
© royalmg, Photocase.com
Samba ist seit der Version 3.3 zusammen mit dem Lock-Manager CTDB erstmals vollumfänglich als Active-Active-Cluster konfigurierbar. Mit der neuen Registry-Konfiguration kann der Admin den Samba-Cluster mit einem lockeren Hüftschwung verwalten.
Die Open-Source-Software Samba [1] stellt seit 1992 auf Linux und anderen Unix-Plattformen Datei- und Druck-Dienste für Windows-Clients zur Verfügung. In dem Bemühen, möglichst viele Eigenschaften von Windows-Servern genau nachzubilden, hinken die Samba-Entwickler [2] naturgemäß hinter dem beweglichen Ziel, Microsofts Entwicklung, her. Dass Microsoft Ende 2007 die Spezifikationen der Serverprotokolle offengelegt hat [3], vereinfacht die Lage zum Glück etwas.
Der Verfolgte wird zum Verfolger
In den letzten zwei Jahren ist jedoch etwas Unerhörtes geschehen: Mit Hilfe der Zusatzsoftware CTDB [4] implementiert Samba ein Feature, das Windows offenbar nicht bietet: Es kann als geclusterter Fileserver arbeiten. Das heißt, Samba bietet ein verteiltes Dateisystem von mehreren Clusterknoten nach außen wie einen einziger CIFS-Server konsistent und performant an. Dabei skaliert der Cluster fast beliebig mit der Zahl der Knoten. Zwar bietet auch Windows 2003 Clustering; es zielt aber vor allem auf Web- und Datenbankserver ab und ist auf acht Knoten beschränkt. Ein Fileserver-Cluster, der frei skaliert, ist mit Microsofts Bordmitteln nicht realisierbar.
Die Software CTDB debütierte im Frühjahr 2007, die CTDB-Anbindung in Samba war bis vor Kurzem aber nur als speziell angepasste Version 3.0.25-ctdb zu haben. Mit Version 3.2.0 hielt der Clustercode im Juli 2008 Einzug in Sambas Standard-Distribution – wenn auch nicht ganz vollständig. Aber Samba 3.3.0, das in diesem Januar erschienen ist, ist nun komplett clusterfähig.
Des Clusters Kern
Der folgende Artikel erläutert die Probleme, die Samba im Cluster löst, geht kurz auf die Entstehung und das Design von CTDB ein und beschreibt schließlich die Konfiguration von CTDB und geclustertem Samba, insbesondere aber Sambas neue Registry-basierte Konfiguration.
Es gibt mehrere Formen des Clustering: Rechen- oder Performance-Cluster, High-Availability-, Loadbalancing-Cluster und diverse Mischformen. Dieser Artikel dreht sich um einen geclusterten oder verteilten Samba-Server, also um einen Verbund mehrerer Rechner (Knoten), die ein gemeinsames verteiltes Dateisystem verwenden.
Auf jedem Knoten läuft Samba und alle Samba-Instanzen erscheinen für den Client wie ein einziger (!) Samba-Server. Die Samba-Instanzen sind identisch konfiguriert und bieten die gleichen Dateibereiche aus dem gemeinsamen Dateisystem als Freigabe an. Bei dem CTDB-Konzept handelt es sich also im Wesentlichen um einen Loadbalancing-Cluster (Activ-Activ-Cluster), angereichert mit High-Availability-Funktionalität.
Als wichtiger Aspekt beim geclusterten Samba-Server gilt seine Skalierbarkeit: Die Anzahl der bewältigten Requests pro Sekunde und die akkumulierten Datendurchsätze sollten je nach Hardware mit der Knotenzahl möglichst linear wachsen. Im Kern geht es darum, aus einem SAN ein geclustertes, hoch verfügbares, skalierendes NAS zu machen.
|
Fleißige |
|---|
|
Eine Entwicklergruppe um Volker Lendecke und Andrew Tridgell (Abbildung 1) implementierte ab 2006 in dem speziellen SVN-Branch »vl-messaging« zunächst einen Message-Dispatcher-Daemon, der auf allen Knoten laufen soll und die Nachrichten verteilt. Außerdem abstrahierten sie im selben Branch Sambas Zugriff auf die TDBs und schufen mit dem Proof of Concept eines zentralen TDB-Daemon eine erste im Cluster skalierende Samba-Version. Nach den Abstraktionsschichten für den TDB-Zugriff erschien im April 2007 die erste CTDB, die das Messaging und die Behandlung der flüchtigen TDB-Datenbanken im Clusterbetrieb beherrscht. Anhand der Vorarbeiten im »vl-messaging«-Zweig ersetzten auf allen Knoten laufende, ihre Datenrecords replizierende CTDB-Daemons den Engpass zentraler TDB-Daemons. Die Handhabung von persistenten TDB-Datenbanken war jedoch nicht implementiert. Diese CTDB-Version arbeitete mit der speziellen Samba-Version 3.0.25-ctdb zusammen. Mittlerweile ist Ronnie Sahlberg der Maintainer des CTDB-Projekts. Sein CTDB-Git-Branch [7] ist der Kristallisationspunkt für den offiziellen CTDB-Code. Neuere CTDB-Versionen unterstützen auch die persistenten TDBs sowie Datenbank-Transaktionen auf dem API-Level, sodass CTDB für alle TDB-Belange einsetzbar ist. Außerdem haben die Entwickler die CTDB um viele Monitoring- und High-Availability-Features ergänzt. Die ganze CTDB-Historie beschreibt das Samba-Wiki [8]. |
Gespaltene Identitäten
Wenn Samba von mehreren Knoten eines Dateisystem-Clusters aus Clients dieselbe Datei zeitgleich anbietet, entstehen prinzipbedingt einige Probleme:
- Das CIFS-Protokoll arbeitet mit ausgefeilten Dateisperren
(Locks): Share Modes, die ganze Dateien exklusiv sperren, und Byte
Range Locks, um Teile einer Datei zu sperren. Diese verpflichtenden
(Mandatory-)Locks der Windows-Welt sind nicht einfach in die
lediglich empfohlenen (Advisory-) Locks der Posix-Welt
übersetzbar [5]. Darum speichert Samba die
CIFS-Locking-Informationen in internen Datenbanken und prüft
sie bei jedem neuen Dateizugriff. Der Cluster muss das Locking
knotenübergreifend konsistent halten, wenn Clients auf
unterschiedliche Knoten zugreifen. - Die verschiedenen Samba-Prozesse schicken einander Nachrichten.
Zum Beispiel kann ein Client einen Lock-Request mit Timeout auf
einen im Moment von einem anderen Client gesperrten Dateibereich
absetzen. Hebt der eine Client dann innerhalb des Timeout die
bestehende Sperre auf, gewährt Samba die neue Sperre und
informiert per Signal den wartenden Zielprozess darüber, dass
eine Nachricht vorliegt. - ID-Mapping-Tabellen, die Windows-Benutzer und -Gruppen den
Unix-Benutzer- und -Gruppen-IDs zuordnen, müssen auf den
Knoten synchron sein, damit Sambas Sicht der Datei-Eigentümer
im Cluster-Dateisystem auf allen Clusterknoten dieselbe ist. - Besitzt ein Server eine eigene Benutzerdatenbank, fällt
Samba die Aufgabe zu, sie clusterweit zu pflegen. - Als Domänen-Mitgliedsserver muss Samba auf allen Knoten
die gleichen Join-Informationen vorhalten, also das Passwort des
Computerkontos und die Domänen-SID. - Die aktiven SMB-Client-Verbindungen und -Sessions auf den
Knoten sollen knotenübergreifend bekannt sein.
Bis auf die Signale, die das Messaging-System neben den Nachrichteninhalten verwendet, um andere Prozesse über das Vorhandensein neuer Nachrichten zu informieren, sind dies alles Informationen, die Samba in seinen internen TDB-Datenbanken ablegt:
- Die Share Modes in der »locking.tdb«
- Die Byte Range Locks in »brlock.tdb«
- Die Nachrichten in »messages.tdb«
- Das ID-Mapping in der »winbindd_idmap.tdb«
- Die Benutzerdatenbank in der »passdb.tdb«, falls
der Parameter »passdb backend = tdbsam« gesetzt
ist - Die Join-Informationen in der
»secrets.tdb«-Datenbank - Die Verbindungen in der »connections.tdb«
- Die Sessions in der »sessionid.tdb«
TDB [6] ist Sambas Trivial Database, eine kleine, schnelle Datenbank ähnlich der Berkeley DB und GNU DBM, die zusätzlich Locking und damit simultanes Schreiben unterstützt. Samba benutzt TDB intern an sehr vielen Stellen, neben den eben genannten Datenbanken beispielsweise für diverse Caches. Falls möglich verwendet Samba den Memory-Mapping-Mechanismus »mmap()«, um Bereiche der TDBs direkt in den Hauptspeicher einzublenden – so fungieren TDBs als schneller gemeinsamer Speicher.

Abbildung 1: Samba-Entwickler 2007 zu Gast bei Google (vorne rechts der Autor des Artikels). Ein Team um Volker Lendecke (Mitte hinten mit schwarzem Shirt) und Andrew Tridgell (ganz links, mittlere Reihe) entwickelt seit 2006 den Clustercode von Samba.
Performance wichtig
Die verwendeten Datenbanken sind durchaus unterschiedlicher Natur: Datenbanken für Locking, Messaging, Verbindungen und Sessions beherbergen nur Daten kurzer Lebensdauer, die Samba aber häufig schreibt und liest. Die anderen Datenbanken enthalten nicht-flüchtige Informationen, deren Überleben über Restarts hinaus wichtig ist. Auf sie greift Samba nur selten schreibend, umso öfter aber lesend zu. Für diese persistenten Datenbanken gelten somit höhere Anforderungen an die Datenintegrität als für die flüchtigen. Andererseits sind die flüchtigen Datenbanken deutlich Performance-kritischer als die persistenten.
Der naive Ansatz, alle Datenbanken in das Cluster-Dateisystem zu legen, funktioniert zwar im Prinzip, nicht aber in der Praxis. TDB arbeitet nämlich beim Locking der Datenbank-Records exzessiv mit Posix-»fcntl()«-Byte-Range-Locks [5]. Die sind auf Cluster-Dateisystemen nicht nur langsam, sondern skalieren vor allem schlecht bis negativ mit der Anzahl der Knoten. Die TDBs ins Cluster-Dateisystem zu legen bedeutet zudem, in der Regel auf das schnelle Memory-Mapping verzichten zu müssen.
Als Hauptaufgabe beim Samba-Clustering erweist sich also das Implementieren einer skalierenden Clustervariante der TDB-Datenbank. Außerdem muss man das Messaging so erweitern, dass es Signale auch an Prozesse entfernter Knoten zu schicken vermag. CTDB (Clustered TDB), Sambas performante Cluster-Implementation der TDB, löst genau diese Probleme. Der Kasten “Fleißige Entwickler” skizziert die Projektgeschichte.
Dateisystem als Black Box
Wer CTDB einsetzt, braucht ein Cluster-Dateisystem, das auf allen Knoten gemounted ist, Posix-»fcntl()«-Locking-Semantik anbietet und seine Locks knotenübergreifend konsistent hält. Dabei spielt es keine Rolle, um welches Dateisystem genau es sich handelt und ob der Speicherplatz per Fibre Channel aus einem SAN kommt, aus einem per I-SCSI angebundenen Storage-Knoten oder sogar aus lokalen Plattenpartitionen. CTDB ist glücklich, solange es auf allen Knoten das gleiche Dateisystem gemounted hat und Byte-Range-Locks darauf setzen darf. Im Minimalfall reicht ein einzelner Rechner mit lokaler Ext-3-Partition.
Ob ein Cluster-Dateisystem für CTDB geeignet ist, zeigt der so genannte Pingpong-Test. Unter [9] liegt das kleine Programm »ping_pong.c« bereit, das testet, ob ein Cluster-Dateisystem kohärentes Byte-Range-Locking anbietet. Außerdem misst es die Locking-Performance und bestimmt die Korrektheit und Performance bei simultanen Schreibzugriffen und des Memory-Mapping (»mmap()«). Details zum Pingpong-Test hält [10] bereit.
Das am besten mit CTDB getestete Dateisystem ist das proprietäre GPFS [11] von IBM; CTDB und das Samba-Clustering verdanken ihre Entstehung nämlich maßgeblich dem Sponsoring von IBM. Als gut evaluiert gilt auch Red Hats Global File System (GFS) in der Version 2 ([12], [13]). CTDB-Pakete werden daher Einzug in die nächste Fedora-Version halten. Außerdem liegen positive Berichte vor vom Einsatz mit dem GNU Cluster File System (Gluster-FS, [14]) und Suns Lustre [15]. Das Oracle Cluster File System (OCFS2, [16], [13]) wird sich erst eignen, wenn die Implementierung des Posix-»fcntl()«-Locking abgeschlossen ist [17].
|
Listing 1: |
|---|
01 192.168.46.70 02 192.168.46.71 03 192.168.46.72 |
So arbeitet CTDB
Und so funktioniert das Ganze: Auf jedem Knoten läuft ein CTDB-Daemon »ctdbd«. Die Daemons handeln untereinander die Metadaten der Cluster-TDB-Datenbanken aus. Jeder CTDB-Daemon hält für die von CTDB verwalteten TDB-Datenbanken je eine lokale Kopie (LTDB), die nicht im Cluster-Dateisystem liegt, sondern auf schnellem lokalen Speicher. Der Zugriff auf die eigentlichen Daten erfolgt über die lokalen TDBs.
Wegen der unterschiedlichen Anforderungen gibt es für die flüchtigen und die persistenten Datenbanken zwei völlig verschiedene Verfahrensweisen: Für persistente Datenbanken hält jeder Knoten stets eine komplette und aktuelle Kopie vor. Lesezugriffe darauf erfolgen lokal. Will der Knoten schreiben, dann sperrt er dazu die gesamte Datenbank in einer Transaktion und erledigt innerhalb der Transaktion seine Lese- und Schreibvorgänge. Der Commit der Transaktion verteilt dann sämtliche Record-Änderungen an alle anderen CTDB-Knoten und schreibt sie auch lokal.
Für flüchtige Datenbanken dagegen hält jeder Knoten immer nur die Records in der lokalen TDB vor, auf die er schon zugegriffen hat. So besitzt immer nur ein Knoten die Hoheit über die aktuellen Daten eines Record: der Data Master. Will ein Knoten einen Record schreiben oder lesen, prüft er zuerst, ob er dessen Data Master ist. Wenn ja, greift er direkt auf die LTDB zu. Anderenfalls besorgt er sich über den »ctdbd« zunächst die aktuellen Record-Daten sowie die Data-Master-Rolle und schreibt dann lokal.
Dadurch, dass der Data Master immer direkt in die lokalen TDBs schreibt, ist ein einzelner CTDB-Knoten nicht langsamer als ein ungeclustertes Samba. Darin, dass bei flüchtigen Datenbanken die Record-Daten nur auf Anfrage an einzelne und nicht an alle Knoten gehen, liegt ferner das Geheimnis des guten Skalierens von CTDB. Denn: Die Änderungen, die ein Knoten an den flüchtigen Datenbanken vornimmt, dürfen, ja sollen ruhig verloren gehen, wenn er aus dem Cluster verschwindet! Die Informationen betreffen ohnehin nur Clientverbindungen auf diesem sowieso ausgefallenen Knoten. Alle anderen Knoten können mit den Daten naturgemäß nichts anfangen.
Performance-Messungen auf einem Cluster [18] bestätigen das Design sehr befriedigend. Ein dort mit 32 Clients gefahrener Smbtorture-»NBENCH«-Test [19] skaliert, wie in Tabelle 1 zu sehen. Eine einzige Verbindung auf einem Clusterknoten-Share erreicht eine Übertragungsrate von 1,7 GByte pro Sekunde.
|
Tabelle 1: |
|
|---|---|
|
Anzahl der Knoten |
Datenrate |
|
1 |
109 MByte/s |
|
2 |
210 MByte/s |
|
3 |
278 MByte/s |
|
4 |
308 MByte/s |
Selbstheilend
Wenn ein Knoten wegbricht, dann ist den flüchtigen Datenbanken vermutlich für ein paar Records auch der Data Master abhanden gekommen. Der Recovery-Prozess versetzt die Datenbank wieder in einen konsistenten Zustand: Ein Knoten ist der Recovery Master, der die Records von allen Knoten einsammelt. Für solche Records, für die er keinen Data Master findet, sucht er den Knoten mit der jüngsten Kopie. Dazu pflegt CTDB in einem zur Standard-TDB zusätzlichen Headerfeld eine Record Sequence Number, die bei jedem Transfer des Record auf einen anderen Knoten hochzählt. Am Ende der Recovery ist der Recovery Master der Data Master jedes Record jeder TDB.
Der Recovery Master geht aus einem Wahlprozess hervor, der mit dem so genannten Recovery Lock arbeitet. Das ist eine Datei im Cluster-Dateisystem, auf die der frisch gekürte Recovery Master am Ende ein Lock erhält. Genau wegen dieses Recovery Lock verlangt CTDB von seinem Cluster-Dateisystem, Posix-»fcntl()«-Locks zu unterstützen. Es sind auch andere, kompliziertere Wahlprozesse denkbar, die diese Anforderung nicht stellen. Andererseits verhindert ein intaktes Cluster-Dateisystem bei CTDB das fehlerträchtige Split-Brain-Problem.
Butter bei die CTDB-Fische
Nach der Theorie nun zur Admin-Praxis. Der Kasten “CTDB besorgen und kompilieren” erklärt, wie der Admin zu einer lauffähigen CTDB-Software kommt. Das eigentliche Samba-Setup passiert nachher im Abschnitt “Samba konfigurieren”. Die Samba-Entwickler empfehlen für ein CTDB-Setup (mindestens) zwei, am besten physikalisch getrennte Netze: Ein öffentliches, aus dem die Clients auf die angebotenen Dienste zugreifen (Samba, NFS, FTP, …), und ein privates Netz, über das CTDB die Cluster-interne Kommunikation abwickelt.
|
CTDB besorgen und |
|---|
|
Seit Ende 2007 verwendet das Samba-Projekt das dezentrale Code-Managementsystem Git [20]. Die Entwickler pflegen Samba und CTDB auf dem Server [git://git.samba.org] beziehungsweise dem Webfrontend [21]. Die Branches für die offiziellen Samba-Versionen sowie der Entwicklungsbranch »master« befinden sich im Repository [git://git.samba.org/samba.git]. Der Mirror [22] liefert sogar Tarball-Snapshots von jeder einzelnen Revision. Die offiziellen CTDB-Quellen bietet Ronnie Sahlberg in seinem Repository [7] an. Das Repository [git://git.samba.org/obnox/samba-ctdb.git] enthält auf den offiziellen Release-Branches fußende Samba-Versionen mit Cluster-Erweiterungen, insbesondere eine produktionstaugliche Clustervariante »v3-2-ctdb« der Samba-Version 3.2. Derzeit ist die CTDB-Software auf Linux und AIX lauffähig [23]. Die übliche Kommandosequenz baut und installiert sie: cd ctdb/ ./autogen.sh ./configure [Optionen] make make install Besondere »configure«-Optionen sind nicht nötig. Mit dem üblichen »–prefix« kann der Admin die Installationsverzeichnisse anpassen. Für RPM-Systeme darf er ein Paket auch direkt aus einem Git-Checkout produzieren: cd ctdb/ ./packaging/RPM/makerpms.sh Bereits kompilierte CTDB- und »v3-2-ctdb«-RPMs für Red Hat gibt es unter [24], für weitere Distributionen bei [25]. |
Das Netz des Cluster-Dateisystems kann ein getrenntes Netz sein oder dasselbe wie das CTDB-interne. Mitunter erweist sich ein separates Managementnetz als sinnvoll, etwa für SSH-Logins auf den Knoten. Den prinzipiellen Aufbau eines CTDB-Clusters zeigt Abbildung 2.
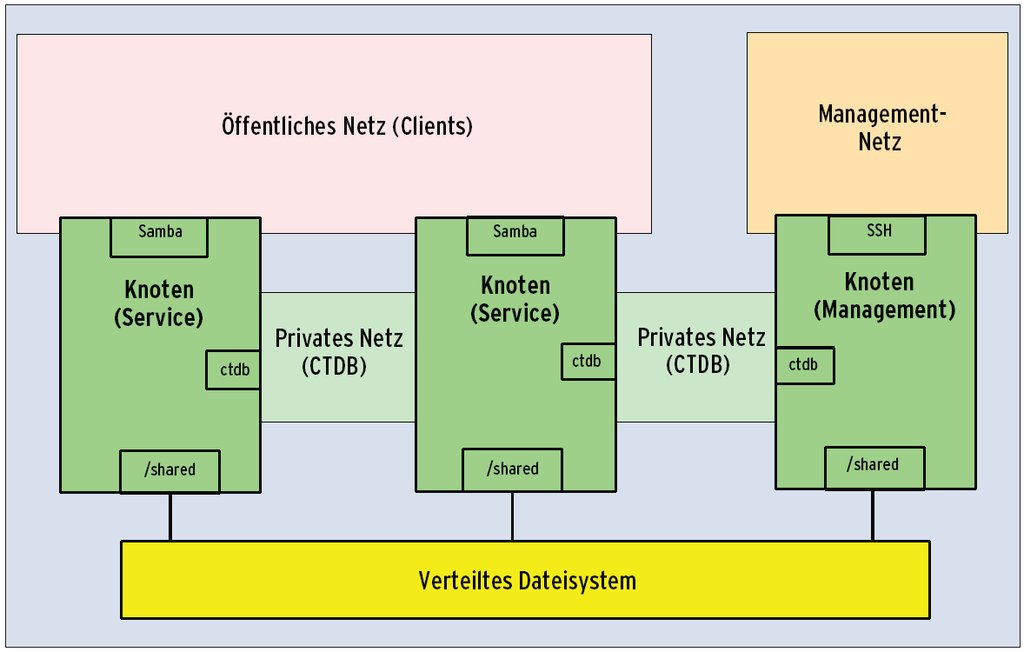
Abbildung 2: Prinzipielles CTDB-Setup mit zwei Serviceknoten und einem separaten Managementknoten. Wie der Storage angebunden und das Cluster-Dateisystem unter »/shared« eingehängt sind, beschreibt die Abbildung bewusst schematisch.
CTDBs zentrale Konfigurationsdatei ist die »/etc/sysconfig/ctdb«. Ganz wichtig ist hier, das Recovery-Lock-File über die Variable »CTDB_RECOVERY_LOCK« zu spezifizieren! Ferner muss der Admin die Datei »/etc/ctdb/nodes« mit den IP-Adressen aller CTDB-Knoten im privaten Netz füllen (Listing 1). Sie muss zudem auf allen Knoten identisch sein.
IP-Failover
Zum Verteilen öffentlicher IP-Adressen auf die Clusterknoten existieren mehrere Möglichkeiten. Sie können statisch vergeben sein, ohne dass CTDB involviert ist. In diesem Fall spielt CTDB seine High-Availability-Stärken nicht aus. Ferner kann der so genannten LVS-Modus eine einzelne IP-Adresse als öffentliche Clusteradresse verwenden, die der LVS-Master-Knoten an die teilnehmenden Knoten verteilt. Das Setzen der Variablen »CTDB_LVS_PUBLIC_IP« und »CTDB_PUBLIC_INTERFACE« in der Datei »/etc/sysconfig/ctdb« aktiviert diesen Modus.
Bei der dritten Methode verteilt CTDB mehrere öffentliche IP-Adressen dynamisch auf die Knoten. Zusammen mit einem vorgeschalteten Round-Robin-DNS erweitert sie den CTDB-Cluster um Loadbalancing und High Availability. Dazu legt der Admin auf jedem Knoten mit der »/etc/sysconfig/ctdb«-Variablen »CTDB_PUBLIC_ADDRESSES« eine Datei – üblicherweise »/etc/ctdb/public_addresses« – fest, die den Adresspool mit Netzmasken und Netzwerk-Interfaces enthält, aus dem CTDB den Knoten bedienen soll.
Diese Adressenliste braucht nicht auf allen Knoten vorhanden und nicht auf allen Knoten gleich zu sein. Hier kann der Admin auch die Netzwerktopologie im öffentlichen Netz berücksichtigen und beispielsweise Partitionen erstellen. Wenn ein Knoten ausfällt, überträgt CTDB seine öffentlichen IP-Adressen auf andere Clusterknoten, die diese Adressen in ihrer »public_addresses«-Liste enthalten.
Adressen schwenken
Es ist wichtig, zu verstehen, dass das Loadbalancing und die Verteilung der Clients auf die Clusterknoten immer pro Verbindung gelten. Wenn also eine IP-Adresse von einem Knoten auf einen anderen schwenkt, dann sind alle Verbindungen, die gerade an dieser IP-Adresse aktiv waren, verloren – die Clients müssen sich neu verbinden.
Damit es dabei nicht zu Verzögerungen kommt, bedient sich CTDB eines Tricks: Wenn eine IP schwenkt, dann kitzelt der neue (!) CTDB-Knoten den Client mit einem illegalen TCP-ACK-Paket (Tickle-ACK), das die ungültige Sequenznummer »0« und die ACK-Nummer »0« enthält. Der Client schickt als Antwort ein gültiges ACK-Paket, worauf der neue Inhaber der IP-Adresse die Verbindung gültig mit einem RST-Paket schließen darf und den Client so dazu zwingt, die Verbindung zu dem neuen Knoten neu aufzubauen.
|
Listing 2: |
|---|
01 192.168.45.70/24 eth0 02 192.168.45.71/24 eth0 03 192.168.45.72/24 eth0 04 192.168.45.73/24 eth0 05 192.168.45.74/24 eth0 06 192.168.45.75/24 eth0 |
Der Werkzeugkasten
Zu dem Daemon »ctdbd« liefert das CTDB-Paket noch zwei nützliche Programme: »ctdb« und »onnode«. Das Tool »ctdb« ist das Client-Interface, um den CTDB-Cluster zu verwalten. Das meistgenutzte Kommando ist sicher »ctdb status«, das den allgemeinen Status des Clusters ausgibt (Abbildung 3). Das Kommando »ctdb ip« zeigt ferner die Verteilung der öffentlichen Adressen auf die Knoten (Abbildung 4). Mit »ctdb« kann der Admin Aktionen im Cluster auslösen, etwa einzelne Knoten ab- oder anschalten, öffentliche IPs hinzufügen oder entfernen, eine Recovery erzwingen sowie umfangreiches Finetuning vornehmen. Information dazu gibt die Manpage, die unter [26] online einzusehen ist.
Als sehr segensreiches Tool erweist sich das Skript »onnode«, das Kommandos auf einem oder mehreren Knoten ausführt:
onnode Knoten[,Knoten...] Kommando
Es informiert sich über die Knoten in der Datei »/etc/ctdb/nodes«. Das Ziel können ein oder mehrere Knotennummern oder ein Nummernbereich sein. Außerdem gibt es symbolische Namen für alle Knoten (»all«), die verbundenen Knoten (»con«), alle gesunden Knoten (»ok«) und den Recovery Master (»rm«). Die Verbindungen zu den Knoten baut »onnode« per SSH auf, sodass es praktisch ist, wenn für das interne CTDB-Netz passwortloses SSH-Login gilt.
Mittels »onnode« rollt der Admin kinderleicht etwa Dienste-Konfigurationsdateien auf die Knoten aus oder installiert überall die gleichen Softwarepakete, wenn er die entsprechenden Daten zuvor in das Cluster-Dateisystem gelegt hat:
onnode all cp /shared/smb.conf /etc/samba/smb.conf
Da Onnode nur die »nodes«-Datei benötigt, kann man es auch benutzen, um »ctdbd« auf allen oder ausgewählten Knoten zu starten:
onnode 0,2-5 service ctdb start
Für weitere Details sei wieder auf die Manpage [27] verwiesen.
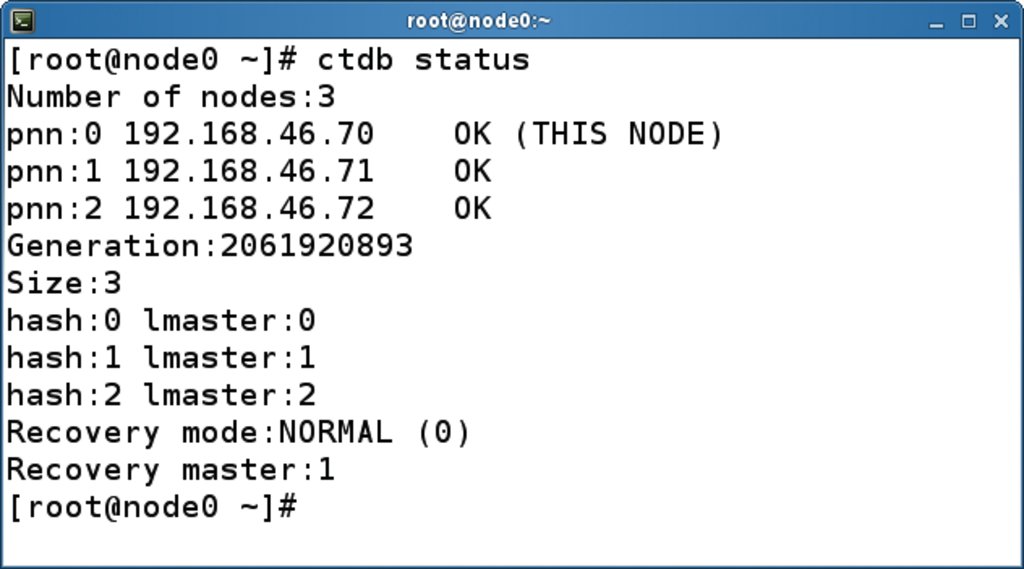
Abbildung 3: Das gern benutzte Kommando »ctdb status« informiert über den Clusterstatus.
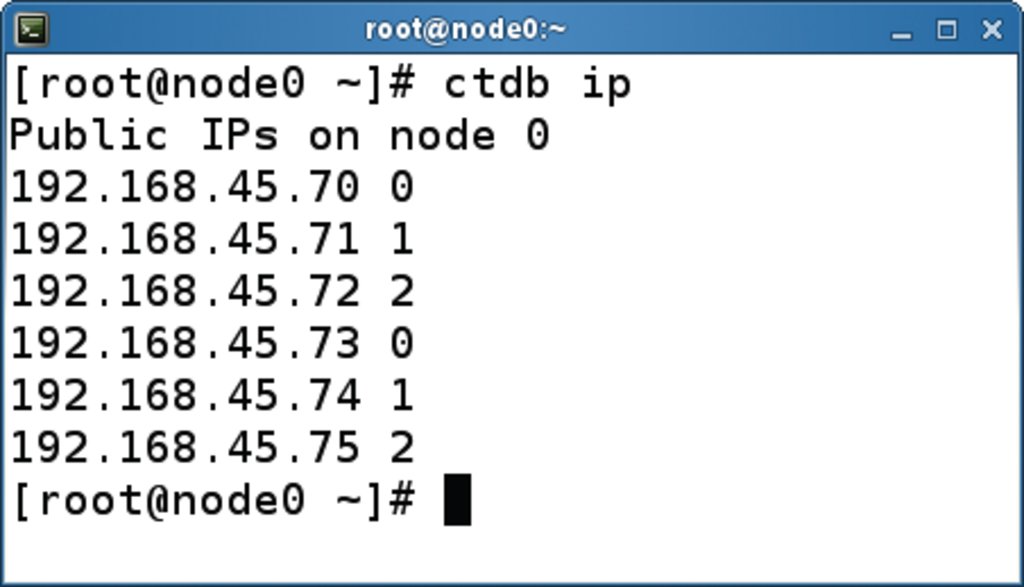
Abbildung 4: Mit »ctdb ip« informiert sich der Admin, wie sich die öffentlichen IP-Adressen auf die Knoten verteilen.
CTDB als Manager
Ursächlich entwickelt, um Samba zu clustern, hat sich CTDB heute zu einer HA-Lösung für eine ganze Reihe von Diensten gemausert, beispielsweise NFS, den FTP-Daemon »vsftpd« und Apache. CTDB verwaltet diese Dienste, indem es die Programme startet, stoppt und zur Laufzeit überwacht. Außerdem führt CTDB geeignete Aktionen beim Schwenken von IP-Adressen durch.
Ob CTDB einen Dienst in dieser Art verwaltet, legen die Konfigurationsparameter »CTDB_MANAGES_Dienst« in der Datei »/etc/sysconfig/ctdb« fest, die die Werte »yes« oder »no« annehmen können. Bisher gibt es:
- »CTDB_MANAGES_SAMBA«
- »CTDB_MANAGES_WINBIND«
- »CTDB_NAMAGES_NFS«
- »CTDB_MANAGES_VSFTPD«
- »CTDB_MANAGES_HTTPD«
Die Startskripte der CTDB-verwalteten Dienste sollte der Admin aus den Runlevels entfernen, also zum Beispiel mit »chkconfig -s smb off«. »CTDB_MANAGES_SAMBA« hat übrigens nichts mit der clusterweiten Verhandlung der TDB-Dateien zu tun. Die erledigt CTDB unabhängig von der Diensteverwaltung. Die eigentliche Überwachung der Dienste führen Eventskripte unter »/etc/ctdb/events.d/« durch, die der CTDB-Daemon aufruft. Einen neuen Dienst in die Verwaltungsobhut von CTDB zu bringen bedeutet also normalerweise “nur”, ein Eventskript schreiben zu müssen.
Samba konfigurieren
Wer ein Samba mit Cluster-Support vorliegen hat (siehe Kasten “Bau-Anleitung für Samba”), konfiguriert es mit einigen »smb.conf«-Parametern:
- »clustering = yes« aktiviert das Clustering zur
Laufzeit. Ohne diesen Parameter verhält sich ein fürs
Clustern gebautes Samba wie eines ohne Cluster-Support. - Entgegen den Informationen auf einigen Seiten im Samba-Wiki,
etwa [23], muss der Admin das »private dir« nicht ins
Cluster-Dateisystem verlegen (höchstens wegen einer lokalen
»smbpsswd«). Diese Information gilt nur für
frühere CTDB-Versionen, die ihre persistenten TDB-Datenbanken
wie die »secrets.tdb« und »passdb.tdb« im
»private dir« nicht behandeln können. Aktuelle
CTDB-Versionen jedoch verteilen auch die persistenten TDBs
automatisch im Cluster. - Wer Group-Mappings braucht, muss mit »groupdb:backend =
tdb« das Backend vom Standardwert »ldb« auf
»tdb« ändern.
Samba speichert die Locking-Informationen einer Datei anhand ihres Identifikationscode – den bildet der »smbd« normalerweise aus einem »stat()«-Systemaufruf aus der Device- und Inode-Nummer der Datei. Das Clustersetup benötigt aber eine knotenübergreifend gültige ID, denn die Device-Nummer ist keine Cluster-Invariante einer Datei.
Mit dem VFS-Modul »fileid« lässt sich jedoch eine alternative, clusterweit gültige File-ID bilden. Es unterstützt zwei Methoden: Die Variante »fsname« zimmert eine Device-Nummer als Hash aus dem Dateisystemnamen (»fsname«) des »getmntent()«-Aufrufs. Die Variante »fsid« bildet die Device-Nummer aus der Dateisystem-ID (»f_fsid«) des »statfs()«-Aufrufs. Default beim »fileid«-Modul ist »fsname«.
- Der Parameter »vfs objects = fileid« im
entsprechenden Konfigurationsabschnitt aktiviert für ein Share
oder global das »fileid«-Modul. Der Wert der Option
»fileid:algorithm« im Abschnitt »[global]«
konfiguriert die Methode. Etwa so wie
vfs objects = fileid fileid:algorithm = fsid
kann ein Beispiel aussehen und in der »[global]«-Sektion angesiedelt sein.
|
Bau-Anleitung für |
|---|
|
Wer keine vorgefertigten Pakete einsetzen kann oder will, baut und installiert sich mit der üblichen Abfolge von Kommandos aus den Quellen von Samba 3.3 ein clusterfähiges Samba einfach selbst: cd samba/source ./autogen.sh ./configure --with-cluster-support --with-ctdb=/usr/include --with-shared-modules=idmap_tdb2 [Weitere Optionen] ./make everything ./make install Das »autogen.sh« braucht nur aufzurufen, wer nicht den Release-Tarball verwendet, sondern einen Schnappschuss aus dem Git-Repository. Bei den »configure«-Parametern legt »–with-ctdb=« fest, wo sich die CTDB-Header im System befinden. Die braucht Samba, um den Code für die Kommunikation mit CTDB zu kompilieren. Ist CTDB bereits aus einem Paket installiert, dann ist »/usr/include« normalerweise richtig. Dass die Modul-Liste in »–with-shared-modules=« auch »idmap_tdb2« enthält, veranlasst den Bau der Cluster-Variante des Standard-ID-Mapping-Moduls »idmap_tdb«. Das Samba-Team arbeitet zurzeit daran, »idmap_tdb« und »idmap_tdb2« zu verschmelzen, sodass das »idmap_tdb« auch im Cluster einsetzbar wird. Mit einer der nächsten Samba-Versionen wird dieser Unterschied also voraussichtlich verschwinden. Ähnlich wie bei dem Bau von CTDB produziert cd samba/source ./packaging/RHEL-CTDB/makerpms.sh RPMs für Red-Hat- und Suse-Systeme auch direkt aus einem Git-Checkout heraus. |
Lauscher aufstellen
Es ist extrem wichtig für das reibungslose Funktionieren der Monitoring- und Failover-Mechanismen von CTDB, die IP-Adressen oder Netzwerk-Interfaces auf denen Samba lauschen soll, nicht per Konfigurationsparameter »interfaces« oder »bind interfaces only« einzuschränken! Das Monitoring der Samba-Dienste beruht nämlich darauf, dass Samba auf der Wildcard-Adresse »0.0.0.0« lauscht, beziehungsweise auf »::« bei IPv6.
Listing 3 zeigt beispielhaft eine Samba-Konfigurationsdatei, die der Admin auf alle Clusterknoten verteilen sollte. Das Kommando »smbstatus« zeigt im Cluster die Verbindungen auf allen Knoten an. Dazu listet es nicht nur die Prozess-ID der »smbd«-Prozesse, sondern gibt deren Knoten-Nummern-Präfix aus (Abbildung 5). Analog kann der Admin auch mit »smbcontrol« clusterweit auf die Samba-Daemons Einfluss nehmen.
|
Listing 3: |
|---|
01 [global] 02 clustering = yes 03 netbios name = cifscluster 04 workgroup = mydomain 05 security = ads 06 passdb backend = tdbsam 07 08 idmap backend = tdb2 09 idmap uid = 1000000-2000000 10 idmap gid = 1000000-2000000 11 12 groupdb:backend = tdb 13 fileid:algorithm = fsname 14 15 [share] 16 path = /storage/share 17 vfs objects = fileid |
Es ergibt übrigens beim Betrieb von geclustertem Samba keinen Sinn, den Netbios-Namensdienst »nmbd« auf mehreren Knoten zu starten – der Broadcast-Dienst hadert mit der gespaltenen Persönlichkeit. Auch der WINS-Dienst ist nicht dafür gewappnet, da Samba die »wins.dat«-Datenbank nicht wie TDBs über CTDB verhandelt.
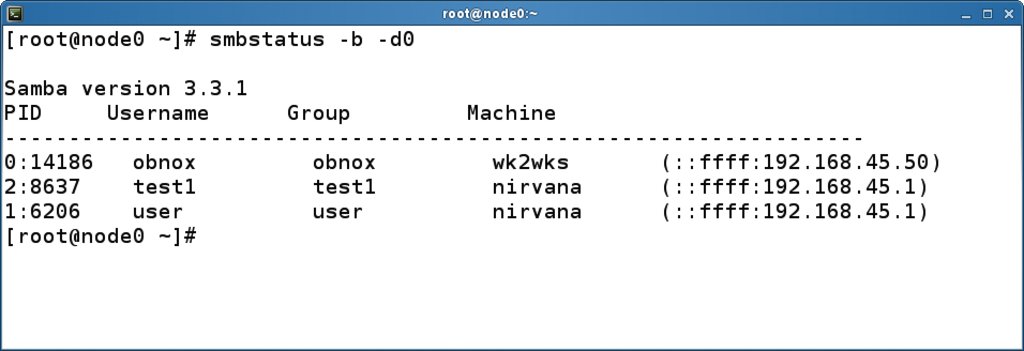
Abbildung 5: Das Kommando »smbstatus« zeigt im Cluster die Verbindungen auf allen Knoten an.
Registry-Konfiguration
Mit Samba 3.2 und der zugleich neu eingeführte Registry-basierten Konfiguration [28] gewinnen Setup und Pflege eines Samba-Clusters einen gewissen Charme. Denn sie benutzt die Windows-Registrierungs-Datenbank (Registry), die Samba für seine Windows-Clients ohnehin implementiert und ihnen über eine Winreg-RPC-Schnittstelle anbietet. Intern weist die »registry.tdb« eine Datenstruktur auf, die sehr gut zum Format einer »smb.conf« passt. Sobald die Samba-Konfiguration in der »registry.tdb« liegt, verteilt sie CTDB automatisch im Cluster.
Die Registry strukturiert ihre Daten als Baum von Schlüsseln (Keys): Ein Registry-Key besteht aus einem Namen, der Liste seiner Subkeys und einer Liste von Registry-Werten (Values). Ein Wert wiederum setzt sich aus einem Namen und den Wert-Daten zusammen. Samba speichert die Konfigurationsdaten unterhalb des Keys »HKLMSoftwareSambasmbconf«. Hier entsprechen Abschnitte einer »smb.conf«-Datei den Subkeys dieses Schlüssels, Konfigurationsparameter entsprechen den Registry-Werten im korrespondierenden Subkey.
Wie bei der Syntax der »smb.conf«-Datei macht die Registry keinen Unterschied zwischen dem Abschnitt »global« und den Share-Definitionen. Die Daten in der Registry entsprechen einer geparsten »smb.conf«-Datei. Da es sich um eine Datenbank mit Schlüsseln und Werten handelt, kennt sie weder eine feste Reihenfolge noch Mehrfachnennungen für Parameter.
Darum bedürfen hier die »include«-Anweisungen einer Sonderbehandlung – sie wirken nämlich nicht als Konfigurationsparameter, sondern als Meta-Direktiven, die Text-Konfigurationsdateien strukturieren. Der Kompromiss lautet: Samba pflegt die Includes pro Abschnitt in einer Liste, die ihrerseits zwar eine Reihenfolge aufweist, deren Auswertung aber als Ganzes erst im Anschluss an die der Parameter passiert.
Hochfahren in drei Stufen
Der Cluster-Admin aktiviert die Registry-Konfiguration in drei Stufen, wobei die Datei »smb.conf« stets die initiale Konfigurationsquelle bleibt:
- Der »smb.conf«-Parameter »registry shares =
yes« im Abschnitt »[global]« schaltet das Lesen
von Freigaben-Definitionen scharf. »smbd« holt sich
diese Liste nicht schon beim Starten aus der Registry – wie
bei den per Konfigdatei definierten Shares -, sondern
lädt sie zur Laufzeit. Falls es ein Share gleichen Namens in
der Registry und in »smb.conf« gibt, macht die
Text-Variante das Rennen. - Eine neue und im Cluster oft dringend nötige
Spezialsemantik des »smb.conf«-Parameters
»include = registry« im Abschnitt
»[global]« mischt globale Optionen aus der Registry
unter die vorhandene Text-Konfiguration. Hierbei bleibt die volle
Semantik von »include« erhalten: Parameter, die in der
»smb.conf« vor »include = registry« stehen,
können durch Registry-Parameter überschrieben werden,
diese wiederum durch spätere Nennung. »include =
registry« aktiviert automatisch »registry shares =
yes«. Vor dem unbedachtem Mischen von Text- und
Registry-Konfiguration sei gleichwohl ausdrücklich gewarnt
– zum Beispiel eignet sich der Orts-Parameter »lock
directory« prima dazu, sich die Registry selbst “unter
dem Hintern” wegzukonfigurieren. - Analog zum kompletten Umschwenken der Konfigurationsdatei
mittels »config file« darf der Admin mit der neuen
»smb.conf«-Direktive »config backend =
registry« eine reine Registry-Konfiguration einrichten. Hier
verwirft Samba alle bereits gelesenen Einstellungen aus der
»smb.conf« und stützt sich allein auf
Registry-Parameter. Auch die Direktive impliziert »registry
shares = yes«.
Ein Cluster-Setup kämpft prinzipbedingt mit einem Henne-Ei-Problem: Die Registry liegt in der Datenbank »registry.tdb« und CTDB soll sie auf den Cluster verteilen. Dafür muss Samba aber schon mit der Option »clustering = yes« initial konfiguriert sein. Daran scheitert eine reine Registry-Konfiguration mit »config backend = registry« erwartungsgemäß. Stattdessen sollte der Admin
[global]
clustering = yes
include = registry
als minimale »smb.conf«-Datei und Standardkonfiguration seines Clusters verwenden.
|
Tabelle 2: |
|
|---|---|
|
Befehl |
Beschreibung |
|
net conf list |
Gibt die komplette Konfiguration im |
|
net conf import |
Importiert eine Konfigurationsdatei im |
|
net conf listshares |
Listet die Share-Namen |
|
net conf drop |
Löscht die ganze Konfiguration |
|
net conf showshare |
Zeigt die Definition eines Share |
|
net conf addshare |
Erzeugt ein neues Share |
|
net conf delshare |
Löscht ein Share |
|
net conf setparm |
Speichert einen Parameter |
|
net conf getparm |
Ruft Parameterwerte ab |
|
net conf delparm |
Löscht einen Parameter |
|
net conf getincludes |
Zeigt die Includes einer Share-Definition |
|
net conf setincludes |
Setzt Includes für ein Share |
|
net conf delincludes |
Löscht Includes einer Share-Definition |
Viele Wege führen ins Registry-Land
Zum Bearbeiten der Samba-Registry öffnen sich mehrere Wege. Zuvor muss der Admin jedoch dem dazu gewillten Benutzer über dieses Kommando den Remote-Zugriff erlauben:
net rpc rights grant Benutzer SeDiskOperatorPrivileg
Der kurioseste Weg führt über den recht unkomfortablen Windows Registry-Editor »regedit.exe« (Abbildung 6). Schon etwas praktischer geht\’s mit dessen Samba-Kommandozeilen-Pendant »net registry«, da der Admin hier die Vorteile und Scripting-Fähigkeiten der Unix-Kommandozeile nutzen kann.
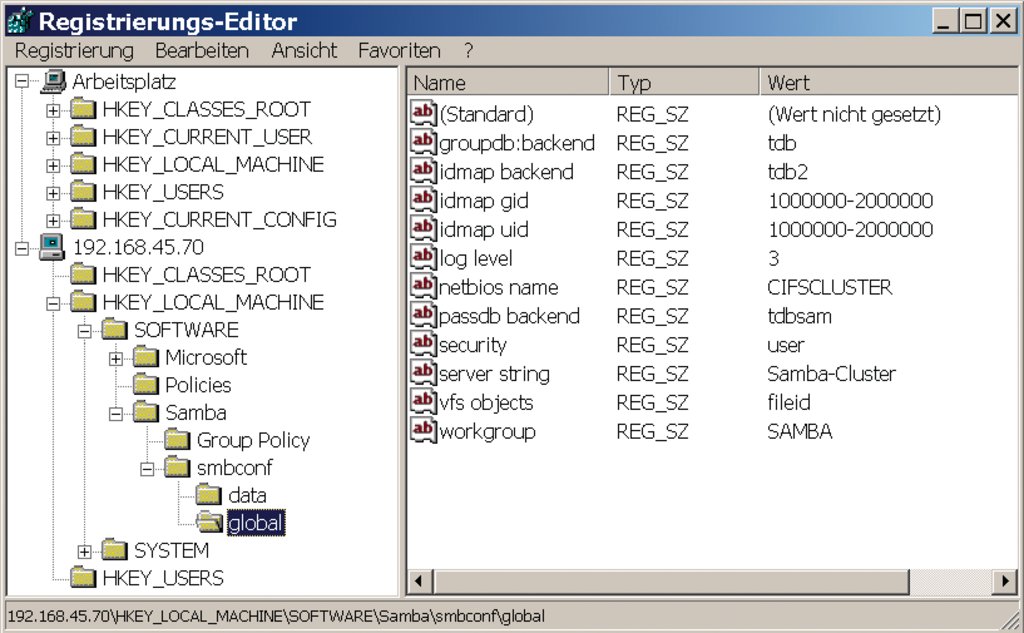
Abbildung 6: Mehr etwas für leidensfähige und eingefleischte Windows-Admins: Samba-3.2-Konfiguration bearbeiten mit dem Registry-Editor »regedit.exe«.
Als Drittes bietet Samba mit dem Kommando »net conf« eine dedizierte Schnittstelle in die Registry-Konfiguration an (siehe Tabelle 2). »net conf list« gibt die gesamte Konfiguration im »smb.conf«-Format aus, umgekehrt importiert »net conf import« eine »smb.conf«-Textdatei in die Registry. Eine Kommandofolge zum Lesen und Schreiben von einzelnen Parametern dagegen zeigt Abbildung 7 beispielhaft.

Abbildung 7: Mehr etwas für souveräne Linux-Admins: Das Kommandozeilentool »net conf« schreibt und liest einzelne Registry-Konfigurationsparameter.
Der Ausfall darf kommen
Zusammen mit CTDB stellt Samba 3.3 erstmals einen sehr gut skalierenden CIFS-Cluster bereit, der ohne Patches und Tricks vergleichsweise einfach für Produktivsysteme installierbar ist. Voraussetzung ist ein frei wählbares Cluster-Dateisystem, das den im Artikel beschriebenen Pingpong-Test besteht. Nach dem Grundsetup machen die Registry-Konfiguration und das »onnode«-Skript das Verwalten angenehm einfach. (jk)
|
Der Autor |
|---|
|
Michael Adam ist Mitglied des internationalen Samba-Entwicklerteams [2] und pflegt die Samba-Softwarebranches mit den Cluster-Erweiterungen. Er arbeitet als Software-Entwickler und Consultant für die Göttinger Sernet GmbH. Seine Freizeit verbringt er am liebsten mit seinen Kindern und auf dem Mountainbike. |





