
© Gunnar Pippel, 123RF
Gibt es kein API für das Einsammeln von Webinformationen, hilft oft Perl mit der Brechstange des Screenscraping. Seit Neuestem überwindet es dabei sogar die Hürde Javascript.
Nicht weniger als drei ehrwürdige Linksys-Router schaufeln die Ethernet-Pakete im Wohnbereich der Perlmeister-Labs umher. Auf allen dreien tut die Tomato-Firmware [2] seit Jahren ohne jeglichen Störfall ihren Dienst. Da Tomatos Admin-Webseite nicht nur allerlei nützliche Einstellungen erlaubt (Abbildung 1), sondern darüber hinaus noch informative Statusdaten anzeigt, lag es nahe, einen Screenscraper zu schreiben, um die Daten in regelmäßigen Abständen auf den PC zu holen, in einer Datenbank zu speichern und bei auffälligen Ausreißern Alarm auszulösen.
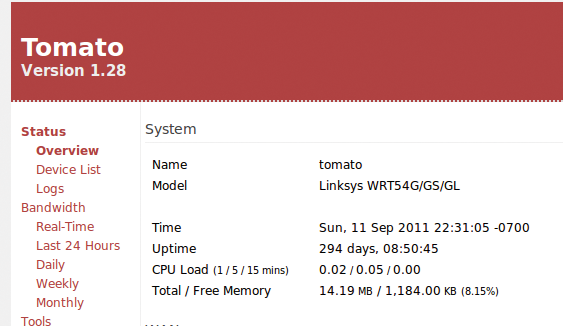
Abbildung 1: Tomatos Übersichtsseite listet unter anderem die Uptime des Routers in Tagen und Stunden auf.
Aua, Javascript!
Der erste Versuch allerdings ging daneben: Beim Einholen der mit Basic Auth gesicherten Seite via »wget http://root:Passwort@192.162.0.1« zeigte sich, dass Tomato die Felder der Anzeige mittels Javascript auffrischt und einfache Webscraper wie das Perl-Modul WWW::Mechanize statt der begehrten Uptime-Zeit lediglich Javascript-Code runterladen (Abbildung 2).

Abbildung 2: Durch einfaches Einholen der Webseite lässt sich der Uptime-Wert nicht extrahieren.
Damit die Seite die Daten richtig anzeigt, muss auf Client-Seite eine Javascript-Engine anlaufen, die den Code interpretiert und gemäß den darin enthaltenen Anweisungen das DOM (Document Object Model) der im Browser dargestellten Seite auffrischt. Einfache Screenscraper tun das nicht, sondern verhalten sich wie Browser mit abgeschaltetem Javascript und erhalten daher nicht das eigentlich gewünschte Ergebnis.
Das siebte Weltwunder
Die herkulische Aufgabe, diese Browseraktionen in Perl zu implementieren, hat das CPAN-Modul WWW::Scripter erledigt. Zusammen mit dem Plugin WWW::Scripter::Plugin::Ajax für Serverrückrufe, der DOM-Schnittstelle HTML::DOM und der Pure-Perl-ECMA-Skript-(Javascript)-Engine JE stellt es alle notwendigen Funktionen bereit.
Wenn man darüber nachdenkt, wie viele DOM-spezifische Unterschiede bei Browsern es allein zwischen dem Internet Explorer und Firefox gibt, dann lässt sich erahnen, wie viel Arbeit in den Modulen steckt. Außerdem verhält sich das Modul wie ein weiterer Browser, Unterschiede zwischen seiner Implementierung und dem sonst verwendeten Desktopbrowser sind unvermeidlich. Eine weitere Möglichkeit, einen Javascript-gesteuerten Skriptclient zu implementieren, wäre der Einsatz einer Browser-Fernsteuerung wie Selenium [3].
Listing 1 zieht zunächst WWW::Scripter herein und lädt das separat erhältliche Ajax-Plugin mit der Methode »use_plugin()« . Die Klasse ist von WWW::Mechanize und damit auch von LWP::UserAgent abgeleitet und unterstützt demnach die Methode »get()« zum Einholen von Webseiten. Da der Router beim HTTP-Zugang nach einem Passwort für den Rootaccount fragt, stellt das Skript dieses mittels der ebenfalls ererbten Methode »credentials()« zur Verfügung.
Listing 1
tomato-overview
01 #!/usr/local/bin/perl -w
02 use strict;
03 use WWW::Scripter;
04 use Sysadm::Install qw(:all);
05 use HTML::TreeBuilder::XPath;
06
07 my $w = WWW::Scripter->new();
08 $w->use_plugin('Ajax');
09
10 my $pw = slurp "pw.txt";
11 chomp $pw;
12 $w->credentials( "root", $pw );
13 $w->get('http://192.168.0.1');
14
15 $w->wait_for_timers( max_wait => 1 );
16
17 my $tree= HTML::TreeBuilder::XPath->new();
18 $tree->parse( $w->content() );
19 my $uptime =
20 $tree->findvalue(
21 '/html/body//tr[@id="uptime"]/' .
22 'td[@class="content"]');
23
24 print "uptime: $uptime\n";
Damit das Passwort nicht hart im Skript kodiert ist, liest es die Funktion »slurp()« aus der Datei »pw.txt« im aktuellen Verzeichnis ein. Die Datei enthält nur eine Zeile mit dem Passwort und sollte gegen unberechtigte Lese- oder gar Schreibzugriffe geschützt sein. Ganz astrein ist diese Lösung freilich nicht, doch irgendwie muss ich den Schlüssel unter der Fußmatte verstecken, wenn das Skript automatisch laufen soll und der User nicht jedes Mal das Passwort tippen kann.
Maschine läuft an
Holt »get()« die Seite vom Webinterface des Routers, enthält diese noch keine Daten, sondern nur den eingebetteten Javascript-Code. Der Aufruf »wait_for_timers()« startet nun die Javascript-Engine und lässt ihn auf dem Seiteninhalt herumfuhrwerken.
Die Methode würde nun so lange blocken, bis auch der letzte Javascript-Timer im Code aufgehört hätte zu laufen, was aber bei vielen Webseiten einfach unendlich lange dauern würde. Der Parameter »max_wait« gibt deshalb vor, nicht länger als eine Sekunde zu warten. Diese Zeitspanne reicht auf Router-Seite erfahrungsgemäß, um die dynamischen Felder zu befüllen. Ein anschließender Aufruf von »content()« gibt das mit den Daten aufgefrischte HTML zurück.
Den HTML-Salat entwirren
Wie in Abbildung 3 ersichtlich, steht der gesuchte Uptime-Wert in einem Wirrwarr von HTML-Tags und man könnte ihn entweder mit regulären Ausdrücken oder einem HTML-Parser herausfieseln. Listing 1 wählt mit dem Xpath-Parser HTML::TreeBuilder::XPath vom CPAN die wohl bequemste Methode. Der Pfadausdruck in Zeile 21 steigt in der Hierarchie des HTML-Dokuments erst zum Body-Tag herunter und sucht dann wegen des doppelten Schrägstrichs in beliebigen Tiefen nach den weiter rechts spezifizierten Tags. Zum Ziel führt schließlich ein TR-Tag mit dem »Id« -Attribut »uptime« , das ein TD-Tag mit dem »class« -Attribut »content« einschließt, wie Abbildung 3 zeigt. Die Methode »findvalue()« fördert den darin begrabenen Text zutage, es bleibt dem Skript nur noch, den gefundenen Wert auf der Standardausgabe auszugeben.
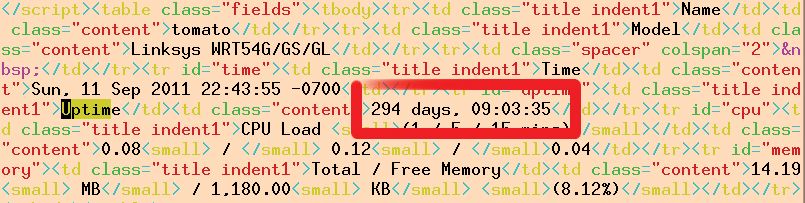
Abbildung 3: Die Javascript-Engine hat die hier hervorgehobenen Uptime-Daten eingefüllt, nachdem sie das Modul WWW::Scripter ausgeführt hat.
Eine etwas dynamischere Aufgabe erzeugt die Tomato-Admin-Seite mit den aktuell verbrauchten Bandbreitenwerten. Unter dem Pfad »/bwm-realtime.asp« der Router-URL erscheint der Graph in Abbildung 4, der eine mittels Javascript erstellte Grafik mit den Schwankungen während der letzten 24 Stunden darstellt. In der Tabelle darunter stehen die aktuellen Werte für empfangene Daten (RX für received) in KBit/s sowie gesendete Daten (TX für transmitted). Neben dem zuerst angezeigten, aktuell gemessenen Wert listet Tomato hier Maximalwerte (Peak) und Durchschnittswerte (Avg) auf sowie die Summe transferierter Bits seit dem Start der Messung, die beim Aufruf der Seite beginnt.
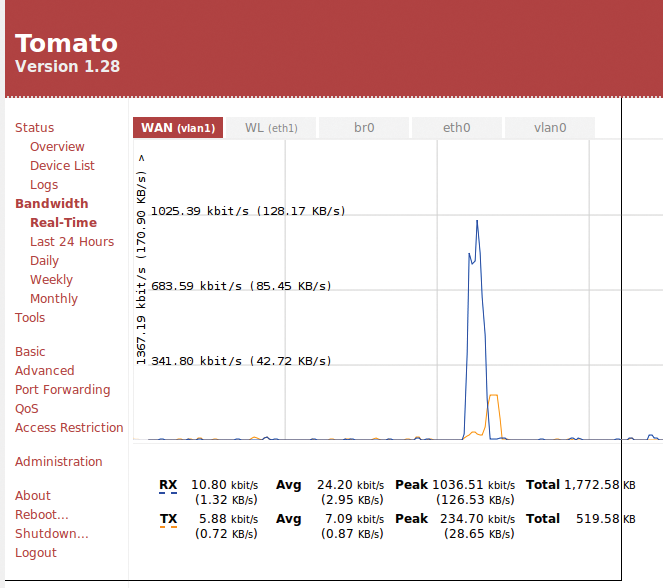
Abbildung 4: Der Tomato-Router frischt die aktuellen Bandbreitenwerte regelmäßig mit Javascript auf.
Beim ersten Laden der Seite stehen alle Werte auf null und erst nach einigen Sekunden füllen sich die Tabellenreihen mit interessanten Werten. Listing 2 wartet aus diesem Grund in der Funktion »rounds()« beim ersten Aufruf in Zeile 18 geschlagene fünf Testdurchläufe ab, während es jeweils den Scripter mit der Methode »check_timers()« dazu auffordert, die Timer im Javascript-Code laufen zu lassen. Anschließend legt es in Zeile 28 jedes Mal eine Sekunde Verschnaufpause ein. Nach Ablauf aller vorgeschriebenen Runden startet Zeile 31 den der Funktion »rounds()« beim Aufruf hereingereichten Callback, was während der Proberunden aus Zeile 18 eine leere Funktionshülse ist, im Realbetrieb ab Zeile 19 aber die ab Zeile 35 definierte Funktion »extract_bandwidth« .
Listing 2
tomato-bandwidth
1 #!/usr/local/bin/perl -w
02 use strict;
03 use Sysadm::Install qw(:all);
04 use WWW::Scripter;
05 use HTML::TableExtract;
06 use YAML qw(Dump);
07
08 my $w = new WWW::Scripter;
09 $w->use_plugin('Ajax');
10
11 my $pw = slurp "pw.txt";
12 chomp $pw;
13
14 $w->credentials( "root", $pw );
15 $w->get(
16 'http://192.168.0.1/bwm-realtime.asp');
17
18 rounds( $w, 5, sub { } );
19 rounds( $w, 1, \&extract_bandwidth );
20
21 ###########################################
22 sub rounds {
23 ###########################################
24 my( $w, $rounds, $callback ) = @_;
25
26 for( 1 .. $rounds ) {
27 $w->check_timers();
28 sleep( 1 );
29 }
30
31 $callback->( $w->content );
32 }
33
34 ###########################################
35 sub extract_bandwidth {
36 ###########################################
37 my( $html ) = @_;
38
39 my $te = HTML::TableExtract->new( );
40 $te->parse( $html );
41
42 my $ts = $te->first_table_found();
43
44 my %bw = ();
45
46 foreach my $row ($ts->rows) {
47 my @cols = map { /(\S+)/ } @$row;
48
49 $bw{ $cols[0] } =
50 { avg => $cols[3],
51 peak => $cols[5],
52 };
53 }
54
55 print Dump( \%bw );
56 }
Als Parser für die in HTML-Tabellen versteckte Information nutzt das Skript das CPAN-Modul HTML::TableExtract. Dessen Methode »parse()« nimmt in Zeile 40 den von Javascript vorher modifizierten HTML-Code der Seite entgegen und formt einen Syntaxbaum daraus. Die Methode »first_table_found()« sucht dann die erste HTML-Tabelle, die auf Tomatos Bandwidth-Seite tatsächlich die gesuchten Daten enthält.
In der Testphase, während der der Entwickler noch nicht weiß, welche Tabelle welche Informationen enthält, hilft die Methode »tables()« desselben Moduls, das alle gefundenen Tabellen als Objekte zurückgibt. Deren Lage und hierarchische Verschachtelung gibt »coords()« an, ihren Inhalt schüttet »rows()« zeilenweise aus. Die Manualseite erklärt die Verwendung ausführlich.
Tomato zeigt die Werte in KBit/s an, fügt aber auch noch einen Wert Kilobyte pro Sekunde hinzu. Da sich beide jedoch lediglich um einen konstanten Faktor unterscheiden, filtert der reguläre Ausdruck in der Map-Anweisung in Zeile 47 letzteren Wert aus, indem er alles nach dem ersten Leerzeichen abschneidet. Die erste Spalte in »@cols« ist so entweder »RX« oder »TX« , gefolgt vom aktuellen Transferwert.
In der vierten und sechsten Spalte (Arrayindex 3 und 5 im Skript) stehen die Werte für die durchschnittliche Bandbreite und die der Spitzenwerte. Zeile 49 schiebt sie als Hash mit den Schlüsseln »avg« und »peak« in einen weiteren Hash unter die Schlüssel »RX« respektive »TX« . Damit sich die Ausgabe des Skripts maschinell leicht verarbeiten lässt, druckt Zeile 55 den resultierenden Hash mit Hilfe der Methode »Dump()« des YAML-Moduls aus.
Installation
Die dynamischen Greiferskripte benötigen außer dem Webscraper WWW ::Mechanize auch noch die CPAN-Module WWW::Scripter und WWW:: Scripter::Plugin::Ajax, die sich zum Beispiel unter Ubuntu mit einer CPAN-Shell installieren lassen. Den in Listing 1 verwendeten Xpath-Parser HTML::TreeBuilder::XPath und den Tabellenparser HTML::TableExtract aus Listing 2 gibt es auch auf dem CPAN.
Die im Artikel gezeigten Tricks lassen sich aber auch auf allerlei andere interessante Seiten anwenden. Der engagierte Scraper-Hacker muss lediglich darauf achten, dass sein Datenstaubsauger nicht gegen die Terms of Service der Anbieter verstößt. (jcb)
Online PLUS
In einem Screencast demonstriert Michael Schilli das Beispiel: https://www.linux-magazin.de/plus/2011/11
Infos
- Listings zu diesem Artikel: ftp://www.linux-magazin.de/pub/listings/magazin/2011/11/Perl
- Tomato-Firmware für Linksys-Router: http://www.polarcloud.com/tomato
- Michael Schilli, “Browser ferngesteuert”: Linux-Magazin 10/06, S. 118, https://www.linux-magazin.de/Heft-Abo/Ausgaben/2006/10/Browser-ferngesteuert
Der Autor

Michael Schilli arbeitet als Software-Engineer bei Yahoo in Sunnyvale, Kalifornien. Er hat “Goto Perl 5” (auf Deutsch) und “Perl Power” (auf Englisch) für Addison-Wesley geschrieben und ist unter mailto:mschilli@perlmeister.com zu erreichen. Seine Homepage ist http://perlmeister.com.





