
© Hernan Schmidt / 123RF.com
Wie alle Komponenten skalierbarer Plattformen müssen auch Datenbanken heute ganz selbstverständlich in die Breite skalieren können. Technisch ist das knifflig, wie Vitess zeigt: Das Programm setzt unter der Haube auf verschiedene Techniken wie Sharding, sieht von außen aber wie MySQL aus.
Wo IT-Unternehmen in der Vergangenheit noch einzelne Setups mit separater Infrastruktur pflegten, geben skalierbare Plattformen heute fast zwangsläufig den Ton an. Weil Kunden von ihren Anbietern wie selbstverständlich erwarten, dass IT-Infrastruktur und ihr Betrieb immer günstiger werden, lässt sich IT heute nur noch effizient betreiben, wenn sie auf schiere Masse setzt. Wo Admins früher vielleicht ein paar Dutzend Systeme unter ihren Fittichen hatten, sind es heute Hunderte Maschinen und oft noch mehr. Das wirkt sich freilich auch auf die Applikationen aus, die auf solchen Plattformen laufen: Sie müssen in der Lage sein, zusammen mit den Umgebungen zu wachsen. Etliche Beispiele beweisen das eindrücklich, etwa Ceph, das mitwachsenden Speicher anbietet, oder Anwendungen, die dem Cloud-ready-Design folgen und auf jeder Ebene intern nahtlos skalieren können.
Auch vor Datenbanken macht der Trend zum Skalieren nicht halt. Dabei sei es, so könnte man meinen, heute gar nicht mehr nötig, über das Thema überhaupt noch groß zu reden. Galera für MySQL existiert schließlich, und für PostgreSQL gibt es am Markt gleich ein Füllhorn von Lösungen, das Skalierbarkeit nachrüstet. So einfach ist die Sache dann aber doch nicht: Galera (Abbildung 1) hat zwar eine Fangemeinde, kommt aber mit architektonischen Schwächen daher, die seinen Einsatz in vielen Szenarien unmöglich machen. PostgreSQL ist längst nicht so beliebt wie MariaDB oder MySQL, es kommt in deutlich weniger Setups zum Einsatz und gilt als komplizierter und schwerfälliger. Ganz davon abgesehen sind auch etliche der Replikationslösungen für PostgreSQL mit kritischen Designfehlern behaftet.
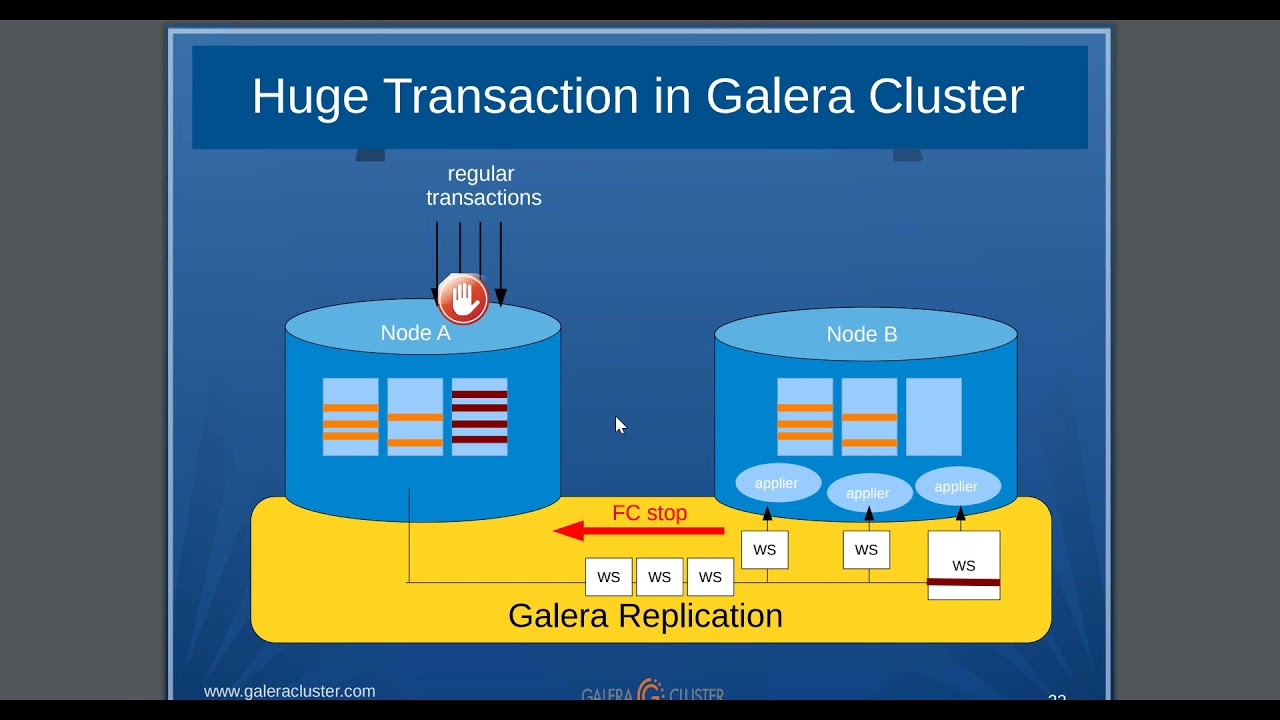
Abbildung 1: Galera gehört zu den Replikationslösungen der ersten Generation, die unter mancher architektonischen Einschränkung leiden. Quelle: Galera
Hier tritt Vitess [1] auf den Plan, eine Skalierbarkeitslösung für MySQL, die sich bei Youtube über Jahre hinweg bewährt hat und ein paar Dinge bewusst anders angeht als Galera. Die Autoren versprechen neben nahtloser Skalierbarkeit bei zuverlässiger Konsistenz auch etliche zusätzliche Features wie eine interne Engine, die Datenbankabfragen optimiert, um mehr Performance aus dem Setup zu kitzeln. Zumindest laut Prospekt bietet sich Vitess im Gespann mit MySQL damit als perfekte Datenbanklösung für skalierbare Setups und mithin auch für Cloud-Setups an. Doch hält es, was seine Autoren versprechen?
Herausforderungen
Bevor wir uns unmittelbar mit Vitess beschäftigen, ist es sinnvoll, die grundsätzlichen Herausforderungen eines verteilten Datenbanksystems kurz zu umreißen. Nur so erschließt sich, wieso man überhaupt spezielle Software braucht, um skalierte Datenbanken zu implementieren. Die Frage, wieso ein einzelnes MySQL auf leistungsfähiger Hardware dazu nicht genügt, ist schließlich durchaus legitim und gar nicht so leicht zu beantworten. Dasselbe gilt für die Frage, wieso ein einzelner Datensatz aus MySQL sich nicht ohne Weiteres auf beliebig viele MySQL-Instanzen im Backend verteilen lässt.
Grundsätzlich gilt, dass Datenbanken in modernen Setups zu den wenigen Orte zählen, an denen überhaupt noch persistente Daten gesichert werden. Gerade moderne Cloud-ready-Anwendungen verfolgen bei ihrer Datenhaltung heute oft einen ganz anderen Ansatz: Sie trennen logisch zwischen Asset-Daten, also statischen Inhalten wie Bildern oder Videos, und tatsächlichen Nutzdaten. Die Asset-Daten wandern in modernen Setups heute oft auf externe Speicher, etwa S3, von wo aus sie per HTTP-Link direkt eingebunden werden. Das reduziert die Last bei der eigentlichen Anwendung und ist für Clients in der Regel flotter, weil sich Speicher nach dem S3-Protokoll geografisch zielgerichtet ansprechen lassen und obendrein mit Caches kombiniert werden können, um eine Art Mini-CDN zu erstellen. Früher war es durchaus üblich, auch Asset-Daten in Datenbanken zu speichern, doch diese Zeiten sind längst vorbei. Warum reicht ein einzelnes MySQL dann aber in Cloud-Setups nicht aus?
Die kurze Antwort auf diese Frage lautet, dass zum Beispiel ein einzelnes MySQL trotz allem ein Single Point of Failure wäre, der je nach Größe eines Setups früher oder später auch Performance-Probleme bekommen kann. Klassische HA-Lösungen wie Cluster-Manager sind den Entwicklern von Cloud-ready-Setups zudem ein Graus. Hier ist die glasklar formulierte Anforderung an jede Anwendung ganz einfach, dass sie nahtlos skalieren und in beliebig vielen verbundenen Instanzen laufen muss. Folgerichtig bleiben auch Lösungen wie MySQL von diesem Grundsatz nicht verschont.
Technisch besteht allerdings eine große Herausforderung darin, ein Ungetüm wie MySQL fit für das Skalieren in die Breite zu machen. Beim klassischen MySQL ist alles darauf ausgelegt, eine zentrale Kontrollinstanz zu haben. Die Master-Instanz ist der alleinige Anlaufpunkt für Schreibvorgänge und garantiert so die Konsistenz, ohne die sich eine Datenbank kaum sinnvoll nutzen lässt. Wie es unter der Haube aussieht, ist jedem Admin klar, der schon einmal ein MySQL in den Fingern hatte: Irgendwo in »/var/lib/mysql/« liegen die Datenbanken mit ihren Tabellen, und es gibt schlicht keinen Weg, mehrere MySQL-Instanzen so zusammenzuschalten, dass sie Anfragen von mehreren Instanzen unter Beibehaltung der Konsistenzgarantien bearbeiten könnten.
Viele Instanzen und Sharding
Genau dieses Problem geht Vitess für MySQL an. Dabei muss man sich Vitess aber deutlich anders vorstellen als Galera. Letzteres fügt sich als ein Plugin in MySQL ein, das mittels eines eigenen Konsensalgorithmus eine Kommunikation zwischen den Knoten implementiert und die Inhalte der Datenbankinstanzen des Clusters synchron hält.
Die Vitess-Architektur (Abbildung 2) ist nicht annähernd so simpel. Vor allem lässt Vitess sich eigentlich nicht mehr als Aufsatz für MySQL bezeichnen. Zwar spielt MySQL im Kontext von Vitess als ein mögliches Backend für das Speichern von Daten noch eine Rolle, doch findet die gesamte Logik der Datenhaltung und Datenverarbeitung letztlich auf der Vitess-Ebene statt und mithin in speziell für Vitess konzipierten Diensten.
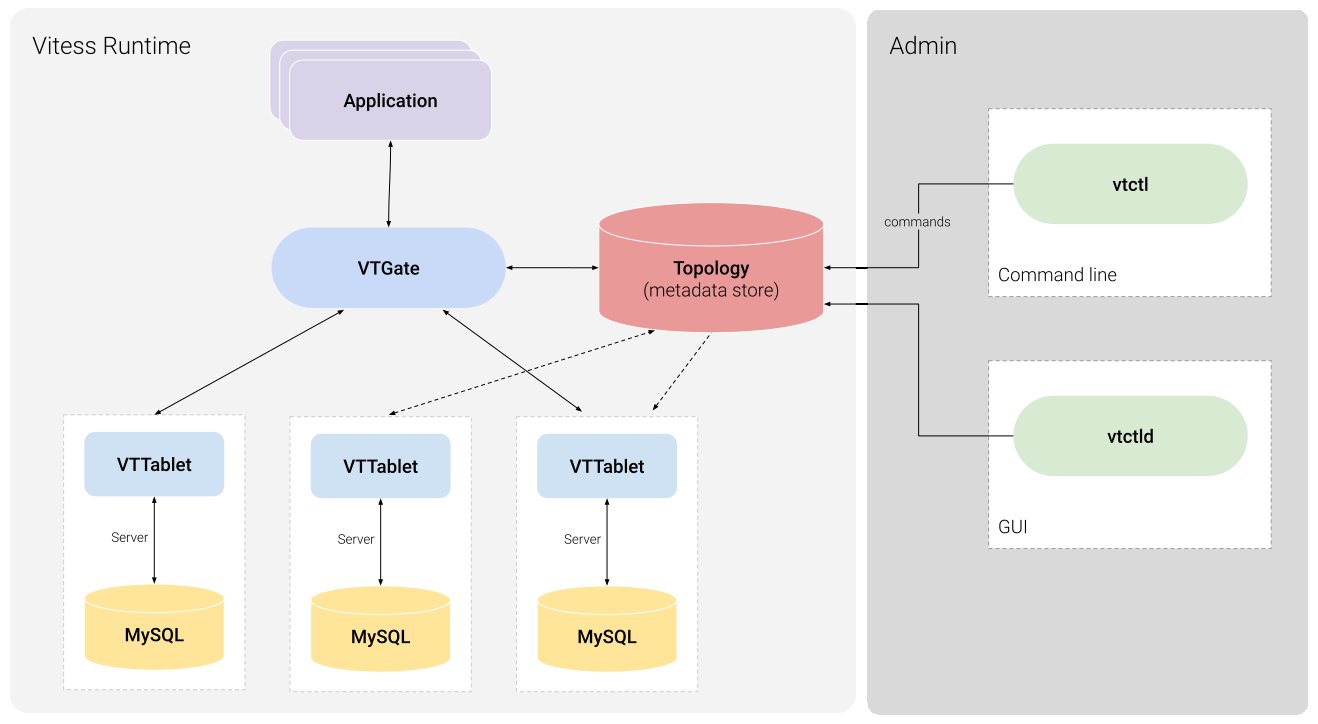
Abbildung 2: Die Cloud-native Datenbank Vitess setzt im Hintergrund auf MySQL und exponiert nach außen das MySQL-Protokoll. Sie abstrahiert MySQL aber mittels einer Zwischenschicht. Quelle: Vitess
Der Dreh- und Angelpunkt der Lösung ist eine Komponente namens VTGate. VTGate steht für Vitess Gateway, ein Fingerzeig auf die Funktion dieser Komponente: Sämtliche Daten, die ihren Weg in die Datenbank finden sollen, müssen hier vorbei. Zur Seite steht VTGate dabei ein zusätzlicher Service, der Topology-Dienst, der die Metadaten einer Vitess-Instanz verwaltet und speichert. Wichtiges Detail: Änderungen an diesen Metadaten, etwa durch das Anlegen neuer Datenbanken oder Tabellen, spielt der Administrator mittels der Werkzeuge »vtctl« oder »vtctld« ein. Ersteres ist ein unmittelbar auf der Kommandozeile nutzbares Tool, Letzteres ist das Backend für ein GUI, über das die Daten in der Datenbank sich ebenfalls modifizieren lassen.
Wenn es um die Metadaten der Datenbank geht, geschieht die Steuerung also mittelbar über den Topology-Dienst, mit dem VTGate ständig kommuniziert. Wichtig für das Verständnis der Art und Weise, wie Vitess funktioniert, ist die Tatsache, dass das Vitess-Gateway selbst eine eigene MySQL-Schnittstelle in Form des Server-Protokolls von MySQL implementiert. Clients, die auf das Gesamtkonstrukt zugreifen, kommunizieren also nicht mit einem echten MySQL, sondern mit einer Art Abstraktionsschicht, die das MySQL-Protokoll beherrscht (Abbildung 3).
Abbildung 3: Aus Client-Sicht ändert sich bei der Arbeit mit MySQL gar nichts. Die gezeigten Befehle aus der Vitess-Dokumentation wären auch auf einem normalen MySQL nutzbar.
Nun macht ein Frontend für das Ablegen von Daten freilich noch keine Datenbank aus, denn irgendwo müssen die Informationen ja hin. Hier setzt Vitess tatsächlich auf MySQL, aber anders, als man es vermuten würde. Einer Instanz eines VTGates können beliebig viele Instanzen eines VTTablet zugewiesen sein, ein weiterer Dienst aus dem Vitess-Universum. Ein VTTablet benötigt im Backend stets eine echte Datenbank, in der es lokal seine Daten ablegen kann, und für diese Aufgabe setzt Vitess dann doch wieder auf MySQL.
Schon aus diesem Design ergibt sich jedoch, dass die einzelne MySQL-Instanz hier im Grunde wirklich nur als Speicher für Daten fungiert. Die eigentliche Magie, also das Verteilen von Daten, übernehmen das VTGate und die VTTablets im Gespann. Ein VTTablet kann dabei mehrere Betriebsmodi haben. Es kann im Primary-Modus sein, sodass es schreibenden Zugriff ermöglicht, es kann im Replica-Modus sein oder im Zustand der Wartung.
Logische Datenbanken
Die Auswirkungen dieser Implementierung sollte man sich als Administrator, der in Zukunft möglicherweise Vitess betreiben möchte, gut vergegenwärtigen: Die klassische Einteilung von MySQL in Datenbanken, Tabellen und Zeilen und Spalten kommt in Vitess nativ so gar nicht vor. Zu dem, was ein Client sieht, wenn er per VTGate auf eine MySQL-Instanz von Vitess zugreift, gibt es auf den im Hintergrund laufenden Prozessen von MySQL und VTTablet auch keine tatsächliche Entsprechung. Stattdessen ist das, was ein Client durch ein VTGate hindurch sieht, immer das kompilierte, logische Gesamtbild eines im Hintergrund auf den einzelnen VTTablet-Instanzen eigentlich weit verteilten Datensatzes. Gewisse Parallelen zu anderen verteilten Lösungen wie Ceph liegen nahe. Dort implementieren die MON-Server die Abstraktion für den Client, und die OSDs legen im Hintergrund Daten auf Blockspeichergeräten ab. Vitess funktioniert ganz ähnlich, wobei die einzelnen Dienste hier VTGate und VTTablet heißen.
Da stellt sich die Frage, wie das Transponieren der Daten durch das VTGate im Hintergrund stattfindet, wie Vitess also das angestammte Datenmodell aus MySQL umsetzt. Verbindet sich ein beliebiger MySQL-Client mit einem VTGate, sieht er weiterhin Datenbanken, Tabellen sowie Reihen und Spalten. Doch VTGate schreibt eben diese Strukturen intern um. Und um es Neulingen nicht ganz so leicht zu machen, nutzen die Vitess-Autoren für die Beschreibung ihres Designs ein ganzes Füllhorn an Fachbegriffen, das angehende Vitess-Admins sich dringend auf die Platte schaufeln sollten.
Da gibt es analog zum Namespace etwa den Keyspace, der auf Ebene von Vitess das Gegenstück zu einer klassischen Datenbank in MySQL darstellt. In der Dokumentation zu Vitess beschreiben dessen Autoren einen Keyspace folgerichtig als logische Datenbank. Wo die Inhalte einer solchen Datenbank letztlich landen, hängt von ihrer Konfiguration und ihrem Betriebsmodus ab – und genau hier liegt der Hase im Pfeffer, was die Skalierbarkeit von Vitess angeht. Denn um die gewünschte Skalierbarkeit zu erreichen, setzt Vitess auf Sharding. Zur Erinnerung: Sharding basiert auf dem Prinzip, einen großen Datensatz in viele kleine Datensätze aufzuteilen, die dann auf unterschiedlichen Storage-Backends landen. Das Prinzip kennen Administratoren unter anderem von Mailservern: Genügt der verfügbare Platz im Backend-Storage nicht, hilft nur, einen zweiten Speicher anzuschaffen und die Mailboxen über beide Storage-Instanzen zu verteilen.
Ganz ähnlich verhält sich Vitess beim Sharding. Das VTGate verteilt Daten, die zusammengehören, über alle VTTablet-Instanzen, die es kennt. Den Shard, also ein solches Datenfragment, bezeichnet Vitess dabei explizit als eine Untereinheit des Keyspaces, was wieder ein bisschen mehr der Funktionalität von Vitess preisgibt: Was nach außen hin, also bei der Ansicht durch VTGate, wie eine Datenbank und eine Tabelle aussieht, entspricht in der Realität etlichen Datenhappen, die in den unterschiedlichen VTTablet-Instanzen beheimatet sind. Hier spielen zudem die zuvor bereits erwähnten Betriebsmodi von VTTablet eine Rolle, denn diese vererben sich auf die Shards, die auf einer VTTablet-Instanz liegen. Entsprechend können auch Shards den Primary-Zustand haben oder den Replication-Zustand nutzen. Der Clou ist, dass die unterschiedlichen Rollen eines Shards dabei auf unterschiedliche VTTablet-Instanzen verteilt sind. Für einen Shard kann dann die VTTablet-Instanz 1 Primary sein, für einen anderen Shard die Instanz 2 und so weiter. Das verteilt Last und erlaubt es zugleich, von den vielen Storage-Geräten in unterschiedlichen MySQL-Knoten im Hintergrund zu profitieren, indem deren Bandbreite logisch einfach zusammengeschlossen wird.
Genau hier ergibt sich auch die eigentliche Kernfunktion von VTGate: Es weiß, welche Shards wo beheimatet sind, und kooperiert dazu ebenfalls mit dem Topology Service. Wenn zuvor von einer kompilierten und logischen Sicht auf den Cluster die Rede war, die Clients bekommen, so ist VTGate in Kooperation mit dem Topology-Dienst dafür verantwortlich, eben diese logische Ansicht ad hoc zu kompilieren und an den Client auszuliefern. Fast schon müßig zu erwähnen, dass auch das VTGate skalierbar ist, dass also viele parallele Instanzen von ihm laufen können.
Das leidige Thema Quorum
Wer sich mit verteilten Systemen und spezifisch mit verteiltem Speicher auskennt, wird spätestens hier die Frage stellen, wie Vitess denn das Problem des Quorums löst, das verteilten Systemen immer anhaftet. Tatsächlich spielt das Quorum auch bei der Arbeit mit Shards eine große Rolle, doch machen es sich die Vitess-Entwickler hier sehr einfach: VTGate generiert die Sicht für Clients ja eben auch unter Mitwirkung des Topology-Diensts. Dem haben die Vitess-Entwickler kurzerhand eine Schnittstelle spendiert, um mit externen Konsensusalgorithmen zu kooperieren. In Vitess ist das ab Werk Etcd, das in vielen Kubernetes-Instanzen ohnehin läuft. Alternativ kann Zookeeper zum Einsatz kommen.
Performance und Redundanz
Einen laufenden Vitess-Cluster muss man sich als eine Menge an Keyspaces vorstellen, die sich in Form von Shards wild über alle vorhandenen Instanzen aus VTTablet und MySQL verteilen. Einen Shard gibt es immer mehrmals, und für Leseoperationen kommen auch die Replica-Shards zum Einsatz. Fällt eine Instanz aus, werden die nun fehlenden Shards auf anderen Instanzen des Clusters automatisch neu instanziiert. Das hilft nicht nur der Performance auf die Sprünge, sondern garantiert auch die Redundanz der Anwendung.
Zugleich sorgt VTGate dafür, dass zentrale Konsistenzgarantien etwa nach dem ACID-Prinzip in Vitess weiterhin gelten. ACID ist quasi die Gretchenfrage, die im Kontext verteilter Datenbanken regelmäßig auftaucht. Ob eine Datenbank zuverlässig konsistent ist, entscheidet letztlich in vielen Bereichen über das Wohl und Wehe der Anwendung. Den Vitess-Entwicklern ist es gelungen, durch VTGate als Proxy-Server mit Fremdsprachenkenntnissen in Form eines reimplementierten MySQL-Protokolls genau diese Konsistenz zu erreichen, was technisch durchaus beeindruckt.
Das gilt umso mehr, da Vitess auch noch die logische Einheit einer Zelle (Cell) kennt und damit nicht weniger meint als das gezielte Verteilen von Shards über die Grenzen physischer Standorte hinweg. Auch Setups für Disaster Recovery sind mit Vitess folglich gut zu realisieren, was Vitess einmal mehr von anderen Lösungen wie Galera abhebt.
Tricks und Kniffe
Die Vitess-Entwickler merken in ihrer Dokumentation an verschiedenen Stellen an, dass vernünftige Replikation zwar ein primäres Design-Ziel von Vitess war, aber längst nicht das einzige. Komplementär wollten die Entwickler sich auch einiger Probleme annehmen, die sie an MySQL nervten, die dort aber bis heute ungelöst bleiben. Ein Problem-Evergreen sind die berühmten Queries des Todes, deren Ausführung gefühlte Ewigkeiten dauert. Es ist kein Geheimnis, dass viele Unternehmen besser Geld in einen Consultant für MariaDB investieren würden als in immer leistungsfähigere Hardware für die Datenbank.
Vielerorts sind etwa in Anwendungen über die Jahre Datenbank-Queries entstanden, die MySQL zu riesigen internen Abfragen zwingen und damit im schlechtesten Fall die gesamte Datenbank außer Gefecht setzen können. Das Problem bei MySQL: Ist so eine Query einmal abgesetzt, gibt es von außen keine Möglichkeit mehr, sie frühzeitig zu beenden. Der Administrator schaut seinem MySQL also dabei zu, wie es sich selbst ins Nirwana verfrachtet oder irgendwann vom Kernel per Out-of-Memory-Killer zurechtgewiesen wird.
In Vitess ergibt sich offensichtlich ein Ansatzpunkt, um dieses Problem zu unterbinden. Auch das VTGate kann bei komplexen Anfragen an die Grenzen seiner Leistungsfähigkeit geraten. Anders als im echten MySQL lässt sich eine solche Query per Vtctl aber von außen beenden, sodass für die Funktionalität der Datenbank keine Gefahr besteht. Auch Prävention ist möglich: Aus Client-Sicht transparent lassen sich auf der VTGate-Ebene nämlich »LIMIT«-Anweisungen für bestimmte Abfragearten hinterlegen, die dazu führen, dass Abfragen nach einer bestimmten Wartezeit automatisch terminieren oder gar nicht erst zur Ausführung gelangen.
In ein ähnliches Horn stößt eine weitere Fähigkeit des VTGates, die eher der Performance-Optimierung dient. Klar: Wenn am VTGate sämtliche Anfragen an die Datenbank vorbeikommen, wissen die VTGate-Instanzen auch, was denn in letzter Zeit so alles abgefragt wurde. Da bietet sich Deduplikation an: Stellt ein VTGate oder eine Instanz aus einem VTGate-Gespann fest, dass gerade mehrere identische Leseoperationen gleichzeitig stattfinden, leitet es nur eine an die Backends im Hintergrund weiter, liefert aber für sämtliche Anfragen das Resultat aus.
Erwähnenswert ist schließlich das Pooling von Verbindungen, das Vitess ab Werk unterstützt. Traditionell benötigt jeder Client, der sich mit einer MySQL-Instanz verbindet, dafür eine eigene, autarke TCP/IP-Verbindung mit eigenem Speicher. In Vitess reden Clients bekanntlich aber nicht unmittelbar mit MySQL, sondern nur mit VTGate. Weil Vitess in Go verfasst ist, steht hier das Connection Pooling aus dieser Sprache zur Verfügung: Statt im Hintergrund etliche autarke Verbindungen zu den einzelnen VTTablet-Instanzen und ihren Backends in Form von MySQL aufzumachen, fasst es alle eingehenden Verbindungen in deutlich weniger offenen Verbindungen im Hintergrund zusammen, erreicht damit aber trotzdem eine höhere Bandbreite und mehr Performance.
Für die Cloud gemacht
Anwendungen, die sich an den Cloud-Dunstkreis richten, sind heute in aller Regel mit einer gewissen Erwartungshaltung seitens der Benutzerschaft konfrontiert. So ist eine Annahme etwa, dass Cloud-ready-Anwendungen ab Werk umfangreiche Schnittstellen für Debugging, vor allem aber für die Analyse der Performance bieten. Für Vitess gilt hier keine Ausnahme, und die Entwickler der Software liefern. Praktisch über alles, was Vitess während der Laufzeit tut, führt es aufwendig Buch, und über standardisierte Schnittstellen bietet es auch die Möglichkeit, diese Daten auszulesen. Davon profitieren dann Dienste wie Prometheus (Abbildung 4), für das Vitess ab Werk sogar eine native Schnittstelle bietet.
Dabei beschränkt die Datensammelwut des Diensts sich nicht auf einzelne Anwendungen wie VTGate. Aus den einzelnen VTTablets lassen sich ebenfalls umfangreiche Metrikdaten herausquetschen, die neben einem umfassenden Performance-Monitoring das klassische Event-Monitoring erlauben. Wichtig aus Sicht des Administrators ist dabei vor allem, ein gesundes Monitoring-Mittelmaß zu finden – gerade, weil Vitess implizit redundant ist und gewisse Selbstheilungsfähigkeiten bietet. So erscheint es übertrieben, den Administrator am Samstag um drei Uhr morgens aus dem Bett zu klingeln, weil in einem Cluster aus 20 Vitess-Knoten eine MySQL-Instanz den Geist aufgegeben hat. Vitess wird schließlich im Rahmen der eingestellten Recovery-Werte alle fehlenden Replicas von Shards automatisch und in kurzer Zeit wiederherstellen.
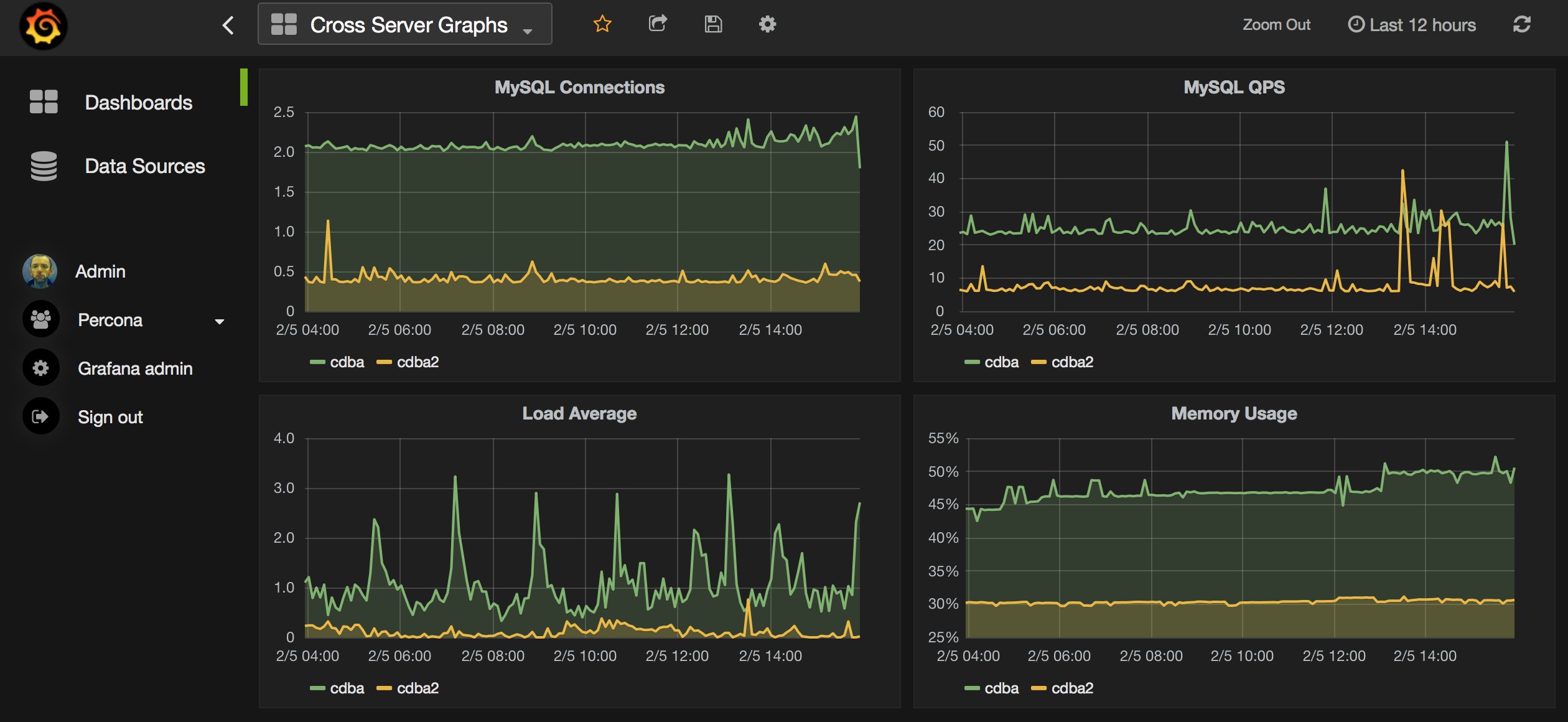
Abbildung 4: MySQL lässt sich in Prometheus – wie hier im Beispiel von Percona – nur per eigenem Exporter integrieren. Vitess hingegen bringt eine eigene Schnittstelle für Prometheus samt Dashboard für Grafana mit. Quelle: Percona
Anders ist die Sache freilich bei zentralen Komponenten gelagert: Fällt ein Load Balancer aus, der mehreren VTGate-Instanzen vorangestellt ist, klappt der Zugriff auf die Datenbank schließlich gar nicht mehr, was Anlass für ein manuelles Eingreifen des Administrators gibt.
Fast nützlicher als das Event-Monitoring dürfte für Vitess-Admins im Alltag ohnehin das ebenfalls mögliche Performance-Monitoring sein. Gerade weil Datenbanken in vielen Setups heute eine zentrale Rolle spielen, ist ihre Performance regelmäßig das Zünglein an der Waage für die Gesamtleistung einer Umgebung. Eben diese lässt sich mittels der aufgezeichneten Metrikdaten aber bis auf die Ebene einzelner Abfragen hinunter penibel überwachen. Auch hier ist mit Vitess deutlich mehr möglich als beispielsweise mit MySQL ab Werk.
Fazit
Die Idee, einen Teil von MySQL auf Basis einer anderen Architektur nachzuimplementieren, löst bei vielen verständlicherweise erst einmal Skepsis aus. Das gilt bei Vitess umso mehr, da die Lösung letztlich ja noch immer ein echtes MySQL im Hintergrund braucht, das als Backend für die VTTablet-Dienste fungiert.
Etwaige Zweifel zerstreuen sich bei näherem Hinsehen jedoch ganz. Anders als die Replikationslösungen für die Datenbanken der ersten Generation wie Galera verfolgt Vitess eine deutlich umfassenderen Ansatz. Der drückt sich in gesteigerter Performance, stärkerer Redundanz, höherer Visibilität von Details (etwa beim Performance-Monitoring) und einer insgesamt deutlich angenehmeren Benutzererfahrung aus.
Dass Vitess als Lösung auf der Höhe der Zeit selbstverständlich über eine perfekte Kubernetes-Integration verfügt und sich etwa über den K8s-Paketmanager Helm unmittelbar in einem Cluster ausrollen lässt, ist da quasi das Sahnehäubchen (Abbildung 5). Wer auf der Suche nach einer skalierbaren Datenbank für die Cloud ist, sollte Vitess jedenfalls auf der Rechnung haben. (jcb)

Abbildung 5: Standesgemäß verfügt Vitess über eine perfekte Integration in Kubernetes und lässt sich darin in wenigen Sekunden zuverlässig ausrollen.
Infos
- Vitess: https://vitess.io





