
© Arcadi Bulva / 123RF.com
Ansible gilt als der weitaus handlichste Automatisierer. Vielerorts haben sich allerdings Marotten eingeschlichen, die das Leben mit dem Werkzeug unnötig erschweren. Wir verraten die zehn besten Tricks und Kniffe für Ansible unter Linux.
Red Hat sagt man in der Open-Source-Community ein glückliches Händchen beim Zukauf anderer Unternehmen nach. Viele der Zukäufe führen im Konzern seither ein ausgesprochen erfolgreiches Dasein wie Ceph oder auch Qumranet, jene Firma, die KVM aus der Taufe hob. Ein weiteres Beispiel für das Geschick der roten Hüte bei ihren Einkaufstouren ist zweifelsohne Ansible, das bis heute als schlanker, leicht zu bedienender und doch hocheffizienter Automatisierer gilt.
Wer Puppet, Salt oder gar Chef mit ihrer komplizierten Syntax nicht mag, kommt bei Ansible in den Genuss echter Automation – und das in einem Format, das es fast schon mit der Schlichtheit von Shell-Skripten aufnehmen kann. Der ein oder andere mag zwar ein Weilchen brauchen, um sich das YAML-Format anzueignen. Sitzen die wenigen nötigen Basics aber erst einmal, bietet Ansible beinahe grenzenlosen Automationsspaß für die ganze (Betriebssystem-)Familie.
Allerdings ist es mit Ansible wie mit praktisch jeder anderen Software auch. Im Netz finden sich etliche Dutzend Anleitungen, die Ansible-Neulingen den Einstieg erleichtern wollen und dabei so rudimentär wie möglich vorgehen. Dagegen ist nichts einzuwenden: Wer sich in eine komplett neue Materie einarbeiten muss, ist froh um jede gedankliche Windung, auf die er nicht selbst zu kommen braucht.
Wer in Sachen Ansible irgendwann wirklich sattelfest ist, übernimmt jedoch viel zu oft Marotten aus der eigenen Ausbildungszeit, die Ansible ineffizient, komplexer oder einfach nur schwieriger zu bedienen machen, als es eigentlich notwendig wäre. Dem Programm wird die simple Bedienung hier faktisch zum Verhängnis: Wer erste Erfolge mit Ansible feiern konnte, glaubt zu oft, er wisse bereits alles darüber und hört dieser Logik folgend auf, sich weiteres Wissen anzueignen. In etlichen Unternehmen liegen dadurch weite Teile der Funktionalität des Automatisierers – und damit ein Gros seiner wirklich tollen Funktionen – praktisch brach.
Schluss damit: Dieser Artikel verrät, wie Sie Ihre Playbooks sinnvoll gestalten, an welche Regeln Sie sich dabei halten sollten und wie sich aus Ansible mehr herausholen lässt, als in der Standardanwendung möglich zu sein scheint. Zwar reichen die paar Seiten dieses Artikels nicht aus, um alle Spezialfunktionen in Ansible zu erläutern und alle Best-Practice-Regeln zu zeigen. Für einen Denkanstoß zu eigenen Erkundungstouren genügt der verfügbare Platz jedoch allemal. Starten wir also mit der Parade der zehn besten Tricks für Ansible.
Tipp 1: Ordnung
Ansible bietet verschiedene Notationsmöglichkeiten und kann Playbooks und Rollen wahlweise in einzelne Dateien oder in eine komplexe Ordnerstruktur packen. Der Reiz ist groß, die gesamte Installation für Ansible in einer einzigen Datei zu verwalten – schließlich erspart man sich damit bei Änderungen das Hangeln durch etliche Verzeichnisse. Dass dieser Ansatz auch Nachteile hat, fällt oft erst auf, wenn man vor einem Playbook mit Tausenden Zeilen sitzt und den Wald vor lauter Bäumen nicht mehr sieht. Der erste Tipp ist deshalb ganz klar: Integrieren Sie Ihre Ansible-Infrastruktur in ein Verzeichnis mit sinnvoller Ordnung. Das hilft auch dabei, einzelne Teile des Setups voneinander unabhängig zu warten und weiterzuentwickeln.
Die einzuhaltende Grundstruktur fällt denkbar simpel aus. Innerhalb eines neuen Ordners »ansible/« legen Sie zunächst die Ordner »roles/«, »group_vars/« und »host_vars/« an. Schon die Namen verraten den Zweck: In »roles/« landen selbst verfasste Ansible-Rollen, in »group_vars/« und »host_vars/« die jeweils gruppen- und Host-spezifischen Variablen des Setups. Im nächsten Schritt erstellen Sie eine Datei »hosts«, in der Sie in Cfg-Syntax alle Hosts vermerken, die zum Ansible-Setup gehören.
Schließlich fehlt noch ein Playbook, das etwa »users.yml« heißen kann. Das Playbook selbst sollte im Idealfall keine unmittelbaren Arbeitsschritte enthalten, die es auf den Hosts auszuführen gilt. Im Ausnahmefall kann man dieses Prinzip für einen einzelnen Befehl oder einen Task zwar ignorieren. Der Übersichtlichkeit zuträglicher ist es aber, für die einzelnen Aufgaben auch separate Rollen im Ordner »roles/« zu erstellen und diese anschließend per »roles:«-Direktive im »users.yml« zu referenzieren.
Auch die Verzeichnisstruktur in den Ordnern mit den Rollen spielt eine Rolle: Hier sollte es zumindest den Ordner »tasks/« mit einer Datei »main.yml« geben, der alle zu absolvierenden Arbeitsschritte enthält. Handelt es sich um viele Arbeitsschritte unterschiedlicher Art, lassen die sich auch in beliebig zu benennende Dateien schreiben, die Sie anschließend aus »main.yml« heraus per »include«-Statement einbeziehen.
Benötigen Sie Trigger für Ereignisse auf dem System nach dem Bewältigen bestimmter Schritte, vermerken Sie diese in »handlers/main.yml«. Vorgabewerte für Variablen definieren Sie in »defaults/main.yml«. Templates gehören in den Ordner »templates/«. Dateien, die es lediglich auf ein System zu kopieren gilt, liegen im Ordner »files/«.
Damit sind alle relevanten Vorkehrungen getroffen. Die beschriebene Ordnerstruktur ermöglicht es, einzelne Rollen für spezifische Aufgaben unabhängig voneinander zu verändern, und sorgt für Ordnung im Ansible-Geflecht (Abbildung 1). Zusätzlich empfiehlt es sich dringend, die dabei entstehende Ordnerstruktur in ein Git-Verzeichnis einzuchecken. So lassen sich Änderungen im Nachhinein leichter nachvollziehen.
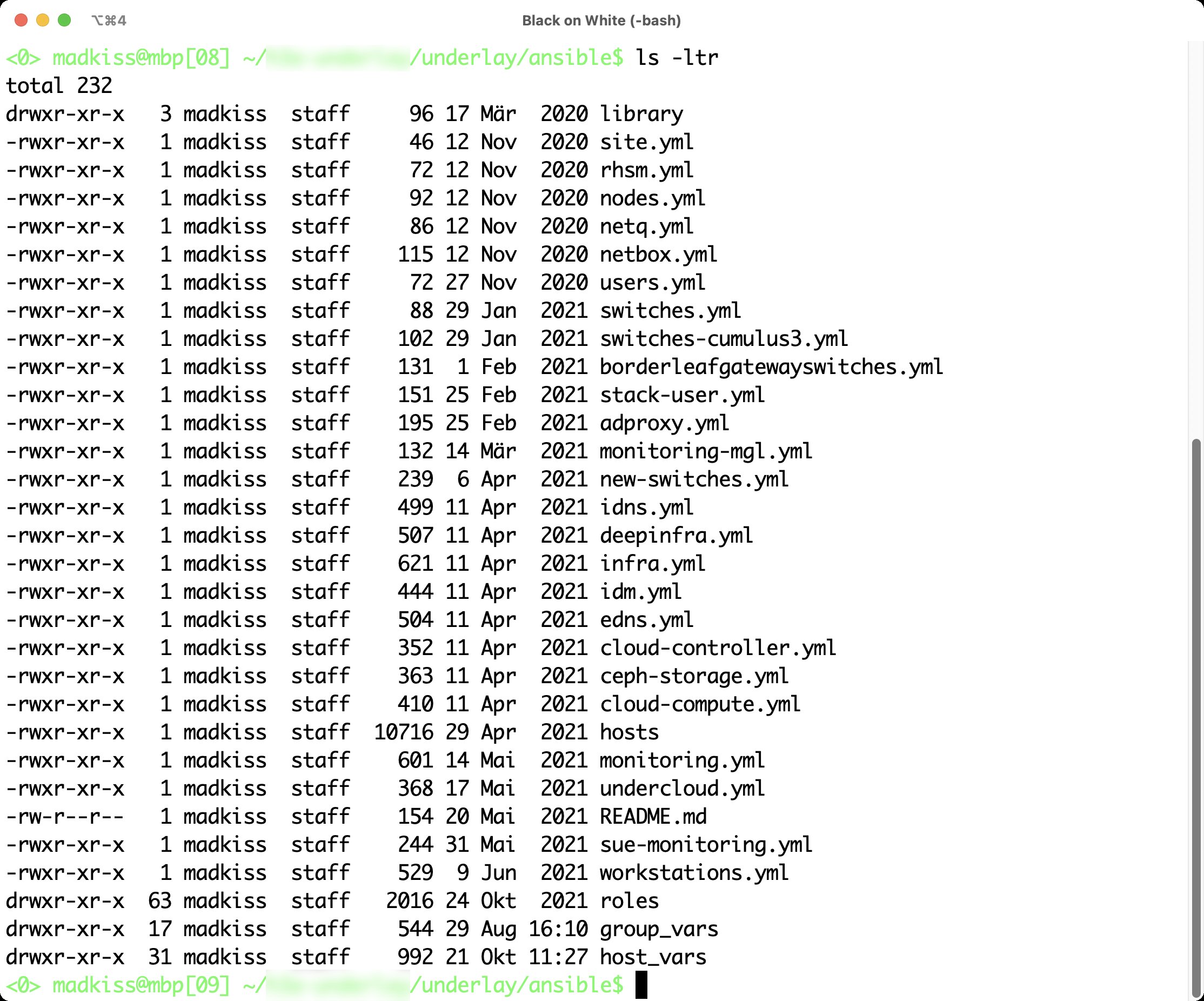
Abbildung 1: Ordnung ist das halbe Leben – das gilt auch für Ansible: Die Ordnerstruktur und die Aufteilung der Dateien sollten erlauben, Ansible sinnvoll zu nutzen. Quelle: Martin Loschwitz
Tipp 2: Namen
Vielen Ansible-Admins ist es zur Marotte geworden, den Parameter »name« beim Schreiben von Ansible-Anweisungen wegzulassen. Das mag der Tippfaulheit geschuldet sein oder einfach der Überzeugung, dass Namen für die einzelnen Anweisungen nicht zwingend nötig sind.
Letzteres stimmt sogar: Auch ein Block mit Anweisungen, der keinen definierten Namen hat, wird in Ansible zuverlässig zum gewünschten Resultat führen – zumindest dann, wenn alles klappt. Funktioniert aber einmal etwas nicht, ist der Ansible-Admin, der »name« verwendet, aber deutlich besser dran als ein Kollege, der die Namen weglässt: Kommen nirgendwo Namen zum Einsatz, dann ist der von Ansible während eines Laufs produzierte Output im Log praktisch nutzlos. Zumindest lässt er sich viel schwerer korrekt interpretieren, als es nötig wäre.
Die Devise lautet entsprechend: Schluss damit! Indem Sie den Anweisungen in Ansible jeweils einen sinnvollen deskriptiven Namen geben, erleichtern Sie sich das Debugging und schaffen quasi im Vorübergehen auch noch eine hilfreiche Dokumentation. Wie sich ein Administrator fühlt, wenn er eine Datei mit Dutzenden Ansible-Anweisungen ohne Namen öffnet, bei denen auch noch jeder Kommentar fehlt, kann sich jeder sturmerprobte Sysadmin leicht ausmalen.
Dieser Punkt ist aber keinesfalls als Plädoyer gegen Variablen zu verstehen, ganz im Gegenteil: Es hat sich als praktisch erwiesen, den Code und die Konfiguration in Ansible so weit wie möglich voneinander zu trennen. Die Rollen und Playbooks nutzen dann nur noch (idealerweise sinnvoll benannte) Variablen, die für jeden einzelnen Host dann in dessen spezifischen Variablen definiert sind.
Tipp 3: Logging
Apropos Logging: Ansible kommt ab Werk bekanntlich mit einem Standard-Logger für die Kommandozeile. Der funktioniert grundsätzlich gut, ist manchmal aber etwas geschwätzig. Speziell nach einem Durchlauf vieler Ansible-Anweisungen gleicht das Terminalfenster dann eher moderner Kunst (Abbildung 2). So kann es durchaus passieren, dass ein Ansible-Fehler so weit aus dem Fenster scrollt, dass er im Puffer des Terminals gar nicht mehr vorkommt und so für die Augen des Administrators für immer verloren ist.
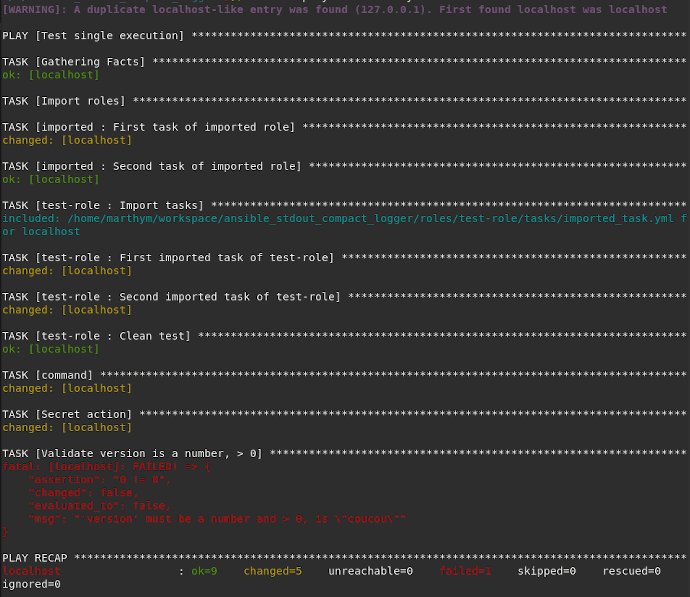
Abbildung 2: Diese Form der Ansible-Ausgabe dürften die meisten Administratoren kennen – viel Farbe und viel Whitespace, aber insgesamt eher wenig Information. Quelle: Pierre Baillet
Was vielen Ansible-Nutzern gar nicht klar ist: So wie Ansible sich per »library« um neue Funktionen erweitern lässt, kann man es auch um neue Ausgabemodule für die Shell erweitern. Der Entwickler des Stdout Compact Loggers [1] für Ansible macht sich genau das zunutze. Dieses Ausgabemodul legen Sie am besten innerhalb Ihres Ansible-Ordners ab, beispielsweise im Unterordner »callbacks/«. In der Ansible-Konfiguration »ansible.cfg« erweitern Sie anschließend den Parameter »callback_plugins« so, dass er auf den Ordner zeigt, in dem sich die zusätzlichen Module befinden.
Im konkreten Fall genügt es, ebenfalls in der Ansible-Konfigurationsdatei den Parameter »stdout_callback« auf »anstomlog« zu setzen. Der nächste Aufruf von Ansible bringt ein deutlich kompakteres Protokoll auf den Schirm, das weniger Platz auf dem Desktop verschwendet, dafür aber deutlich mehr Informationen liefert (Abbildung 3). So fügt das Plugin für jede Meldung eine Uhrzeit ein, anhand derer sich zeitliche Ereignisse viel besser nachvollziehen lassen.
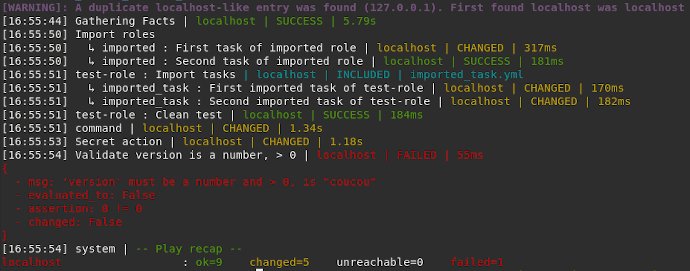
Abbildung 3: Statt mit viel blankem Bildschirm wartet der Compact Logger mit einer nützlichen, gegenüber dem Standard um viele Details angereicherten Ausgabe auf. Quelle: Pierre Baillet
Tipp 4: YAML
Sind Sie bis hierher den Vorgaben dieses Artikels gefolgt, nutzen Sie bereits eine Ordnerstruktur, die sämtlichen Anforderungen des Alltags gewachsen ist. Wie schade wäre es, diese durch ein Kuddelmuddel in den Playbooks und den selbst verfassten Rollen gleich wieder zu ruinieren? Eigenartigerweise tappen viele Ansible-Administratoren in genau diese Falle. Statt sich entweder an die Ansible-native Syntax zu halten (Listing 1) oder die YAML-Syntax (Listing 2) zu verwenden, mischen sie in ihren Playbooks wild Schritte in beiden Notationen.
Gut, das kann schon einmal passieren, wenn die Zeit drängt und man die Lösung für ein dringendes Problem per Copy & Paste aus dem Internet übernimmt. Dadurch finden sich Mixturen beider Stile vielerorts gar innerhalb der gleichen Dateien. Ideal ist das aber keinesfalls – und Sie tun gut daran, sich auf eine Syntax festzulegen. Im Idealfall entscheiden Sie sich für YAML, denn es macht Ansible-Anweisungen deutlich besser strukturiert und übersichtlicher.
Listing 1
Ansible-Notation
- name: add user testuser1 user: name=testuser1 state=present groups=wheel
Listing 2
YAML-Notation
- name: add user linuxmagazin
user:
name: testuser1
state: present
groups: wheel
Tipp 5: Variablen
Wohl jeder Administrator kennt das Problem: Ein Ansible-Playbook, das vor Jahren ein im Unternehmen schon längst nicht mehr tätiger Mitarbeiter verfasst hat, benötigt ein Update. Der Kollege hat seinerzeit ausgiebigen Gebrauch von Variablen gemacht. Schade nur, dass er sie nicht auch dokumentiert hat. Denn dann wüsste auch der Nachfolger im Amt, dass die Variable »mgmt_cws1_n7p1« den ersten Port der ersten Netzwerkkarte in der ersten Cluster-Workstation (vulgo Jumphost) des Managementnetzwerks beschreibt. Bei guter Dokumentation verstünde der neue Admin vielleicht sogar, dass die Zählung die Bezeichnungen der Netzwerkkarten des Systems übernimmt und dass somit das Pendant zu »n7p1« auf der Workstation »ens7f0« ist und im Rechner eben nicht sieben Netzwerkkarten stecken.
Hätte, hätte, Fahrradkette: Die Realität der meisten Ansible-Setups in freier Wildbahn sieht eher so aus, dass Variablen und insbesondere deren Namen vollständig undokumentiert sind. Das stellt ein riesiges Problem dar und bietet völlig unnötiges Potenzial für Ärger. Jedem Verfasser von Anweisungen für Ansible sei deshalb dringend ans Herz gelegt, Variablen wie beschrieben in den Ansible-Anweisungen zentral zu definieren und mit sinnvollen Standardwerten zu versehen. Zudem sollte man sie in jedem einzelnen Fall mit einer kurzen Erläuterung versehen, sofern sich Art und Funktion der Variable nicht absolut zuverlässig von selbst ergeben.
Die Hürden für das letztgenannte Kriterium liegen ausgesprochen hoch. Selbst eine Variable »root_pw« ermöglicht ohne weitere Lektüre des Ansible-Quelltexts nur bedingt Rückschlüsse auf ihre Funktion. Handelt es sich um das Root-Passwort eines Systems, das eines Containers oder um das Kennwort von root in MariaDB? Fragen über Fragen, zu denen der Ansible-Admin die Antworten besser in Form von Kommentaren liefert, statt sie schuldig zu bleiben.
Tipp 6: Gemeinsam
Mancherorts entwickeln Administratoren Ansible-Anweisungen im festen Glauben, außer ihnen sei ohnehin niemals jemand anderes im Unternehmen gezwungen, Ansible aufzurufen. Dann kommt der Skiurlaub inklusive schwerem Unfall, ein Sabbatical oder irgendein anderes Ereignis, das die wochenlange Abwesenheit des Admins verursacht. Dann sitzt zu guter Letzt doch ein armer Tropf vor der Installation und soll “mal eben eine Kleinigkeit” anpassen, weil es im produktiven Einsatz zu einem Problem gekommen ist.
Wollen Sie sichergehen, dass beispielsweise Variablen in Ihren Playbooks nicht mit ungültigen Werten gefüttert werden, führen Sie dafür idealerweise Tests ein. Die Betonung liegt dabei auf ungültig: Was für Ansible syntaktisch korrekt ist, muss als Wert einer Variablen in einer Konfigurationsdatei für einen Dienst noch lange nicht funktionieren.
Die Funktion zum Prüfen von Variableninhalten heißt »assert«, Listing 3 zeigt ein Beispiel dafür. Enthält die Variable »version« nicht eine Zahl, die größer als 0 ist, führt die »assert«-Anweisung dazu, dass Ansible abbricht. Idealerweise gehört eine solche Direktive freilich in den Code, bevor weitere Aufgaben wie das Ausrollen einer Konfigurationsdatei stattfinden.
Listing 3
assert-Beispiel
- name: "Validate version is a number, > 0"
assert:
that:
- "{{ version | int }} > 0"
msg: "'version' must be a number and > 0, is \"{{version}}\""
Tipp 7: Konfiguration
Vor allem passionierte Systemadministratoren sind es gewohnt, dass es für zentrale Dienste exakt eine Konfigurationsdatei gibt. Das Prinzip übertragen sie unbewusst auf Ansible, wenn sie ihre Arbeit damit beginnen. Daher nehmen sie an, es gäbe nur eine »/etc/ansible/ansible.cfg«, die für alle Ansible-Aufrufe auf dem System die Konfiguration festlegt. Dass das so nicht ganz stimmen kann, hat dieser Artikel bereits belegt: Zum Austauschen der Logging-Komponente ist ja eine »ansible.cfg« entstanden, die im Ordner des »ansible«-Aufrufs liegt. Dort wird der Automatisierer sie zuverlässig beachten.
Der dringende Appell lautet daher: Möchten Sie das Verhalten von Ansible beeinflussen, nutzen Sie am besten die verfügbaren Möglichkeiten, das über »ansible.cfg« zu tun. Außer in dem Ordner, aus dem heraus ein Ansible-Aufruf erfolgt, sucht das Werkzeug unter anderem auch in »~/.ansible.cfg« nach Konfigurationsparametern. Beherzigen Sie diesen Rat nicht, wird es schnell unangenehm.
In freier Wildbahn begegnen einem bisweilen Playbooks und Rollen mit aufgeblähtem Code, die Unzulänglichkeiten in der Ansible-Konfiguration umgehen sollen. Das Argument, das sei dann wenigstens systemunabhängig und funktioniere überall gleichermaßen, zieht wie beschrieben nicht: Ebenso leicht ließe sich eine lokale »ansible.cfg« ausliefern.
Tipp 8: Nachnutzbarer Code
Im Umgang mit Ansible tritt regelmäßig das Problem auf, dass es Rollen oder Playbooks für spezielle Dienste nicht in Ansible selbst gibt. Wollen Sie beispielsweise PowerDNS ausrollen, finden Sie in Ansible ab Werk dafür zunächst keine Vorbereitung. Unerfahrene Administratoren greifen in dieser Situation zu eher radikalen Maßnahmen und beginnen, selbst eine Rolle für das Deployment des Diensts zu schreiben.
An Begründungen für diesen fragwürdigen Schritt mangelt es erfahrungsgemäß nicht. Oft hört man, eine Rolle für das eigene Unternehmen sei schließlich maßgeschneidert und perfekt an die Bedingungen vor Ort angepasst. Hier spielt vielen Administratoren wohl das deutsche Mantra der maßgeschneiderten IT-Lösung einen Streich. Damit gehen Vertriebler hierzulande seit Dekaden auf Kundenfang, nur um ihren Kunden am Ende doch wieder Lösungen von der Stange anzudrehen – im günstigsten Fall. Im ungünstigsten Fall verstricken sie die Kundschaft im Rahmen solcher Projekte tatsächlich in teure, langwierige Entwicklungsaufträge, die oft genug in einem gleißenden Feuerball enden. Was solche fehlgeschlagenen Projekte im Großen sind, das ist im Kleinen der Versuch, das Rad im Hinblick auf Ansible für einzelne Programme neu zu erfinden.
Bald schon stellt der ausführende Administrator nämlich frustriert fest, dass es gar nicht so simpel ist, automatisiert ein PowerDNS auszurollen. Je nach Zielsystem und Distributionsversion müssen verschiedene Pakete mit unterschiedlichen Konfigurationen installiert werden. Dafür müssen in Ansible entsprechende Schalter existieren. Der Automatisierer selbst beherrscht das problemlos, eine If-Direktive kennt das Werkzeug schließlich. Mittels etlicher Variablen aus dem Ansible-Inventar lässt sich problemlos feststellen, welches OS in welcher Version vorliegt. Ähnlich funktioniert das Spiel, wenn es um unterschiedliche Templates geht, die es mit Inhalt zu befüllen gilt.
Doch hier hören die Probleme noch lange nicht auf: Je nach benötigtem Dienst sind verschiedene Arbeitsschritte in spezifischer Reihenfolge abzuarbeiten, möglicherweise über die Grenzen eines Systems hinweg. Das muss man implementieren, testen und möglicherweise auch debuggen. Arbeiten an der Entwicklung nur ein Admin oder lediglich eine kleine Gruppe von Admins, zieht sich die Entwicklung einer entsprechenden Ansible-Rolle im schlimmsten Fall wie ranziger Strudelteig.
Daher gilt: Suchen Sie eine Ansible-Rolle für ein spezifisches Programm, sehen Sie zunächst in Verzeichnissen wie Github oder der Ansible Galaxy nach, ob es die jeweilige Lösung nicht bereits gibt. Die hat dann zwar möglicherweise viel Code im Gepäck, den Sie für das lokale System gar nicht benötigen. Dafür ist sie aber getestet, durch die Open-Source-Gemeinde kuratiert und meist voll funktionsfähig.
Tipp 9: Verschlüsselung
Man mag es kaum glauben, doch auch 2023 finden sich noch Ansible-Implementierungen, die Passwörter im Klartext verzeichnen. Das kann nun wirklich nicht der Ernst der involvierten Administratoren sein: Einerseits wird es auf diese Weise nämlich faktisch unmöglich, die Ansible-Infrastruktur in einem (öffentlich zugänglichen) Git-Verzeichnis zu warten – schließlich will niemand seine Passwörter für interne Dienste im Internet lesen. Andererseits sollte es ohnehin völlig inakzeptabel sein, in Dateien auf dem System überhaupt noch Passwörter im Klartext zu nutzen.
Tatsächlich stellt Ansible in Form von »ansible-vault« ein Werkzeug zur Verfügung, mit dem das Problem sich elegant umgehen lässt (Abbildung 4). Das zu Ansible gehörende Vault ist dabei nicht mit dem Namensvetter von HashiCorp zu verwechseln. Möchten Sie ihn lieber mit Ansible einsetzen, haben Sie aber durchaus die Möglichkeit dazu: Über die Ansible-Funktion »hashi_vault« lassen sich Passwörter aus HashiCorp Vault auslesen.
Abbildung 4: Ansible Vault bietet eine komfortable Möglichkeit, Passwörter innerhalb des Automatisierers zuverlässig und sicher zu verwalten. Quelle: Martin Loschwitz
Tipp 10: Ausblick
Schließlich sei noch auf einen Umstand hingewiesen, den mancher fleißige Ansible-Nutzer selbst nach Jahren noch nicht kennt: Ansible eignet sich ganz hervorragend dazu, Workloads in virtuellen Umgebungen, in privaten Cloud-Umgebungen und bei den großen Hyperscalern zu steuern, anzulegen und zu löschen. Dabei beschränkt das Werkzeug sich keinesfalls nur auf virtuelle Instanzen. Über Erweiterungskits für Azure, AWS sowie GCP unterstützt Ansible etwa das Anlegen der allermeisten Ressourcen, die diese drei Plattformen anbieten.
So ist es problemlos möglich, ein Ansible-Playbook zu erstellen, das in Azure erst ein VPC samt entsprechender Security Groups erstellt und anschließend eine EC2-Instanz mit angehängtem Volume startet. Die Idempotenz, die bei Ansible zentrales Design-Element ist, funktioniert auch hier: Läuft die genannte Instanz bereits und der Administrator lässt das Playbook ein weiteres Mal laufen, prüft Ansible lediglich den Zustand und tut, falls alles passt, gar nichts.
Damit ist Ansible vor allem für jene eine interessante Option, die für das Verwalten von Cloud-Workloads lieber die ihnen bekannten Werkzeuge nutzen möchten als externe Tools einzusetzen. Im Zweifelsfall müssen Sie hier aber prüfen, ob Ansible wirklich alle von Ihnen benötigten Funktionen unterstützt. Auf den Betrieb hybrider Workloads in skalierbaren Umgebungen spezialisierte Werkzeuge haben üblicherweise auch Features an Bord, um beispielsweise Netzwerke zwischen den Plattformen zu erstellen – etwa Morpheus (Abbildung 5). Das klappt mit Ansible zwar letztlich auch, spezialisierte Werkzeuge bieten dabei allerdings mehr Komfort.
Abbildung 5: Ansible kann auch Workloads in öffentlichen Clouds verwalten. Für den Betrieb komplexer hybrider Setups eignen sich Werkzeuge wie Morpheus allerdings besser. Quelle: Morpheus
Fazit
Hinter einer relativ einfach gestalteten Benutzerschnittstelle versteckt Ansible eine Menge praktischer Funktionalität. Deren tatsächlicher Umfang ist selbst vielen passionierten Ansible-Anwendern aber oft gar nicht klar. Das führt im Alltag zu weit vom Idealzustand entfernten Ansible-Setups, die an vielen Stellen mehr Aufwand verursachen als nötig.
Beherzigen Sie die in diesem Artikel beschriebenen Grundsätze, dann verwalten Sie Ihre gesamte Ansible-Umgebung ohne Schwierigkeiten in einem Git-Verzeichnis. Das erleichtert die Anwendung des Prinzips Infrastructure as Code (IaC) erheblich. Obendrein bietet Ansible für externe Dienste wie Azure, AWS oder GCP mehr als nur grundlegende Unterstützung. Für viele Setups dürfte das Programm daher ausreichen, um die Automatisierung und – bis zu einem gewissen Grad – auch die Orchestrierung vollständig abzudecken.
Das gilt umso mehr, weil Ansible mittlerweile eine große Verbreitung erreicht hat. Dritthersteller und auch die rege Community offerieren entsprechend viele Module, Rollen und Playbooks, um die allermeisten gängigen Werkzeuge zu steuern. (jcb)
Infos
- Ansible Compact Logger: https://github.com/octplane/ansible_stdout_compact_logger





