
© SergeyNivens / 123RF.com
Tabellen dienen in Datenbanken und darüber hinaus als etabliertes Format zum Speichern von Informationen. Doch nicht immer passen sie zu den Anforderungen – ein Argument unter mehreren für NoSQL.
Ereignisse zu bestimmten Daten, Kernladung zu chemischen Eigenschaften, Artikel zu Preisen, Autoren zu Werken, Vokabeln zur Übersetzung – sehr vieles, was wir wissen, dreht sich auf einer abstrakten Ebene betrachtet um die Beziehung von zwei oder mehr Dingen zueinander. Eine naheliegende Form, derartige Verhältnisse abzubilden, sind die Zeilen und Spalten einer Tabelle. Diesen Vorteil kannten buchstäblich schon die alten Griechen – Ptolemäus beispielsweise schieb bereits im zweiten Jahrhundert astronomische Beobachtungen in Tabellenform auf. Seither hat die Tabelle einen Siegeszug durch sämtliche Lebensbereiche angetreten, angefangen von der Religion, wo man schon vor Jahrhunderten die Schilderung gleicher Ereignisse in verschiedenen Evangelien tabellarisch erfasste (Kanontafeln), bis in die Musik, wo sich die Notenschrift als Tabelle verstehen lässt, bei der die Taktstriche die Spalten markieren und die Notenlinien die Zeilen.
Als in den 70er Jahren des vergangenen Jahrhunderts in der Informatik die Suche nach Möglichkeiten zum effizienten Verwalten großer Datenmengen startete, griff man wieder auf die Tabelle zurück: Edgar F. Codd entwickelte damit das relationale Datenbankmodell und den Vorläufer der Abfragesprache SQL. Beides gibt es bis heute, nach wie vor dominieren relationale Datenbanken (RDBMS) den Markt und stellen die Top Vier: Oracle, MySQL, Microsoft SQL Server und PostgreSQL (2022). Weshalb also sollte man sich da nach Alternativen umsehen, wo doch die hergebrachte Datenbanktechnik eine offenbar so universelle Grundform der Informationsspeicherung nutzt?
Spezielle Daten
Eine Antwort auf die Frage lautet: Weil zwar vieles, aber eben nicht alles, sich gut als Tabelle notieren lässt. Das betrifft zunächst unstrukturierte Daten, beispielsweise Texte, in denen die Elemente einer Aussage nicht separiert in einzelnen Attributen und deren Werten vorliegen. Damit lassen sie sich nicht einfach Zeilen und Spalten zuordnen, sodass sich Tabellen dafür nicht anbieten. Genauso wenig empfehlen sich Tabellen in Fällen, in denen die Art und Anzahl der zu speichernden Attribute stark schwankt. Da das relationale Modell mit einem Datenbankschema arbeitet, das die Tabellen am Anfang fest und unveränderlich definiert, scheitert es daran, spontan auftretende Attribute nachträglich zu integrieren; oder es müsste sich mit ineffizienten, weil nur dünn besetzten Tabellen begnügen, wenn es alle erdenklichen Möglichkeiten vorab aufnehmen würde.
Selbst eher einheitliche und strukturierte Daten müssen sich nicht zwingend für Tabellen eignen. Ein Problem, das Vektordatenbanken aus der Welt schaffen, liegt zum Beispiel in der Dimension der Daten. Sie gehen mit als Vektoren definierten Daten um, die Sie sich im dreidimensionalen Raum als Pfeile vorstellen können. Die Pfeile weisen ausgehend vom Ursprung des Koordinatensystems in einer bestimmten Richtung und mit einer bestimmten Länge auf einen Punkt im Raum. Vektoren kommen etwa bei sogenannten Embeddings zum Einsatz, wie sie große Sprachmodelle verwenden, um Wörter zu repräsentieren (Abbildung 1).
Weil unsere Vorstellungskraft lediglich für drei Dimensionen ausreicht, stellen wir uns stark vereinfacht vor, die Vektoren der drei Begriffe “Hund”, “Katze” und “Maus” würden auf Punkte in der linken hinteren unteren Ecke eines Raums deuten und die der Begriffe “Motor”, “Getriebe” und “Reifen” wiesen in die vordere obere rechte Ecke. In Wirklichkeit besitzen Worte nicht drei, sondern Hunderte oder Tausende Dimensionen. Trotzdem lassen sich zwischen ihnen – wie im dreidimensionalen Raum – Entfernungen berechnen.
Auf diese Weise bestimmt der Anwender dann anhand der Entfernungen der Wörter zueinander, dass “Katze”, “Hund” und “Maus” in einem gemeinsamen Kontext bedeutsam sind, der sich mit dem Begriff “Tier” beschreiben lässt. Analog gehört das Wort “Getriebe” in den Kontext “Auto”. Ein Wort mit Hunderten Vektoren passt allerdings nicht nur schlecht in eine Tabelle, man könnte auch mit SQL kaum die relevante Frage formulieren, nämlich: Welche Worte kommen im selben Kontext vor, liegen also im vieldimensionalen Raum in der Nähe des Ausgangsbegriffs? Solche Abfragen nach den nächsten Nachbarn sind eine Spezialdisziplin der Vektordatenbanken.
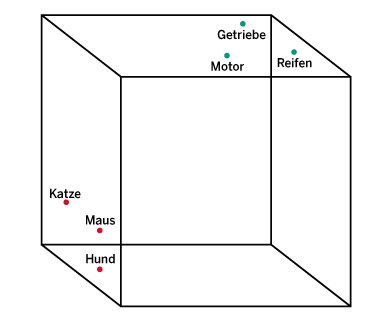
Abbildung 1: Worte als Vektoren – in Wirklichkeit allerdings in viel mehr Dimensionen, als sich bildlich darstellen lassen – kann man in Vektordatenbanken ablegen.
Neben der Art der Daten und ihrer Dimensionalität gibt es weitere Eigenschaften einer Datenbank, bei denen das relationale Modell an seine Grenzen stoßen kann. Das betrifft zum Beispiel Skalierbarkeit und Ausfallsicherheit. Relationale Datenbanken skalieren bevorzugt vertikal, das heißt durch Aufrüsten des Datenbankservers (mehr CPUs, mehr RAM, schnellere Massenspeicher). Hier setzt selbstverständlich die zur Verfügung stehende Technik Grenzen. Im Prinzip grenzenlos funktioniert dagegen das horizontale Skalieren. Zahlreiche NoSQL-Datenbanken beherrschen es. Dabei wird statt leistungsfähigerer Hardware mehr von derselben Hardware von der Stange hinzugefügt. Damit das klappt, muss sich die Workload parallelisieren lassen, und die Daten müssen sich über viele Knoten verteilen lassen. Ist die Verteilung obendrein redundant, trägt das zugleich zur Ausfallsicherheit bei, weil überlebende Knoten mit demselben Datenbestand ausgefallene ersetzen können.
CAP-Theorem
Alle wünschenswerten Eigenschaften können jedoch nie beisammen sein. Das besagt das CAP-Theorem, demzufolge stets lediglich zwei der drei folgenden Forderungen erfüllt sein können: Konsistenz (Consistency, C), Verfügbarkeit (Availability, A) und Partitionstoleranz (P) (Abbildung 2). Konsistenz meint, dass bei jedem Lesevorgang immer die zuletzt aktualisierten Daten empfangen werden. Ist das nicht möglich, muss eine Fehlermeldung erfolgen. Verfügbarkeit heißt, dass es auf jede Anfrage immer eine Antwort gibt – möglicherweise aber nicht mit den aktuellsten Daten. Und unter Partitionstoleranz versteht man, dass das System weiterarbeiten kann, obwohl der Datenbestand dadurch partitioniert wurde, dass Nachrichten zwischen den Clusterknoten verlorengegangen sind oder verzögert wurden.
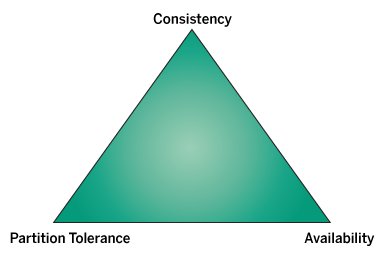
Abbildung 2: Das CAP-Theorem behauptet, dass sich immer nur zwei der drei Eigenschaften eines verteilten Systems gleichzeitig umsetzen lassen.
Alle drei Forderungen zusammen sind nicht zu erfüllen. Bei relationalen Datenbanken handelt es sich in der Regel um CA-Systeme. Das bedeutet: Sie wahren die Konsistenz und bleiben dabei verfügbar, sind aber nicht partitionstolerant, weil sie sich nicht so über mehrere Knoten verteilen lassen, dass ein Zusammenbruch der Kommunikation zwischen den Knoten zu tolerieren wäre. CP-Systeme, dazu zählt beispielsweise MongoDB, eine Single-Master-Datenbank mit genau einem Primary Node für alle Schreiboperationen, bewahren ebenfalls die Konsistenz und sind partitionstolerant, verkraften also den Ausfall der Kommunikation zwischen zwei Knoten. Sie stehen danach jedoch solange nicht mehr zur Verfügung, bis alle Secondary Nodes zum dann neu eingesetzten Primary Node wieder aufgeschlossen haben – es mangelt in dieser Zeit dementsprechend an Availability (A). AP-Systeme wie Cassandra oder CouchDB sind immer verfügbar und ebenso partitionstolerant, allerdings nicht immer konsistent.
Der Anwender muss sich also entscheiden: Spielt für ihn die Konsistenz die Hauptrolle (zum Beispiel bei Finanzsoftware), bevorzugt er voraussichtlich eine relationale Datenbank. Legt er dagegen mehr Wert auf Verfügbarkeit oder Partitionstoleranz, greift er zu einer NoSQL-Variante.
Transaktionen
Das wirkt sich zudem auf das Transaktionsmodell aus. Das Modell, das hier die Konsistenz in den Mittelpunkt stellt, ist ACID. ACID steht für Atomicity (Atomität), Consistency (Konsistenz), Isolation (Isolation) und Durability (Dauerhaftigkeit). Es ist das vorherrschende Transaktionsmodell bei relationalen Datenbanken und garantiert Konsistenz, auch um den Preis womöglich verminderter Verfügbarkeit.
Daneben existieren ebenso andere Transaktionsmodelle wie BASE (Basically Available, Soft State, Eventual Consistency), die Verfügbarkeit höher bewerten als Konsistenz. Sie garantieren immer eine Antwort, selbst wenn die vielleicht nicht immer die aktuellsten Daten liefert. Falls sich in einem sozialen Netz zum Beispiel die Anzahl der Kontakte vorübergehend einmal nicht auf dem neuesten Stand befindet, mag das eher zu verschmerzen sein als eine Fehlermeldung, die das System auslösen müsste, weil es auf die aktuellsten Werte gerade nicht zugreifen konnte. Das BASE-Modell kommt eher bei NoSQL-Vertretern vor.
Replikation
Mit dem Transaktionsmodell eng verknüpft sind Probleme bei der Replikation, die sich speziell dort einstellen können, wo das System strikt am ACID-Modell festhalten muss. Wird unter diesen Umständen eine Transaktion auf verschiedene Knoten repliziert, kommt es nicht nur darauf an, welche Aktionen repliziert und committed werden, sondern auch, in welcher Reihenfolge. Ansonsten können sich die Konsistenz verletzende Widersprüche zwischen den Replikaten ergeben.
Verteilte relationale Datenbanken erfordern deswegen spezielle Protokolle wie das des sogenannten Two-Phase-Commits. Dabei gibt es zwei Rollen: Koordinator und Agent. In der ersten Vorbereitungsphase macht der Koordinator die Agenten mit der Transaktion bekannt und fordert sie zur Abstimmung darüber auf. Stimmen alle zu, wird die Transaktion in der zweiten Phase commited. Fällt die Abstimmung nicht einstimmig dafür aus oder bleiben Antworten aus, veranlasst der Koordinator alle Agenten dazu, die Transaktion zurückzurollen. Das Verfahren ist kompliziert, und besonders bei vielen kurzen Transaktionen können die daraus resultierenden Locks wegen der notwendigen Netzwerkkommunikation um Größenordnungen länger dauern als die eigentliche Transaktion.
Wesentlich einfacher gestaltet sich die Sache, wenn man temporäre Konsistenzverletzungen tolerieren kann, was viele NoSQL-Datenbanken ermöglichen. Das Abmildern der ACID-Garantien funktioniert auf zwei Wegen: Zum einen, indem die Garantie lediglich für einen Teilbereich der Datenbank gegeben wird, beispielsweise bloß für ein einzelnes Tupel in einem Key-Value-Store, für eine Datenbankpartition oder einen Shard. Ein kompliziertes verteiltes Commit-Protokoll braucht es dann zwar nicht mehr, aber nun muss der Applikationsentwickler dafür sorgen, dass er Transaktionen, die mehrere dieser Teilbereiche überspannen, geschickt aufteilt. Zum anderen lässt sich ganz auf starke Konsistenz verzichten, was allerdings nur für einige Webanwendungen akzeptabel erscheint. In jedem Fall verzeichnen NoSQL-Datenbanken damit erhebliche Performancegewinne.
Fazit: Für und Wider
RDBMS sind also das ältere und am weitesten verbreitete Modell, das meist streng auf Konsistenz achtet, seine Daten häufig ohne Redundanz in normalisierten Tabellen speichert und über eine ausgefeilte Abfragesprache (SQL) verfügt. Letztere erlaubt es sehr effizient, Daten miteinander zu verknüpfen (Joins). Für die genannten Vorteile bezahlen Anwender mit Schwierigkeiten beim Skalieren und der Hochverfügbarkeit sowie mit geringerer Performance.
Demgegenüber stehen diverse Spielarten von NoSQL-Datenbanken, die Daten verwalten können, für die Tabellen kaum infrage kommen. Zusätzlich lassen sie sich oft besser skalieren und zeigen sich leistungsfähiger. Hochverfügbarkeit bieten sie nicht selten nebenher. Doch das hat genauso seinen Preis: Konsistenz lässt sich nicht unter allen Umständen garantieren, die Speicherung kann redundant sein und deshalb mehr Platz beanspruchen, die Abfragesprache ist weniger mächtig als SQL, und bestimmte bereichsübergreifende Abfragen müssen Applikationsentwickler vorher bedenken.
All das führt zu dem Schluss, dass generell keines der beiden Modelle per se das andere schlägt. Stattdessen muss der Anwender vom Einsatzzweck her beurteilen, welches im vorliegenden Fall die meisten Vorteile verspricht und gleichzeitig notwendige Voraussetzungen erfüllt.





