
© Zacarias da Mata, Fotolia
Konturarm präsentieren sich gängige Open-Source-Cloudlösungen in Sachen Hochverfügbarkeit. Dieser Artikel testet Open Stack, Eucalyptus, Open QRM und vergleicht die Fähigkeiten, die ein Linux-Eigenbau bietet. Gerade bei der Standardausstattung der drei Fertigprodukte kam manch schauderhaftes Detail zutage.
Cloud Stacks versprechen Wolken problemlos zu installieren, zu konfigurieren und zu warten. Klick, klick – und schon hat der Kunde eine weitere virtuelle Maschine in der Cloud, zum Beispiel für den nächsten Webserver im Cluster, geklont aus dem bewährten Image im Storage. Doch rational betrachtet müssen Cloud Stacks wesentlich mehr bieten als das einfache Anlegen virtueller Maschinen. In einem Rechnerpark, der Hunderte Nodes vereint, ist es in der Praxis mehr als wahrscheinlich, dass regelmäßig einzelne Knoten ausfallen.
Der ideale Cloud Stack verfügt daher über ein eingebautes, automatisiertes Monitoring, fängt Probleme auch ohne Interaktion eines Admin ab und weiß sie gar zu umgehen, indem er defekte Nodes deaktiviert und ersetzt. Virtualisierungs-Platzhirsch VMware macht das fast perfekt vor, lässt sich dafür aber auch teuer bezahlen ([1], siehe auch den Vergleich mit Citrix Xen Server in diesem Heft).
Das Linux-Magazin hat sich die drei prominentesten Open-Source-Cloudlösungen vorgeknöpft und ihre HA-Fähigkeiten auf den Prüfstand gestellt. Den Anfang im Test machen mit Open Stack ([2], [3]) und Eucalyptus ([4], [5]) zwei Projekte, die mit dem Ziel antreten, Admins ein umfassendes Interface fürs Cloud Computing an die Hand zu geben. Noch deutlich weiter geht der Kandidat Nummer drei, Open QRM ([6], [7]). Abschließend zeigt der Artikel, dass auch der Eigenbau aus Linux-Bordmitteln und bewährten HA-Tools keine Wolkenschlösser produziert.
Open Stack
Open Stack enthält als relativ neues Projekt Komponenten von Open Nebula, der Cloudplattform der US-Weltraumbehörde Nasa, aber auch Bestandteile der Plattform von Rackspace [8]. Sowohl die Nasa als auch Rackspace entschlossen sich 2010 fast zeitgleich dazu, ihre internen Lösungen zu veröffentlichen. Schnell verfielen sie auf die Idee, aus der Arbeit mit dem gleichen Ziel eine gemeinsames Projekt zu machen, und hoben Open Stack aus der Taufe.
Open Stack besteht aus drei Kernkomponenten: Swift, Glance und Nova. Swift ist eine Abstraktionsschicht für Storage, basiert auf einem Objekt-Modell und ist prinzipiell vergleichbar mit Amazon S3 [9]. Admins kommissionieren damit schnell und unkompliziert zusätzlichen Speicher für neue VMs. Glance kümmert sich um die Verwaltung von Images für virtuelle Maschinen (Abbildung 1). Ein Administrator soll so eine neue virtuelle Maschine auf Basis eines schon vorhandenen VM-Image innerhalb von wenigen Sekunden anlegen können.
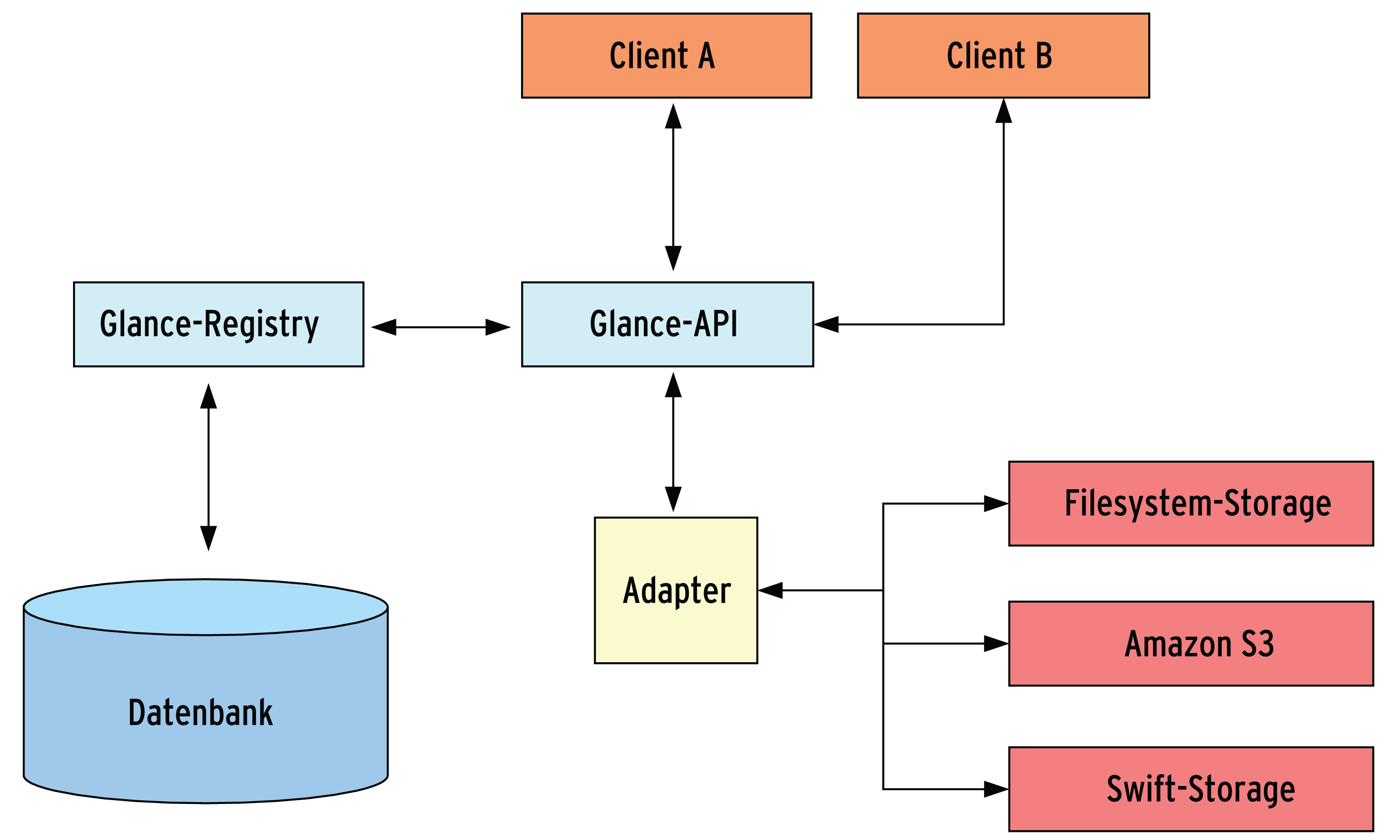
Abbildung 1: Unter der Haube von Open Stack stellen die Dienste Swift und Glance Images und Storage zur Verfügung. Die dritte Komponente Nova ist die Schnittstelle zu Administrator und Web-GUI.
Nova schließlich ist die Open-Stack-Komponente, mit deren Hilfe der IaaS-Dienst realisiert ist: Sie stellt per Klick oder Befehl auf der Kommandozeile virtuelle Maschinen bereit und benutzt dazu die Infrastruktur, die Swift und Glance ausbreiten.
HA: Fehlanzeige
Die Pflicht erfüllt Open Stack locker, aber die Kür fällt weniger schön aus: Im Test bewahrheitete sich das Vorurteil, dass Hochverfügbarkeit als integriertes Konzept bei Open Stack praktisch keine Rolle spielt. Ein einfacher Versuch macht das deutlich: Ein Open-Stack-Setup, das sich über mehrere Rechner erstreckt, erhält mittels Kommandozeile den Auftrag, Storage für eine neue VM zur Verfügung zu stellen. Danach startet der Tester via Nova ein vorgefertigtes Image. Solange auf dem Host für die virtuelle Maschine alles in Ordnung ist, wähnt sich der Cloudbenutzer in Sicherheit.
Die erweist sich schlagartig als trügerisch, wenn das Hostsystem aufgrund eines Ausfalls nicht mehr erreichbar ist: Die VM des Benutzers hängt so lange, bis das Hostsystem wieder funktioniert und die virtuelle Maschine neu gestartet ist. Ein Mechanismus, der Open Stack die VM auf einem anderen Host im Cluster neu starten ließe, existiert nicht. Keine Spur von Hochverfügbarkeit, ein automatisches Abfangen von Ausfällen ist nicht vorgesehen. Die Nutzer der Cloud-Dienste haben auf die Wiederbelebung der VMs praktisch keinen Einfluss; sie sind den Admins der Cloud ausgeliefert.
Eucalyptus
Eucalyptus ist einer der ältesten Cloud-Stacks. Zu Redaktionsschluss war die Version 3 [10] laut Hersteller bereits fertig, auf der Open-Eucalyptus-Seite stand aber für den Test leider nur Version 2 zum Download bereit. Das ist schade, weil gerade die dritte Ausgabe deutliche Verbesserungen im Bereich der Hochverfügbarkeit zu bieten hat. Doch schon in der zweiten Ausgabe steht die Infrastruktur eigentlich parat, die notwendig wäre, um den Ausfall von Nodes zu kompensieren und gestörte virtuelle Maschinen neu zu starten.
Eucalyptus zeichnet sich insbesondere durch seine Kompatibilität zu Amazons EC2 [11] aus. So lassen sich virtuelle Maschinen aus einer privaten Eucalyptus-Wolke in den “Amazonas” migrieren und vice versa.
Viele Controller
Die Software besteht aus fünf Komponenten: Der Cloud Controller (CLC) ist die Instanz für den Betrieb der Cloud, in der alle Fäden zusammenlaufen. Er wickelt auf Wunsch auch die Kommunikation mit der EC2 ab. Daneben übernimmt Walrus [12], eines der beiden Storage Interfaces von Eucalyptus, die Verwaltung des physikalischen Speichers der einzelnen Nodes. Der Cluster Controller (CC) stellt Images für virtuelle Maschinen bereit und startet oder stoppt virtuelle Maschinen auf den verfügbaren Nodes nach Bedarf.
Der Storage Controller (SC) ist das Gegenstück zu Amazons EBS und erlaubt das Speichern von Images irgendwo in der Cloud, ohne auf genau spezifizierten physikalischen Speicher angewiesen zu sein. Last but not least kümmert sich der Node Controller (NC) darum, dass auf den vorhandenen Nodes die Cloud-Dienste nach Anweisung starten oder stoppen.
Wie bei Open Stack ist aber auch bei Eucalyptus 2 die Situation in Hinblick auf Hochverfügbarkeit eher trist. Fällt ein Node aus, merkt der Cloud Controller das zwar. Er korrigiert anschließend auch die maximale Kapazität in seiner eigenen Datenbank und hört auf, dem ausgefallenen Knoten neue VMs zuzuweisen. Die VMs aber, die zum Zeitpunkt des Node-Crash auf dem Knoten noch aktiv waren, fallen vorerst unter den Tisch – so lange, bis ein Cloud-Admin sie händisch auf einem anderen Node neu startet.
Erst Eucalyptus 3 bringt Hochverfügbarkeit
Offensichtlich hatten aber auch die Macher bei Eucalyptus gemerkt, dass der Zustand ohne Hochverfügbarkeitsfunktionen eigentlich untragbar ist, und bei der neuen Version 3 entsprechend nachgebessert. Eucalyptus 3 (Abbildung 2) kommt gewissermaßen frisch aus der Presse – Eucalyptus-CEO Marten Mickos ließ in diversen Interviews im August [13] keinen Zweifel daran, welches Feature sich die Admins und Nutzer von Eucalyptus am dringlichsten gewünscht hatten: Hochverfügbarkeit.
Abbildung 2: Eucalyptus 3 bekommt endlich eine vollständige HA-Lösung: Ähnlich wie bei Open QRM klappt hier künftig das Neustarten von abgestürzten virtuellen Maschinen völlig automatisch.
Und darum haben die Entwickler wohl auch einige Arbeit in das Thema HA gesteckt: Eucalyptus 3 verspricht seine eigenen Komponenten wie die verschiedenen Controller innerhalb des Eucalyptus-Universums redundant auszulegen. Außerdem unterstützt der Node Controller in Kombination mit dem Cluster Controller jetzt Notfallaktionen: Merkt der CC, dass ein Knoten nicht mehr zur Verfügung steht, streicht er ihn – wie bisher – aus der Cloud.
Anders als in Version 2 stellt Eucalyptus 3 auch fest, welche Cloud-Dienste auf dem just ausgefallenen Knoten liefen, und startet sie deshalb jetzt auf einem anderen Node neu.
Open QRM
Der dritte Bolide im Test ist Open QRM, und schon auf den ersten Blick zeigen sich im Vergleich mit Eucalyptus und Open Stack sehr deutliche Unterschiede. Während die beiden letzten ausdrücklich als Framework für Cloud Computing daherkommen, will Open QRM mehr sein als das. Die Suite bezeichnet der Hersteller vollmundig als “Data-Center Management Platform” und legt damit die Messlatte reichlich hoch: Mit Open QRM sollen sich die Abläufe eines gesamten Rechenzentrums umfassend kontrollieren und steuern lassen, inklusive des Einrichtens von virtuellen Domains für Kunden und des Betriebs der VMs über Hardware-Ausfälle hinweg.
Der Dreh- und Angelpunkt einer Open-QRM-Architektur ist der zentrale Server, dessen Administrationsinterface die Wolke verwaltet (Abbildung 3). Die Administration der Storage-Einheiten, die Open QRM zur Verfügung stehen, erledigt der Admin hier. Ebenso legt er in diesem GUI fest, welche virtuellen Maschinen es gibt und welche Netzwerkverbindungen diese miteinander haben.
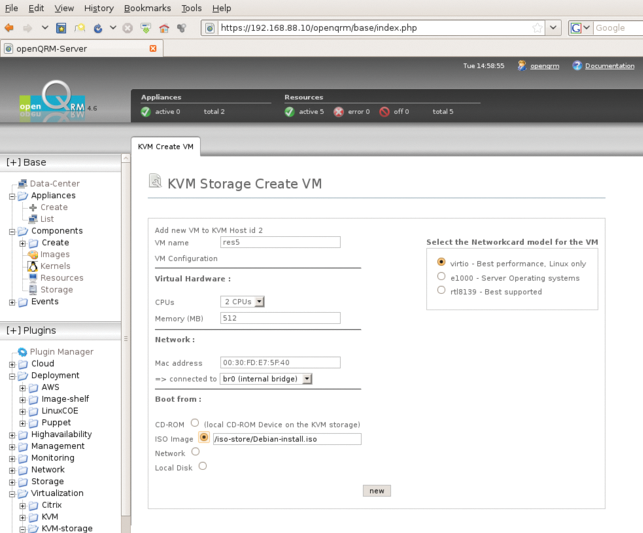
Abbildung 3: Die Abstraktion spiegelt sich bei Open QRM nur zum Teil im Interface für Admins – das ist wohl besser so: »KVM anlegen« klingt eindeutiger als »Virtualisierungsressource anlegen«.
Der Kern von Open QRM ist modular aufgebaut. In einem schlanken Framework sind integriert: Konfigurationsplugins für diverse Aufgaben, ein Modul für Storage-Verwaltung, eines für Monitoring, eines für das Provisioning und sogar ein Modul, das sich explizit um Hochverfügbarkeit kümmert. Die einzelnen Plugins greifen ineinander und führen die Tasks durch, die der Administrator per Browser in Auftrag gibt.
Abstraktion extrem
Ein gewisses Maß an Abstraktion gehört bei Cloudlösungen fest dazu. So ist es für den Endanwender, der eine virtuelle Maschine für einen bestimmten Zweck braucht, völlig irrelevant, woher der Speicher für diese VM kommt, auf welchen Festplatten innerhalb der Cloud seine Daten lagern und wie das Netzwerk funktioniert. Es zählt nur, ob die Cloud die erwartete Leistung bringt.
Open QRM führt die Abstraktion auch im Konfigurationsinterface ein. Zwar müssen Admins noch immer festlegen, an welchem Speicher eine mit Open QRM realisierte Virtualisierungslösung sich bedient und auf welchen Nodes die virtuellen Maschinen starten, aber das Open-QRM-Webinterface bietet dafür vielfältige Werkzeuge und eine eigene Logik.
Unter der Haube kombiniert der so genannte Storage Abstraction Layer alle zur Verfügung stehenden Storage-Devices zu einfachen Speicherpools. Er sorgt dafür, dass Programme und Werkzeuge innerhalb des Open-QRM-Universums stets mit den gleichen Befehlen auf Speicherplatz zugreifen können. Somit ist es letztlich egal, ob der Speicher-Zugriff auf ein per I-SCSI angebundenes SAN oder ein DRBD-Laufwerk auf einem Storage-Cluster erfolgt: In Open QRM sieht jeder Speicherplatz gleich aus, was gerade für die Automatisierungsfunktionen an Bedeutung gewinnt.
Die Abstraktion gilt übrigens nicht nur im Hinblick auf denStorage, sondern auch für virtuelle und echte Geräte. Alle Dienste in Open QRM betrachtet das Management-Center einfach als Ressourcen. Nicht-virtualisierte Systeme lassen sich mithin genauso als Ressource verwalten wie virtuelle Maschinen (siehe Abbildung 4).
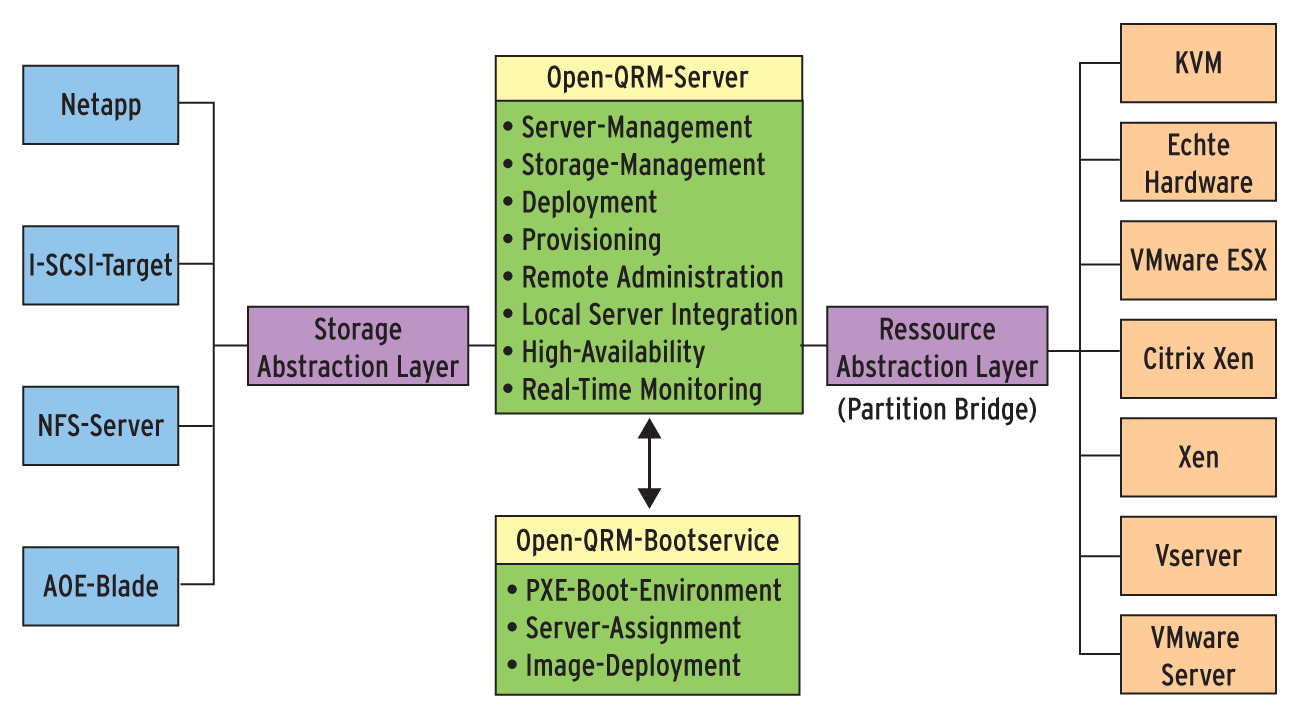
Abbildung 4: Open QRM setzt verstärkt auf Abstraktion. Alles ist entweder ein Storage oder eine Ressource. Das zahlt sich schnell aus, vor allem beim automatischen Start abgestürzter VMs.
Bootservice
In unmittelbarem Zusammenhang mit der Steuerung von Computersystemen steht der Open-QRM-Bootservice. Der Dienst wirkt auf den ersten Blick wie eine Nebensache, ist aber eminent wichtig: Von ihm erfahren physikalische und virtuelle Systeme, welches System sie booten sollen. Indirekt sorgt er dafür, dass aus Systemen überhaupt erst Ressourcen im Open-QRM-Sinne werden. Der Bootservice wird aktiv, wenn auf einem System ein bestimmtes Software-Image deployt werden soll. Er erfüllt aber auch eine wichtige Rolle, wenn physikalische oder virtuellle Maschinen ein neues System booten sollen.
Fällt eine Instanz unter Open QRM aus, dann bleibt das dem eingebauten Monitoringsystem, einem internen Nagios 3 (Abbildung 5), nicht verborgen. Um dessen Konfiguration braucht der Admin sich nicht zu kümmern: Es landet zusammen mit Open QRM automatisch auf dem zentralen Server und ist für Open QRM gleich passend konfiguriert. Wesentlich angenehmer als bei einem reinen Nagios gestaltet sich das Hinzufügen neuer Hosts: Per Mausklick erweitern Admins die Konfiguration, sodass das Monitoring neue Hosts in Sekundenschnelle erfasst und überwacht.
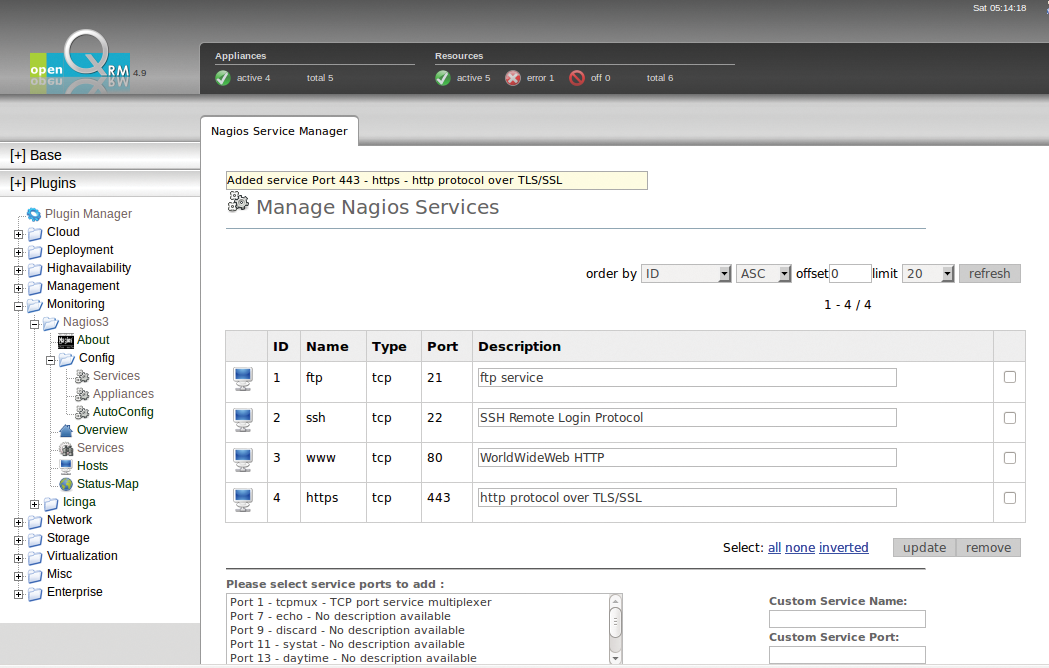
Abbildung 5: Open QRM hat Nagios 3 eingebaut, nimmt aber dem Admin viel lästige Konfigurationsarbeit ab.
Aber Open QRM kann auch etwas unternehmen, wenn eine Ressource etwa nach dem Ausfall einer Hardwarekomponente nicht mehr funktioniert. Hier greift das Abstraktionsmodell: Nach Lage der Dinge reanimiert Open QRM die abgestürzte Ressource entweder auf anderer Hardware, wandelt sie unmittelbar in ein physikalisches System um oder – und das ist durchhaus beachtlich – bootet mittels IPMI (Intelligent Platform Management Interface, eine Schnittstellensammlung zur Wartung und Administration von Rechnern, [14]) einen zusätzlichen Server, um die Ressource dort zu starten (siehe Abbildung 6).
Abbildung 6: Hochverfügbarkeit im Webinterface einstellen, das kann nur Open QRM mit dem HA-Manager-Plugin. Wer das mit IPMI kombinieren will, braucht aber die Enterprise-Variante.
Nahtlos transparent
Die so versprochene “intelligente Hochverfügbarkeit” funktioniert auch in der Praxis sehr gut: Weil das Open-QRM-Kontrollzentrum die Kommunikation zwischen dem Storage auf der einen und den Ressourcen auf der anderen Seite nahtlos transparent abwickelt, verschwimmen die Grenzen zwischen physikalischen Hosts und virtuellen Maschinen. Vom Open-QRM-Bootservice erfährt ein physikalischer Computer oder eine VM beim Systemstart, welches Betriebssystem zu booten ist.
Auch ein fixes Widmen einzelner Maschinen ist möglich, meist aber nicht sinnvoll. Über den Open-QRM-Kern erfährt das bootende System auch, wo es seine Daten findet. Damit kennt es alle wichtigen Details und kann seine Arbeit aufnehmen.
Open QRM Enterprise verspricht die physikalischen in virtuelle Systeme nahtlos zu überführen, ebenso virtuelle in physikalische und virtuelle in andere virtuelle Systeme. Das Ganze verwaltet der Admin mit grafischen Tools, zum Beispiel dem Baukasten des Visual Infrastructure Designers aus Abbildung 7.
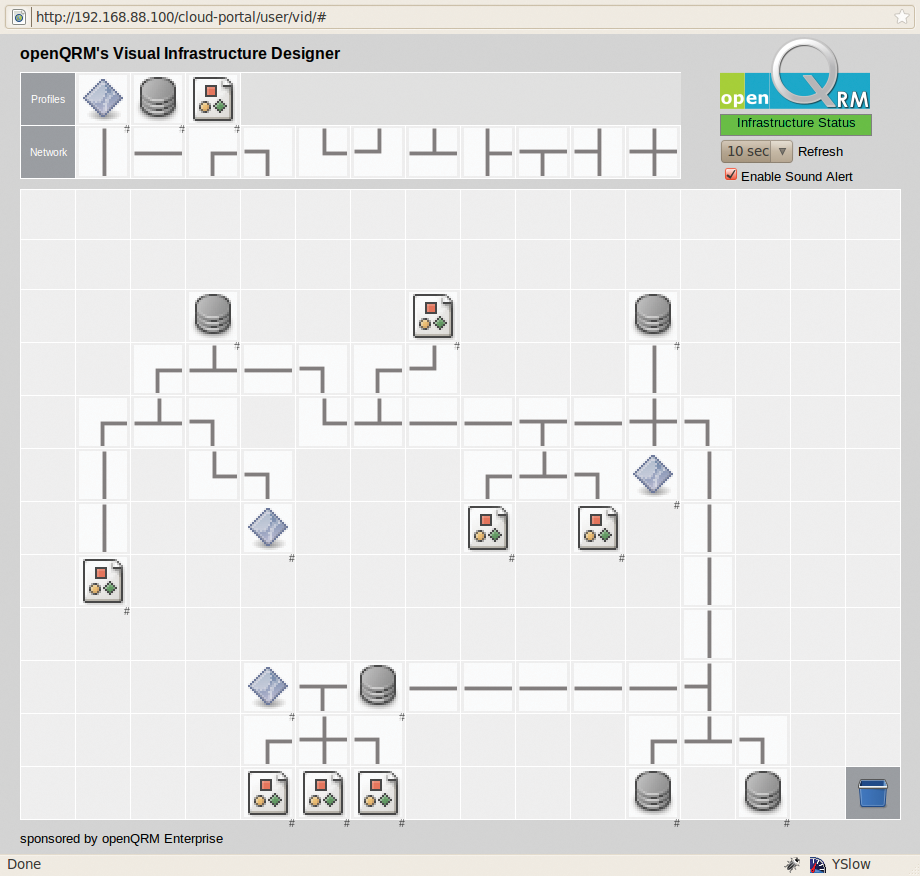
Abbildung 7: Die eigene Cloud-Infrastruktur entwerfen per Drag&Drop, das verspricht der Open QRM Visual Infrastructure Designer.
Intelligente Hochverfügbarkeit dank Green IT
Ebenfalls enthalten sind in Open QRM Features, die die Entwickler als Green IT bezeichnen. Ausgehend von der Beschreibung eines typischen HA-Clusters – ein System betreibt einen Dienst und das andere System langweilt sich – rechnen sie vor, dass Open-QRM-gesteuerte Rechenzentren wesentlich umweltfreundlicher sind. Weil jedes System auf jedem Host laufen kann und es sehr unwahrscheinlich ist, dass alle Server gleichzeitig ausfallen, lässt sich in einem typischen HA-Szenario die Zahl der Standby-Server massiv reduzieren. Per IPMI-Protokoll aktiviert die Enterprise-Variante von Open QRM dann bei Bedarf zusätzliche Server, und stellt so sicher, dass der Webauftritt auch einen plötzlichen Ansturm interessierter Neukunden meistert.
Die Eigenbau-Cloud
Wer auf ein Cloud-typisches Konfigurationsinterface verzichtet, kann sich mit den Bordmitteln jeder Linux-Distribution eine Mini-Cloud bauen, die in Sachen Hochverfügbarkeit wesentlich mehr Features hat als mancher Softwarestack von der Stange. Das alternative Konzept fußt auf der Idee, dass die typische Aufgabe einer Cloud darin besteht, Benutzern Ressourcen zum Betrieb virtueller Maschinen zu verschaffen, und dass es außerdem schnell und einfach geht, neue VMs zu erstellen.
Am Anfang steht immer der Storage. Damit virtuelle Maschinen in größerem Maßstab laufen können, muss Plattenplatz vorhanden sein. In einer typischen Cloud handelt es sich dabei fast zwangsläufig um Shared Storage. Nur der macht die Cloud später problemlos an gestiegene Bedürfnisse anpassbar – wovon der Admin besser von Anfang an ausgeht. Welche Art von geteiltem Speicher zum Einsatz kommt, ist der Präferenz des Admin sowie den finanziellen und zeitlichen Ressourcen überlassen.
Klassische SANs verfügen meist über ordentliche Frontends für die Administration und funktionieren dank aktueller FC-Treiber für Linux problemlos [15], verursachen bei der Anschaffung jedoch horrende Kosten und binden eine Plattform zumindest über den Zeitraum der Garantie (meist handelt es sich um fünf Jahre) an den Hersteller des SAN.
Wer einen kleineren Geldbeutel hat, greift auf DRBD [16] zurück: Zwei Server von der Stange, LVM und DRBD sorgen dafür, dass sich Platz nahtlos zuweisen lässt. In Kombination mit Pacemaker und einem der verschiedenen I-SCSI-Targets wird aus den Stangen-Rechnern ein echter Ersatz für SAN-Devices – der auch den Ausfall eines Knotens ohne Schwierigkeiten überlebt. Das Verwalten des verfügbaren Speichers passiert in diesem Falle nicht über ein Webinterface, sondern über die jeweiligen Kommandozeilen-Werkzeuge. Alternativ steht die Linux Cluster Management Console LCMC [17] zur Verfügung, mit der sich die Administration auch grafisch erledigen lässt.
Frontends, Monitoring, HA
Wo der Speicherplatz für virtuelle Maschinen herkommt, ist damit klar – es fehlen aber noch die Server, auf denen die virtuellen Maschinen tatsächlich laufen. Bei der hier vorgestellten Mini-Cloud unterliegen Admins im Hinblick auf die Virtualisierung keinen Zwängen. Sämtliche mit einem I-SCSI-Terminator ausgestatteten Linux-Distributionen sind mögliche Zielsysteme, genauso aber auch VMware oder Citrix Xen Server. Vorteilhaft ist freilich der Einsatz von Linux-Distributionen, die mit Pacemaker [18] ausgestattet sind.
Dann lassen sich nämlich auch die Frontends in die Clusterverwaltung des SAN-Ersatzes aufnehmen. Pacemaker kümmert sich darum, dass tatsächlich all jene VMs laufen, die auch laufen sollen. Stürzt ein Virtualisierungsfrontend ab, merkt Pacemaker das und startet die fehlenden VMs auf einem der anderen Hosts. Mit der eingebauten Monitoringfunktion von Pacemaker lässt sich dieses Prinzip so weit aufbohren, dass es bei einzelnen VMs auch prüft, ob die Prozesse tatsächlich da sind.
Unverzichtbar ist in einem Cloudsetup dennoch auch ein leistungsfähiges und umfassendes externes Monitoringsystem. Es stellt sicher, dass Admins von Ausfällen einzelner Rechner zumindest frühzeitig erfahren. Verfügen die Nodes der eigenen Virtualisierungsplattform über Managementkarten mit IPMI-Schnittstelle, lassen sie sich auch direkt aus Nagios heraus rebooten. Über Shellskripte lässt sich sogar eine nahezu automatische Verwaltung der virtuellen Maschinen realisieren.
Über die gleiche Monitoringfunktion, die per IPMI den Reboot durchführt, wäre es freilich auch möglich, die virtuellen Maschinen wieder zu starten, die einem bestimmten Node zugeordnet sind. Der Aufwand, ein solches Setup nachzubauen, ist aber beträchtlich.
Auch die Cloudkunden haben die Möglichkeit, sich durch die typischen Tools des Linux-Cluster-Stack innerhalb ihrer virtuellen Maschinen zu schützen. Dazu müssen sie jedoch mindestens zwei virtuelle Maschinen zur Verfügung haben – und diese sollten nicht auf demselben Host laufen. Neben einer gemeinsamen, alternierenden Service-IP bedarf es noch der typischen Werkzeuge Corosync oder Heartbeat für die Kommunikation der Clustermanager in den VMs, Pacemaker als Cluster Resource Manager und möglicherweise auch DRBD, um sicherzustellen, dass beide virtuellen Maschinen stets die neuesten Daten erhalten.
Eine ausführliche Anleitung vom Autor dieses Artikels, die sich mit der Einrichtung von Pacemaker beschäftigt, findet sich unter [19] und [20], zwei weitere Artikel in der Titelstrecke dieser Linux-Magazin-Ausgabe schildern den Eigenbau-Ansatz von mehreren Seiten.
The Winner is … Open QRM
Die oben vorgestellten Komplettlösungen zielen darauf ab, Admins ein möglichst umfassendes und nützliches Werkzeug zur Cloudadministration zu geben. Open QRM erfüllt diese Aufgabe gut, ist aber eigentlich nicht Cloud-spezifisch und bringt einige Funktionen mit, die für Cloudadmins keinen Nutzen haben. Eucalyptus und Open Stack eignen sich perfekt, um Kunden schnell ein Plätzchen in der Wolke herzurichten, Verrechnung und dergleichen inklusive. Dafür hapert es in Sachen Hochverfügbarkeit und Verlässlichkeit bei Ausfällen.
Open QRM ist im Gegensatz zu Eucalyptus und Open Stack eine sehr elegante Lösung zum automatisierten Überwachen von virtuellen Maschinen innerhalb der Cloud. Die verschiedenen Abstraktionsschichten beweisen, dass sich die Entwickler einige Gedanken zu diesem Thema gemacht haben. Die Umsetzung von Virtualisierung in Open QRM und die damit verbundene Option, nahtlos zwischen einer virtuellen Maschine und einem physikalischen Server hin und her zu schwenken, überzeugen. In Sachen Virtualisierung unterstützt Open QRM neben den üblichen Verdächtigen KVM und Xen auch VMware sowie Hosts mit Citrix Xen Server, Open VZ, Lxc oder Virtualbox.
Auch beim Storage gibt sich die Umgebung kontaktfreudig und spricht I-SCSI, AOE und lässt sich auch mit einer Netapp-Appliance verbinden. Unterstützung für DRBD ist ebenso enthalten, genauso wie für verschiedene LVM-Funktionen. Open QRM ist eine runde Sache, auch wenn der Funktionsumfang wohl über die Grenzen dessen hinausschießt, was viele Admins brauchen. Wer Open QRM ausprobieren möchte, kann das auf praktisch allen gängigen Distributionen tun. Es gibt zwei Varianten der Umgebung: Die Open-Source-Version sowie die Enterprise-Version. Letztere bietet vor allem ein Modul für elektronische Zahlungsabwicklung (Billing) mit eigener Währung. Auch die im Artikel beschriebenen Funktionen für IPMI-Management sind der kostenpflichtigen Enterprise-Version vorenthalten.
Bedingt empfehlenswert: Eucalyptus und Open Stack
Eucalyptus 2 und Open Stack versagen beim Thema Hochverfügbarkeit in der Cloud vollständig. Angesichts der Tatsache, dass HA-Clustering in der IT seit mindestens 15 Jahren ein Thema ist, erscheint es fast schon gruselig, dass die Entwickler der gängigen Cloudlösungen dieses Thema bisher fast komplett ausgeklammert haben. Gerade ein Service, der vielen Benutzern gleichzeitig eine Dienstleistung verspricht, müsste an dieser Stelle mehr leisten.
Ein wohltuender Lichtblick ist da zweifellos Eucalyptus 3: In der noch dampfenden neuen Release der ehemaligen Ubuntu-Standardcloud haben die Entwickler das Thema Hochverfügbarkeit tief verankert. Mit Eucalyptus 3 schlafen Admins besser, denn selbst wenn einer von den diversen Knoten einer Cloud mal den Geist aufgibt, kümmert sich die Eucalyptus-3-Zentrale darum, dass die fehlenden Dienste woanders ins Leben zurückgeholt werden.
Wer auf Open Stack oder Eucalyptus 2 festgenagelt ist, muss sich seine Hochverfügbarkeit auf Umwegen gewährleisten.
Ohne GUIs: Der Eigenbau
Die Eigenbau-Cloud bietet gerade im Hinblick auf Automatisierung gegenüber den Clouds von der Stange gewichtige Vorteile. Im Gegenzug müssen Admins auf praktische Frontends für Ressourcen-Nutzung, -Verwaltung und -Verrechnung verzichten. Wer die Dienste seiner Cloud nicht an etliche Endkunden durchreicht und auf buchhalterische Features verzichten kann, sollte die Cloud auf Grundlage des Linux-HA-Clusterstacks aber zumindest in seine Überlegungen mit einbeziehen. Wer mehr will, greift derzeit am Besten zu Open QRM.
Infos
- Charly Kühnast, Marcel Schynowski, Markus Feilner, Norbert Graf, “Wählerischer Platzhirsch”: Linux-Magazin 08/10, S. 70
- Open Stack: http://www.openstack.org
- Stefan Seyfried und Christian Behrendt, “Cactus im Anmarsch”: Linux-Magazin 05/11, S. 72, https://www.linux-magazin.de/Heft-Abo/Ausgaben/2011/05/Open-Stack
- Eucalyptus Community: http://open.eucalyptus.com
- Christian Baumann, André Nähring, “Zuverlässiger Antrieb”: Linux-Magazin 07/11, S. 40
- Open QRM: http://www.openqrm.org
- Markus Klimke, “Rollenspiele”: Linux Technical Review 04, S. 90
- Rackspace: http://www.rackspace.com
- Markus Feilner, “Wolkenkratzer”: Linux-Magazin 05/10, S. 40
- Eucalyptus 3: http://www.eucalyptus.com/products/eee
- Amazon EC2: http://www.amazon.com/ec2
- Eucalytus Walrus: http://open.eucalyptus.com/wiki/EucalyptusWalrusInteracting_v1.6
- Eucalyptus-CEO Mickos im Interview: http://infochachkie.com/marten-mickos/
- IPMI Details von Intel:http://www.intel.com/design/servers/ipmi/
- Michael Lorenz, “Canale Grande”: Linux-Magazin 05/09, S. 52
- DRBD: http://www.drbd.org
- LCMC: http://lcmc.sf.net
- Pacemaker: http://www.clusterlabs.org
- Martin Loschwitz, “Der Cluster-Leitstand”: Admin-Magazin 04/2011, S. 68
- Martin Loschwitz, “Eigene Clouds”: Admin-Magazin 05/2011, S. 98
Der Autor

Martin Gerhard Loschwitz arbeitet als Principal Consultant bei der Firma hastexo. Er beschäftigt sich dort intensiv mit Hochverfügbarkeitslösungen und pflegt in seiner Freizeit den Linux-Cluster-Stack für Debian GNU/Linux.





