Server (siehe unten) per Netzwerk oder andere Interfaces über geräteunabhängige Software konfigurieren und fernsteuern. Seit Anfang 2011 ist Netpp Open Source.
Das Framework hat sich für die Entwicklung netzwerkfähiger (Embedded-Linux)-Geräte sowohl beim Prototyping wie auch der finalen Implementation insofern bewährt, als dass es lästige Handarbeit und administrativer Aufwand wie Synchronisation der Firmware mit der Benutzersoftware spart. Wie die Testbench in der VHDL-Welt existiert in der Netpp-Welt eine Testbench für die Gerätefunktionen auf der Benutzerebene, typischerweise realisiert mit Python-Skripten.
Ob das Gerät nun ein echtes Gerät mit Mikrocontroller und Betriebssystem (Linux oder leichtgewichtiger) ist oder eine Simulation, spielt in diesem Szenario theoretisch keine Rolle mehr. Egal ist auch, wo die Simulation abläuft. Sie lässt sich beispielsweise auf dem Multikern-Linux-Rechner des Chefs durchführen, während die Software auf dem Windows-XP-PC des Praktikanten per Netpp virtuelle Pins konfiguriert.
In der Praxis läuft das Virtuelle trotz leistungsfähigem Arbeitsrechner meist langsamer ab als die Zielhardware. Beim einfachen Blinker-Beispiel oben wird sich die Simulation in der Ausführungsdauer von jener der echten Welt nicht wesentlich unterscheiden, aber die Emulation eines kompletten Embedded-Linux-Rechners – so wie es Qemu kann – wäre für diese Methode eine Nummer zu groß. Deswegen beschränkt sich der Anwendungsbereich bisher auf einfache Mikroprozessor-Systeme – das ist zumindest das, was der Doppelkern-Laptop des Autors dieses Artikels noch bewältigt.
Das Funktionsprinzip von Netpp ist folgendes: Ein Netpp-fähiges Gerät nimmt entweder die Rolle eines Master (Client) oder Slave (Server) ein. Da TCP/IP aber diese Unterschiede auf Hardware-Ebene a priori nicht kennt, kann Netpp gleichzeitig als Master und Slave arbeiten. Die folgenden Beispiele behandeln diese unterschiedlichen Rollen jeweils einzeln.
Simulation als Master
Angenommen, jemand entwickelt die Ansteuerung eines LCD-Bildschirms und will die Ausgabe der Pixel auf einem virtuellen Bildschirm simulieren. Dann ergibt es einen Sinn, dass die Hardware eigenständig Ausgaben tätigt – sie nimmt deshalb die Rolle des Masters ein. Der virtuelle Bildschirm wiederum ist als einfacher Remote-Framebuffer (über die SDL-Library [9]) implementiert, in dessen Speicher Pixelwerte geschrieben werden. Das Update des Framebuffers erfolgt über die C-Routine »sim_updatefb()« in Listing 3, welche die VHDL-Seite als Prozedur »updatefb()« periodisch aufruft.
Die »DEVICE« – und »TOKEN« -Argumente sind jeweils Handles für das Gerät beziehungsweise die zugehörige Eigenschaft des Geräts, die die Software beim Start der Simulation ermittelt. Zu diesem Zeitpunkt baut sich auch die TCP-Verbindung zum Gerät, hier dem Remote-Bildschirm, auf. Einfacher wäre es natürlich, den Framebuffer lokal auszugeben und wenn nötig durch eine Remote-X-Window-Verbindung zu tunneln.
Listing 3
Master-Routine in C
01 int set_buffer(DEVICE d, TOKEN t, void *buf, int len) 02 { 03 int error; 04 DCValue val; // netpp Runtime-Datentyp 05 val.value.p = buf; // Zeiger auf Framebuffer 06 val.len = len; // Laenge des Buffer 07 val.type = DC_BUFFER; // Typ DC_BUFFER 08 09 error = dcDevice_SetProperty(d, t, &val); // Puffer schreiben 10 if (error < 0) handleError(error); 11 return error; 12 } 13 14 void sim_updatefb(FBHANDLE handle) 15 { 16 FBuffer *fb = GET_FB(handle); // Framebuffer-Kontext holen 17 printf("Updating buffer size %ld\n", fb->size); 18 set_buffer(fb->device, fb->token, fb->data, fb->size); 19 }
Simulation als Slave
Wenn jemand beispielsweise eine Hardware-Krypto-Erweiterung entwickeln will, die über einen USB-Port mit dem Hostrechner kommuniziert, nimmt dieser klar die Master-Rolle ein: Er schickt die Anforderungen, der Slave antwortet. Beim Implementieren der Simulation ergibt sich nun die etwas knifflige Frage: Wie teilt man der Simulation, die ihre eigene Mainloop hat, die Rolle eines Netpp-Slave zu, der eine ganz andere Mainloop besitzt, in der er auf TCP-Aktivitäten wartet? Mit Threading.
Listing 4 aus der »simnetpp.vhdl« -Netpp-Datei startet zum Anfang der Simulation im Masterclock-Prozess mit »thread_init()« einen separater Netpp-Thread. (»thread_init()« ist wieder eine in C implementierte Funktion aus »thread.c« .) Sobald »sigterm« High wird, beendet sich die Schleife und der Thread terminiert.
Für die Datenkommunikation zwischen den beiden quasi-parallel laufenden Threads kommt analog zur Lösung per Unix-Pipes eine Software-Fifo-Implementation der Ghdlex-Codesammlung zum Einsatz. Die arbeitet gegenüber der Pipe bidirektional. Per Netpp lässt sich der Ein- und Ausgabepuffer des Fifos via obigen Thread schreiben beziehungsweise lesen. Die Simulation liest dabei fortlaufend den Status des Software-Fifo und ermittelt, ob Daten verfügbar sind oder geschrieben werden können. Einem auf Netpp umgebogenen Gerätetreiber gelingt so beispielsweise mit einem virtuellen USB-Fifo zu sprechen und man merkt – abgesehen von der langsameren Ausführungsdauer – davon idealerweise nichts.
Listing 4
simfifo.vhdl (Auszug)
01 process 02 variable err : integer; 03 begin 04 err := thread_init(""); 05 if err < 0 then 06 assert false report "Failed to launch thread" severity failure; 07 end if; 08 clkloop : loop 09 wait for 1 us; 10 clk <= not clk; 11 if sigterm = '1' then 12 exit; 13 end if; 14 end loop clkloop; 15 16 print(output, " -- TERMINATED --"); 17 thread_exit; 18 wait; 19 end process;
Zugriff auf virtuelle Register
Netpp erlaubt virtuelle wie auch reale Hardware in XML zu beschreiben, was den Weg vom Prototypen zur Hardware oft erleichtert. In einem Team, das ein auf programmierbarer Logik fußendes Hardware-Design von Grund auf neu entwickeln will, wird sich typischerweise der HDL-Experte die geplanten Funktionen des Geräts schildern lassen und parallel dazu die Testbench entwickeln.
Meistens ist es so, dass die Entwickler als erstes über einen Satz Register zur Konfiguration des Geräts nachdenken. Sobald die Grundfunktionen des Designs per Simulation soweit verifiziert sind, wird der Firmware-Programmierer die Register benutzen wollen. Die Ghdlex-Bibliothek enthält einige Stümpfe, um kodierte Register anzusprechen.
Im Kern entstehen beim Netpp-»make« aus der XML-Hardwarebeschreibung automatisch eine Anzahl Dateien, für das folgende Beispiel:
- »registermap_pkg.vhdl« : Package mit Definition von Konstanten, entsprechend der Register und Bitfeld-Namen aus der XML-Beschreibung,
- »registermap.h« : C-Header mit Register-Definitionen,
- »proplist.c« : die Property-Liste des Netpp-Slave, die faktisch alle Eigenschaften enthält, die der Netpp-Client kommuniziert bekommt.
Kompiliert ergeben die drei Dateien – zusammen mit der geräteunabhängigen »libslave.a« aus Netpp – eine typische Netpp-Slave-Simulation.
Anhand eines einzelnen Registers lässt sich bei diesem Beispiel demonstrieren, wie Entwickler nach und nach mehr Funktionen in ein Hardware-Modul integrieren: Die XML-Datei »ghdlsim.xml« definiert innerhalb des Knotens »<registermap>« diverse »<register>« -Knoten mit einzelnen untergeordneten »<bitfield>« -Knoten. In Abbildung 5 zeigt ein XML-Editor ein so definiertes simples Control-Register an.

Abbildung 5: »ghdlsim.xml« in einen XML-Editor geladen zeigt eine einfache Registerdefinition an.
Eigenschaftsdefinitionen
Weiter unten in der XML-Datei beschreibt eine Property-Definition die Eigenschaft des virtuellen Geräts (Abbildung 6). Die Definition macht das Bit 7 mit der ID »RESET« des »Control« -Registers per »<regref>« -Verweis über die Eigenschaft »Reset« via Netpp-Protokoll als Bool-Typ zugänglich. Die »simfifo.vhdl« -Simulation aus der Ghdlex-Sammlung benutzt obige XML-Definition, um die Register-Erweiterung zu erzeugen. Der Aufruf des »simfifo« -Executable startet die Simulation und einen Netpp-Slave-Thread. Der liefert auf die »netpp localhost« -Anfrage eines Netpp-Masters folgende Liste von Eigenschaften:
Properties of Device 'GHDLSimInterface' associated with Hub 'TCP': Child: [00000001] 'Enable' Child: [00000002] 'Fifo' Child: [00000003] 'Reset' Child: [00000004] 'Throttle' Child: [00000005] 'Timeout'
Diese Properties lassen sich nun abfragen und ändern, beispielsweise das Throttle-Bit, welches die Simulation etwas drosselt, wenn keine Aktivität auf dem FIFO-Interface stattfindet. Das Kommando »netpp localhost Throttle« fragt die Property ab und bekommt als Antwort: »Type : Boolean [RW.] Value: 1« . Mit »netpp localhost Throttle 0« kann der Entwickler die Property setzen.
Am Ende fehlt der Simulation nur noch das Emulieren des virtuellen Registerzugriffs. Im vorliegenden Fall ist die oben definierte Register-Map einfach ein Array aus 256 Bytes, aus dem die von eben bekannte Prozedur »regmap_read()« laufend selektiv einzelne Register aus der Simulation abfragt. Das ist nicht besonders effizient und kann sogar sehr zeitaufwändig werden, wenn viele Register anzusprechen sind. Deswegen sollte man die Abfrage nur dort implementieren, wo sie nötig ist. Listing 5 fragt darum das »val« -Register nur bei der steigenden »clk« -Flanke ab. Mehr Details zum Hardwaredesign mit Netpp beschreibt [8].
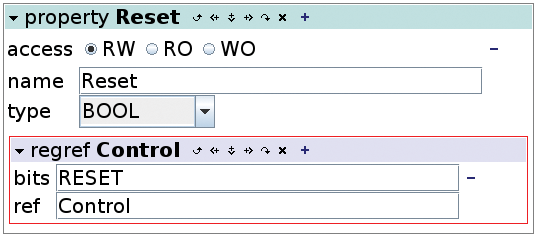
Abbildung 6: Das »ghdlsim.xml«-Mapping des Hardware-Bit in ein abstraktes Property.
Listing 5
Abfrage virtueller Register
01 process (clk) 02 variable val : unsigned(7 downto 0); 03 begin 04 if rising_edge(clk) then 05 regmap_read(RegControl, val); 06 throttle <= val(BIT_THROTTLE); -- Das 'Drossel'-Signal abfragen 07 end if; 08 end process;
Fazit und Ausblick
Mit VHDL und den gezeigten Simulationtechniken und -tools können Entwicklerteams in einer Art Rapid Prototyping frühzeitig die Funktionalität des späteren Gerätes skizzieren und verifizieren. Sie sparen damit meistens zeitraubende Iterationen und Testprozeduren. Außerdem können sie aus der Gerätebeschreibung in XML gleich die Entwicklerdokumentation erzeugen. Nach abgeschlossener Simulation erzeugt der Entwickler mit einem Synthesewerkzeug aus den VHDL-Daten eine FPGA- oder CPLD-spezifische Netzliste und programmiert den Chip.
Der Artikel hat nur einen (relativ neuen) Teilaspekt moderner Geräteentwicklung beleuchten können. Wer ins Thema umfassender einsteigen will, findet bei der aktiven und begeisterten Entwickler-Community Rat und Hilfe, beispielsweise im populären deutschsprachigen Mikrocontroller-Forum. [10] Dort gibt es zudem viele Anwendungsbeispiele zu programmierbarer Hardware, wie Evaluationskits, Synthesewerkzeuge und deren Betrieb unter Linux.
Infos
- Detaillierte Übersicht über Verilog: http://www.mikrocontroller.net/articles/Verilog
- Dokumente zu VHDL: http://tams-www.informatik.uni-hamburg.de/research/vlsi/vhdl/index.php?content=03-documentation
- GTK Wave: http://gtkwave.sourceforge.net
- Dateien zur Simulation: ftp://www.linux-magazin.de/pub/listings/magazin/2012/02/VHDL
- Zylin ZPU: http://opensource.zylin.com/zpu.htm
- GHDL-Erweiterungen (Ghdlex-Bibliothek): http://section5.ch/downloads/ghdlex-0.03eval.tgz
- Yann Guidon, “GHDL interfaces and extensions”: http://ygdes.com/GHDL/
- Netpp-Bibliothek: http://section5.ch/netpp
- SDL: http://www.libsdl.org
- Forum zu Elektronik und Hardwareprogrammierung: http://www.mikrocontroller.net





