
© Kheng Ho Toh / 123RF.com
Um bestehende Forschung verstehen zu können, sie zu reproduzieren und darauf aufzubauen oder um sich neuer Forschung effektiv zu widmen, muss die verwendete Software nachhaltig sein. Was bedeutet das, und wie erreicht man es?
Software ist heute in fast allen Disziplinen ein fester Bestandteil der Forschungsarbeit. Zu den typischen Anwendungsgebieten zählen die Simulation, das Generieren, Verarbeiten, Analysieren und Visualisieren von Daten sowie insbesondere in den Natur- und Ingenieurwissenschaften das Steuern von Experimenten. Wird für diesen Zweck im Rahmen der Forschung Software entwickelt, spricht man von Forschungssoftware.
Solche Software hat erheblichen Einfluss auf die Forschungsergebnisse. Sie ermöglicht eine kritische Prüfung beziehungsweise Reproduktion der gewonnenen Resultate durch Dritte sowie den Transfer in einen neuen oder breiteren Kontext. Software ist somit zu einem zentralen Gut in der Forschung geworden. Sie optimiert bestehende und ermöglicht neue Forschungsmethoden, implementiert und bettet Wissen ein und stellt selbst ein wesentliches Forschungsprodukt dar.
Für eine gute wissenschaftliche Praxis sollte die entstehende Forschungssoftware Open Source sein, so wie es sich im Linux-Umfeld bewährt hat. Etablierte Open-Source-Lizenzen bieten ausreichende Lizenzierungsmöglichkeiten, sodass es die seltene Ausnahme sein sollte, Forschungssoftware geschlossen zu halten.
Was ist Forschungssoftware?
Forschungssoftware ist Software, die im wissenschaftlichen Erkenntnisprozess eingesetzt wird, zum Beispiel in den Naturwissenschaften für Klimasimulationen. Dabei steht der Begriff Software für die Gesamtheit der Programme, Verfahren und Routinen für den Betrieb eines Computersystems [1]. Somit umfasst Forschungssoftware Quellcodedateien, Algorithmen, Skripte, Berechnungsabläufe und ausführbare Dateien, die während des Forschungsprozesses oder für einen Forschungszweck erstellt wurden.
Softwarekomponenten wie Betriebssysteme, Programmiersprachen, Bibliotheken und so weiter, die für die Forschung verwendet werden, aber nicht mit einer klaren Forschungsabsicht erstellt wurden, sollten als Software in der Forschung und nicht als Forschungssoftware betrachtet werden [2]. Beispielsweise kommt in der Forschung häufig Microsoft Excel zum Einsatz, bei dem es sich nicht um Forschungssoftware handelt, da es nicht mit einer klaren Forschungsabsicht erstellt wurde.
Nachhaltigkeit
Der Begriff Nachhaltigkeit bezieht sich bei Software zumeist auf den Energieverbrauch. Im Kontext von Forschungssoftware geht es jedoch um etwas anderes, nämlich darum, diese Software möglichst lange weiterentwickeln und wiederverwenden zu können. Daneben ist hier die Reproduzierbarkeit von Ergebnissen wichtig. Nachhaltigkeit bedeutet in diesem Zusammenhang, dass die Forschungssoftware, die wir heute verwenden, in Zukunft weiter verfügbar bleibt und weiter verbessert sowie unterstützt wird. Mit anderen Worten: Forschungssoftware sollte sowohl jetzt als auch in Zukunft verfügbar, auffindbar, nutzbar und an neue Anforderungen anpassbar sein. Sie benötigt daher eine Umgebung, die Nachhaltigkeit unterstützt.
Vielfach wird in der Forschung bisher zu wenig getan um sicherzustellen, dass die Nutzung der Software über ein einzelnes Projekt hinaus überhaupt möglich ist (Fit for Reuse) oder gar eine unabhängige Qualitätssicherung (Fit for Purpose) sichergestellt werden kann. Trotz der zunehmenden Bedeutung von Forschungssoftware für den wissenschaftlichen Entdeckungsprozess kommen etablierte Softwareentwicklungspraktiken bisher selten in der Wissenschaft zur Anwendung [3]. Forschungssoftware sollte zudem offen [4] und FAIR [5] sein. FAIR (Findable, Accessible, Interoperable, Reusable [6]) zielt auf die Verfügbarkeit, Reproduzierbarkeit und Wiederverwendbarkeit von Forschungsergebnissen ab.
Institutionelle Unterstützung
In Großbritannien gibt es bereits seit 2010 das Software Sustainability Institute [7]. Es hat seinen Sitz an den Universitäten von Edinburgh, Manchester, Oxford und Southampton und stützt sich auf ein spezialisiertes Team mit umfassender Erfahrung in den Bereichen Softwareentwicklung, Schulung, Projekt- und Programmmanagement, Forschungsförderung, Öffentlichkeitsarbeit und gesellschaftliches Engagement (Abbildung 1).

Abbildung 1: Das Motto des Software Sustainability Institute.
Bereits seit 25 Jahren bietet die Software Carpentry Initiative [8] Workshops und Kurse an, um grundlegende Softwareentwicklungskompetenzen in die Wissenschaft zu tragen. Während das Software Sustainability Institute und die Software Carpentry Initiative Unterstützung bei der Entwicklung nachhaltiger Forschungssoftware bieten, ist es das Anliegen der Society of Research Software Engineering [9], das Berufsbild der Entwicklerinnen und Entwickler von Forschungssoftware (Research Software Engineer) zu etablieren.
Auch in Deutschland gibt es seit 2019 die Gesellschaft für Forschungssoftware [10], die es sich zum Ziel gesetzt hat, die Bedeutung der Softwareentwicklung im Forschungsprozess angemessen zu würdigen. Die Herausforderungen bestehen unter anderem in einer fehlenden Anerkennung für Softwareentwicklung als wissenschaftliche Leistung sowie der fehlenden Verankerung im wissenschaftlichen Reputationssystem. Als weitere Probleme kommen die eingeschränkte Verfügbarkeit und Nutzbarkeit wissenschaftlicher Software, Mehrfach- und Parallelentwicklungen, häufig ungenügende Kompetenzen im Software Engineering sowie fehlenden Qualitätsstandards für die Entwicklung und Begutachtung wissenschaftlicher Software hinzu.
Wissenschaftliches Rechnen (Scientific Computing oder Computational Science) umfasst die Entwicklung von Forschungssoftware für Modellsimulationen und Datenanalysen, um reale Systeme zu verstehen und Fragen zu beantworten, wenn dafür weder Theorie noch Experiment allein ausreichen. Wissenschaftliches Rechnen befasst sich mit dem Einsatz von Software zur Lösung wissenschaftlicher Probleme, Gegenstand der Informatikforschung ist der Entwurf von Hardware, Algorithmen und Softwaresystemen.
Open Source ist etabliert
Forschungssoftware als Open Source zu veröffentlichen, ist eine etablierte Praxis in der Wissenschaft. Eine beliebte Open-Source-Plattform dafür ist Github. Um den aktuellen Stand der Veröffentlichung von Forschungssoftware zu analysieren, haben wir deren Veröffentlichung sowie die Beziehung zwischen Forschungssoftware und Forschungspublikationen studiert [4]. Für diese Analyse wird Forschungssoftware entweder durch Veröffentlichungen identifiziert, die Software-Repositories zitieren, oder durch Software-Repos, die Publikationen zitieren. Forschungssoftware wurde in unserer Studie somit anhand einer Kombination aus Metadaten von Forschungspublikationen und Software-Repositories analysiert.
Eine erste interessante Beobachtung: Die analysierten Datensätze decken recht unterschiedliche Bereiche ab. In Github-Repositories zitierte Veröffentlichungen stammen hauptsächlich aus dem wissenschaftlichen Rechnen, insbesondere den Lebenswissenschaften (Abbildung 2). Bei den Informatikveröffentlichungen, die Github-Repositories zitieren, dominieren die Themen Software Engineering, Informationssysteme und Human-Centered Computing (Abbildung 3).
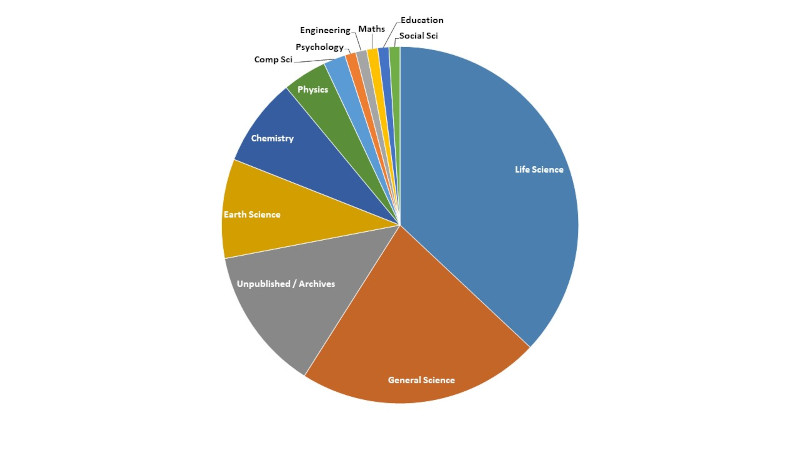
Abbildung 2: Die Forschungsbereiche von Veröffentlichungen, die in Github-Repositories zitiert werden.
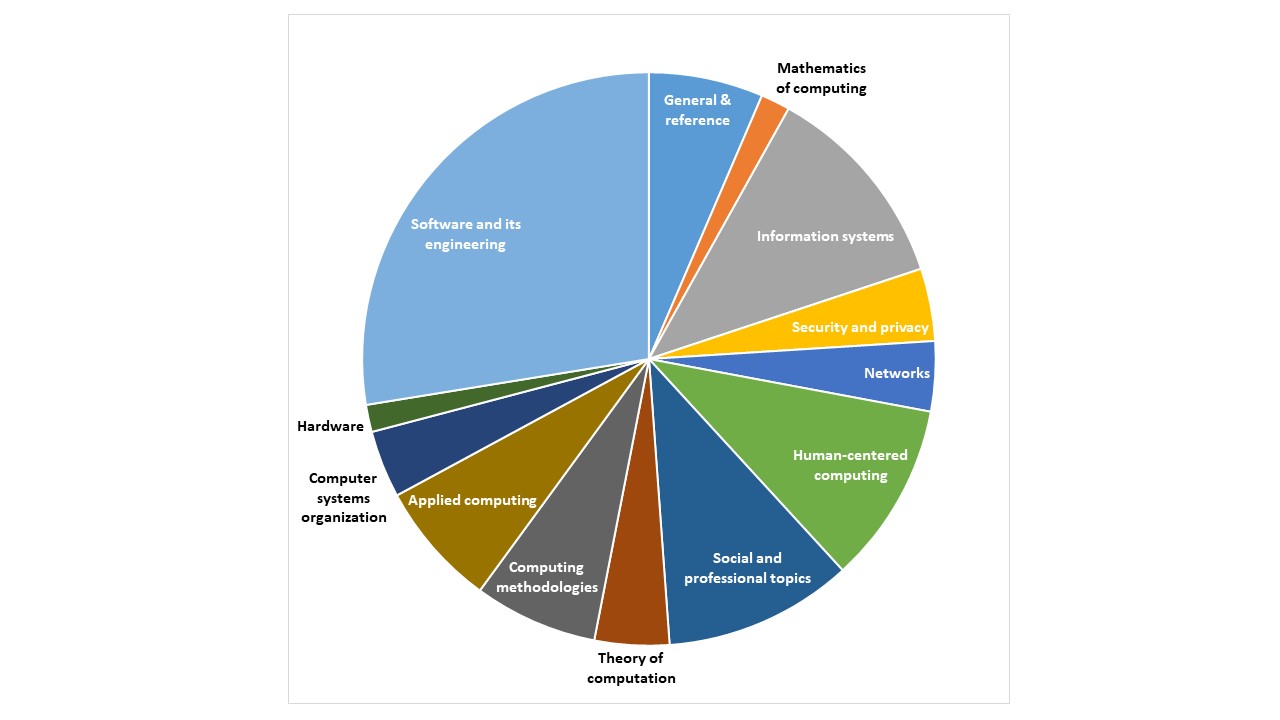
Abbildung 3: Forschungsbereiche der Informatikpublikationen mit Zitierung von Github-Repositories.
Nachhaltigkeit
Für diese Studie betrachten wir Forschungssoftware als nachhaltig, wenn sie eine längere Lebensdauer hat und noch aktiv weiterentwickelt wird. Die Lebensdauer eines Software-Repositories umfasst die Zeitspanne zwischen seiner ersten und seiner letzten Commit-Aktivität. Um die Nachhaltigkeit von Forschungssoftware zu analysieren, unterteilen wir die Repositories in lebendige (live) und ruhende (dormant) Repos. Wir betrachten ein Repository als ruhend, sobald es mindestens ein Jahr lang keine Commit-Aktivität gab.
Wie bereits erwähnt, beschäftigen sich in Github-Repositories zitierte Veröffentlichungen hauptsächlich mit dem wissenschaftlichen Rechnen. Hier kann man eine gleichmäßige Aufteilung zwischen lebendigen und ruhenden Software-Repositories beobachten. Dasselbe gilt für Veröffentlichungen aus der Informatik. Allerdings haben Informatik-Repositories eine erheblich längere Lebensdauer als jene rund um das wissenschaftliche Rechnen. Die Lebensdauer der Informatik-Repositories ist mit einem Median von 5 Jahren verteilt (Abbildung 4). In der Informatikforschung kommen häufig kommerzielle Open-Source-Frameworks zum Einsatz, die auch durch Mitarbeiter der involvierten Unternehmen gepflegt werden.
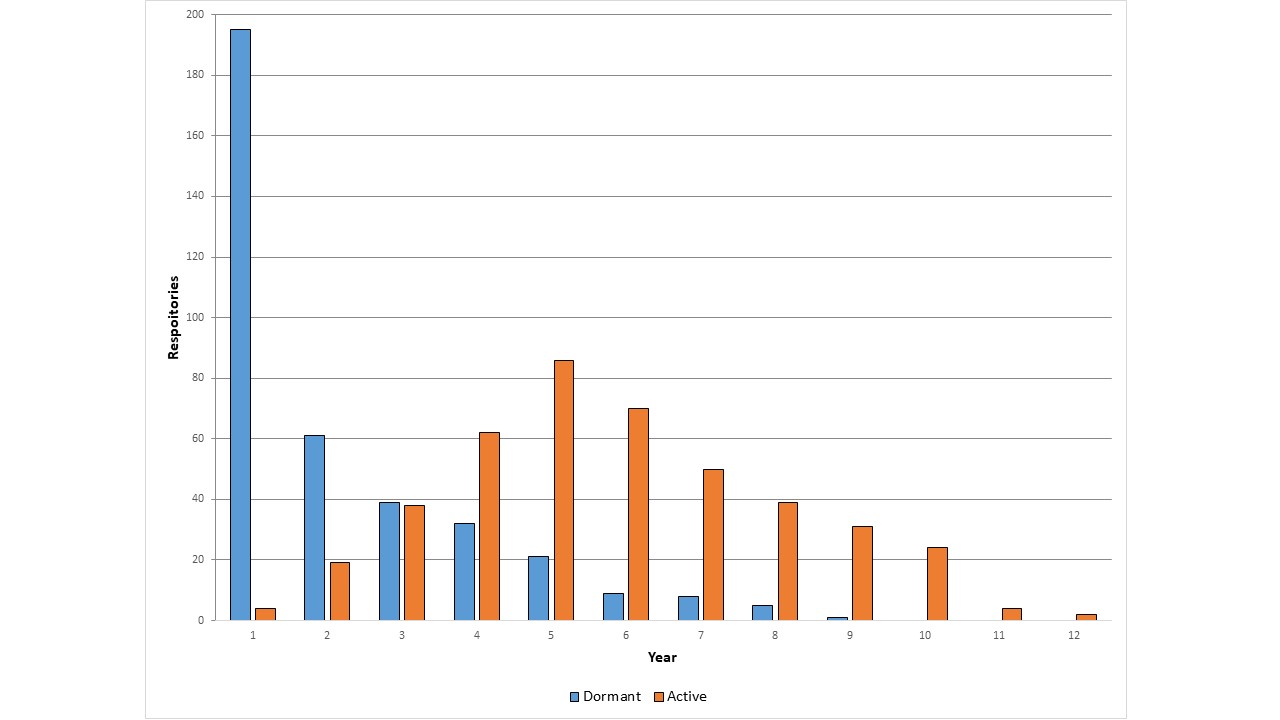
Abbildung 4: Lebensdauer von Github-Repositories, die in Informatikveröffentlichungen zitiert werden.
Die Lebensdauer der Software-Repos im wissenschaftlichen Rechnen hat eine Verteilung mit einer mittleren Lebensdauer von nur 15 Tagen, ein Drittel dieser Repositories bleibt weniger als einen Tag aktiv. (Abbildung 5). Es steht zu vermuten, dass im wissenschaftlichen Rechnen die Forschungssoftware oft erst nach dem Erscheinen der entsprechenden Publikation veröffentlicht wird. Die Weiterentwicklung der Software findet dann nicht auf Github statt, sondern – sofern überhaupt – wie bisher an irgendeiner privaten Stelle.
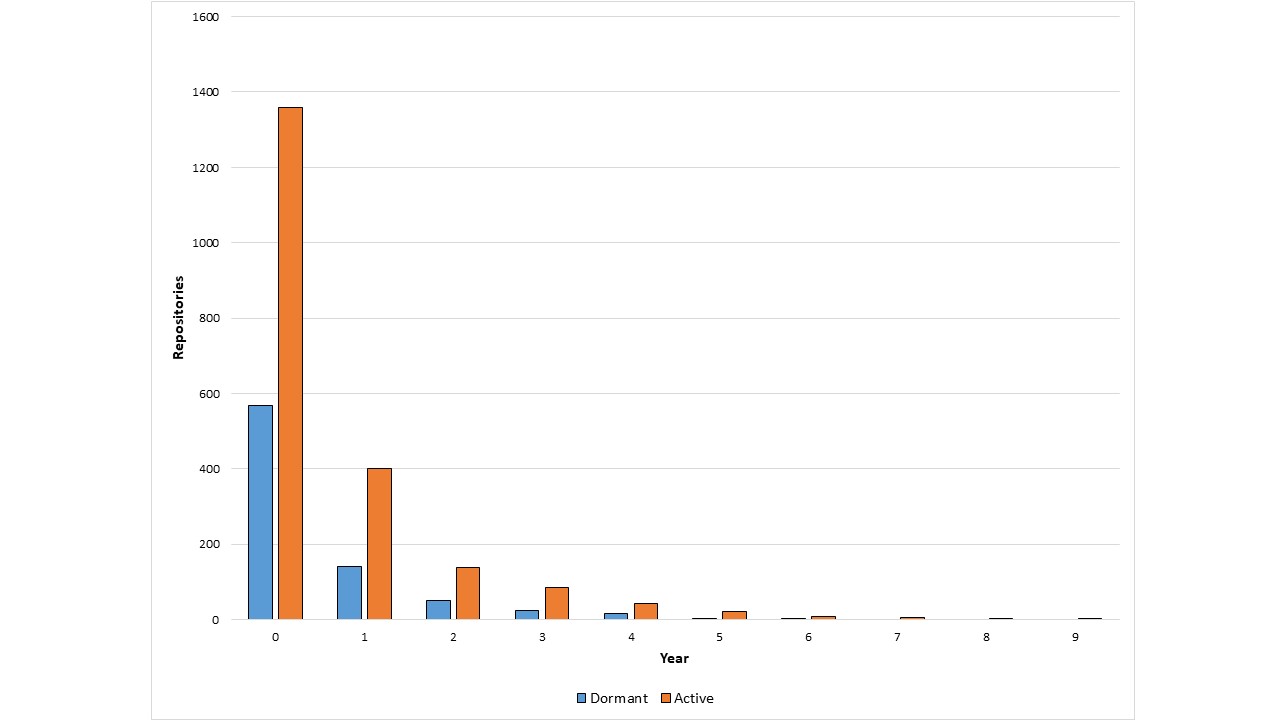
Abbildung 5: Die Lebensdauer von Github-Repos, die Veröffentlichungen aus dem wissenschaftlichen Rechnen zitieren.
Archivierung
Im Gegensatz zu Forschungsdaten sollte Forschungssoftware sowohl für die Reproduzierbarkeit archiviert als auch für die Wiederverwendbarkeit aktiv gewartet werden. Das lässt sich gut durch die Kombination von Zenodo.org (für Archivierung und Reproduzierbarkeit) und Github.com (für Wartung und Wiederverwendung) erreichen.
Für die gute wissenschaftliche Praxis sollte man Softwareartefakte unter Berücksichtigung der Reproduzierbarkeit und der nachhaltigen Weiterentwicklung veröffentlichen. Github unterstützt nicht direkt die Langzeitarchivierung von Softwareversionen, die verwendet wurden, um bestimmte Forschungsergebnisse zu erzielen. Das lässt sich beispielsweise auffangen, indem man zunächst einen Schnappschuss von Github erstellt und ihn dann auf Zenodo.org archiviert [11]. Github dient dabei der Nutzung, Wiederverwendung und aktiven Beteiligung von Forschern, während Zenodo die Archivierung und Reproduzierbarkeit veröffentlichter Ergebnisse sicherstellt. Die Reproduzierbarkeit und Wiederverwendbarkeit von Forschungssoftware erfordert daher spezifische Lösungsansätze.
Ein bei Zenodo archivierter Snapshot kann bei der Reproduktion eines veröffentlichten Ergebnisses helfen, repräsentiert aber nur den aktuellen Stand einer möglicherweise veralteten Softwareversion. Versionskontrollsysteme wie Git, für das Github als Entwicklungsplattform dient, ermöglichen das Tagging von Releases. Mit solchen Tags lassen sich bestimmte Release-Versionen der Software identifizieren, was die Reproduzierbarkeit bestimmter Forschungsergebnisse unterstützen kann.
Das Software Heritage Archive bietet eine weitere Option für die Softwarearchivierung [12]. Es gilt jedoch zu berücksichtigen, dass das langfristige Aufbewahren von Software schwierig und teuer ist. Softwarevirtualisierungstechniken wie Docker-Container und Online-Dienste unterstützen die Portabilität und damit die Interoperabilität und Wiederverwendbarkeit über Plattformen hinweg. Es wird jedoch eine Herausforderung sein, beispielsweise komplette virtuelle Maschinen oder Docker-Images so zu archivieren, dass wir sie auch noch nach Jahrzehnten ausführen können.
Fazit und Ausblick
Wiederverwendbare und nachhaltige Forschungssoftware erfordert professionelle Entwicklungsprozesse. Nur so können Software-Engineering-Methoden die Forschung in anderen Disziplinen verbessern. Aber auch die Forschung im Software Engineering und in der Informatik selbst profitiert von der Wiederverwendung, sobald es um Forschungssoftware geht.
Um den Stand auf diesem Gebiet zu untersuchen, haben wir die Praktiken der Veröffentlichung von Forschungssoftware in der Informatik und im wissenschaftlichen Rechnen analysiert. Dabei traten signifikante Unterschiede zutage: Das wissenschaftliche Rechnen betont die Reproduzierbarkeit von Ergebnissen, während die Informatik primär auf Wiederverwendung setzt.
Generell sollte es sich bei Forschungssoftware um Open Source handeln. Die etablierten Lizenzen aus diesem Bereich bieten adäquate Lizenzierungsmöglichkeiten, sodass keine Notwendigkeit besteht, die Software geschlossen zu halten. Nur in Ausnahmefällen und aus sehr triftigen Gründen sollte man Forschungssoftware geschlossen entwickeln.
Aus softwaretechnischer Sicht ermöglichen modulare Softwarearchitekturen die Wiederverwendung von Teilen von Forschungssoftwaresystemen [13]. Modularität ist essenziell für Wartbarkeit, Skalierbarkeit, Agilität und Wiederverwendbarkeit. Bisher sind allerdings viele Forschungssoftwaresysteme nicht in einer modularen Architektur aufgebaut. Das sollte sich künftig ändern, denn Modularität erleichtert einen kollaborativen Entwicklungsprozess für Open-Source-Forschungssoftware [14]. Nachhaltige Forschungssoftware wird modular aufgebaut sein müssen, um sie möglichst lange weiterentwickeln und wiederverwenden zu können. (jcb/jlu)
Infos
- Definition für Software: https://www.britannica.com/technology/software
- “FAIR4RS Principles”: https://doi.org/10.15497/RDA00068
- “Software Engineering for Computational Science: Past, Present, Future”: https://doi.org/10.1109/MCSE.2018.021651343
- “Open Source Research Software”: https://doi.org/10.1109/MC.2020.2998235
- “From FAIR research data toward FAIR and open research software”: https://doi.org/10.1515/itit-2019-0040
- “Towards FAIR principles for research software”: https://doi.org/10.3233/ds-190026
- Software Sustainability Institute: https://www.software.ac.uk
- Software Carpentry Initiative: https://software-carpentry.org
- Society of Research Software Engineering: https://society-rse.org
- Research Software Engineers: https://de-rse.org
- “Inhalte referenzieren und zitieren”: https://guides.github.com/activities/citable-code/
- “Software Heritage: Why and How to Preserve Software Source Code” (PDF): https://hal.archives-ouvertes.fr/hal-01590958
- “Software Architecture: Past, Present, Future”: https://doi.org/10.1007/978-3-319-73897-0_10
- “The Collaborative Modularization and Reengineering Approach CORAL for Open Source Research Software”: https://oceanrep.geomar.de/id/eprint/50147/





