
© Alex Rodrigo Brondani / 123RF.com
Bibliotheken, Klassen, Module, Pakete – es gibt viele Methoden, um Code in kleinere Einheiten zu unterteilen. Die Bash kennt jedoch keine davon. Höchste Zeit, das zu ändern.
Im ersten Teil dieser Serie [1] haben wir einige Tricks kennengelernt, mit denen sich Bash-Skripte lesbarer machen und gleichzeitig Code-Injektionen verhindern lassen. In diesem Beitrag gehen wir das nächste große Problem an, das auf dem Weg zum eigenen verteilten System als Hindernis auftaucht: die Wiederverwendbarkeit von Code.
Verteilte Systeme bestehen aus mehreren Prozessen, die zum Teil auf dieselben Funktionen zugreifen, etwa zur Kommunikation. Wir wollen diese Funktionen nicht in allen Prozessen doppelt und dreifach implementieren. Deshalb brauchen wir zunächst einen Mechanismus, mit dessen Hilfe wir Codeabschnitte importieren können.
Not macht erfinderisch
Die Shell-Familie, zu der die Bash zählt, kennt weder Bibliotheken noch Klassen oder Module. Um Skripte in kleinere logische Einheiten zu unterteilen gibt es lediglich den Befehl »source«, in Skripten oft mit ».« abgekürzt. Er lädt zwar Code dynamisch, stellt uns dabei aber ein weiteres Hindernis in den Weg: Da wir nicht wissen, wo unsere Skripte installiert sein werden, können wir »source« keine absoluten Pfade übergeben. Relative Pfade kommen ebenfalls nicht infrage, da sie nicht relativ zum Pfad des Skripts aufgelöst werden, sondern relativ zum aktuellen Verzeichnis. Rufen wir das Skript aus einem anderen Verzeichnis heraus auf als dem, in dem es gespeichert ist, würden die Pfade also nicht mehr stimmen.
Wir kommen also nicht darum herum, ein kleines Framework mit einer Funktion zum Laden von Modulen zu schreiben. Das Framework werden wir Bash Module System oder kurz BMS nennen. Seine Kernfunktion »try_include()« bekommt einen Modulnamen übergeben und hat die Aufgabe, den absoluten Pfad des Moduls zu bestimmen und es anschließend mit »source« zu laden.
Unter der Annahme, dass alle Module in einem Verzeichnis namens »include/« liegen, das sich im selben Pfad wie das laufende Skript selbst befindet, ist das relativ schnell erledigt, wie Listing 1 zeigt. Der erste Eintrag des Arrays »BASH_SOURCE« enthält den Pfad des laufenden Skripts, so wie es aufgerufen wurde. Der Eintrag darf also auch ein relativer Pfad oder ein symbolischer Link sein, weshalb wir den Befehl »realpath« einsetzen, um den absoluten Pfad zu bestimmen. Davon entfernen wir den letzten Slash und alles was darauf folgt; übrig bleibt der Pfad des Verzeichnisses, in dem das Skript liegt. Daran hängen wir »include/«, den Modulnamen sowie die Dateierweiterung an und können dann den Pfad an »source« übergeben.
Listing 1
Naive try_include-Funktion
include() {
local mod_name="$1"
local mod_dir
local mod_path
if ! mod_dir=$(realpath "${BASH_SOURCE[0]}"); then
echo "Kann ${BASH_SOURCE[0]} nicht aufloesen" 1>&2
return 1
fi
mod_dir="${mod_dir%/*}"
mod_path="$mod_dir/include/$mod_name.sh"
if ! . "$mod_path"; then
echo "Kann $mod_path nicht laden" 1>&2
return 1
fi
return 0
}
Inklusion für die Bash
Unsere »try_include()«-Funktion tut zwar, was sie soll, bietet aber nicht viel Komfort. Angenommen, ein Modul muss sich beim Laden initialisieren – wohin mit dem Initialisierungscode? Schreiben wir ihn direkt in das Modul, also ohne ihn in eine Funktion zu setzen, wird er so ausgeführt, als stünde er direkt in »try_include()«. Bugs bei der Initialisierung des Moduls würden also »try_include()« beeinträchtigen, was wir unbedingt vermeiden wollen. Schöner wäre es, wenn wir Module mit einem Konstruktor initialisieren könnten. Daher legen wir fest, dass ein Modul einen Konstruktor definieren muss, der den Namen »__init« trägt und bei Erfolg den Rückgabewert »0« liefert. Diesen Konstruktor rufen wir aus »try_include()« heraus auf.
Bevor wir die Funktion überarbeiten, müssen wir uns auch Gedanken machen, was beim mehrfachen Laden eines Moduls passiert. Nutzt es Variablen, würden diese zurückgesetzt und das Modul verlöre seinen internen Zustand. Wir müssen »try_include()« daher so schreiben, dass es Module nur dann lädt, wenn das nicht schon erfolgt ist. Dazu schreiben wir zunächst die Hilfsfunktion »have()«, die ein assoziatives Array nutzt, um zu bestimmen, ob ein Modul bereits geladen wurde. In diesem assoziativen Array speichern wir zu jedem geladenen Modul den Pfad, von dem wir es geladen haben. Wenn der Eintrag eines Moduls nicht leer ist, wissen wir also, dass das Modul bereits geladen wurde. Listing 2 zeigt die Funktion.
Listing 2
Assoziatives Array für Modulpfade
have() {
local module="$1"
if [[ -n "${__BMS_INCLUDED[$module]}" ]]; then
return 0
fi
return 1
}
Die Prüfung, ob ein Modul bereits geladen wurde, lässt sich schnell in »try_include()« einbauen. Ein kurzer Aufruf von »have()« wie in Listing 3 genügt, um die Logik korrekt zu implementieren. Damit »have()« beim nächsten Aufruf den richtigen Wert zurückgibt, müssen wir aber noch das assoziative Array »__BMS_INCLUDED« aktualisieren. Das tun wir allerdings nur, wenn der Aufruf des Konstruktors des Moduls erfolgreich war. Da wir den Konstruktor nach dem Aufruf nicht mehr benötigen, setzen wir zuletzt noch »unset« auf ihn an, was ihn aus dem Speicher entfernt.
Nun funktioniert »try_include()« so, wie wir es haben wollen. Beim Laden mehrerer Module wird die Handhabung allerdings etwas unbequem. Daher schreiben wir bei dieser Gelegenheit gleich noch die Wrapper-Funktion »include()«, mit der wir bequem mehrere Module auf einmal laden.
Listing 3
Verbessertes try_include()
try_include() {
local module="$1"
local mod_path
local -i err
if have "$module"; then
return 0
fi
mod_path="$__BMS_PATH/$module.sh"
if ! . "$mod_path" &>/dev/null; then
echo "Kann $mod_path nicht laden" 1>&2
return 1
fi
if __init; then
__BMS_INCLUDED["$module"]="$mod_path"
err=0
else
echo "Kann $module nicht initialisieren" 1>&2
err=1
fi
unset -f __init
return "$err"
}
include() {
local modules=("$@")
local module
for module in "${modules[@]}"; do
if ! try_include "$module"; then
return 1
fi
done
return 0
}
Die von der neuen »try_include()«-Funktion genutzten globalen Variablen müssen wir allerdings noch initialisieren. Das erledigt der Konstruktor unseres Modulsystems in Listing 4: Er löst den Modulpfad auf und weist ihn anschließend einer Variablen zu, die er mit »declare -gxr« als global exportiert und als read-only deklariert. Letzteres verhindert ein versehentliches oder absichtliches Verändern der Variablen. Dadurch, dass wir sie exportieren, lässt sie sich auch in Subshells einsetzen.
Listing 4
Konstruktor des Modulsystems
__bms_init() {
local mod_dir
if ! mod_dir=$(realpath "${BASH_SOURCE[0]}"); then
echo "Kann ${BASH_SOURCE[0]} nicht aufloesen" 1>&2
return 1
fi
mod_dir="${mod_dir%/*}"
declare -gxr __BMS_PATH="$mod_dir/include"
declare -Axg __BMS_INCLUDED
readonly -f have
readonly -f try_include
readonly -f include
return 0
}
Dieses Vorgehen dürfen wir daher auch bei globalen Variablen in Modulen unter keinen Umständen vergessen. Bei der Deklaration von »__BMS_INCLUDED« gehen wir ähnlich vor, nur dass wir die Variable nicht mit »-r« als read-only deklarieren, sondern stattdessen mit »-A« als assoziatives Array. Zuletzt markieren wir auch noch die Funktionen »have()«, »try_include()« und »include()« als read-only, was sie vor nachträglichen Veränderungen schützt.
Es bleibt nur noch die Frage, von wo der Konstruktor unseres Modulsystems aufgerufen wird. Nach dem Strickmuster aus dem ersten Beitrag der Serie schreiben wir eine kurze Befehlsgruppe, die wir zusammen mit den vier Funktionen in einem Skript namens »bms.sh« speichern (Listing 5). Diese Befehlsgruppe prüft zunächst, ob »__BMS_INCLUDE« deklariert wurde. Falls ja, ist das Modulsystem bereits geladen, und die Initialisierung wird übersprungen. Anderenfalls wird der Konstruktor aufgerufen und anschließend per »unset« aus dem Speicher entfernt.
Listing 5
Modulsystem im Einsatz
{
if ! compgen -v | grep "^__BMS_INCLUDED$" &> /dev/null; then
if ! __bms_init; then
echo "Kann BMS nicht initialisieren" 1>&2
fi
unset -f __bms_init
fi
}
Erste Probefahrt
Die Datei »bms.sh« legen wir jetzt an einem für alle Benutzer sichtbaren Ort ab, zum Beispiel im Verzeichnis »/usr/local/share/bms/«. Hier erstellen wir auch ein Verzeichnis namens »include/«, in dem wir unsere Module ablegen.
Um BMS komfortabel in einem Skript zu verwenden, ziehen wir jetzt noch einen Trick aus dem Hut, den uns die Manpage [2] der Bash verrät: Wenn wir einen einfachen Dateinamen an »source« übergeben, sucht es das Skript auch in den Verzeichnissen, die in der Umgebungsvariablen »PATH« stehen. Wenn wir also unter »/usr/local/bin/« einen symbolischen Link auf »bms.sh« erstellen, können wir BMS wie in Listing 6 in ein Skript integrieren.
Listing 6
BMS einbinden
#!/bin/bash
main() {
test_hallo
return 0
}
{
if ! . bms.sh; then
exit 1
fi
if ! include "test"; then
exit 1
fi
main "$@"
exit "$?"
}
Zuletzt schreiben wir noch ein kleines Modul namens Test, das im Konstruktor eine Variable deklariert und mit der Funktion »test_hallo()« den Benutzer grüßt (Listing 7). Wir legen es im bereits erstellten Include-Verzeichnis ab. Wenn wir nun das Skript aus Listing 6 ausführen, begrüßt uns wie in Abbildung 1 zu sehen unser modulares System.
Listing 7
Erster Test
__init() {
declare -gxr __test_name="$USER"
return 0
}
test_hallo() {
echo "Hallo $__test_name"
}
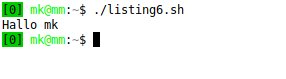
Abbildung 1: Das Modulsystem funktioniert.
Spielregeln für Module
Zwar funktioniert unser Modulsystem nun, es hat aber einen kleinen Haken: Anders als in Sprachen, die a priori Module unterstützen, müssen sich alle unsere Module einen Namespace teilen. Das bedeutet, dass keine zwei Module eine Funktion oder eine globale Variable mit demselben Namen definieren dürfen, da sie einander sonst ins Gehege kommen.
Um sicherzustellen, dass das nicht passiert, legen wir daher ein paar Konventionen fest. Wenn ein Modul eine Funktion definiert, muss der Name der Funktion mit dem Modulnamen und einem Unterstrich beginnen. Eine interne Funktion, die nicht von außerhalb des Moduls aufgerufen werden soll, muss mit einem Unterstrich, dem Modulnamen und einem weiteren Unterstrich beginnen. Eine von einem Modul deklarierte globale Variable muss mit zwei Unterstrichen, dem Modulnamen und einem weiteren Unterstrich beginnen. Ein Modulname muss wiederum aus Kleinbuchstaben und Ziffern bestehen. Die Tabelle “Namenskonventionen für BMS-Module” fasst diese Regeln mit Beispielen zusammen.
Neben Namenskonventionen brauchen wir auch noch eine Verhaltensregel. Im ersten Beitrag haben wir gesehen, dass Bash-Funktionen die Variablen des Aufrufers erben und somit verändern können. Um das zu verhindern, legen wir fest, dass alle lokalen Variablen mittels »local« oder »declare« entsprechend deklariert werden müssen. Um uns mit den Regeln vertraut zu machen, wollen wir nun unser erstes richtiges Modul schreiben.
|
Element |
Namenskonvention |
Beispiel |
|---|---|---|
|
Modul |
Kleinbuchstaben und Ziffern |
»mod« |
|
Funktion |
Modulname + “_” + … |
»mod_funktion« |
|
interne Funktion |
“_” + Modulname + “_” + … |
»_mod_helfer« |
|
globale Variable |
“__” + Modulname + “_” + … |
»__mod_variable« |
Hilfsfunktionen für Arrays
In unserem verteilten System werden wir häufig mit Arrays zu tun haben, weshalb wir zunächst ein Modul schreiben, das uns beim Ausgeben, Sortieren und Durchsuchen von Arrays hilft. Das Modul nennen wir »array« und legen es unter »/usr/local/share/bms/include/array.sh« ab.
Die erste Funktion des Moduls, »array_to_lines()«, bekommt ein Array übergeben und soll jedes Element in einer separaten Zeile ausgeben. Die einfachste Variante wäre, über das Array zu iterieren und jedes Element mit »echo« auszugeben. Allerdings fällt diese Variante flach, da der Echo-Befehl der Bash Optionen akzeptiert. Enthielte das Array ein Element wie »-n«, würde »echo« es als Option interpretieren und nichts ausgeben.
Es gibt aber noch einen weiteren Befehl zur Textausgabe: »printf«. Er nimmt als erstes Argument einen Format-String mit Platzhaltern entgegen. Die übrigen Argumente formatiert er entsprechend der Platzhalter und fügt sie in die Ausgabezeichenkette ein. Der Platzhalter »%s« weist »printf« zum Beispiel an, das nächste Argument als String formatiert einzufügen. Mit einem Backslash lassen sich Kontrollzeichen in die Ausgabe einbetten, etwa »\n« für einen Zeilenumbruch.
Der »printf«-Befehl hat außerdem die Besonderheit, dass er den Format-String wiederverwendet, falls mehr Argumente übergeben wurden als es Platzhalter gibt. Wir können uns daher die Schleife sparen und »printf« direkt das gesamte Array vorsetzen. Liefern wir »printf« allerdings weniger Argumente als es Platzhalter gibt, füllt es die Ausgabe auf, im Fall von »%s« beispielsweise mit leeren Strings. Im Falle eines leeren Arrays würde »printf« also eine leere Zeile ausgeben, was nicht korrekt wäre. Wir rufen »printf« deshalb nur dann auf, wenn das Array nicht leer ist (Listing 8).
Listing 8
array_to_lines
array_to_lines() {
local array=("$@")
if (( ${#array[@]} > 0 )); then
printf "%s\n" "${array[@]}"
fi
}
Als Nächstes gehen wir »array_sort()« an. Wir wollen nicht selbst einen Mergesort schreiben, sondern bedienen uns kurzerhand bei den Coreutils: Deren Sort-Befehl liest die zu sortierenden Daten zeilenweise aus der Standardeingabe und gibt das sortierte Ergebnis auf der Standardausgabe aus. Wir müssen also nichts weiter tun, als die eben geschriebene Funktion »array_to_lines()« und den Sort-Befehl per Pipe zu verketten.
Ohne Angabe von Optionen nimmt »sort« eine lexikalische Sortierung vor, bei der etwa die 20 vor der 3 kommt. Um das zu verhindern, geben wir »sort« noch ein »-V« mit, was für das Sortieren von Versionsnummern gedacht ist und für die meisten Anwendungen die richtige Reihenfolge ergibt. Listing 9 zeigt »array_sort()« in seiner gesamten vierzeiligen Pracht.
Listing 9
array_sort
array_sort() {
local array=("$@")
array_to_lines "${array[@]}" | sort -V
}
Zuletzt kommen wir zum Durchsuchen von Arrays, das wir in der Funktion »array_contains()« implementieren. Sie bekommt als Parameter ein Element und ein Array übergeben und liefert 0 zurück, falls das Array das Element enthält. Anderenfalls lautet der Rückgabewert 0.
Ähnlich wie »array_sort()« könnten wir diese Funktion als Verkettung von »array_to_lines()« mit dem Grep-Befehl schreiben. Die zeilenweise Ausgabe des Arrays und der Aufruf von Grep sind allerdings relativ zeitaufwendig. Deshalb bietet diese Variante in der Praxis keinen Geschwindigkeitsvorteil gegenüber einer einfachen Schleife und arbeitet bei Arrays mit Hunderten Elementen sogar deutlich langsamer. Darum iterieren wir in »array_contains()« (Listing 10) mit einer Schleife über das Array und vergleichen jedes Element mit dem gesuchten.
Listing 10
array_contains
array_contains() {
local needle="$1"
local haystack=("${@:2}")
local cur
for cur in "${haystack[@]}"; do
if [[ "$needle" == "$cur" ]]; then
return 0
fi
done
return 1
}
Per Konvention benötigen wir jetzt noch einen Konstruktor für unser Modul. Da wir bei der Implementierung vollkommen ohne globale Variablen und andere Module auskamen, brauchen wir immerhin keine Initialisierung. Uns genügt es daher, wenn der Konstruktor wie in Listing 11 direkt Erfolg vermeldet.
Listing 11
Konstruktor
__init() {
return 0
}
Funktionstest
Um zu überprüfen, ob unser Modul-Framework funktioniert, schreiben wir kurzerhand ein Testskript (Listing 12). Es erstellt zunächst ein Array mit fünf Zufallszahlen zwischen 0 und 10. Die Bash stellt dazu die Variable »$RANDOM« bereit, die bei jedem Lesen eine neue Zufallszahl zwischen 0 und 32 767 zurückgibt. Mit dem Modulo-Operator »%« teilen wir sie durch 10 und hängen den sich ergebenden Rest an das Array an.
Anschließend geben wir erst das unsortierte Array mit »array_to_lines()« aus und rufen anschließend »array_sort()« auf, was das Array sortiert und ausgibt. Zuletzt testen wir »array_contains()«, indem wir drei weitere Zufallszahlen zwischen 0 und 10 generieren und prüfen, ob das Array sie enthält.
Beim Ausführen des Testskripts erhalten wir eine Ausgabe wie die in Abbildung 2 gezeigte. Das Framework und auch unser erstes Modul funktionieren wie erwartet. Damit haben wir die erste große Etappe hinter uns gebracht.
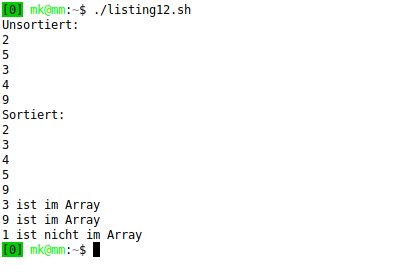
Abbildung 2: Wenn diese oder eine ähnliche Ausgabe zu sehen ist, ist das ein gutes Zeichen.
Listing 12
Testskript
#!/bin/bash
main() {
local array
local i
array=()
for (( i = 0; i < 5; i++ )); do
local num
num=$((RANDOM % 10))
array+=("$num")
done
echo "Unsortiert:"
array_to_lines "${array[@]}"
echo "Sortiert:"
array_sort "${array[@]}"
for (( i = 0; i < 3; i++ )); do
local num
num=$((RANDOM % 10))
if array_contains "$num" "${array[@]}"; then
echo "$num ist im Array"
else
echo "$num ist nicht im Array"
fi
done
return 0
}
{
if ! . bms.sh; then
exit 1
fi
if ! include "array"; then
exit 1
fi
main "$@"
exit "$?"
}
Ausblick
Ob das Modul jedoch wirklich in allen Situationen richtig funktioniert, können wir anhand dieser kleinen Stichprobe noch nicht beurteilen. Um mehr Vertrauen in unseren Code zu bekommen, brauchen wir rigorose Tests, die unsere Funktionen mit möglichst vielen verschiedenen Eingaben durchspielen. Wie wir diese Tests bewerkstelligen, sehen wir uns in der nächsten Folge dieser Reihe an. (jcb/jlu)
Infos
- Shell-Serie (Teil 1): Matthias Kruk, “Muschelperlen”, LM 06/2022, S. 76, https://www.lm-online.de/47902
- Bash-Manpage: https://linux.die.net/man/1/bash





