
© elcabron, 123RF.com
Im vergangenen Herbst legten die freien Datenbanken MySQL, PostgreSQL, Ingres und Firebird neue Releases mit einer ganzen Latte Neuerungen auf. Dieser Überblick hilft die Systeme mit den eigenen Anforderungen abzugleichen und zu klären, ob sich gar das teure Oracle lohnt.
Die Redewendung “Drum prüfe, wer sich ewig bindet…” stammt natürlich nicht aus der Datenbankentwicklung. Doch auch in diesem unromantischen Zusammenhang gilt: Bindung an eine so unternehmenskritische Komponente ist von eher langfristiger Natur, denn das “S” in SQL steht nach gängiger Interpretation nicht für “Standardized”, sondern “Structured”.
Kein Standard
Ein Wechsel der Datenbank-Engine setzt also, allen Standardisierungs-Bemühungen für SQL zum Trotz, auch umfangreichere Anpassungen der Befehle voraus, über die eine Anwendung mit der Datenbank kommuniziert. Als Hilfestellung bei der keineswegs einfachen Wahl vergleicht dieser Artikel die aktuellen Highlights von MySQL, PostgreSQL, Ingres, Firebird und Oracle und trägt zudem deren Neuerungen seit Anfang 2008 zusammen. Tabelle 1 gibt einen detailreichen Überblick über die Features der Kandidaten.
MySQL
Die Erfolgsgeschichte von MySQL, der verbreitetsten Datenbank-Engine, begann mit der Release von Version 3.23 im Januar 2001. Spötter bezeichneten MySQL, das damals nur elementare Funktionen enthielt, als besseres Dateisystem. Doch wegen der von Anfang an guten Performance und der verständlichen Dokumentation schwang sich der Newcomer trotzdem flott zum meistgenutzten Datenbanksystem auf.
Seit dieser Zeit ist viel passiert: Die Inno-DB-Storage-Engine von dem schon 2005 zu Oracle gehörigen Innobase sorgte für referenzielle Integrität und ACID-Transaktionen. Allerdings fehlen dieser Engine, die mit der aktuellen Version 5.5 zum Standard avanciert, nach wie vor Volltext-Indices.
In den Jahren 2004 bis 2008 hat aber auch MySQL von anderen Systemen schon länger bekannte Features übernommen, etwa Prepared Statements, Stored Procedures sowie Trigger und Views. Unter der Ägide von Sun lieferte Version 5.1 Partitionierung, Event-Scheduler und zeilenbasierte Replikation, außerdem ein Plugin-API, das Storage-Engines zur Laufzeit lädt, sowie tabellenbasierte Serverlogs. Eine Performance Schema genannte Pseudo-Storage-Engine erlaubt den Zugriff auf Performancedaten über Abfragen.
Oracles halber Schritt
Mit Version 5.5 liegt seit 15. Dezember die erste Release seit der Übernahme von Sun durch Oracle vor. Die Entwicklung der bereits als Alpha-Release verfügbaren MySQL-Version 6.0 hat Oracle dagegen eingestellt [1].
Version 5.5 bringt verfeinerte Möglichkeiten zur Partitionierung: Ranges oder Listen als Basis für die Partitionierung dürfen nun einen oder mehrere Spaltenwerte referenzieren. Auch bei der Replikation legt MySQL 5.5 nach: Neben der asynchronen Replikation, bei der sich der Masterserver nicht um den Erfolg der Replikation kümmert, und der synchronen Replikation, bei der Transaktionen erst nach Abschluss aller Replikationsoperationen als erfolgreich gelten, strebt die neue halbsynchrone Replikation einen Kompromiss zwischen Datensicherheit und Performance an.
Dort wartet der Masterserver nur noch während eines konfigurierbaren Zeitfensters auf maximal einen Slaveclient. Tritt ein Timeout auf, so schaltet der Server, um die Performance nicht zu stark zu beeinflussen, in den unsicheren asynchronen Modus, doch nur so lange, bis sich einer der Slaves zurückmeldet.
Version 5.5 unterstützt außerdem temporäre Tabellen. Die XML-Unterstützung bleibt weiterhin auf X-Path-Queries beschränkt. Mit der MySQL-Workbench, die auch in einer GPL-lizenzierten Community-Variante verfügbar ist, liegt ein leistungsfähiges grafisches Designwerkzeug vor (Abbildung 1).
Abbildung 1: Mit der MySQL-Workbench gibt es seit 2008 ein grafisches Datenbank-Designwerkzeug für Linux, Mac OS und Windows, das wesentlich mehr leistet als die verbreitete Webanwendung PHP Myadmin.
Abgespaltet: Maria DB
Wie bei Open Office kam es nach der Übernahme von Sun durch Oracle auch bei MySQL zu einem Fork: Einer der MySQL-Initiatoren, Michael “Monty” Widenius, bezweifelte in seinem Blog, dass die am weitesten verbreitete Datenbank-Engine und die kommerziell erfolgreichste unter einem Dach koexistieren können [2]. Vor der Übernahme habe MySQL Oracle gezwungen, die Lizenzkosten zu senken, argumentiert Widenius und glaubt daher nicht, dass Oracle Geld für die Entwicklung neuer Features ausgibt, da dies die Marktchancen für das Hauptprodukt schmälere.
Widenius’ Fork Maria DB, liegt bereits stabil in Version 5.2 vor [3]. Im Vergleich zu MySQL 5.1, auf deren Quellcode der Fork aufsetzt, bietet er unter anderem Erweiterungen bei Rechenausdruck-basierten virtuellen Spalten und eine Plugin-basierte Authentifizierung.
Außerdem sind die als experimentell bezeichneten Storage-Engines Sphinx, eine Volltext-Suchmaschine [4], und Oqgraph [5] hinzugekommen, eine Graphdatenbank-Engine, wie sie aus der NoSQL-Welt bekannt ist. Leider arbeitet Oqgraph nur im RAM. Nach einem Neustart des Servers lässt sich die Graphdatenbank nur aus SQL-Befehlen wiederherstellen, was die Praxistauglichkeit bisweilen sehr einschränkt.
PostgreSQL
Wie schon der Name zeigt (Post Ingres), hat PostgreSQL seine Wurzeln im Ingres-Projekt der Universität of California in Berkeley. Bereits 1985 startete Michael Stonebraker dort das Postgres-Projekt, das Ingres technologisch beerbte, ohne den Quellcode zu übernehmen. Das heutige PostgreSQL, das SQL sichtbar im Namen trägt, startete erst 1994 als Anschlussprojekt, das die Ingres-Abfragesprache QUEL [6] durch SQL ersetzte.
Dank seiner universitären Wurzeln gehört PostgreSQL bis heute nicht einer einzelnen Firma, was Anwender angesichts der Unruhe, die die Oracle-Übernahme in der MySQL-Community ausgelöst hat, inzwischen vielleicht als Vorteil empfinden. PostgreSQL gibt es unter einer BSD-artigen Lizenz [7].
Noch im letzten Jahrtausend implementierte PostgreSQL im Enterprise-Umfeld gefragte Features wie Views, Trigger, temporäre Tabellen und Multi Version Concurrency Control (MVCC), ein Verfahren, das konkurrierende Zugriffe effizienter ausführt, den einzelnen Nutzern Schnappschüsse des aktuellen Datenbestandes bereitstellt und damit ein unbeabsichtigtes Blockieren der Datenbank verhindert.
Bei der früh implementierten Trigger-Unterstützung hebt sich PostgreSQL bis heute von der Konkurrenz ab: Die durch bestimmte SQL-Operationen ausgelösten Prozeduren dürfen Entwickler nicht nur im PostgreSQL-spezifischen PL/PgSQL, sondern auch in den verbreiteten Sprachen Tcl, Perl und Python schreiben. Das Spektrum der externen Erweiterungen reicht von der Bash [8] über das besonders Webentwicklern geläufige PHP bis zum speziell für das Einbetten in andere Software konzipierte Lua [9].
PostgreSQL enthält ein umfangreiches Volltext-Suchsystem. Seit PostgreSQL 8.3 ist das frühere Tsearch2-Modul fester Bestandteil der Datenbank-Engine. Es unterstützt Unicode und linguistische Funktionen wie Stop-Words und Synonyme [10]. Bei der Replikation hinkt PostgreSQL MySQL allerdings hinterher: Erst die kürzlich erschienene Version 9 beherrscht asynchrone Replikation (siehe Artikel in diesem Schwerpunkt). Eine synchrone Replikation ist für die Folgeversion geplant. Allerdings gibt es eine Reihe von Third-Party-Erweiterungen, die diese bereits jetzt bereitstellen [11]. Mit Pg-Admin3 (Abbildung 2) steht auch für PostgreSQL ein leistungsfähiges grafisches Verwaltungstool zur Verfügung.
Abbildung 2: Der Pg-Admin3 administriert auch fortgeschrittene PostgreSQL-Funktionen wie Trigger oder die Volltextsuche in einem übersichtlichen GUI.
Ingres
Wie PostgreSQL und MySQL liegt auch Ingres seit Herbst in einer neuen Version vor. Zu den wichtigen Neuerungen dieser Version 10 gehören spaltenspezifische Datenverschlüsselung, Support für den JDBC-4-Standard und Multiversion Concurrency Control. Erstmals steht auch eine 64-Bit-Version für Windows zur Verfügung.
Batch-Queries bündeln nun mehrere »Insert-« oder »Delete« -Kommandos und übertragen sie in einem Stück an den Server. Eine Optimierung bei Abfragen über partitionierte Tabellen steigert die Performance, wobei eine neue Funktion für das Dynamic Partition Pruning zum Einsatz kommt: das Überspringen nicht zu durchsuchender Partitionen. Für mehr Tempo auf Unix-Systemen sorgen der Einsatz von Direct-I/O [12] und das Prä-Allozieren von Plattenplatz mit dem »fallocate« -System-Call [13].
Version 9.3 vom Oktober 2009 erweiterte dagegen vor allem den Umfang des Ingres-SQL-Dialekts: Vergleiche mit »LIKE« dürfen sich seither auf Spalten vom Typ »LONG VARCHAR« und »LONG NVARCHAR« beziehen. Außerdem kommen die Vergleichsoperatoren »BEGINNING« , »CONTAINING« und »ENDING« sowie »SIMILAR TO« mit Unterstützung für Reguläre Ausdrücke hinzu.
Leider nur für Windows erhältlich greift das Community-Projekt Easy Ingres [14] PHP-Entwicklern unter die Arme, die Anwendungen auf Basis von Ingres statt für MySQL schreiben. Auch hilft die Software beim Programme-Migrieren von MySQL zu Ingres. Das unter der Federführung des französischen PHP-Programmierers Cedric Pasquotti entwickelte Projekt kombiniert die Ingres-Datenbank (zurzeit noch Version 9.2) mit Apache 2.2.8, PHP 5.2.9, der Ingres Developer Workbench [15], dem Scite Editor 1.77 sowie der Demo-Applikation Frequent Flyer und sorgt für die passende Konfiguration.
Eine 70er-Jahre-Datenbank
Die Geschichte von Ingres beginnt bereits 1974 als eine der frühen Umsetzungen des damals neuen Konzepts der relationalen Datenbank. Die kommerzielle Ära von Ingres endete Anfang 2004 in weitgehender Bedeutungslosigkeit. Doch nach der Release unter der GPL 2 nahm die Entwicklung neue Fahrt auf.
Ingres setzte vor allem Enterprise-Features wie Partitionierung und Replikation früh um. Bei der Verarbeitung von Geodaten hat der Hersteller mit dem an das universitäre Ingres-Projekt anschließenden PostgreSQL zurzeit nur einen Konkurrenten. Bei der XML-Unterstützung ist Ingres dagegen nicht auf der Höhe der Zeit, sie fehlt komplett, eine Volltext-Suche ebenso, und ein Tool wie Squirrel-SQL (Abbildung 3, [17]) muss unter Linux das fehlende grafische Verwaltungswerkzeug ersetzen.
Abbildung 3: Da es unter Linux kein speziell auf Ingres zugeschnittenes grafisches Verwaltungswerkzeug gibt, bleibt außer der Kommandozeile nur der Rückgriff auf generische Datenbank-Tools wie Squirrel-SQL.
Dem verstärkten Trend zu nicht-relationalen Datenbanken trägt Ingres offenbar auch Rechnung, indem es eine proprietäre Vektordatenbank anbietet (siehe Kasten “Vector Wise”). Vector Wise stammt aus einem Forschungsprojekt des Amsterdamer CIW. In die Weiterentwicklung zu einem kommerziellen Produkt haben Ingres und Intel investiert.
Vector Wise
Im Juni 2010 stellte Ingres die erste Version der spaltenorientierten Datenbank Vector Wise [16] vor, zunächst nur für 64-Bit-Linux als RPM und TGZ, inzwischen auch als Amazon-Cloud-RPM. Es gibt aber nur 180-Tage-Testversionen. Ingres bietet zudem eine Administrationsoberfläche (leider nur) für 32-Bit-Windows und einen JDBC-Treiber zum Download an.
Spaltenorientierte Vektoren
Die Abfragearchitektur von Vector Wise fußt nicht auf einzelnen spaltenorientierten Tupeln, sondern auf spaltenorientierten Vektoren. Dazu kennt die Engine Varianten der relationalen Operatoren (Selektion, Projektion, Join, Sortierung), die mehrere Werte quasi-parallel verarbeiten und dabei die Möglichkeiten moderner CPUs nutzen.
Die Größe der Vektoren wählt eine Logik so, dass alle nur für die Abfrage benötigten Daten in den CPU-Cache passen. Zudem komprimiert Vector Wise die Datensätze. Ingres und Intel behaupten, dass im Ergebnis komplexe Datenanalysen gegenüber relationalen Datenbanken auf Vector Wise um zwei Größenordnung schneller laufen.
Firebird
Obwohl Firebird laut Ohloh.net mehr Benutzer hat als Ingres, kennen durchschnittliche Computernutzer den Datenbankserver bestenfalls, weil er der Auslöser für einen Namenswechsel des Webbrowsers Firefox war. Was die Leistung angeht, muss sich Firebird (Abbildung 4) jedoch vor der freien Konkurrenz nicht verstecken: Er kennt Stored Procedures, Trigger und referenzielle Integrität. Zu den fortgeschrittenen Funktionen gehören MVCC und Cursors.

Abbildung 4: Flamerobin ist ein leistungsfähiger Datenbankmanager für Firebird, der grafische Tools und einen SQL-Editor mit Syntax Highlighting und Autocompletion kombiniert. Firebird ist der freie Nachfolger von Borlands Interbase.
So genannte Careful Writes sorgen für das schnelle Recovery, ohne dass dafür die üblichen Logs nötig sind. Außerdem stellt Firebird ungewöhnlich viele Anbindungen zur Verfügung: Es lässt sich über ODBC, OLEDB, JDBC 4, ein natives API und über einen Dbexpress-Treiber ansprechen. Außerdem gibt es Module für Perl, Python, PHP und Dotnet.
Firebird geht auf das proprietäre Interbase zurück, das Borland Mitte 2000 als freie Software herausgab. Die erste Release erschien im März 2002. Bis Februar 2004 hatte das Entwicklerteam die Software von C nach C++ portiert und als Version 1.5 herausgegeben. Wichtige Features wie Trigger kamen mit Version 2, während die aktuelle Version 2.5 sich auf ein neues Threading-Modell konzentriert. Von Bedeutung ist dies vor allem für die Embedded-Version, mit der Firebird als einzige der vorgestellten Datenbanken aufwarten kann. Auch sind jetzt mehrere Prozessorkerne möglich.
Oracle Database
Oracle ist in der aktuell verfügbaren Version 11g Release 2 seit September 2009 verfügbar und die wichtigste kommerzielle Datenbankvariante auf dem Markt. Im Vergleich zu den gelisteten Open-Source-Systemen bietet sie das mit Abstand mächtigste Feature-Set, fordert Administratoren und Entwicklern jedoch auch am meisten Know-how ab.
Bereits mit Version 10g setze Oracle auf eine damals neuartige Clustertechnologie, das so genannte Grid. Aktuelle Versionen entwickeln diese Technik weiter. So erlaubt es der Oracle Real Application Cluster (RAC), One-Node-Single-Instance-Systeme in das Grid zu überführen, um Features wie Rolling Upgrades und Transparent Session Failover bei einem Ausfall des Datenbanksystems zu nutzen.
Im Bereich der Speicherverwaltung hebt sich Oracle besonders von den Konkurrenzprodukten ab, da Oracles ASM (Automatic Storage Management) sich zu einem vollwertigen Storage-Manager mit Stripe- und Mirroring-Unterstützung entwickelt hat, der ein Volume-Manager auf Betriebssystemebene überflüssig macht und so eine einheitliche Ressourcenverwaltung sicherstellt.
Mit dem Oracle Database Filesystem stehen Large Objects direkt im Dateisystem zur Verfügung. Mittels Fuse und der darunterliegenden PL/SQL-Implementierung sind Strukturen der Datenbank wie Dokumente zum Beispiel für einen Webserver ohne zusätzlichen Programmieraufwand erreichbar.
Darüber hinaus glänzt die proprietäre Engine im Bereich der dynamischen Speicherverwaltung und Archivierung von Altdaten mit einer Vielzahl von Neuerungen, die den Platzbedarf und den administrativen Overhead in großen Umgebungen erheblich reduzieren.
Als Killer-Feature bei der Datenbankentwicklung gilt die Edition-based Redefinition. Als eine Art interner Versionsverwaltung lassen sich verschiedene Versionen eines Package oder einer Funktion innerhalb der Datenbank erstellen, testen oder ausführen und schließlich für andere Anwender sichtbar machen sowie in den Produktionsbetrieb überführen. Auch für Views steht dieses Feature nun zur Verfügung und erlaubt es, Basistabellen im laufenden Betrieb umzustellen.
Qual der Wahl
Der Markt der SQL-Datenbank ist im Wesentlichen aufgeteilt, es findet “nur noch” ein Verdrängungswettbewerb statt. Das macht die Auswahl für die Kunden kaum einfacher, weil die etablierten Anbieter ständig an Performance und Features schrauben. Schwerer noch wiegt, dass die Anforderungen der Applikationsschichten in der Praxis stark differieren – zwischen denen jedes Datenbanksystem nur einen mehr oder minder passenden Kompromiss anbieten kann.
Beim Vergleich technischer Features hilft die Tabelle 1 in diesem Artikel. In Sachen Enterprise-Einsatz gibt eine Studie [18] von Forrester Research eine erste Orientierung: Danach dominieren IBM, Microsoft und Oracle mit 88 Prozent Marktanteil das Feld, weil hier Performance, Verfügbarkeit und Skalierbarkeit überzeugen würden.
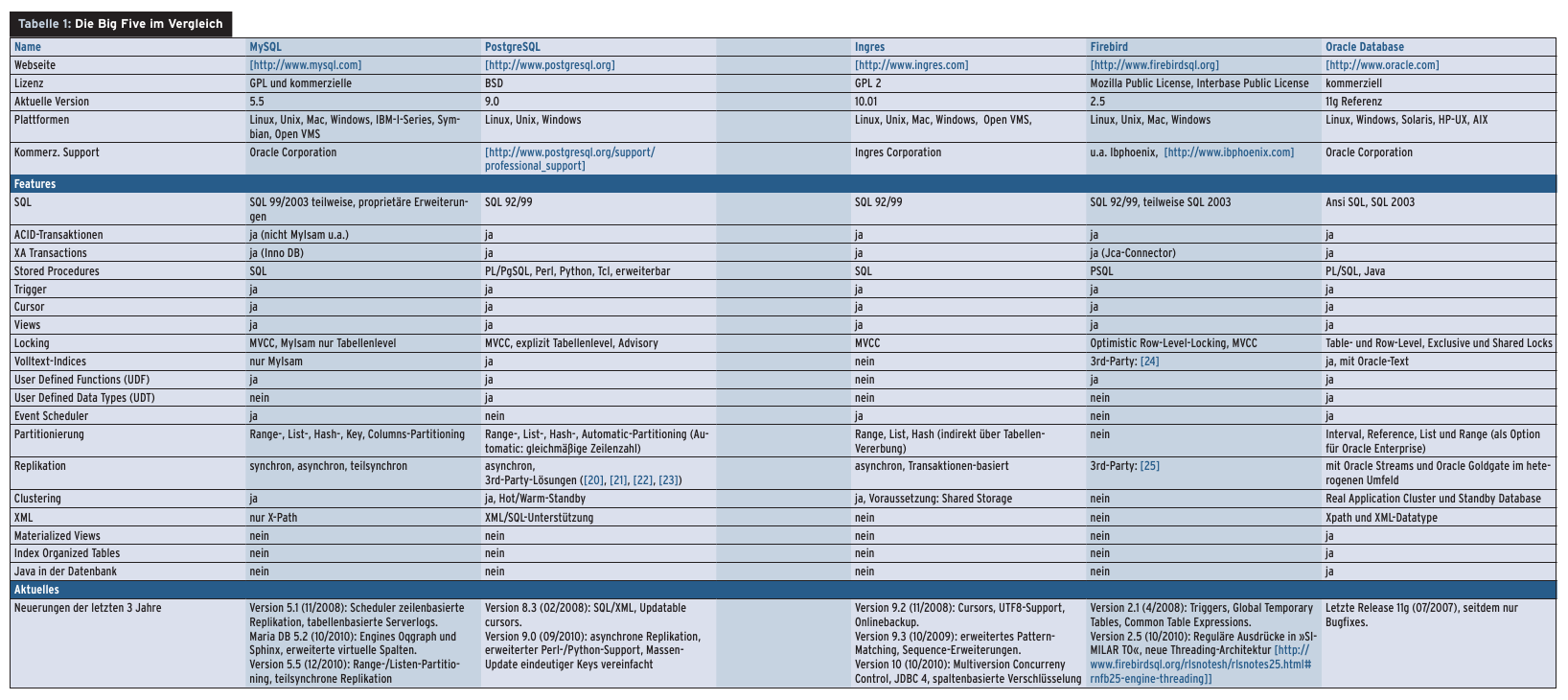
Tabelle 1
: : Die Big Five im Vergleich” width=”300″ height=”134″ /> Tabelle 1: : Die Big Five im VergleichIngres sei bei weniger als 1 TByte Daten und maximal 1000 gleichzeitigen Benutzern die derzeit beste Open-Source-Datenbank, auch wenn sie nicht die bekannteste sei. Allerdings sehen nur wenige fertige Anwendungspakete Ingres als Datenbank vor.
Laut Studie hat MySQL bei den Features zu Ingres aufgeschlossen und auch eine große Benutzergemeinde, es fehle aber an Zertifizierungen und Unterstützung wichtiger Produkte wie die von Peoplesoft, SAP und Siebel [19]. PostgreSQL besitze zwar die größte Entwicklergemeinde, sei aber in Firmen kaum verbreitet und bei Verfügbarkeit, Sicherheit und Performance abgeschlagen. (mfe)
Infos
- Rest der MySQL-6-Doku: http://dev.mysql.com/doc/refman/6.0/en/
- Michael Widenius’ Blog: http://monty-says.blogspot.com/2009/12/help-saving-mysql.html
- Maria-DB-Release 5.2: http://monty-says.blogspot.com/2010/10/mariadb-522-gamma-is-released.html
- Sphinx: http://sphinxsearch.com
- Oqgraph: http://openquery.com/graph/doc
- QUEL: http://en.wikipedia.org/wiki/QUEL_query_languages
- PostgreSQL-Lizenz: http://www.postgresql.org/about/licence
- Bash-Trigger für PostgreSQL: http://plsh.projects.postgresql.org
- Lua-Trigger für PostgreSQL: http://pllua.projects.postgresql.org
- PostgreSQL-Volltextsuche: http://www.postgresql.org/docs/9.0/static/textsearch.html
- PostgreSQL-Replikation: http://wiki.postgresql.org/wiki/Replication,_Clustering,_and_Connection_Pooling
- Linux Direct-I/O: http://docs.redhat.com/docs/en-US/Red_Hat_Enterprise_Linux/5/html/Global_File_System/s1-manage-direct-io.html
- »fallocate« -System-Call: http://lwn.net/Articles/240571/
- Easy Ingres: http://esd.ingres.com/product/Community_Projects/Development_Tools/Windows_32-Bit/EasyIngres/
- Ingres Database Workbench: http://esd.ingres.com/product/Community_Projects/Development_Tools/Linux_32-Bit/Ingres_Database_Workbench
- Ingres Vector Wise: http://www.ingres.com/vectorwise/
- Squirrel-SQL: http://squirrel-sql.sourceforge.net
- The Forrester Wave, ” Enterprise Database Management Systems”: http://info.ingres.com/g/?UJR6Q22767=clicksrc:pr (Registrierung erforderlich)
- Mathias Huber, “Ingres und MySQL führen bei Open-Source-Datenbanken”:https://www.linux-magazin.de/content/view/full/41390
- Slony: [http://www.slony.info]
- Londiste: [http://skytools.projects.postgresql.org/doc/londiste.cmdline.html]
- Bucardo: [http://bucardo.org]
- Pgpool-Projekte: [http://pgpool.projects.postgresql.org]
- Firebird-3rd-Party-Indexer: [http://www.firebirdfaq.org/faq328/]
- Firebird-3rd-Party-Replikation: [http://www.firebirdfaq.org/faq249/]





