
© Sergiy Tryapitsyn / 123RF.com
Oh, verdammt! Es ist schon Freitag 15 Uhr, und ich habe kommende Woche Urlaub! Da muss ich schnell noch ein paar offene Themen erledigen.
“Eile macht Arbeit, die Vorsicht verhindert”, sagte einst William Penn. Ich bin wahrlich weder religiös noch abergläubisch, aber ich habe einen Grundsatz: keine spontanen, tiefgreifenden Changes vor dem Wochenende. Das bedeutet nicht, dass ich nicht am Wochenende eine größere Migration von Produktivsystemen umsetzen würde, nein. Das bedeutet vielmehr, dass ich nicht am Freitag spontan und ungeplant einen Change Request anstoße, um eine Lücke in der Projektzeiterfassung zu füllen, nur, weil ich gerade noch etwas Luft habe.
Ich weiß nicht, ob das Meme [1] vom Read-only-Friday [2] auch jüngeren Lesern bekannt ist. Definitiv kommt das Meme allerdings nicht von ungefähr. Doch warum eigentlich Read-only-Friday? Alle in der IT arbeitenden Menschen gelangen irgendwann an den Punkt, an dem ein bislang produktives IT-System einem größeren Change unterworfen wird. Möglicherweise wird das System während einer Wartung gepatcht – wahrscheinlich der unproblematischste Fall. Alternativ könnte an einem System eine größere Migration stattfinden, etwa von einem bisherigen Database-Management-System auf ein neues – von Oracle zu PostgreSQL, von MS SQL Server zu MariaDB und so weiter.
Am Ende steht gar ein kompletter Umzug ins Haus. Das hieße, dass jemand die Kapazität des Speicherplatzes im Blick behalten muss. Dasselbe gilt selbstverständlich für das Backup-Device. Datenbanken schreiben Transaction-Logs, sofern sie korrekt eingerichtet sind. Vielleicht braucht es auch jemanden, der in der VMware-Landschaft Maschinen ausrollen und konfigurieren sowie Snapshots erzeugen und resetten kann. Dazu kommt DNS, und das gleich mehrfach: Mindestens einmal für den Application Server, mindestens einmal für das DBMS und vermutlich noch einige Male mehr für diverse Satellitensysteme, die bislang womöglich vom Schirm verschwunden waren.
Kein Lückenfüller
Es liegt also auf der Hand: Eine solche Aufgabe will gut geplant sein und kann eben nicht als Lückenfüller am Freitagnachmittag herhalten. Tatsächlich stufe ich die genannten Fälle zweifellos als eigenständige Projekte ein. Weder den Tausch einer Datenbank noch den physikalischen Umzug in ein neues Rechenzentrum, in die Cloud, oder wenigstens in einen neuen Namensraum interpretiere ich als kleinere Aufgabe – und zwar aus Erfahrung.
Es ist mir nahezu nie untergekommen, dass derlei Anforderungen zeitlich, personell und hinsichtlich ihrer Komplexität im Rahmen eines kleineren Aufgabenpakets geblieben wären. Im Gegenteil endeten solche Unterfangen, falls unterschätzt, mitunter in einem handfesten Debakel. Nicht wegen der Unfähigkeit der damit betrauten Personen, sondern vielmehr, weil dazu Personen erforderlich gewesen wären, die nie eingeweiht waren.
Schlechte Planung beschränkt sich aber bei Weitem nicht auf den Freitag. Wer größere Umstellungen beabsichtigt, tut das idealerweise in einer eigenen Lab-Umgebung. In solch einem Sandkasten dürfen Dinge schiefgehen. Dort protokollieren wir Fehler und passen die entsprechenden Prozesse und Routinen an. Selbstverständlich bedeutet ein Erfolg in der Testumgebung noch lange keinen Erfolg bei der Produktivumgebung, allerdings treten dort Engpässe offen zutage.
Dazu gehören Zeit – schaffen wir das Projekt überhaupt an einem Wochenende? – und ausreichend Ressourcen. Es käme einer Katastrophe gleich, erst am Sonntagnachmittag zu bemerken, dass weder für Datenbankdateien noch für Transaction-Logs oder Backups ausreichende Kapazitäten zur Verfügung stehen. Solche Erfahrungen lassen sich in sprichwörtlichem Gold aufwiegen!
Nicht jede Transaktion müssen Sie gleichermaßen aufwendig testen. Mein ehemaliger Professor für Softwaretechnik und Projektmanagement pflegte stets zu sagen: “Kleine Projekte sind anders zu handhaben als große Projekte.” Vermutlich hatte er damals dabei noch nicht das Wort Agilität im Kopf, aber seine Ausführungen gingen in eine ähnliche Richtung. Es ergibt kaum Sinn, für eine mit einem Personentag Aufwand geschätzte Aufgabe eine einwöchige Testphase anzuberaumen. Idealerweise erstellen Sie entsprechende Backups und landen im Ernstfall bei wenigen Stunden Verzug.
Simulanten
Um den Admin bei solchen Tests zu unterstützen, bieten inzwischen einige Tools sogenannte Dry-run-Optionen an. Dahinter verbergen sich Trockenläufe, bei denen die Software die tatsächliche Arbeit lediglich simuliert. Zu den interessantesten gehören hier meiner Meinung nach Rsync, Make und Ansible.
Ich habe Kollegen erlebt, die – aus welchem Grund auch immer – bei Rsync Quelle und Ziel vertauschten. Den Aufruf hatten sie ohne vorherigen Abgleich mit der Manpage irgendwo aus dem Internet kopiert und direkt in die Root-Shell eingefügt. Das Ergebnis: Das Kommando aus der ersten Zeile von Listing 1 kopierte zwar im Archive-Mode (»-a, –archive«) alle Berechtigungen und Ownerships, allerdings in die falsche Richtung.
Der Schalter »–delete« führte dazu, dass sämtliche Dateien, die sich nicht im Quellordner befanden, aus dem Zielordner gelöscht wurden. Bei Verwechslung von Quelle und (leerem) Ziel gewann dieses Missverständnis im Nu an Tragik. Das ist außerdem der richtige Moment, um ein Backup zur Hand zu haben.
Listing 1
Rsync-Test
$ rsync -av --delete SOURCE DESTINATION
$ for i in {1..15000}; \
do touch $(printf "%05d\n" $i).dat; \
done
Zur Verdeutlichung habe ich die Verzeichnisse »SOURCE/« und »DESTINATION/« angelegt und per Bash 15 000 Dateien in Source erzeugen lassen (Listing 1, ab Zeile 2). Das Resultat zeigt Abbildung 1. Anschließend starte ich Rsync wie oben beschrieben, um zu demonstrieren, wie schnell das Tool den Quellordner leer räumt.
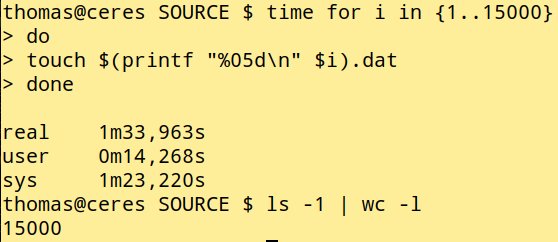
Abbildung 1: Testfall: mit wenig Code 15 000 Dateien erzeugen.
Fürs Erzeugen der 15 000 leeren Dateien benötigt mein eher schwachbrüstiger Testrechner über 93 Sekunden. Wie in Abbildung 2 zu sehen, arbeitet Rsync da viel effizienter. Nicht einmal eine Sekunde braucht das Tool, um alle Dateien zu löschen. Wer also Rsync via »–delete« mit dem Löschen beauftragt, besitzt kaum eine Chance, seinen Fehler noch zur Laufzeit zu erkennen und den Vorgang abzubrechen.
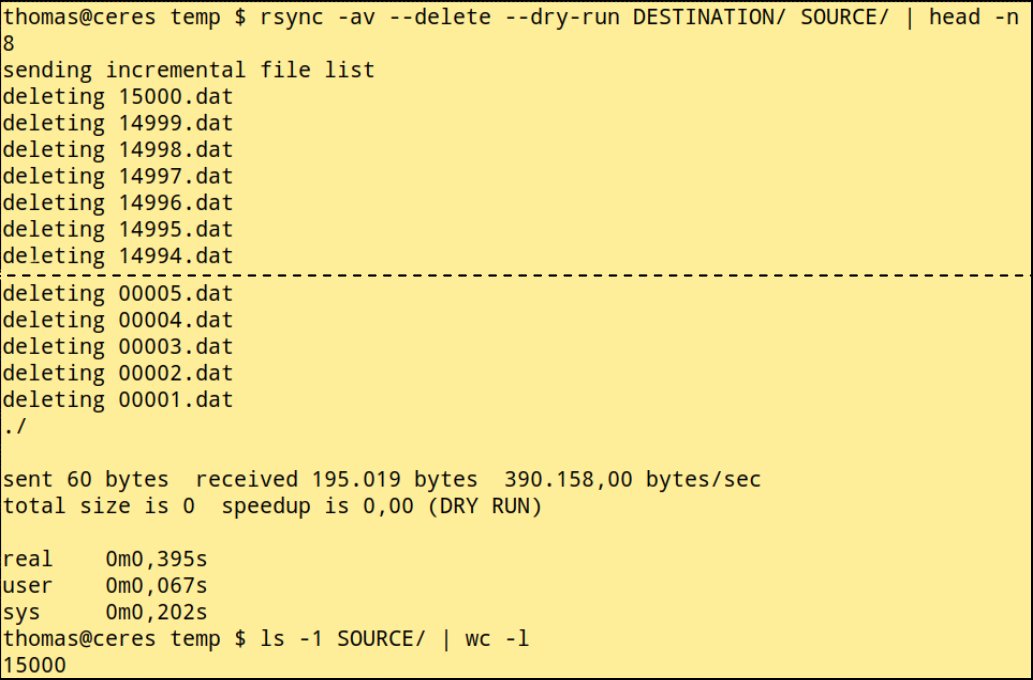
Abbildung 2: Rsync kann einen Testlauf mittels Dry-run-Option ausführen.
Ein zweiter Test mit aktivem Schalter »–dry-run« hilft, solche Fehler zu vermeiden. Wie ebenfalls in Abbildung 2 gezeigt, beansprucht meine kleine Testmaschine für den Trockenlauf sogar nur ungefähr ein Drittel der Zeit wie für den Echtlauf. Dementsprechend lohnt es sich, diese Option im Kopf zu behalten. Viel wichtiger ist jedoch, dass Rsync selbst die zu löschenden Dateien auflistet. Damit sollten katastrophale Verwechslungen der Vergangenheit angehören.
Trockenübung
Der Debian Paketmanager Apt beherrscht ebenfalls Dry-runs. Aktivieren kann ich den Simulationsmodus gleich über mehrere Schalter, von »-s« über »–simulate« und »–just-print« bis hin zu »–dry-run«. Das funktioniert auch als nicht privilegierter User.
Wenn Sie umfangreichere Umbauten am System planen, beispielsweise den Umstieg von Gnome auf KDE beziehungsweise von Ubuntu auf Kubuntu, sind Sie gut beraten, Apt zunächst einen Dry-run starten zu lassen. Damit erkennen Sie, was am System verändert wird und wie viele Hunderte Pakete zusätzlich installiert werden müssen.
Ich kann mich noch gut erinnern, dass jemand in meinem Bekanntenkreis, warum auch immer, die Glibc deinstallieren wollte. Kurzerhand hat die Person dabei das komplette System zerstört. Ein Aufruf von »sudo apt remove libc6« hätte vermutlich als Warnung genügt. Die Ausgabe könnte kaum weniger Unheil versprechen: Eine illustre Clique mit Mitgliedern wie Bash, Coreutils, Init, Util-linux, Tar, Grep, Login und viele mehr werden als zur Deinstallation vorgemerkt ausgegeben. Wer des Lesens mächtig ist, kapiert spätestens an dieser Stelle, dass er mit seinem Vorhaben gewaltig auf dem Holzweg ist.
Allzweck-Ansible
Auch Ansible reiht sich in den Kreis der Tools ein, die sich eignen, um große Zerstörung anzurichten, die aber auch Gelegenheit bieten, dem Desaster durch Simulationen vorzubeugen. Der sogenannte Check-Mode versucht weitestgehend, die Änderungen am Zielsystem zu simulieren, ohne tatsächlich Veränderungen vorzunehmen. Sie aktivieren ihn mittels des Parameters »-C« beziehungsweise »–check«.
Wichtig ist dabei zu wissen, dass bei Weitem nicht alle Module den Check-Mode implementieren. Die meisten Core-Module sollten allerdings genau das tun. Im Umkehrschluss sollten Sie hier besonders gut achtgeben. Obwohl der Probelauf eines Playbooks im Check-Mode sauber aussieht, gibt es keinerlei Garantie, dass ein echter Lauf problemlos funktioniert.
Innerhalb von Playbooks gibt es einen relativ ungünstig benannten Schalter: »check_mode: yes/no«. Ansible-Tasks, die unabhängig davon, ob der Check-Mode aktiv ist, stets im Normal-Mode ablaufen sollen, zeichnet man mit »check_mode: no« aus. Stellen Sie sich hier Fälle vor, in denen lediglich lesender Zugriff stattfindet, also Tasks, die sowieso keinerlei Veränderungen am System vornehmen.
Tasks, die unabhängig vom angegebenen Check-Mode grundsätzlich im Check-Mode ablaufen sollen, markieren Sie mit »check_mode: yes«. Diese Variante bietet sich im Wesentlichen für tatsächliche Testfälle an, in denen Variablen, Bedingungen und so weiter, die unter Umständen zu Änderungen führen könnten, grundsätzlich im Test-Modus laufen sollen. Werfen Sie dazu bitte einen Blick auf Listing 2.
Listing 2
Ansible-Tasks mit check_mode
---
- name: Check-Mode-Tests
hosts: debian_servers
tasks:
- name: Task wird immer Änderungen am System durchführen, selbst im Check-Mode
command: df -h /usr/
check_mode: no
- name: Task wird stets im Check-Mode ausgeführt und nie das System ändern
lineinfile:
line: "hostname"
dest: /etc/motd
state: present
check_mode: yes
Fazit
Wie schon das Sprichwort sagt: Vorsicht ist die Mutter der Porzellankiste. Genauso sollten Sie es in der IT handhaben. Überstürzter Aktionismus hat noch nie geholfen, weil er error-prone ist, also fehleranfällig. Obendrein erreichen Sie, wenn überhaupt, das gewünschte Ergebnis nur mühsam.
Ich möchte keineswegs Dijkstra überstrapazieren, der mit “Durch Testen kann man stets nur die Anwesenheit, nie aber die Abwesenheit von Fehlern beweisen” einen der meistzitierten Gemeinplätze der IT geschaffen hat. Viele Fehler lassen sich vermeiden, viele andere eingrenzen. Mit den richtigen Vorkehrungen, mit Lab-Umgebungen, mit Backups und Unit-Tests bis hin zu Dry-runs steigern Sie die Chance, dass am Ende etwas Sauberes herauskommt. Zusätzlich ruinieren Sie sich nicht mit einem Verstoß gegen das Read-only-Friday-Gebot das Wochenende oder den Urlaub. (csi)
Infos
- Quelle: https://www.reddit.com/r/networkingmemes/comments/16vcyzs/happy_readonly_friday/
- “Is It Read-Only Friday?”: https://isitreadonlyfriday.com





