
Shariff_Che'Lah, Fotolia.de
Oft ist nicht nur [www.lieschen-mueller.de] nicht erreichbar, wenn der Webserver ausfällt, sondern es entstehen empfindliche wirtschaftliche Schäden: Einem Shop entgehen Umsätze, einer Business-Applikation fehlt die Bedienoberfläche. Entsprechend dringlich ist es, Apache & Co. vor Ausfällen zu bewahren.
Ein Patentrezept für den hoch verfügbaren Webserver gibt es nicht, zu unterschiedlich sind Art und Umfang seiner Aufgaben. Mal geht es um wenige statische Seiten, mal um dynamischen Content, an dem auch Datenbanken und Applikationsserver beteiligt sind. Mal dreht es sich um wenige Zugriffe, mal um Zigtausende, mal spielen spezielle Sicherheitsbedürfnisse eine Rolle, mal ist der Status einer Session zu erhalten.
Dazu kommt: Bei manchen Angeboten fällt ein Crash kaum ins Gewicht, bei anderen drohen hohe Schäden – je nachdem fällt das Budget für Verfügbarkeit aus. In all diesen Fälle bieten sich Lösungen an: Zwar sind es nicht immer die gleichen, aber es lassen sich Klassen bilden.
Standby-Server
Die einfachste Variante ist wohl ein Standby-Server, der entweder ausgeschaltet auf seinen Einsatz wartet (Cold Standby, Abbildung 1) oder sich die Zeit bis dahin mit anderen Aufgaben vertreibt, also auch nicht extra booten muss, um einzuspringen (Hot Standby). Bei einem Cold-Standby-System benutzen beide Server nacheinander die gleiche IP-Adresse, beim Hot Standby muss ein Skript das Netzwerkinterface neu konfigurieren, um im Einsatzfall auf der überlebenden Maschine mindestens die virtuelle, so genannte Service-Adresse zu ergänzen, unter der die Benutzer den Webserver erreichen.
Ein zweites Problem ergibt sich daraus, dass beide Server dieselben Daten anbieten sollen. Die müssen deswegen auf einem Shared Storage liegen (SCSI, Fibre Channel, I-SCSI oder Ähnliches). Solange man auf diesem Storage kein Cluster-Filesystem wie GPFS [1] oder OCFS [2] verwendet, können Server und Ersatzsystem nur strikt nacheinander auf den Plattenspeicher zugreifen, ihn aber immerhin beide von Anfang an mounten.
Eine weitere Alternative ergibt sich, wenn der Admin die Disks stattdessen repliziert – dafür eignet sich etwa DRDB [3]. Dann hat jedes System seine eigene Instanz im exklusiven Zugriff.
Schon bei einem simplen Standby-System kann man darüber hinaus intern mit einfachen Mitteln für noch mehr Redundanz sorgen, um möglichen Hardware-Ausfällen vorzubeugen. Dazu zählen etwa das Bonding von Netzwerkinterfaces [4], ein redundantes Netzteil oder eine unterbrechungsfreie Stromversorgung (USV) sowie eine Raid-Konfiguration auf dem Storage-System.
Hat man diese beiden Punkte – IP-Adressen und Daten – im Blick, dann funktioniert das Standby-Konzept, bleibt aber mit einigen Einschränkungen behaftet, die es nicht für jeden Einsatzfall empfehlen. So erkennt es einen Ausfall nicht automatisch, der Admin muss daher das Problem zunächst selbst bemerken und dann das Ersatzsystem manuell aktivieren, was viel Zeit kosten kann.
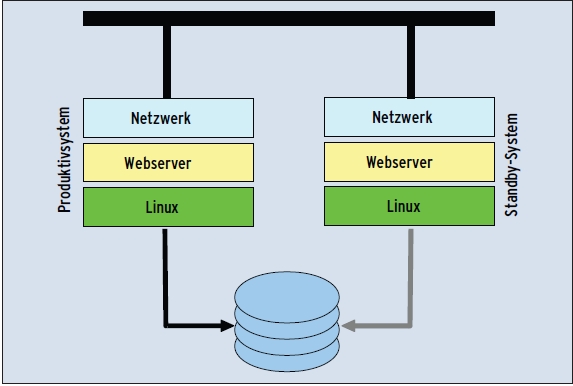
Abbildung 1: Der Standby-Server wird manuell aktiviert, falls das Produktivsystem ausfällt. In einfachen Fällen erhöht diese simple Konstruktion die Verfügbarkeit bereits hinreichend.
Im Fall eines Cold Standby nimmt der Betreiber außerdem in Kauf, dass die Hälfte seiner Hardware die meiste Zeit über unproduktiv herumsteht. Schließlich lassen sich andere, oft unverzichtbare Komponenten – etwa Middleware wie Datenbanken oder Applikationsserver – nach diesem Konzept nur dann absichern, wenn sie auf derselben Hardware laufen wie der Webserver, was allein aus Performancegründen oft unmöglich ist.
Einfaches Failover
Einige dieser Nachteile vermeidet bereits die nächste Ausbaustufe, der einfache Failover-Cluster (Abbildung 2), wie man ihn beispielsweise bereits mit Linux-HA (Version 1) etwa seit der Jahrtausendwende einrichten kann.
Er geht in zweierlei Hinsicht deutlich über das Standby-Konzept hinaus: Erstens verwendet er einen Heartbeat, also eine Art Lebenszeichen, um einen Systemausfall selbstständig zu detektieren, zweitens regelt er den Zugriff auf den Shared Storage durch so genanntes Fencing automatisch, sodass es hier nicht zu Konflikten kommt. Gewinnt ein Clusterknoten den Eindruck, dass sein Gegenüber wider Erwarten doch noch lebt, während er sich selbst für die Ressourcen verantwortlich fühlt (Split Brain), schießt er ihn mit einer speziellen Technik ab (Stonith, Shoot the other node in the head).
Lebenszeichen auf Applikationsebene sind bei dieser Version jedoch erst in Ansätzen vorhanden. Im Wesentlichen hört jeder Knoten den Herzschlag seines Gegenüber ab. Bleibt der aus, geht der überlebende Knoten vom Hinscheiden des Partners aus und startet seinerseits die zuvor von ihm angebotenen Ressourcen. Dazu zählt auch die virtuelle IP-Adresse, die im Zuge eines Failover nun auf den verbleibenden Knoten umzieht, damit sich aus der Perspektive der Clients nichts an der Erreichbarkeit ändert.
Beim Starten und Stoppen der verschiedenen Dienste kann die erste Linux-HA-Version in vielen Fällen auf die vorhandenen Init-Skripte zurückgreifen. Überhaupt kommt sie mit lediglich drei Konfigurationsdateien in Textform aus, wodurch sich der nötige Administrationsaufwand stark vermindert.
Die größte Beschränkung dieses Konzepts liegt darin, dass es immer nur zwei Knoten bedienen kann. Müssen die Komponenten einer Applikation mehr als zwei Server benutzen, scheidet der Ansatz von vornherein aus.
Ausgebauter HA-Cluster
Mit Linux-HA in Version 2 (ab 2005, [5]) fiel die Zwei-Knoten-Grenze: Jetzt sind 16 Knoten integrierbar und alle beteiligten Dienste lassen sich unabhängig voneinander überwachen und sichern (Abbildung 3). Das Verhalten im Fehlerfall steuert ein raffiniertes Regelwerk, mit dem sich vorgeben lässt, auf welchen Knoten ein Dienst umziehen soll.
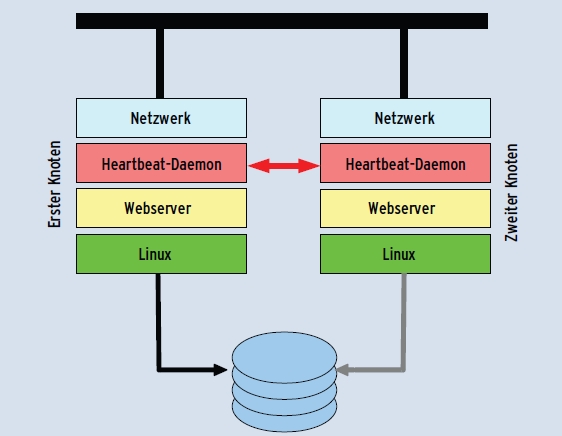
Abbildung 2: Ein einfacher Failover-Cluster detektiert Ausfälle automatisch und regelt den Zugriff auf den Shared Storage via Fencing. Im Ernstfall zieht er sogar die Notbremse und schießt den zweiten Knoten ab.
So kann der Admin beispielsweise vorgeben, dass der Webserver auf einen Knoten wandern soll, auf dem nicht bereits ein Webserver läuft (um Portkonflikte zu vermeiden) und der zusätzlich mit keiner höheren Last als einem Load Average von 2,5 belegt sein darf. Der Applikationsserver soll dagegen auf jenen Knoten umziehen, auf den die Datenbank bereits gewandert ist, was aber in keinem Fall ein Webserver sein darf und so weiter. Mit Hilfe eines Punktesystems ermittelt der Cluster automatisch die Konfiguration, die eine größtmögliche Übereinstimmung mit den vorgegebenen Regeln gewährleistet.
Der Preis für all dies ist eine wesentlich komplexere Architektur und Konfiguration. Zentrale Instanz ist jetzt ein Cluster Resource Manager (CRM), der Heartbeat-Dienst ist nunmehr alleine für die Kommunikation der Knoten zuständig und ein separater Cluster Consensus Membership Service (CCM) verwaltet Zugehörigkeit und Status von Clusterknoten. Ressourcen lassen sich jetzt gruppieren, klonen und manuell zwischen den Knoten verschieben.
Nach Querelen im HA-Projekt scheint sich gegenwärtig eine Konfiguration durchzusetzen, die Pacemaker [6] als Resource Manager und Open AIS [7] statt Heartbeat für die Kommunikation der Knoten verwendet. Dazu kommt ein Distributed Lock Manager (DLM) der den Zugriff auf den Shared Storage managt. Auf ihn verlassen sich auch Cluster-Filesysteme wie GFS [8] oder OCFS2.
Kommerzielle Konkurrenz
Alternativ zu Linux-HA (Version 2) stehen unter Linux auch einige kommerzielle Cluster-Suiten bereit. Dazu gehört beispielsweise der Veritas Cluster Server ([9], für RHEL 4 und 5, SLES 9 und 10 sowie Oracle Enterprise Linux 4), mit dem sich im Unterschied zu Linux-HA auch Crossplattform-Cluster aufbauen lassen, die Solaris-, AIX- oder HP-UX-Nodes einbeziehen. Außerdem kann man hier fertige Resource Agents für die Überwachung gängiger Business-Applikationen und Datenbanken erwerben (natürlich auch für Webserver).
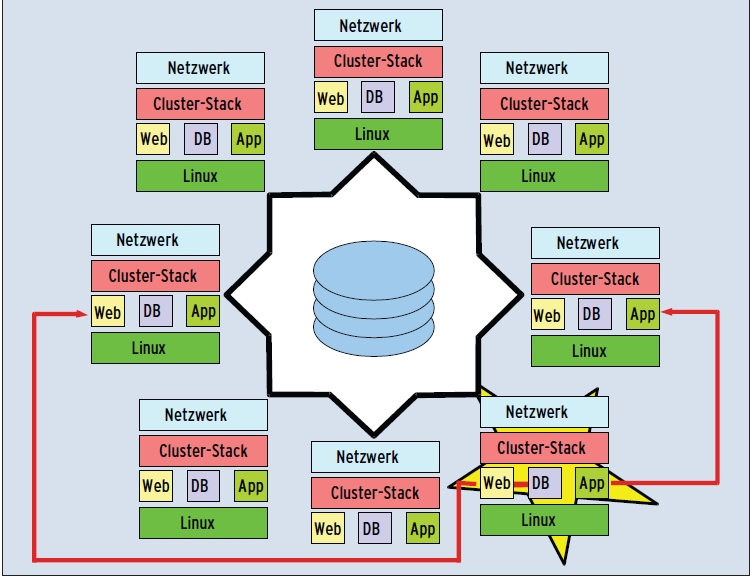
Abbildung 4: Auch ein Load Balancer kann für die nötige Redundanz sorgen und ist das Mittel der Wahl, wenn aus Performancegründen ohnehin eine Lastverteilung nötig ist.
Eine weitere Möglichkeit bietet der Lifekeeper-Cluster der Firma Steeleye [10]. Er unterstützt RHEL, SLES und Centos, kommt mit bis zu 32 Knoten klar und erleichtert die Konfiguration ebenfalls durch vorbereitete Module – darunter für Apache, etliche Datenbanken, Applikationsserver und so weiter.
Load Balancer
Eine Webserver-Farm mit Hunderten einzelner Server ließe sich allerdings kaum mit einem Failover-Cluster absichern – und das ist auch gar nicht nötig. Weiß der vorgeschaltete Load Balancer (Abbildung 4) nämlich, dass er einen bestimmten Knoten nicht mehr mit Aufträgen versorgen soll, ist eigentlich alles erledigt. Die Masse der restlichen Server in der Farm fängt den Ausfall ab und der Admin kann das Gerät später ersetzen.
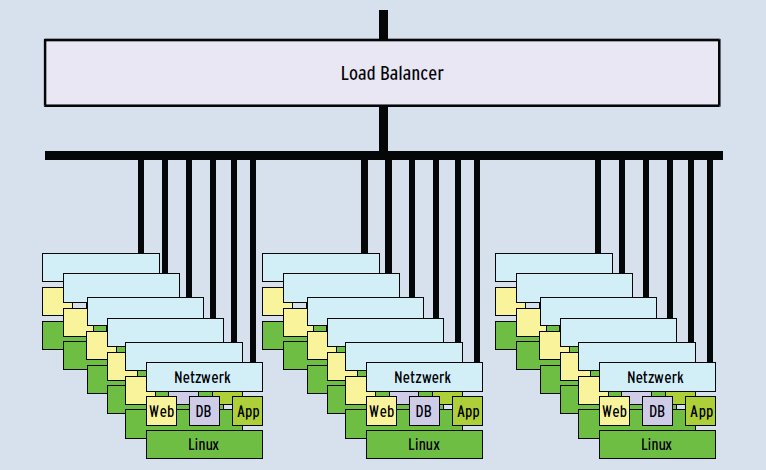
Abbildung 3: Ein ausgebauter Failover-Cluster – beispielsweise mit Linux-HA, Version 2, oder einer kommerziellen Software – bedient ein Dutzend Knoten oder mehr und verteilt ausgefallene Services im Cluster auf der Grundlage eines Regelwerks neu.
Die klassische Linux-Software für ein solches Szenario ist der Linux Virtual Server (LVS, [11]). Er beherrscht eine ganze Palette an Verteilstrategien auf den OSI-Layern 3 und 4 und bietet auch persistente Verbindungen. Ein recht einfaches Load Balancing lässt sich alternativ bereits durch eine geschickte DNS-Konfiguration erreichen: Ordnet der Admin hier einem Namen mehrere IP-Adressen zu (Resource Record Set) erhält er eine gleichmäßige Lastverteilung.
Wer dagegen von den Vorteilen der Layer-7-Lastverteilung profitieren möchte, die beispielsweise spezialisierte Webserver für Skripte, statische Seiten oder Bilder möglich macht, der greift zu Produkten wie Pound [12] oder XLB [13], die allerdings deutlich mehr Rechenpower verschlingen. Der große Vorteil der letztgenannten HA-Lösungen besteht darin, dass die hohe Verfügbarkeit quasi ein Seiteneffekt des in diesem Fall ohnehin nötigen Load Balancing ist.
Fazit
So oder so nützt es im Ernstfall freilich wenig, wenn zwar der Webserver geclustert ist, andere Infrastruktur-Komponenten aber Single Points of Failure darstellen – etwa Router, Switches oder die Internetanbindung. Andererseits: Ein Szenario, das fehlertolerant die meisten denkbaren Ausfälle abfängt, ist zwar möglich, aber auch sehr teuer. In der Regel diktiert hier das Primat der Ökonomie die Lösung des Problems: Die Versicherung sollte keinesfalls teurer sein als der im schlimmsten Fall eintretende Schaden.
|
Infos |
|---|
|
[1] GPFS: [http://www-03.ibm.com/systems/clusters/software/gpfs/index.html] [2] OCFS: [http://oss.oracle.com/projects/ocfs/] [3] DRDB: [http://www.drbd.org] [4] Bonding Driver Howto: [http://www.cyberciti.biz/howto/question/static/linux-ethernet-bonding-driver-howto.php] [5] Linux-HA 2: [http://www.linux-ha.org] [6] Pacemaker: [http://www.clusterlabs.org/wiki/Main_Page] [7] Open AIS: [http://www.openais.org/doku.php] [8] GFS: [http://sources.redhat.com/cluster/gfs/] [9] Veritas Cluster Server: [http://www.symantec.com/business/cluster-server] [10] Lifekeeper: [http://www.steeleye.com/downloads/resource/linux/lifekeeper-for-linux.pdf] [11] Linux Virtual Server: [http://www.linuxvirtualserver.org] [12] Pound:[http://www.apsis.ch/pound/index_html] [13] XLB: [http://sourceforge.net/projects/xlb/] |





