
© Sergey Nivens / 123RF.com
Die CouchDB wartet mit zahlreichen interessanten Features auf, die aus ihr eine schnelle, aber auch bequeme Datenablage machen. Dieser Artikel demonstriert das anhand einiger Beispiele.
Ob Internet of Things oder Serverlandschaft, Microservices oder Cronjobs – eine Vielzahl an Anwendungen produzieren allerlei Statusmeldungen, die der Admin sammeln und auswerten will. Ob es der Alarm vom Mähroboter ist, die gewaltsame Beendigung eines lange laufenden Tasks oder einfach nur die Regenwarnung: Wer die unterschiedlichen Meldungen zentral speichern und unabhängig von ihrer Struktur auswerten will, steht vor einer Herausforderung (Listing 1).
Listing 1
Unterschiedliche Statusmeldungen
{ "timestamp":"202405141201",
"source": "gardenrobot-1",
"message": { "type":"alert",
"value":"animal" }
}
{ "timestamp":"202405141220",
"source": "gardenrobot-1",
"message": { "type":"warning",
"value":"low power" }
}
{ "timestamp":"202405150200",
"source": "server"
"message": { "type":"task done",
"value":"night-backup",
"result": "done",
"errors": [] }
}
{ "timestamp":"202405160800",
"source" : "18739949083333",
"rss" : "watherchannel",
"region":"Berlin",
"message": { "type":"warning",
"value":"rain",
"category": "heavy",
"chance" : "80%" }
}
Beim zentralen Erfassen und späteren Filtern der Statusmeldungen, etwa nach Anzahl pro Stunde oder nach Herkunft, soll die CouchDB helfen. Ihr großer Vorteil dabei, den sie mit anderen NoSQL-Datenbanken teilt, liegt in der Schemafreiheit der Daten. Jeder CouchDB-Datensatz kann eine eigene Struktur aufweisen, zumindest solange sie sich im Format JSON abbilden lässt. Durch diese Freiheit lassen sich viele unterschiedliche Statusmeldungen in einer Datenbank verwalten und abfragen, ohne dass an die Struktur der Meldungen angepasste Tabellen nötig wären.
Ändert sich das Format einer Statusmeldung, muss das lediglich in darauf bezogenen Abfragen berücksichtigt werden, fürs Speichern sind keine Änderung an der Datenbank notwendig. Es liegt also nahe, eine solche dokumentbasierte Datenbank für unterschiedliche Datenstrukturen wie Statusmeldungen aus verschiedenen Quellen zu verwenden. Bietet die Datenbank außerdem – wie die CouchDB – noch einfache Cluster-, Replikations- und Abfragemöglichkeiten, ist sie auf jeden Fall einen zweiten Blick wert.
CouchDB gehört zu den Urgesteinen der NoSQL-Datenbanken. Damien Katz entwickelte die Software bereits im Jahr 2005. Die Grundidee stammt aus seiner vorigen Tätigkeit als Senior Developer bei Lotus Notes, einer verteilen Kollaborationssoftware. Er kombinierte den schemalosen, dokumentorientierten Ansatz von Lotus Notes mit der damals relativ neuen Map/Reduce-Technik, die große Datenmengen auf verteilten Systemen abfragen kann. Seit 2008 ist CouchDB ein Apache-Project. Aus der Version 1.0 im Jahr 2010 hat sich bis zum heutigen Tag die Version 3.3 entwickelt.
Das Akronym “Couch” steht offiziell für “Cluster of Unreliable Commodity Hardware” (Cluster unzuverlässiger Standardhardware) und soll ausdrücken, dass das System ebenso ohne leistungsstarke Hochverfügbarkeitsserver gut funktioniert. Eine zweite Bedeutung (dafür steht das Logo mit der Couch) könnte aber zudem auf die Einfachheit abzielen, mit der sich Datenbanken ohne festes Schema einrichten lassen. Dabei gehen die Fähigkeiten der CouchDB über einen reinen Key-Value-Store hinaus. Das Datenbanksystem glänzt mit einem Multimaster-Replikationsmodell, ACID-konformer Speicherung von Dokumenten, Indizierungsfunktionen oder mit Map/Reduce-Technik in JavaScript sowie der Abfragesprache Mango.
Die nötigen Binaries und Informationen zur Installation der CouchDB finden sich auf der Webseite des Projekts [1]. Für Windows und macOS laden Sie die Installer direkt herunter, bei CentOS/Debian und Ubuntu genügen ein paar Zeilen in der Konsole, um die Pakete direkt aus den Repositories zu installieren. Letztendlich liegen auch die Source-Files dort. CouchDB ist in Erlang/OTP geschrieben, einer funktionalen Sprache aus der Welt der Telekommunikation. Die Stärken dieses Sprachtyps zeigen sich in der einfachen Parallelverarbeitung, der Fehlertoleranz und der Robustheit. Von Beginn an gehörte zu den Schwerpunkten der CouchDB-Entwicklung die Konzentration auf verteilte Datenbanken im Netz. Erlang war für diesen Einsatzzweck das Mittel der Wahl, gerade um die Sicherheit und Konsistenz von Daten in einem Cluster mit hoher Belastung zu gewährleisten.
Während der Installation wird zwischen einer Stand-alone-Variante und einer Variante als Teil eines Clusters unterschieden – für den ersten Eindruck genügt die Stand-alone-Installation.
Fauxton
Die CouchDB nutzt zur Kommunikation kein eigenes Transportformat, sondern setzt ganz auf den HTTP/REST-Standard. Nach der erfolgreichen Installation mit den Standardwerten lauscht die CouchDB-Instanz auf dem Port 5984. Je nach Installation (Localhost oder IP-Adresse/Domain) fragen Sie mit einem Aufruf per Browser oder GET-Request auf die Basisadresse eine kurze Statusmeldung zum Test ab (Listing 2).
Listing 2
Statusmeldung
{ "couchdb":"Welcome",
"version":"3.3.3",
"git_sha":"40afbcfc7", "uuid":"3b74c04721ee61dbe9db74ac3c69e8f8",
"features":["access-ready", "partitioned", "pluggable-storage-engines", "reshard", "scheduler"],
"vendor":{"name":"The Apache Software Foundation"} }
Der Vendor-Name lässt sich später einfach ändern, ebenso der Port und andere, hier nicht weiter betrachtete Einstellungen. Um die CouchDB in den Grundzügen kennenzulernen, eignet sich das eingebaute Frontend Fauxton. Ich gehe von einer lokalen Installation aus und erreiche Fauxton unter »http://localhost:5984/utils«. Initial erscheint dort die Datenbankübersicht (Abbildung 1).
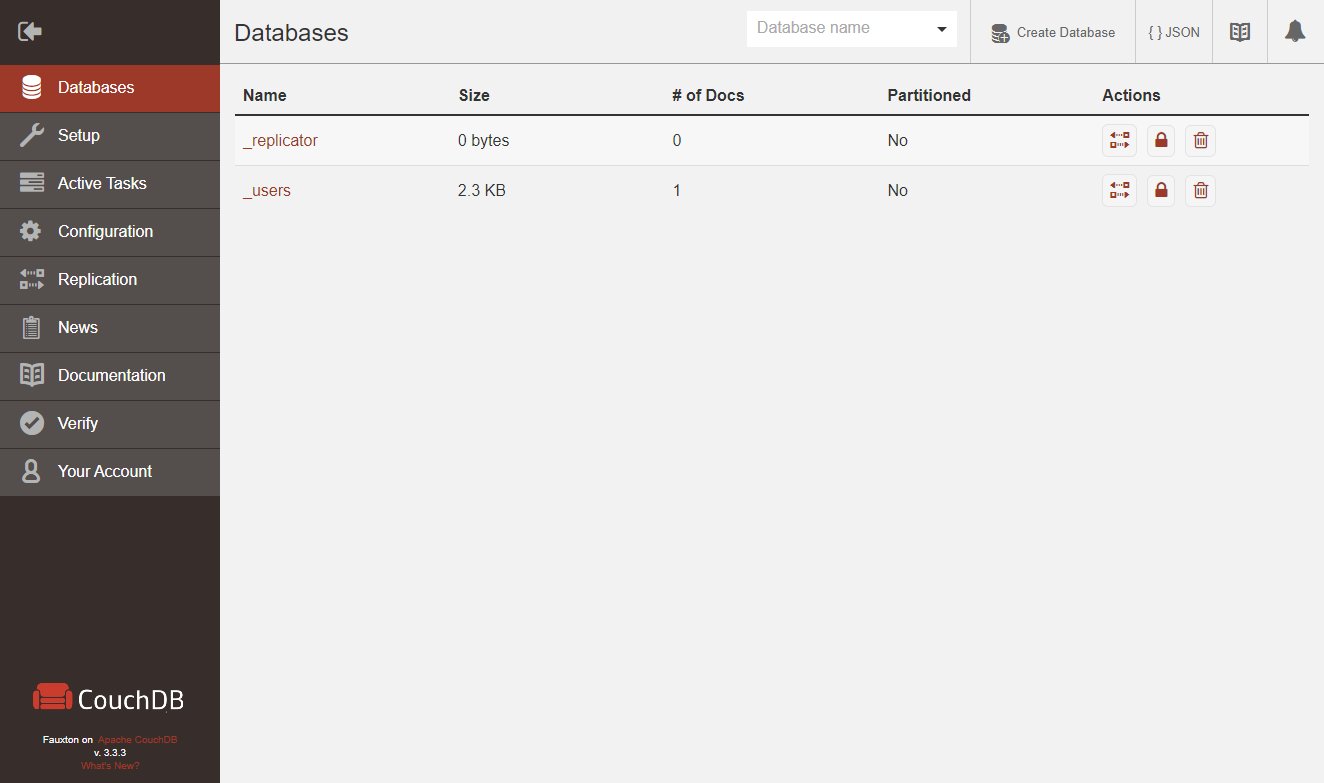
Abbildung 1: Die Fauxton-Oberfläche zeigt zunächst eine Übersicht über die Datenbank.
Die beiden internen Datenbanken »_replicator« und »_users« sind bereits angelegt. Wie in Abbildung 1 zu sehen, zeigt der Menüpunkt Databases alle angelegten Datenbanken mit Details an. Außerdem passen Sie hier die Sicherheitseinstellungen pro Datenbank an und löschen Datenbanken. Eine einmal angelegte Datenbank lässt sich weder umbenennen noch automatisch leeren. Unter Setup findet sich die Installationsart: Single Node oder Cluster.
Der Menüpunkt Active Tasks umfasst sämtliche aktiven Vorgänge in der CouchDB. Unter Configuration justieren Sie einige Einstellungen und fügen ergänzende, nicht standardmäßige Einträge zu den Einstellungen hinzu. Hinter Replication verbirgt sich eine Auflistung laufender und vergangener Replikationen. An dieser Stelle legen Sie zudem eine neue Replikation an. Nach Anwahl von News lassen sich News aus dem Blog integrieren. Documentation enthält Links zu verschiedenen Dokumentationsquellen. Verify gestattet es, die Installation zu überprüfen. Unter Your Account verwalten Sie den Account des aktuellen Admins oder richten neue Admin-Konten ein.
Speichern
Fragt sich nun, wie die Statusmeldungen in die CouchDB kommen. Dazu gibt es kein spezielles CouchDB-Format oder Protokoll. Alle Aktionen erfolgen über den HTTP/REST-Standard. Egal ob Browser, Python, Curl, Postman oder Lisp – alles, was HTTP/REST spricht, lässt sich benutzen. Selbstverständlich existieren in vielen Sprachen Helfer und Wrapper, die komplexere Aufgaben in die eigentlichen HTTP-Aufrufe übersetzen – im Kern jedoch sind alle Aktionen »GET«-, »PUT«-, »POST«- oder »DELETE«-Aufrufe, standardmäßig über den Port 5984. Nach der Installation können Sie den Port beliebig abändern.
Die Hierarchie innerhalb einer CouchDB-Installation gestaltet sich relativ flach. Es gibt Datenbanken, und intern speichert jede Datenbank als logische und physische Einheiten JSON-Dokumente. Ein Dokument kann zusätzliche Daten und ebenso binäre Nicht-JSON-Formate als Attachment enthalten.
Die Namen von allem, was für das CouchDB-System selbst wichtig ist, beginnen mit einem Unterstrich – seien es die Systemdatenbanken »_users« und »_replication«, Dokumente wie »_design« oder Felder eines Dokuments wie »_id« und »_rev«. Der Anwender kann selbst keine Datenbanken oder Dokumente und Felder mit einem führenden Unterstrich anlegen, es sei denn, sie gehören zum CouchDB-System.
Während der Installation wurden bereits ein Username und ein Passwort für die Administration angegeben. Der Einfachheit halber kommt dieses Konto auch in Fauxton sowie für das Erstellen der Datenbanken per Curl oder Python zum Einsatz. Für eine User/Passwort-Kombination »admin/admin« wird das Attribut »Authorization: Basic YWRtaW46YWRtaW4=« in den Aufrufen verwendet. Selbstverständlich sollten im Produktivbetrieb unterschiedliche User oder Rollen angelegt werden. Nur der Vollständigkeit halber sei erwähnt, dass es beim Speichern von Dokumenten möglich ist, die Daten automatisch zu prüfen (Funktion »validate_doc_update«) oder zu ändern (Funktion »update«).
Datenbanken
Ausgehend von der Datenbankansicht in Fauxton lässt sich mit einem Klick auf Create Database die Datenbank »messages« anlegen. Hier genügt die Einstellung »Non-partitioned«. Sehr große Datenbanken lassen sich gleich beim Anlegen partitionieren, sodass Abfragen immer nur auf einen bestimmten Bereich der Daten erfolgen. Nach dem Anlegen in Fauxton finden Sie sich direkt in der Datenbankansicht wieder. Alternativ erstellen Sie die Datenbank über die Konsole (Listing 3, zweite Zeile). Als Antwort kommt von der CouchDB ein kurzes »{ok:true}« im Erfolgsfall oder eine Fehlermeldung:
{"error":"file_exists","reason":"The database could not be created, the file already exists."}
Listing 3
Kommunikation auf der Kommandozeile
### Anlegen einer Datenbank: $ curl -X PUT localhost:5984/messages -H "Authorization: Basic YWRtaW46YWRtaW4=" ### Löschen einer Datenbank $ curl -X DELETE localhost:5984/messages -H "Authorization: Basic YWRtaW46YWRtaW4=" ### Details einer Datenbank anzeigen $ curl -X GET localhost:5984/messages ### Neues Dokument per PUT $ curl -X PUT http://localhost:5984/messages/first_message -d '{"message":"Hello"}' ### Neues Dokument per POST $ curl -X POST http://localhost:5984/messages -d '{"_id":"second_message","message":"World"}' -H "Content-type: application/json" ### Dokument per GET holen $ curl -X GET http://localhost:5984/messages/first_message ### Alle Dokumente einer Datenbank abrufen $ curl -X GET http://localhost:5984/messages/_all_docs ### Einzelne ausgewählte Dokumente inklusive Inhalt abrufen $ curl -X POST http://localhost:5984/messages/_all_docs?include_docs=true -d '{"keys":["first_message","second_message"]}' -H "Content-type: application/json"
Am wahrscheinlichsten ist die Kommunikation mit der CouchDB über ein Anwendungsprogramm. In der Grundstruktur muss ein Programm »GET«-, »PUT«-, »POST«- und »DELETE«-Requests absetzen und die URL, die Header zur Authentifizierung und die zu übergebenden Daten füllen. Alles weitere wird nur noch über den Inhalt der Requests gesteuert. Ein einfaches Beispiel in Python zeigt Listing 4: ein Grundprogramm, das die Datenbank anlegt und das Ergebnis dieser Operation ausgibt. Beim ersten Durchlauf sollte die Datenbank angelegt werden, der zweite Durchlauf würde in einer Fehlermeldung enden.
Listing 4
Anlegen einer Datenbank in Python
import json
import urllib3
http = urllib3.PoolManager()
COUCHDB_URL = "http://localhost:5984"
AUTH = 'Basic YWRtaW46YWRtaW4=' # admin/admin
HEADERS = {'Content-type': 'application/json','Authorization': AUTH}
def create_database (database_name):
url = f'{COUCHDB_URL}/{database_name}'
result = http.request('PUT', url, headers=HEADERS)
return (json.loads(result.data))
print(create_database ("messages"))
Das Sicherheitskonzept der CouchDB sieht vor, dass der Zugriff auf eine Datenbank über User oder Rollen zu regeln ist. In der Fauxton-Datenbankübersicht stellen Sie für jede Datenbank in der Spalte Actions die Zugriffsrechte ein (Abbildung 2). Das Anlegen einer Datenbank setzt automatisch den eingeloggten Benutzer (im Beispiel admin) als Admin ein. Wer alle Nutzer und Rollen in den Permissions einer Datenbank entfernt, erhält eine öffentliche Datenbank, in der jeder ohne Authentifizierung lesen und schreiben kann. Für den ersten Test in einer lokalen Umgebung genügt das. Man erspart sich bei den Requests die Authentifizierungs-Header, was beim Herumprobieren mit Curl in der Konsole etwas Tipparbeit spart.
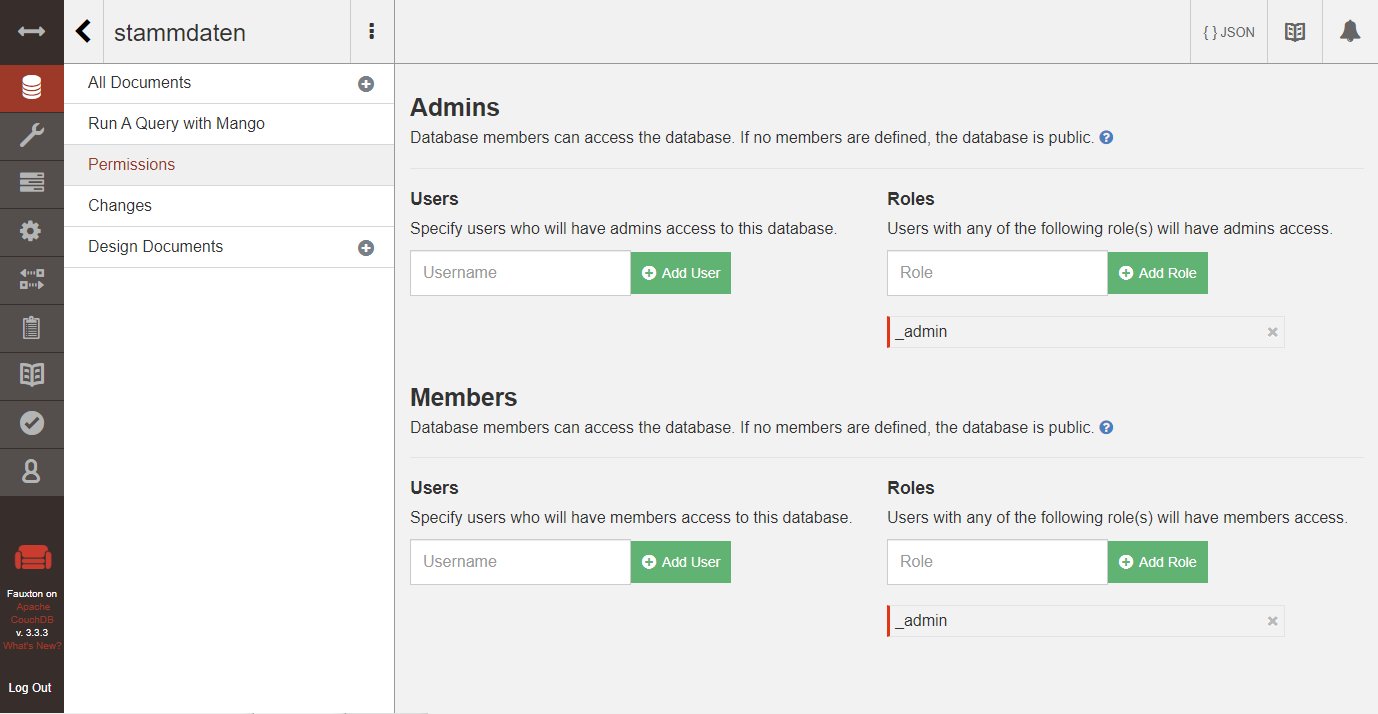
Abbildung 2: Innerhalb der Ansicht Permissions in der Fauxton-GUI konfigurieren Sie Nutzer und Rollen.
So einfach wie sich die Datenbank anlegen lässt, lässt sie sich mit einem »DELETE«-Request an Stelle des »PUT« wieder löschen (Listing 3, Zeile 4). Dabei gilt es aufzupassen: Das Löschen per »DELETE«-Request erfolgt sofort. Sämtliche Daten innerhalb der Datenbank gehen damit verloren. In Fauxton entfernen Sie in der Datenbankübersicht eine Datenbank in der Spalte »Actions«. Fauxton fragt vor dem Löschen sicherheitshalber noch einmal nach.
Eine Datenbank innerhalb einer CouchDB-Installation kapselt Daten und Abfragen. Es gibt bis auf eine Ausnahme keine wirklichen Joins in einer CouchDB, und so erübrigt sich die Überlegung, ob Dokumente in »messages« mit Dokumenten einer anderen Datenbank verknüpft werden können. Innerhalb einer Datenbank besitzt jedes Dokument eine eindeutige ID, doch dieselbe ID kann ebenso in anderen Datenbanken vorkommen. Einmal angelegt, lassen sich einige Informationen und Statistiken der Datenbank per »GET«-Request abrufen (Listing 3, Zeile 6). Denken Sie bitte dran: Nur wenn kein User und keine Rollen für diese Datenbank eingestellt sind, kann die Autorisierung entfallen.
Dokumente
Das Speichern eines Dokuments funktioniert entweder per »PUT«-Request mit der ID als Teil der URL (Listing 3, Zeile 8) oder als »POST«-Request an die gewünschte Datenbank (Listing 3, Zeile 10). Bei einem »POST«-Request mit einem neuen Dokument muss das Feld »_id« enthalten sein. Fehlt es, oder spielt die ID des Dokuments keine Rolle, können Sie das Feld beim Anlegen des Dokuments unter den Tisch fallen lassen. Anschließend vergibt die CouchDB eine UUID für das neue Dokument. »POST«-Requests an die CouchDB müssen Sie mit dem Header »Content-type:application/json« versehen. Nach dem erfolgreichen Speichern eines Dokuments liefert CouchDB die ID und die initiale Revisionsnummer des neuen Dokuments. Im Fehlerfall gibt die Datenbank eine entsprechende Meldung aus:
{"ok":true,"id":"second_message","rev":"1-183d19dc77574e297dc791f3723caf41"}.
Auch innerhalb eines Programms bringt das Speichern eines Dokuments per »PUT« oder »POST« keine großen Anforderungen mit sich. Wer überhaupt keine Lust auf Konsole oder Code verspürt, legt über Fauxton ein Dokument mit validem JSON an. Dazu klicken Sie innerhalb der gewünschten Datenbank auf Create Document. Die CouchDB schlägt daraufhin eine UUID als »_id« vor, die sich nach Belieben vor dem Speichern ändern lässt.
Nun ist ein guter Zeitpunkt, um die Liste von Statusmeldungen aus Listing 1 mit einer der drei Möglichkeiten in der Datenbank »messages« abzulegen (Abbildung 3). Dazu noch ein Gedanke die gewählten IDs der Dokumente betreffend: Wenn ein wichtiges Kriterium die Sortierung nach Zeit oder anderen aufsteigenden Werten ist, empfiehlt sich eine ID mit führendem Zeitstempel. So lässt sich, ohne eine Abfrage zu programmieren, schon einmal der Zeitbereich mit CouchDB-Bordmitteln eingrenzen, indem Sie die interne Abfrage »_all_docs« mit den passenden Optionen »startkey« und »endkey« ausstatten (dazu später mehr).
Besonders, wenn viele Statusmeldungen aus unterschiedlichen Systemen einlaufen, lassen sich einheitliche IDs aber nicht immer gewährleisten. Daher bleibt die Form der ID in diesem Beispiel außer Acht, und Sie sollten die Meldungen entweder per »POST« ohne Angabe eines »_id«-Felds oder mit Übernahme der CouchDB UUID in Fauxton nach Create Document speichern.
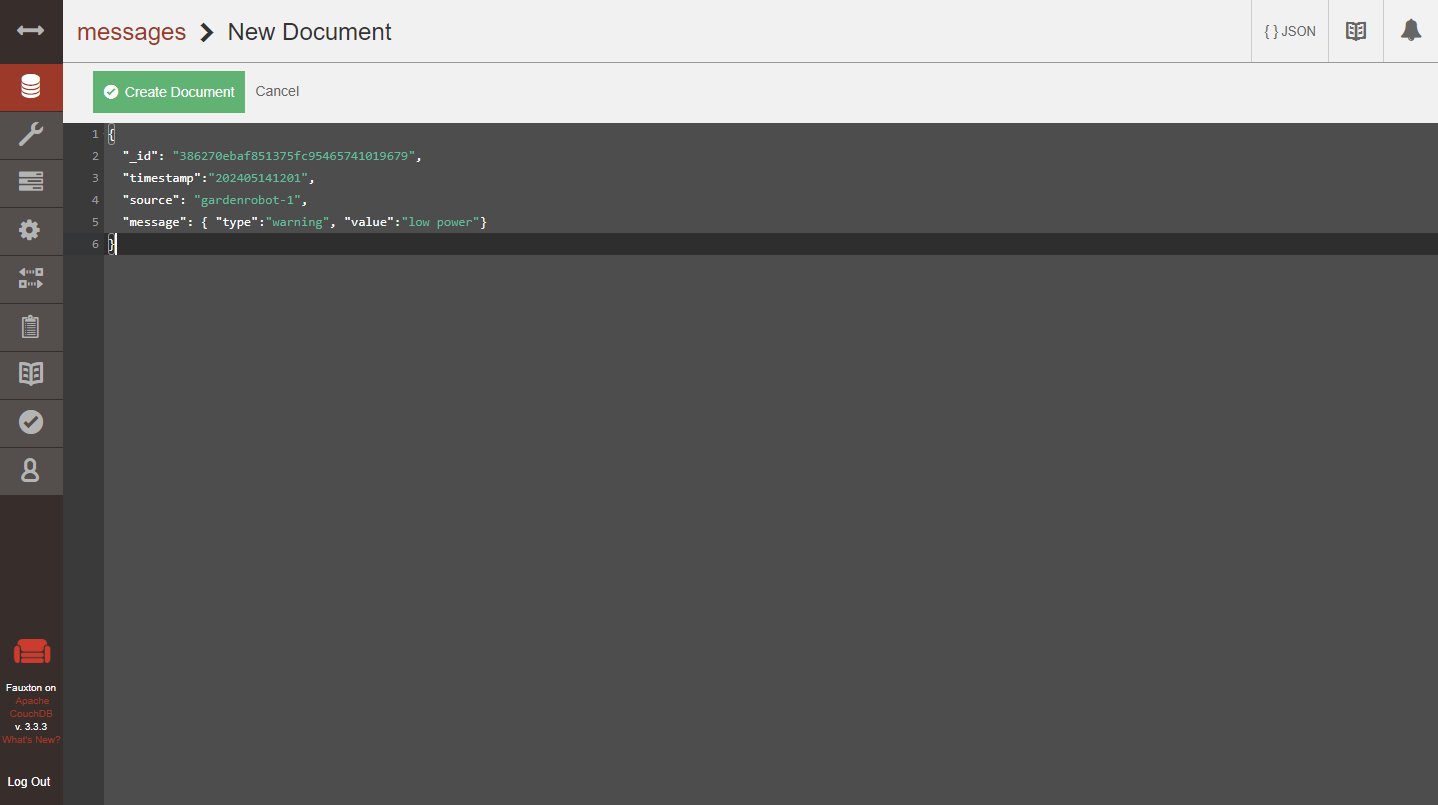
Abbildung 3: Beim Anlegen eines Dokuments in Fauxton sollten Sie stets überlegen, ob sich nicht eine ID mit vorangestelltem Zeitstempel empfiehlt.
ACID, Append Only, MVCC
Der Revisionsnummer, die die CouchDB automatisch beim ersten Speichern in das Dokument eingefügt hat, kommt eine zentrale Funktion im CouchDB-System zu. Ohne Angabe der Revisionsnummer, bestehend aus einer fortlaufenden Versionsnummer und einem Hash des Inhalts, lassen sich Dokumente weder verändern noch löschen. Obendrein gibt es ohne angegebene Revisionsnummer keine Update-Möglichkeiten. Woran liegt das?
Die Datenspeicherung in der CouchDB erfolgt durch das Anhängen neuerer Daten an ältere. Sie erfüllt die ACID-Bedingungen (Atomicity, Consistency, Isolation, Durability). Ein Datensatz wird entweder komplett oder – im Fehlerfall – gar nicht geschrieben. Veränderungen an einem Datensatz sind angehängte neuere Versionen eines Dokuments, dadurch entfällt das Locking von Datensätzen bei Schreiboperationen. Solange Sie nicht explizit die Daten alter Revisionen löschen, können Sie die gesamte Historie eines Dokuments unter Verwendung alter Revisionsnummern abrufen.
Um die gleichzeitige Datenänderungen dennoch zu kontrollieren, nutzt die CouchDB den Ansatz von MVCC (Multi Version Concurrency Control) unter Zuhilfenahme der Revisionsnummer. Gerade bei mehreren zeitlich sehr nahen Lese-/Schreibvorgängen spielt diese Eigenschaft eine wichtige Rolle. Wenn zwei Benutzer Dokument A mit der Revisionsnummer »1-c6438911bbf« in einem Programm öffnen und verändern, gewinnt das Programm, das zuerst die bislang gültige Revisionsnummer beim Speichern mitgibt. Durch das Speichern erhöht sich die Revisionsnummer des Dokuments. Die Version, die als Zweites gesichert werden soll, weist nun einen veralteten Revisions-Key auf. Ihr wird daher ein Document-Update-Conflict-Fehler gemeldet. Am Ende ist das Benutzerprogramm für das Konfliktmanagement zuständig.
Anders sieht es bei CouchDB-Replikationen aus. Wenn hier in einem Cluster dasselbe Dokument geändert wird und sich etwa durch Störungen die Replikation verzögert, entscheidet das Datenbanksystem, welche Version gewinnt, und behält das zweite Dokument als vorherige Version.
Map/Reduce und Views
Ohne eigene Abfragen steckt hinter CouchDB zunächst lediglich ein Key/Value-Store mit der Möglichkeit, die Dokumente anhand der IDs einzugrenzen. Einzelne Dokumente werden mit einem »GET«-Request unter Angabe des Datenbanknamens und der Dokument-ID gelesen (Listing 3, Zeile 12). Für das Abrufen mehrerer Dokumente kommt die CouchDB-eigene Abfrage »_all_docs« auf Datenbankebene zum Einsatz (Listing 3, Zeile 14).
Diese Abfrage ist bereits ein Vorgriff auf die Möglichkeiten von Map/Reduce. Die Funktion »_all_docs« liefert eine Liste sämtlicher Dokumente in einer Datenbank inklusive der aktuellen Revisionsnummern. Was aber fehlt, ist der eigentliche Inhalt der Dokumente. Ergänzen Sie die URL der Abfrage durch den Parameter »include_docs=true«, gibt die CouchDB zusätzlich die Dokumentdaten in dem Eintrag »doc« pro Zeile aus.
Um die Liste der gewünschten Dokumente einzugrenzen, gibt es für die Abfrage »_all_docs« die Möglichkeit, mit »startkey=xxx« und »endkey=yyy« einen Bereich von Keys zu definieren, aus dem Sie Dokumente erhalten möchten. Das ist allerdings nur dann sinnvoll, wenn die Dokument-IDs so aufgebaut sind, dass sie sich gut eingrenzen lassen, beispielsweise durch Zeitangaben.
Soll die Datenbank wenige, ganz bestimme Dokumente laden, versehen Sie einen POST-Request auf »_all_docs« mit dem Attribut »keys”:[key1,key2,…]«. Ebenso werden ausschließlich mit der Angabe »include_docs=true« die kompletten Dokumente zurückgegeben (Listing 3, Zeile 16). Damit die Dokumente schemalos zu speichern und unter Angabe der ID wieder abzurufen, enden die Fähigkeiten der CouchDB aber noch lange nicht.
Beispielsweise sollen vielleicht nur Statusmeldungen erscheinen, die für einen Alarm stehen, oder alle Statusmeldungen eines bestimmten Typs. Doch wie lässt sich das umsetzen, wenn sich lediglich nach der ID einer Statusmeldung suchen lässt und diese IDs zudem zufällige UUIDs sind? Die Lösung: Hinter der CouchDB verbirgt sich eben kein reiner Key-Value Store, sondern sie kann mithilfe von Map/Reduce-Indizes andere Abfragen als nach der ID erstellen. Eigene Map- und Reduce-Funktionen programmiert man von Haus aus in Javascript. Andere Sprachen lassen sich jedoch durch Änderung der Query-Server-Einstellung der Instanz implementieren. Interne Reduce-Funktionen wie »_count« oder »_sum« sind nativ in Erlang implementiert und somit beim Indizieren sehr leistungsfähig.
Ein wichtiger Punkt bei Map/Reduce lautet, dass es während der Indizierung keinen Zugriff auf andere Dokumente gibt. Jedes Dokument wird allein für sich betrachtet. Es ist allerdings möglich, zur Abfragezeit ein referenziertes Dokument durch »_include_docs=true« in das Ergebnis einzubetten. Die Map-Funktion bekommt als Eingangsparameter immer ein komplettes Dokument. Je nach gewünschtem Index schreibt der Befehl »emit(key,value)« einen Eintrag in den Index.
function (doc) { emit(doc.timestamp, 1); }
Der Wert für »value« lässt sich frei wählen und kann Null sein. Nur wenn Sie die Liste später durch eine Reduce-Funktion gruppieren wollen, muss ein Wert in »value« stehen, der zusammengefasst oder gezählt werden kann. Da wir später eine Statistik über die Anzahl der Meldungen pro Stunde haben möchten, kommt zu jedem Key zunächst eine »1« als Value dazu. Der Reduce-Schritt ist optional und nötig, wenn die Ergebnisse der Liste beispielsweise summiert werden sollen oder wenn die Abfrage gruppiert wird. Für den Einstieg genügt eine der nativ integrierten Reduce-Funktionen wie »_sum« oder »_count«. Eine Map/Reduce-Funktion, die einen Index schreibt und optional aggregiert, heißt in der CouchDB-Welt View. Doch wohin mit damit?
Design Documents
Abfragen und andere Funktionen werden in Dokumenten innerhalb der Datenbank gespeichert, in der auch die Datendokumente liegen. Die ID des Dokuments beginnt stets mit »_design/name«, es nennt sich folglich Design-Dokument. Dabei müssen nicht alle Abfragen einer Datenbank nur in einem Design-Dokument gesichert sein – im Gegenteil, das Verteilen auf unterschiedliche Design-Dokumente erscheint aus Performance-Gründen ratsam. Ein Design-Dokument entspricht einem Container für eine Vielzahl von Funktionen der CouchDB (View, Update, Filter, Validate). Momentan interessieren uns die Map/Reduce-Funktionen, die als Views in dem Design-Dokument abgelegt sind. Um eine Liste aller Zeitstempel der Statusmeldungen zu bekommen, speichern Sie ein Design-Dokument mit der View und der Map-Funktion in der Datenbank »messages« (Listing 5).
Listing 5
Design-Dokument mit Views
{
"_id": "_design/abfragen",
"_rev": "6-856a5c52b1a9f33e136b7f044b14a8e6",
"language": "javascript",
"views": {
"nach-timestamp": {
"map": "function (doc) {\n if (doc.timestamp) {\n emit(doc.timestamp, null);\n }\n}"
},
"nach-stunden": {
"map": "function (doc) {\n if (doc.timestamp) {\n emit(doc.timestamp.substr(8,2), null);\n }\n}"
}
}
}
# Ergebnis einer Abfrage /messages/_design/abfragen/_view/nach-timestamp
{"total_rows":3,"offset":0,"rows":[
{"id":"386270ebaf851375fc95465741019679","key":"202405141201","value":1},
{"id":"386270ebaf851375fc9546574101a657","key":"202405150200","value":1},
{"id":"386270ebaf851375fc95465741020597","key":"202405160800","value":1}
]}
Da Design-Dokumente bis auf die spezielle ID ganz normale Datendokumente sind, gleichen sich auch die Speichervorgänge. Ob »PUT«/»POST« oder in Fauxton, Sie tragen das Design-Dokument wie gewohnt in die Datenbank ein. Bitte beachten Sie, dass Sie beim Speichern des Design-Dokuments die Zeilenenden der Funktionen durch ein Newline (»\n«) ersetzen müssen.
Nachdem Sie ein Design-Dokument mit Views gesichert oder verändert haben, beginnt die Indizierung sämtlicher in dieser Datenbank abgelegten Dokumente in allen Views des Design-Dokuments. Dieser Vorgang nimmt je nach Anzahl der Dokumente einige Zeit in Anspruch. Den Fortschritt können Sie in Fauxton unter Active Tasks oder per GET-Request (mit Authentifizierung) auf »http://localhost:5984/_active_tasks« beobachten. Kommen später neue Datendokumente hinzu oder wird ein Datendokument verändert, wird automatisch diese Funktion für dieses eine Dokument aufgerufen. Das aktualisiert den bestehenden Index. Das Ergebnis einer Abfrage lässt sich über Fauxton direkt einsehen (Abbildung 4).
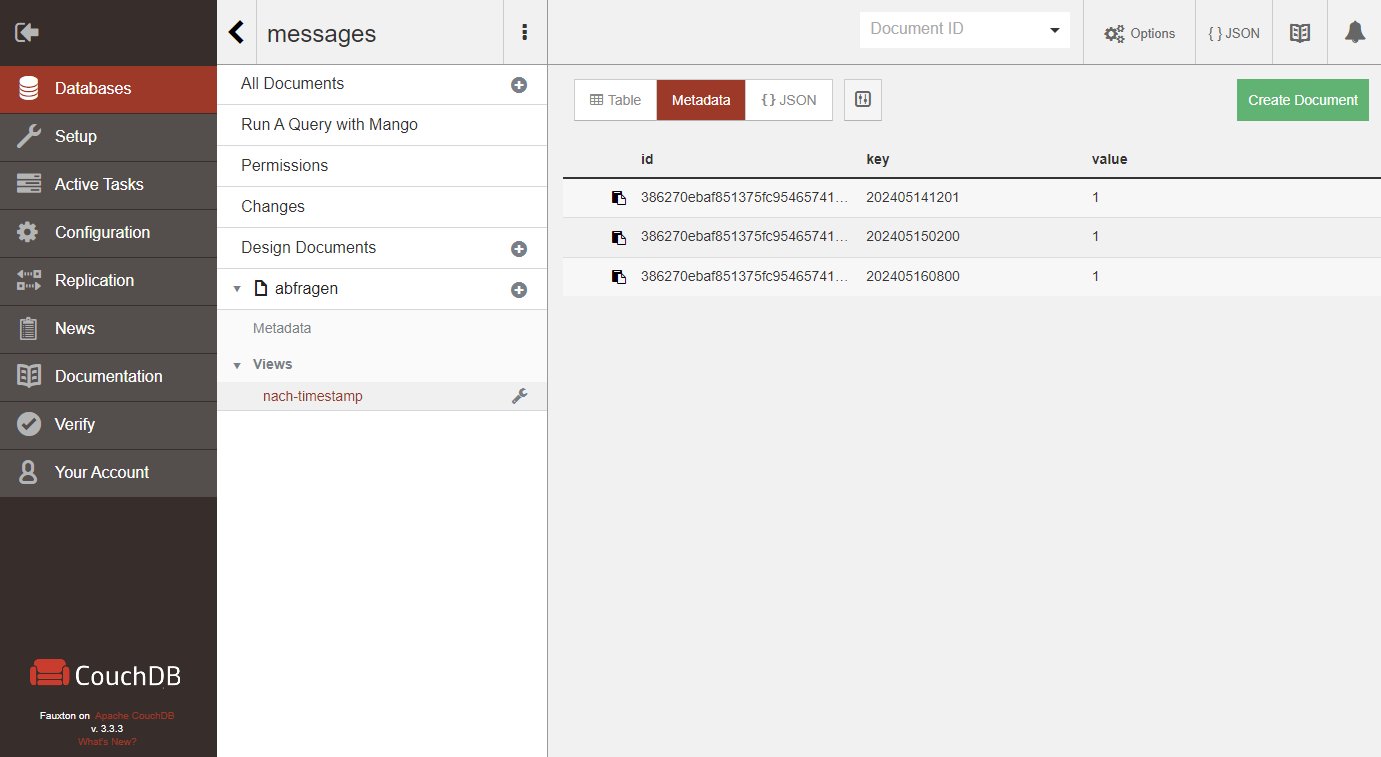
Abbildung 4: Das Ergebnis einer Indexaktualisierung sehen Sie in Fauxton ein.
Etwas kompakter fällt das Ergebnis bei einer Abfrage per Curl oder ganz einfach über den Browser unter »http://localhost:5984/messages/_design/abfragen/_view/nach-timestamp« aus. Im Ergebnis der Abfrage ist der gewünschte Index (“timestamp”) nun als Key angegeben und aufsteigend sortiert. Jede View liefert, sofern Dokumente im Index vorhanden sind, die ID des Dokuments und den Key/Value aus dem Emit-Statement.
Selbstverständlich möchte man nicht alle Daten aus der Liste als Ergebnis erhalten. Durch das Eintragen der Keys in einen internen B+-Baum realisieren Sie flott die gewünschten Bereichsabfragen. So sehen Sie mit dem Parameter »startkey=”20240515″« beim Aufruf der View alle Statusmeldungen ab dem 15. Mai 2024, mit dem Parameter »endkey=”20240516″« alle Meldungen bis zum 16. Mai.
Durch das Kombinieren von »startkey« und »endkey« in einem Aufruf lässt sich ein Zeitbereich eingrenzen. Dabei sollten Sie im Hinterkopf behalten, dass bei einer Standardabfrage der Endkey zum Ergebnis gehört. Dementsprechend liefert eine Abfrage von »startkey=”20240516″&endkey=”20240516″« keine Ergebnisse, da zwar korrekt ab »20240516« gesucht wird, aber gleichzeitig nur bis (exklusiv) »20240516«.
Mit der gewöhnlichen Abfrage bekommen Sie nun die Liste der IDs und Keys, doch immer noch nicht die Inhalte der Dokumente. Nun kann entweder das Benutzerprogramm anhand der Liste der IDs die Dokumente einzeln herunterladen, oder in der Abfrage wird zusätzlich der Parameter »include_docs=true« angegeben. Wie bei »_all_docs« findet sich das eigentliche Datendokument dann in der Ausgabeliste in jeder Zeile unter »doc«.
Anhand des Beispiels offenbaren sich darüber hinaus die Grenzen der Abfragen mit Mapping. So fördert diese Abfrage nicht zutage, welche Meldungen vormittags oder nachts aufgetreten sind. Bereichssuchen funktionieren ausschließlich von vorn nach hinten. Um nach der Uhrzeit zu suchen, braucht es eine zweite View, die nur die Stunden emittiert (Listing 6).
Listing 6
Views nach Timestamp und Stunden
{
"_id": "_design/abfragen",
"_rev": "6-856a5c52b1a9f33e136b7f044b14a8e6",
"language": "javascript",
"views": {
"nach-timestamp": {
"map": "function (doc) {
if (doc.timestamp) { emit(doc.timestamp, null); }
}"
},
"nach-stunden": {
"map": "function (doc) {
if (doc.timestamp) { emit(doc.timestamp.substr(8,2), null);}
}"
},
"nach-stunden-count": {
"map": "function (doc) {
if (doc.timestamp) {emit(doc.timestamp.substr(8,2), 1);}
}",
"reduce": "_count"
},
"nach-source-type-count": {
"reduce": "_count",
"map": "function (doc) {
if (doc.source && doc.message.type && doc.message.value) {
emit([doc.source, doc.message.type,doc.message.value], 1);
}
}"
}
}
}
Reduce-Funktion
Da das Thema Reduce-Funktionen relativ umfangreich ausfällt [2], kommt hier lediglich die CouchDB-eigene Funktion »_count« zur Sprache. Sobald eine Reduce-Funktion in einer View vorhanden ist, wird das Ergebnis des Mappings nicht mehr als Liste ausgegeben, sondern in der Reduce-Funktion zusammengefasst.
Um die Anzahl der Statusmeldungen pro Stunde auszuwerten, müssen Sie die View »nach-stunden« etwas modifizieren (Listing 6). Als virtueller Strich zum späteren Zählen und Zusammenfassen wird als Value eine 1 in den Index geschrieben. Ein normaler Aufruf der View fasst zunächst alle Zeilen zusammen und gibt als Ergebnis die Summe aus. Das Feld »key« ist in diesem Fall »null« (Listing 7). Doch das entspricht kaum dem erwarteten Ergebnis. Das Geheimnis liegt im Parameter »group=true« bei der Abfrage. Er legt fest, dass die Summierung nach »key« sortiert ausgegeben werden soll. Und schon ist das gewünschte Ergebnis erreicht (Listing 8).
Listing 7
View mit Reduce ohne Gruppierung
$ curl -X GET localhost:5984/messages/_design/abfragen/_view/nach-stunden-count
{"rows":[
{"key":null,"value":4}
]}
Listing 8
View mit Gruppierung nach Key
$ curl -X GET localhost:5984/messages/_design/abfragen/_view/nach-stunden-count?group=true
{"rows":[
{"key":"02","value":1},
{"key":"08","value":1},
{"key":"12","value":2}
]}
Nun lassen sich als Key nicht nur einfache Werte verwenden, sondern auch Arrays. Somit kann eine einzige View die Ergebnisse in mehreren Ebenen gruppieren und zählen. Dazu gehören eine Map-Funktion, die ein Array als Key und einen anderen Wert (hier 1) als Value ausgibt (Listing 9) sowie zur Abfrage der entsprechenden Gruppierungsparameter »group_level=x« . Ein »group_level« von 0 gruppiert überhaupt nicht, und die Reduce-Funktion liefert in unserem Beispiel nur die Anzahl 4. Setzen Sie das »group_level« auf 1, wird anhand des ersten Eintrags des Arrays gruppiert und gezählt. Bei »group_level=2« fasst CouchDB die ersten beiden Einträge zusammen und zählt sie gruppiert.
Selbstverständlich lässt sich das erneut mit dem schon bekannten »startkey« und »endkey« kombinieren, etwa um nur die Source »gardenrobot-1« auszuwerten. Auch dabei ist die Logik zu beachten, dass der Endkey nicht in der Ausgabe enthalten ist. Sie benötigen dazu einen Endkey, der höher ist als »gardenrobot-1«. Da nicht bekannt ist, welcher der nächstgrößere Key ist, muss der Endkey entweder »gardenrobot-1X« heißen oder »gardenrobot-1″,{}«, da ein leeres Objekt höher rangiert als jeder String.
Listing 9
View mit Reduce und Gruppierung
$ curl -X GET localhost:5984/messages/_design/abfragen/_view/nach-source-type-count?group_level=1
{"rows":[
{"key":["18739949083333"],"value":1},
{"key":["gardenrobot-1"],"value":2},
{"key":["server"],"value":1}
]}
Replikation
Die Datenbank »messages« bildet den zentralen Punkt, an dem alle Statusmeldungen einlaufen. Allerdings wäre es aus Performance- oder Speichergründen sinnvoll, die Statusmeldungen in weiteren unterschiedlichen Datenbanken sortiert abzulegen. Eine Datenbank für IoT, eine Datenbank für Wetterwarnungen und eine Datenbank für die Servermeldungen. Dank der Replikationsfähigkeiten der CouchDB geht eine Lösung schnell von der Hand. Dazu legen Sie zunächst, wie am Anfang des Artikel beschrieben, drei weitere Datenbanken an: »iot_messages«, »wetter_messages« und »server_messages«.
Jede Datenbank innerhalb einer CouchDB-Installation kann sowohl als Server als auch als Client einer Replikation fungieren. Zwei Datenbanken können sich zudem gegenseitig replizieren. Bei der Replikation spielt es keine Rolle, ob die Datenbanken in derselben CouchDB-Instanz liegen oder nicht. Sie können sogar auf einer CouchDB-Instanz 1 eine Replikation einer Datenbank von Instanz 2 auf Instanz 3 einstellen.
Die Replikation erfolgt durch den Changes Feed einer CouchDB-Datenbank, in dem die Dokument-IDs von geänderten (oder neu angelegten) Dokumenten hinterlegt sind. Ein Anlegen, Updaten oder Löschen eines Dokuments hängt die ID und Revisionsnummer des Dokuments an den Changes Feed an. Vorherige Einträge eines Dokuments verschwinden dabei aus dem Feed, sodass jede Dokument-ID nur einmal vorkommt.
Bei Replikationen von Source zu Target ist wichtig, dass die Revisionsnummer eines geänderten Source-Dokuments höher sein muss als die Revisionsnummer eines Target-Dokuments, damit die Replikation ausgeführt wird. Diesen wichtigen Punkt demonstrieren wir im Folgenden anhand eines kleinen Beispiels.
Sie starten eine einmalige Replikation von der Datenbank Source in die Datenbank Target (aber nicht zurück). Die Datenbank Source erhält das folgende, neue Dokument:
{"_id":"d1",_rev:"1-1k9xyc","name":"Kurowski"}
Das wird nun in die Datenbank Target repliziert, wobei dort das identische Dokument entsteht. Daraufhin findet eine Änderung in der Datenbank Target statt. Als Ergebnis erhöht sich die Revisionsnummer in Target:
{"_id":"d1",_rev:"2-7ks112l","name":"Oliver Kurowski"}
Wird das Dokument in Source ebenfalls modifiziert, schließt sich keine Replikation auf Target an, da die Revisionsnummer nicht höher, sondern gleich ausfällt. In diesem Fall sind die Daten nicht konsistent – es existieren zwei unterschiedliche Dokumente mit derselben ID und Versionsnummer. Erst wenn die Datei in Source ein weiteres Mal verändert wird, steigt die Revisionsnummer auf »3-…« und das Dokument lässt sich nach Target replizieren.
Auch hinter Löschungen von Dokumenten stecken keine eigentlichen Löschungen. Stattdessen markiert die Datenbank das Dokument mit dem Feld »_deleted:true«, die Revisionsnummer erhöht sich und lässt sich dann nicht mehr aufrufen. Wird im vorigen Fall also das Dokument auf Target gelöscht, bekommt es wie bei einer Änderung eine höhere Revisionsnummer, und ein erneutes Replizieren wäre erfolglos. Erst wenn Sie das Dokument in Source erneut modifizieren, zählt die Revisionsnummer weiter, und das Dokument lässt sich replizieren.
Fazit
Ich konnte in diesem Artikel vermutlich lediglich Ihre Neugier auf die Möglichkeiten der CouchDB wecken. Map/Reduce ist ein mächtiges Werkzeug, um Abfragen über große Datenmengen zu gestalten. Gerade in Verbindung mit Gruppierungen zeigt es sich überaus leistungsstark.
Es gibt noch zahlreiche weitere interessante Themen zur CouchDB, auf die ich nicht eingegangen bin. Dazu zählen neben Attachments die Möglichkeit, binäre Daten wie Bilder und andere Formate an ein Dokument anzuhängen und abzurufen, sowie die deklarative CouchDB-Abfragesprache Mango, die es erlaubt, ohne Map/Reduce Daten abzufragen. Letztendlich ist das Cluster- und Replikationsmodell unter anderem mit konfigurierbaren Shards und Kopien ein starkes Argument, die Datenbank kennenzulernen. Viel Spaß dabei!
Infos
- Installation: https://couchdb.apache.org
- Map/Reduce: https://de.slideshare.net/slideshow/couchdb-mapreduce-13321353/13321353





