
© Filippo Carlot / 123RF.com
Das Archiv des Deutschen Wetterdiensts umfasst Klimadaten aus Deutschland für mehr als ein Jahrhundert. Per Python-Skript kann man diese Rohwerte abholen und die mittlere Jahrestemperatur für unterschiedliche Regionen und Jahre berechnen.
Gibt es den Klimawandel, und ist er menschengemacht? Beide Fragen untersucht die Wissenschaft. In beiden Fällen kommt sie zu einer eindeutigen Antwort. Die zweite Frage bleibt hier außen vor, die erste versuchen wir uns selbst zu beantworten – mit der Skriptsprache Python und Daten aus dem Internet.
Seit dem 20. Jahrhundert zeichnet der Deutsche Wetterdienst (DWD [1]) Klimadaten für Deutschland auf und hält sie für jedermann zugänglich vor. Im Folgenden erläutern wir exemplarisch anhand von Temperaturdaten, wie sich das Klima in Deutschland und seinen Regionen in den letzten 100 Jahren entwickelte. Die Arbeit erledigt Python: Es lädt die Daten, wertet sie aus und bereitet sie grafisch auf.
Die Daten
Der Deutsche Wetterdienst ist dafür bekannt, seine Messungen und Vorhersagen offen zu kommunizieren. Vorbildlich stellt er Niederschlags- und Temperaturdaten in ordentlich gepflegten Verzeichnissen zusammen, auf die auch ein Webbrowser zugreifen kann.
Unsere kleine Demonstration basiert auf den Jahresmittelwerten der Temperatur [2], ortsaufgelöst auf einer Skala von 1 km2. Wollen Sie es genauer wissen, finden Sie beim DWD auch Temperaturangaben in Abständen von Monaten, Tagen und sogar fünf Minuten.
Alle Skripte zu diesem Beitrag liegen als Jupyter-Notebook vor, das Sie bei Interesse im Download-Bereich zum Artikel finden.

Abbildung 1: Die Webseite des Deutschen Wetterdiensts hält Temperaturdaten für den Zeitraum ab 1881 vor.
Daten abholen
Die Daten des Wetterdiensts folgen dem Namensschema »grids_germany_annual_air_temp_mean_{}17.asc.gz«, wobei die geschweiften Klammern als Platzhalter für das Jahr fungieren. Die Endung ».asc« verweist auf eine einfache Textdatei, ».gz« auf ein Gzip-Archiv.
Die entsprechende Funktion aus der Python-Bibliothek Pandas benötigt nur eine Zeile, um einzelne Dateien in ein Dataframe umzuwandeln (Listing 1). Die Variable »fn« enthält den Dateinamen, nachdem ».format(str(y))« das Jahr eingesetzt hat. Die ersten sechs Zeilen in der Datei enthalten Kommentare und werden übersprungen. Ein oder mehrere Leerzeichen trennen die Spalten voneinander – eine Kleinigkeit für reguläre Ausdrücke. Der Ausdruck »\s« steht für Whitespace, also ein Leerzeichen oder auch einen Tabulator. Der Zusatz »+« legt fest, dass mindestens ein Leerzeichen die Spalten trennt. Eine weitere Codezeile speichert die Daten. Auch hier erkennt Pandas an der Dateiendung, dass es sich um GZ-komprimierte Daten handelt.
Im vollständigen Skript im Jupyter-Notebook steuert die Variable »READDATA«, ob Python tatsächlich Daten vom DWD-Server einlesen oder zur Kontrolle lediglich die Dateinamen ausgeben soll. Das verhindert bei Testläufen unnötige Requests an den DWD-Server.
Listing 1
Dateien abholen
import pandas as pd
fnt = 'https://opendata.dwd.de/climate_environment/CDC/grids_germany/annual/air_temperature_mean/grids_germany_annual_air_temp_mean_{}17.asc.gz'
fnot = 'data/dwd/DE_annual_tmean_{}2.asc.gz'
startfrom = 2020
endby = 2023
for y in range(startfrom,endby):
print(y, end= ', ')
fn = fnt.format(str(y))
df = pd.read_csv(fn,skiprows=6, header = None, sep= '\s+')
fno = fnot.format(str(y))
df.to_csv(fno, index = None )
Datenstruktur
Listing 2 liest zwei Dateien ein, die das vorige Skript aus dem Internet kopiert hat. Die Datei besteht aus 861 Zeilen und 654 Spalten, durchnummeriert von 0 bis 653. Die enthaltenen Werte stehen für Zehntel Grad Celsius, der Wert »-999« dient als Platzhalter für fehlende Messungen. Die Bedeutung der Zahlenkolonnen erschließt sich nach einer Umwandlung der Daten in ein Bild.
Listing 2
Daten einlesen
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
year1 = 1960
year2 = 2022
fn1 = f'data/dwd/DE_annual_tmean_{year1}.asc.gz'
fn2 = f'data/dwd/DE_annual_tmean_{year2}.asc.gz'
df1 = pd.read_csv(fn1)
df2 = pd.read_csv(fn2)
print(df1.shape)
Der Befehl »imshow« der Bibliothek Matplotlib interpretiert die Daten eines Arrays als Bildpunkte. Abbildung 2, das Resultat des Codes aus Listing 3, lässt den Umriss Deutschlands erkennen. Die Differenzen der fehlenden Werte »-999« liefern den Wert 0 und bilden den schwarzen Randbereich. Die Division durch 10 rechnet die Werte von Zehntel Grad in volle Grad Celsius um.
Listing 3
Tabellenwerte als Grafik
plt.imshow((df2-df1)/10, cmap = 'gray') plt.colorbar() plt.show()
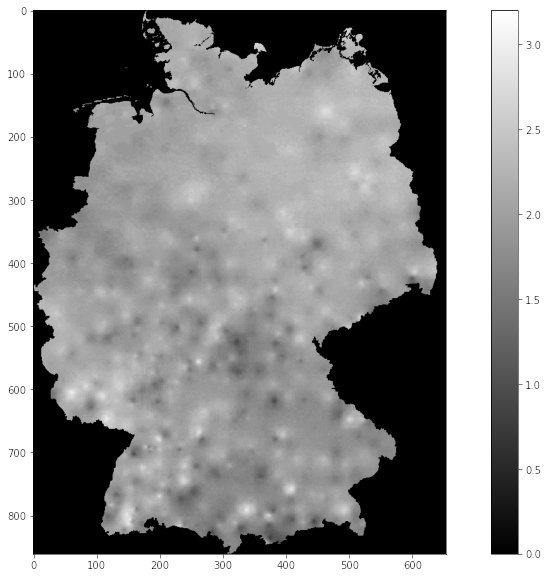
Abbildung 2: Die Differenz der mittleren Jahrestemperaturen von 1960 und 2022, erzeugt durch den Code aus Listing 3.
Bereits an dieser Stelle fällt auf, dass die Grauwertzuordnung rechts im Bild keine negativen Werte aufweist. Im Jahr 2022 existierte also in Deutschland kein einziger Bereich, der im Jahresmittel kälter war als 1960. Stattdessen gibt es Hotspots, die im Mittel um mehr als 3 Grad Celsius wärmer waren als gut 60 Jahre zuvor.
Listing 4
Eckdaten der Gauß-Krüger-Projektion
NCOLS 654 NROWS 866 XLLCORNER 3280414.711633467 YLLCORNER 5237500.62890625 CELLSIZE 1000
Hinter den Daten, die als Bildpunkte die Fläche Deutschlands widerspiegeln, verbirgt sich eine Gauß-Krüger-Projektion [3] mit dem Koordinatenreferenzsystem EPSG:31467 [4]. Vereinfachend wendet es der DWD auf ganz Deutschland an, der Fehler ist bei einer Auflösung von 1000 Metern vernachlässigbar. Listing 4 nennt den unteren linken Referenzpunkt in Metern. Bei 654 Spalten und 1000 Metern Auflösung liegt beispielsweise der rechte Eckpunkt der Karte bei einem Rechtswert von 3 934 414 Metern, der südlichste Punkt Deutschlands bei 3 589 244 Metern, jeweils mit dem in Listing 4 genannten Hochwert von 5 237 500 Metern (Abbildung 3).
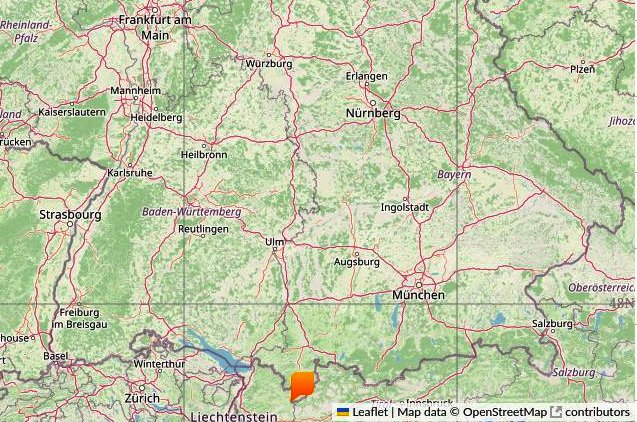
Abbildung 3: Der südlichste Punkt Deutschlands liegt ostwärts des Bodensees (orangefarbene Markierung).
Die Bibliothek Pyproj transformiert Geokoordinaten in nahezu jedes Format, ist aber nicht Gegenstand dieses Artikels. Stattdessen verweisen wir hier auf Online-Umrechner [5] im Internet. Die Tabelle “Großstädte” nennt einige Metropolen, ihre GPS-Koordinaten und den Index bezogen auf die DWD-Datentabelle. Letzterer, mit »rw« (Rechtswert) und »hw« (Hochwert) abgekürzt, folgt unmittelbar aus der Gauß-Krüger-Projektion, bereinigt um den in Listing 4 genannten Referenzpunkt, gerundet auf 1000 Meter.
|
City |
Lat |
Lng |
»hw« |
»rw« |
|---|---|---|---|---|
|
Berlin |
52.5167 |
13.3833 |
274 |
517 |
|
Hamburg |
53.5500 |
10.0000 |
167 |
285 |
|
München |
48.1375 |
11.5750 |
767 |
411 |
|
Köln |
50.9422 |
6.9578 |
456 |
76 |
|
Frankfurt |
50.1136 |
8.6797 |
550 |
196 |
Listing 5
Temperaturverteilung
alpha = np.where(df2<-90, 0.0, 1.0)
lcities = ['Berlin', 'Hamburg', 'Munich', 'Cologne', 'Frankfurt']
lrw = [517, 285, 411, 76, 196]
lhw = [274, 167, 767, 456, 550]
plt.scatter(lrw, lhw)
plt.imshow(df2/10, cmap=plt.cm.coolwarm, alpha=alpha, vmin = 8, vmax=13)
plt.colorbar()
plt.title(f'Temperaturunterschiede im Jahr {year2}')
plt.show()
Die erste Anweisung (»np.where(…)«) in Listing 5 erzeugt eine Maske für die Fläche Deutschlands. Werte von -99.9 (genauer »< -90«) erhalten den Wert 0, alle anderen den Wert 1. Diese Maske erzeugt die Grafik aus Abbildung 4. Für die eigentliche Temperaturauswertung spreizen die Parameter »vmin« und »vmax« die Temperaturskala, um Unterschiede zu betonen. Dabei dienen fünf in Abbildung 5 als gelbe Kreise zu erkennende Großstädte als Bezugspunkte.
Abbildung 4: Die Auswertung der Stellen ohne Messwerte (»-999«) ergibt eine Maske mit den Umrissen Deutschlands.
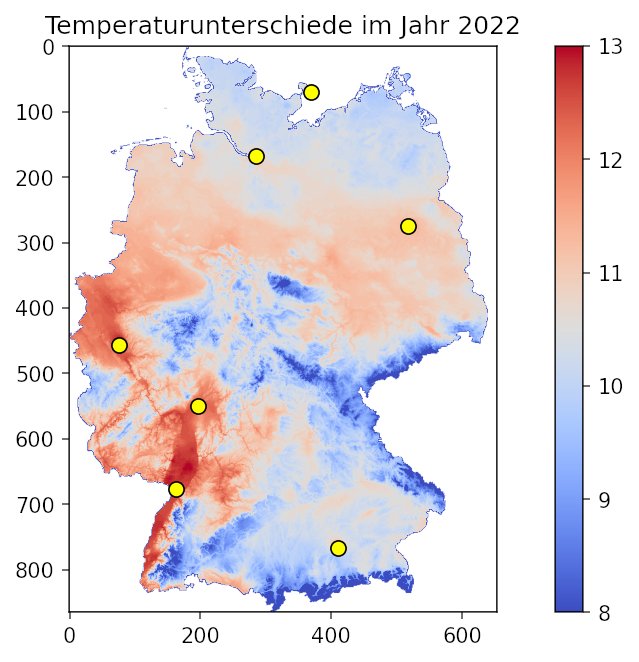
Abbildung 5: Die Messwerte offenbaren die Unterschiede in der mittleren Jahrestemperatur im Jahr 2022.
Wählt man die Jahre als Schleifenindex, berechnet Python für jedes Jahr zu einem Bezugsjahr die Differenztemperatur. Die Daten seit 1881 decken eine Zeitspanne von gut 140 Jahren ab. Bei einer Bildrate von 20 Bildern pro Sekunde ließe sich daraus ein Video von 7 Sekunden Laufzeit erzeugen.
Temperaturstatistik
In Listing 5 genügen letztlich zwei Zeilen Python-Code, um die mittlere Jahrestemperatur zu kalkulieren: Die Methode »reshape(-1)« wandelt die Tabelle in eine Spalte um, der Aufruf »mean()« berechnet das Jahresmittel.
Listing 6
Mittlere Jahrestemperatur
fnt = 'data/dwd/DE_annual_tmean_{}.asc.gz'
startfrom = 1881
endby = 2023
thres = -80 # ignore values lower than thres
READDATA = False
years = list(range(startfrom, endby))
tmean = []
for y in range(startfrom,endby):
fn = fnt.format(str(y))
df = pd.read_csv(fn)
df = df/10
data = df.to_numpy().reshape(-1)
data = data[data>thres]
datatm = data.mean().round(2)
tmean.append(datatm)
Abbildung 6 fasst die Ergebnisse für alle Jahre seit 1881 zusammen. Im Mittel schwanken die Werte um weniger als ein Grad. Kalte Winter wie im Jahr 2010 drücken das Jahresmittel um 1,5 Grad, sind aber recht selten. Der Temperaturanstieg von rund 2 Grad in den letzten 40 Jahren lässt sich deutlich erkennen.
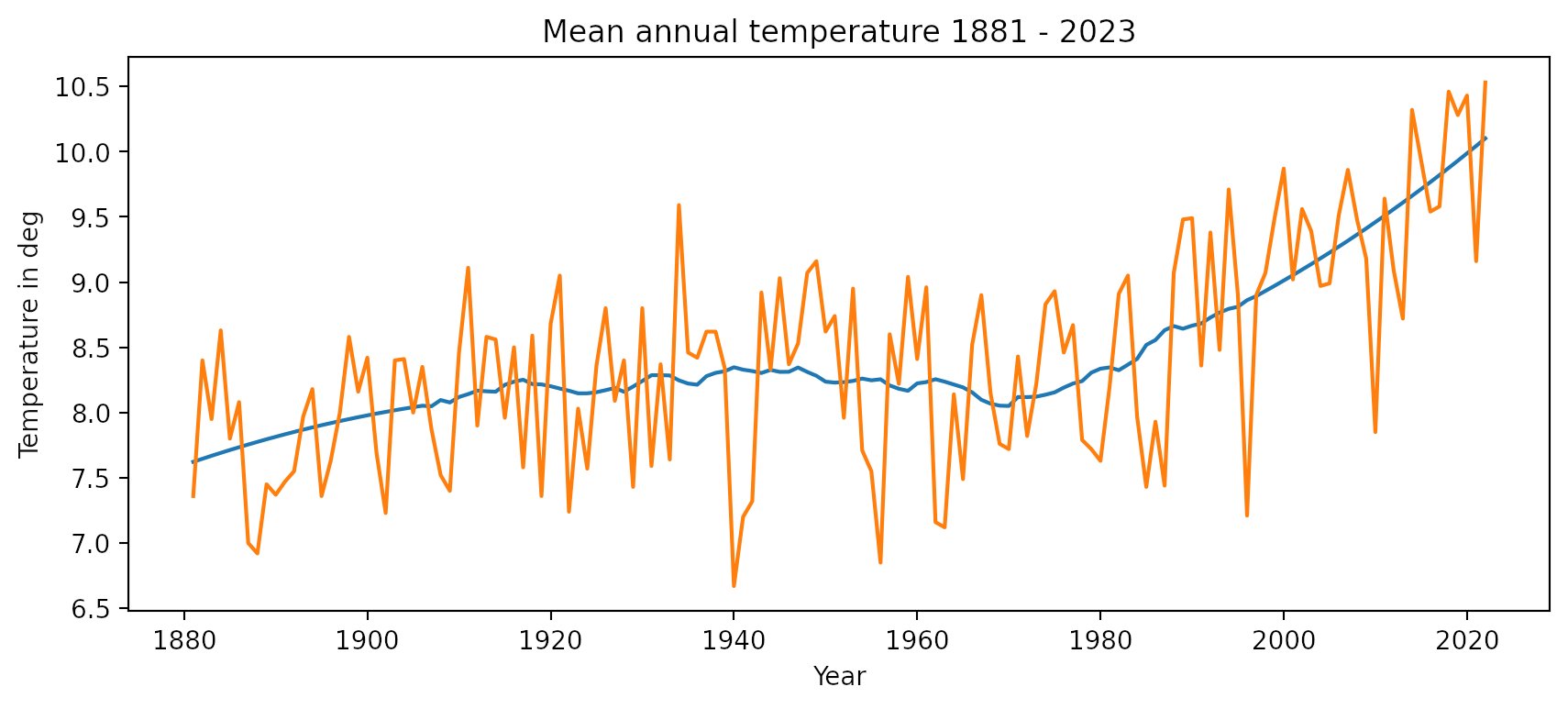
Abbildung 6: Die Auswertung der mittleren Jahrestemperaturen seit 1881 signalisiert unmissverständlich eine Klimaerwärmung.
Ähnlich, wie die Daten die Entwicklung der mittleren Temperatur in Deutschland verraten, zeigen sie auch die Temperaturverläufe für einzelne Regionen auf. Listing 7 bestimmt die mittlere Temperatur einzelner Punkte in Deutschland. Der erste Parameter ist der Datensatz eines Jahrs, der zweite die Position, der dritte die Größe des Subarrays.
Listing 7
Mittelwert eines Subarrays
def cen_mean(ar, c, sc):
"""
calculate mean of subarray of size c-sc ...c+sc+1
in:
ar: array
c: center point (c0, c1)
sc: +- size around center point
out:
mean of center
Ignore any values >= -999 (border values in DWD data)
"""
arc_inn = ar[c[0]-sc:c[0]+sc+1,c[1]-sc:c[1]+sc+1]
arc_inn_m = arc_inn.reshape(-1,)
arc_inn_m = arc_inn_m[arc_inn_m >-999].mean()
return round(arc_inn_m/10,2)
Beispielsweise berechnet der Aufruf »cen_mean(ar, (767, 411), 6)« die mittlere Temperatur in München innerhalb einer Fläche von 10*mal 10 Kilometern. Abbildung 7 zeigt die Temperaturverläufe für die Metropolen München, Berlin und Köln. Auch hier fällt ein deutlicher Temperaturanstieg seit den 70er-Jahren des letzten Jahrhunderts auf. Befreit vom (steigenden) Mittelwert liefern die ortsaufgelösten Jahresmittelwerte Temperaturverteilungen, die sich unmittelbar vergleichen lassen.
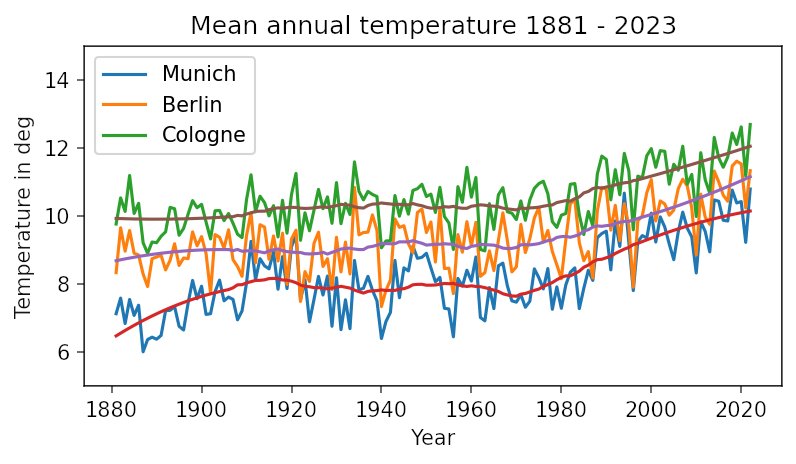
Abbildung 7: Die mittleren Jahrestemperaturen in ausgewählten Großstädten bestätigen den allgemeinen Trend zur Erwärmung.
Der hinter Abbildung 8 stehende Code geht einen anderen Weg. Er mittelt alle normalisierten Jahrestemperaturen über die letzten 60 Jahre. Die Grafik zeigt also nicht den Temperaturanstieg mit der Zeit, sondern die mittleren jährlichen Temperaturunterschiede, mit einer Auflösung von 1 Kilometer. München hebt sich mit mehr als einem halben Grad Differenz von seiner Umgebung ab. Flüsse wie Isar, Donau, Naab, Neckar, Main oder Regnitz lassen sich an ihren Temperaturgradienten deutlich erkennen. Die Schwäbische Alb zeichnet sich als blauer Streifen oberhalb der Donau ab.
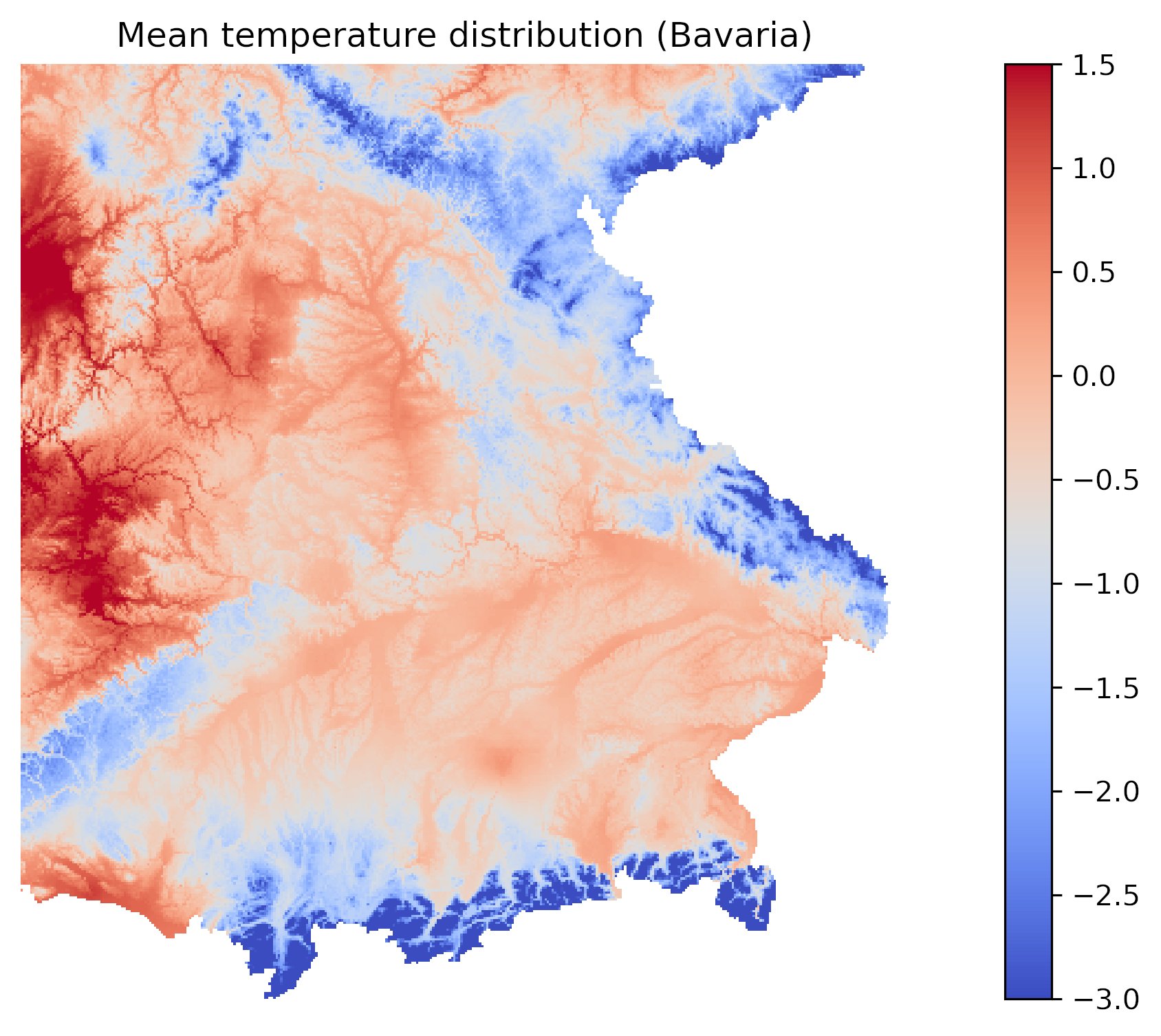
Abbildung 8: Die mittlere Jahrestemperatur in Bayern, gemittelt über die letzten 60 Jahre.
Überlast
Wie das Klimaforscher schon länger voraussagen, zeichnet sich auch in unserer Auswertung eine statistisch einwandfreie Temperaturerhöhung seit den 1970er-Jahren ab. Damals lag der “Erdüberlastungstag” (Earth Overshoot Day) am Jahresende, und die Erde konnte alle Menschen nachhaltig versorgen. Seitdem hat sich die Weltbevölkerung auf über 8 Milliarden Menschen verdoppelt. Heute liegt der globale Overshoot Day im Juli, Deutschland erreicht ihn schon im April. Nach diesem Stichtag lebt die Menschheit von den Rücklagen.
Deshalb spielt die Frage, woher der Klimawandel kommt, eigentlich keine Rolle. Ausschlaggebend ist die Tatsache, dass wir mehr Ressourcen verbrauchen als nachwachsen können. Wird die Luft wärmer, nimmt sie in unseren Breiten mehr Wasser auf, und es kommt zu Starkregen. Erwärmen sich die Weltmeere, liefern sie die Energie für Wirbelstürme. Gleichzeitig trocknen Landstriche aus, die wirtschaftlich nutzbaren Ackerflächen schwinden. Ebenso verschwinden Schutzgebiete für die Natur. Bereits jetzt sind viele Küstengebiete überfischt. Zwar wächst die Weltbevölkerung mittlerweile weniger schnell, nimmt aber dennoch weiter zu.
Der Deutsche Wetterdienst hält nicht nur Daten zur Temperaturentwicklung vor, sondern auch solche zu Niederschlagsmengen. Eine Analyse dieser Daten würde zu ähnlichen Schlüssen führen wie die Betrachtung der Temperaturen: höhere Niederschlagsmengen bei gleichzeitig größer ausgeprägten Extrema.
Fazit
Die Frage, ob es global einen Klimawandel gibt und ob ihn die Menschheit verursacht, lässt sich mit einem Datensatz von wenigen Dutzend Jahren nicht beantworten. Unbestreitbar bleibt, dass die Temperatur in Deutschland und der Welt seit 40 Jahren stetig zunimmt.
Unsere Python-Skripte werten die Temperaturdaten des Deutschen Wetterdiensts aus. Für jede Region in Deutschland bestimmen sie den Temperaturanstieg im Vergleich zum letzten Jahrhundert. Darüber hinaus liefern sie ein recht stabiles Bild über die mittlere Temperaturverteilung in Deutschland: In München und an der Isar ist es um mehrere Grad wärmer als auf der Schwäbischen Alb oder im Bayerischen Wald. (jlu)
Infos
- Deutscher Wetterdienst: https://www.dwd.de
- Jahresmittelwerte Temperatur: https://opendata.dwd.de/climate_environment/CDC/grids_germany/annual/air_temperature_mean/
- Gauß-Krüger-Projektion: https://de.wikipedia.org/wiki/Gau%C3%9F-Kr%C3%BCger-Koordinatensystem
- EPSG-Codes: https://de.wikipedia.org/wiki/European_Petroleum_Survey_Group_Geodesy
- Koordinatenumrechner: https://www.koordinaten-umrechner.de






Wie Sozialprofessor Dr. Heinz Bude so schön feststellte, reicht “ein bisschen wissenschaftsähnlich” heutzutage aus, selbst wenn dafür Python verwendet wird. Es ist für einen Dipl.-Ing. trotzdem keine Wissenschaft. Dass Programmierer keine Statistiker sind und somit den Unterschied zwischen Korrelation und Kausalität nicht erkennen können, geschenkt. Große Datenmangen machen das ja auch schwierig. Es hätte dem Verfasser aber doch auffallen können, dass seine zusammengerechnete Karte seltsame Diskrepanzen aufweist, wie die blauen Flecken, z.B. im Hochgebirge. Wer sich über Jahrzehnte einen breiteren Horizont erarbeitet hat, dem fällt auch auf, dass die roten und orangen Gebiete mit Gebieten mit höherem Bevölkerungszuwachs in den… Mehr »