
© Valerii Minhirov / 123RF.com
Die Welt des Scale-out ist stateless: Wer auf höhere Last mit mehr Instanzen statt mit einem stärkeren Server reagieren will, braucht in der Regel zustandslose Anwendungen – Datenbanken sind das aber nicht. YugabyteDB löst das Dilemma für PostgreSQL.
Heutige Anwendungen skalieren meist problemlos in die Breite – auf mehreren Servern, virtuellen Maschinen, Kubernetes-Pods, Containern oder in der Cloud – weil sie zustandslos (stateless) sind. Genau diese Skalierbarkeit schafft die Elastizität und Widerstandsfähigkeit, die Geschäftsanwendungen brauchen. Das gilt ganz besonders in der Cloud, wo jede Komponente bei einem Ausfall ersetzbar sein soll und wo die Elastizität für Kostensenkungen ohne Performance-Verlust sorgt. Allerdings kommt kaum eine Anwendung ohne eine Datenbank aus, in der sie ihre Daten so speichern kann, dass deren Konsistenz auch dann gewahrt bleibt, wenn konkurrierende Transaktionen sie manipulieren. Eine Datenbank aber ist in der Regel zustandsbehaftet (stateful), und das stellt beim Skalieren eine Herausforderung dar.
Monolithische RDBMS
Diese Herausforderung konnte man bei relationalen Datenbanken (RDBMS) so lange einfach ignorieren, wie man sie nur auf einem einzigen Server öffnete. Diese Einschränkung erlaubte den Datenbankprozessen, einfach das Shared Memory des Betriebssystems zu nutzen, das Latches (Spinlocks oder Mutexes) schützten.
Datenbanknutzer meinen häufig, der Shared Memory Pool ihrer Datenbank sei nur als Cache zur Steigerung der Performance gut, weil er viele I/O-Zugriffe auf das Daten-File einspart. Tatsächlich ist aber einer der Hauptgründe für die Existenz des Shared Memory Pools der Umstand, dass er als Single Source of Truth dient, wenn verschiedene Sessions lesend und schreibend auf einen bestimmten Datenblock zugreifen sollen, ohne ihn zu korrumpieren. Dass ein größerer Shared Memory Pool auch die Lese- und Schreibzugriffe für häufig benötigte Blöcke auf die Festplatte vermindert, ist aber lediglich ein Zusatznutzen. Speziell PostgreSQL delegiert diese Cache-Funktion teilweise an den Linux-Kernel, weswegen die Empfehlung dort lautet, den Shared Memory Pool kleiner zu halten, um mehr Platz für die Puffer des Dateisystems übrig zu lassen.
Jedenfalls beschränkt dieser Mechanismus die Datenbank auf einen einzigen Server, der sein RAM mit allen Prozessen teilen kann. Eine Ausnahme macht Oracles Real Applications Cluster (RAC), bei dem mehrere RDBMS-Instanzen eine Datenbank öffnen können. Das erzwingt allerdings eine komplexe Intra-Cluster-Synchronisation, bei der die gegenwärtig aktuelle Version eines Datenblocks nur an einem einzigen Ort existieren darf und deshalb zwischen den physischen Maschinen hin und her verschoben werden muss. Dieses globale Cache- und Lock-Management setzt ein Netzwerk mit ausgesprochen niedriger Latenz voraus, etwa das Infiniband-Netz innerhalb von Oracles Exadata-Servern. In einem herkömmlichen Netz. Zwischen verschiedenen Rechenzentren oder in der Cloud funktioniert das nicht. Außerdem erfordert RAC Blockspeicher, auf die mehrere virtuelle Maschinen zur selben Zeit zugreifen können. Das ist ungewöhnlich und im Cloud-Umfeld eine weitere Herausforderung.
Die monolithischen RDBMS wurden im Laufe der Jahre mit einer Vielzahl an Features ausgestattet, die geschäftlichen Anforderungen entgegenkamen oder das Entwickeln und Testen erleichtern sollten. Dank der ACID-Garantien (Atomicity, Consistency, Isolation, Durability) liefern diese Anwendungen auch dann korrekte Ergebnisse, wenn es zu Race Conditions oder anderen Fehlern kommt. Der Schlüssel dazu ist SQL mit seiner referenziellen Integrität (Fremdschlüssel) oder Unique Constraints. Der Clou: Dafür braucht es keinen zusätzlichen Code in der Applikation. Sobald ein Isolationsgrad festgelegt ist, werden Anomalien verhindert, die aus konkurrierenden Zugriffen folgen könnten, wiederum ohne zusätzlichen Code.
Eine weitere Funktion, die in einer monolithischen Architektur leicht zu implementieren ist, sind die verschiedenen Indizes, die sich automatisch pflegen lassen. Dadurch kann man ein und dieselbe Datenbank für mehrere Anwendungsfälle nutzen und genießt dank der logisch-physikalischen Unabhängigkeit mehr Flexibilität. Kurz gesagt, die Anwendung fragt die Tabellen ab, ohne sich Gedanken über den Zugriffspfad auf die Daten zu machen. Die Datenbank findet auf transparente Weise selbst den optimalen Zugriffspfad durch die richtigen Indizes.
Webscale und NoSQL
Mit der Zeit wurde der Druck immer stärker, das Bedürfnis nach Skalierung in die Breite zu bedienen. Gründe dafür waren das Internet, webbasierte Unternehmen und die Cloud: Millionen Benutzer lassen sich nicht aus einer einzigen Datenbank bedienen, die an einem einzigen Ort irgendwo in der Welt ihren Dienst tut. Das ist aus drei Gründen unmöglich.
Erstens beträgt die Latenz zwischen verschiedenen Regionen auf der ganzen Welt Hunderte von Millisekunden. Das wird für die Benutzer spürbar und ist nicht akzeptabel. Technisch lässt sich daran nichts ändern, weil sich Informationen nicht schneller als mit Lichtgeschwindigkeit übertragen lassen. Deshalb bleibt als einzige Möglichkeit, die Daten an verschiedenen Orten in der Nähe der Anwender vorzuhalten. Dieses Speichern an verschiedenen Orten ist zugleich oft auch eine rechtliche Vorbedingung.
Zweitens dient als Netzwerk zwischen den geografischen Regionen das Internet, in dem Pakete durch eine Infrastruktur geleitet werden, in der es jederzeit zu Performance-Engpässen und Fehlern kommen kann. Liefe die Datenbank nur an einem Ort, wäre die Applikation nicht mehr verfügbar, sobald das Netz ausfiele. Alle gängigen RDBMS implementieren eine Aktiv-Passiv-Replikation und stellen Lesereplikate bereit, mit denen Reports auch dann noch ausgegeben werden können, wenn die primäre Datenbank ausgefallen ist. Es gelingt so aber nicht, über verschiedene Knoten hinweg zu skalieren und konsistente Lese- und Schreibtransaktionen darüber zu realisieren.
Drittens brauchen manche Workloads hohe Durchsatzraten mit vorhersehbaren Antwortzeiten selbst unter Spitzenlast (beispielsweise Handel am Black Friday). Das Skalieren durch den Einsatz von mehr CPUs und mehr RAM in einem Server (Scale-up) erfordert eine Downtime und hat außerdem immer Grenzen. Um die Verfügbarkeit der Applikation in allen Situationen zu gewährleisten, muss die Datenbank auf mehreren Servern laufen, deren Anzahl man bei Bedarf aufstocken und später auch wieder verringern kann, um Kosten zu sparen. Gleichzeitig erlaubt das auch Updates im laufenden Betrieb.
Dieser Bedarf nach einem Skalieren in die Breite (Scale-out) hat einen neuen Typ von Datenbanken hervorgebracht, die die Daten in sogenannte Shards partitionieren, die sie dann auf mehreren Servern speichern. Eine Lösung bestand darin, Transaktionen im Wesentlichen wie vor dem Aufkommen der relationalen Datenbanken auszuführen, mit einer hierarchischen und verteilten Struktur, die keine komplexen Transaktionen und keine garantierte Konsistenz zulässt und mit sehr einfachen Speicherprimitiven auskommt. Das sind die NoSQL-Datenbanken. Sie ähneln den Datastores vor der Erfindung von SQL, sind aber über ein widerstandsfähiges und elastisches Netz von Knoten verteilt. Sie eignen sich hervorragend für bestimmte Aufgaben, bei denen man die Zugriffsmuster im Voraus gut kennt. Einige Firmen haben ihre Daten in eine solche Datenbank migriert. Das wiederum erzwingt aber mehr Code in der Applikation, der den Verlust der SQL-Features ersetzen muss. Bis vor einiger Zeit war das allerdings der einzige Weg für ein Scale-out.
NewSQL
Der Bedarf nach einem Scale-out erfasste alle Arten von Workloads, darunter auch komplexe OLTP-Arbeitslasten, bei denen sich die Entwickler all die SQL-Features zurückwünschten, die sie von ihren bisher benutzten RDBMS kannten – jetzt aber mit allen Vorteilen der Scale-out-Architektur von NoSQL. So kam das populäre SQL wieder zurück, und zwar in einer Form, die man als NewSQL apostrophiert.
Für Data Warehouses und analytische Anwendungen war das ganz leicht: Man verwendete einfach die Sharding-Technik von NoSQL, um die Daten aufzuteilen, und jedes Shard war ein eigenes RDBMS. Allerdings erlaubt diese Herangehensweise keine Transaktionen über die Grenzen eines Shards hinaus, keine globalen Indizes, keine Unique Constraints, keine Fremdschlüssel zwischen Shards und keine Joins zwischen Partitionen. Für analytische Anwendungen lässt sich das hinnehmen, aber OLTP-Anwendungen brauchen globale Transaktionen.
Verteilte SQL-Datenbanken sind in dieser Hinsicht die vorerst letzte Entwicklung. Sie bieten alle SQL-Features, einschließlich Cross-Node-Transaktionen, Fremdschlüsseln und Unique Constraints in einer Scale-out-Architektur. In diese Riege gehören Googles Cloud Spanner sowie CockroachDB und TiDB. Erstere bietet SQL ähnlich wie PostgreSQL, Letztere ähnelt MySQL. Der Hersteller Yugabyte geht einen Schritt weiter, indem er PostgreSQL wiederverwendet, um alle SQL-Features zu erhalten, und das Ganze dann auf das Fundament einer Spanner-ähnlichen verteilten Engine aufsetzt. So bekommt der Anwender mit YugabyteDB das Beste aus zwei Welten. Er kann sich mit jedem beliebigen Knoten verbinden und erhält stets Schreib- und Lesezugriff auf eine einzige logische Datenbank (Abbildung 1).
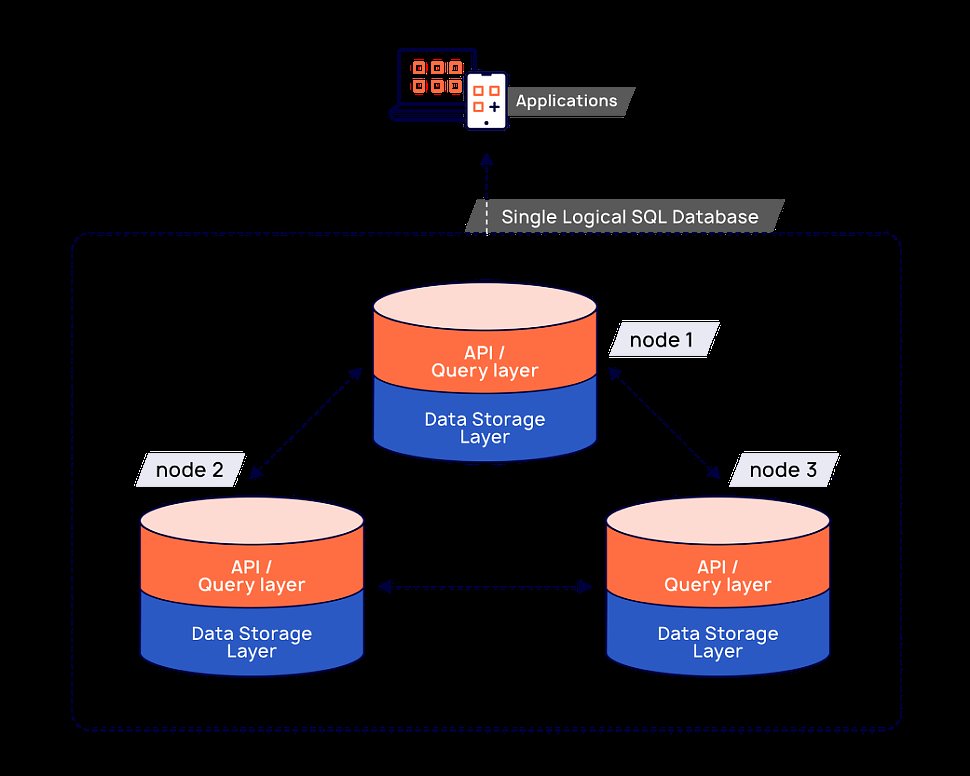
Abbildung 1: Benutzer können sich mit einem beliebigen Knoten verbinden und von dort aus lesend und schreibend auf die Datenbank zugreifen. Quelle: Yugabyte
Verteiltes SQL
YugabyteDB basiert einerseits auf erprobter Arbeit, wie sie das Google-Papier über Spanner beschreibt, und andererseits auf einer einzigartigen Innovation: In einer zweischichtigen Architektur baut das wiederverwendete PostgreSQL im SQL-Layer auf der darunterliegenden DocDB-Schicht auf, dem verteilten Storage- und Transaktions-Layer. Applikationen können sich mit jedem Knoten verbinden und sehen von dort aus eine einzige logische Datenbank. Zwar ist YSQL, der PostgreSQL-kompatible Layer, die hauptsächliche Schnittstelle, allerdings lässt sich die auch austauschen. Yugabyte hält beispielsweise eine Cassandra-ähnliche API bereit, die dann zum Einsatz kommen kann, wenn der Anwender keinen vollen SQL-Support benötigt und stattdessen die Syntax und spezielle Features von Cassandra nutzen möchte (wie dessen Time to live, TTL).
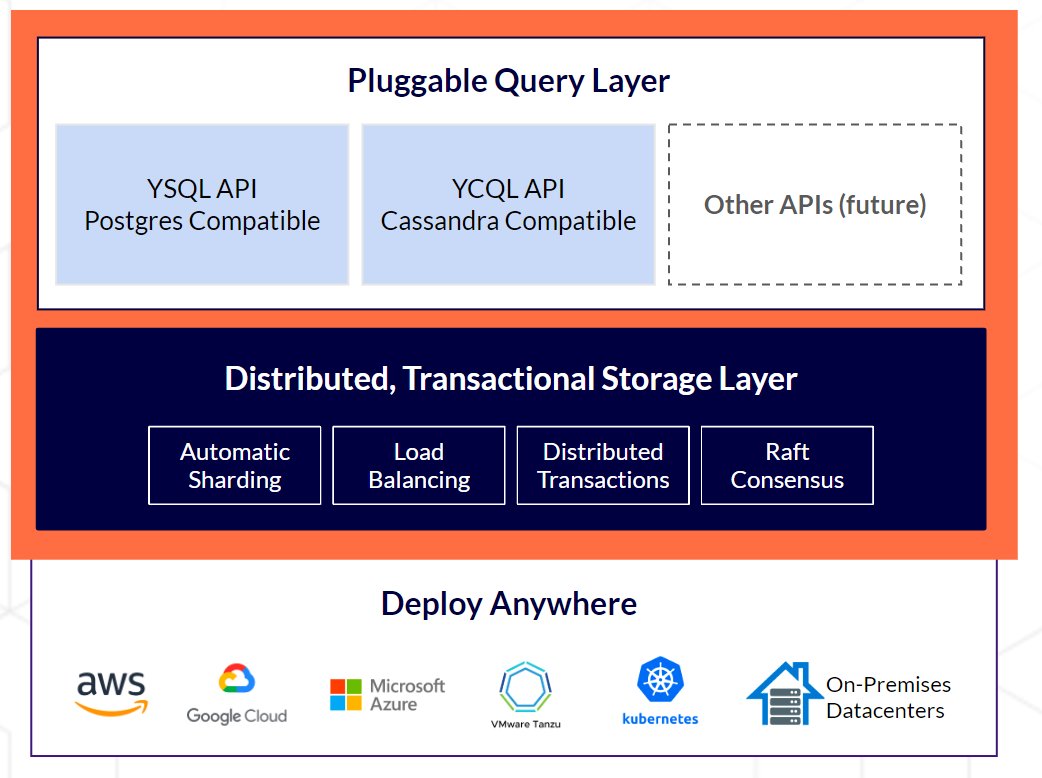
Abbildung 2: Die austauschbaren API-Layer über der verteilten Storage-Engine sind eine Besonderheit von YugabyteDB. Quelle: Yugabyte
Das PostgreSQL-Backend, das mit zusätzlichem Code für den Cluster bereit gemacht wurde, parst die Queries und führt sie aus. Die Tabellen sind durch eine Hash- oder Range-Funktion in Shards aufgesplittet und auf die Datenbankknoten verteilt. Die Standard-Sharding-Strategie umfasst einen Hash auf die erste Spalte des Schlüssels und eine automatische Aufteilung, wenn die Tabelle wächst.
Die PostgreSQL-Syntax wurde jedoch erweitert, um eine vollständige administrative Kontrolle zu ermöglichen. So erzeugt das Beispiel aus Listing 1 eine Tabelle mit Hash-Sharding auf Basis der »empno«-Spalte mit 42 voreingestellten Shards (die hier »tablets« heißen). Listing 2 erzeugt einen Index für die Spalte »hiredate«, der nach Bereichen gesplittet ist, um einen Scan des Indexbereichs zu ermöglichen. Voreingestellt sind dafür Jahresbereiche 2010 bis 2020.
Listing 1
create table
yugabyte=# create table emp ( empno int, hiredate timestamp, primary key (empno hash) ) split into 42 tablets;
Listing 2
create index
yugabyte=# create index emp_hire
on emp ( hiredate asc )
split at values (
('2010-01-01'),
('2015-01-01'),
('2020-01-01')
);
Um im Zuge von Joins Latenzen zwischen den Knoten zu vermeiden, lassen sich mehrere Tablets im selben Shard speichern, sodass alle Joins lokal bleiben. Einige Referenztabellen lassen sich mit mehreren Regionen synchronisieren. Mit einem Replikationsfaktor RF = 3 über drei Rechenzentren oder Verfügbarkeitszonen lässt sich die Datenbank auch dann noch benutzen, wenn eines der Rechenzentren ausfällt. Die Verteilung der Knoten kann auch im Rahmen eines Multi-Cloud- oder Hybrid-Cloud-Setups erfolgen (Abbildung 3).
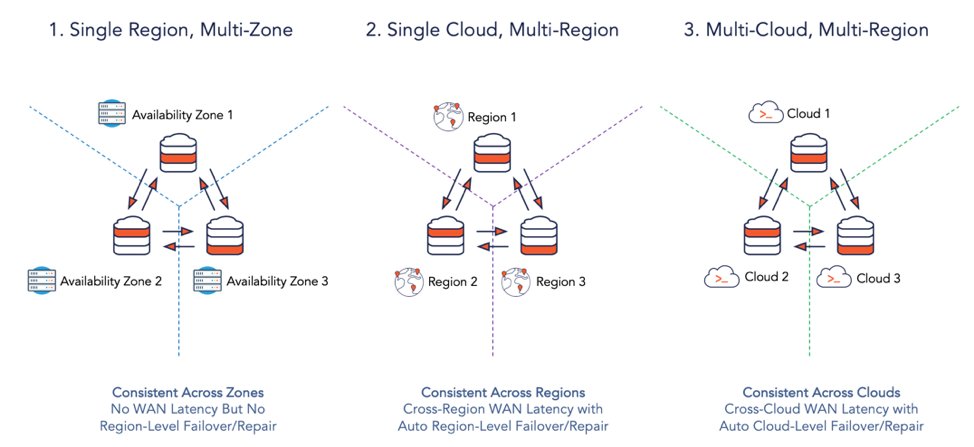
Abbildung 3: Für das Verteilen der Knoten gibt es verschiedene Möglichkeiten. Quelle: Yugabyte
Standardmäßig werden die Tabellen und Indizes über den gesamten Cluster verteilt. Wenn es die Latenz oder die Datenverwaltung erfordern, lässt sich die Verteilung auf eine Untermenge des Clusters beschränken, etwa auf eine bestimmte Region. Das erreicht man mithilfe der PostgreSQL-Funktionen für Partitionierung sowie mit Tablespaces. Tablespaces dienen hier dazu, Tabellen, Indizes und Partitionen auf die Cluster-Topologie abzubilden. Das Beispiel aus Listing 3 repliziert eine Region (»eu-west«) über drei Availability Zones.
Listing 3
Replikation
create tablespace "eu-west" with ( replica_placement= $$
{
"num_replicas": 3,
"placement_blocks": [
{ "cloud": "cloud", "region": "eu-west1", "zone": "eu-west1a",
"min_num_replicas": 1 },
{ "cloud": "cloud", "region": "eu-west1", "zone": "eu-west1n",
"min_num_replicas": 1 },
{ "cloud": "cloud", "region": "eu-west1", "zone": "eu-west1c",
"min_num_replicas": 1 }
]
} $$);
alter table emp set tablespace = "eu-west";
Danach werden die Table Tablets mit dieser Topologie neu abgeglichen (letzte Zeile). Dabei handelt es sich um einen Online-Vorgang, der die Tablets bewegt, während sie gelesen und beschrieben werden. Das klappt dank der Replikation.
Architektur
Angesichts der technischen Herausforderungen gibt es nicht viele verteilte SQL-Datenbanken, die alle SQL-Funktionen bieten, ohne Transaktionen auf einen einzigen Server zu beschränken.
Google Spanner begann mit eingeschränktem SQL, fügte später aber Protokoll- und Syntaxkompatibilität mit PostgreSQL hinzu. Dabei bleibt es auf die Google Cloud-Plattform beschränkt. CockroachDB macht dasselbe, öffnet sich aber für andere Plattformen und bietet einige Kernfunktionen als Open Source. Seine PostgreSQL-Kompatibilität erfordert immer noch eine Codeänderung bei der Portierung von PostgreSQL. TiDB ist mit MySQL kompatibel.
YugabyteDB ist vollständig Open Source und zielt auf PostgreSQL-Kompatibilität bei identischem Anwendungsverhalten ab. Dieser Artikel über verteiltes SQL mit YugabyteDB konzentriert sich auf die YSQL-API, auch wenn viele Cassandra-Umsteiger das Cassandra-ähnliche YCQL verwenden.
PostgreSQL-Kompatibilität
Die Entscheidung für die Kompatibilität mit PostgreSQL war getrieben von dessen Beliebtheit für OLTP-Anwendungen und seine Übereinstimmung mit dem SQL-Standard. Die Verwendung desselben Protokolls und derselben Syntax sowie die Bereitstellung derselben Funktionen sind nicht nur für die Portabilität bestehender Anwendungen nützlich, sondern auch für die Vertrautheit. YugabyteDB ist eine neue Datenbank, und im Problemfall würde die Suche nach einer Antwort etwa auf Stack Overflow oder in anderen Online-Ressourcen nur wenige Treffer erzielen.
Für alle SQL-Fragen gilt jedoch, dass die Wissensbasis in Dokumentationen, Foren und Blogs in Bezug auf PostgreSQL auch für YugabyteDB gilt. Die Kompatibilität zielt darauf ab, dieselben Anwendungen und Tools wie für PostgreSQL laufen zu lassen. YugabyteDB bietet alle Isolationsebenen mit derselben Semantik wie PostgreSQL, um das gleiche Verhalten in der Produktion zu gewährleisten. Andere verteilte Datenbanken implementieren nur das Isolations-Level Serializable, bei dem die Anwendung eine Wiederholungslogik implementieren muss.
Der Code der YSQL-Schicht basiert auf einem Fork von PostgreSQL, der viele SQL-Funktionen mitliefert. Das umfasst nicht nur alle aktuellen PostgreSQL-Funktionen, sondern schließt auch die Verwendung zahlreicher PostgreSQL-Erweiterungen ein. Die Stellen im Code, die YugabyteDB-spezifisch sind, sind klar gekennzeichnet. Suchen Sie im Code nach »IsYBRelation()«, um eine gute Vorstellung zu bekommen. Diese Vorgehensweise ermöglicht das Anpassen an die neuen Funktionen zukünftiger PostgreSQL-Versionen, die jedes Jahr veröffentlicht werden.
Open Source
Genau wie bei PostgreSQL gibt es bei YugabyteDB keine Enterprise-Edition: YugabyteDB ist mit all seinen Datenbankfunktionen Open Source, um den Benutzern alle Freiheiten zu lassen und Beiträge der Gemeinschaft zu ermöglichen. Für die Produktion bietet das Unternehmen Yugabyte Support und verwaltete Dienste an, aber die Datenbank bleibt mit allen Funktionen quelloffen. Als Open-Source-Lizenz dient Apache 2. Die Entscheidung für freie Software hat der Gründer und CTO von Yugabyte, Karthik Ranganathan, ausführlich erläutert [1].
Da YugabyteDB quelloffen ist, lässt es sich einfach testen. Es läuft auf jeder Linux-Plattform, egal ob Server, virtuelle Maschine oder im Container. Man benötigt nur lokalen Speicher und Netzwerkzugang. Der einfachste Weg, es auf einem Laptop zu testen, ist die Verwendung von Docker. Prinzipiell reicht ein einziger Knoten aus. Durch Hinzufügen von drei oder mehr Knoten kann man die Ausfallsicherheit (durch Simulation eines Ausfalls) und Elastizität (durch einfaches Hinzufügen weiterer Knoten) testen. Die einfache Webkonsole genügt, um den automatischen Ausgleich von Daten und ihre Verarbeitung zu beobachten.
Die Kommandos aus Listing 4 erzeugen ein Netzwerk, starten einen ersten Knoten und exportieren die Ports 5433 für PostgreSQL und 7000 für die Web-Konsole, die den Tablet-Server und die Tablets zeigt. Letztere erreicht man unter http://localhost:7001. Nach dem Start kann sich jeder PostgreSQL-Client via »postgres://yugabyte@localhost:5431/yugabyte« mit der Datenbank verbinden.
Listing 4
Start eines ersten Knotens
$ docker network create -d bridge yb $ docker run -d --name yb1 --hostname yb1 --net=yb -p5431:5433 -p7001:7000 yugabytedb/yugabyte:latest yugabyted start --daemon=false --listen yb1
Weitere Knoten fügt man mit der Option »–join« hinzu; in Listing 5 wird ein Drei-Knoten-Cluster aufgebaut. Der Anwender kann sich danach mit jedem verfügbaren Knoten verbinden und von dort aus lesen und schreiben, selbst wenn ein anderer Knoten ausgefallen ist. Dieselbe Datenbank lässt sich auch in der YugabyteDB Managed Cloud erstellen, die auf AWS und in der Google Cloud läuft. Dort lässt sich eine kleine Maschine kostenlos nutzen.
Listing 5
Knoten hinzufügen
$ docker run -d --name yb2 --hostname yb2 --net=yb -p5432:5433 -p7002:7000 yugabytedb/yugabyte:latest yugabyted start --daemon=false --listen yb2 --join yb1 $ docker run -d --name yb3 --hostname yb3 --net=yb -p5433:5433 -p7003:7000 yugabytedb/yugabyte:latest yugabyted start --daemon=false --listen yb3 --join yb1
Herausforderungen
Die Abfrageschicht basiert auf dem PostgreSQL-Code, wobei die Zeilen und Indexeinträge der YugabyteDB-Tabellen (YSQL) gesharded werden. Die Aufteilung erfolgt mittels einer Bereichs- oder Hash-Funktion. Das lässt sich in »create table« und »create index« durch die Angabe von »ASC« oder »DESC« für das Range-Sharding oder »HASH« für das Sharding auf Grundlage der Hash-Funktion vorgeben. Die Hash-Funktion wird standardmäßig für die erste Spalte des Primärschlüssels von Sekundärindizes berechnet. Die Standardwerte dienen dazu, Migrationen von PostgreSQL zu erleichtern, ohne die DDL (Data Definition Language) zu ändern.
Das Sharding erfolgt automatisch, indem die Shards (die sogenannten Tablets) aufgeteilt werden, wenn die Tabelle wächst. Es gibt zudem eine zusätzliche Syntax respektive administrative Befehle, um die Tabellen und Indizes zum Beispiel vor einem Bulk-Load händisch zu splitten. Das bedeutet, dass die Tabellenzeilen und Indexeinträge standardmäßig alle unabhängig voneinander verteilt werden. Aus Leistungserwägungen ist es jedoch möglich, einige kleine Tabellen und Indizes zusammen in ein einziges Tablet zu verlagern. Diese Entscheidung hängt vom Einsatz ab: Ein Cluster mit nur einer Region kann eine Latenz von einer Millisekunde zwischen den Verfügbarkeitszonen akzeptieren, ein Cluster mit mehreren Regionen muss die knotenübergreifenden Remote-Aufrufe (RPC) reduzieren.
Die Anwendung, die als Client der Datenbank fungiert, kann sich mit jedem Knoten (Tserver, für Tablet Server) verbinden. Jeder Knoten bietet einen PostgreSQL-Endpunkt, der für jede Verbindung einen Backend-Prozess forkt. Das Parsen und Ausführen der Abfrage bewerkstelligt der PostgreSQL-Code, der für den Cluster-Einsatz erweitert und optimiert wurde. Statt jedoch Tupel aus oder in den gemeinsamen Buffer-Cache und in die lokalen Datendateien zu lesen oder zu schreiben, wie dies bei PostgreSQL der Fall wäre, sendet das Backend Lese- und Schreibvorgänge im Batch an Tablet Leader, die über die Knoten (Tserver) im Cluster verteilt sind. Das PostgreSQL-Backend ist ein Client für DocDB, wie die verteilte transaktionale Key-Value-Datenspeicherschicht heißt.
Jedes Tablet wird aus Gründen der Hochverfügbarkeit repliziert, wobei eines der Replikate (Tablet-Peers) als Tablet Leader fungiert, an den Lese- und Schreibvorgänge gesendet werden. Der Name Leader stammt vom Raft-Algorithmus, der exakt einen Leader pro Tablet garantiert, selbst im Falle eines Ausfalls, solange das Quorum vorhanden ist. Der Leader-Lease-Algorithmus verhindert jede Split-Brain-Situation. Wenn ein Leader nicht verfügbar ist, wählt das Quorum der Follower einen neuen Leader, wobei garantiert wird, dass keine Daten verloren gehen und die Wiederherstellungszeit minimal bleibt (Recovery Time Objective RTO in Sekunden, Konfiguration abhängig von der erwarteten Netzwerklatenz).
Alle Lese- und Schreibvorgänge der SQL-Schicht werden auf der Grundlage der Tupel-Verteilungsmethode (durch Aufteilung auf den Primärschlüssel oder Indexeintrag) an den Tablet Leader gesendet und optimiert, um die Auswirkungen der Latenz auf die Antwortzeit zu verringern. Ein einziger Leader garantiert die Konsistenz von Lese- und Schreibvorgängen. Die Verteilung der Daten und der Verarbeitung erfolgt durch den automatischen Ausgleich von Leader und Follower. Die Schreibvorgänge werden mit den Followern synchronisiert und warten auf die Quorum-Bestätigung. In einem Cluster mit dem Replikationsfaktor RF = 3 wird die Änderung in der Regel lokal ausgeführt und auf die Bestätigung eines der beiden Follower gewartet. Falls der Leader etwa aufgrund eines Server-Ausfalls nicht mehr verfügbar ist, hat mindestens einer der Follower die letzte Änderung erhalten und kann zum neuen Leader gewählt werden. Im Sinne des CAP-Theorems erfüllt YugabyteDB die Anforderungen C und P (Consistency und Partition Tolerance), es bleibt mit der bestmöglichen Verfügbarkeit immer konsistent.
Jeder Tablet-Peer ist eigentlich ein LSM-Baum auf der Grundlage von RocksDB, der alle Änderungen als neue Versionen von Zeilen oder Spalten speichert. Alle Isolationsebenen werden mit pessimistischem oder optimistischem Locking unterstützt. Die erste Ebene des LSM-Baums, die MemTable, befindet sich im RAM. Sie wird in SST-Dateien (Sorted Sequence Table) ausgelagert, sobald sie eine bestimmte Größe erreicht (standardmäßig 128 MByte). Dabei entstehen viele SST-Dateien mit allen Zwischenversionen. Um die Datenmenge zu begrenzen, werden diese im Hintergrund komprimiert: Die Daten der SST-Files werden in einer neuen SST-Datei verkettet und abgelaufene Einträge entfernt. Anschließend werden die abgelaufenen ursprünglichen SST-Dateien gelöscht.
Alle Änderungen werden mithilfe einer Hybrid Logical Clock (HLC) in eine Reihenfolge gebracht, um die Serialisierbarkeit von Transaktionen trotz der möglichen Zeitverschiebung zwischen den physischen Zeiten der einzelnen Server zu gewährleisten [2]. Der Titel ist eine Anspielung auf Google Spanner, das das Problem der Zeitverschiebung mit Atomuhren löste, dann aber den Einsatz auf seine Rechenzentren beschränkte. YugabyteDB löst dieses Problem, indem es die hybride logische Uhr mit dem Lamport-Algorithmus synchronisiert. So muss es nur in den sehr seltenen Fällen, in denen es keine Nachrichten zwischen den Servern gibt, auf den Lock-Versatz warten.
Roadmap
YugabyteDB wurde entwickelt, um leistungsstarkes OLTP zu ermöglichen, das alle SQL-Features benötigt, die in der 30-jährigen Geschichte der monolithischen Datenbanken erfunden wurden. Das ist der Grund für die Wiederverwendung von PostgreSQL, und es gibt nur wenige Funktionen, die in einem verteilten Kontext nicht unterstützt werden [3].
OLTP-Anwendungen führen auch einige analytische Abfragen aus, für die YugabyteDB möglicherweise nicht optimiert ist. In Cloud-nativen Anwendungen werden diese in der Regel von einem anderen, eigens entwickelten Datenbankdienst verarbeitet. Dies erfordert mehr Code und Komponenten, um die Extraktion, Transformation und das Laden von Daten in die spezialisierte Datenbank zu definieren. YugabyteDB hat Change Data Capture implementiert, das über Debezium und Kafka die Daten an andere Datendienste streamen kann. Event-Streaming wird jedoch niemals die Einfachheit und Leistung einer konvergenten Datenbank übertreffen. Wo das möglich ist, sind Echtzeit-Analysen in einer operativen Datenbank einfacher auszuführen.
SQL bietet viele Features für das Ausführen komplexer Abfragen mit Fensterfunktionen, sekundären Indizes und materialisierten Ansichten. An dieser Stelle wird an YugabyteDB gearbeitet, um sie im verteilten Kontext zu optimieren. Die wichtigste Technik besteht darin, die Filter (»WHERE«-Klausel), Aggregationen (»GROUP BY«) und Sortierungen (»ORDER BY«) auf die Speicherschicht (DocDB) zu verlagern. So werden sie auf jedem Datenbankknoten verarbeitet, statt einen vollständigen Satz von Zeilen an die SQL-Schicht senden zu müssen, um diese Aktionen auszuführen.
Wie schon erwähnt, existiert neben der wichtigsten API, der PostgreSQL-API (YSQL genannt), eine weitere mit Cassandra kompatible (YCQL). So kann man zum Beispiel bei Zeitreihen je nach Bedarf die passende Schnittstelle wählen. YCQL erlaubt eine optimale Dateneingabe, da es von den Cassandra-Treibern profitiert, die threaded und Cluster-fähig sind und keinen zusätzlichen Overhead durch die Bereitstellung einer komplexen Transaktionssemantik verursachen. YSQL eignet sich besser für Abfragen, da es viele Funktionen zum Verarbeiten von Daten und viele Index-Typen zum Optimieren des Zugriffs bietet.
YugabyteDB wird stetig weiter verbessert, und bei Open Source geht es nicht nur um den Code. Das Architekturdesign und die Roadmap sind auf Github veröffentlicht [4]. Viele neue Funktionen sollen die Benutzererfahrung verbessern, neue Cloud-native Anwendungen unterstützen oder bei der Migration von PostgreSQL, Oracle oder anderen traditionellen Datenbanken hin zu Yugabyte helfen.
Obwohl alle Benchmarks eine gute Leistung für OLTP zeigen, gibt es einige komplexe Abfragen, insbesondere für Analysen, die weitere Entwicklungen im Query Planner und im Executor von YugabyteDB erfordern. Diese Arbeiten sind noch nicht abgeschlossen, und die Entwickler heißen Beiträge der Gemeinschaft willkommen. (jcb)
Infos
- “Why We Changed YugabyteDB Licensing to 100 Prozent Open Source”: https://www.yugabyte.com/blog/why-we-changed-yugabyte-db-licensing-to-100-open-source
- “Distributed Transactions Without Atomic Clocks”: https://vimeo.com/545130381
- PostgreSQL-Kompatibilität: https://docs.yugabyte.com/preview/explore/ysql-language-features/postgresql-compatibility/#un-Supported-postgresql-features
- Design und Roadmap: https://github.com/yugabyte/yugabyte-db





