
© Tatiana Vorona / 123RF.de
Längst haben sich Container etabliert, und mit ihnen Kubernetes. Während die Hersteller ungeahnte Möglichkeiten und den effizienten Betrieb großer Umgebungen versprechen, verzweifeln Admins eher am K8s-typischen Chaos.
Einem Zeitreisenden aus dem Jahr 2000 dürften in der heutigen IT viele Dinge recht seltsam vorkommen. Aktuelle Setups unterscheiden sich stark von jenen der Jahrtausendwende, sowohl im Hinblick auf die genutzte Technik als auch bezüglich der Best Practices der Systemadministration.
Vor einem Vierteljahrhundert sahen sich Admins beispielsweise nicht mit den Rechenmonstern der Gegenwart mit 64 CPU-Kernen im Doppelpack und 512 GByte RAM konfrontiert. Wer seinerzeit einen Server bestellte, galt fast schon als Krösus, wenn er die Maschine mit 16 GByte RAM und einem batteriegestützten Pufferspeicher für den RAID-Controller ausstattete. Virtualisierung spielte noch keine Rolle, Anwendungen rollte man über die Paketverwaltung der eigenen Distribution direkt aus.
IP-Adressen verwalteten Admins regelmäßig in Excel-Dateien, und mit der Automation war es ebenfalls nicht sonderlich weit her. Wer eine Konfiguration per Scp von einem Host auf mehrere andere übertrug und mittels Bash-Skripten darin ein paar Variablen spezifisch für die einzelnen Hosts setzte, galt bereits als Speerspitze der bequemen Systemadministration. Heute lockt so etwas niemanden mehr hinter dem Ofen hervor.
Erst das Aufkommen von Prozessoren, die spezielle Features für die Virtualisierung boten, brachte die Dinge in Bewegung. Die dadurch ausgelösten Veränderungen halten bis heute an, obwohl die eingesetzten Werkzeuge inzwischen mehrere Generationen lang gereift sind. Erst galten Voll- und Paravirtualisierung als das nächste große Ding, weil sich nur damit die plötzlich vorhandene Rechenleistung moderner Mehrkern-CPUs mit VT-d sinnvoll nutzen ließ. Dann trat Amazon auf den Plan und eroberte den Markt im Sturm, indem es eine neue Art und Weise vorstellte, wie sich Computing- und Storage-Ressourcen bereitstellen ließen. Cloud Computing verhieß geringe Kosten für den Betrieb eigener Infrastruktur bei voller Flexibilität dank eines Selbstbedienungskonzepts.
Dass der Kostenfaktor nicht ganz so rosig aussieht, haben allerdings zwischenzeitlich etliche Cloud-Nutzer leidvoll erfahren. Die Büchse der Pandora war aber geöffnet, zahllose Firmen haben seither ihr Glück in der eigenen Cloud gesucht. Viele sind daran ebenso spektakulär wie dramatisch gescheitert. Schließlich trat Docker auf den Plan und verankerte im Fahrwasser der Cloud die Container-Virtualisierung im IT-Bewusstsein.
Logisch: Einzelne Dienste brauchen nicht zwangsläufig eine eigene virtuelle Maschine, um mit einem erhöhten Level an Sicherheit vom Host-System isoliert zu laufen. Der Linux-Kernel selbst bietet in Form von Namespaces und Cgroups längst Funktionen, die übernehmen können, was klassische Voll- und Paravirtualisierung einst leistete. Darauf fußende Container-Implementierungen verursachen deutlich weniger Overhead als KVM und Konsorten, weil sie weder ein eigenes BIOS emulieren müssen noch einen eigenen Kernel erfordern.
Problem: Komplexität
Wer denkt, das klänge doch wundervoll, irrt sich. Cloud Computing und Container-Virtualisierung bringen etliche Ebenen an Komplexität mit, um überhaupt funktionieren zu können (Abbildung 1). Das Gestalten einer virtuellen Netzwerkumgebung in einer Cloud setzt Software-defined Networking voraus. Obendrein müssen Clouds nahtlos skalieren, weil sie sich für ihre Betreiber ohne die Economy of Scale nicht rechnen. Gemeint ist die Möglichkeit, ein Setup automatisch um beliebig viele Knoten zu erweitern, ohne relevante Herstellkosten.
Abbildung 1: Dass Sie auf dieser Grafik kaum etwas erkennen, verwundert nicht: Der Atlas der Cloud Native Computing Foundation (CNCF) listete im Oktober 2023 nicht weniger als 1260 verschiedene Lösungen für die K8s-Integration auf. Quelle: CNCF
Das allerdings verlangt nach einem skalierbaren Speicher, der mit der Plattform mitwächst. Aus heutiger Sicht stellt das technisch zwar keine Herausforderung mehr dar, komplex zeigen sich Lösungen wie Ceph oder Longhorn aber trotzdem – deutlich komplexer als etwa ein SAN, das den zeitreisenden Admin aus dem Jahr 2000 noch aus eigener Erfahrung kennt. Hinzu kommt, dass man für den Betrieb von Setups im Rahmen einer skalierbaren Plattform immer auch eine Software benötigt, die den Betrieb koordiniert.
Im Container-Kontext hat sich dafür Kubernetes als Mittel der Wahl durchgesetzt. Es fällt jedoch selbst einigermaßen komplex aus und bindet für Cloud-ready-Software zusätzliche Komponenten ein, die noch mehr Komplexität mitbringen. Im Setup der Gegenwart bekommt der Admin es also mit viel mehr Komponenten zu tun, mit viel mehr Software und mithin auch mit viel mehr Ebenen, die ausfallen können. Das gilt selbst dann, wenn man von Themen wie Monitoring, Alerting und Trending (MAT) einmal ganz absieht: Das Überwachen skalierbarer Plattformen fällt technisch viel komplexer aus, als es manchem Admin lieb ist.
Glaubt man den Werbeversprechen der großen Anbieter wie Red Hat und Suse, gibt es bei all dem freilich kein Problem. Sie stellen, so behaupten sie wenigstens, dem Administrator ja Werkzeuge zur Seite, die alle Komponenten im wunderbaren Einklang steuern und verwalten. Das ist zweifelsohne nett, solange diese Werkzeuge funktionieren. Geht jedoch etwas schief, steht der Admin wie der Ochse vom Berg, falls er sich mit den Innereien von SDN, SDS, Kubernetes und Konsorten zuvor nicht ausgiebig beschäftigt hat.
Da hilft es kaum, dass gerade Red Hat und Suse die Containerisierung beliebiger Software mit so viel Druck erzwingen, dass die einstigen Enterprise-Flaggschiffe RHEL und SLES in absehbarer Zeit zum bloßen Abspielwerkzeug für Container von Drittanbietern degradiert sein werden. Admins stehen hier also wohl oder übel zusätzlichen Layern der Komplexität gegenüber. Weiß der Admin in einem solchen Konstrukt nicht, was er tut, muss ihm der Betrieb der eigenen Umgebung eher Angst einflößen.
Obendrein erweisen sich die Werbeversprechen der Anbieter im Alltag manchmal als recht fragwürdig. Längst häufen sich die Szenarien, in denen Red Hat, Suse und Konsorten lapidar die Neuinstallation von Knoten empfehlen, sobald ein Problem auftritt, das sich nicht trivial reproduzieren lässt. Schnell entsteht dann der Eindruck, der Anbieter habe seine Technik selbst nicht so richtig im Griff.
Spätestens hier bekommt der Administrator ein mulmiges Gefühl, weil sich an dieser Schwelle aus dem Handling- und Admin-Problem ein noch viel größeres Sicherheitsproblem entwickelt. Womit müssen Admins also rechnen, was können sie tun, um die Komplexität zu reduzieren – und gefährden die Anbieter womöglich aktiv die Stabilität und Sicherheit der eigenen Lösungen?
Kollidierende Ansprüche
Sinnvoll erfassen lässt die Situation sich nur, wenn man einerseits die Motive analysiert, die hinter dem aktuellen Handeln der großen Hersteller stehen, und andererseits untersucht, wie sich das auf reale Setups auswirkt. Selbst wenn die Anbieter in ihren Broschüren und auf ihren Webseiten etwas anderes behaupten, trachten sie vor allem nach dem eigenen kommerziellen Erfolg. Der stimmt im besten Falle mit dem der eigenen Klientel überein, aber eben nicht zwangsläufig. Der seit Jahren vehement betriebene Umstieg auf Container verdeutlicht das gut.
Haben Sie schon einmal eine Linux-Distribution selbst gepflegt, haben Sie eine ungefähre Vorstellung vom immensen damit verbundenen Aufwand. Bis vor wenigen Jahren galten Distributionen quasi als Wunschlos-glücklich-Pakete. Wer einen SLES oder ein RHEL nutzte, erwartete ganz selbstverständlich, Dienste wie Apache, Nginx oder MySQL zusammen mit Lösungen wie PHP fertig aufeinander abgestimmt zu erhalten.
Obendrein durfte man voraussetzen, für das System eine Weile Support zu bekommen und sich bei Problemen an den Hersteller wenden zu dürfen. Dazu gilt es, im Hinterkopf zu behalten, dass anders als skalierbare Umgebungen der Gegenwart konventionelle Setups im Grunde alle fünf Jahre turnusgemäß auszutauschen waren. Spätestens dann waren die Garantie und der Support für die Hardware seitens des Herstellers abgelaufen. Systemhäuser und IT-Anbieter erzielten über viele Jahre hinweg einen großen Teil ihrer Umsätze damit, Firmen dasselbe Setup mit wenigen Aktualisierungen immer wieder aufs Neue zu verkaufen, aus den eben geschilderten Gründen.
Aus Sicht eines Distributors gestaltet sich dieses Unterfangen ausgesprochen aufwendig und sehr kostspielig. Je nach Länge des Release-Zyklus des eigenen Systems kommt es bis heute regelmäßig vor, dass ein Hersteller Unterstützung für drei Versionen seiner Distribution liefern muss – und das gilt für alle enthaltenen Komponenten. Bei Red Hat geht es im Augenblick um RHEL 7 bis 9, bei Suse um SLES 12 und SLES 15, bei Canonical um Ubuntu 20.04, 22.04 sowie 24.04 ab April 2024.
Hat etwa bei Suse ein Kunde auf SLES 12 Probleme mit MySQL, muss ein Suse-Entwickler in die Untiefen der Systemarchäologie hinabsteigen und das Problem kleinteilig nachvollziehen. Kommt es ganz dicke, steht hinterher noch die Veröffentlichung eines Updates an, beispielsweise wenn es sich um ein Problem mit Sicherheitsbezug handelt.
Alte Zöpfe abschneiden
Der Schwenk hin zu Container-Virtualisierung bot der Industrie die Möglichkeit, sich auf einen Schlag vieler dieser Probleme zu entledigen. Weil jeder Container die Laufzeitumgebung für seine Hauptapplikation im Gepäck hat, erübrigen sich beispielsweise die gefürchteten Probleme beim Update von einer Major-Version einer Distribution auf die jeweils nächste beinahe vollständig. Zudem geht die Pflege des Grundsystems erheblich leichter von der Hand: Besteht die Kernaufgabe eines Systems nur darin, Container zu starten, erfordert das außer einem Linux-Kernel, einem sehr überschaubaren Userland und eben der Laufzeitumgebung für Container kaum weitere Komponenten.
Die nötigen Bestandteile lassen sich zudem weitgehend unbeeinflusst von irgendwelcher Userland-Software entwickeln und pflegen, weil die ja im Container läuft. Eine bereits existierende Mikrodistribution wie CoreOS für die eigenen Anwendungen des Anbieters, etwa Ceph im Falle von Red Hat, bietet darüber hinaus den Vorteil, dass sie zugleich als Grundsystem für Container fungieren kann. Dadurch lassen sich eigene Anwendungen einfach in Container-Form verteilen, statt fertige Pakete für etliche verschiedene Distributionen bereitzuhalten. Das erfordert obendrein viel weniger Personal als die auf Paketen basierende Vorgehensweise.
Schon die bis hierhin beschriebenen Vorteile wären aus Sicht der Distributoren mehr als ausreichend, um den Schwenk hin zu Containern zu rechtfertigen. Sie zählen aber gar nicht als das schlagende Argument. Das lautet stattdessen, dass Anbieter wie Red Hat oder Suse dank der Container-Methode auch den Umfang der eigenen Distribution signifikant reduzieren können. Unternehmen und Firmen hinter weitverbreiteten Anwendungen wie MySQL, PostgreSQL oder Nginx bieten längst Container ihrer Software als fertiges Abbild an.
In der Linux-Welt wird man deshalb absehbar auf die Hersteller eben dieser Container verweisen und achselzuckend zu Protokoll geben, dass der Kunde Support für MySQL doch lieber beim Hersteller als beim Anbieter der Distribution kaufen soll: Der Hersteller kenne sein Produkt ja ohnehin besser und könne es daher auch besser unterstützen. Dass sie diese Dienste nicht mehr selbst mit Support versorgen müssen, ist ein Effekt, den die Distributoren gern mitnehmen.
Mehraufwand
Fragen Sie sich nun, was Sie davon haben, bekommen Sie zahlreiche mehr oder minder gute Argumente zu hören. Tatsächlich impliziert das Container-basierte Deployment-Modell für den Admin jedoch grundsätzlich mehr Verwaltungsaufwand und Support-Bedarf. Wo bisher ein Vertrag mit einem einzelnen Anbieter genügte, fallen für MySQL, Nginx & Co. künftig vermutlich Verträge mit verschiedenen Herstellern an. Sollte Red Hat ein entsprechendes Rundum-sorglos-Paket im Angebot behalten, dürfte sich das Unternehmen das zumindest fürstlich entlohnen lassen. Gut möglich, dass die aufgerufenen Preise dann deutlich über dem liegen, was viele Firmen zahlen wollen oder können.
Insofern lässt sich gut nachvollziehen, dass so manchem Admin der Kamm schwillt, sobald die Hersteller ihn mit Containern zwangsbeglücken. Bei aller berechtigter Kritik gilt trotzdem: Solange der Systemadministrator es nur auf einem einzelnen physischen System mit Containern zu tun bekommt, hält sich die zusätzliche Komplexität des Setups in überschaubaren Grenzen (Abbildung 2).
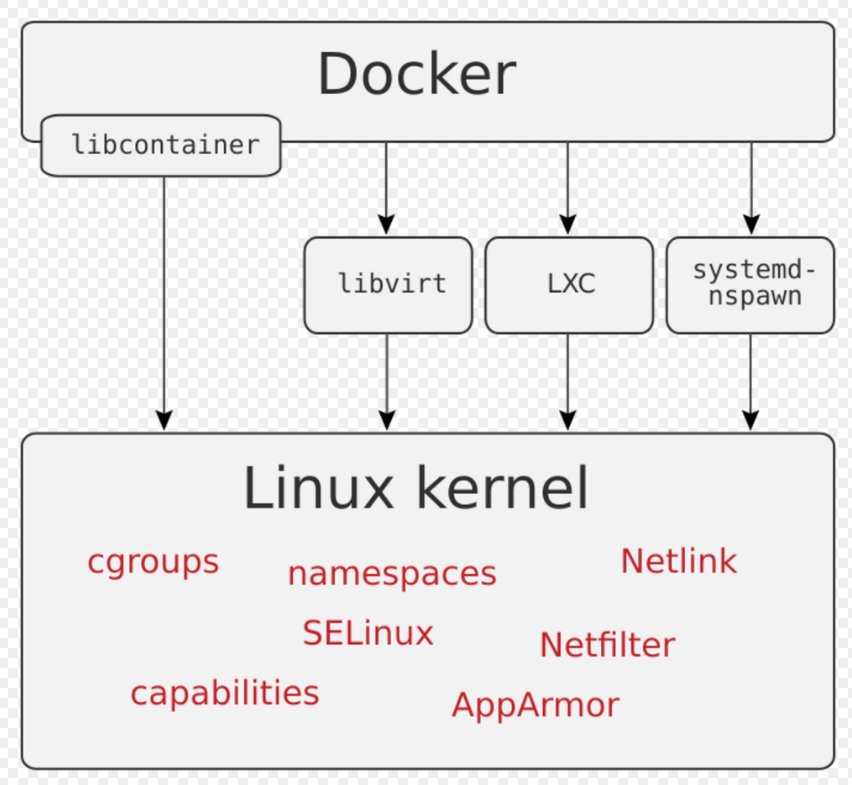
Abbildung 2: Container fügen auf Linux-Systemen zwar eine Abstraktionsebene hinzu. Das lässt sich aber verkraften, solange SDN und SDS außen vor bleiben. Quelle: MDPI
Zwar starten die gängigen Laufzeitumgebungen einen Prozess mit eigenem Dateisystem in einem abgetrennten Namespace und mit eigenen Cgroups. Der läuft aber weiterhin auf demselben System, taucht in der Ausgabe von Ps auf und lässt sich lokal handhaben. Das Handling von Protokollen hat man innerhalb der Community mittlerweile so weit standardisiert, dass sich hier kaum noch Unterschiede zur Konfiguration des normalen Diensts aus einem Paket ergeben. Die Dienste in Containern sind üblicherweise so konfiguriert, dass sie ihre Log-Meldungen auf Stdout ausgeben und dieser Kanal in eine Datei in »/var/log/« umgeleitet wird. Der Administrator muss dann lediglich darauf achten, die Konfiguration nicht durch eine eigene zu überschreiben.
Apropos Konfiguration: Viele Hersteller konfigurieren ihre Container mittlerweile so vor, dass sie zentrale Konfigurationsdateien an ihrem typischen Ort suchen. Die MySQL-Konfiguration etwa liegt weiterhin in »/etc«, der entsprechende Container des Herstellers verlinkt sie per Bindmount im Container an die passende Stelle. Obendrein bedeutet der Betrieb von Containern nicht automatisch, dass Lösungen wie Software-defined Networking zum Einsatz kommen.
Das macht allerdings nicht den Umstand wieder gut, dass auf dem Host-System typische CLI-Kommandos fehlen, die im Zusammenhang mit Diensten in Containern stehen. Wer die Administration von Ceph gewohnt ist, erwartet beispielsweise, dass ein »ceph« auf der Shell funktioniert. Das Binary steht in Container-Setups aber nur im Container zur Verfügung, zumindest, bis der Admin das Paket »ceph-common« nachinstalliert.
In Summe lässt sich rein mit containerisierten Diensten jedoch leben, zumal Container ungeachtet aller Unkenrufe durchaus Vorteile bringen. Einzelne Dienste lassen sich damit tatsächlich sehr leicht und völlig unabhängig vom Rest des Systems aktualisieren. Dazu stoppt der Admin den alten Container, lädt eine neue Version herunter und startet sie – fertig.
Komplexität der Cloud
Wirklich unübersichtlich gerät die Gemengelage erst, sobald Ansätze wie Software-defined Networking ins Spiel kommen. Das tritt typischerweise dann ein, wenn es um den Betrieb von Workloads über die Grenzen einzelner physischer Knoten hinweg geht – sprich: um Dienste in der Cloud. Erstaunlich selten spielt dabei eine Rolle, ob das Unternehmen die Cloud, die es nutzt, selbst betreibt oder sich bei einem Anbieter (meist einem Hyperscaler) einmietet.
Üblicherweise sind für den Betrieb der Plattform andere Abteilungen zuständig als für den Betrieb von Anwendungen darauf. Verursacht eine Anwendung also ein Problem, würde sie vermutlich in einer anderen Umgebung dasselbe tun. Schwierig kann es in solchen Konstellationen werden, wenn das Debugging ebenfalls auf der Ebene der Plattform stattfinden muss. Sind die Admins für “oben” und “unten” nicht dieselben, müssen die Abteilungen umfassend miteinander kommunizieren.
Ganz unabhängig davon, wer zuständig ist: Das Debugging von verteilten Anwendungen stellt Admins vor ungleich größere Probleme als das Debugging monolithischer Einzelteile auf einzelnen Systemen. Das liegt einerseits daran, dass verteilte Systeme eine implizit höhere Komplexität aufweisen als klassische Komponenten. Andererseits, und das ist die Krux, gefallen sich Anbieter seit einigen Jahren darin, den berüchtigten Layer Cake ihrer Lösungen stets weiterzutreiben und immer höhere Türme verschiedener Komponenten zu konstruieren. Kubernetes selbst bietet dafür ein sehr gutes Beispiel.
So kommt bei K8s zunächst zum Tragen, dass die Komponenten der Lösung üblicherweise selbst in Container-Form auf den Zielsystemen laufen. Die Steuerung übernimmt dabei der Kubernetes-eigene Cluster-Manager, auf den Knoten läuft das Kubelet als ausführender Agent. Allein diese Komponente hostet jedoch noch keine einzige Kundenanwendung. Die muss in einzelnen Containern laufen, die Kubernetes selbst steuert. Konstrukte wie Mandantenfähigkeit oder die physische Trennung verschiedener Workloads setzen zwingend Software-defined Networking voraus.
Zwischen dem physischen Netz und jenem, das ein Kunde etwa von seinem Dienst in einem Container aus sieht, befindet sich also ein komplexes Konstrukt, das meist aus Diensten wie OpenFlow, Open vSwitch und OVN besteht. Kubernetes setzt für SDN regelmäßig auf Calico oder Funnel, um überhaupt eine Anbindung einzelner Container an ein Netz zu schaffen. Von Storage ist dabei noch gar keine Rede: Den implementieren gerade in skalierbaren Umgebungen viele Kunden mit Rook, das einen RADOS-Cluster – also Ceph – in Kubernetes ausrollt und über die K9s-APIs steuerbar macht (Abbildung 3).
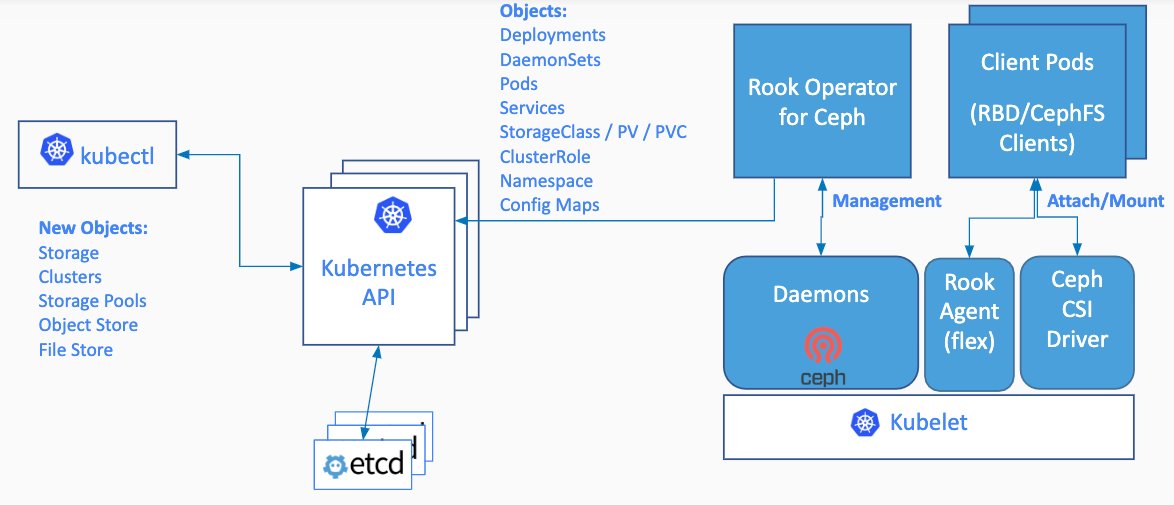
Abbildung 3: Rook auf Kubernetes liefert bereits eine erkleckliche Summe von Layern: Kubernetes mit SDN, die APIs, die Kubernetes-Pods und darin die RADOS-Dienste, die schließlich die Ceph-Frontends nutzen – Layer Cake vom Feinsten. Quelle: Cagri Ersen
Alle bislang genannten Einschränkungen von Anwendungen, die in Containern laufen, gelten auch hier. Zusätzlich steht dem Administrator beim Debugging aber noch Kubernetes mit seiner Netzwerkabstraktion im Weg. Wer etwa schon einmal OpenFlow-Einträge eines Systems untersucht hat, erinnert sich vermutlich mit Schrecken daran.
Hier enden die Hiobsbotschaften aus Sicht des Admins allerdings noch nicht. Lösungen wie OpenShift automatisieren das Deployment des Layer Cake. Sie sorgen dafür, dass der Administrator erst damit in Kontakt kommt, wenn etwas klemmt. Im ständigen Bestreben nach Everything-as-a-Service suggerieren sie zudem, dass weitere automatisiert mit ausgerollte Komponenten wie Istio eine Bereicherung und mithin notwendig seien. Zusätzlich zur schon vorhandenen Abstraktion von Containern, SDN und SDS gesellt sich eine weitere: Der Umstand, dass sich der Traffic zwischen den einzelnen Komponenten nicht nachvollziehen lässt, weil Istio als Mesh-Lösung die Kommunikationspfade ständig durcheinanderwirbelt (Abbildung 4).

Abbildung 4: Allein für die Diensteerkennung, gRPC-Funktionen und Service-Proxies inklusive Mesh-Lösungen listet die CNCF mehr als 30 verschiedene Lösungen, die sich zum Teil noch miteinander kombinieren und aufeinander stapeln lassen. Quelle: CNCF
Erschwerend kommt schließlich hinzu, dass die Anbieter sich ständig neue Deployment-Schemas überlegen, um ihre Software unters Volk zu bringen. Ein besonders krasses Negativbeispiel dafür ist Red Hats OpenStack-Plattform, die der Anbieter mittlerweile vor allem als Deployment-Grundlage für die Kubernetes-Distribution OpenShift betrachtet. Die installiert OpenStack und setzt darauf dann ein weiteres OpenStack, quasi als virtuelle Cloud auf echter Hardware (TripleO oder OpenStack on OpenStack). Daraufhin erweiterten Container das Bild, sodass mittlerweile sukzessive neu entwickelte Werkzeuge wie Metalsmith die sogenannte Undercloud ersetzen.
Absehbar soll jedoch OpenShift als Deployment-Werkzeug der Wahl dienen, um OpenStack auszurollen. Wer dann noch OpenShift in diesem OpenStack betreibt, etwa um eine eigene Instanz für einen Kunden oder ein Projekt anzubieten, hat OpenShift on OpenStack on OpenShift. Die geballte Komplexität von gefühlten 25 Abstraktionsschichten lässt dabei ein sinnvolles Debugging kaum noch möglich erscheinen. Alles klar?
Fazit: Was tun?
Was aber kann der Administrator tun, um den Überblick zu behalten und nicht dem Wahnsinn anheimzufallen? Die unbefriedigende Antwort auf die Frage lautet: nicht viel.
Werkzeuge wie OpenShift oder Rancher, um das Konkurrenzprodukt von Suse zu erwähnen, dürften die Cloud-lastige IT der Gegenwart aller Voraussicht nach noch eine ganze Weile dominieren. Ist der Admin auf den Betrieb der genannten Komponenten angewiesen, bleibt ihm lediglich, sich mit der Materie möglichst intensiv zu beschäftigen und so viel Wissen wie möglich anzuhäufen. Dazu gehört außerdem, sich mit Wissensgebieten zu befassen, die vielleicht nicht per se das eigene Steckenpferd sind. Die klassischen Silo-Ansätze, wonach es ein Team für Storage, ein weiteres für das Netz und ein drittes für den Betrieb der Systeme gibt, funktioniert in eben diesen Umgebungen gar nicht mehr.
Unternehmen wie Red Hat täten allerdings gut daran, bei der Umsetzung ihrer Produkte genauer zu hinterfragen, ob die Kombination gefühlt wahlloser Komponenten wirklich nötig ist, nur um an manchen Stellen absolute Nischen-Features zu unterstützen. Nicht alles, was sich technisch irgendwie umsetzen lässt, erweist sich für Einsatzszenarien in der echten Welt als sinnvoll. Tatsächlich zeigen sich die Hersteller mittlerweile selbst regelmäßig mit Support-Anfragen überfordert, die sich aus allzu komplexen Setups mit großen Stücken des berüchtigten Layer Cakes ergeben. Wem es bisher schon zu lästig war, Red Hat mit zahllosen Log-Dateien zur Analyse eines Problems zu versorgen und dazu Tarballs von mehreren MByte Größe in Red Hats Support-System zu laden, den erwarten im Kontext skalierbarer Umgebungen schlechte Nachrichten.
Obendrein kommt den Faktoren Monitoring, Alerting und Trending in skalierbaren Umgebungen eine noch viel größere Bedeutung zu als in konventionellen Setups. Der Administrator will und muss Dienste wie Zeitreihendatenbanken nutzen, um das Setup möglichst feingliedrig zu überwachen und selbst kleine Fehlfunktionen schnell zu bemerken. Das gilt umso mehr, als ein kleiner Fehler in einer Komponente in einer verteilten Umgebung zu Folgefehlern an einer völlig anderen Stelle führen kann (Abbildung 5). (jcb)
Abbildung 5: In verteilten Umgebungen ist ein umfassendes Monitoring viel wichtiger als in konventionellen Setups: Sonst bleiben viele Probleme unerkannt. Quelle: Camil Blanaru





