
© Dmitry Molchanov / 123RF.com
Steht Mike Schilli vor der Qual der Wahl, eine Wandertour aus seiner Sammlung von Stadtwanderwegen herauszusuchen, greift er zu einem selbst gebauten Vorschlagsprogramm.
Welchen der auf dem Routenplanerdienst Komoot aufgezeichneten Stadtwanderwege soll ich heute erneut absolvieren? Diese Frage stelle ich mir überraschend oft. Je nach physischer Verfassung soll die Tagestour kurz oder lang, hügelig oder flach und somit anstrengend oder erholsam sein. Je nach Zeitvorgabe darf sie unter Umständen nicht zu weit von zu Hause entfernt liegen.
Allerdings bietet Komoot nur sehr rudimentäre Filtermöglichkeiten (Abbildung 1) und kann mit dem kleinstmöglichen Suchradius von drei Meilen nur das Stadtgebiet von San Francisco nach gespeicherten Touren absuchen. Für feinere Suchvorgaben schwebt mir ein Kommandozeilenwerkzeug vor, das anhand von Höhenprofil, Tourlänge und Entfernung zum Einstieg die Auswahl stark verringert.
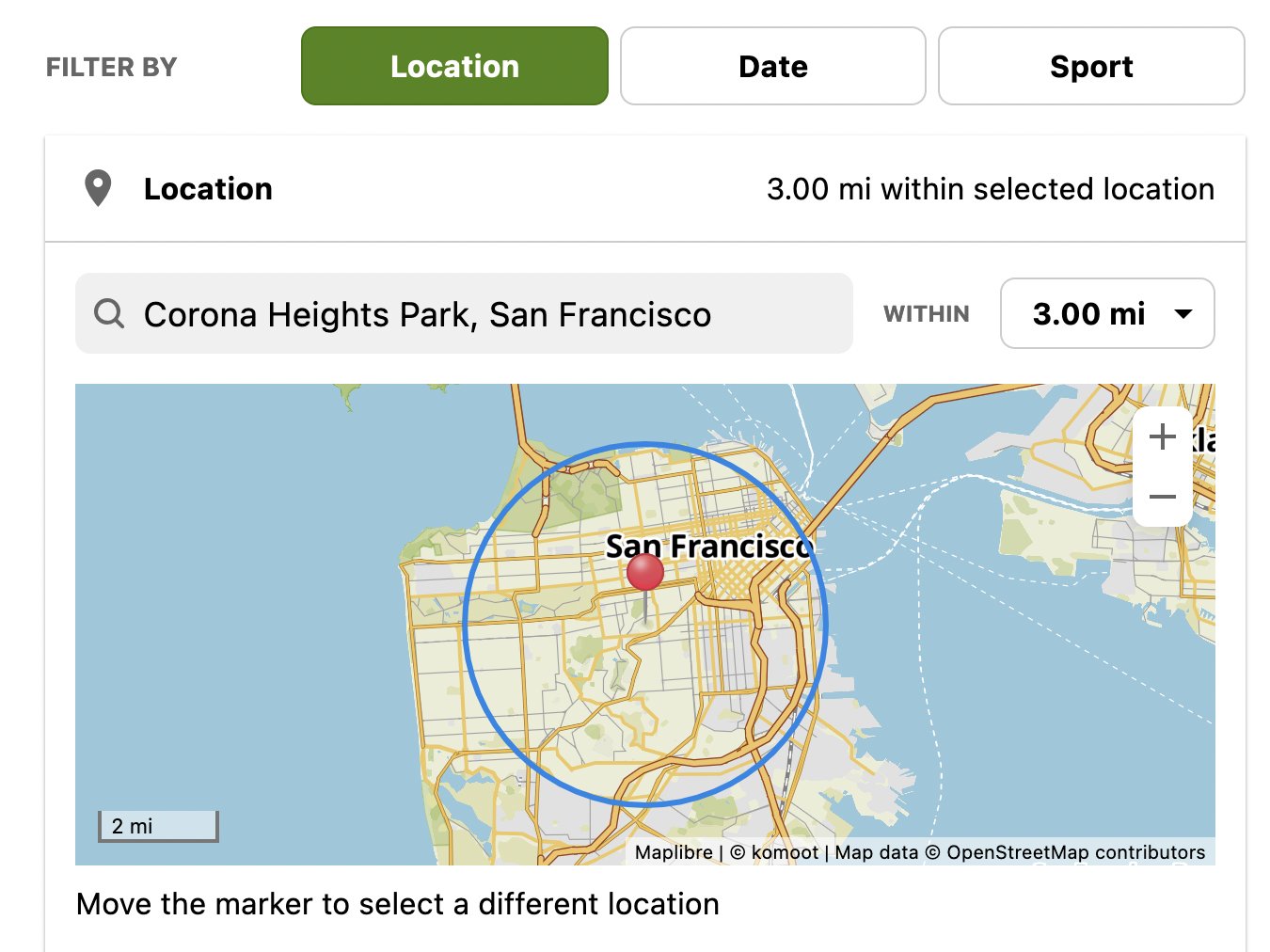
Abbildung 1: Der Routenplanerdienst Komoot bietet nur grobe Wanderwegfilter.
Die Tourdaten, anhand derer das neue Tool seine Auswahl treffen kann, liegen dank einer zurückliegenden Snapshot-Ausgabe [1] bereits als GPX-Dateien auf der Festplatte vor. Dieses XML-Format hält die Wegpunkte der jeweiligen Tour als Geokoordinaten mit Höhe über dem Meeresspiegel samt Zeitstempeln fest (Abbildung 2). Mangels öffentlich verfügbarer API auf Komoots Webseite hat sich seinerzeit ein Screenscraper dort eingeloggt, die GPX-Daten vom Netz geholt und sie lokal unter ihrer ID (zum Beispiel als »523799045.gpx«) auf der Festplatte ins Verzeichnis »tours/« kopiert.
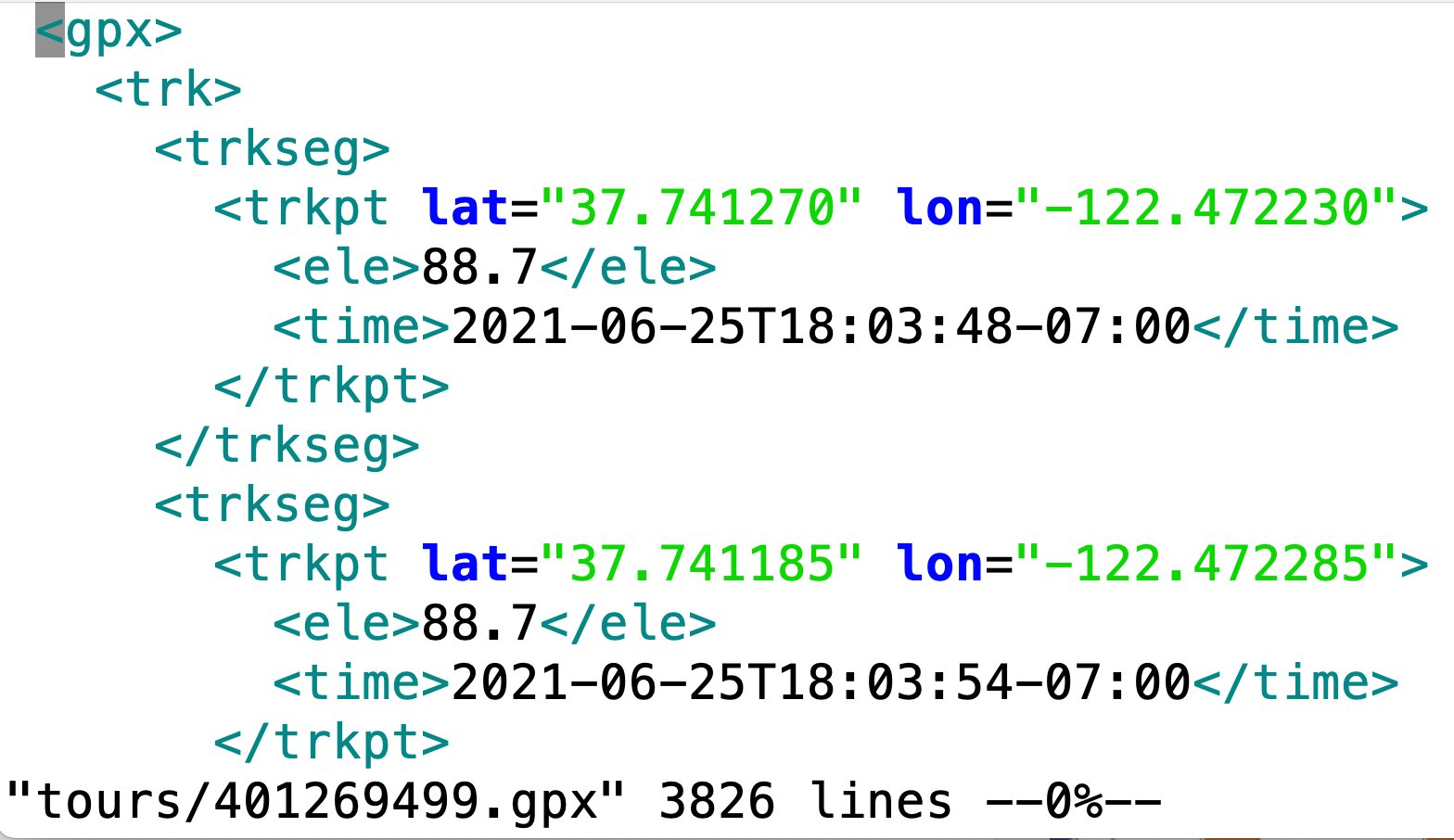
Abbildung 2: Beispiel einer Tourdatei im GPX-Format.
Zur Nachbearbeitung weist die CSV-Datei in Listing 1 den IDs leicht erkennbare Routennamen zu. Es handelt sich um eine Auswahl meiner Touren, die teils in Deutschland, teils in den USA liegen. Der Rest geht nun automatisch. Ein Präprozessor wurstelt sich durch die GPX-Daten aller Tracks, bestimmt deren Gesamtdauer, die erklommenen Höhenmeter und die Entfernung des Toureinstiegs vom Wohnort. Anschließend filtert ein Kommandozeilenprogramm in Go die Touren aufgrund eingestellter Kriterien heraus.
Listing 1
tour-names.csv
id,name 401269499,Forest Hill Parkside Farmers Market 411337149,Presidio 394385030,Vulcan Stairs and around Buena Vista 526430358,Aggenstein 434310884,Heidelberg Schlierbach 418406673,Tank Hill Mt Olympus 514603221,Bernal around the Hill 434601991,Heidelberg Philo-Altstadt-Schloss 510083576,Forest Hill Stairs Mini Loop 405638419,Around Mt Davidson 393675355,Laidley Glen Park Loop 416081317,Sanchez-Mission
Schwindelnde Höhen
Wie anstrengend sich eine Tour gestaltet, hängt unter anderem davon ab, wie viele Höhenmeter der Wanderer dabei bergauf läuft. Jeder abgewanderte Geopunkt der GPX-Datei (Abbildung 1) enthält nicht nur die geografische Länge und Breite (»trkpt lat/lon«), sondern auch die aktuelle Höhe über dem Meeresspiegel in Metern (»ele«). Führt der Weg nach oben, wächst der Höhenwert von Punkt zu Punkt an.
Um also die auf der Tour zu absolvierenden Höhenmeter auszurechnen, muss der Algorithmus durch alle Punkte des Tracks wandern, jeweils die Differenz der Meereshöhe zum Folgepunkt durch Subtraktion ermitteln und schließlich diese Differenzen insgesamt aufsummieren. Negative Werte filtert er vorher heraus, denn für die Schwere der Tour sollen nur Steigungen zählen, keine abfallenden Wegstücke.
Listing 2 löst diese Aufgabe elegant in nur wenigen Zeilen R-Code. Die Installation von R mittels »sudo apt-get install r-base-core« bringt noch keine GPX-Library mit. Im CRAN-Netzwerk steht jedoch eine bereit, die mit »install.packages(‘gpx’)« in einer interaktiven R-Session (einfach »R« auf der Kommandozeile aufrufen) auf dem lokalen Rechner landet. Danach findet sich im Suchpfad das Programm »Rscript«, das die nachfolgenden Listings aus ihren Shebang-Zeilen am Anfang aufrufen und das den Code in den Listings durch den R-Interpreter schickt.
Listing 2
climb.r
#!/usr/bin/env Rscript
library("gpx")
hike <- read_gpx("tours/686129674.gpx")
track <- hike$tracks[[1]]
ele <- track$Elevation
steps <- diff(ele)
upsteps <- steps[steps > 0]
print(sum(upsteps))
Zum Code: Die in Zeile 3 aufgerufene Funktion »read_gpx()« stammt aus der vorher installierten Library »gpx« und nimmt den Pfad zu einer GPX-Datei entgegen. Zurück kommt im Erfolgsfall ein Sammelsurium von benannten Datenbehältern sowie unter dem Namen »tracks« ein Array mit Tracks. Davon kann eine GPX-Datei mehrere enthalten, hier wird aber nur der erste gebraucht. Zeile 4 holt den entsprechenden Dataframe mit dem Ausdruck »hike$tracks[[1]]« hervor (Array-Elemente in R werden ab 1 durchnummeriert, nicht ab 0) und weist ihn der Variablen »track« zu.
Abbildung 3 zeigt die Daten des in der Variablen »track« liegenden Dataframes. Da die Höhenwerte im Dataframe »track« in der Spalte »”Elevation”« liegen, holt Zeile 5 sie mit dem Ausdruck »track$Elevation« heraus. Diesen Vektor mit allen Höhenwerten der Trackpunkte in der Datei weist das Skript dann der Variablen »ele« zu.
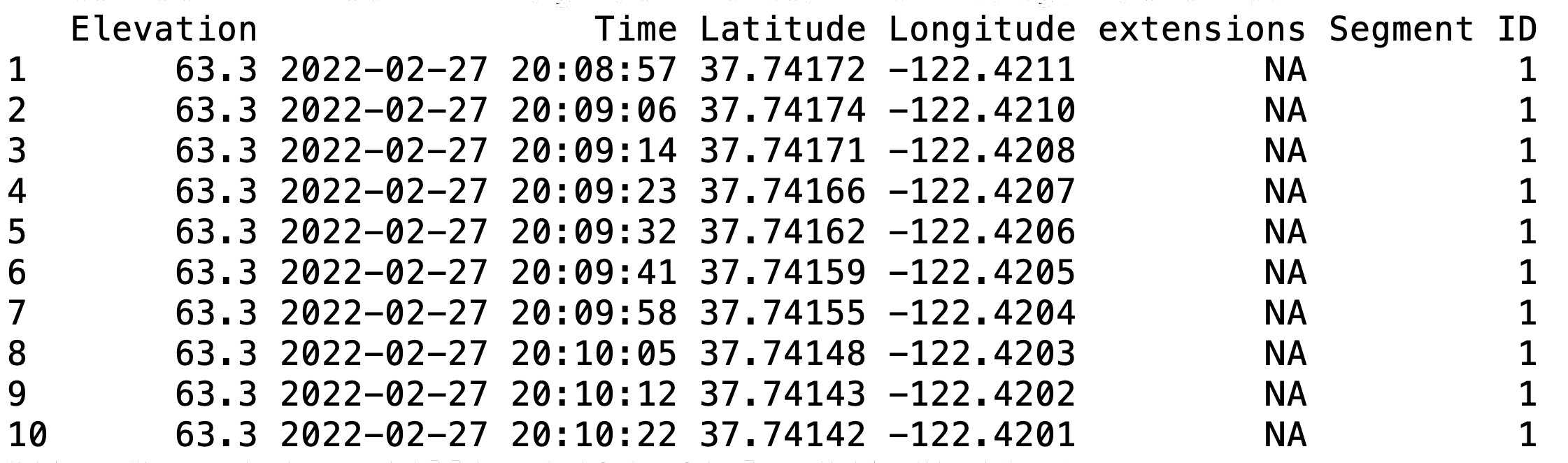
Abbildung 3: Der Dataframe entsteht aus den XML-Daten der GPX-Datei.
Nur bergauf zählt
Nachdem die Höhenwerte der Messpunkte alle im Vektor »ele« liegen, ermittelt die in R eingebaute Funktion »diff()« die Einzeldifferenzen zwischen ihnen. Das Ergebnis ist wieder ein Vektor. Lägen also in »ele« die Werte »(2,10,8,12)«, würde »diff()« daraus »(8,-2,4)« machen. Die Recode-Anweisung in Zeile 7 filtert die negativen Werte heraus, sodass im Beispiel nur noch »(8,4)« übrig bleiben. Die Funktion »sum()« in Zeile 8, die ebenfalls aus dem R-Standardfundus stammt, schnappt sich diesen Vektor und summiert dessen Einzelelemente auf. Im Beispiel wäre das Ergebnis 12.
Das Skript in Listing 2 lässt sich von der Kommandozeile aus aufrufen und gibt die Summe der während der Tour erklommenen Höhenmeter als Integer auf der Standardausgabe aus. Das später vorgestellte Filterprogramm braucht nun aber nicht nur die Höhenmeter einer Tour aus der Sammlung, sondern die Werte von allen Touren. Außerdem benötigt es außer den Höhenmetern auch die geografische Breite und Länge des Startpunkts des Tracks sowie die Dauer der Tour in Minuten. Das erledigt der Präprozessor aus Listing 3, der eine CSV-Datei nach dem Muster von Abbildung 4 erstellt.
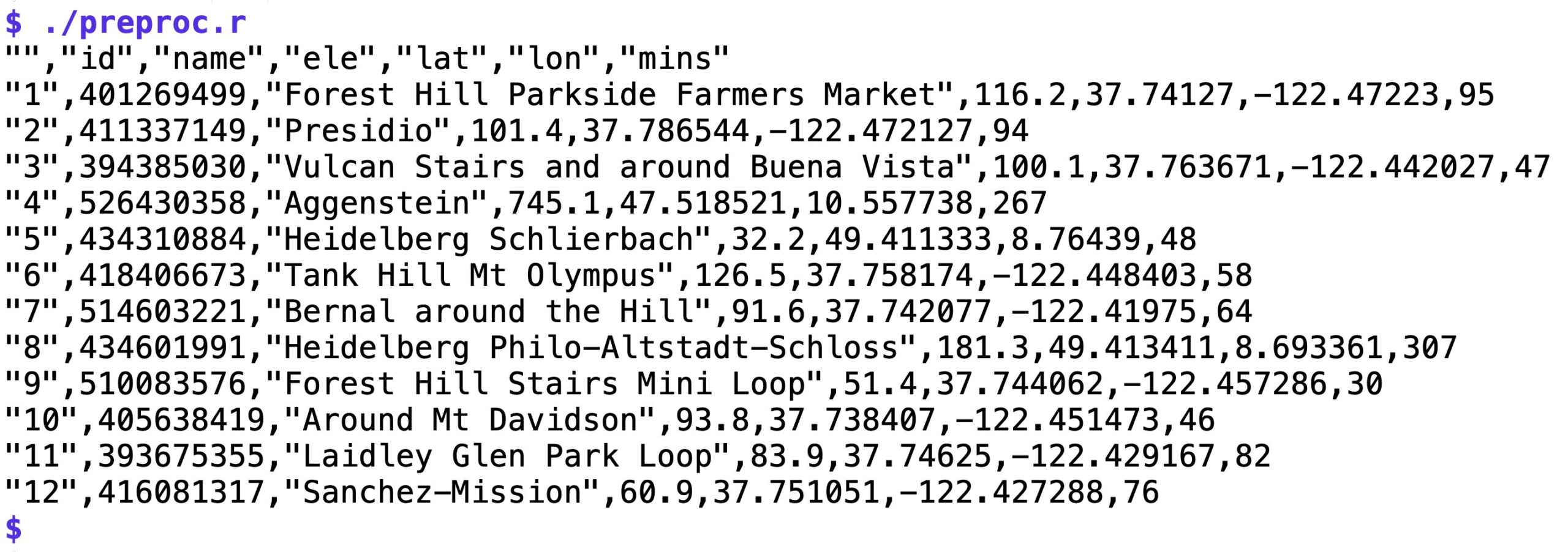
Abbildung 4: Die von »preproc.r« erzeugte CSV-Datei enthält die Metadaten aller Touren.
Listing 3
preproc.r
#!/usr/bin/env Rscript
library("gpx")
idnames <- read.csv("tour-names.csv")
for (row in 1:nrow(idnames)) {
id <- idnames[row, "id"]
gpxf <- paste("tours/", id, ".gpx", sep="")
hike <- read_gpx(gpxf)
track <- hike$tracks[[1]]
# elevation
ele <- track$Elevation
steps <- diff(ele)
upsteps <- steps[steps > 0]
idnames[row,3] = sum(upsteps)
names(idnames)[3] = "ele"
# starting point
idnames[row,4] = track[1, "Latitude"]
idnames[row,5] = track[1, "Longitude"]
names(idnames)[4] = "lat"
names(idnames)[5] = "lon"
# duration
start <- track[1, "Time"]
stop <- tail(track, 1)[1, "Time"]
mins <- round(as.numeric(difftime(stop, start), units="mins"), 0)
idnames[row,6] = mins
names(idnames)[6] = "mins"
}
write.csv(idnames)
Wie funktioniert nun der Präprozessor? Als Erstes liest Listing 3 die CSV-Daten aus »tour-names.csv« (Listing 1) ein und bekommt einen Dataframe mit den Spalten »id« und »name« zurück. Die For-Schleife ab Zeile 4 iteriert durch alle Zeilen dieses Dataframes. Zeile 5 extrahiert die numerische »id« der Tour, Zeile 6 stöpselt daraus den Pfad zur GPX-Datei auf der Platte zusammen. Die Funktion »read_gpx()« liest daraufhin die Tourdaten aus dem GPX-Format, und der Rest der Höhenmeterrechnung erfolgt analog zu Listing 2. Nun gilt es, den errechneten Zahlenwert in einer neuen Spalte »”ele”« an den Dataframe anzuhängen.
Mehr Spalten
Um einem Dataframe eine neue Spalte hinzuzufügen, genügt es, ihr einen Wert zuzuweisen. Dazu verwendet man entweder die Dollar-Notation (»idnames$newcol«) oder die Indexnummern für Zeile und Spalte wie in »idnames[row,col]«, wobei »col« für die neue Spaltennummer steht.
Im vorliegenden Fall ist »row« die Indexnummer der aktuell von der For-Schleife bearbeiteten Datenreihe, und »col« ist gleich 3, da »”ele”« als dritte Spalte im Dataframe erscheinen soll. Damit die neue Spalte auch einen Namen erhält und nicht nur neue Werte, gilt es, anschließend in Zeile 14 noch, das Array »names(idnames)« durch Anhängen eines Elements mit dem neuen Spaltennamen zu modifizieren.
Wichtig ist es, erst einen neuen Spaltenwert einzufügen, damit R weiß, dass der Dataframe gewachsen ist. Erst dann kann auch der Name in »names« hinein. Jeder Versuch, das vorher auszuführen, provoziert eine Fehlermeldung, da R dann denkt, der Dataframe wäre zu schmal.
Tourstart
Für den Inhalt der nächsten zwei Spalten, Nummer 4 und 5, sucht das R-Skript die geografische Breite und Länge des Startpunkts der Tour. Da die GPX-Daten als Dataframe vorliegen, ist das ein Kinderspiel: Die erste Zeile adressiert R einfach mit dem Index 1 und versteht den Namen der Spalte als Spaltenindex. Deshalb muss Zeile 16 nur nach dem Index »[1, “Latitude”]« im GPX-Dataframe fragen und bekommt die geografische Breite als Zahlenwert geliefert. Für die geografische Länge gilt das analog, hier fügen die Zeilen 18 und 19 neue Spalten als Nummer 4 und Nummer 5 in den Ergebnis-Dataframe »idnames« ein.
Nun fehlt noch die Dauer der Tour, die der Abschnitt ab Zeile 20 ermittelt und ins Ergebnis einfügt. Sie errechnet sich aus der Differenz zwischen dem letzten und dem ersten Zeitstempel in der GPX-Datei. Zeile 21 holt unter der Indexnummer 1 die erste Zeile und mit »”Time”« den Wert in der Spalte mit den Zeitstempeln. Den letzten Eintrag aus dem GPX-Dataframe ermittelt in Zeile 22 die R-Funktion »tail()« mit dem Parameter 1 (nur das letzte Element), mit analoger Spaltenextraktion wie zur Ermittlung der Startzeit.
Anfang und Ende
Die Differenz dieser beiden Zeitstempel errechnet die R-Funktion »difftime()«. Um das Ergebnis in Minuten zu erhalten, ruft Zeile 22 die R-Funktion »as.numeric()« mit dem Parameter »units=”mins”« auf. Zurück kommt eine Fließkommazahl mit Minutenbruchteilen, die die R-Funktion »round()« mit einem Präzisionswert von 0 (keine Nachkommastellen) auf die nächste ganze Zahl rundet. Fertig ist die Tourlänge, und die Zeilen 23 und 24 fügen den Wert in Spalte 6 unter dem Namen »”mins”« in den Ergebnis-Dataframe ein.
Abschließend schreibt »write.csv()« das Ganze im CSV-Format in die Standardausgabe, und der Benutzer legt das Ergebnis zur späteren Filterung in der Datei »tour-data.csv« ab. Dort schnappt das nachfolgend erläuterte Go-Programm »hikefind« das Resultat auf und filtert es. Dazu übernimmt Listing 4 mit »readCSV()« das Einlesen der Metadaten und legt die Einzeleinträge in einem Array-Slice mit Elementen vom Typ »Tour« ab. Ab Zeile 10 definiert, nimmt es alle wichtigen Metadaten wie Dauer, Höhenmeter oder Startpunkt auf.
Listing 4
csvread.go
package main
import (
"encoding/csv"
"fmt"
"io"
"os"
"strconv"
)
const csvFile = "tour-data.csv"
type Tour struct {
name string
file string
gain int
lat float64
lng float64
mins int
}
func readCSV() ([]Tour, error) {
_, err := os.Stat(csvFile)
f, err := os.Open(csvFile)
if err != nil {
panic(err)
}
tours := []Tour{}
r := csv.NewReader(f)
firstLine := true
for {
record, err := r.Read()
if err == io.EOF {
break
}
if err != nil {
fmt.Printf("Error\n")
return tours, err
}
if firstLine {
// skip header
firstLine = false
continue
}
gain, err := strconv.ParseFloat(record[3], 32)
panicOnErr(err)
lat, err := strconv.ParseFloat(record[4], 64)
panicOnErr(err)
lng, err := strconv.ParseFloat(record[5], 64)
panicOnErr(err)
mins, err := strconv.ParseInt(record[6], 10, 64)
panicOnErr(err)
tour := Tour{
name: record[2],
gain: int(gain),
lat: lat,
lng: lng,
mins: int(mins)}
tours = append(tours, tour)
}
return tours, nil
}
func panicOnErr(err error) {
if err != nil {
panic(err)
}
}
Erwartungsgemäß geht die Datenverarbeitung in Go weniger elegant von der Hand. Das Paket »encoding/csv« versteht zwar das CSV-Format, aber Gos Reader-Typ muss sich mühsam durch die Zeilen der Datei arbeiten, auf das Dateiende prüfen (Zeile 29) und etwaige Lesefehler behandeln. Da die erste Zeile im CSV-Format die Spaltennamen auflistet, steuert die Logik ab Zeile 36 mit der Bool-Variablen »firstLine« daran vorbei.
Mit »ParseFloat()« und »ParseInt()« und der jeweiligen Präzision (32 oder 64 Bit) sowie der Basis 10 für den Integer fieseln die Zeilen 41 bis 48 dann die Spaltenwerte heraus, Zeile 49 füllt die Struktur vom Typ »Tour« damit. Zeile 55 hängt den Einzeleintrag an das Array-Slice mit allen Zeilendaten aus der CSV-Datei an, und weiter geht es in die nächste Runde.
Wählerisch
Das Hauptprogramm in Listing 5 versteht eine Reihe von Filter-Flags. Dabei steht »–gain« für den maximalen Höhenanstieg in Metern und »–radius« für die maximale Entfernung zum Wohnort, dessen Koordinaten »home« in Zeile 9 definiert. Außerdem legt »–mins« die maximale Tourdauer in Minuten fest. Die Flags nehmen entweder Fließkomma- oder Ganzzahlwerte vom Benutzer entgegen, auf deren Basis Hikefind die Touren aus der CSV-Metadatei entsprechend filtert.
Listing 5
hikefind.go
package main
import (
"flag"
"fmt"
"github.com/fatih/color"
geo "github.com/kellydunn/golang-geo"
)
func main() {
home := geo.NewPoint(37.751051, -122.427288)
gain := flag.Int("gain", 0, "elevation gain")
radius := flag.Float64("radius", 0, "radius from home")
mins := flag.Int("mins", 0, "hiking time in minutes")
flag.Parse()
flag.Usage = func() {
fmt.Print(`hikefind [--gain=max-gain] [--radius=max-dist] [--mins=max-mins]`)
}
tours, err := readCSV()
if err != nil {
panic(err)
}
for _, tour := range tours {
if *gain != 0 && tour.gain > *gain {
continue
}
start := geo.NewPoint(tour.lat, tour.lng)
dist := home.GreatCircleDistance(start)
if *radius != 0 && dist > *radius {
continue
}
if *mins != 0 && tour.mins > *mins {
continue
}
fmt.Printf("%s: [%s:%s:%s]\n",
tour.name,
color.RedString(fmt.Sprintf("%dm", tour.gain)),
color.GreenString(fmt.Sprintf("%.1fkm", dist)),
color.BlueString(fmt.Sprintf("%dmins", tour.mins)))
}
}
Die For-Schleife ab Zeile 21 iteriert über alle mittels »readCSV()« in Zeile 17 eingelesenen Metadaten und setzt die drei implementierten Filter »gain«, »radius« und »mins« an. Die Entfernung vom Wohnort prüft der Radius-Filter mithilfe des Github-Pakets »kellydunn/golang-geo«, das mithilfe der Funktion »GreatCircleDistance()« die Entfernung der beiden Geopunkte in Kilometern ermittelt und anschließend das numerische Ergebnis mit dem eingestellten Filterwert vergleicht.
Springt einer der drei Filter an, geht die For-Schleife mittels »continue« ohne Ausgabe in die nächste Runde. Passiert ein Eintrag hingegen alle Filter unbeschadet, gibt die Print-Anweisung ab Zeile 33 die Tour aus.
Bunt und in Farbe
Damit die Metawerte der ausgedruckten Touren später schön ins Auge springen, zieht Listing 5 anfangs das Paket »fatih/color« von Github herein, das Funktionen zur Ausgabe der in Terminals üblichen ANSI-Farbcodes bereitstellt.
Sie kompilieren Listing 4 und Listing 5 mit dem üblichen Dreisprung (Listing 6). Das resultierende Binary »hikefind« gibt entweder alle Touren aus (Abbildung 5, ohne Kommandozeilenoptionen) oder schlägt mit beliebigen Kombinationen aus den verschiedenen Filtertypen eine entsprechend kompaktere Auswahl vor.
Listing 6
Kompilieren
$ go mod init hikefind $ go mod tidy $ go build hikefind.go csvread.go

Abbildung 5: Ohne Optionen aufgerufen, listet Hikefind alle vorhandenen Trails auf.
Abbildung 6 zeigt alle Wanderwege im Umkreis von 10 Kilometern meiner Wahlheimat San Francisco, die weniger als 100 Höhenmeter ansteigen und die sich in maximal einer Stunde bewältigen lassen. Übrig bleiben lediglich drei Routen – es ist halt doch eine recht hügelige Stadt. (uba)

Abbildung 6: Durch Einsatz der Filteroptionen entsteht eine Auswahl ganz nach Gusto des Benutzers.
Der Autor
Michael Schilli arbeitet als Software Engineer in der San Francisco Bay Area in Kalifornien. In seiner seit 1997 laufenden Kolumne erforscht er jeden Monat die praktische Anwendung verschiedener Programmiersprachen. Unter mailto:mschilli@perlmeister.com beantwortet er gern Ihre Fragen.
Infos
- Snapshot: Mike Schilli, “Wandern nach Plan”, LM 09/2021, S. 84, https://www.lm-online.de/44765





