
© serkucher / 123RF.com
Geld ist in Startups meist chronisch knapp, doch um Dienste online zu bringen, braucht es Investitionen. Wie ermitteln frisch gebackene Unternehmer, mit welchen Beträgen sie rechnen müssen?
Euphorie prägt häufig den Alltag in Startups. Das gilt vor allem für Unternehmen, die eine neuartige, bisher nicht Markt zu findende Anwendung entwickeln. Zwar halten sich die wenigsten Neubetriebe für das nächste deutsche Einhorn, ein gewisser Anspruch an die eigene Innovation und eigene Ambitionen findet sich aber fast überall. Doch manchmal ist es mit der Euphorie auch schnell wieder vorbei – nämlich dann, wenn es darum geht, nach dem Fertigstellen einer ersten Version einen regulären Betrieb für das eigene Programm zu etablieren.
Der Go-live einer neuen Anwendung wirft ganz praktische Fragen auf: Wo hostet man den Dienst – auf eigener Infrastruktur, bei einem Anbieter in Form einer VM oder beim Hyperscaler? Welche Kosten muss man erwarten, damit zusammen mit der ersten Rechnung des IT-Dienstleisters nicht gleich auch der Insolvenzverwalter kommt? Vor dem Hintergrund, dass in Startups Geld oft die knappste aller Ressourcen ist, spielen solche Fragen eine zentrale Rolle. Frisch gebackene Unternehmer tun sich besonders an dieser Stelle regelmäßig schwer. Immerhin ist es alles andere als trivial, den eigenen Bedarf zu kalkulieren und mit ihm die Kosten, die der Betrieb der Anwendung sowohl anfangs als auch bei Wachstum produzieren wird. Obendrein gibt es dafür praktisch keine fertigen Werkzeuge, da Art und Umfang benötigter Ressourcen stark von der Spezifik der jeweiligen Anwendung abhängen.
Anwendungsentscheidung
Hinzu kommt: Nicht jeder Ansatz funktioniert für jede Anwendung gleich gut. Manche Anwendungen lassen sich hervorragend auf eigener Hardware in einer Co-Location betreiben. Andere lassen ihren jeweiligen Schöpfern möglicherweise gar keine Wahl. Das passiert beispielsweise, wenn die App spezifische Dienste in der Cloud benötigt. Wer eine besondere Datenbank in GCP oder in Azure als Herzstück der eigenen Anwendung braucht, ist mindestens an den Anbieter gebunden.
Das verkompliziert die Sache weiter, denn für unterschiedliche Dienste finden sich bei den Hyperscalern verschiedene Verrechnungsmodelle in Abhängigkeit von Zeit und Anzahl der Anfragen für ein- wie ausgehenden Traffic. Selbst eingefleischte Profis durchdringen sie im Hinblick auf die jeweilige Plattform oft nicht gänzlich. Zumal sich in vielen Fällen nicht leicht ermitteln lässt, wie viele Anfragen eine Anwendung etwa in Abhängigkeit von der Anzahl der Zugriffe von außen tatsächlich produziert. Möchten Sie den Bedarf sinnvoll erheben, vollführen Sie dementsprechend einen Balanceakt zwischen Maschinenraum, Taschenrechner und Kalkulationswerkzeug (Abbildung 1) des Anbieters.
Abbildung 1: AWS bietet zwar ein Kalkulationswerkzeug für die zu erwartenden Kosten, aber es ist derart komplex, dass die meisten jungen Unternehmen an dessen Nutzung scheitern.
Dieser Artikel gibt Gründerinnen und Gründern einen Leitfaden an die Hand, auf welche Faktoren sie achten müssen, welche Möglichkeiten im Raum stehen, und wo sich gegebenenfalls Kosten einsparen lassen. Nicht alle Beispiele lassen sich eins zu eins auf jedes Szenario anwenden. Wer ein Startup gründen möchte, bekommt jedoch wenigstens eine Vorstellung von den zwingend zu beachtenden Faktoren. Als Beispiel dient ein Unternehmen, das eine neuartige Online-Anwendung entwickeln und auf den Markt bringen möchte. Wer stattdessen vorhat, ein Dienstleistungsunternehmen zu gründen, geht auch nicht komplett leer aus. Dafür sind in der Regel ebenfalls Ressourcen nötig, vor allem solche, um bestimmte Dienste für die eigene Belegschaft bereitzustellen. Deren Kalkulation kann sich an den vorgestellten Prozeduren zumindest orientieren.
Wohin damit?
So etwas wie die Gretchenfrage bei allen Startups ist, wie man die nötige IT-Infrastruktur betreiben möchte. Vom Wie hängt im konkreten Fall direkt das Wo ab. Groß ist die Verlockung, sich flugs bei einem der Hyperscaler einzumieten und dessen Ressourcen in Anspruch zu nehmen. Gerade Gründer erliegen der Versuchung regelmäßig, weil in der Public Cloud Ressourcen mehr oder weniger beliebig zur Verfügung stehen und so das Skalieren in die Breite problemlos klappt. Zudem lässt sich der Hyperscaler-Vertrag dank des On-Demand-Prinzips so kurzfristig kündigen wie man ihn ursprünglich eingegangen ist.
Ein weiterer Pluspunkt: Zahlreiche lästige IT-Dienste des Alltags wie Monitoring, Loadbalancing, persistenter und trotzdem redundanter Speicher und eine Anbindung an einen Objektspeicher mit S3-Protokoll bieten die Hyperscaler quasi nebenbei. Darüber muss man sich also keine Gedanken machen. Stattdessen liegt bei diesem Konstrukt der Fokus eines Unternehmens von Anfang an auf der Entwicklung des eigentlichen Produkts. Klingt doch großartig, oder?
Schauen Sie genauer hin, bekommt die heile Hyperscaler-Welt bald Risse. Dass AWS, Azure und GCP keine Wohlfahrtsvereine sind, hat sich längst herumgesprochen. Seit Jahren geistern Geschichten von Startups durchs Netz, die nach der ersten AWS-Rechnung gleich wieder schließen mussten. Allerdings entpuppen sich diese Geschichten oft entweder als Legende oder als Musterbeispiel von Fahrlässigkeit. Denn wer zum Beispiel eine große Instanz, die prinzipiell nur für kurze Tests das Licht der Welt erblickt hat, einen ganzen Monat laufen lässt, braucht sich über eine horrende Rechnung ohne Gegenwert nicht wundern. Immerhin, über Policy-Regeln vermeiden Sie solche Probleme bei den großen Public-Cloud-Anbietern, obgleich deren Einrichtung ein mühseliger Akt ist. Die tatsächliche Gefahr bei Hyperscalern lauert an einer anderen Stelle.
Schließlich führt die On-Demand-Bezahlung dazu, dass AWS und Co. ihre Gewinne stets sofort einfahren wollen. Nicht zuletzt deshalb haben die Anbieter in den vergangenen Jahren ordentlich an der Preisschraube gedreht. Selbst vergleichsweise einfache virtuelle Instanzen bei AWS, Azure und GCP schlagen mittlerweile mit mehreren Hundert Euro pro Monat zu Buche – und das sind nicht die fetten, Tausende Benutzer gleichzeitig abfertigende Server. Gesellen sich dann noch Dienste wie Loadbalancer-as-a-Service, Monitoring-as-a-Service oder besondere Datenbanken dazu, wächst die Hyperscaler-Rechnung schnell in schwindelerregende Höhen. Die hohe Flexibilität gerade zu Beginn der Entwicklung erkaufen sich Startups also im wahrsten Sinn des Wortes durch hohe laufende Kosten, also Operational Expense oder OpEx.
Außerdem ist das Argument fadenscheinig, Verträge bei AWS seien jederzeit leicht zu kündigen. Den Lock-in-Effekt schaffen Unternehmen sich im Normalfall ganz von selbst. Haben Sie Ihre Anwendung zur Entwicklungsreife gebracht und dabei durchgängig einen Hyperscaler benutzt, werden Sie wohl kaum kurz vor dem Starttermin das gesamte Setup auf billigere Infrastruktur wie in eine Co-Location im Rechenzentrum umziehen. Einerseits würde das den Go-live-Termin erheblich verzögern. Andererseits müssten Sie sich dann ohnehin erst wieder mit den Widrigkeiten des IT-Betriebs beschäftigen oder die Aufgabe an Dienstleister auslagern.
Death by Lock-in
Während das zumindest theoretisch noch möglich ist, haben Sie auf ganzer Linie verloren, wenn Sie die programmierte Anwendung von Diensten abhängig gemacht haben, die es nur bei den Hyperscalern gibt. Ein gutes Beispiel dafür sind Datenbanken. Alle drei Hyperscaler offerieren spezielle Datenbanken, etwa Google Big Table oder Aurora bei AWS. Die Datenbanken eignen sich hervorragend für den ihnen zugedachten Anwendungszweck. Doch sie besitzen eben auch eine proprietäre Schnittstelle und selbst einsetzbare Gegenstücke existieren nicht, meist schon gar nicht als freie und kostenlose Software.
Haben Sie eine solche Komponente erst in die eigene Anwendung integriert, kommen Sie von ihr im Normalfall praktisch nicht mehr los und haben sich dauerhaft an den Hyperscaler und dessen Preisgestaltung gebunden. Hier spielt die Frage nach der Menge der benötigten Ressourcen dann nahezu keine Rolle mehr. Vielmehr bepreist man das eigene Produkt zwangsweise so, dass es die – teils haarsträubenden – Kosten des Hyperscaler-Setups regelmäßig abdeckt.
Junge Unternehmen tun gut daran, solche Lock-ins gerade in der Anfangsphase zu vermeiden. Im Netz finden sich zahllose Vergleichstabellen für Hyperscaler-Dienste und mögliche Alternativen, die sich im Falle eines Falles auch lokal betreiben lassen. Auch hybride Setups können eine Alternative sein. Dabei wickelt man einen Teil der Arbeit in der Cloud ab und nutzt dort einen spezifischen Dienst, behält aber über das Gros der eigenen IT-Infrastruktur die Kontrolle – im eigenen Rechenzentrum oder in gehosteter Form. Implizit einher geht damit die Kontrolle über die Rechnung. Denn Kosten für konventionelle Hosting- und IT-Dienstleistung lassen sich zumindest im Regelfall gut über einen Zeitraum X kalkulieren.
Beim Hyperscaler hingegen scheitern nicht wenige Startups daran, dass sich anfallende Kosten im Voraus kaum prognostizieren lassen. Warum das so ist, darüber scheiden sich die Geister. Mitverantwortlich sind zweifelsohne die intransparenten Preismodelle der Hyperscaler, ebenso wie der zum Teil schludrige Umgang junger Unternehmen mit deren Ressourcen. Wer Hosting-Dienstleistung stattdessen zum Fixpreis einkauft, hat zumindest diese Gefahr vorerst gebannt.
Co-Location und Mietserver
Alternativen zu den Hyperscalern existieren in mannigfaltiger Art und Weise. Beispielsweise muss es am Anfang nicht zwingend eigene Hardware sein. Sofern Sie nicht damit rechnen, dass Ihr Produkt am Tag nach dem Launch gleich von der halben Republik genutzt werden möchte, fahren Sie möglicherweise auch mit gemieteten virtuellen Servern bei klassischen Hostern gut. Die bekommen Sie gegen geringen Aufpreis meist schon mit einmonatiger Vertragslaufzeit und mitunter zum sehr fairen Kurs von 130 Euro pro Monat für eine ordentliche Spezifikation. Wer fünf oder sechs solcher Instanzen kombiniert, geht mit unter 1000 Euro pro Monat aus der Türe, muss sich aber trotzdem lediglich um einen Teil des IT-Betriebs selbst kümmern.
Auf einem Beispiel-Setup wie dem genannten lässt sich bereits komfortabel Kubernetes betreiben, was das Einrichten von Loadbalancern, Datenbanken oder Monitoring, Alerting und Trending (MAT) relativ simpel macht. Zusätzlich legt man sich mit einem Setup solcher Art nicht dauerhaft auf einen Anbieter fest. Der Weg zum Hyperscaler steht bei Bedarf auch zu einem späteren Zeitpunkt noch offen, ebenso wie der Weg hin zum vollständigen Eigenbetrieb der IT-Infrastruktur, etwa in einer Co-Location.
Sofern Sie das in Erwägung ziehen, sollten Sie außerdem darüber nachdenken, möglicherweise nicht zu nagelneuer Hardware, sondern zu generalüberholten Servern zu greifen. Einen HP ProLiant DL380 Gen10 (Abbildung 2) zum Beispiel erstehen Sie mit sehr ordentlicher Konfiguration realistisch für 5000 Euro pro System, mit 4 TByte Speicher in Form flotter SAS-SSDs. Weil es von den genannten Servern so viele gebrauchte Systeme gibt, funktioniert die Ersatzteilversorgung problemlos.
Zwar sind 30 000 Euro für eine Kubernetes-Umgebung mit solchen Boliden nicht gerade ein Schnäppchen. Verglichen mit den Kosten, die sechs neue Server mit entsprechender Menge an RAM und CPU-Kernen kosten, fällt der Betrag trotzdem moderat aus. Hier lohnt es sich außerdem, über Virtualisierung nachzudenken. Denn ein System mit 48 CPU-Kernen, 512 GByte RAM und 4 TByte Plattenplatz muss nicht zwangsläufig exklusiv für einen Kubernetes-Controller zum Einsatz kommen. Dieser lässt sich auch zusammen mit einem Compute-Node für K8s in VMs verpacken.

Abbildung 2: Ein vermeintlich altes Eisen wie ein DL380 Gen10 ist refurbished gut und günstig zu bekommen. Für viele alltägliche Aufgaben taugt er nach wie vor.
Bedarfsermittlung
Nach den Erfahrungen des Autors ist es regelmäßig so, dass vor allem junge Gründer sich den tatsächlichen und möglichen Ressourcenbedarfs einer Anwendung im Onlinebetrieb nur arg eingeschränkt vorstellen können. Frei nach dem Motto “Haben ist besser als brauchen” schießt so mancher bei der Dimensionierung des ersten Versuchs weit über das Ziel hinaus. Das führt zu hohen Einstiegskosten.
Der Ansatz ist nicht zwangsläufig ein Problem. Schließlich schafft man auf diese Weise ein Polster für das erste Skalieren in die Breite. Besonders Startups mit chronisch klammen Konto sollten ihr Geld anfangs zusammenhalten. Das wirft die Frage auf, wie man den tatsächlichen Ressourcenbedarf zuverlässig ermittelt. Und das wiederum ist hochgradig komplex und fast eine Wissenschaft für sich.
Denn an dieser Stelle hilft nur ein Abstieg tief in die Technikkatakomben der eigenen, noch jungen Firma. Erst einmal gilt: Solang es von einem Produkt noch gar keine Anwendung gibt, die der Version 1.0 zumindest nahekommt, sind alle Performance- und Ressourcen-Profile faktisch unbrauchbar und höchstens eine akademische Fingerübung. Zunächst müssen Sie also eine Vorabversion der jeweiligen Anwendung an den Start bringen, die sich realistisch messen lässt.
Eine zentrale Rolle spielen hier vor allem zwei Fragen: Einerseits die nach den genutzten Programmier- und Skriptsprachen und andererseits jene nach den benötigten Diensten zum Ausliefern der Anwendung. Den Alltag der allermeisten Administratoren etwa vermag man mit der Frage nach Apache Tomcat gründlich zu ruinieren. Nicht aus Versehen, denn Tomcat genießt den zweifelhaften Ruf, CPU-Leistung und RAM schneller zu verschlingen, als der Admin die entsprechenden Ressourcen erweitern kann. Der Tomcat-Einsatz geht einher mit der Nutzung von Jakarta EE (vormals Java EE), was vor allem für neue Apps nur noch selten Verwendung findet. Heute geben stattdessen moderne Sprachen wie TypeScript, Ruby, Go oder C# den Ton an. Auch Kotlin oder Swift erfreuen sich einer gewissen Beliebtheit.
Minimales Setup bauen
Ganz unabhängig von der genutzten Programmiersprache folgt die Bedarfserhebung einem relativ starren Schema. Es sieht im ersten Schritt vor, eine Proof-of-Concept-Installation (PoC) eines Minimum Viable Product (MVP) zu schaffen. Auf gut Deutsch steht dem jungen Unternehmen also die Aufgabe ins Haus, eine Testinstallation mit der (halbwegs) fertigen Anwendung zu erstellen, und zwar genauso, wie sie im Rechenzentrum oder beim Hyperscaler später laufen würde.
Die Anwendung selbst sollte dabei sämtlich unbedingt notwendigen Funktionen bieten, um das Produkt am Markt in einer Minimalversion erfolgreich zu platzieren. Die Ressourcen für den Betrieb der eigentlichen Anwendung gehören ebenso zum PoC wie nötige Ressourcen links und rechts, etwa persistenter Objektspeicher, auf den die Anwendung per S3-Protokoll zugreift. Darüber hinaus sollte ein solcher PoC bereits erforderliche Infrastruktur enthalten, konkret Monitoring, Alerting und Trending (MAT) und Log Aggregation.
Gerade das Trending von MAT nimmt dabei eine herausgehobene Position ein, auf die der Artikel später genauer eingeht. Soll eine Lösung für die Flottenverwaltung von Anwendungen zum Einsatz kommen, etwa Kubernetes, muss sich die ebenfalls im PoC wiederfinden – sie nimmt einen ordentlichen Schluck aus der Ressourcenpulle. Wohlbemerkt: Ein PoC muss keinesfalls auf echtem Blech entstehen. Hier ist ein günstiger Zwischenschritt, ein paar VMs entweder selbst zu hosten oder ad hoc einzukaufen. Damit lässt sich üblicherweise zufriedenstellend testen.
Achten Sie bitte darauf, dass das PoC-Setup der späteren Produktivumgebung auch im Hinblick auf genutzte Softwarekomponenten so gut wie möglich entspricht. Wer etwa auf Linux setzt und in Produktion später vor allem Ubuntu nutzen möchte, fährt seine initialen Tests idealerweise nicht mit Alma Linux oder RockyLinux. Zwar steckt bei all diesen Systemen unter der Haube ein Linux-Kernel. Je nach Distributor ist der aber um zahllose Patches angereichert, die die Ergebnisse erster Tests zum Teil erheblich verfälschen können.
Last erzeugen
Haben Sie sich einen PoC mit der fertigen Anwendung gebaut, steht im nächsten Schritt das Erzeugen von Last in dieser Umgebung auf dem Plan. Das lässt sich praktisch nicht generisch beschreiben – denn hier hängt ganz viel davon ab, welche Aufgabenschritte in der Anwendung abzuwickeln sind, wie der Zugriff durch Clients funktioniert oder welche Auswahlmöglichkeiten Clients bieten. Eine weitere Herausforderung: Zwar kann ein erster Test durchaus darin bestehen, dass man selbst die Anwendung aktiv nutzt und dadurch implizit auf Herz und Nieren prüft. Im Kontext des angeschlossenen MAT entstehen dabei auch bereits erste Messwerte. Doch wird eine Installation zu einem späteren Zeitpunkt ja idealerweise mehr Datenverkehr und mehr Nutzung ausgesetzt sein als durch einen einzelnen Client.
Es gilt also, möglichst viele parallele Anfragen zu generieren, um eine realistische Vorstellung der Situation zu bekommen. Eine Option dabei ist ein Test in der echten Welt mit Friendly Customers. Das sind Kunden, die noch nicht für die Nutzung des Produkts zahlen, es ansonsten aber normal verwenden. Eine Alternative dazu besteht darin, Lasttests automatisiert abzuspulen. Wie das im Detail funktioniert, hängt von der jeweiligen Anwendung ab.
Im Netz finden sich mehrere Lastgeneratoren für HTTP/HTTPS. Die Krux: De facto müssen Sie für einen aussagekräftigen Lasttest den gesamten Schatz der Funktionen, die eine Online-App bietet, in einem dieser Lastgeneratoren nachbauen. Das fällt leichter, wenn Sie die eigene Anwendung gleich so konstruiert haben, dass sie per API ansteuerbar ist und das Webinterface lediglich API-Kommandos generiert und sie an die APIs sendet. Moderne Mikroarchitekturanwendungen richten sich häufig nach diesem Prinzip. Darüber hinaus existieren am Markt sogar Werkzeuge, die in der Lage sind, eine laufende Browser-Session mitzuprotokollieren und daraus einen automatisierten Ablauf von Anfragen zu generieren. Im Anschluss lässt sich die Anwendung im Netz mit generischen Anfragen aus diesem Werkzeug bombardieren.
Details mit Prometheus
Danach schlägt die Stunde von Monitoring, Alerting und Trending. Besonders der Trending-Teil verlangt Aufmerksamkeit. Der besagt schon, dass es bei MAT um mehr geht als bloße Ereignisüberwachung. Vorrangig in skalierbaren Anwendungen spielt das Trending eine große Rolle. Denn beim Trending überwacht der Admin eine Umgebung kontinuierlich im 15-Sekunden-Takt hinsichtlich der momentanen Verwendung der verfügbaren Ressourcen. Bis auf die Ebene jedes (virtuellen) Systems erfasst die Trending-Software dabei basale Leistungswerte wie RAM-Verbrauch, CPU-Nutzung und benötigten Plattenplatz.
Der Königsweg für Trending führt gegenwärtig nach einhelliger Meinung über Prometheus (Abbildung 3) im Gespann mit Grafana (Abbildung 4). Prometheus [1] selbst ist dabei eine Zeitreihendatenbank, die Trending-Daten abspeichert und aus ihnen quasi als Abfallprodukt noch Ereignis-Monitoring-Daten generiert. Zum Erfassen des Ressourcenbedarfs eines Startups ist dieser Punkt aber zu vernachlässigen. Hier gilt es zunächst, die “Baseline” zu ermitteln, also die Last auf allen beteiligten Komponenten während des Grundbetriebs.
Abbildung 3: Prometheus gilt als Königsweg in Sachen Trending, wird aber nur im Gespann mit Grafana wirklich leistungsfähig.
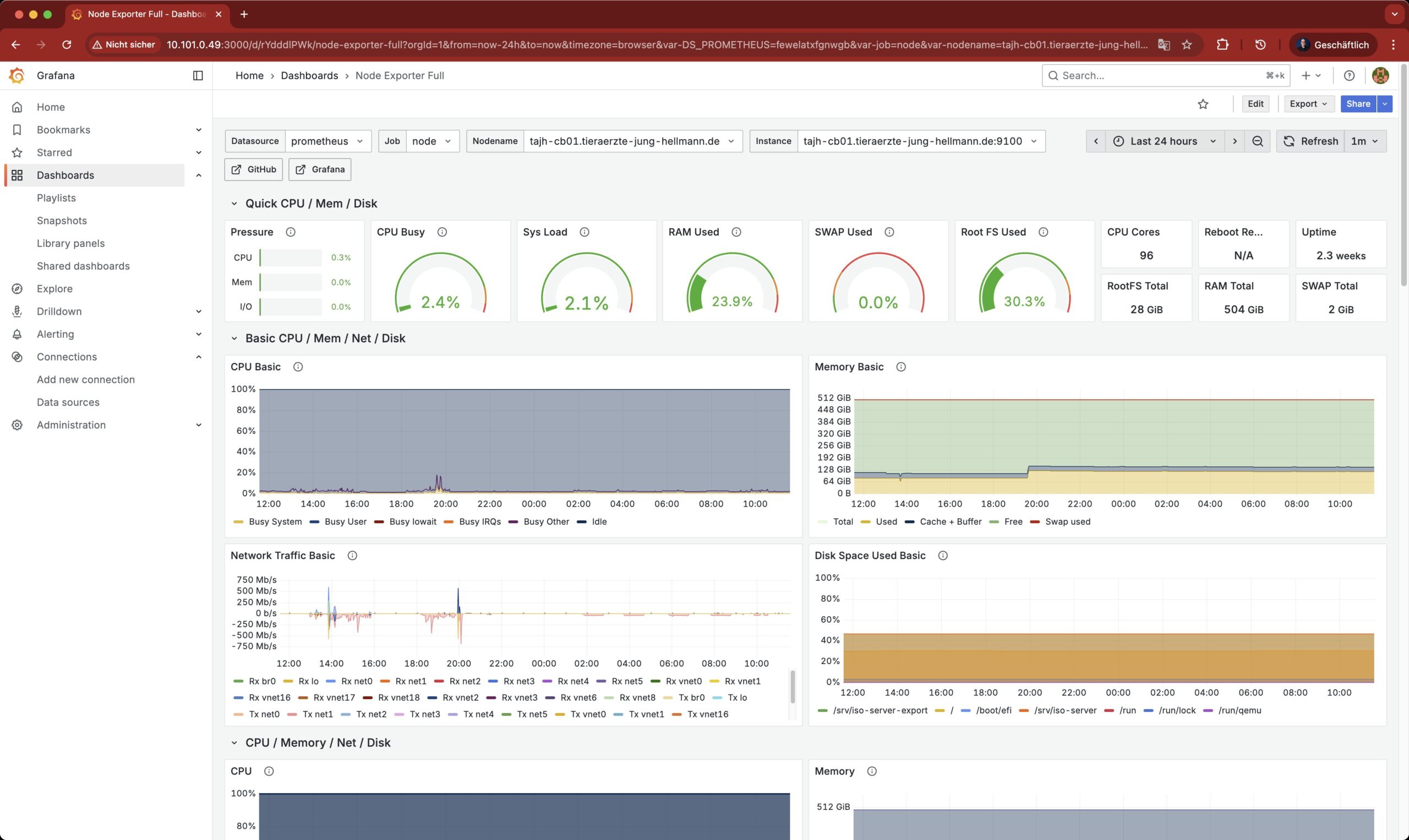
Abbildung 4: Der Node Exporter von Prometheus erfasst alle basalen Performance-Daten von Systemen, darunter CPU- und RAM-Last, die sich gut für Auswertungen eignen.
Bei neuen Anwendungen, die ihren Weg in die Produktion erst noch finden müssen, ist das die Grundlast der laufenden Komponenten. Dementsprechend gilt es also, in den genutzten Systemen der Umgebung Komponenten wie den Prometheus Node Exporter [2] an den Start zu bringen, um sie hinsichtlich der genutzten Ressourcen zu überwachen. Kommen weitere Serverkomponenten wie Tomcat [3] oder Datenbanken wie MariaDB [4] zum Einsatz, existieren für sie eigene Exporter für Prometheus. Deren Installation wirkt manchmal etwas hemdsärmelig, lässt sich aber mittels Ansible oft gut automatisieren. All diese Exporter müssen dort laufen, wo auch die Anwendungen laufen, die die App zum Leben erwecken.
Setzt ein Produkt auf Kubernetes unter der Haube, lässt dieses sich üblicherweise über Custom Resource Definitions (CRDs) [5] hervorragend in K8s integrieren und darüber installieren. Wichtig ist außerdem, zusammen mit Prometheus Dashboards in Grafana [6] auszurollen, über die sich zentrale Komponenten wie CPU-Nutzung und RAM sowie die wichtigsten Vitalwerte der genutzten Komponenten im Auge behalten lassen. Das eröffnet die Möglichkeit, sich mit wenigen Mausklicks einen umfassenden Überblick über die aktuelle Ressourcensituation zu verschaffen.
Dann erst beginnt die eigentliche Arbeit: Ist die Baseline erfasst, setzen Sie das Setup idealerweise sukzessive immer heftigerer Last aus, etwa durch mehr konkurrierende Anfragen. Dabei entstehen Metrikdaten, die anschließend in Grafana dargestellt werden und mit der steigenden Last korrelieren. Wer sich nicht die Mühe machen und separate, automatisierte Lasttests für die eigene Anwendung entwickeln möchte, greift zu einem Trick. Können Sie zum Beispiel einen Vergleich zwischen der Situation mit einem, fünf und 20 konkurrierenden Nutzern herstellen, notfalls auch über manuelle Abfragen, lässt sich die Entwicklung der Last danach über die Vorhersagefunktionen von Prometheus oder Grafana hochrechnen. Das ist nicht absolut genau, gibt aber zumindest Anhaltspunkte – freilich unter der Annahme, dass die Last sich linear entwickelt. Verhält sich die entwickelte Anwendung bei 1000 Nutzern fundamental anders als bei 20, greifen die Prognose-Features der genutzten Werkzeuge nicht. Bitte bedenken Sie außerdem, dass Grafana und Prometheus Last stets linear hochrechnen. Wer also eine Fernsehwerbung schaltet und dadurch punktuell exponentiell wachsende Zahlen beim Zugriff produziert, kann das ebenfalls nicht sinnvoll vorhersagen.
Anwendungen profilieren
Der letzte Schritt bei der Errechnung benötigter Ressourcen befasst sich mit dem Profiling der Apps selbst. Das fällt noch genauer aus als die Überwachung mit Grafana und Prometheus, zielt zum Teil aber auf andere Faktoren ab. Wer beispielsweise Coroot [7] nutzt, kann detailliert aufzeigen, wie sich die Anwendung unter Last verhält und wo Performance-Engpässe lauern.
Gerade Lösungen wie Coroot (Abbildung 5) erleichtern Entwicklern hier die Arbeit. Sie implementieren ihre Instrumentalisierung mittels eBPF [8], eine direkte Anbindung an ein Profiling-Werkzeug etwa über Open Telemetry im Code braucht es dementsprechend nicht. Gerade Werkzeuge wie Coroot zeigen zudem auch auf, wie sich Zugriffszeiten unter Last entwickeln. Das gibt Hinweise auf Optimierungspotenzial. Zusammen mit den MAT-Daten aus dem vorherigen Schritt sind diese Trending-Daten mithin ein wichtiges Werkzeug, um die Applikation flotter und damit besser zu machen.
Abbildung 5: Coroot lässt sich hervorragend für die Profilierung von Anwendungen nutzen und ergänzt MAT mit Prometheus und Grafana um wertvolle Daten zur Verbesserung des Programms.
Fazit
Neben der Wahl der gewünschten Zielplattform ist für Startups vor allem die Wahl der Toolchain für die sinnvolle Überwachung einer PoC-Installation wichtig. Hier bietet sich das Open-Source-Kit aus Prometheus und Grafana an. Ergänzt um leistungsstarke Werkzeuge wie Coroot entsteht ein stimmiges Gesamtbild des Ressourcenfußabdrucks eines Programms. Er erlaubt die Planung der benötigten Ressourcen für den Go-live ebenso wie für die nötige Skalierung in naher wie ferner Zukunft. (jcb)
Infos
- Prometheus: https://prometheus.io/
- Node Exporter: https://prometheus.io/docs/guides/node-exporter/
- Tomcat Exporter: https://github.com/nlighten/tomcat_exporter
- MariaDB Exporter: https://github.com/prometheus/mysqld_exporter
- CRDs: https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/
- Grafana: https://grafana.com/
- Coroot: https://coroot.com/
- eBPF: https://ebpf.io/





