
© Dan Comaniciuo / 123RF.com
Das Pareto-Prinzip gilt auch bei der Datenanalyse: 20 Prozent der Zeit beschäftigt sich der Analytiker mit der Auswertung, die Hauptarbeit liegt im Bereinigen der Daten.
Wie lassen sich Fehler in Daten erkennen und bereinigen? Bei gewöhnlichen Datensammlungen helfen einfache statistische Verfahren. Dieser Artikel beschäftigt sich jedoch mit Zeitreihen, wo jeder Messwert aufgrund seines Zeitstempels einzigartig ist. Das erfordert eine etwas andere Vorgehensweise, die wir im Folgenden beschreiben.
Daten
Um die Arbeitsweise der folgenden Skripte leichter nachvollziehen zu können, benötigen wir einen Fake-Datensatz. Den erzeugt eine Python-Funktion. Sie simuliert die elektrische Leistung eines 100-Watt-Solarpanels, das eine Woche lang Leistungsdaten liefert. Eine zweite Funktion greift dann zerstörerisch in den Datensatz ein. Nach der Bereinigung soll der malträtierte Datensatz den ursprünglichen Daten möglichst ähnlich sein. Das gelingt erstaunlich gut, obwohl ein Teil der Daten überschrieben wurde. Dabei wurden die folgenden Fehler in die Original-Daten eingebaut:
- falscher Datentyp (String statt Zahl)
- fehlende Einzelwerte
- fehlende Wertesequenzen
- große Ausreißer und Platzhalter für fehlende Werte (hier »9999«)
- Ausreißer, die innerhalb des Wertebereichs liegen
- Lücken im Zeitablauf, ungleichförmige Zeitabstände
- sich wiederholende Datensätze, Dubletten
- nicht chronologische Zeitstempel
Selbst die erfolgreichste Datenbereinigung kann nicht zaubern. Als falsch erkannte Werte hinterlassen zwangsläufig eine Lücke. Zwar lassen sich Lücken schließen, wie wir noch sehen werden, doch dabei lässt sich fehlende Information nicht vollends ersetzen. Manche Fehler sind leicht zu finden, etwa die großen Ausreißer. Gravierendere Probleme bereiten Fehlwerte, deren Größe innerhalb der Spanne der erwartbaren Werte liegt.
Wir stellen hier einen pragmatischen Ansatz vor, der viele Falschwerte erkennt, aber einige False-Positive-Werte nicht ausschließen kann. Die Funktion »fakedata()« (Listing 1) generiert einen Datensatz, der die Leistungswerte eines 100-Watt-Solarmoduls über eine Woche in zehnminütigem Abstand simuliert. Nachts liefert die Anlage keine Leistung. Schlechtes Wetter gibt es nicht, wohl aber eine sanfte Modulation, die zur Wochenmitte mehr Strom bereitstellt als an den Wochenenden. Die Leistungsdaten »power« sind vom Datentyp »float«, die von »date« zunächst vom Datentyp »object (string)«.
Listing 1
fakedata()
import numpy as np import pandas as pd def fakedata(): """ Simulate electric power data for one week, one value per 10 minutes """ ndays = 7 # duration in days pointsph = 6 # points per hour; if changed, change " freq='10min' " below as well. ppd = np.arange(0,pointsph*24) # points per day dpower = ppd*0. # power during day dpower[6*pointsph:18*pointsph] = np.cos(ppd[6*pointsph:18*pointsph]/(pointsph*24)*np.pi*tpower = np.concatenate([dpower]*ndays) date = pd.date_range(freq='10min', start='2024-01-01',§§ periods=len(tpower)).astype(str).df = pd.DataFrame(dict(power=tpower, date=date)) df['power'] = df.power * (0.8 * np.sin(df.index/len(df)*np.pi)+0.2) return df
Um später die Daten besser vergleichen zu können, ersetzt im Dataframe »dfd« das Datum den Index. Der Datums-String liegt im ISO-8601-Format vor, sodass die Funktion »to_datetime()« ihn problemlos in ein »datetime«-Objekt umwandelt. Den resultierenden Plot zeigt Abbildung 1.
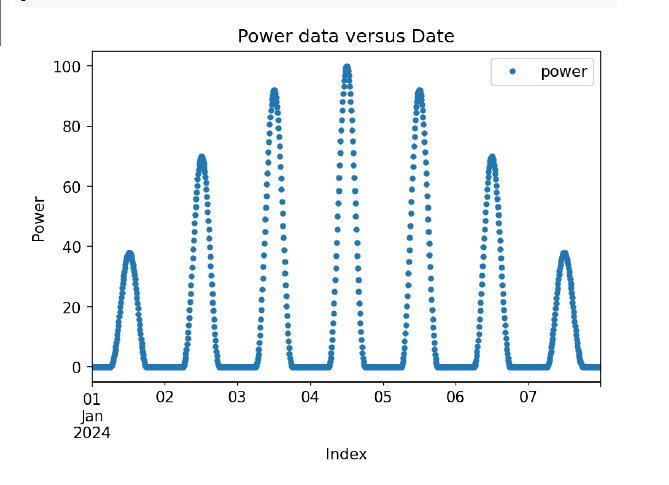
Abbildung 1: Die Leistung des beispielhaften Solarmoduls über die Zeit.
Die in der beobachteten Zeitspanne gelieferte Energie ist das Integral über die Messpunkte nach der Zeit. Entweder berechnet man sie mit der NumPy-Trapezformel »trapezoid()« oder einfacher über das Produkt aus mittlerer Leistung multipliziert mit der Zeitspanne. Das im Download-Bereich zu diesem Artikel bereitstehende Jupyter-Notebook mit dem Python-Code enthält beide Versionen. Die Simulation erreicht bei einem optimal ausgerichteten Solarmodul mit 100 Watt Peak-Leistung einen Gesamtwert von 3 kWh in einer Woche.
Daten schädigen
Im nächsten Schritt geht es darum, die Daten mutwillig zu verfälschen, um später etwas bereinigen zu können. Das erledigt der Code in Listing 2, dessen Eingriffe fast 70 Prozent der Ursprungsdaten verändern.
Listing 2
Daten schädigen
missing_rows = 0.2 ### missing rows
missing = 0.3 ### drop "power" values
missing_date = 0.3 ### rename "date" values to 'no date'
hide = 0.1 ### empty values (not nan)
outliers= 0.05 ### value: 9999
outliers_sml = 0.05 ### value: 80 (0.05 == 30 values was too big)
rng = np.random.default_rng(42)
# dg = df[['power', 'date']].copy()
dg = df.copy()
# dg = df.copy()
### remove rows
to_remove = rng.choice(list(range(len(dg))), int(len(dg)*missing_rows), replace=False)
dg = dg.drop(dg.index[to_remove], axis=0)
print('Removed rows: ', int(len(dg)*missing_rows))
### remove "power" data
to_remove = rng.choice(list(range(len(dg))), int(len(dg)*missing), replace=False)
dg.iloc[to_remove,0]= np.nan
print('Power NaN values: ', int(len(dg)*missing))
### remove "date" data
to_remove = rng.choice(list(range(len(dg))), int(len(dg)*missing_date), replace=False)
dg.iloc[to_remove,1]= 'no date'
print('Date NaN values: ', int(len(dg)*missing_date))
### replace by ''
dg['power'] = dg.power.astype(str)
to_change = rng.choice(list(range(len(dg))), int(len(dg)*hide), replace=False)
dg.iloc[to_change,0]= ''
print('Hidden values by empty string: ', int(len(dg)*hide))
### large outliers
to_change = rng.choice(list(range(len(dg))), int(len(dg)*outliers), replace=False)
dg.iloc[to_change,0]= 9999
print('Large "9999" outliers: ', int(len(dg)*outliers))
### small outliers
to_change = rng.choice(list(range(len(dg))), int(len(dg)*outliers_sml), replace=False)
dg.iloc[to_change,0]= 80
print('Small "80.00" outliers: ', int(len(dg)*outliers_sml))
### reverse order
dg = pd.concat([dg.iloc[:500,:], dg.iloc[:499:-1,:]], axis=0)
### duplicate values
dg = pd.concat([dg.iloc[:,:], dg.iloc[490:520,:]], axis=0)
### remove information about ordering, create new index
dg = dg.reset_index(drop=True)
Um ein Gefühl für die Schäden zu bekommen, bestimmen wir die Energiesumme. Die Ursprungsdaten lieferten einen Wert von 3 kWh. Ein Aufruf der Funktion »power()« scheitert jetzt jedoch zunächst. Sie beschwert sich mit der Fehlermeldung »Error: could not convert string to float« über den Datentyp.
Die Ursache ist ein Automatismus von Pandas: Es wählt für eine Spalte den Datentyp aus, der auf alle Werte zutrifft. Ein einziger Ausdruck, der sich nicht als Zahl darstellen lässt, genügt, um die Werte dem Typ »object« zuzuordnen. Als Gegenmaßnahme erzwingt die Funktion »to_numeric()« die Umwandlung in eine Zahl:
dg['power'] = pd.to_numeric(dg['power'], errors='coerce')
Dort, wo sie fehlschlägt, bricht die Funktion ab. Mit dem Parameter »errors=’coerce’« ersetzt sie nicht passende Werte durch »NaN«. Eine vorläufige Umwandlung des Datums-Strings in einen Datumsindex erlaubt den Vergleich beider Datensätze (Listing 3). Den zugehörigen Plot zeigt Abbildung 2.
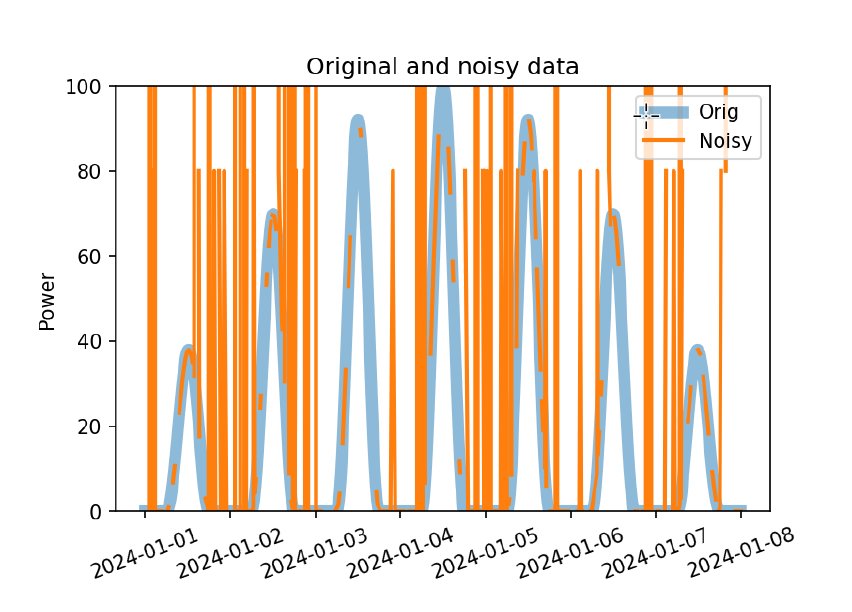
Abbildung 2: Die Originaldaten und gewollt verrauschte Daten im Vergleich.
In der Rohform sind die künstlich verrauschten Daten praktisch unbrauchbar. Während die Originaldaten eine Energie von knapp 3 kWh ausweisen, liefert die Funktion »power()« nun eine Energie von mehr als 100 kWh.
Listing 3
Vergleich der Datensätze
dgd = dg.copy()
dgd['tdate'] = pd.to_datetime(dgd.date, errors='coerce')
dgd = (dgd[~dgd.tdate.isnull()]
.set_index(['tdate'])
.loc[:,['power']])
plt.figure(figsize=(6,4), dpi=150)
plt.title('Original and noisy data')
plt.plot(dfd.index, dfd.power, alpha = 0.5, lw=6, label='Orig')
plt.plot(dgd.index, dgd.power, lw=2, label='Noisy')
plt.ylim(0,100)
plt.xticks(rotation=20)
plt.ylabel('Power')
plt.legend()
plt.show()
Daten bereinigen
Der erste Schritt entfernt die leicht als solche erkennbaren Ausreißer. In unserem Beispiel fungiert die Zahl »9999« als Platzhalter für fehlende Werte. Statt nach ihr zu suchen, definieren wir eine Schwelle und verwerfen alle Zahlen oberhalb des Schwellwerts.
In Anlehnung an eine Normalverteilung gilt die Vermutung, dass gültige Werte nur wenig um den Mittelwert streuen. Der sogenannte Z-Score dient als Kriterium:

Ist ein Wert größer als der dreifache Z-Score, gilt er als Ausreißer. Bei einer Normalverteilung würde das auf weniger als 1 Prozent der Werte zutreffen (Abbildung 3).
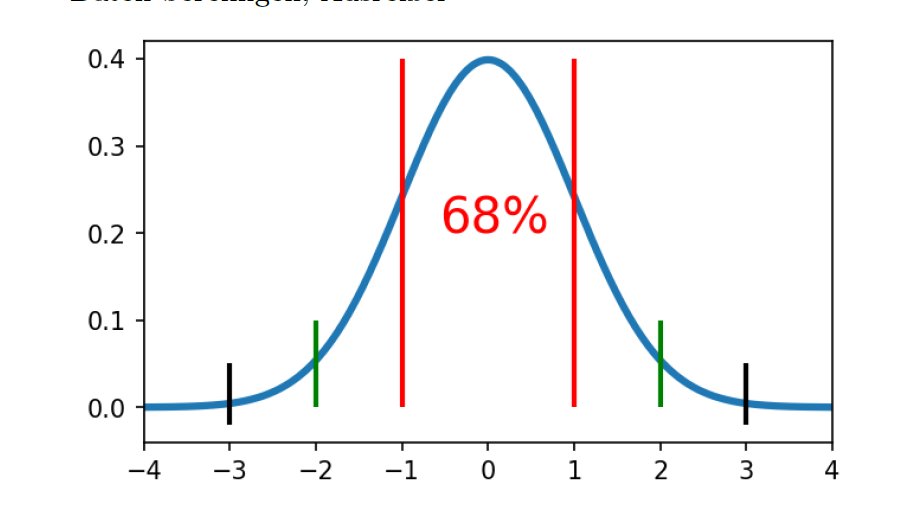
Abbildung 3: Geht man von einer Normalverteilung aus, muss sich die Mehrheit der Messwerte um den Mittelwert gruppieren.
Bei großen Datenmengen fehlt die Zeit, jeden Wert einzeln zu überprüfen. Daher löscht in Listing 4 der Befehl »dhd[~dhd[‘power’].isnull()]« alle nicht belegten Werte. Die schräg laufende Linie in Abbildung 4 erinnert an die Fehler der Zeitzuordnung in der gestörten Datendatei.
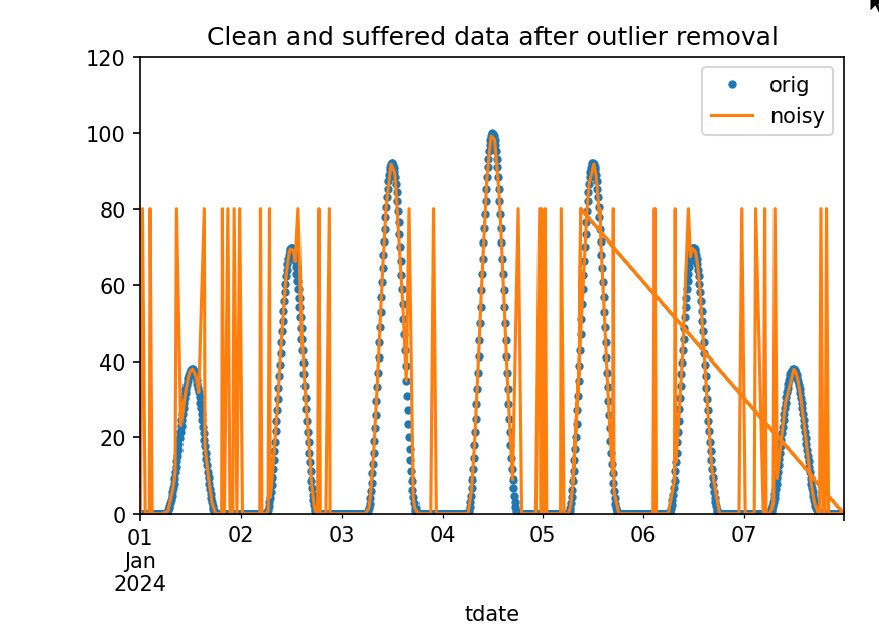
Abbildung 4: Originaldaten und gestörte Daten nach der Ausreißerentfernung.
Listing 4
Ausreißer entfernen
# Start cleaning, save raw data in dgd
dhd = dgd.copy()
mmean, mstd = dhd.power.mean(), dhd.power.std() # 816 +- 2705
zscores = 3* (dhd.power - mmean)/mstd
print('size before cleaning: ', dhd.shape, '; #outliers: ', len(dhd[zscores>1]))
# remove outliers
dhd = dhd.drop( dhd[zscores>1].index, axis=0)
print('size after oulier cleaning: ', dhd.shape)
size before cleaning: (589, 1) ; #outliers: 31
size after oulier cleaning: (558, 1)
dhd = dhd[~dhd['power'].isnull()]
Datumswerte korrigieren
Pandas kennt eine mächtige Methode, um den Zeitindex zu korrigieren: das Resampling (Listing 5). Das kleinste Zeitintervall zwischen den Messwerten liegt bei 10 Minuten. Die Methode ».resample(’10min’).mean()« erzeugt einen neuen Index. Er deckt die gesamte Zeitspanne vom ersten bis zum letzten Zeitstempel ab, in Schritten von zehn Minuten. Innerhalb der Intervalle aggregiert er die Daten, hier als Mittelwert.
Listing 5
Resampling (Auszug und Anwendung)
dmd = dhd.copy()
dmd = dmd.resample('10min').mean()
print(dmd.shape) # (1008, 1)
"""
# dmd.head(3)
-----------------------
tdate power
-----------------------
2024-01-01 00:00:00 0.0
2024-01-01 00:10:00 NaN
2024-01-01 00:20:00 NaN
-----------------------
"""
Die gestörte Chronologie der verrauschten Daten korrigiert sich automatisch. Dubletten verschwinden durch die Mittelung über die Intervalle. Der Befehl vergrößert die Zahl der Zeilen auf über 1000. Für viele der Datenpunkte gibt es keine zugehörigen Messwerte. Hier schreibt die Operation den Wert »NaN« hinein.
Als Vorbereitung für den nächsten Schritt erhält jede Datenzeile in der Spalte »dateindex« eine Indexzahl. Das ist einfacher, als das Datum in eine Zahl zu konvertieren. Nach dem Löschen aller Leerdaten im nächsten Schritt spiegeln sich die Lücken auch in »dateindex« wider (Listing 6). Das Datenvolumen reduziert sich um 60 Prozent.
Listing 6
Neu indizieren
dmd['dateindex'] = np.arrange(Len(dem)) #did.info() print(dmd.shape) dmd = dmd[~dmd['power'].isnull()]
Fehlwerte finden
Der nächste Schritt ist der schwierigste. Er ermittelt, welche Werte nicht in den Kurvenverlauf passen, obwohl sie sich im Wertebereich nicht von korrekten Werten unterscheiden. Um die Bereinigungsschritte zu überprüfen, haben wir für die gestörte Datei leicht identifizierbare Zahlen gewählt. So wurden 40 Werte mit der Zahl 80 überschrieben. In der Grafik stechen sie als Peaks konstanter Amplitude hervor.
Vom Wissen um die Datenstruktur wollen wir hier jedoch keinen Gebrauch machen – anderenfalls wären die Fehlwerte in den Nachtstunden leicht zu erkennen. Verfahren wie Isolation Forests oder Local Outliers Finder (LOF) eignen sich für die hier gestellte Aufgabe. Es würde hier zu weit führen, die Arbeitsweise im Einzelnen zu erläutern. Stattdessen demonstrieren die Python-Aufrufe aus Listing 7 das Ergebnis von LOF. Die Information, wie nahe Werte beieinander liegen, bezieht LOF aus dem Hilfsindex.
Listing 7
Local Outlier Finder
from sklearn.neighbors import LocalOutlierFinder X = dmd[['power', 'dateindex']] clf = LocalOutlierFactor(n_neighbors=16, contamination=0.045) # 16 / 15 y_pred = clf.fit_predict(X) X_scores = clf.negative_outlier_factor_ print(len(dmd[y_pred == -1])) outlier_candidates = dmd[y_pred == -1]
Von den 32 verbliebenen Falschwerten erkennt das Verfahren 16, mit nur einem falsch positiven Wert. Angesichts der Schwierigkeit, dass keine A-priori-Information über die Daten einflossen, darf das als passables Ergebnis gelten. Um den Automatisierungsprozess nicht zu unterbrechen, werden alle 16 Daten gelöscht, darunter der falsch positive Wert. Zurück bleiben 330 Datenzeilen.
Die Quelldaten verzeichnen einen Wert alle 10 Minuten. Die Information der bereinigten Daten ist auf über 60 Prozent (330 Werte) geschrumpft. Analysiert man die Verteilung der fehlenden Werte, ergibt sich, dass Einzellücken 65-mal auftreten, Zweierlücken 51-mal. Ketten mit mindestens 7 fehlenden Daten werden 23-mal beobachtet.
Feinschliff
Der letzte Bereinigungsschritt beseitigt unter Beibehaltung gleicher Zeitabschnitte die Lücken. Statt über 10 Minuten werden jetzt die Daten über eine Stunde agglomeriert. Das beseitigt alle Lücken, die kürzer als 6 fehlende Werte sind (Listing 8).
Listing 8
Lücken beseitigen
dod = dmd.copy()
dod= dod.resample('h').mean()
dod.shape, dod.isna().sum()
Im Beispiel verbleiben 16 Zeitstempel, denen eine Zuordnung fehlt. Von den vielen Möglichkeiten, die Pandas bietet, kommt hier die Methode »interpolate()« zum Einsatz. Sie schaut auf den linken und rechten Randwert eines »NaN«-Intervalls und berechnet die offenen Werte durch Interpolation.
Die Grafik aus Abbildung 5 vergleicht die Ausgangs- mit den bereinigten Daten. Insgesamt gibt das Resultat den Verlauf der Originaldaten recht gut wieder. Allerdings fallen Peaks unterschiedlicher Höhe auf. Ihnen liegen die Ausreißer zugrunde, denen ursprünglich der Wert 80 Watt zugeordnet wurde. Das Verfahren LOF konnte sie nicht beseitigen, da sie sich zu wenig von ihrer Umgebung unterschieden. Das Mitteln über Stundenintervalle reduzierte ihren Einfluss jedoch deutlich.
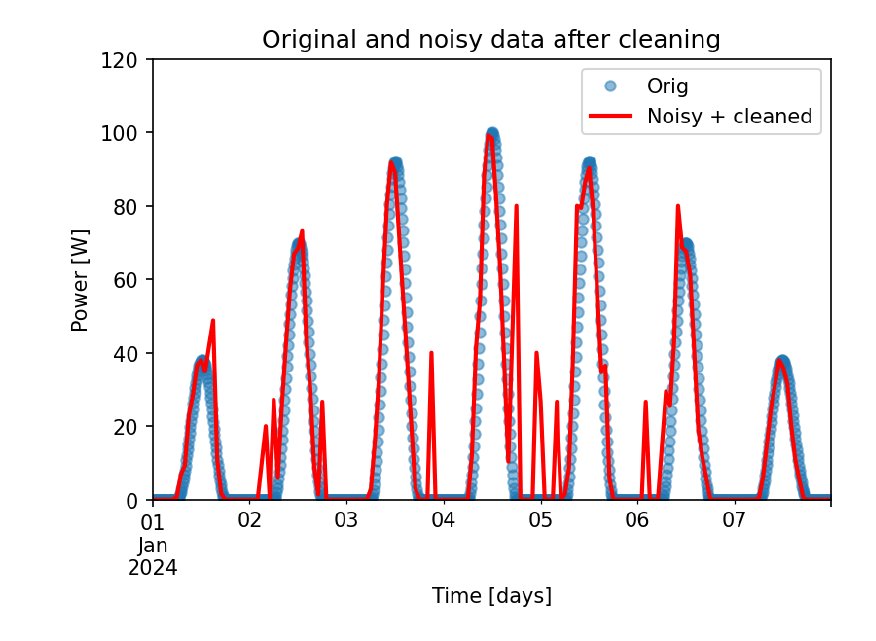
Abbildung 5: Originaldaten und verrauschte Daten nach Ende der kompletten Datenbereinigung.
Integriert man jetzt über die Daten, stimmen das Resultat nahezu mit dem aus den Originaldaten überein. Ursprünglich liegt der Energieertrag bei knapp 3 kWh. Aus den verrauschten und bereinigten Daten ergibt sich ein Wert von 3,5 kWh, bei über 70 Prozent geschädigten Daten. Zur Erinnerung: Unbereinigt lag der Wert bei über 100 kWh.
Fazit
Die Zeitreihenanalyse untersucht Daten, die dank ihres Zeitstempels sowohl einzigartig als auch chronologisch sortiert sind. Vor einer Analyse steht die Bereinigung der Daten. Erfahrungsgemäß erfordert dieser Schritt die meiste Arbeit. Jeder Fehler, der an dieser Stelle unbemerkt bleibt, führt bei der Auswertung zu Problemen. Geschädigte Daten verursachen abwegige Interpretationen.
Das demonstriert dieser Artikel an einem Beispiel zur Bestimmung der Energie, bei dem alle gängigen Fehlerquellen auf einen Demo-Datensatz angewendet wurden. Statt des korrekten Werts von 3 kWh berechnet das Integral über die unkorrigierten Daten eine 30-fach größere Zahl. Trotz einer Schädigung von rund 70 Prozent der Ausgangsdaten führt die Bereinigung zu einem Datensatz, der sich nur wenig von den Originaldaten unterscheidet.
Noch bessere Ergebnisse könnte man erzielen, indem man Vorinformationen zu den Daten nutzt. Im hier gezeigten Beispiel ließe sich leicht überprüfen, ob die Leistungsdaten in der Nacht tatsächlich bei null liegen. Davon haben wir hier keinen Gebrauch gemacht, da wir lediglich das Bearbeiten der Daten anhand ihrer Statistik demonstrieren wollte. (jcb/jlu)





