
© Andrea De Martin / 123RF.com
Netflix führt Protokoll darüber, wer wann welche Sendung ansieht. Mike Schilli bohrt mit einem Go-Programm tiefer und analysiert seine Sehgewohnheiten.
Woher weiß Netflix eigentlich so genau, welchen Film ich als Nächstes sehen möchte? Als Streaming-Dienst hat der Movie-Moloch Zugang zu meinen Sehgewohnheiten, und über seine Profile weiß er, was die Personen in meinem Haushalt so alles weggeguckt haben.
Nicht geizig, lässt Netflix seine User in ihre eigene Historie hineinspitzeln. Über den Menüpunkt Profiles und das jeweilige User-Profil findet sich unter Viewing Activity eine Liste (Abbildung 1) aller je angesehenen Filme samt Datumsstempel, die sich sogar bequem als CSV-Datei herunterladen lässt (Abbildung 2). Darin stehen zeilenweise jeweils der Titel des Films respektive der Serie sowie das Datum der Vorführung im Heimkino (Abbildung 3).
Abbildung 1: Hier geht es zur CSV-Datei mit der Historie.
Abbildung 2: Ein paar Sekunden später liegt die CSV-Datei vor.

Abbildung 3: Das persönliche Resultat: in 17 Jahren fast 3000 konsumierte Videos.
Wortkarg
Früher waren dort detailreichere Daten zu finden, die unter anderem verrieten, welche Videos die User angeklickt, aber kurz darauf wieder gestoppt hatten. Laut Netflix fiel dieses Feature dem Datenschutz zum Opfer, aber zumindest stellt eine Gesamtliste aller je angesehenen Filme mit Datumsstempel schon einmal eine gute Basis für allerlei statistische Auswertungen dar.
Eine CSV-Datei lässt sich mit Skriptsprachen wie Python ratzfatz auslesen, oft mit einem Einzeiler. Go ist da etwas umständlicher – Listing 1 zeigt, wie es geht. Die einlesende Funktion »readHistory()« ab Zeile 12 gibt als Ergebnis einen Array-Slice mit Film-Events vom Typ »viewing« zurück. Er enthält neben dem Filmtitel als String noch den Datumsstempel des Ereignisses im Go-eigenen Zeittyp »time.Time«.
Listing 1
csv.go
package main
import (
"encoding/csv"
"fmt"
"os"
"time"
)
type Viewing struct {
Title string
Date time.Time
}
func readHistory() ([]Viewing, error) {
csvFile := "history.csv"
viewings := []Viewing{}
r, err := os.Open(csvFile)
if err != nil {
fmt.Printf("Can't open %s (%v)\n", csvFile, err)
return viewings, err
}
defer r.Close()
csvReader := csv.NewReader(r)
records, err := csvReader.ReadAll()
if err != nil {
fmt.Printf("CSV reader error in %s: %v\n", csvFile, err)
return viewings, err
}
// skip header
records = records[1:]
for _, line := range records {
t, err := time.Parse("1/2/06", line[1])
if err != nil {
fmt.Errorf("Can't parse %v in %s: %v\n", line, csvFile, err)
return viewings, err
}
v := Viewing{Title: line[0], Date: t}
viewings = append(viewings, v)
}
return viewings, nil
}
Komplex
Ein neuer »Reader« des Pakets encoding/csv aus der Standard-Library liest die kommaseparierten Einträge der CSV-Datei Zeile für Zeile aus. Das ist keineswegs trivial, denn das Format akzeptiert ja beispielsweise auch Strings, die Kommas enthalten – die gilt es dann mit Anführungsstrichen zu schützen. Das Go-Paket erledigt diese Aufgaben klaglos. Die erste Zeile der Netflix-Datei enthält, wie im CSV-Format üblich, einen Header, der beschreibt, was denn die Felder in den nachfolgenden Records bedeuten. Zeile 28 in Listing 1 entfernt ihn manuell, die echten Daten folgen erst hinterher.
Da das Datum im zweiten Feld der nachfolgenden Datenzeilen im Format »mm/dd/yy« vorliegt, schnappt sich »time.Parse()« (aus Gos Standardfundus) den String in Zeile 30, um ihn zu interpretieren. Das Layoutformat »”1/2/06″« beschreibt mit »1« den Monat, »2« den Tag und »06« das Jahr. Heraus purzelt ein Zeitstempel vom Typ »time.Time«, den das Programm später für einfache Datumsberechnungen weiterverwenden kann.
Jedes gefundene Ereignis schiebt Zeile 36 jeweils ans Ende des Ergebnis-Arrays »viewings«. Dessen Elemente bestehen aus Strukturen des ab Zeile 8 definierten Typs »viewing«, der einen Titel sowie den Zeitstempel als »time.Time« enthält.
Grafisch aufgemotzt
Nun liegen die geguckten Videos in internen Datenstrukturen vor, die statistische Auswertung kann beginnen. Meine persönliche Netflix-Historie reicht bis 2006 zurück, als ich als internethungriger Heißsporn auf den damaligen Streaming-Zug aufsprang, aus dem ich seither nicht mehr ausgestiegen bin. Da wäre es ganz interessant herauszufinden, wie viele Videos ich über die Jahre pro Monat aufgerufen habe. Abbildung 4 zeigt den Verlauf. Nach einem zaghaften Beginn im Jahr 2006 findet sich zwischen den Jahren 2010 und 2014 eine euphorische Binge-Watching-Phase mit bis zu 100 Videos pro Monat, die dann langsam abebbt und sich aktuell bei etwa 10 Clips pro Monat eingependelt hat.
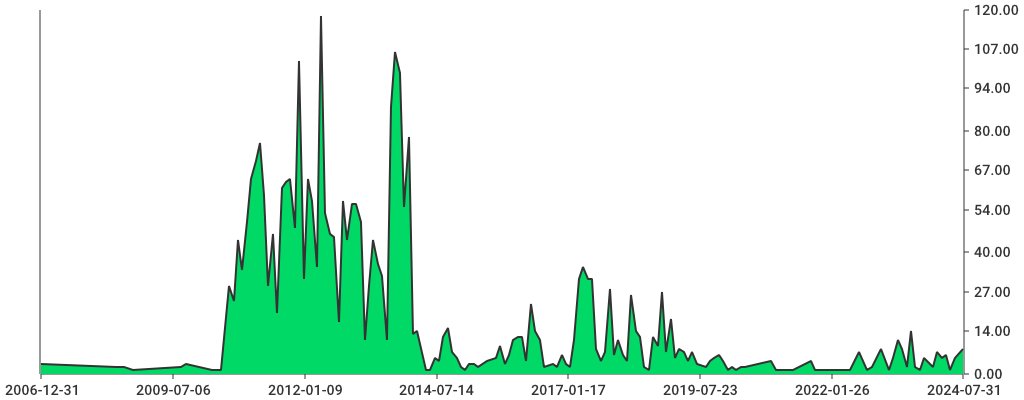
Abbildung 4: Der Verlauf der Shows pro Monat über die Jahre.
Wie lässt sich eine Zeitreihe so wie in Abbildung 4 in Go grafisch aufmotzen? Listing 2 nutzt dazu das Paket go-chart von Github, um die Anzahl der monatlich konsumierten Videos über die Zeitachse aufzutragen. Referenziert ein Eintrag aus der Netflix-Historie einen bislang unbekannten Monat, erzeugt Zeile 18 einen Zeitstempel, der auf 0 Uhr am Monatsanfang zeigt. Die Variable »prevMonth« speichert diesen Wert über die aktuelle Schleifenrunde hinaus und akkumuliert jeden weiteren Eintrag im selben Monat unter dem Zeitstempel des Monatsanfangs.
Erkennt Zeile 19, dass die (rückwärts) sortierten Ereignisse nun in einem anderen Monat stehen, schiebt Zeile 20 einen neuen Monat auf die Zeitachse in »xVals« und setzt den zugehörigen Zähler in »yVals« auf null. Anschließend erhöht Zeile 24 den Zähler für angeschaute Videos im aktuell verarbeiteten Monat um eins.
So steht am Ende der For-Schleife in »xVals« ein Array von Monatszeitstempeln und in »yVals« ein gleich langes Array von Zählern von angesehenen Videos. Die nimmt der Typ »TimeSeries« auf und verwandelt sie in eine Grafik. Zeile 35 schiebt den Graphen in ein Koordinatensystem »Chart«, der Aufruf von »Render()« in Zeile 46 macht eine PNG-Datei daraus.
Listing 2
chart.go
package main
import (
"fmt"
"github.com/wcharczuk/go-chart/v2"
"os"
"time"
)
func main() {
viewings, err := readHistory()
if err != nil {
panic(err)
}
xVals := []time.Time{}
yVals := []float64{}
prevMonth := time.Time{}
for i := len(viewings) - 1; i >= 0; i-- {
v := viewings[i]
month := time.Date(v.Date.Year(), v.Date.Month(), 1, 0, 0, 0, 0, v.Date.Location())
if prevMonth.IsZero() || prevMonth != month {
xVals = append(xVals, month)
yVals = append(yVals, 0)
prevMonth = month
}
yVals[len(yVals)-1] += 1
}
chartData := chart.TimeSeries{
XValues: xVals,
YValues: yVals,
Style: chart.Style{
StrokeWidth: 2,
StrokeColor: chart.ColorBlack,
FillColor: chart.ColorGreen,
},
}
graph := chart.Chart{
Series: []chart.Series{
chartData,
},
}
f, err := os.Create("netflix.png")
if err != nil {
fmt.Println("Error creating file:", err)
return
}
defer f.Close()
graph.Render(chart.PNG, f)
}
Tiefer mit Meta
Ob es sich bei einem angesehenen Video um einen Kinofilm oder eine Serienfolge gehandelt hat, ist für menschliche Beobachter ziemlich klar: “Breaking Bad, Episode 1” war zweifellos Teil einer Serie, “3:10 to Yuma” ebenso glasklar ein Film. Eine Maschine braucht dazu aber Hintergrundwissen oder – computertechnisch ausgedrückt – Metainformationen. Ganz wie die Internet-Movie-Database IMDB Informationen zu Filmen sammelt, speichert Omdb.com solche Infos in einer Datenbank und lässt Suchabfragen per API zu. Dazu gilt es lediglich, einen API-Key zu beantragen, den es gegen Registrierung kostenlos gibt und der bis zu 1000 Abfragen pro Tag zulässt. Brauchen Sie mehr Zugriffe, können Sie per Patreon-Spende aufstocken.
Abbildung 5: Einen kostenlosen API-Key holen Sie auf Omdb.com ab.
Listing 3 schlägt die Metainformationen zu einem Netflix-Video mit der Funktion »omdbFetch()« anhand des Videotitels online in der Datenbank nach. Zurück kommt eine Struktur vom Typ »MovieMeta«, die außer dem Videotitel noch die IMDB-Bewertung des Titels von 0 bis 10 Punkten enthält. Weitere Felder wären sowohl möglich als auch sinnvoll und fallen hier nur der Kürze halber weg. Die von der OMDB-API zurückkommenden JSON-Daten (Abbildung 6) enthalten extrem nützliche Informationen wie die mitwirkenden Schauspieler (»Actors«), den Regisseur (»Director«) und sogar, wie viel Geld der Film im Kino eingespielt hat (»BoxOffice«).
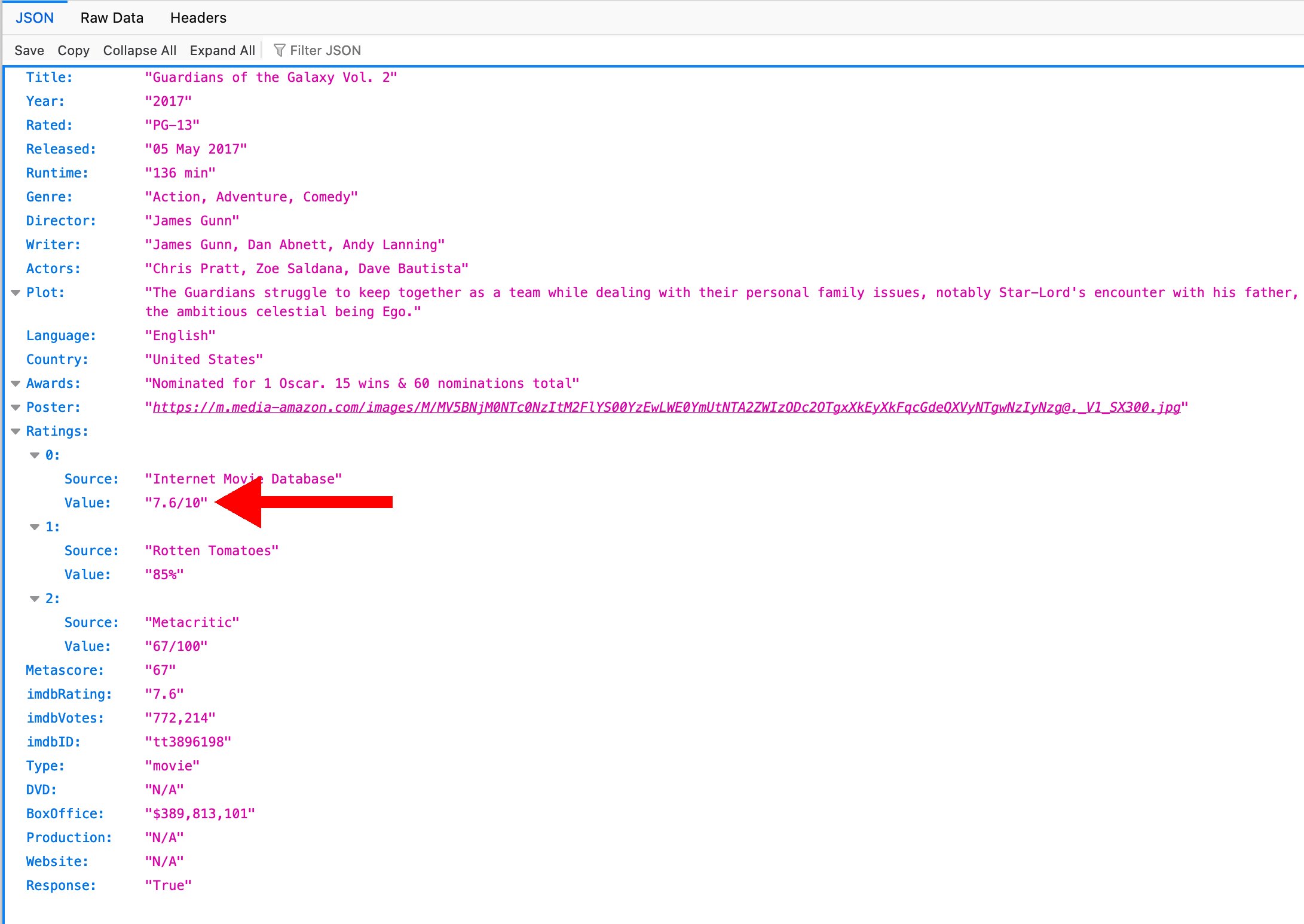
Abbildung 6: Die von OMDB zu einem Film gelieferten Metadaten. Der rote Pfeil verweist auf das IMDB-Rating.
Listing 3 steckt die für den API-Call erforderliche URL in der Variablen »apiURL« zusammen, nachdem es vorher in Zeile 18 den erforderlichen API-Key aus der Geheimnisdatei »~/.murmur« gefischt hat. Dort liegt er unter dem Schlüssel »omdb-api-key«, nachdem der Admin sich bei Omdb.com registriert, den API-Key dort abgeholt und ihn in der Murmeldatei als YAML-Eintrag im Format »omdb-api-key: “Key“« abgelegt hat.
Listing 3
omdb.go
package main
import (
"fmt"
"github.com/mschilli/go-murmur"
"github.com/tidwall/gjson"
"io/ioutil"
"net/http"
"net/url"
)
type MovieMeta struct {
Title string
Rating string
}
func omdbFetch(title string) (MovieMeta, error) {
mmeta := MovieMeta{}
baseURL := "http://www.omdbapi.com"
apiURL, _ := url.Parse(baseURL)
apiKey, err := murmur.NewMurmur().Lookup("omdb-api-key")
if err != nil {
return mmeta, err
}
q := url.Values{}
q.Add("t", title)
q.Add("apikey", apiKey)
apiURL.RawQuery = q.Encode()
resp, err := http.Get(apiURL.String())
if err != nil {
return mmeta, err
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
return mmeta, fmt.Errorf("HTTP status %d", resp.StatusCode)
}
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
return mmeta, err
}
jsonErr := gjson.Get(string(body), "Error")
if jsonErr.Exists() {
return mmeta, fmt.Errorf("%s not found in omdb", title)
}
mmeta.Title = title
mmeta.Rating = gjson.Get(string(body),
`Ratings.#(Source=="Internet Movie Database").Value`).String()
return mmeta, nil
}
JSON-Zugriff
Findet Omdb.com den Titel des gesuchten Films nicht in seiner Datenbank, legt es im zurückgeschickten JSON-Salat unter dem Schlüssel »Error« eine Fehlermeldung ab. Die Funktion »Get()« aus dem Paket gjson von Github schnappt sich den Eintrag in Zeile 38 und prüft ihn. Steht dort tatsächlich eine Fehlermeldung, meldet sie »return« in Zeile 40 an den Aufrufer der Funktion »omdbFetch()«, also an das Hauptprogramm. Das interpretiert ihn nach Gusto.
Hat Omdb.com den Titel hingegen gefunden, bohrt sich der »gjson«-Query in Zeile 43 über den JSON-Eintrag »Ratings« in die Hierarchie der IMDB-Bewertungen und fischt mit »Value« den String-Eintrag im Format»X.YY/10« heraus. Er landet im Feld »Rating« der Struktur »MovieMeta«, die die Zeile 45 im Erfolgsfall an den Aufrufer zurückreicht.
Film oder Serie?
Um nun herauszufinden, bei wie vielen der gestreamten Videos es sich um Serien beziehungsweise um Filme handelte, hangelt sich Listing 4 ab Zeile 13 durch alle Streaming-Events. Es holt sich mit »omdbFetch()« über den Titel die Metainformationen zum Video. Aus der Tatsache, dass nichts gefunden wurde, schließt es, dass es sich um eine Serie handelt, denn »omdb« enthält ausschließlich Filme, keine Serien. In den Variablen »series« und »movies« zählt der Code mit und summiert das Ergebnis auf.
Listing 4
genre.go
package main
import (
"github.com/wcharczuk/go-chart/v2"
"os"
)
func main() {
series := 0
movies := 0
viewings, err := readHistory()
if err != nil {
panic(err)
}
for _, v := range viewings {
_, err := omdbFetch(v.Title)
if err == nil {
movies += 1
} else {
series += 1
}
}
pie := chart.PieChart{
Width: 512,
Height: 512,
Values: []chart.Value{
{Value: float64(series), Label: "Series"},
{Value: float64(movies), Label: "Movies"},
},
}
f, err := os.Create("genre.png")
if err != nil {
panic(err)
}
defer f.Close()
err = pie.Render(chart.PNG, f)
if err != nil {
panic(err)
}
}
Das Verhältnis von Serien zu Filmen illustriert die mit dem Paket chart erzeugte Kuchengrafik in Abbildung 7. In meinem persönlichen Profil (das unter Umständen durch weitere Personen in meinem Haushalt verfälscht wurde, die zu faul waren, die App auf ihr eigenes Profil umzustellen) liegt das Verhältnis bei etwa 10:1, es kommen also 10 Serienfolgen auf einen Film.
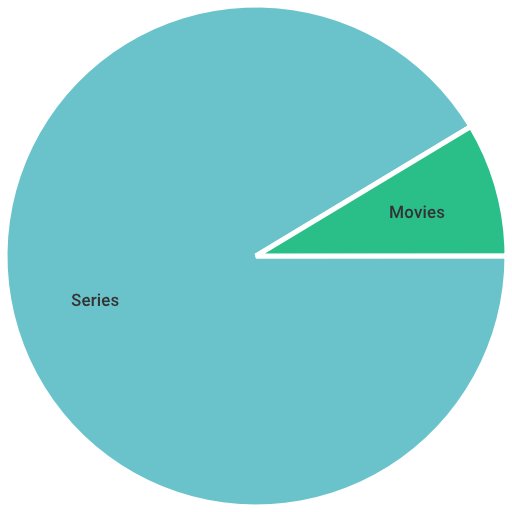
Abbildung 7: Auf Netflix guckt Mike Schilli meist Serien.
Hopp oder top
Die Güte einer Filmproduktion ist oft Geschmackssache. Bewertungsaggregatoren wie Rotten Tomatoes oder IMDB spannen eine Community von Filmenthusiasten dazu ein, eine repräsentative Wertung in Form einer Fließkommazahl abzugeben. Die Meta-Daten in der JSON-Antwort von Omdb.com enthalten für viele Filme mehrere Wertungen. Da wäre es doch ganz interessant, eine objektive statistische Werteverteilung meiner geguckten Filme zu sehen.
Dazu malt Listing 5 das Histogramm aus Abbildung 8, das illustriert, dass sich mein Geschmack in etwa mit dem des breiten Publikums deckt. Die meisten von mir angesehenen Filme fallen in den Bereich von 7,0 bis 7,5 von maximal 10 Bewertungspunkten, mit einer Gauß-artigen Glockenkurve als Verteilung.
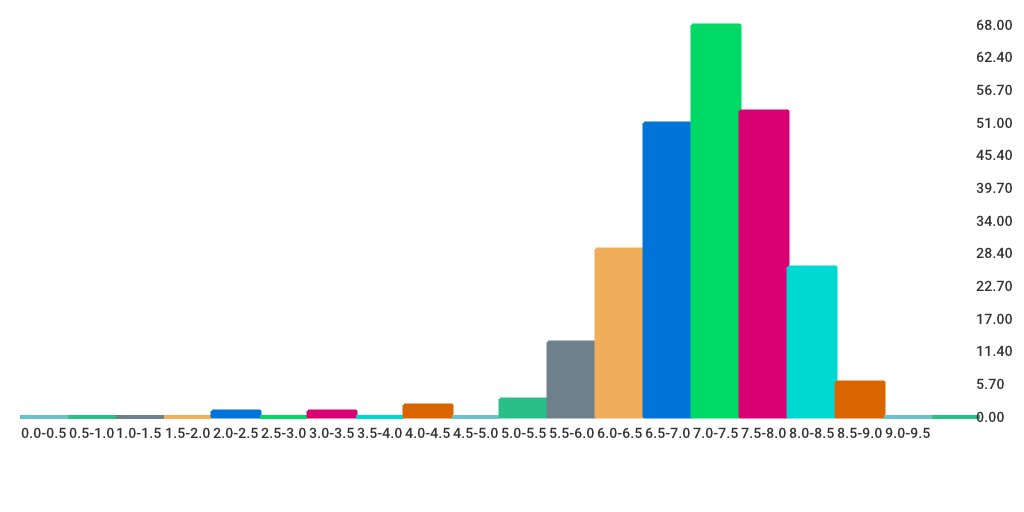
Abbildung 8: Histogramm der IMDB-Bewertungen aller angeschauten Filme.
Listing 5 iteriert dazu wieder durch alle Streaming-Events. Diesmal verwirft es alle Serien, da auf IMDB nur Filme Ratings bekommen (Abbildung 9). Da die JSON-Daten das Rating als String im Format »X.YY/10« angeben, fieseln die Zeilen 24 bis 25 die Fließkommazahl durch einen Split-Befehl aus der Library strings und mithilfe von »ParseFloat()« aus dem Standardpaket strconv heraus.

Abbildung 9: Listing 5 holt die OMDB-Metadaten zu den Ratings ein.
Die einzelnen Klassen des Histogramms (auf Englisch Bins, also Eimer) bestehen aus 20 gleich breiten Rating-Spannen. Zeile 34 in Listing 5 gibt die Klassenbreite als 0,5 an, gefolgt vom Minimalwert 0 und dem Maximalwert 10 für die Ratings. Die gefundenen Fließkommazahlen steckt das Hauptprogramm in das Array »data« und übergibt es der Funktion »drawHisto()« zum Zeichnen des Histogramms.
Dort gilt es, die Werte auf gleich große Eimer zu verteilen, um sie später mit dem Typ »BarChart« aus dem Paket chart als ansprechende Grafik zu malen. Dazu iteriert die For-Schleife ab Zeile 39 über alle Elemente des Arrays und bestimmt durch Integer-Division den für den aktuellen Wert zuständigen Eimer im Array »bins«. Zeile 42 zählt die im Eimer enthaltenen Einträge um eins hoch.
Zum Zeichnen der Grafik benötigt das Paket chart die Daten für die darzustellenden Balken als Werte vom Typ »chart.Value«. Sie enthalten jeweils einen Fließkommawert sowie den String »Label«, der den zugehörigen Eintrag auf der X-Achse der Grafik repräsentiert. Zeile 57 übergibt das finale Säulen-Array dem chart-Paket, »Render()« in Zeile 61 malt es samt Achsen und deren Beschriftungen formschön in eine PNG-Datei.
Listing 5
ratings.go
package main
import (
"fmt"
"github.com/wcharczuk/go-chart/v2"
"os"
"strconv"
"strings"
)
func main() {
viewings, err := readHistory()
if err != nil {
panic(err)
}
data := []float64{}
for _, v := range viewings {
md, err := omdbFetch(v.Title)
if err != nil {
if strings.Contains(err.Error(), "not found in omdb") {
continue // series
} else {
panic(err)
}
}
parts := strings.Split(md.Rating, "/")
value, err := strconv.ParseFloat(parts[0], 64)
if err != nil {
continue
}
data = append(data, value)
}
drawHisto(data)
}
func drawHisto(data []float64) {
binWidth := 0.5
minValue := 0.0
maxValue := 10.0
numberOfBins := int((maxValue - minValue) / binWidth)
bins := make([]int, numberOfBins)
for _, value := range data {
if value >= minValue && value < maxValue {
i := int((value - minValue) / binWidth)
bins[i]++
}
}
bars := []chart.Value{}
for i, count := range bins {
binStart := minValue + float64(i)*binWidth
binEnd := binStart + binWidth
bars = append(bars, chart.Value{
Value: float64(count),
Label: fmt.Sprintf("%.1f-%.1f", binStart, binEnd),
})
}
barChart := chart.BarChart{
Height: 512,
Width: 1024,
Bars: bars,
}
f, _ := os.Create("ratings.png")
defer f.Close()
barChart.Render(chart.PNG, f)
}
Um die vorgestellten Listings zu Binaries zusammenzubauen, kompilieren und binden die drei Go-Build-Befehle in Listing 6 die für die drei Hauptprogramme jeweils erforderlichen Source-Dateien, nachdem vorher »go mod tidy« alle abhängigen Libraries von Github eingeholt hat.
Listing 6
build.sh
$ go mod init netflix $ go mod tidy $ go build chart.go csv.go $ go build genre.go omdb.go csv.go $ go build ratings.go omdb.go csv.go
Ausblick
Damit wäre der Grundstein für das Erforschen der Netflix-Gewohnheiten gelegt. Hier noch einige weitere Ideen: Es ließe sich leicht herausfinden und grafisch illustrieren, welche Wochentage der Netflix-Gucker am häufigsten im Pantoffelkino verbringt – vielleicht sogar als Matrix-Anzeige im Format von Github-Beiträgen? Möglicherweise ließe sich eine künstliche Intelligenz dazu einspannen, aus den Plot-Beschreibungen angesehener Filme den Handlungsstrang eines neuen Super-Blockbusters zu generieren? Wie immer sind der Kreativität keine Grenzen gesetzt. (uba)





