
© Diana Bargan / 123rf.com
Das Thema Offloading erreicht die Speichermedien: Scaleflux tritt mit NVMe-basierten Laufwerken an, die nicht nur speichern, sondern auch rechnen können. Das soll helfen, die CPU zu entlasten und für höhere Bandbreiten sowie geringere Latenzen zu sorgen, kostet aber eine Stange Geld. Lohnt der Aufwand?
Wer schon einige Lenze in der IT unterwegs ist, weiß: Jeder Server hat an irgendeiner Stelle einen Flaschenhals, den berüchtigten Bottleneck, der seine Leistungsfähigkeit begrenzt. Allerdings ist dieser Bottleneck mal hier mal da zu finden. Denn die Hersteller der einzelnen Komponenten spielen seit Jahren ein Katz-und-Maus-Spiel: Neue CPUs bringen üblicherweise neue Chipsätze mit sich, die höhere Bandbreiten für die angebundenen Geräte und den RAM ermöglichen. Das macht die Speicherlaufwerke nicht selten zum Bremsklotz. Daraufhin legen deren Hersteller nach und bringen schnellere Geräte auf den Markt, sodass plötzlich das Netzwerk die Performancegrenze definiert. Gerade beim Netz hat es in den vergangenen Jahren große Innovationen gegeben. Eine davon ist das mittlerweile breit verfügbare 400-Gbit-Ethernet – das flugs den Schwarzen Peter zu den Storage-Geräten zurückgeschoben hat.
Besonders kritisch werden kann die Situation außerdem, wenn Komponenten wechselwirken. Das trifft besonders dann zu, wenn diese unter hoher Rechenlast stehen – beispielsweise Datenbankknoten, Server mit laufenden Hadoop- oder Redis-Instanzen oder Mitglieder eines ElasticSearch-Clusters. Hier kommen mehrere Faktoren zusammen: Insbesondere einzelne Arbeitsschritte wie das Komprimieren von Daten, ihre Indizierung oder das Ausmisten nicht mehr benötigter Datensätze brauchen einerseits eine große Bandbreite auf dem angeschlossenen Speichermedium und andererseits hohe Rechenleistung seitens der CPU. Das führt schlimmstenfalls dazu, dass ein einzelnes System ein gesamtes Setup ausbremst. Etwa dann, wenn die zentrale Datenbank eingehende Anfragen nicht mehr oder zumindest nicht flink genug beantworten kann. Anwendern wie Administratoren gefällt das gar nicht, denn vor allem auf der Endanwenderseite fühlt sich die Nutzung eines Diensts in einer solchen Situation äußerst zäh an.
Das beschriebene Problem ist nicht neu, weshalb die Hardwareindustrie schon vor Jahren damit begonnen hat, Lösungen zu suchen. Den meisten Admins dürfte der Begriff Offloading im Netzwerkkontext jedenfalls bekannt vorkommen. Gemeint ist damit, dass eine Netzwerkkarte (NIC) sich eben nicht mehr nur um die Verarbeitung des durchfließenden Traffics kümmert, sondern auch Computing-Aufgaben übernimmt. Kommt VxLAN zum Einsatz, müssen Pakete etwa entsprechend gekennzeichnet werden (VxLAN-Tag). Das kann die Host-CPU übernehmen, oder die NIC, sofern sie entsprechende Funktionalität auf ihrem Chip implementiert hat. Ist das der Fall, ergeben sich mehrere Vorteile: Die Berechnungen finden näher am eigentlichen Netzwerkverkehr statt, was Gewinne in Sachen Performance bringt. Obendrein ist die NIC auf diese Aufgabe hin optimiert, was ebenfalls an der Performance-Schraube dreht. Fast ebenso wichtig: Die von der NIC bereits erledigen Aufgaben fallen der Host-CPU nicht mehr zur Last. Diese kann sich dementsprechend um andere Dinge kümmern. NICs mit den passenden Funktionen führen alle großen Hersteller heute im Sortiment, und die Unterstützung in Linux etwa mittels DPDK ist inzwischen umfassend implementiert.
Computational Storage
Ähnliche Ziele verfolgt der Ansatz des Computational Storage für Speichergeräte. Dessen Anfänge waren eher banal. Längst etabliert ist beispielsweise das Prinzip des Storage Tierings, bei dem zwischen heißen und kalten Daten unterschieden wird, die jeweils anders behandelt werden. Heiße Daten liegen auf flottem Flash-Speicher, kalte Daten auf langsamen Platten oder sogar auf Tapes, wenn sie für die Archivierung vorgesehen sind. Dass überhaupt von Festplatten die Rede ist, zeigt, wie alt der Ansatz eigentlich ist. Festplatten weisen bauartbedingt eine viel geringere Bandbreite als Flash-Speicher und zugleich eine viel höhere Latenz auf. Indem man den damals noch extrem teuren Flash-Speicher einer Festplatte zur Seite stellte, ließen sich zumindest für Writes die Vorteile beider Lösungen kombinieren. Das reicht für moderne Anwendungen wie große Datenbanken, Hadoop & Co. aber längst nicht aus. Von den Durchsätzen, die aktuelle KI-Lösungen benötigen, ist dabei noch gar nicht die Rede.
Weitere Ansätze buhlten zwischenzeitlich um die Gunst der Nutzer: Eine Weile waren zum Beispiel DPUs beliebt, Data Processing Units, spezielle Bauteile, die ebenfalls in Servern verwendet wurden und der Netzwerkkarte quasi zur Hand gehen sollten. Besonders in Netzwerkgeräten finden sich DPUs noch heute, in General-Purpose-Maschinen hingegen hat das Vorgehen sich nicht durchgesetzt. Ein Problem dabei: Die verwendete Software muss eng mit der DPU kooperieren, de facto also komplett auf diese abgestimmt sein. Das macht die Zusammenarbeit mit Software etwa aus der Open-Source-Welt schwierig. Der von Facebook entwickelte Key-Value-Store RocksDB beispielsweise ist in der Lage, von DPUs in entsprechenden Setups zu profitieren – doch geht das nicht ohne spezifische Anpassungen an RocksDB. Es gibt vorgefertigte Lösungen für dieses Szenario, jedoch nur von einzelnen Herstellern zu wenig schlanken Tarifen, was einer echten Verbreitung entgegensteht. Eine Weile waren zum Beispiel DPUs beliebt, Data Processing Units, spezielle Bauteile, die ebenfalls in Servern verwendet WURDEN und DER Netzwerkkarte quasi zur Hand gehen sollten.
Mittlerweile drängen allerdings Anbieter wie Scaleflux [1] auf den Markt, die das Prinzip weiter ausreizen und Rechenleistung unmittelbar in der Netzwerkkarte verbauen. Das eliminiert manchen Nachteil vorheriger Lösungen, wie den Zwang, zusätzliche Hardwarekomponenten einzusetzen. Besonders wichtig aus Sicht der jeweiligen Anbieter: Die Lösungen sollen aus der Perspektive des Betriebssystems und der des Anwenders transparent sein. Die enge Bindung zwischen der Entwicklung von Hard- und Software, die bei Brückenlösungen wie DPUs noch die Regel war, soll also entfallen. Erreichen will man das, indem die Speicherlaufwerke selbst direkt in den Datenstrom eingreifen und verschiedene Operationen ausführen, die Durchsatz, Latenz und Speicherdichte verbessern. Zusätzlich implementieren Computational-Storage-Laufwerke diverse Funktionen, die in normalen NVMes fehlen, etwa die Möglichkeit, atomare Speichervorgänge auszuführen. Solche Features verschaffen dem Administrator an anderer Stelle dann wieder Luft, zum Beispiel, wenn er die Datenbank von der Pflicht befreien kann, sich um atomare Operationen selbst zu kümmern.
Verglichen mit den weniger beliebten Ansätzen, etwa auf Basis von DPUs, eröffnet sich bei typischen Computational-Storage-Laufwerken einerseits also die Möglichkeit, sie in viel mehr Setups einzusetzen. Andererseits führt die fehlende Anpassung an spezifische Anwendungen auch dazu, dass sich nicht aus jeder Datenbank noch das letzte Quäntchen Performance herausquetschen lässt – eben weil die Computing-Routinen der Hardware nicht an die jeweiligen Programme angepasst sind.
Was Scaleflux bietet
Am Computational-Storage-Markt gilt Scaleflux als ein Pionier der Branche. Das Unternehmen ist in der Tat älter, als mancher vermuten würde: Bereits seit 2014 arbeitet man an Computational-Storage-Laufwerken, und 2020 war man mit entsprechender Hardware am Markt gut etabliert. Seither hat Scaleflux das eigene Portfolio kontinuierlich ausgebaut – und kann auf Erfolge verweisen: Alibaba Cloud, immerhin der größte Cloud-Anbieter Chinas, setzt auf Scaleflux-Hardware, um die hauseigene PolarDB zu beschleunigen. PolarDB ist eine Cloud-native Datenbank mit eigenen Storage-Knoten, auf denen die Fähigkeiten der Scaleflux-Hardware sich laut Alibaba besonders gut nutzen lassen.
Was aber kann Scaleflux eigentlich liefern, und wie funktionieren die Laufwerke im Detail? Ein Blick in das aktuelle Portfolio des Unternehmens schafft Klarheit. Dort bewirbt man zwar noch die 2000er-Serie der eigenen Laufwerke, das eigentliche Highlight ist jedoch die deutlich jüngere 3000er-Serie. Sie kommt grundsätzlich in drei Formen daher: als AiC, also als Add-in-Card mit PCIe-Anschluss, als SSD mit U2-Schnittstelle oder als SFX 3000, der Anbietern die Konstruktion eigener Hardware mit Scaleflux-Featuren ermöglicht (Abbildung 1, Abbildung 2, Abbildung 3). Die vorgefertigten Laufwerke erhalten Sie zudem in den Geschmacksrichtungen NSD und CSD, wobei letztere das Capacity-Multiplier-Feature enthält – dazu später mehr. Klar ist jedenfalls: Scaleflux-Laufwerke lassen sich in jedem Server betreiben, der freie PCIe-Slots hat oder reguläre U2-NVMes aufnehmen kann. Das dürfte auf die allermeisten Standardserver von der Stange zutreffen.

Abbildung 1: Computational Storage SSDs von Scaleflux kommen in drei Formfaktoren daher: als AiC-Karte für den PCIe-Slot … Quelle: Scaleflux

Abbildung 2: … als reguläre NVMe mit U2-Schnittstelle im 2,5-Zoll-Formfaktor sowie … Quelle: Scaleflux

Abbildung 3: … als M2-Speicherriegel für die entsprechenden Steckplätze. Art und Umfang der verbauten Komponenten sind über die verschiedenen Formfaktoren hinweg identisch. Quelle: Scaleflux
Die Herstellerangaben zu den Fähigkeiten der Laufwerke lesen sich durchaus beeindruckend. Wer die Funktionen der Geräte virtualisieren will, bekommt eine vollständige SR-IOV-Implementierung mit insgesamt 15 verschiedenen Virtualisierungsfunktionen. Hardwareunterstützung für verschiedene Sicherheitsfunktionen nach dem OPAL-2.0-Standard der Trusted Computing Group (TCG) ist ebenfalls Bestandteil der Hardware. Für das sequenzielle Lesen nennt der Anbieter darüber hinaus eine Geschwindigkeit von 7,2 GByte pro Sekunde, für das Schreiben immerhin 4,8 GByte. Erwähnenswert sind daneben die IOPS-Angaben der Hardware: Über eine Million IOPS will man mit aktivierter Kompression bei Lese-Schreib-Workloads (Verhältnis 70/30) mit 4-KByte-Blockgröße erreichen. Mit anderen Standard-NVMes lassen sich diese Werte allerdings nicht direkt vergleichen, hier sollten Sie also Vorsicht walten lassen und die Fähigkeiten der Scaleflux-Hardware unbedingt genauer untersuchen.
Was Scaleflux verbaut
Ihren Anfang nimmt diese Untersuchung bei den genutzten Hardwarekomponenten, die der Admin sich ins Rechenzentrum holt. Für das Speichern von Daten kommen wenig überraschend NAND-Chips zum Einsatz, wie sie industrieweit für NVMes Standard sind. Das eigentliche Herzstück der Scaleflux-Laufwerke steckt aber in deren Prozessor, der bei der 3000er-Serie in Form eines ASICs auf ARM-Basis daherkommt (Abbildung 4). Hierin liegt übrigens einer der größten Unterschiede zur Vorgängerserie: Jene nutzte noch einen FPGA-basierten Chip, der sich im Laufe der Entwicklung allerdings als zu schwachbrüstig entpuppte. Passend dazu liefert die 3000er-Serie zudem eine zeitgemäße PCIe-4-Schnittstelle, wo die Vorgängerserie sich mit dem deutlich langsameren PCIe-3 begnügen musste.
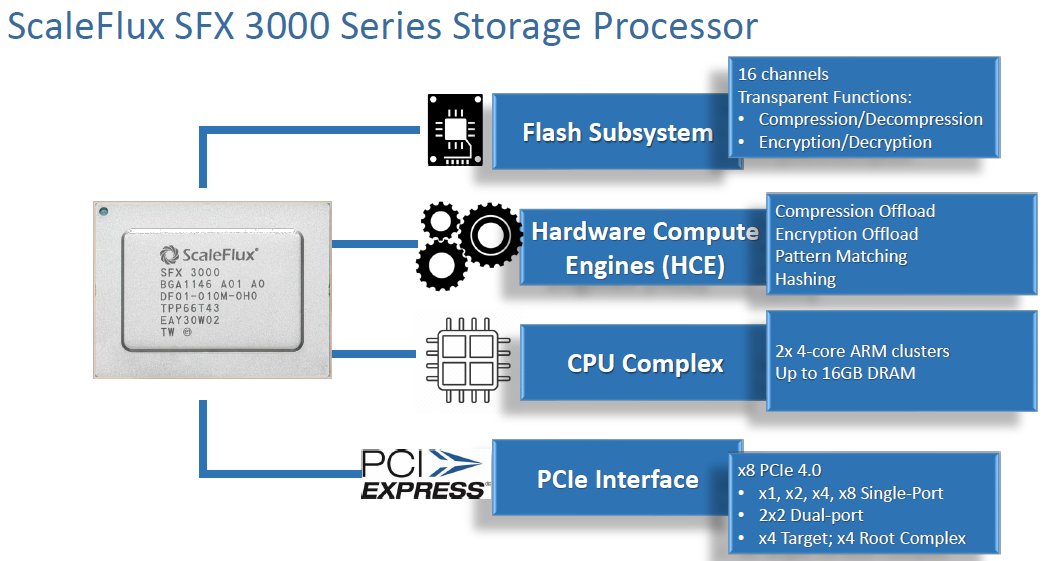
Abbildung 4: Scaleflux-NVMe-Laufwerke bieten neben dem typischen NAND-Speicher auch einen eigenen ARM-SoC mit eigenem RAM und speziellen Erweiterungen für Aufgaben wie die Komprimierung von Daten. Quelle: Scaleflux
Dem SoC zur Seite stehen RAM sowie verschiedene Spezialkomponenten zur Beschleunigung einzelner Arbeitsschritte. Während die Computational-Komponenten über alle Modelle der Serien hinweg identisch sind, ergeben sich bei der Anzahl der NAND-Chips und ihrer Größe Unterschiede: Erhältlich sind Scaleflux-NVMes aktuell in Größen von 3,2, 3,84, 6,4 sowie 7,68 TByte.
Gemeinsamkeiten
Der zentrale Unterschied zwischen den CSD- und NSD-Laufwerken ist wie beschrieben der Capacity Multiplier, darüber hinaus bieten die Geräte dasselbe Set an Grundfunktionen. Darin finden sich als Fundament die transparente Kompression und Dekompression der In-Flight-Daten einer Datenbank. Das Ziel der Übung lautet offensichtlich: Durch die Kompression erhöht sich die theoretisch verfügbare Bandbreite, und mehr Daten können zeitgleich ihre Reise durch den Bus bis zur Anwendung antreten. Das komplette Prozedere wickelt der ARM-SoC im Laufwerk ab, der zudem entsprechende Codecs implementiert hat und dadurch noch etwas schneller wird, als eine generische ARM-CPU es wäre. Dazu komprimiert der ARM-SoC im Speicherlaufwerk die Daten vor dem Ablegen im Flash-Speicher und entpackt sie erst wieder, wenn sie von der jeweiligen Datenbank angefordert werden. Wie vom Hersteller versprochen, ist dieser Vorgang aus Sicht der Anwendung komplett transparent: Die Datenbank, die an der Spitze eines solchen Konstrukts läuft, bekommt von der Kompression der Daten gar nichts mit. Sie kann eben dank der im Laufwerk eingebauten Rechenleistung Daten trotzdem so schnell lesen und schreiben, als handele es sich um eine normale NVMe.
Von der Kompression profitieren auf der Anwendungsseite besonders umfangreiche Datenbankabfragen und solche, bei denen große Datenmengen zu verarbeiten sind. Drei Vorteile reklamiert der Hersteller dabei für sich: Zunächst seien Lesevorgänge deutlich schneller und mit geringerer Latenz abzuarbeiten, als bei normalen Laufwerken. Das ergibt sich daraus, dass das Auslesen der komprimierten Blöcke so schnell wie bei normalen SSDs funktioniere, im selben Zeitraum aber eben viel mehr Daten auszulesen sind. In gemischten Lese- und Schreib-Workloads, wie sie in den meisten Rechenzentren Standard sind, reduziert die Kompression zudem die Latenz weiter, weil die Write-to-Read-Interferenz geringer ausfällt. Unter diesem Begriff versteht man die Wartezeit, die entsteht, wenn etwa der Controller einer SSD zwischen Lese- und Schreibbefehlen hin- und herschaltet. Wieder gilt: Weil mehr Daten parallel ausgelesen werden, sind insgesamt weniger Wechsel zwischen Lese- und Schreibmodus nötig, sodass die Latenz sich insgesamt verbessert.
Obendrein erhöht laut Scaleflux die Kompression der Daten die Lebensdauer der verbauten NAND-Chips, weil dann insgesamt weniger auf den Datenträger geschrieben wird. In Erinnerung gerufen sei an dieser Stelle die Art und Weise, wie Flash-Chips grundsätzlich funktionieren: In ihrem Kern nutzen sie chemische Reaktionen zum Speichern der Daten. Diese Reaktionen lassen sich allerdings nicht beliebig oft wiederholen. Eben deshalb ist bereits bei der Anschaffung heute die DWPD-Zahl eines Laufwerks für Administratoren ein entscheidender Faktor. Sie gibt grob vereinfacht an, wie oft das Laufwerk insgesamt komplett überschrieben werden kann, ohne dass Datenkorruption durch defekte Blöcke zu befürchten ist. “SSDs gehen nicht seltener kaputt als Festplatten, aber besser berechenbar”, lautet in diesem Kontext ein Bonmot der Branche, das im Kern durchaus richtig zutrifft.
Scaleflux selbst bezeichnet die Funktion vielleicht etwas überkandidelt als Endurance Multiplier, liefert selbst allerdings keine konkreten Zahlen hinsichtlich der Zeit, um die das Feature die Lebenserwartung eines NVMe-Laufwerks steigert. DWPD-Angaben suchen Sie ebenfalls vergeblich. Sehr wohl dagegen finden Sie Informationen zum Kompressionsgrad, den man bei Scaleflux erreichen will: Um den Faktor 4 soll dieser im Schnitt liegen – vorausgesetzt, die zu verarbeitenden Daten lassen sich komprimieren.
Korrelierend dazu implementieren die Modelle der 3000er-Reihe von Scaleflux außerdem Verschlüsselung nach den TCG-OPAL-Standards. Die Verschlüsselung verläuft aus Sicht des Betriebssystems erneut transparent, die jeweilige Anwendung weiß also nicht, dass die Daten verschlüsselt auf dem Datenträger liegen. Weil das Laufwerk die Verschlüsselung – dank entsprechender Codecs sehr flink – bewältigt, ergeben sich in Sachen Performance keine Nachteile.
Unterschiede
Vor dem Hintergrund der Kompression der Laufwerke rückt der Capacity Multiplier nochmal in den Fokus, den Scaleflux für sein Produkt massiv bewirbt. Er bezieht sich nämlich ebenfalls auf die implizite Kompression und markiert den einzigen zentralen Unterschied zwischen den NSD-Laufwerken und den deutlich teureren CSD-Laufwerken.
Unter Capacity Multiplier versteht der Hersteller den Ansatz, bereits beim Provisionieren des Laufwerks so zu tun, als sei das Laufwerk eigentlich viel größer. Das birgt gewisse Vorteile, etwa dass sich der durch die Kompression gewonnene Platz auch durch das Betriebssystem effektiv nutzen lässt. Andererseits gehen mit dem Ansatz Risiken einher: Ist der Grad der Kompression, dem die theoretische Berechnung der Laufwerksgröße zugrunde liegt, nicht zu erreichen, kann das Laufwerk schneller volllaufen, als seine Größenangabe es plausibel macht. Zumindest würde in diesem Szenario das Betriebssystem korrekte Belegungswerte vom Laufwerk geliefert bekommen. Eine Situation, in der laut Df noch 50 Prozent Platz zur Verfügung stehen, das Laufwerk aber trotzdem bereits voll ist, ist insofern nicht zu erwarten. Ob Ihnen der Mehrwert durch die Nutzung der Funktion den Aufpreis wert ist, müssen Sie letztlich für sich selbst entscheiden.
Nach Maß
Wieder gemeinsam ist beiden Serien ist der verwendete Chip und dass der Hersteller für diesen nicht nur Implementierungsunterstützung anbietet, sondern gegebenenfalls sogar bei der Entwicklung hilft. Dabei spielt auch die Firmware eine Rolle, die auf den Scaleflux-Laufwerken läuft: Csware (Abbildung 5) bietet die Möglichkeit, mithilfe des Herstellers spezielle Firmware für spezifische Einsatzzwecke auszurollen. Firmen wie Alibaba dürften von eben dieser Option ausgiebig Gebrauch gemacht haben, stoßen bei Scaleflux jedoch vermutlich auf größeres Interesse als kleine Unternehmen mit kleinen Plattformen.
Unabhängig von der Größe steht jedenfalls allen Firmen die Möglichkeit offen, den ARM-SoC der 3000er-Reihe in eigenen Anwendungsfällen zu verbauen. Das ist insbesondere dann interessant, wenn Sie die Vorteile von Computational Storage nutzen wollen, ohne auf die Geräte von Scaleflux zurückzugreifen.

Abbildung 5: Der SFX-3000-Chip ist das Herzstück der Scaleflux-Architektur. In Verbindung mit entsprechender Firmware soll er für noch bessere Performancewerte als die Standardversion sorgen. Quelle: Scaleflux
Was andere sagen
Dass sich mit Scaleflux-Hardware geringere Latenzen und höhere Bandbreiten ebenso erreichen lassen wie höhere Speicherdichte und dadurch ein geringerer Wear-Level-Faktor bei den SSDs, liegt auf der Hand. Fragt sich trotzdem, wie groß die Vorteile tatsächlich sind, die durch die Verwendung der Komponenten entstehen. Im Netz finden sich dazu ergiebige Quellen mit konkreten Zahlen. Eine davon ist der Datenbankspezialist Percona, der Scaleflux sowohl im Kontext von MySQL als auch von PostgreSQL erprobt hat.
Weitere Zahlen, vor allem solche für Oracle, liefert das amerikanische Branchenmagazin StorageReview.com. Die Testparameter sind dabei durchaus vergleichbar, gemessen wurden zufällige wie sequenzielle Lese- und Schreibvorgänge in verschiedenen Chunk-Größen etwa von 4 KByte und 64 KByte sowie Lese- und Schreibvorgänge in Oracle selbst.
Beide Anbieter gelangen dabei zu Testergebnissen, die in sich kohärent und in Relation zueinander stimmig sind. Zufällige Lese- wie Schreibvorgänge bei 4 KByte Chunk-Size führen beim Lesen von Daten zu ähnlichen Ergebnissen über alle Laufwerke hinweg, und zwar unabhängig davon, ob das Kompressionsverhältnis von 2:1 beim Test eingehalten wurde. Hier liegen sowohl die CSD3000-Laufwerke mit 3,84 TByte als auch jene mit 7,68 TByte im Bereich zwischen 850 000 und 900 000 IOPS. Schreiben mit derselben Blockgröße führt zu deutlich anderen Resultaten: Ohne Datenkomprimierung bringen es die Laufwerke auf 380 000 bis 420 000 IOPS, mit Komprimierung auf weit über 700 000. Beim Lesen mit einer Blockgröße von 64 KByte sinkt die IOPS-Zahl auf knappe 6000 ohne und auf 7000 mit Kompression. Die Schreibvorgänge sind hier aber noch interessanter: Mit aktivierter Komprimierung schlagen sich sowohl die kleine als auch die große Scaleflux-NVMe mit 6000 IOPS gut. Ohne Kompression liegen beide Geräte bei einem eher schwachen Wert unter 2000. In allen beschriebenen Fällen wirkte sich die genutzte Kompression zudem positiv auf die Latenz aus, die im Schnitt um 30 bis 40 Prozent geringer ausfiel.
Weniger drastisch wirkt der Faktor Kompression sich im Fall von Datenbankanwendungen aus. Hier verläuft die Baseline der kleinen NVMe der 3000er-Serie bei guten 250 000 IOPS, während die große NVMe mit aktivierter Kompression die 300 000 IOPS deutlich überspringt. Die Werte für normales SQL – also MariaDB oder PostgreSQL – und Oracle sind dabei deutlich vergleichbar, wobei Oracle insbesondere von aktivierter Kompression auf der großen SSD profitiert: Hier stehen 220 000 IOPS 330 000 IOPS gegenüber.
StorageReview.com hat einen weiteren Use-Case ausgemacht, der die Vorzüge der Scaleflux-Laufwerke besser zur Geltung bringt: Speicherlaufwerke im VDI-Kontext (virtuelle Desktop-Infrastruktur). Hier liegen die Messwerte der großen SSDs mit aktivierter Kompression teilweise um mehr als 100 Prozent höher als jene der kleinen SSD ohne Kompression. Das ergibt aber auch Sinn: Im VDI-Kontext dürfte der Anteil der zu speichernden Daten, der sinnvoll zu komprimieren ist, deutlich größer sein als in den meisten Datenbankszenarien mit traditionell eher kleiner Chunk-Size.
Während StorageReview.com in seinen Tests ausschließlich Scaleflux-Laufwerke einander gegenübergestellt hat, wagte Percona zusätzlich den direkten Vergleich mit einem Laufwerk von Intel, dem Modell P4610. Der Vergleich ist realistisch, denn das Intel-Gerät zählt zu den Standard-NVMes und findet sich mithin als Standardlösung in vielen Einsatzszenarien. Allerdings liegt der Percona-Test bereits etwas länger zurück und setzt deshalb auf den Vorgänger der CSD3000, die CSD2000. Hier dürfte die Erklärung dafür liegen, dass die Scaleflux-Laufwerke bei den Percona-Tests den Intel-Gegenstücken in vielen Einzeltests nur wenig in Sachen Geschwindigkeit voraus hatten.
Kombiniert man die Testergebnisse von Percona und StorageReview.com jedoch miteinander und lässt die Aussagen des Anbieters zu den Geschwindigkeitsverbesserungen der 3000er-Serie einfließen, ergibt sich ein schlüssiges Gesamtbild. Demnach liegt der Geschwindigkeitsvorteil der 3000er-Serie von Scaleflux gegenüber einem Setup ohne die Spezialhardware bei MySQL im Schnitt um 50 Prozent höher, bei PostgreSQL je nach Szenario sogar um 200 Prozent. Dank der Kompression fassten Scaleflux-Laufwerke bei maximaler Nutzung im Schnitt über 200 Prozent der Daten des vergleichbaren Intel-Gerätes.
Fazit
Konkrete Preise waren Scaleflux wie üblich nicht zu entlocken. Doch Google-Recherchen ergeben, dass die Geräte des Herstellers preislich etwa auf dem Niveau normaler NVMe-Laufwerke ohne die Zusatzfunktionen liegen. Letztere sind seither deutlich günstiger geworden, sodass aus heutiger Sicht die Scaleflux-Hardware ein wenig teurer sein dürfte. Technisch profitieren Setups von den Vorzügen der Geräte allerdings erheblich. Jeder Datenbankadministrator wird sich über 50 Prozent Performance-Gewinn und mehr freuen, die er durch den bloßen Austausch der Storage-Hardware erreichen kann. Dass dabei darüber hinaus die CPU entlastet wird, ist ein gern gesehener Nebeneffekt. Klar ist auch: Passt man mithilfe des Anbieters die Firmware der Laufwerke stärker an die eigenen Anwendungsszenarien an, lässt sich vermutlich noch mehr Performancezuwachs herauskitzeln.
Bei Scaleflux selbst denkt man inzwischen schon in andere Richtungen. Aktuell enthalten die ARM-SoCs noch keine Codecs für Multimedia-Anwendungen. Gerade diese würden von erhöhtem Durchsatz und geringerer Latenz jedoch erheblich profitieren – und hier wäre zudem der Faktor der Entlastung für die Host-CPU nochmals deutlich größer. Perspektivisch sind Scaleflux-Laufwerke dementsprechend für den Multimediabereich nicht nur vorstellbar, sondern relativ wahrscheinlich. (jcb/csi)
Infos
- Scaleflux: https://scaleflux.com





