
© Jacek Nowak / 123RF.com
In Zeiten der Cloud-ready-Architektur und Mikrokomponentenanwendungen müssen auch Datenbanken nach Maß mitwachsen oder schrumpfen können. PostgreSQL bietet für eine solche Skalierung bis heute keine freie oder standardisierte Lösung. Citus will das ändern.
Datenbanken bilden die Basis für viele Anwendungen. In modernen Cloud-ready-Apps sind sie oft genug die einzige Komponente, die überhaupt noch persistente Daten enthält, während alle anderen Teile der Anwendung nach Belieben kommen und gehen.
Gerade in jüngerer Vergangenheit wird dabei allerdings auch ein Problem immer offensichtlicher: Das Grunddesign der meisten Datenbanken, ob MariaDB, PostgreSQL oder sonst ein Vertreter, ist oft mehrere Jahrzehnte alt. Es stammt damit aus einer Zeit, in der vom Skalieren in die Breite auf Ebene einer Anwendung noch keine Rede war. Wer in den 2000ern mehr Wumms in seiner Datenbank brauchte, kaufte fettere Hardware und hoffte, dass das genügen würde. Wollen Datenbanken heute mit ihren Mikroarchitekturgegenstücken auf der Anwendungsseite mithalten, müssen sie das verteilte Speichern von Daten unterstützen. Nur dann ist das Skalieren in die Breite – im Grunde ein Synonym für verteiltes Speichern von Daten – nämlich realistisch.
PostgreSQL präsentiert sich in dieser Hinsicht gewissermaßen als Nachzügler. Für MariaDB und zuvor MySQL etwa existiert Galera als Multi-Master-Lösung seit einer gefühlten Ewigkeit. Zwar impliziert Galera eigene Herausforderungen in Sachen Design und Betrieb, hat aber in vielen Rechenzentren heute seinen festen Platz. Vielen gilt es gar als Königsweg, um skalierbare MySQL-Architekturen zu bauen.
Anders sieht die Sache bei PostgreSQL aus. Zwar gibt es auf dem Markt etliche Lösungen, die PostgreSQL um echte Multi-Master- und Distributed-Storage-Fähigkeiten erweitern. Zum Teil gibt es sie aber nur als Bestandteil eines kommerziellen Produkts, oft stehen sie auch nicht unter einer offenen Lizenz. Zum Quasi-Standard hat sich keiner der Ansätze gemausert.
Citus [1] möchte das ändern: Die in den USA ansässige Firma verspricht Admins nicht weniger als das Wunschlos-glücklich-Paket für skalierbares PostgreSQL. Dabei kommt ihr ein Konzept zu Hilfe, das passionierte Admins vielleicht noch von ihrer Arbeit mit Mailservern kennen: Sharding. Wie genau das funktionieren soll, ob das Produkt hält, was der Hersteller verspricht, und was für und gegen Citus spricht, verrät dieser Artikel.
Blast from the past
Sieht man sich die Architektur von Citus an, fallen im direkten Vergleich mit anderen skalierbaren Ansätzen für PostgreSQL etliche Unterschiede auf. So setzt die Konkurrenz regelmäßig auf eigene Module für das Finden eines Datenkonsenses und kombiniert diese mit der ohnehin in PostgreSQL vorhandenen Streaming Replication.
Noch ganz anders geht Yugabyte vor, im Grunde gar kein richtiges PostgreSQL: Hier werkelt unter der Haube ein eigener Key-Value-Store, dem der Hersteller eine Schnittstelle für verschiedene Protokolle als Mittlerschicht zwischenschaltet. Die spricht Redis, aber eben auch weite Teile des PostgreSQL-Protokolls. Kritiker bemängeln bei Yugabyte gern, dass es eben nicht alle Befehle von PostgreSQL und dessen SQL-Dialekt unterstützt.
Bei Citus ist das anders: Es setzt im Hintergrund auf mehrere Ebenen des echten PostgreSQL und kann folgerichtig dessen gesamten SQL-Dialekt abbilden. Das wirft freilich die Frage auf, wie Citus unter der Haube für Konsistenz sorgt und wie es die Skalierbarkeit in die Breite denn realisiert.
ACID als Herausforderung
Wer sich mit Datenbanken etwas auskennt und die eingangs erwähnten Anmerkungen zum Thema Konsensalgorithmus im Hinterkopf hat, der ahnt vermutlich bereits, wohin die Reise bei Citus geht. Einer zentralen Herausforderung beim Design verteilter Datenbanken sieht Citus sich ebenso gegenüber wie jeder andere Ansatz, der PostgreSQL fit für skalierbare Umgebungen machen möchte, nämlich den Anforderungen des sogenannten ACID-Prinzips.
ACID steht als Abkürzung für Atomicity, Consistency, Isolation und Durability. Der Begriff beschreibt die Art und Weise, wie eine Datenbank sich Clients gegenüber verhalten muss, wenn diese Daten in ihr verändern. Atomicity meint, dass Schreibvorgänge in der Datenbank nur entweder vollständig oder gar nicht ausgeführt werden dürfen. Bricht eine Transaktion mittendrin ab, muss die Datenbank dem nächsten Client, der auf die Daten zugreift, den vollständigen alten Datensatz präsentieren statt eines halb veränderten neuen.
Consistency bedeutet, dass alle Daten stets konsistent bleiben, also allen vorgegebenen Regeln genügen, einschließlich aller Constraints, Kaskaden und Trigger. Isolation heißt, dass keine Transaktion eine andere beeinflussen darf. So darf eine Transaktion keine Daten lesen, die eine andere noch nicht fertig geschrieben hat. Durability erfordert, dass einmal committete Änderungen an der Datenbank dauerhaft gespeichert bleiben. Selbst wenn sich unmittelbar im Anschluss ein Crash ereignen sollte, müssen die bestätigten Änderungen gesichert sein.
Es liegt auf der Hand, dass diese Anforderungen schon bei einer nur lokalen Datenbank schwierig zu erfüllen sind. Geht es um verteilte Systeme, kommt noch ein zusätzlicher Layer an Komplexität hinzu. Die meisten Lösungen für skalierbares PostgreSQL setzen auf einen Konsensalgorithmus, im Normalfall Paxos oder Raft, um des Problems Herr zu werden. Sie arbeiten, wie es etwa auch der Cluster-Manager Pacemaker tut, indem sie einen Verbund aus Datenbankinstanzen in logische Partitionen aufteilen. Schreibzugriff erhält stets nur jene Partition, die die Mehrheit der Knoten auf ihrer Seite weiß. Das sorgt dafür, dass einzelne Nodes ausfallen dürfen, führt aber zu Performance-Problemen.
Citus wählt deshalb einen anderen Weg: Es unterteilt die Daten innerhalb des Clusters zunächst in logische Segmente, die sogenannten Shards. Ein Shard ist in Citus stets eine Tabelle in einer PostgreSQL-Datenbank. Solche Shards lassen sich auf beliebig viele Instanzen von PostgreSQL im Hintergrund verteilen. Als eine Art Gateway stellt Citus den Shards dann die sogenannten Coordinators (Abbildung 1) voran. Sie enthalten die Metadaten aller gespeicherten Datenbanken und suchen für ihre Clients bei Lese- oder Schreibanfragen die passenden Daten von den PostgreSQL-Instanzen im Hintergrund zusammen (Abbildung 2). Bei Schreibvorgängen leiten sie Daten an diese weiter. Sie folgen dabei aber nicht einem Konzept auf Basis eines Konsensalgorithmus, stattdessen kommt das 2-Phase-Commit-Prinzip zum Einsatz. Hier gilt ein Schreibvorgang erst dann als abgeschlossen, wenn er auf dem zuständigen Shard-Server angekommen ist und der den Empfang quittiert hat.
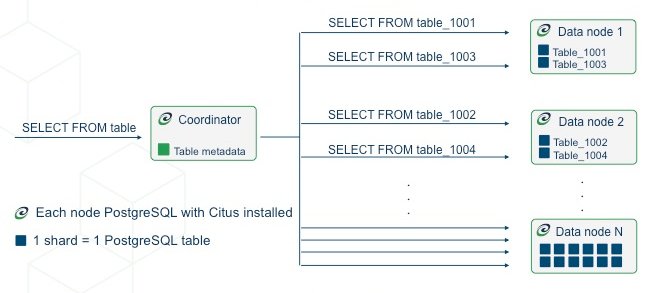
Abbildung 1: Citus teilt Daten auf verschiedene PostgreSQL-Instanzen auf und stellt diesen Shards einen Coordinator für den Zugriff voran. Quelle: Citus

Abbildung 2: Weil von den Worker-Knoten im Hintergrund beliebig viele Instanzen laufen dürfen, skaliert Citus nahtlos in die Breite.
Der 2-Phase-Commit-Ansatz ist deutlich schneller als der auf Basis von Paxos oder Raft, hat jedoch einen entscheidenden Nachteil: Ist das für einen Shard zuständige Backend nicht verfügbar, stehen dessen Daten weder für Schreib- noch für Lesevorgänge bereit. Citus umgeht das Problem, indem es die in PostgreSQL ohnehin vorhandene Streaming-Replikation einsetzt, um für einzelne Shards Hochverfügbarkeitspartner zu bauen. Fällt ein Backend mit Shards aus, soll dessen Streaming-Replication-Partner schnell verfügbar sein und die Lücke stopfen.
Ein kleiner Haken dabei: Der Administration muss diese Art der Replikation erst mühsam händisch einrichten. Citus verlässt sich hier großteils auf Technik, die PostgreSQL ohnehin bietet. Einen passenden Assistenten bietet die Software bedauerlicherweise nicht an.
Schwieriges Setup
Überhaupt dürften Einrichtung und Ausrollen bei Citus aktuell die neuralgischsten Punkte in der Produktstory sein, und zwar aus mehreren Gründen. Datenbanken sind implizit komplex, viele Administratoren müssen sich damit herumschlagen, ohne ausgewiesene Fachleute für PostgreSQL oder andere SQL-Dialekte zu sein. Etliche Hersteller sind deshalb dazu übergegangen, für ihre Produkte entweder umfassende Dokumentation anzubieten oder gleich ab Werk eine Automation zu liefern, die dem Administrator einen fertigen Datenbank-Cluster auf die Festplatten zaubert.
Das wäre auch im Falle von Citus ausgesprochen wünschenswert, denn neben den einzelnen PostgreSQL-Instanzen auf den Coordinator- und Backend-Knoten muss der Admin hier auch die Citus-Extension für PostgreSQL installieren. Sollen weitere Features wie die erwähnte Streaming-Replikation zum Einsatz kommen, steht auch noch deren Setup auf dem Plan. In Summe hat der Admin selbst ohne Tuning sicherlich etliche Stunden mit dem initialen Einrichten eines Citus-Clusters zu tun, besonders dann, wenn er mit dem Produkt bis dato keine Erfahrung sammeln konnte.
Am mühseligen Setup trägt die Citus-Datenbank allerdings gehörige Mitschuld. In der Dokumentation des Produkts findet sich lediglich eine kurze Anleitung hinsichtlich der Punkte, die Admins auf den Shard- und Coordinator-Knoten ausführen müssen, um die Pakete für Citus zu installieren und in Gang zu setzen. Die liegen obendrein nur für Ubuntu und RHEL vor. Wer also etwa Debian oder SLES nutzt, schaut in die Röhre.
Schlimmer noch ist, dass sich in der gesamten Citus-Dokumentation keine Anleitung findet, um einen für die Produktion geeigneten, leistungsfähigen Citus-Cluster zu bauen, der auch Replikation von Shard-Knoten unterstützt. Lapidar verweist die Anleitung hier auf die Dokumentation von PostgreSQL selbst. Eigentlich ist der Autor dieser Zeilen ein großer Verfechter des Ansatzes, Dokumentation nicht zu duplizieren, sondern lieber auf bereits existierende zu verweisen. Bei einem Setup mit der Komplexität einer verteilten PostgreSQL-Datenbank erscheint dieser Ansatz allerdings nicht sonderlich realitätsnah. Hier wünscht der Administrator sich zu Recht eine Schritt-für-Schritt-Anleitung.
Noch besser wäre die bereits erwähnte Automationslösung seitens des Herstellers. Dass es auf dem Markt zu viele Automatisierer gibt und eine verhältnismäßig kleine Firma wie Citus nicht für alle gängigen Optionen Varianten anbieten kann, gilt dabei nicht als Ausrede: Spätestens seit Ansible (Abbildung 3) lässt sich eine komplette Automation für ein Produkt wie Citus in verhältnismäßig wenig Code realisieren, und – wichtiger noch –, ohne auf den Zielsystemen eine besondere Infrastruktur vorauszusetzen.
Ansible per se ist schnell installiert. Bei Vorliegen eines fertigen Playbooks bietet es alles, was der Administrator braucht um loszulegen, nachdem er seine lokalen Systeme in eine neue Inventardatei geschrieben hat. Auch hier kann Citus nicht zufriedenstellen: Im Netz findet sich zwar ein Ansible-Modul dafür, doch das kommt nicht vom Hersteller und hat seit 2020 auch keine Updates mehr erhalten.
Abbildung 3: Citus stellt für sein Produkt weder eine offizielle Kubernetes-Integration noch eine aktuelle Automation mittels Ansible zur Verfügung. Das ist für eine skalierbare Anwendung heute eigentlich zu wenig.
Pech bei Kubernetes
Die Missstände in Sachen Dokumentation und Automation bei Citus wären noch verzeihlich, käme das Programm stattdessen mit einer brauchbaren Kubernetes-Integration daher. Das ergäbe aus vielen Gründen durchaus Sinn. Eine verteilte Datenbank wie PostgreSQL mit entsprechender Vorarbeit, verlässlicher Konsistenz und Skalierbarkeit in die Breite wirkt ja im Grunde wie geschaffen für die Welt der Cloud-Native-Anwendungen. Kombiniert mit einer Netzwerkkomponente wie Istio wären sogar Faktoren wie die Streaming-Replikation für höhere Verfügbarkeit im 2-Phase-Commit-Kontext innerhalb von Kubernetes deutlich leichter zu realisieren als mittels der klassischen Methode auf nacktem Blech.
Obendrein böte Kubernetes einen Haufen Funktionalität, die dem Admin das Setup erheblich erleichtern würde. Mittels eigener Custom Resource Definitions (CRDs) könnte man Citus-Instanzen in Kubernetes unmittelbar steuern. Kubernetes wäre in der Lage, ad hoc und bedarfsabhängig neue Backends für zusätzliche Shards anzulegen oder den Cluster auch wieder zu verkleinern. Replikation & Co. wären über die Controller in Kubernetes spielend leicht und für den Administrator komplett automatisiert zu konfigurieren. Dass das kein Hirngespinst ist, sondern ein zur Realität passender Ansatz, zeigt die Konkurrenz von Yugabyte. Die liefert ihren Key-Value-Store mit PostgreSQL-Frontend nämlich gleich mit einem passenden Operator für Kubernetes aus, der das Deployment zum Kinderspiel macht (Abbildung 4).
Abbildung 4: Die Konkurrenz macht es besser: Yugabyte kommt mit kompletter Integration in Kubernetes daher und erleichtert Admins die Arbeit dadurch erheblich. Quelle: Yugabyte
Völlig anders sieht die Sache bei Citus aus. Hier findet sich im Bugtracker des Projekts auf Github ein auf das Jahr 2016 datierter Fehlerbericht, der vom Projekt eine rudimentäre Einbindung in Kubernetes und zumindest das Bereitstellen entsprechender Container-Abbilder fordert. Der Fehlerbericht ist bis heute im Status “offen”, und obwohl etliche Nutzer der Software ihr Interesse an einem passenden Container und entsprechender Integration bekundet haben, ist der Hersteller hier bis heute nicht aus dem Quark gekommen.
Anders gesagt: Die gesamte Integration in Kubernetes, die bei vielen anderen Anbietern vergleichbarer Produkte praktisch zum guten Ton gehört, fehlt bei Citus vollständig. Vor dem Hintergrund des Anwenderkreises, an den die Software sich richtet und innerhalb dessen sie übrigens auch bewusst Werbung für sich selbst macht, wirkt das nachgerade grotesk.
Eigentlich vernünftig
Das gilt umso mehr, da Citus wegen der bereits beschriebenen architektonischen Details eigentlich eine solide Lösung für verteiltes PostgreSQL darstellt. Seit Citus 11 gehören zudem alle Features, die zuvor der Enterprise-Edition der Software vorbehalten waren, zum Hauptprodukt und stehen unter einer freien Lizenz. Das sorgt dafür, dass Citus der Konkurrenz in vielen Dingen weit voraus ist.
Ein paar Beispiele machen das sehr deutlich. Zunächst sorgt die verteilte Struktur der Shards in Citus dafür, dass die Anwendung nicht nur für klassische Datenbankanwendungen zu gebrauchen ist, die eine relationale Datenbank erwarten. Weil die Coordinators Daten auf beliebig viele Backends verteilen können und ihnen damit beliebig viel Bandbreite zur Verfügung steht, eignet sich Citus stattdessen auch für den Einsatz als Zeitreihendatenbank. Das zentrale Zugriffsmuster auf Citus bleibt dabei zwar die Tabelle, doch sind die Koordinatoren so leistungsstark, dass sie in der Außenwirkung vergleichbar viele Transaktionen in ähnlicher Zeit hinbekommen wie Prometheus oder InfluxDB.
Dass es auf dem Markt relativ wenig Software gibt, die Zeitreihendaten auf Basis des PostgreSQL-Dialekts verarbeitet, ist hier sicher ein Wermutstropfen. Die Art und Weise, wie Citus das Setup seiner Datenbank verkompliziert hat, weckt aber keine Hoffnungen, dass sich an diesem Problem in Zukunft etwas ändert.
Maßgeschneidert
An dieser Stelle glänzt die Citus-Dokumentation immerhin durch Vollständigkeit sowie durch Verständlichkeit. Wer bereits mit PostgreSQL gearbeitet hat, muss sich an etliche Änderungen in der Art und Weise gewöhnen, wie der Zugriff auf die gespeicherten Daten in Citus verglichen mit echtem PostgreSQL funktioniert. Hier wird offensichtlich, dass die eigentliche Zauberkomponente im Gespann vorrangig die Coordinators sind, die auf der einen Seite von Clients Anfragen annehmen und diese dynamisch so verarbeiten, dass die bestmögliche Performance für den Client herauskommt.
Die Krux: Wer bestimmte Design-Muster von PostgreSQL kennt, kann diese Erfahrung nicht automatisch auf Citus umlegen, denn hier funktionieren Zugriffsmuster anders. Die Citus-Entwickler erklären in ihrer Dokumentation anhand mehrerer Beispiele ausführlich, für welchen Einsatzzweck sich welche Architektur von Datenbanken und Tabellen besonders eignet. Wer etwa Performance-Daten in Citus ablegen will, findet eine Anleitung für ein Zugriffsmuster, das in der Grundstruktur einer Zeitreihe und nicht einer klassischen relationalen Datenbank entspricht. Allerdings impliziert das auch, dass Setups auf Basis von Citus regelmäßig spezifisch für Citus konzipiert sind. Ein Schelm, wer hier die Absicht des Anbieters vermutet, durch die Citus-typischen Features das Programm als Bundle zusammen mit Endanwendersoftware an den Mann oder die Frau zu bringen.
Sinnvoll geht Citus auch in Sachen Kompression und Performance vor. So verspricht der Hersteller durch Parallelisierung von Anfragen auf die verschiedenen Citus-Shards im Hintergrund eine bis zu 300 Mal schnellere Verarbeitung als beim klassischen PostgreSQL. Hier hilft es freilich auch, wenn der Administrator die passende Hardware unterfüttert: Weil Shards in der Breite beliebig oft vorhanden sein können, empfiehlt sich auf den einzelnen Systemen der Einsatz pfeilschneller Flash-Speicher. Die sorgen zudem dafür, dass beim Faktor der Latenz das Netzwerk der Flaschenhals ist und nicht länger das einzelne Speichergerät.
Multi-Tenant-Setups
Obendrein haben die Entwickler sich viele Gedanken über die Themen Security und Compliance gemacht. So verfügt Citus über eine Benutzerverwaltung auf der Ebene der Coordinators, und Sicherheitsoptionen lassen sich bis hinunter auf einzelne Zeilen der Tabellen einzelner Shards implementieren. So werden Multi-Tenant-Setups möglich: Derselbe Citus-Cluster kann dann mehrere Setups versorgen, weil auf der Ebene der Datenbank entsprechende Sicherheitsbarrieren dafür sorgen, dass Kunde A die Inhalte der Datenbanken von Kunde B nicht sieht.
Allerdings würde auch dieses Problem zumindest in den Hintergrund rücken, ließe Citus sich schnell als Cluster in einer Kubernetes-Umgebung ausrollen. Dann würde der Administrator vermutlich eher zwei separate Cluster ausrollen und den dadurch bedingten Overhead in Kauf nehmen, als auf der Datenbankebene die Benutzerverwaltung zu bemühen.
Shards sinnvoll steuern
Ganz unabhängig vom Deployment-Szenario bietet Citus verschiedene Möglichkeiten, mittels vieler kleiner und großer Schrauben die Performance der Lösung für einzelne Einsatzbereiche zu optimieren. Für Shards, also Tabellen derselben PostgreSQL-Datenbank, lässt sich etwa festlegen, dass diese “colocated” sein sollen, also auf denselben Worker-Knoten im Hintergrund liegen. Das erspart den Koordinatoren bei der Abfrage Netzwerk-Roundtrips und kommt somit der Latenz zugute (Abbildung 5).
Abbildung 5: In Sachen Performance zeigt Citus sich auf der Höhe der Zeit. Durch Colocation lassen sich etwa die Zugriffszeiten auf einzelne Shards deutlich verringern. Quelle: Citus
Ganz andere Möglichkeiten ergeben sich durch das automatische Ausbalancieren von Shards. Das funktioniert ohne Downtime: Fügt der Administrator in Citus weitere Backends hinzu, beginnen die Coordinators automatisch damit, einzelne Shards neuen Worker-Knoten zuzuordnen. Gleichzeitig konfigurieren sie im Hintergrund PostgreSQLs logische Replikation, um eine Kopie des Datensatzes vom alten Worker-Node auf dem neuen anzulegen. Sobald das erfolgreich geschehen ist, ändern die Coordinator-Knoten in ihren Metadaten die Zuweisung für den Shard vom alten auf den neuen Worker-Knoten und leiten Anfragen künftig an die neue Instanz. Der Vorteil dieses Ansatzes: Die Datenbank bleibt während des gesamten Vorgangs ebenso verfügbar wie der jeweilige Shard.
Fazit: Licht und Schatten
Das Fazit zu Citus fällt alles andere als leicht. Auf der Habenseite stehen einige sehr gute Funktionen. Skalierbares PostgreSQL, das nicht auf einen Konsensalgorithmus setzt, sondern 2-Phase-Commits unterstützt und dadurch hohe Performance bietet – das ist ein Pfund, mit dem sich gut wuchern lässt. Zudem spricht für Citus, dass der Anbieter verschiedene Aspekte im Hinblick auf die Themen Sicherheit und Zuverlässigkeit ebenfalls beachtet und gut implementiert hat. Wer eine leistungsstarke und zuverlässige Datenbank sucht und sich nicht davor fürchtet, eine eigene Anwendung spezifisch auf Citus zuzuschneiden – denn eine Drop-in-Alternative gibt es wegen der spezifischen Zugriffsmuster der Coordinators praktisch nicht – findet in Citus ausgezeichnete Technologie unter freier Lizenz zum Nulltarif.
Noch besser gefiele Citus allerdings, hätte der Hersteller das Thema Deployment nicht so brachial versaubeutelt. Kaum ausführliche Dokumentation, kein wie auch immer gearteter Ansatz zur unkomplizierten Automatisierung und praktisch überhaupt keine Integration oder auch nur Vorbereitung im Hinblick auf das Thema Kubernetes – im Jahr 2022 reicht das nicht mehr aus. Das gilt umso mehr vor dem Hintergrund, dass Citus als skalierbare Software von den diversen Kubernetes- oder IaaS-Funktionen wie Orchestrierung massiv profitieren würde. Was hier in den Anbieter gefahren ist, seine Kunden mit einem derart unausgereiften Ansatz zu konfrontieren, bleibt ein Rätsel.
Immerhin bietet Citus gehostete Versionen seiner Datenbank auf Azure als schlüsselfertiges Produkt an, also als Database-as-a-Service. Wer hier keine Compliance-Probleme bekommt und ohnehin auf Azure setzt, findet in diesem Angebot womöglich eine Alternative zum absurd komplexen Setup-Prozess einer Software, die lediglich in RPM- und DEB-Form für zwei der großen Standard-Distributionen vorliegt. Für die Mehrheit der Endanwender dürfte das Azure-Angebot aber wohl eher ein nettes Addon sein als tatsächliche Hilfe. Am Ende gilt: Wer sich die Mühe antut, findet in Citus ein gutes Produkt. Wie Herbert Grönemeyer so treffend festhielt: “Es könnt’ alles so einfach sein – isses aber nicht.” (jcb)
Infos
- Citus: https://www.citusdata.com





