
© Jim Mills, 123RF.com
PostgreSQL beabsichtigt mit der neuen Version 9.0 zurück ins Spiel der großen Datenbank-Engines zu finden. Dazu bringt sie asynchrone Replikation und manch weiteres nützliches Feature fürs Unternehmen mit. Der Artikel zeigt anhand einer Suse-Installation, wie Admins Streaming Replication konfigurieren.
Oktober 2010, die PostgreSQL-Community ist sich einig: Mit der neunten Version [1] schließt die Open-Source-Datenbank in vielen Bereichen zur Konkurrenz auf. Die meisten der 200 Funktionserweiterungen und Verbesserungen (siehe den Datenbank-Vergleich in diesem Schwerpunkt) standen schon länger auf der Wunschliste der Anwender, vor allem in Sachen HA und Replikation hinkte PostgreSQL der Konkurrenz hinterher.
Jetzt helfen neue HA-Mechanismen den Datenbankprofis im Unternehmen einfache Master-Slave-Setups einzurichten. Der Artikel zeigt das zum einfachen Nachbau anhand von Open Suse oder SLES.
Streaming Replication
Der neue Streaming-Replication-Mechanismus der Version 9.0 (Abbildung 1) ist in wenigen Schritten eingerichtet. Zwar bringt PostgreSQL nur asynchrone Replikation, die synchrone soll aber in 9.1 folgen. Dank Write-Ahead Logging (WAL, [2]) fällt jetzt die bei Anwendern ungeliebte Notwendigkeit weg, ganze 16-MByte-Logsegmente nach der Point-in-Time-Recovery-Methode (PITR) zu übertragen.
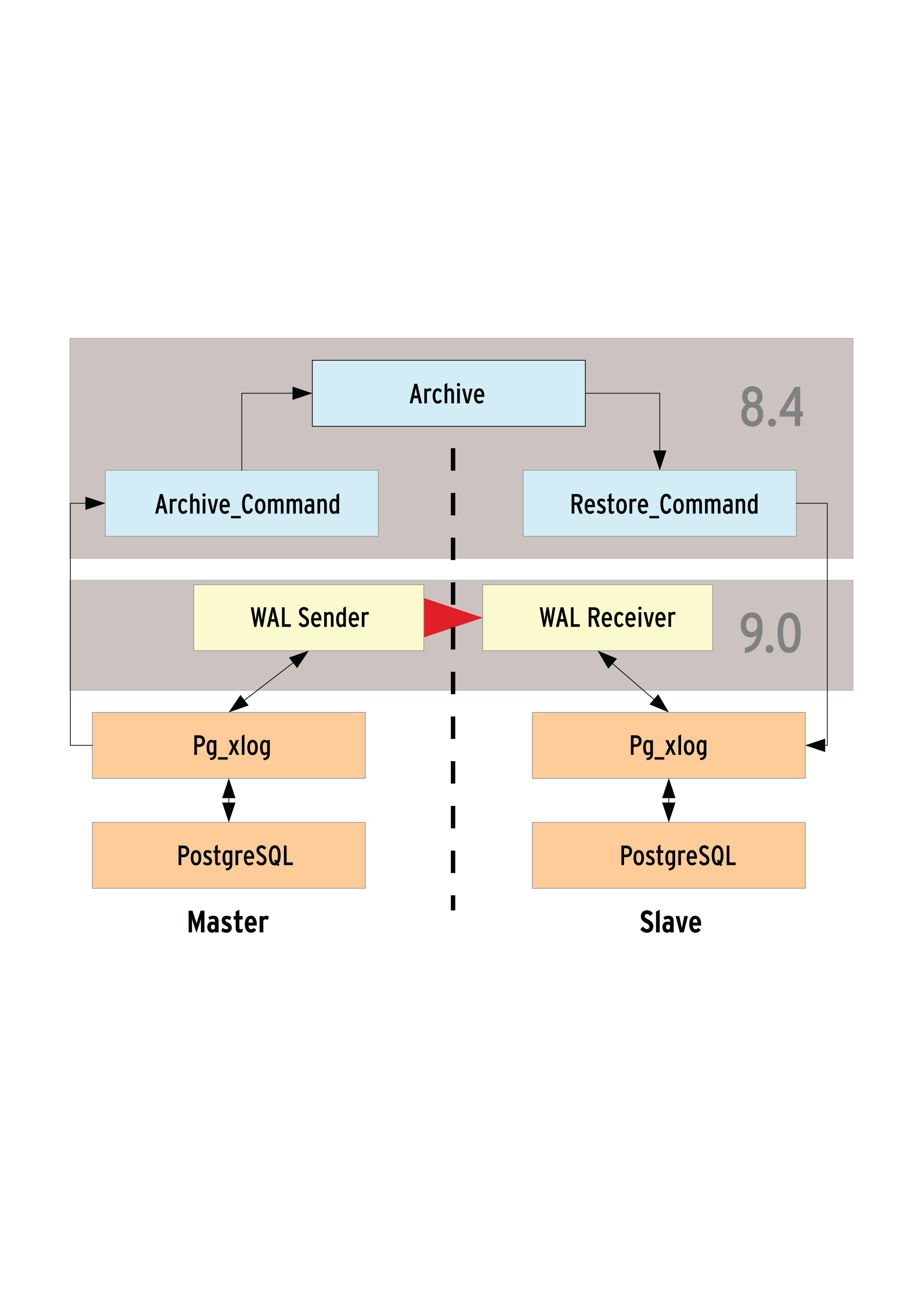
Abbildung 1: Wo früher Warm Standby über das Archive-Kommando funktionierte (oben), arbeitet heute die Streaming Replication mit WAL-Sender und -Receiver.
Darüber hinaus stehen Slaves neuerdings zumindest mit Hot Standby read-only zur Verfügung. Im Gegensatz zur synchronen Replikation ist zwar der Datenbestand nach einem Schreibvorgang nicht sofort auf dem Slave verfügbar, jedoch halten sich die Abweichungen mit meist unter einer Sekunde Differenz auch auf belasteten Datenbanken in Grenzen. Das macht den Einsatz eines Slave auch in anderen Szenarien attraktiv, zum Beispiel fürs Reporting.
Installation
Die aktuelle Version von PostgreSQL war bis Redaktionsschluss noch nicht in den Standard-Repositories der Suse-Distributionen angekommen. Aktuelle Pakete für Open Suse wie auch SLES lassen sich jedoch im »server:database« -Repository des Open Suse Build Service finden, das beim Qualitätsstandard mit den Standard-Repositories gut mithält. Listing 1 zeigt dessen Integration und die Paket-Installation.
Listing 1
PostgreSQL 9.0 auf Open Suse 11.3
01 zypper ar http://download.opensuse.org/repositories/server:/database:/postgresql:/9.0/openSUSE_11.3/server:database:postgresql:9.0.repo 02 zypper ref 03 zypper in postgresql-server 04 /etc/init.d/postgresql start
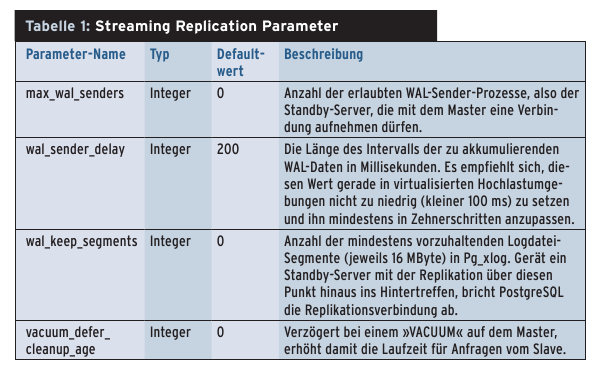
Das folgende Setup richtet einen Master (»10.1.1.1« ) und einen Slave (»10.1.1.2« ) ein. Das Szenario lässt sich durch beliebige weitere Slaves erweitern. Deren maximale Anzahl definiert der Eintrag »max_wal_senders« in »/var/lib/pgsql/data/postgresql.conf« (Listing 2). Tabelle 1 gibt einen Überblick über die Parameter für die Streaming Replication in der Konfigurationsdatei.
Listing 2
/var/lib/pgsql/data/postgresql.conf
01 listen_addresses = '*' 02 max_connections = 500 03 shared_buffers = 32MB 04 wal_level = hot_standby 05 archive_mode = on 06 archive_command = 'rsync -a %p /var/lib/pgsql/data/pg_xlog_archive/%f'. 07 max_wal_senders = 1 08 wal_keep_segments = 32
Nach dem Start des PostgreSQL-Dienstes hat der Server seinen Datenbereich unter »/var/lib/pgsql/data« initialisiert. Mit
sudo -u postgres mkdir /var/lib/pgsql/data/pg_xlog_archive; chmod 700 /var/lib/pgsql/data/pg_xlog_archive
legt der Admin das konfigurierte Archiv auf dem Master an. Die Streaming Replication benötigt momentan noch dauerhaft einen Superuser-Account, den der Admin in der PostgreSQL-Konfiguration absichern sollte (Listing 3)
Listing 3
/var/lib/pgsql/data/pg_hba.conf
01 TYP DATENBANK USER ADDRESSE ACL 02 host replication postgres 10.1.1.2/32 trust 03 host replication all 0.0.0.0/0 reject
Den Slave initialisieren
Danach erstellt er auf dem Master einen Abzug der Datenbanken und synchronisiert diesen per Rsync auf einen Slave:
psql -c "SELECT pg_start_backup('master-backup')"
rsync -HPSav --exclude postmaster.pid --exclude postmaster.log data/* root@10.1.1.2:`pwd`/data/
psql -c "SELECT pg_stop_backup()"
Auf dem Slave steht dagegen in »/var/lib/pgsql/data/postgresql.conf« :
hot_standby = on archive_mode = off archive_command = ''
Und in »/var/lib/pgsql/data/recovery.conf« :
standby_mode = on restore_command = 'rsync -a /var/lib/pgsql/data/pg_xlog_archive/%f %p' primary_conninfo = 'host=10.1.1.1 port=5432user=postgres' trigger_file = '/tmp/pgsql-replication.trigger'
Nach erfolgreicher Inbetriebnahme findet der Admin folgende Log-Einträge: Auf dem Master taucht der Slave bereits mit seiner IP auf und meldet »LOG: replication connection authorized: user=postgres host=10.1.1.2 port=55723« . In ähnlicher Weise meldet auch der Slave den Vollzug mit »LOG: streaming replication successfully connected to primary« . In der Prozessliste durch »ps -ef« schlägt sich das funktionierende Setup ebenfalls nieder (Abbildung 2).
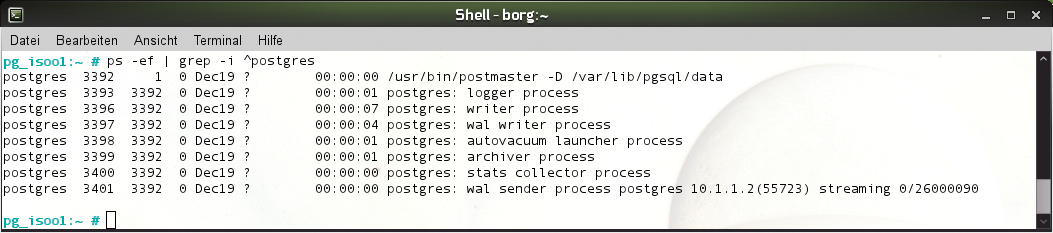
Abbildung 2: Nachdem die Verbindung zwischen Master und Slave besteht, zeigt auch die Prozessliste die zuletzt gestreamte Log-Position.
Ab diesem Moment repliziert PostgreSQL alle Daten vom Master an den oder die Slaves. Von denen kann jetzt bereits jeder im schlimmsten Fall zu einem Master werden. Der Kasten “Best Practices bei DB-Replikation” gibt grundsätzliche Tipps nicht nur für solche Setups.
Best Practices bei DB-Replikation
Die Natur der Datenreplikation ist durchaus komplex, man denke nur an Themen wie ACID- oder AKID-Konformität. Doch einige Vorgaben haben sich als elementarer Grundstock für den erfolgreichen Betrieb herauskristallisiert. Der Admin sollte Folgendes beachten:
- Generell UTC verwenden und auf Zeitzonen mit Sommerzeit (DST, Daylight Savings Time) verzichten.
- Seine Uhren mit NTP und mehreren Zeitservern synchronisieren.
- Möglichst identische Systeme mit der gleichen Systemkonfiguration verwenden.
- Klare Namen an die Systeme vergeben. Bezeichner wie »master« und »slave« sind denkbar ungeeignet und erzeugen schon bei einem Switch der Datenbanken-Rollen Konfusion.
- Die Replikationsstände regelmäßig überwachen. Auseinanderdriftende Datenbestände verursachen unvorhersehbare Probleme.
Beim letzten Punkt ist es für den Datenbank-Admin sinnvoll, auf dem Master mit »SELECT pg_current_xlog_location();« den aktuellen Datenbestand (anhand der aktuellen Position im Log) abzufragen. Den vergleicht er mit der letzten empfangenen Log-Position auf dem Slave (»SELECT pg_last_xlog_receive_location();« ) und dessen aktueller Log-Position (»SELECT pg_last_xlog_replay_location();« , dieser Stand ist wirklich auf der Platte).
In-Place Upgrades
Wo früher Admins für ein Datenbank-Upgrade noch »pg_dump« und »pg_restore« oder im besten Falle den Pg-Migrator [3] verwenden mussten, kommt heute »pg_upgrade« zum Einsatz und verkürzt die Wartungsfenster für große Datenbanken bei einem sicheren Upgrade beträchtlich. Selbst nach einem empfohlenen »vacuumdb –all –analyze« sind auch größere Datenbestände eher in Minuten als Stunden auf den aktuellen Stand gebracht.
Performance Nebensache
Auch wenn für die Entwickler Performance-Optimierungen bei dieser Release keine Priorität hatten, wirkt sich so manche Änderungen sehr positiv aus. Durch Indizes mit »NOT-NULL« -Feldern untersucht die Version 9 im Gegensatz zu PostgreSQL 8.4 nur den Index, während 8.4 hierzu die Tabelle selbst filtern musste. Mit dem Entfernen unnötiger Join-Statements, beispielsweise wenn referenzierende IDs per »UNIQUE« ohnehin eindeutig sind, lässt sich in größeren Abfragen deutlich Zeit sparen.
Mit der effizienteren Neu-Implementation von »LISTEN« und »NOTIFY« bearbeitet der Master Events schneller, und dank der neuen Payload-Option kann eine lauschende Anwendung einen bis zu 8000 Byte langen String erhalten. Die Anweisung »VACUUM FULL« dupliziert nicht mehr jeden Datensatz einzeln, sondern erzeugt eine neue Tabelle und kopiert alle Einträge in einem Vorgang. Das spart je nach Datenmenge bis zu 60 Prozent der bisher benötigten Zeit.
Column-Trigger rufen automatisch Stored Procedures auf, sobald die Datenbank den Wert eines Feldes explizit aktualisiert, »WHEN« -Trigger prüfen dagegen datenbezogene Konditionen. Beide Funktionen vereinfachen viele Arbeiten innerhalb einer Applikation und reduzieren die Anzahl der auszuführenden Trigger, was die CPU entlastet sowie RAM und Festplatten-I/O spart.
Das folgende Bespiel ruft die Procedure »tr_update_status()« auf, sobald jemand einen Eintrag der Tabelle »tbl_user« im Feld »user_status« aktualisiert:
CREATE TRIGGER update_status BEFORE UPDATE OF user_status ON tbl_user FOR EACH ROW EXECUTE PROCEDURE tr_update_status();
Das lässt sich in vielen Fällen sinnvoll verwenden: Auf einem Asterisk-Server mit PostgreSQL-Backend zum Beispiel kann der Admin dies nutzen, um nach einem Telefonanruf eine Neuberechnung des Guthabens durchzuführen, ohne eine eigene komplexe Applikationslogik entwickeln zu müssen.
Mehr Sicherheit durch Token und Passwort-Policy
Mit der Möglichkeit, per Radius [4] zu authentifizieren, etwa durch Token, Cryptocard oder E-Token (Alladin) [5], macht PostgreSQL einen großen Schritt in Richtung hochsichere Umgebung. Mit der einfachen Konfiguration der Einträge »radiusserver« , »radiussecret« , »radiusport« und »radiusidentifier« ist die Anbindung auch schon erledigt. Das Modul »passwordcheck« erzwingt jedoch auch ohne Radius sichere Kennwörter.
Schon in älteren Versionen ließ sich PostgreSQL mit Erweiterungen wie Slony [6], Londiste [7] oder Pgpool-II [8] das Replizieren beibringen. So schnell sind diese Erweiterungen in vielen Installationen auch nicht zu ersetzen, weil sie häufig maßgeschneiderte Setups mitbringen. Die jetzt in Version 9 eingebaute Streaming Replication ist jedoch ein großer Schritt, da die meisten Admins keine komplexen Replikationsstrategien benötigen, wenn sie lediglich Daten von mehreren Orten im Netzwerk intensiv nutzen oder hochverfügbar machen wollen.
Es kommt noch mehr
Hot Standby und In-Place Upgrades sorgen dafür, dass PostgreSQL auch in Sachen Usability einen erheblichen Fortschritt verzeichnet. Bessere Performance und zahlreiche kleinere Verbesserungen an der Kommandosprache wie zum Beispiel »GRANT ON ALL« oder »DEFAULT PERMISSIONS« helfen dem Admin einfache Aufgaben nun auch wirklich einfach umzusetzen. Das spart Zeit.
Für gehobene Ansprüche in der Replikation, zum Beispiel Multi-Master-Setups, empfiehlt es sich, noch bis März zu warten, da dann der Postgres Extensible Cluster (Postgres-XC, [9]) auch Schreibvorgänge unter Version 9.0 relativ einfach verteilen wird. Mit den durch Oracle ausgerufenen Preissteigerungen für MySQL [10] dürfte bis dahin PostgreSQL auch für hartgesottene MySQL-Befürworter einen neuen Blick wert sein.
Infos
- PostgreSQL 9.0: http://www.postgresql.org/docs/9.0/static/release-9-0
- PostgreSQL WAL: http://tuning.postgresql.de/wal
- Pg-Migrator: http://pgfoundry.org/projects/pg-migrator
- Free Radius SQL, Howto: http://wiki.freeradius.org/SQL_HOWTO
- Titel-Thema “Schlüsseldienste: Zertifikate, Keys und Tokens in der Praxis”: Linux-Magazin, 12/10, S. 29 bis 56
- Slony: [http://www.slony.info]
- Londiste: [http://skytools.projects.postgresql.org/doc/londiste.cmdline.html]
- Pgpool-Projekte: [http://pgpool.projects.postgresql.org])
- Postgres-XC: http://wiki.postgresql.org/wiki/Postgres-XC
- MySQL-Preise: http://www.mysql.com/products
Der Autor

Michael Kromer ist Senior IT Consultant und Linux Engineer bei der Millenux GmbH in München. Er entwickelt an diversen Open-Source-Projekten (Kernel, Open NX, Asterisk, Virtualbox und ISC Bind) mit. Zu finden ist er unter http://medozas.de.





