
© Siarhei Yurchanka / 123RF.com
Typische Linux-PCs arbeiten mit CISC-CPUs, deren Wurzeln bis in die 1970er-Jahre zurückreichen. Mit den Alternativen ARM und RISC-V etablieren sich heute alternative Instruction Set Architectures aus der RISC-Welt.
Der erste von Linus Torvalds veröffentlichte Linux-Kernel lief 1991 auf einem Intel-80386-Prozessor (und dem schon verfügbaren Nachfolger 80486). Die beiden CPUs bilden mit dem Pentium (i586) und dem Pentium Pro (i686), II und III sowie kompatiblen Konkurrenzprodukten von AMD und Cyrix eine Prozessorfamilie. Alle Mitglieder dieser Familie gehören zur Intel-32-Bit-Architektur (kurz: IA-32 oder x86). Neuere CPUs mit einer Erweiterung auf 64 Bit bilden die x86_64- beziehungsweise AMD64-Familie.
Die enger miteinander verwandten CPUs verbindet eine gemeinsame Befehlssatzarchitektur (Instruction Set Architecture, ISA). Das bedeutet im Wesentlichen, dass sie sich nach außen (zum Assembler-Programmierer oder zum Compiler-Entwickler hin) ähnlich verhalten. Wenn die Weiterentwicklung einer CPU kompatibel zum Vorgänger ist, sie also Code ausführen kann, der für den Vorgänger geschrieben wurde, gehört sie zur selben Befehlssatzarchitektur. In diesem Sinn bilden x86 und x86_64 eine gemeinsame ISA, denn die x86_64-CPUs können sich im 32-Bit-Modus wie die älteren CPUs verhalten. Auch die noch älteren 16-Bit-CPUs (Intel 8086 und 80286) reihen sich da ein. Allerdings läuft Linux seit 2012 nicht mehr auf dem 80386, und Torvalds denkt sogar über ein Ende der Unterstützung für den 486er nach [1].
Heute ist Linux mit einer Vielzahl an Prozessoren kompatibel, die sich stärker voneinander unterscheiden, als es in den 1990er-Jahren der Fall war. Aktuelle Raspberry-Pi-Modelle führen Linux auf dem 64-Bit-ARM-Chip Cortex-A72 aus, die ISA heißt ARMv8. Ähnliche ARM-CPUs treiben auch moderne Android-Smartphones an, für die M1- und M2-basierten Macs von Apple (wieder ARMv8-basiert) gibt es ebenfalls einen Linux-Port. Der VisionFive 2 [2] im RasPi-Format ist mit seinem RISC-V-Prozessor ein Vertreter einer neuen Gerätegeneration, die auf die Open-Source-Hardware RISC-V [3] setzt; die ISA heißt riscv64. Außerdem läuft Linux auch auf IBM-Mainframes der Z-Serie, die einen Telum-Prozessor mit einem Instruction Set namens Power ISA verwenden.
Entwicklungsschritte
Wie leistungsfähig der Prozessor in einem Rechner, Smartphone oder sonstigen Gerät ist, hat zentralen Einfluss auf die Performance des ganzen Systems. Zum Leistungsvergleich von Systemen eignen sich einfache Kenngrößen wie der CPU-Takt und die Anzahl der Prozessorkerne nicht. Die Taktfrequenz gibt nur an, wie viele Instruktionen pro Sekunde (im Idealfall) der Prozessor verarbeiten kann. Das berücksichtigt aber nicht, wie produktiv eine solche Instruktion ist. Zudem bleiben Instruktionen außen vor, die mehr als einen Takt benötigen. Lediglich bei bis auf die Taktfrequenz identischen Prozessoren führt der schnellere Takt direkt zu mehr Leistung.
Um nun Rechner mit unterschiedlichen CPUs vergleichen zu können, nutzt man synthetische und praxisorientierte Benchmarks. Sie erledigen auf dem zu beurteilenden Rechner verschiedene Aufgaben, messen die Laufzeiten und berechnen daraus einen Score. Der lässt sich dann direkt mit entsprechenden Scores anderer Maschinen vergleichen [4].
Über viele Jahrzehnte konnten Prozessorentwickler die Leistung steigern, indem sie die CPUs unter anderem durch ständig abnehmende Abstände zwischen den Transistoren auf dem Chip beschleunigten. Aus den geringeren Abständen resultieren kürzere Signallaufzeiten zwischen den Komponenten, ein Chip gleicher Größe kann bei zunehmender Miniaturisierung mehr Transistoren aufnehmen. Nach dem Mooreschen Gesetz war alle zwei Jahre eine Verdopplung der Transistorenzahl und damit exponentielles Wachstum zu beobachten (Abbildung 1). Solches Wachstum hat aber physikalischen Grenzen [5], und bei den Taktraten bremst das Wachstum schon ein.
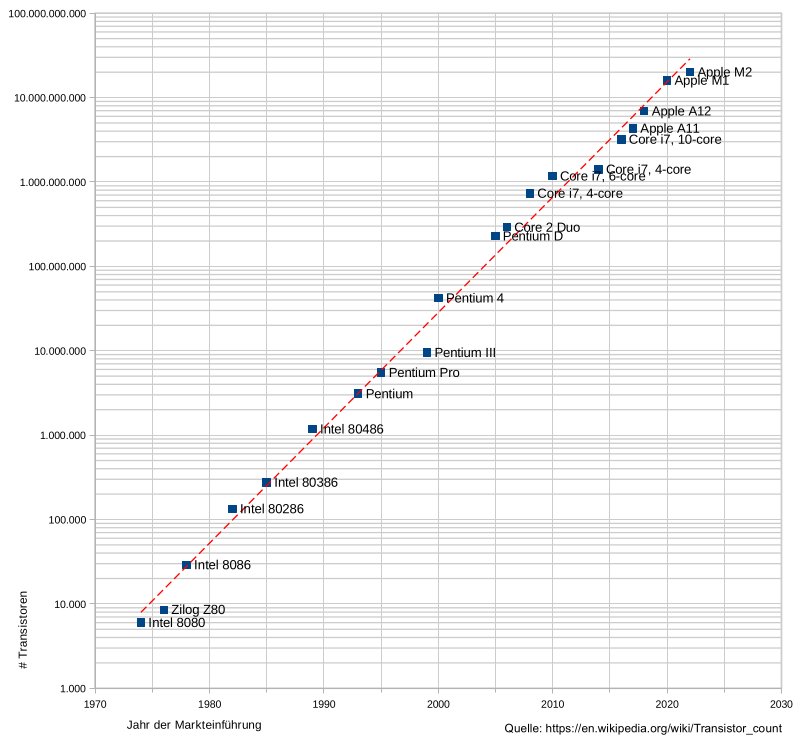
Abbildung 1: Die y-Achse zeigt die Transistorenzahl mit logarithmischer Skala. Das exponentielle Wachstum von 1974 bis 2022 lässt sich hier gut erkennen.
Pipelining und Multi-Core
Um Prozessoren auch ohne Taktänderung zu beschleunigen, setzen die Hersteller einige bewährte Optimierungsverfahren ein. Dazu gehören schnelle Caches für Instruktionen und Daten sowie Pipelines, mit denen sich die Verarbeitung einer Instruktion auf mehrere separate Pipeline-Stufen aufteilen lässt. Wie an einem Fließband in der industriellen Fertigung durchläuft jede Instruktion diese Stufen nacheinander, und zu jedem Zeitpunkt beschäftigt sich die CPU gleichzeitig mit mehreren Instruktionen, die unterschiedlich weit durch die Pipeline gelaufen sind.
Anspruchsvoll wird das Pipelining, wenn bedingte Sprünge ins Spiel kommen. Die CPU muss die Pipeline dann mit neuen Instruktionen befüllen, ohne sicher zu wissen, ob diese wirklich ausgeführt werden sollen: Welcher Befehl auf einen bedingten Sprung folgt, hängt davon ab, ob die Bedingung erfüllt ist – so funktionieren Fallunterscheidungen. Eine Zeit lang war es Mode, die Programmierer (oder Compiler) aufzufordern, bei Sprungbefehlen in Form einer Probable-Branch-Instruktion einen Hinweis auf die Sprungwahrscheinlichkeit einzubauen.
Moderne CPUs arbeiten stattdessen mit Sprungvorhersagen (Branch Prediction), die ohne Mithilfe der Code-Entwickler funktionieren [6]. Prozessoren mit superskalaren Pipelines können in einem Schritt mehrere Instruktionen in die Pipeline holen und in der Rechenphase auf verschiedene Recheneinheiten aufteilen, sofern die verfügbar sind: Ganzzahl- und Fließkommaberechnungen nutzen zum Beispiel verschiedene Recheneinheiten, sodass dann eine Integer- und eine Floating-Point-Addition echt parallel ablaufen können.
Auch Pipelining als CPU-Beschleuniger stößt aber an Grenzen, weil sich die Verarbeitung einer Instruktion nicht in beliebig viele Stufen aufteilen lässt. Das Grundkonzept der Parallelisierung lässt sich auch anders umsetzen, zum Beispiel mit mehreren Prozessoren in einem Rechner oder mehreren Kernen in einer CPU. Die Hersteller entwickeln zur weiteren Leistungssteigerung seit einigen Jahren Mehrkern-CPUs, was aber nicht mehr automatisch zu schneller laufenden Programmen führt: Damit eine Anwendung mehrere Kerne nutzen kann, müssen die Entwickler sie zunächst parallelisieren, also dafür sorgen, dass mehrere Vorgänge parallel auf verschiedenen CPU-Kernen laufen.
Pipelining und andere Verfahren zur Leistungssteigerung gehören zur Mikroarchitektur, die die ISA konkret implementiert. Zu einer ISA kann es zahlreiche Chips mit unterschiedlichen Mikroarchitekturen geben. Die CPUs sind dann miteinander kompatibel, auch wenn sie intern einen völlig anderen Aufbau aufweisen.
Architekturen
Die Bemühungen, Prozessoren leistungsfähiger zu machen, haben die Hardwareentwickler zum Teil in sehr unterschiedliche Richtungen geführt. Eine Grundsatzfrage war etwa: Ist es besser, wenn Prozessoren immer leistungsfähigere Instruktionen unterstützen, was das Leben für Assembler-Programmierer und Compiler-Entwickler vereinfacht? Oder ist es sinnvoller, wenn sich CPUs darauf beschränken, vergleichsweise simple Instruktionen auszuführen, das aber sehr schnell? Der erste Ansatz führte zu CISC-Prozessoren (Complex Instruction Set Computing), der zweite zu RISC-CPUs (Reduced Instruction Set Computing).
Die Unterschiede zwischen den CPUs beschränken sich nicht auf interne Optimierungen. Neben offensichtlichen Aspekten wie dem Pin-Layout gibt es strukturelle Eigenschaften wie die Breite der Daten- und Adressbusse sowie die Größe interner Prozessorregister. Vor allem ist für Anwendungsprogrammierer und Compiler-Entwickler der Befehlssatz wichtig, den die CPU versteht. Anwendungen laufen nicht automatisch auf beliebigen Geräten; sie müssen zum Betriebssystem (und dessen Version) sowie zur Hardware passen. Bei Linux muss es meist auch die richtige Distributionsversion sein, wenn das Programm zur Laufzeit Bibliotheken einbindet, die es nicht selbst mitbringt.
Mit passender Hardware ist dabei nicht der benötigte Arbeitsspeicher oder Plattenspeicher gemeint – vielmehr geht es um den Prozessor. Lauffähige Programmdateien (Executables) enthalten nicht portablen Maschinencode. Manche Prozessoren sind miteinander kompatibel, andere wenigstens abwärtskompatibel zu früheren Generationen der gleichen CPU. Das bedeutet, dass alte Programme, die für eine frühere CPU-Generation entwickelt wurden, auch auf dem aktuellen Chip laufen.
Für welche Prozessoren die Compiler Ihrer Linux-Installation Code erzeugen können, finden Sie heraus, indem Sie über die Anweisung »gcc -march=/ -xc /dev/null« eine Fehlermeldung provozieren. Der C-Compiler bezeichnet die Zielplattform als Target CPU, und die unmittelbar unterstützten Targets gehören alle zur selben Prozessorfamilie. Bei den ersten beiden Aufrufen in Abbildung 2 reagiert der C-Compiler auf die Wahl eines ungültigen Targets (über »-march=/«) mit der Ausgabe der ihm bekannten Targets, die alle zur Familie der 64-Bit-Intel-CPUs (x86_64) gehören. Dabei spielt es keine Rolle, ob der Compiler unter Linux (oben) oder MacOS (Mitte) läuft, da in beiden Fällen ein Intel-Prozessor im Rechner steckt.
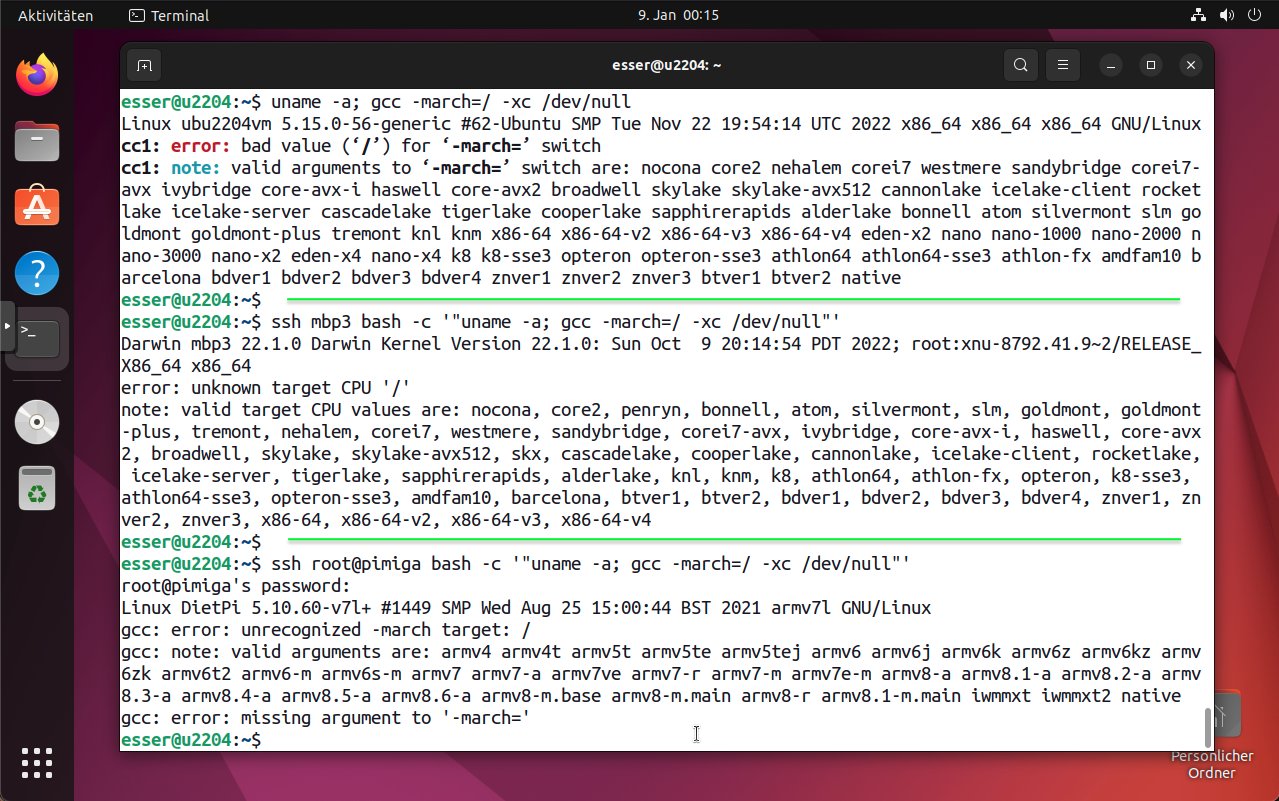
Abbildung 2: Der C-Compiler zeigt an, für welche Prozessoren er Code erzeugen kann. Dabei geht es oft um Optimierung.
Übersetzen Sie Software (Anwendungen oder auch den Linux-Kernel) aus den Quellen und verlangen dabei, Code für den in den verwendeten Rechner verbauten Prozessor zu generieren, profitieren Sie von Optimierungen, die nur mit dieser CPU möglich sind. Der Maschinencode nutzt dann zum Beispiel Instruktionen, die es auf anderen Prozessoren nicht gibt. Der Preis für die Optimierung: Die erstellten Binaries laufen nicht auf anderen Maschinen mit geringfügig älterer CPU.
Das untere Drittel der Abbildung zeigt die Rückmeldung, die der C-Compiler auf einem Raspberry Pi 4B gibt: Der Single Board Computer nutzt einen ARM-Prozessor, und entsprechend unterstützt die installierte GCC-Version diverse ARM-Modelle.
Um Code für eine fremde Architekturfamilie zu erzeugen, benötigen Sie einen Cross-Compiler und die komplette zugehörige Toolchain aus Assembler, Linker und weiteren Hilfsprogrammen. Die Programmdateien einer solchen Toolchain heißen zur besseren Unterscheidung nicht einfach »gcc«, »as« oder »ld«, sondern erhalten ein gemeinsames, bis zu vierteiliges Präfix (Abbildung 3), beispielsweise:
- »x86_64-linux-gnu-« (Intel-PC, Linux),
- »x86_64-apple-darwin22.1.0-« (Intel-Mac, MacOS),
- »armv6-rpi-linux-gnueabihf-« (Raspberry Pi 4B, Linux) oder
- »riscv32-linux-gnu-« (RISC-V-32, Linux; Abbildung 3).
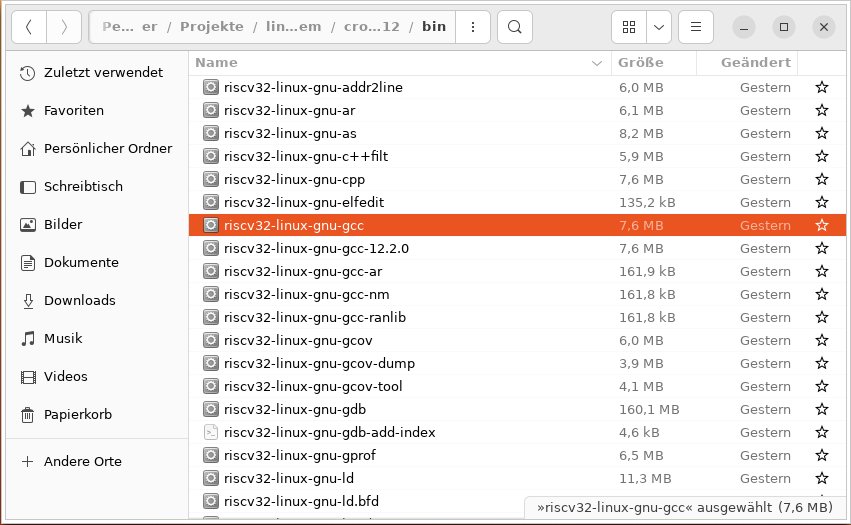
Abbildung 3: Mitglieder einer Cross-Compiler-Toolchain erkennen Sie am Namenspräfix. Die gezeigten Tools erzeugen 32-Bit-RISC-V-Binaries.
Der Cross-Compiler, der Code für RISC-V-32 erzeugt, heißt dann etwa »riscv32-linux-gnu-gcc«, der Assembler »riscv32-linux-gnu-as« und der Linker »riscv32-linux-gnu-ld«.
Die drei bis vier Komponenten des Präfixes geben die Architektur (»x86_64«, »armv6« oder »riscv32«), den Anbieter (»apple«, »rpi« = Raspberry Pi), das Betriebssystem (»linux«, »darwin22.1.0«) und das ABI (Application Binary Interface) an. Letzteres legt Aufrufkonventionen für Funktionen fest und muss stimmen, damit Programme Funktionen aus Bibliotheken nutzen können [7].
Operanden
Die Komponenten im Prozessor, die Berechnungen vornehmen, bezeichnet man traditionell als ALU (Arithmetic Logic Unit). Neben typischen mathematischen Operationen wie den vier Grundrechenarten, Modulo (Divisionsrest) oder trigonometrischen Funktionen (Sinus, Cosinus etc.) gibt es auch logische (bitweises AND/OR/XOR, Negation) und Verschiebeoperationen. Alle haben gemeinsam, dass sie mindestens einen Operanden benötigen, mit dem sie dann rechnen, und dass die Berechnung ein Ergebnis erzeugt.
Wie groß die Operanden sein dürfen und wo man sie findet, hängt vom Befehlssatz ab. Typischerweise stellt die Größe der Standardregister auch das Limit für die Operandenbreite dar. Sind also die Standardregister der CPU 32 Bit breit, rechnet sie mit bis zu 32 Bit breiten Ganz- und Fließkommazahlen. Bei einem Prozessor mit 64-Bit-CPU sind entsprechend 64 Bit die Grenze. Dazu passt, dass Registerinhalte potenzielle Argumente für Rechenoperationen sind.
Ein typisches Beispiel dieser Kategorie ist die x86_64-Instruktion aus der ersten Zeile von Listing 1. Sie addiert die Inhalte der Register »rax« und »rbx« und speichert die Summe im Register »rax«. Genauso können Konstanten Argumente sein (zweite Zeile). Auch ein im Hauptspeicher liegender Wert kann als Operand dienen. Dazu gibt man die Speicheradresse an, entweder explizit über ein Register oder gelegentlich auch über einen zusammengesetzten Ausdruck. Die Instruktionen aus den Zeilen 3 bis 5 sind gültige 32-Bit-Assembler-Befehle für x86.
Listing 1
x86_64-Operanden
add rax, rbx add rax, 42 add eax, [0x12345678] add eax, [ebx] add eax, [0x12345678+ebx+4*ecx]
Die Instruktionen in den Zeilen*3 und 4 haben zwei Operanden, die der Programmierer im Maschinencode als Registernummer (»eax«, »ebx«) beziehungsweise als 32-Bit-Speicheradresse (»0x12345678«) ablegt. Die letzte Instruktion hat ebenfalls zwei Operanden, aber der hintere ist komplex: Im Maschinencode finden sich später die Adresse »0x12345678«, die internen Nummern der Register »ebx« und »ecx« sowie eine Kodierung des Faktors 4.
Listing 2
Assembler-Code
03 05 78 56 34 12 03 03 03 84 8b 78 56 34 12
Assembliert (also in Maschinencode umgewandelt) werden die drei letzten Instruktionen aus Listing 1 zu den Byte-Folgen aus Listing 2. Das können Sie schnell mit einem Online-x86-Assembler [8] überprüfen. Die Speicheradresse »0x12345678« wird jeweils über die Byte-Folge »78 56 34 12« kodiert, weil Intel-Prozessoren das Little-Endian-Modell für die Darstellung von Ganzzahlen verwenden [9]. Sie legen die vier Bytes einer 32-Bit-Zahl also in umgekehrter Lesereihenfolge im Speicher ab, die niederwertigen Bits stehen jeweils links.
Weniger klar ist die Bedeutung der jeweils vorangehenden Bytes, also »03 05« im ersten und »03 84 8b« im dritten Befehl. Dasselbe gilt für die Kombination »03 03« im zweiten Befehl. Es gibt in der x86-Architektur acht je 32 Bit breite Standardregister (»eax«, »ebx«, »ecx«, »edx«, »esi«, »edi«, »esp«, »ebp«). Bei x86_64 heißen sie »rax«, »rbx«, »rcx«, »rdx«, »rsi«, »rdi«, »rsp« und »rbp«. Hinzu kommen noch acht einfach als »r8« bis »r15« durchnummerierte Register.
Eines von acht Registern in einer Byte-Folge zu kodieren, erfordert 3 Bits (23=8). Die mittlere Instruktion »add eax, [ebx]« muss zwei Registernummern (für »eax« und »ebx«) kodieren, benötigt dafür also 6 Bits. Die letzte Instruktion »add eax, [0x12345678+ebx+4*ecx]« enthält drei Register zu je 3 Bits sowie eine 32-Bit-Adresse. Hinzu kommt ein Faktor (hier 4), für den nur die Werte 1, 2, 4 und 8 zulässig sind, was sich in 2 Bits kodieren lässt. Es ergeben sich für die Argumente also in der Summe 40 Bits (6+32+2) Speicherbedarf, sprich 5 Bytes.
Vor die Argumentkodierung gehört noch der Opcode, eine Bitfolge, die die eigentliche Instruktion kodiert. Es gibt aber nicht einfach einen Opcode für »mov«, weil es sich bei den drei »mov«-Beispielen aus Listing 2 um drei unterschiedliche Befehle handelt. Abbildung 4 zeigt die Kodierung mehrerer ähnlicher »mov«-Instruktionen, die jeweils den Wert in eines der acht Standardregister schreiben; die letzte Spalte enthält die Binärdarstellung des ersten Bytes. Der Opcode für diesen Befehl besteht nur aus den ersten 5 Bits, danach folgt schon das erste Argument (die 3-Bit-Registernummer).

Abbildung 4: Die Kodierungen ähnlicher »mov«-Befehle mit verschiedenen Zielregistern unterscheiden sich nur in drei Bits.
Aus dieser Übersicht lässt sich die Zuordnung (»eax=000«, »ebx=011«, »ecx=001« und so weiter) ableiten, die auch für alle übrigen Befehle gilt, die mit einem oder mehreren Registern arbeiten. In Abbildung 5 sehen Sie für die drei Beispielbefehle die Kodierungen und insbesondere die Längen. Der mittlere Befehl kommt mit 2 Bytes aus, die anderen Befehle erfordern 6 respektive 7 Bytes, wobei jeweils die 32-Bit-Adresse schon 4 Bytes belegt.

Abbildung 5: x86-Befehle sind unterschiedlich komplex und lang. Die Beispiele kodieren bis zu drei Register, eine Adresse und eine Konstante in einem Befehl.
Speicherzugriff
Die bisherigen Codebeispiele führten Additionen aus und schrieben das Rechenergebnis jeweils in das Register »ebx«. Eine übliche Anweisung in einem Hochspracheprogramm ist das Addieren zweier Variablen samt Speichern der Summe in einer dritten Variablen. In C-Syntax sieht das zum Beispiel wie folgt aus:
int a = 42, b = 9, c; c = a + b;
Die Werte 42 und 9 aus den Variablen »a« und »b« liegen im Hauptspeicher. Ihre Speicheradressen lassen sich in C über den Address-of-Operator (»&«) ermitteln. Bei der Addition hat der Prozessor keinen unmittelbaren Zugriff auf die Speicherzellen. Die Berechnung von »c = a + b« erfordert daher mehrere Schritte: Zunächst gilt es, »a« und »b« aus dem Speicher auszulesen, sodass die CPU die Werte kennt. Dann erfolgt die eigentliche Addition, gefolgt vom Zurückschreiben des Ergebniswerts »c« in den Speicher.
Es stellt sich die Frage, wie viele Assembler-Befehle man benötigt, um diese Arbeiten zu erledigen. Denkbar wäre etwa, alles in eine einzelne Instruktion zu packen. Das entsprechende hypothetische Beispiel aus der zweiten Zeile von Listing 3 geht davon aus, dass Speicheradressen nur 16 Bits breit (und damit über vierstellige Hexadezimalzahlen darstellbar) sind und dass »a«, »b« und »c« an den Adressen »0xa000«, »0xa004« und »0xa008« liegen. Der Abstand von je 4 Bytes ergibt sich aus der üblichen Größe von Integer-Zahlen (32 Bits, also 4 Bytes).
Listing 3
Assembler-Varianten
; -------- Variante 1 -------- add [0xa008],[0xa000],[0xa004] ; -------- Variante 2 -------- mov reg1,[0xa000]mov reg2,[0xa004]add reg1,reg2 ; Erg. in reg1mov [0xa008], reg1 ; -------- Variante 3 -------- mov reg1,[0xa000]add reg1,[0xa004]mov [0xa008],reg1
Das alternative Szenario aus den Zeilen 4 bis 7 packt jeden Arbeitsschritt in eine separate Instruktion. Dabei heißen Lesebefehle Load und Schreibbefehle Store, der Prozessor implementiert eine Load/Store-Architektur. Eine Zwischenform, die Speicherinhalte zu Registern addieren kann, haben Sie bereits in Listing 1 kennengelernt. Mit neutralen Registernamen sieht der Code so aus wie in den letzten drei Zeilen von Listing 3.
Die drei Varianten unterscheiden sich hinsichtlich der Anzahl der benötigten Instruktionen, aber auch in der Komplexität: Der Einzeiler aus der ersten Variante kombiniert drei Speicherzugriffe (zwei Operanden lesen, Ergebnis schreiben) mit einer arithmetischen Operation, während bei der zweiten Variante jede Instruktion entweder einen Speicherzugriff ausführt oder rechnet. Die dritte Form kombiniert den lesenden Speicherzugriff mit einer Addition.
Je nachdem, welche dieser Varianten der Befehlssatz eines Prozessors unterstützt, fällt bei der CPU-internen Implementierung (also in der Mikroarchitektur) unterschiedlicher Aufwand an: Wenn Befehle vor und nach Berechnungen auf den Speicher zugreifen dürfen, ist es schwieriger, eine Pipeline zu konstruieren.
RISC und CISC
Die klassische Unterscheidung zwischen RISC- und CISC-CPUs (Reduced beziehungsweise Complex Instruction Set Computing) definiert die folgenden Einschränkungen für RISC-Architekturen:
- Kein Befehl darf Speicherzugriff und arithmetische oder logische Berechnungen kombinieren.
- Befehle haben alle dieselbe Länge und einen einheitlichen Aufbau. Das bedeutet oft, dass eine Speicheradresse kein Operand sein kann, weil etwa Befehle 32 Bits lang sind und damit kein Platz für eine 32-Bit-Adresse bleibt. Das macht es der CPU leichter, die aktuelle Instruktion zu dekodieren und die Adresse der jeweils nächsten Instruktion zu finden.
- Wegen der geringeren Befehlslänge fallen bei RISC in der Regel mehr Instruktionen an als bei CISC, um eine Aufgabe zu erledigen. Das bedeutet auch mehr Speicherzugriffe für das Laden der Instruktionen.
Das Rechnen mit Speicherinhalten ist bei RISC also umständlich, weil die Datentransfers separat erfolgen. Deswegen haben RISC-CPUs oft viele Standardregister, die Platz für Zwischenergebnisse bieten, was die Häufigkeit von Speicherzugriffen reduziert. RISC-Prozessoren führen Instruktionen unmittelbar aus, während CISC-CPUs die komplexeren Befehle zunächst in einfachere Mikrobefehle übersetzen, die die Maschine ausführen kann.
Abbildung 6 zeigt ein kurzes C-Programm und dessen Übersetzung in 32-Bit-Intel-Code (x86) sowie RISC-V-Code (riscv32). Bei RISC-V sind alle Befehle in 4 Bytes kodiert, bei Intel schwankt die Länge zwischen 1 Byte und 7 Bytes.
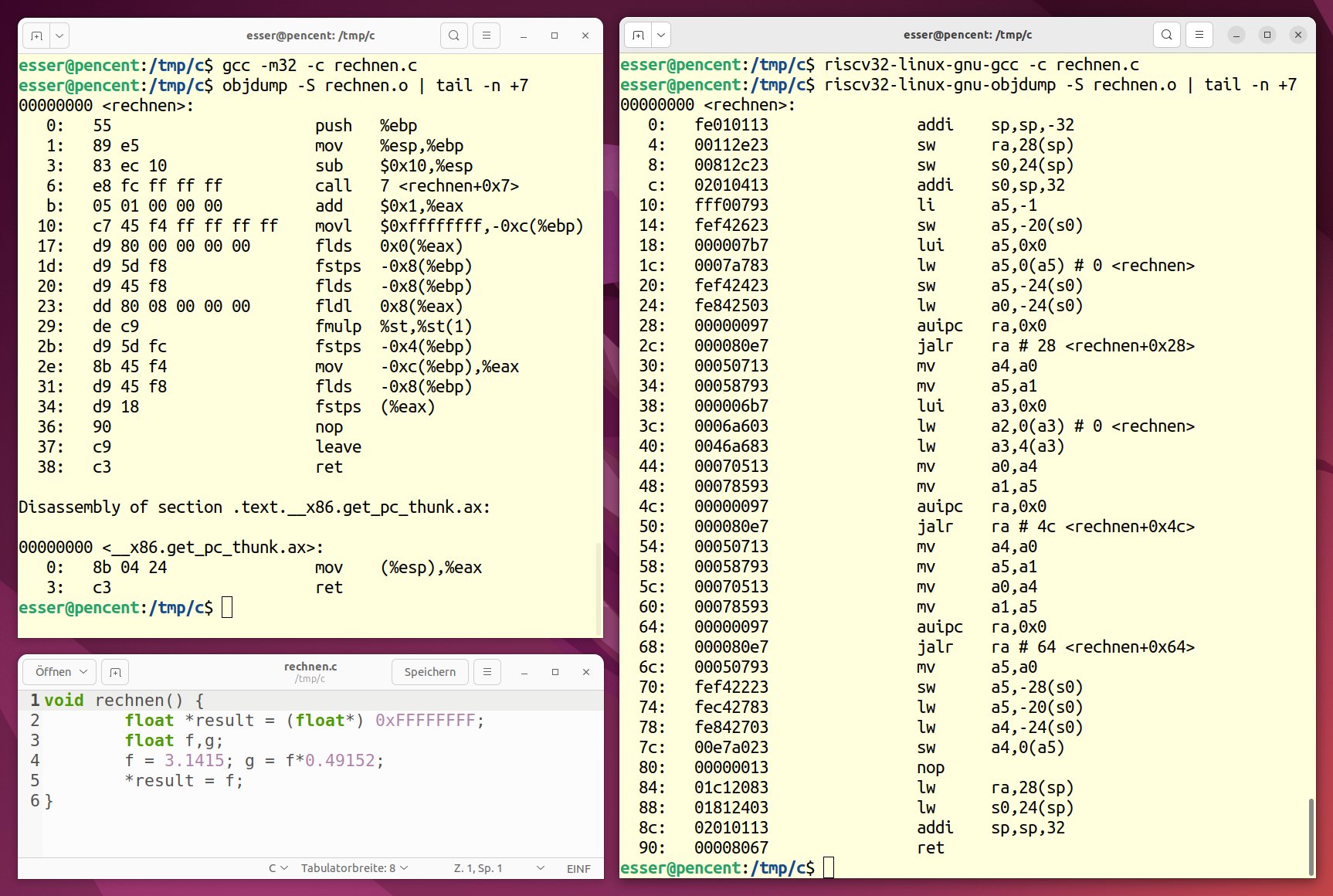
Abbildung 6: Zwei GCC-Versionen übersetzen ein Programm in x86- und riscv32- Binaries.
Weiter spannend
Während es sich bei RISC-V (schon dem Namen nach) und ARM um RISC-Architekturen handelt, gehören die Intel-Prozessoren in die CISC-Kategorie. Die Aufteilung in RISC und CISC anhand bestimmter Eigenschaften bleibt aber umstritten.
Ein interessanter Ansatz ist, die Perspektive des CPU-Entwicklers einzunehmen [10] und sich zu fragen, ob man bei freiem Platz auf dem CPU-Chip (dank fortschreitender Miniaturisierung) eher neue Funktionen für die ISA hinzufügen will, also zusätzliche Instruktionen (CISC), oder Verbesserungen für die Mikroarchitektur, also beispielsweise bessere Pipelines (RISC).
Der Wechsel von Apple zu einer selbst entwickelten RISC-Plattform (Apple Silicon, M1/M2 auf ARM-Basis) und die zunehmende Verfügbarkeit von ARM- und RISC-V-basierten SBCs sorgen dafür, dass das Thema Architekturen auch künftig interessant bleibt. (jcb/jlu)
Infos
- “Maybe we should just bite the bullet”: https://lkml.iu.edu/hypermail/linux/kernel/2210.2/07782.html
- VisionFive 2: https://www.starfivetech.com/en/site/boards
- RISC-V: https://riscv.org
- “CPU-Benchmarks lesen und verstehen”: https://www.intel.de/content/www/de/de/gaming/resources/read-cpu-benchmarks.html
- “The future of computing beyond Moore’s Law”: https://royalsocietypublishing.org/doi/full/10.1098/rsta.2019.0061
- Branch Predictor: https://en.wikipedia.org/wiki/Branch_predictor
- “Cross-Compiling GCC Toolchain for ARM Cortex-M Processors”: https://www.linkedin.com/pulse/cross-compiling-gcc-toolchain-arm-cortex-m-processors-ijaz-ahmad/
- Online-Assembler/Disassembler: https://defuse.ca/online-x86-assembler.htm
- Byte-Reihenfolge: https://de.wikipedia.org/wiki/Byte-Reihenfolge
- “RISC vs. CISC Microprocessor Philosophy in 2022”: https://itnext.io/fa871861bc94





