
© Dmitryi Opishanskyi / 123RF.com
Ob Mensch oder Maschine: Arbeiten mehrere Parteien zusammen, ohne sich abzusprechen, kommen sie sich ins Gehege. Wie Computer mit diesem Problem umgehen, beschreibt diese Folge unserer Serie zur Bash-Programmierung.
Bisher haben wir an dieser Stelle Themen behandelt, die für Bash-Skripte aller Art wichtig sind. Mit dem anfangs ausgerufenen Ziel, ein verteiltes System zu entwickeln, hatte das aber noch nichts zu tun. In dieser und den kommenden Folgen wird sich das ändern: Es soll ein Mechanismus entstehen, mit dem unsere Skripte Nachrichten austauschen können. Damit das gelingt, müssen mehrere Skripte auf dieselben Dateien zugreifen. Würden diese Zugriffe gleichzeitig erfolgen, könnte das allerdings schwer zu diagnostizierende Fehler zur Folge haben. Deshalb bauen wir zwei Module, die gleichzeitige Dateizugriffe zu verhindern helfen.
Ausgeschlossen
Angenommen; wir haben eine Zählvariable mit dem Wert 0, die wir in einer Datei »zaehler« speichern. Folgender Code soll die Variable inkrementieren:
wert=$(< zaehler) ((wert++)) echo "$wert" > zaehler
Führen zwei Skripte diese Befehle nun exakt gleichzeitig aus, lesen beide denselben Wert 0 aus der Datei, inkrementieren ihn und schreiben jeweils den Wert 1 zurück. Obwohl der Zähler zweimal inkrementiert wurde, ist sein Wert somit nur um eins größer als vorher. Diese Klasse von Fehlern nennt man Race Condition. Sie kann immer dann auftreten, wenn mehrere Prozesse gleichzeitig auf Daten zugreifen. Die wichtigste Methode, um derartige Race Conditions zu verhindern, heißt Mutex. Mit ihr wollen wir beginnen.
Ein Mutex – der Begriff steht als Kürzel für Mutual Exclusion, also gegenseitiger Ausschluss – kennt zwei Operationen: Man kann ihn schließen oder öffnen. Wer den Mutex schließt, betritt eine sogenannte kritische Sektion, in der sich nur ein Prozess aufhalten darf. Am Ende der kritischen Sektion öffnet man den Mutex wieder. Das erlaubt dem nächsten Prozess, die kritische Sektion zu betreten. Sie können sich die kritische Sektion also als einen Raum vorstellen und den Mutex als dessen Tür. Versucht ein zweiter Prozess, die kritische Sektion zu betreten, während sich ein erster bereits darin aufhält, muss der zweite Prozess warten, bis der erste die Tür wieder öffnet, also die kritische Sektion verlässt.
Das Schließen des Mutex implementieren wir in »mutex_lock()«, das Öffnen in der Funktion »mutex_unlock()«. Die beiden Funktionen verwendet man immer nach dem folgenden Muster:
mutex_lock <I>mutex_name<I> # ... kritische Sektion ... mutex_unlock <I>mutex_name<I>
Innerhalb der Mutex-Funktionen gilt es, den Zustand des Mutex so zu speichern, dass er auch für andere Prozesse sichtbar ist. Da sich hierfür Shell-Variablen nicht eignen, bleibt nur das Dateisystem. Naheliegend wäre es, ein Lockfile zu nutzen, das man beim Schließen des Mutex erstellt und beim Öffnen entfernt. Warum Lockfiles keine gute Idee sind, wird aber schnell klar, wenn man die Funktion »mutex_trylock()« in Listing 1 betrachtet.
Listing 1
Fehlerhaftes mutex_trylock()
mutex_trylock() {
local mutex="$1"
local -i locked
locked=$(< "$mutex")
if (( locked == 0 )); then
echo "1" > "$mutex"
return 0
fi
return 1
}
Die Funktion soll versuchen, einen Mutex zu schließen, und dem Aufrufer per Rückgabewert mitteilen, ob das erfolgreich war. Sie liest dazu erst den Wert des Mutex und prüft dann, ob der Mutex geschlossen ist. Wir stehen also wieder vor demselben Problem wie am Anfang: Wenn zwei Prozesse exakt gleichzeitig »mutex_trylock()« aufrufen, finden beide einen noch unverschlossenen Mutex vor, schließen ihn, und betreten dann gemeinsam die kritische Sektion. Das Problem rührt daher, dass das Testen und das Schließen des Mutex separate Schritte sind. Damit kein anderer Prozess dazwischenkommen kann, muss beides in einem untrennbaren Schritt erfolgen, einer sogenannten atomaren Operation.
Die Coreutils stellen uns zwei Befehle bereit, die wir zu diesem Zweck nutzen können: »ln« und »mkdir«. Der Befehl »ln« erzeugt mit der Option »-s« einen symbolischen Link. Falls der Link bereits existiert, gibt er einen Fehler zurück. Ruft man den Befehl mit denselben Pfaden mehrmals gleichzeitig auf, ist nur einer der Aufrufe erfolgreich, und die anderen geben einen Fehler zurück. Der Befehl zeigt also exakt das Verhalten, das wir zum Schließen eines Mutex brauchen.
Der zweite Befehl, »mkdir«, verhält sich ähnlich. Er erstellt aber keinen symbolischen Link, sondern ein Verzeichnis. Ob wir nun Symlinks oder Verzeichnisse verwenden, ist Geschmackssache. Symbolische Links haben aber den Vorteil, dass sich das Ziel des Links zweckentfremden lässt, um zusätzliche Informationen zu speichern. Wir entscheiden uns daher für Symlinks und speichern die PID des jeweiligen Prozesses im Ziel des Links (Listing 2).
Listing 2
Korrektes mutex_trylock()
mutex_trylock() {
local mutex="$1"
if ! ln -s "$$" "$mutex" 2>/dev/null; then
return 1
fi
return 0
}
Wir verwenden nun »mutex_trylock()«, um die Funktion »mutex_lock()« zu schreiben, die den aufrufenden Prozess blockiert, bis der Mutex erfolgreich geschlossen wurde. Dazu muss sie lediglich »mutex_trylock()« in einer Schleife aufrufen. Wichtig ist, dass sich der Prozess mit »sleep« schlafen legt, wenn er den Mutex nicht schließen konnte. Anderenfalls würde er mit kontinuierlichen Aufrufen von »mutex_trylock()« einen CPU-Kern komplett auslasten – sogenanntes Busy Waiting oder aktives Warten.
Des Weiteren ist es für manche Anwendungen wichtig, einen Timeout zu definieren, nach dessen Ablauf die Funktion aufgeben soll. Wir statten »mutex_lock()« deshalb mit einem zweiten Parameter aus, mit dem der Aufrufer ein Zeitlimit in Sekunden festlegen kann. Wurde kein Zeitlimit übergeben, soll die Funktion den Aufrufer so lange blockieren, bis der Mutex geschlossen ist (Listing 3).
Listing 3
Blockieren mit Timeout
mutex_lock() {
local mutex="$1"
local -i timeout="${2--1}"
while ! mutex_trylock "$mutex"; do
if (( timeout == 0 )); then
return 1
fi
(( timeout-- ))
sleep 1
done
return 0
}
Anders als beim Schließen des Mutex spielt es beim Öffnen keine Rolle, ob die Operation atomar ist. Ein Aufruf von »rm« genügt daher, um »mutex_unlock()« zu implementieren. Die Funktion sehen Sie in Listing 4.
Listing 4
Mutex öffnen
mutex_unlock() {
local mutex="$1"
if ! rm "$mutex" 2>/dev/null; then
return 1
fi
return 0
}
Die drei Funktionen speichern wir nun zusammen mit einem leeren Modulkonstruktor in einem neuen Modul, das wir »mutex« nennen und unter »/usr/local/share/bms/include/mutex.sh« ablegen. Mit einem Skript wie dem in Listing 5 testen wir, ob der Mutex richtig funktioniert: Zeitversetzt starten wir zwei Prozesse, von denen der erste in der kritischen Sektion mehrere Sekunden verweilt, um den anderen Prozess am Mutex warten zu lassen.
Listing 5
B wartet auf A
prozess() {
local name="$1"
echo "$name: Warte auf Mutex"
mutex_lock mutex
echo "$name: Kritische Sektion betreten"
sleep 5
echo "$name: Verlasse kritische Sektion"
mutex_unlock mutex
}
main() {
prozess "A" &
sleep 1
prozess "B"
}
Die Ausgabe des Skripts sollte, sofern wir alles richtig gemacht haben, so ähnlich aussehen wie in Abbildung 1: Prozess A betritt die kritische Sektion und verweilt dort für fünf Sekunden. Prozess B, der eine Sekunde zeitversetzt startete, wartet nun etwa vier Sekunden, bis A die kritische Sektion verlässt und er sie betreten kann.

Abbildung 1: Kritische Sektionen werden seriell ausgeführt.
Auf die Plätze
Mutexes können aber noch mehr. Wenn man einen Mutex rückwärts verwendet, er also im Normalzustand geschlossen ist, kann man mit ihm eine ungeordnete Warteschlange realisieren. Ein Verbraucherprozess reiht sich in die Warteschlange ein, indem er »mutex_lock()« aufruft. Ein Erzeugerprozess kann nun durch Aufruf von »mutex_unlock()« einen der wartenden Prozesse durchlassen. Welcher der Prozesse Vorfahrt erhält, hängt allerdings weniger von der Reihenfolge der Prozesse ab als von ihrer Priorität und vom Linux-Kernel.
Es gibt noch einen Haken: Da ein Mutex nur zwei Zustände hat, funktioniert diese Schlange nur dann, wenn die Verbraucher sich genauso schnell in die Schlange einreihen wie die Erzeuger sie durchlassen. Wenn zwei Erzeuger nacheinander den Mutex öffnen, ohne dass sich ein Verbraucher dazwischen eingereiht hatte, verfällt der ungenutzte Platz in der Schlange. Dient die Warteschlange dazu, Nachrichten zwischen Prozessen zu übertragen (wie wir es vorhaben), dann würde eine Nachricht spurlos verschwinden. Für verlässliche Kommunikation ist das absolut inakzeptabel.
Wir erweitern den Mutex daher um einen Zähler, der inkrementiert wird, wenn ein Erzeuger den Mutex öffnet, und dekrementiert wird, sobald ein Verbraucher den Mutex schließt. Da Erzeuger und Verbraucher aber gleichzeitig den Zähler verändern könnten, muss man diesen wiederum durch einen weiteren Mutex schützen. Dieses Konstrukt mit einem zählenden Mutex nennt man Semaphor – mit dem gleichnamigen optischen Telegrafen hat es allerdings nicht viel gemein.
Wir implementieren unsere Semaphoren in dem Modul »sem«. Angelehnt an die API der POSIX-Semaphoren nennen wir die Funktion zum Einreihen »sem_wait()« und die zum Durchlassen eines wartenden Prozesses »sem_post()«. Erstere implementieren wir wie in Listing 6 gezeigt. Den rückwärts benutzten Mutex nennen wir »Waitlock«, den Mutex, der den Zähler schützt »Countlock«. Eine Hilfsfunktion »_sem_counter_dec()« dekrementiert den Zähler und gibt seinen neuen Wert aus. Sollte der Wert größer als null sein, muss der Prozess den Waitlock hinter sich wieder öffnen, da anderenfalls der nächste Aufruf von »sem_wait()« blockieren würde, bis »sem_post()« aufgerufen wird.
Listing 6
An einem Semaphor warten
:sem_wait() {
local sem="$1"
local -i timeout="${2--1}"
local -i err
err=1
if ! mutex_lock "$sem/waitlock" "$timeout"; then
return 1
fi
if mutex_lock "$sem/countlock"; then
local -i counter
counter=$(_sem_counter_dec "$sem/counter")
if (( counter > 0 )); then
mutex_unlock "$sem/waitlock"
fi
mutex_unlock "$sem/countlock"
err=0
fi
return "$err"
}
Die Funktion »sem_post()« fungiert als Gegenstück zu »sem_wait()«. Sie lässt einen Prozess passieren, der am Semaphor wartet. In der Funktion müssen wir den Semaphor also in umgekehrter Reihenfolge manipulieren: Wir schließen den Countlock, inkrementieren den Zähler, öffnen den Countlock und öffnen erst dann den Waitlock (Listing 7).
Listing 7
Einen Prozess passieren lassen
sem_post() {
local sem="$1"
local -i err
err=1
if mutex_lock "$sem/countlock"; then
_sem_counter_inc "$sem/counter"
mutex_unlock "$sem/countlock"
mutex_unlock "$sem/waitlock"
err=0
fi
return "$err"
}
Nun stellt sich allerdings die Frage, wie man einen Semaphor überhaupt erstellt. Schließlich kennt die Shell keine Datentypen wie C-Structs. Die zwei Funktionen lassen aber schon erahnen: Bei einem Semaphor handelt es sich um ein Verzeichnis, das zwei Mutexes und einen Zähler enthält. Der Parameter »sem« der Funktionen ist das Shell-Pendant eines Pointers auf ein C-Struct: der Pfad eines Verzeichnisses. Die Funktion »sem_init()«, die einen neuen Semaphor »sem« erzeugt und mit dem Wert »value« initialisiert, implementieren wir daher wie in Listing 8 gezeigt. Das fertige Modul legen wir unter »/usr/local/share/bms/include/sem.sh« ab.
Listing 8
Semaphoren erzeugen
sem_init() {
local sem="$1"
local -i value="$2"
local err
err=1
if ! mkdir "$sem"; then
log_error "Konnte Semaphor $sem nicht erstellen"
return 1
fi
if ! mutex_trylock "$sem/countlock"; then
log_error "Konnte $sem/countlock nicht schliessen"
else
if (( value == 0 )) &&
! mutex_trylock "$sem/waitlock"; then
log_error "Konnte $sem/waitlock nicht schliessen"
elif ! echo "$value" > "$sem/counter"; then
log_error "Konnte $sem/counter nicht setzen"
else
err=0
fi
mutex_unlock "$sem/countlock"
fi
if (( err != 0 )); then
rm -rf "$sem"
fi
return "$err"
}
Um zu testen, ob der Semaphor richtig funktioniert, schreiben wir nun ein Skript, das einen Erzeuger und zwei Verbraucher simuliert. Der Erzeuger soll eine zufällige, einstellige Anzahl an Elementen erzeugen, die von den Verbrauchern konsumiert werden.
Für unsere Simulation heißt das: Der Erzeuger soll in einer Schleife »sem_post()« aufrufen, eine kurze Nachricht ausgeben und zwischen den Aufrufen eine zufällige Dauer (unter drei Sekunden) warten. Die Verbraucher sollen um die erzeugten Elemente konkurrieren: Sie rufen »sem_wait()« so lange in einer Schleife auf, bis keine Elemente mehr vorhanden sind. Mit einem Timeout von 10 Sekunden erreichen wir, dass die Verbraucher nicht ewig auf Elemente warten.
Mit dem Befehl »wait« weisen wir die Shell an, auf das Ende der drei Prozesse zu warten, die wir mittels »&« im Hintergrund laufen lassen. Zuletzt wird der Semaphor mit einem Aufruf von »sem_destroy()« entfernt. Da sich hinter der Funktion nicht viel mehr als ein Aufruf von »rm« versteckt, sparen wir uns hier eine Beschreibung. Das gesamte Testskript sehen Sie in Listing 9.
Listing 9
Konkurrierende Verbraucher (Auszug)
erzeuger() {
local -i i
for (( i = 0; i < RANDOM % 10; i++ )); do
sleep $((RANDOM % 3))
sem_post sem
echo "E: Element erzeugt ($i)"
done
}
verbraucher() {
local name="$1"
local -i i
for (( i = 0; 1; i++ )); do
echo "$name: Warte auf Element"
if ! sem_wait sem 10; then
echo "$name: Timeout"
return 1
fi
echo "$name: Element verbraucht ($i)"
done
}
main() {
if sem_init sem 0; then
erzeuger &
verbraucher "V1" &
verbraucher "V2" &
wait
sem_destroy sem
fi
}
Das Skript führen wir nun mehrmals nacheinander aus. Da die Reihenfolge, in der die Verbraucher die Elemente konsumieren, sich bei jedem Durchlauf verändert, erhalten wir nicht jedes Mal dieselbe Ausgabe. Eines bleibt allerdings gleich: Die Verbraucher können, wie in Abbildung 2 zu sehen, immer erst dann fortfahren, wenn der Erzeuger ein Element erzeugt hat.
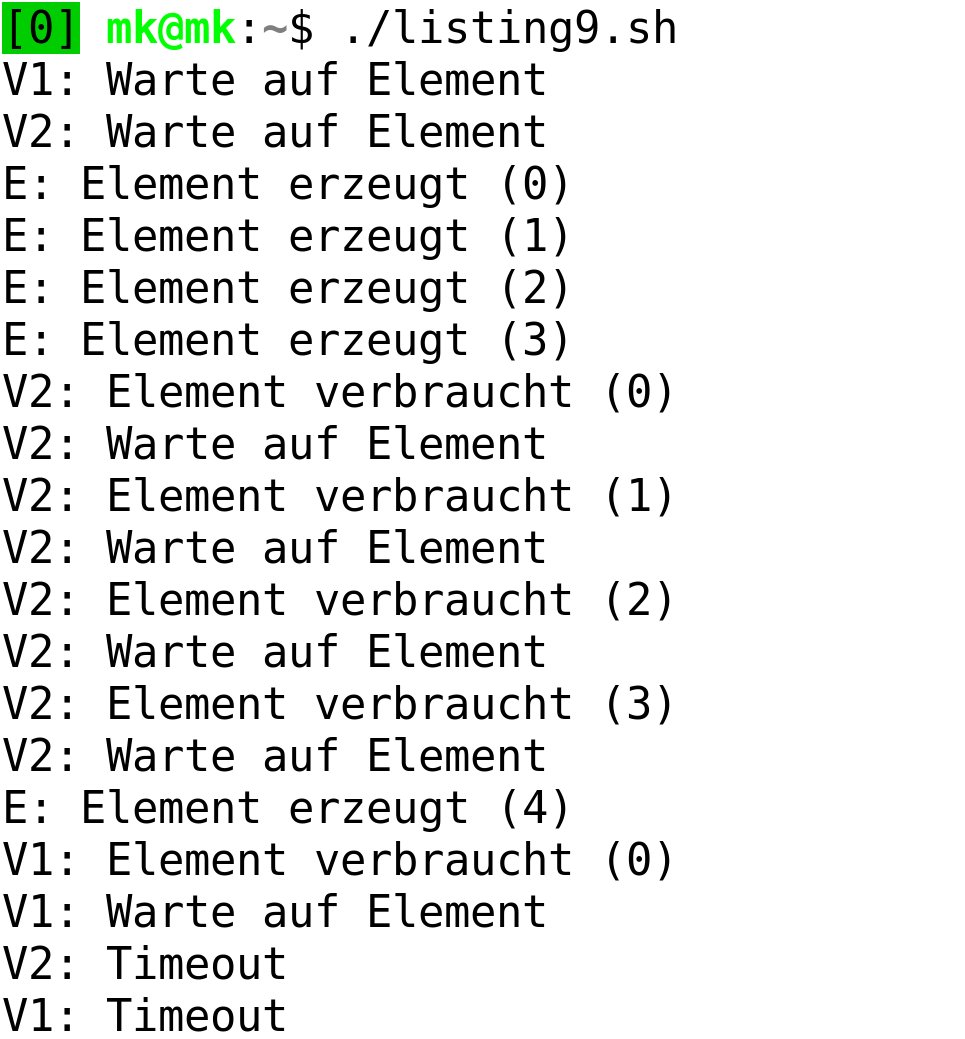
Abbildung 2: Die Reihenfolge der Prozesse ist nicht deterministisch.
Fazit
Mit Mutexen und Semaphoren haben wir alles, was wir brauchen, um Skripte mit vielen nebenläufigen Prozessen zu schreiben. Das Testskript, das wir zum Schluss entwickelt haben, lässt schon erahnen, wie es weitergeht: Das nächste Mal werden wir eine Datenstruktur implementieren, mit der wir Nachrichten zwischen mehreren Prozessen austauschen können. (jcb)





