
© Agata Gadykowska / 123RF.com
Kubernetes ist in aller Munde, doch viele tun sich mit dem Einstieg schwer. Dieser Artikel stellt die architektonischen Grundlagen sowie die wichtigsten Komponenten und Begriffe rund um die Lösung vor.
Kubernetes gehört im aktuellen Zirkus der IT-Werkzeuge zweifelsohne zu den schillerndsten Lösungen. Ein anhaltender Hype begleitet die einst von Google entwickelte Umgebung, die heute unter der Ägide der Cloud Native Computing Foundation (CNCF) steht und mithin zum echten Community-Projekt geworden ist.
Allerdings wirkt es auch, als habe Kubernetes (kurz: K8s, wegen der acht Buchstaben zwischen dem K und dem s) einen Keil in die Riege der Administratoren getrieben: Während Container-Befürworter sich heute oft eine IT ohne Container und den passenden Orchestrierer gar nicht mehr vorstellen können, hatten andere bis dato nur wenig Grund, sich mit Kubernetes überhaupt zu befassen. Das führt manchmal bis zu einer Trotzreaktion frei nach dem Motto “Was der Bauer nicht kennt, frisst er nicht”.
Das ist im Übrigen alles andere als unverständlich, denn wie es sich für einen echten Hype gehört, wird das Kubernetes-Universum mittlerweile von einer Art Fachsprache dominiert, die Außenstehende erst einmal erlernen müssen. Selbst viele eingefleischte Admins der ersten K8s-Stunde wissen vor lauter CRDs (Custom Resource Definitions), Providern und Replica-Sets mittlerweile nicht mehr so recht, was nun eigentlich was ist und was wann wofür zum Einsatz kommt. Vor dem Hintergrund des Kubernetes-Hypes lässt sich das gut nachvollziehen, schließlich entwickelt sich die Lösung ständig weiter.
Dieser Artikel eilt Kubernetes-Neulingen zu Hilfe und bietet eine grundlegende Einführung in das Thema, die keinerlei Vorwissen voraussetzt. Neben den wichtigsten Begriffen aus der K8s-Bubble steht ein kurzer Architekturüberblick zu Kubernetes ebenso auf dem Plan wie eine Erläuterung der wichtigsten Funktionen der Lösung aus Benutzersicht. Wer sich also bisher mit K8s so überhaupt nicht befasst hat, bekommt hier das benötigte Wissen.
Das Vorwort: Container
Bevor es um Kubernetes geht, stehen allerdings ein paar Klarstellungen in Sachen Container an. Hier sieht der Administrator sich ebenso mit vielen Begriffen und vor allem vielen Abkürzungen konfrontiert, die kaum zu verstehen sind, hat man sich mit dem Thema nicht schon einmal befasst.
Was die meisten Administratoren noch wissen: Bei Kubernetes handelt es sich im Kern um eine Lösung, die Container über die Grenzen physischer Systeme hinweg orchestriert – sie also so zusammen ausrollt und betreibt, dass aus einzelnen Containern eine funktionierende Symphonie entsteht. Damit Kubernetes auf den Zielsystemen Container starten und stoppen kann, braucht es dort die entsprechenden Werkzeuge. Wer mit Containern schon einmal zu tun hatte, der kennt den Kommandozeilenbefehl »docker« [1].
Nun könnte Kubernetes freilich die benötigte Infrastruktur auf den Systemen selbst implementieren. Das Werkzeug sieht seine Kernaufgabe jedoch im Flottenmanagement, Container möchte es vor Ort auf den einzelnen Systemen mittels einer lokalen Laufzeitumgebung ausrollen. Das Problem: Es gibt mittlerweile mehrere solcher Umgebungen.
Den meisten Administratoren dürften die Begriffe Containerd und Runc ein Begriff sein. Das Gespann kommt heute in Docker zum Einsatz; das Kommandozeilenwerkzeug »docker« dient lediglich als Frontend für Containerd, das im Hintergrund Runc aufruft. Erst Runc legt Container an und verwaltet sie. Es ist mithin auch die Komponente, die die Open-Container-Initiative-Spezifikationen (OCI) beherrscht (Abbildung 1).
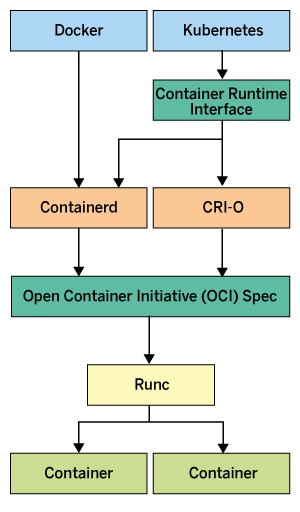
Abbildung 1: Kubernetes startet über das Kubelet Container auf den Zielsystemen selbst und nutzt die CRI-Schnittstelle. Quelle: Tom Donohue / www.tutorialworks.com
Zudem kommt Runc nicht nur im Kontext von Docker und Containerd zum Einsatz, sondern auch im Kontext von CRI-O, von dem mancher Administrator ebenfalls bereits gehört haben dürfte. CRI-O steht für Container Runtime Interface-O und ist bereits eine waschechte Abkürzung aus dem Kubernetes-Kontext. Noch vor wenigen Jahren nutzte Kubernetes die Schnittstelle von Containerd, also jene aus Docker. Dann entstand jedoch auf Geheiß von IBM und Red Hat eine eigene Lösung.
Anders formuliert: Kubernetes folgt auf der Ebene seiner eigenen API mittlerweile einem Standard, der die Kommunikation mit externen Container-Laufzeitumgebungen definiert (CRI). Die eigenständigen Projekte Containerd und CRI-O stehen in Konkurrenz zueinander, implementieren aber beide den CRI-Standard und kommen mithin als mögliches K8s-Backend infrage. Unter der Haube nutzen beide Lösungen Runc. Die Standard-Methode, Kubernetes zu betreiben, fußt heute auf CRI-O.
Ebenfalls der Erklärung bedarf in diesem Kontext noch der Begriff Podman [2]. Dabei handelt es sich um ein Konkurrenzprodukt von Docker, das die Werkzeuge »docker« und »containerd« ersetzt. Podman ruft im Hintergrund also Runc direkt auf, statt wie Docker noch eine Abstraktionsebene einzuziehen. Das ist vor allem dann für Admins interessant, wenn sie auf einzelnen Systemen untersuchen müssen, warum etwa Container dort nicht funktionieren. Letztlich handelt es sich bei Podman nur um ein anderes Frontend für Runc.
Grundlagen
Weiter im Text geht es mit den absoluten Basics zu Kubernetes. Im K8s-Universum gibt es einen Begriff, der in den meisten Architekturdiagrammen zu Kubernetes fehlt, aber dessen Funktionsprinzip gut beschreibt. Deshalb steht er ganz oben auf der Liste der Kubernetes-Abkürzungen, die es zu verinnerlichen gilt: Desired State Management, abgekürzt als DSM.
Der Terminus technicus beschreibt die Art und Weise, wie Kubernetes funktioniert: Der Benutzer teilt der Lösung mit, welchen Zustand seine Ressourcen haben sollen. Kubernetes kümmert sich im Hintergrund automatisch darum, diesen Zustand wie gewünscht herzustellen. Die Aufforderung an den Kubernetes-Cluster lautet also nicht: “Starte Container A auf Knoten 1, Container B auf Knoten 2 sowie Container C auf Knoten 3, und sorge dafür, dass die Datensätze der Container Replicas sind, also miteinander abgeglichen”.
Stattdessen lautet die Anweisung: “Erstelle drei Replicas desselben Containers”, und K8s geht auf Basis seiner Standardkonfiguration automatisch davon aus, dass die drei Instanzen der Container auf unterschiedlichen Hosts laufen sollen. Auf den Begriff des Replikats geht der Artikel später noch im Detail ein.
Das richtige Format
Wer die Kubernetes-Dokumentation oder Anleitungen zum Thema liest, stolpert dort regelmäßig über Dateien im YAML- oder JSON-Format, die es dem laufenden Cluster zu übergeben gilt. Vor dem Hintergrund des Desired State Management wird offensichtlich, was es damit auf sich hat: In Form dieser Snippets teilt der Administrator einer laufenden Kubernetes-Instanz mit, wie denn der Desired State überhaupt aussieht. Es handelt sich also um ein Format für Templates, in dem der Administrator sein Wunsch-Setup möglichst genau beschreibt.
Kubernetes wertet diese Information im Anschluss aus und erstellt die Ressourcen nach Vorgabe. Wem das Prinzip aus der Cloud bekannt vorkommt, der denkt instinktiv an Dienste wie CloudFormation von AWS – und liegt damit goldrichtig: Das Desired State Management ist ein Kernprinzip klassischer Orchestrierung und mithin auch Kern der Funktionalität von CloudFormation oder anderen Lösungen wie OpenStack Heat.
Die Architektur
Es stellt sich die Frage, wie Kubernetes es auf die Reihe bekommt, die vom Benutzer in Form eines Templates vorgegebene Definition des Desired States in laufende Ressourcen umzusetzen. Hier geht es nun im Kern um die Kubernetes-Architektur, in der etliche Komponenten zum Erreichen dieses Zustands beitragen. Grob lassen sich die K8s-Dienste in zwei Kategorien unterteilen: die Control Plane und die Nodes, die die eigentlichen Container enthalten (Abbildung 2).
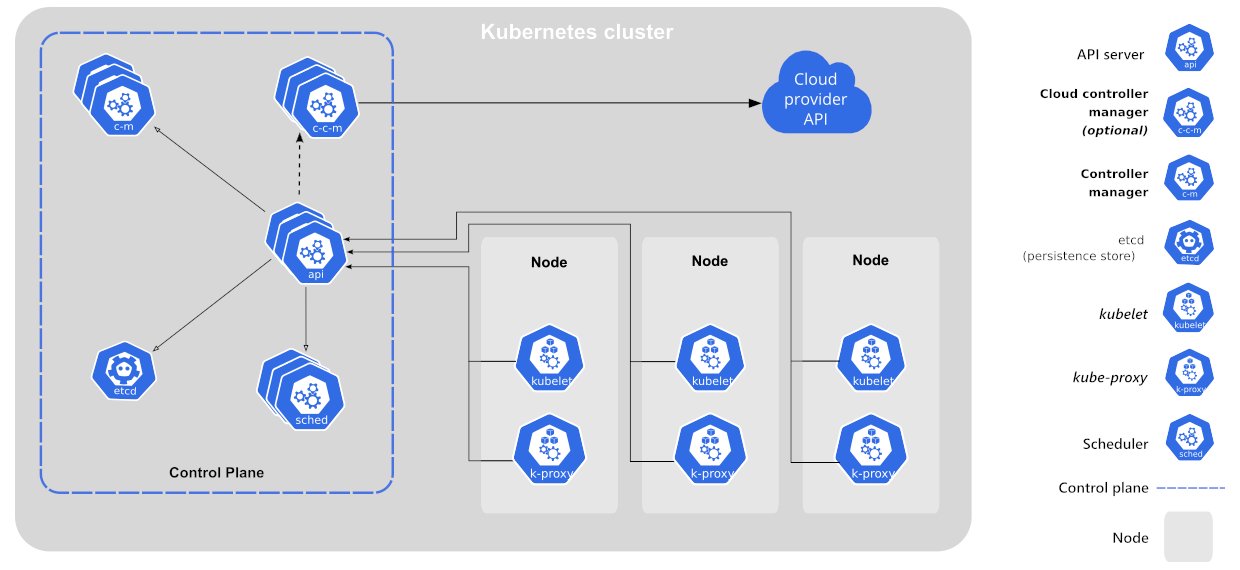
Abbildung 2: Die Kubernetes-Architektur besteht einerseits aus den Controller-Diensten im Controller-Cluster und andererseits aus Kubelet, das auf den Zielsystemen die eigentliche Konfiguration vornimmt. Quelle: Kubernetes
Die Control Plane wiederum besteht aus mehreren Microservices. Als Dreh- und Angelpunkt fungiert der API-Server der Lösung, der den größten Teil der Kommunikation mit der Außenwelt für K8s abwickelt. Liefert der Benutzer auf der Kommandozeile mittels »kubectl« eine Definition von Ressourcen an Kubernetes aus, kommuniziert Kubectl im Hintergrund mit der API von Kubernetes. Es handelt sich dabei um eine klassische ReST-Schnittstelle, die einerseits Updates für bestehende Ressourcen oder Anlegebefehle für neue Ressourcen akzeptiert, die aber für laufende Ressourcen auch als Informationsquelle dient.
Obendrein lassen sich über die Kubernetes-API einzelne Ressourcen der Umgebung auch unmittelbar steuern. Führt der Nutzer etwa ein Kommando aus, um eine in Containern laufende Anwendung zu stoppen, übersetzt Kubectl den Befehl im laufenden Betrieb in eine aktualisierte Ressourcendefinition mit dem erwünschten Status “angehalten” und übergibt der Kubernetes-API dieses Template.
Hier zeigt sich, dass Werkzeuge wie Kubectl im Alltag vielseitig sind, denn das Starten und Stoppen einzelner Ressourcen funktioniert wie beschrieben sehr gut. Wollte der Admin auf diesem Weg allerdings eine ganze virtuelle Umgebung mit einzelnen Befehlen beschreiben, wäre das sehr mühsam. In solchen Szenarien kommen die YAML-Templates zur Hilfe.
Hochverfügbarkeit eingebaut
Ein zentraler Aspekt moderner IT-Architekturen ist eingebaute Hochverfügbarkeit. Wo noch vor ein paar Jahren Krücken wie Pacemaker zum Einsatz kamen, wollen sich moderne Anwendungen selbst um ihre eigene Verfügbarkeit kümmern. Auch die Control Plane eines K8s-Clusters muss Hochverfügbarkeitsanforderungen genügen. Der Ausfall der zentralen Dienste eines Kubernetes-Clusters würde zwar nicht zu einem Loss of Functionality der ausgerollten Ressourcen führen, doch ließen diese sich nicht mehr steuern (Loss of Control).
Konsequent sind alle Komponenten eines K8s-Clusters nativ HA-fähig. Eine Sonderrolle spielen dabei gespeicherte Informationen über die Zustände der in Kubernetes ausgerollten Ressourcen. Im Grunde handelt es sich dabei ja um klassische Datenbankinhalte, und wer sich mit Hochverfügbarkeit im Datenbankkontext schon einmal beschäftigt hat, der weiß, dass das Thema alles andere als trivial zu handhaben ist.
Kubernetes versucht sich nicht selbst daran, die eigenen persistenten Daten hochverfügbar zu halten. Stattdessen wälzt es die Aufgabe auf eine externe Komponente ab, den Etcd. Dabei handelt es sich im Wesentlichen um einen implizit hochverfügbaren Key-Value-Store. Zu jedem Kubernetes-Controller-Cluster gehört deshalb auch ein Etcd-Cluster, der Schreib- und Lesezugriffe im Multi-Master-Modus ermöglicht (Abbildung 3). So verwandeln sich viele kleine K8s-Dienste flugs in ein multidimensionales Mesh: Beliebig viele Instanzen der Kubernetes-API greifen im Hintergrund auf beliebig viele Instanzen von Etcd zu. Fällt eine der Instanzen aus, übernehmen die verbliebenen ad hoc deren Aufgaben.
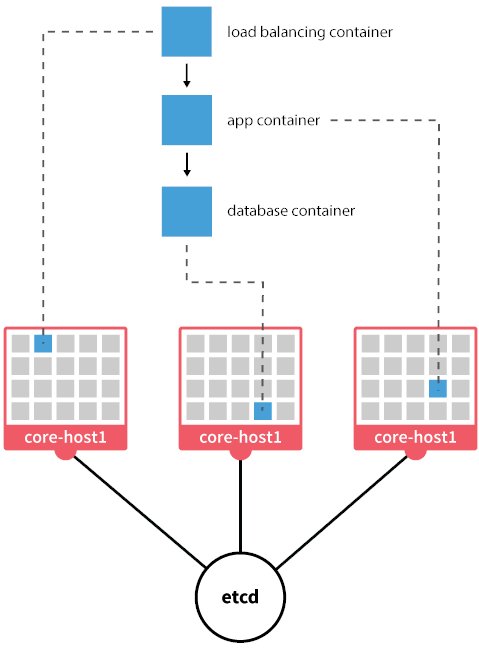
Abbildung 3: Etcd kümmert sich per Konsensalgorithmus um das redundante Speichern der Kubernetes-eigenen Metadaten. Quelle: Etcd
Ressourcen anlegen
Bisher klafft in der Kubernetes-Story, wie dieser Artikel sie beschreibt, allerdings noch ein Loch. Zwar ist es toll, DSM-Definitionen auf der einen Seite entgegennehmen und auf der anderen Seite persistent und hochverfügbar zugleich speichern zu können. Aber irgendeine Instanz muss am Ende ja auch dafür sorgen, dass aus den DSM-Angaben Ressourcen auf Systemen werden, im Idealfall also laufende Container.
Hier kommt der Kubernetes Controller Manager ins Spiel, der mehrere Komponenten umfasst: Der Node Controller führt Buch über sämtliche zur Verfügung stehenden Zielsysteme, die Container-Workloads betreiben können. Der Job Controller ist dafür zuständig, anstehende Arbeiten für die Ausführung einzuplanen. Hinzu gesellen sich die Endpoints, Service Accounts und Token Controller. Sie verwalten interne Details von Kubernetes, wie die Benutzerverwaltung der Lösung, und pflegen ein Verzeichnis der laufenden Dienste in Kubernetes und von deren Endpunkten (also den URLs, über die man sie erreicht).
Den Begriff Controller nutzt Kubernetes übrigens nicht nur im Kontext der eigenen Infrastruktur, sondern auch für einen speziellen Ressourcentyp. Ein Controller auf der Ebene der Kubernetes-Ressourcen ist im Grunde eine Art programmierte Endlosschleife, die den Ist- und Soll-Zustand der vorhandenen Ressourcen abgleicht. Erst Controller machen aus einer DSM-Deklaration also eine laufende Infrastruktur, indem sie unter Nutzung der anderen Kubernetes-Dienste deren Erstellung erzwingen.
Container-Frachtmeister
Auf der Seite der Kubernetes-Controller-Dienste fehlt damit nur noch ein Service, um die Riege der zwingend benötigten Basiswerkzeuge zu komplettieren: der Scheduler. Der Name ist hier Programm: Der Scheduler behält den Überblick über sämtliche verfügbaren Nodes und ihre aktuelle Auslastung. Reicht ein Benutzer eine DSM-Definition ein, die das Anlegen neuer Container bedingt, wählt der Scheduler auf Zuruf des Controller-Managers dafür die passenden Ziele aus. Controller-Entscheidungen beziehen sich allerdings nicht nur direkt auf Container, sondern können auch andere virtuelle Ressourcen umfassen – dazu später noch mehr.
Was ist ein Kubelet?
Wer Kubernetes noch nicht selbst in den Fingern hatte, kennt oft trotzdem zumindest einen Begriff aus der Kubernetes-Welt: Kubelet. Dabei handelt es sich um eine weitere Kubernetes-Komponente, die allerdings nicht wie alle anderen bisher beschriebenen auf dem Kubernetes-Controller-Cluster läuft.
Stattdessen hilft es, sich die Cluster-weite Architektur von Kubernetes als Server-Agent-Architektur vorzustellen. Ein Nutzer übergibt dem Cluster in deklarativer Sprache Ressourcendefinitionen, die Kubernetes im nächsten Schritt auf den einzelnen Compute-Knoten des Clusters in konkrete Infrastruktur umsetzen muss, also etwa in Container. Genau das erledigt Kubelet.
Sobald der Scheduler das Zielsystem für Ressourcen ausgewählt hat, läuft die dortige Kubelet-Instanz los und startet die gewünschten Ressourcen. Container legt der Dienst etwa mittels der bereits erwähnten Container-Schnittstelle CRI-O an. Die kleinste Einheit einer Ressource, mit der Kubelets hantieren, ist übrigens der Pod: Ein solcher umfasst eine beliebige Anzahl von zusammengehörigen Containern, die stets auf demselben System laufen.
Kubernetes erweitern
In der Theorie sind damit alle Komponenten beschrieben, die aus Anweisungen eines Nutzers laufende Kubernetes-Instanzen machen. Der Vorrat an Funktionen in Kubernetes ist durchaus beachtlich – es finden sich etwa Definitionen für virtuelle Netzwerke, virtuelle Storage Volumes und Container, daneben unterstützt Kubernetes virtuelle Load Balancer. Die sind nötig, weil Kubernetes im Normalfall Container mit privaten IP-Adressen anlegt und dann per Load Balancer Port-Weiterleitungen einrichtet. Mit purem Kubernetes lässt sich mithin bereits einiges an Funktionalität implementieren.
Ein paar Beispiele belegen das nachdrücklich. Die eingangs bereits erwähnten Replica Sets fungieren in der Kubernetes-API als umschreibende Definition dafür, dass eine Ressource nicht nur aus einem Pod besteht, sondern aus mehreren, die es aufeinander abgestimmt mit Konfiguration zu versehen gilt. Das können etwa Datenbanken wie Yugabyte [3] sein, die direkt auf der Datenbankebene Replikation implementieren, statt diese Aufgabe auf den Storage unter ihnen abzuwälzen.
Der Haken bei der Sache: Längst nicht alle denkbaren Funktionen sind im Basissatz der Kubernetes-Funktionen angelegt. Wer etwa schon einmal in die OpenStack-Welt geschnuppert hat, der weiß, dass Software Defined Storage (SDS) und Software Defined Networking (SDN) eine große Rolle spielen. Wer beispielsweise das gesamte Netzwerk seines Rechenzentrums virtualisiert und dafür auf Komponenten wie Ciscos ACI setzt, will auch das Netzwerk seiner Container in dieses System integriert wissen. Wer Storage Appliances nutzt oder auf einen Ceph-Cluster setzt, der möchte Kubernetes irgendwie daran anbinden, damit persistente Storage Volumes von dort aus auch im Cluster zur Anwendung kommen können.
Völlig undenkbar wäre es allerdings, dass die Kubernetes-Entwickler diese Schnittstellen zu externen Diensten selbst entwickeln und pflegen. Weder besitzen sie das dazu notwendige Wissen, noch wäre es aus ihrer Sicht sinnvoll, sich ständig nicht nur mit der Hauptapplikation zu befassen, sondern auch noch mit etlichen Nebenschauplätzen. Ein frühes Designziel von Kubernetes war es deshalb, externe Schnittstellen für Erweiterungen zu bieten. Auch in diesem Kontext fliegen dem geneigten Nutzer allerdings wieder etliche Begriffe und Abkürzungen um die Ohren, die im Kubernetes-Kontext der Erklärung bedürfen.
Ein zentraler Begriff ist dabei der des Plugins. Plugins bilden das faktische Bindeglied zwischen Kubernetes und externen Technologien, übersetzen also Anforderungen von Kubernetes in Maschinencode auf den Zielsystemen. In Kubernetes finden sich hier zum Teil weitere Untergliederungen für einzelne Plugin-Bereiche. Für seine Netzwerke setzt K8s etwa durchgehend auf Plugins nach der CNI-Spezifikation (Container Network Interface). Ähnliches gilt für Storage-Plugins.
Provisioner
Als Schnittstelle zwischen Plugins in Kubernetes dienen die sogenannten Provisioner. Sie docken auf der einen Seite also an die Kubernetes-API an und wissen auf der anderen Seite, welche Plugins sie aufrufen müssen, um einen bestimmten Konfigurationszustand zu erzeugen.
Die logische Verbindung innerhalb der Kubernetes-API zwischen Ressourcen verschiedener Art und einem spezifischen Provisioner erfolgt dabei im Beispiel von Storage über sogenannte Classes. Eine Storage Class definiert in Kubernetes also einen bestimmten Storage-Typ, auf den Kubelet durch ein passendes Plugin zugreift, wenn es zum Anlegen einer solchen Ressource aufgefordert wird. Bei anderen externen Erweiterungen unterscheiden die Begrifflichkeiten sich zum Teil; im Großen und Ganzen ist das Funktionsprinzip jedoch dasselbe.
Custom Resource Definitions
Auch der Begriff der Custom Resource, üblicherweise als CR abgekürzt, sowie deren textliche Ausprägung (Custom Resource Definition, CRD) begegnen dem Administrator regelmäßig. Dabei handelt es sich allerdings nicht primär um eine externe Erweiterung, sondern eher um eine Art Abkürzung im Umgang mit der API selbst.
Kubernetes kommt ab Werk mit einer langen Liste von Ressourcen, auf die Admins in ihren DSM-Manifesten zugreifen. Wenn externe Zusatzanwendungen zum Einsatz kommen oder spezielle Aufgaben immer wieder zu erledigen sind, genügen diese Standard-Definitionen aber womöglich trotz ihres großen Umfangs nicht. Die entsprechende Infrastruktur unter Kubernetes wäre dann zwar vorhanden. Weil sich aber die jeweiligen Ressourcen in der Kubernetes-API nicht aufrufen ließen, lägen die Ressourcen brach. Hier helfen CRDs: Sie ermöglichen es dem Admin, in einem Kubernetes-Cluster beliebige Ressourcentypen zu definieren und mit entsprechender Funktionalität im Hintergrund zu verknüpfen.
Sie erleichtern es zudem, eine Art Template für besonders häufig genutzte Ressourcenkombinationen anzulegen. Eine CRD könnte etwa Webserver heißen und die für einen Webserver benötigten Ressourcen wie ein virtuelles Netz ad hoc anlegen, zugleich aber auch das richtige Abbild auswählen und eventuelle Vorkehrungen für eine dynamische Firewall hinterlegen. Der Benutzer müsste später lediglich eine Ressource namens Webserver in seinem Manifest referenzieren, ohne jedes Mal die gesamte Titulatur in DSM-Sprache zu verwenden. Das spart Zeit und hilft dabei, YAML-Templates für den Einsatz in K8s kurz zu halten.
Wie der Erfolg von CRDs eindrücklich beweist: Praktisch alle externen Lösungen für den Betrieb mit Kubernetes – ganz gleich, ob diese Plugins und Provisioner brauchen oder “nur” innerhalb von Kubernetes laufen – bringen eigene CRD-Ressourcen mit. Die Arbeit mit CRDs ist für Kubernetes-Admins mithin ein alltägliches Geschäft.
Komplementär zu Custom Resources gibt es Custom Controllers. Sie funktionieren wie die nativen Kubernetes-Controller, bieten aber die Möglichkeit, beliebige zusätzliche Arbeitsschritte innerhalb der Kubernetes-API auszuführen. Die Kombination aus Custom Resources und Custom Controllers heißt Operator. Ein Kubernetes-Operator liefert dem Administrator also den größten Teil der Funktionalität, die er benötigt, um schnell eine spezifische Software in Betrieb zu nehmen. Ein bekanntes Beispiel ist der Operator für die Zeitreihendatenbank Prometheus [4], mit dem sich für einen gesamten Kubernetes-Cluster schnell ein umfassendes Monitoring samt Alarmierung und Trending (MAT) herstellen lässt (Abbildung 4).
Abbildung 4: Prometheus kommt als Operator für K8s daher und enthält sowohl Definitionen für Custom Resources als auch für Custom Controllers. In kurzer Zeit lässt sich so ein komplettes Monitoring für K8s realisieren.
Dienste
Mindestens so lebendig wie der Markt der externen Lösungen, die sich mit Kubernetes verbinden lassen, ist der Markt von Software, die auf der Kubernetes-Ebene selbst Features hinzufügt. Im Linux-Magazin waren solche Lösungen bereits oft genug Thema.
Ein prominentes Beispiel ist Rook [5], das einen Ceph-Cluster auf der Kubernetes-Ebene implementiert. Mittels eigener CRDs lassen sich die durch Rook entstehenden Volumes anschließend als native Ressource unmittelbar an Container anschließen. Eine andere sehr prominente Lösung ist Istio [6], ein Service-Mesh, das zwischen den einzelnen Pods einer Anwendung in K8s Verschlüsselung und Load Balancing dynamisch implementiert (Abbildung 5).
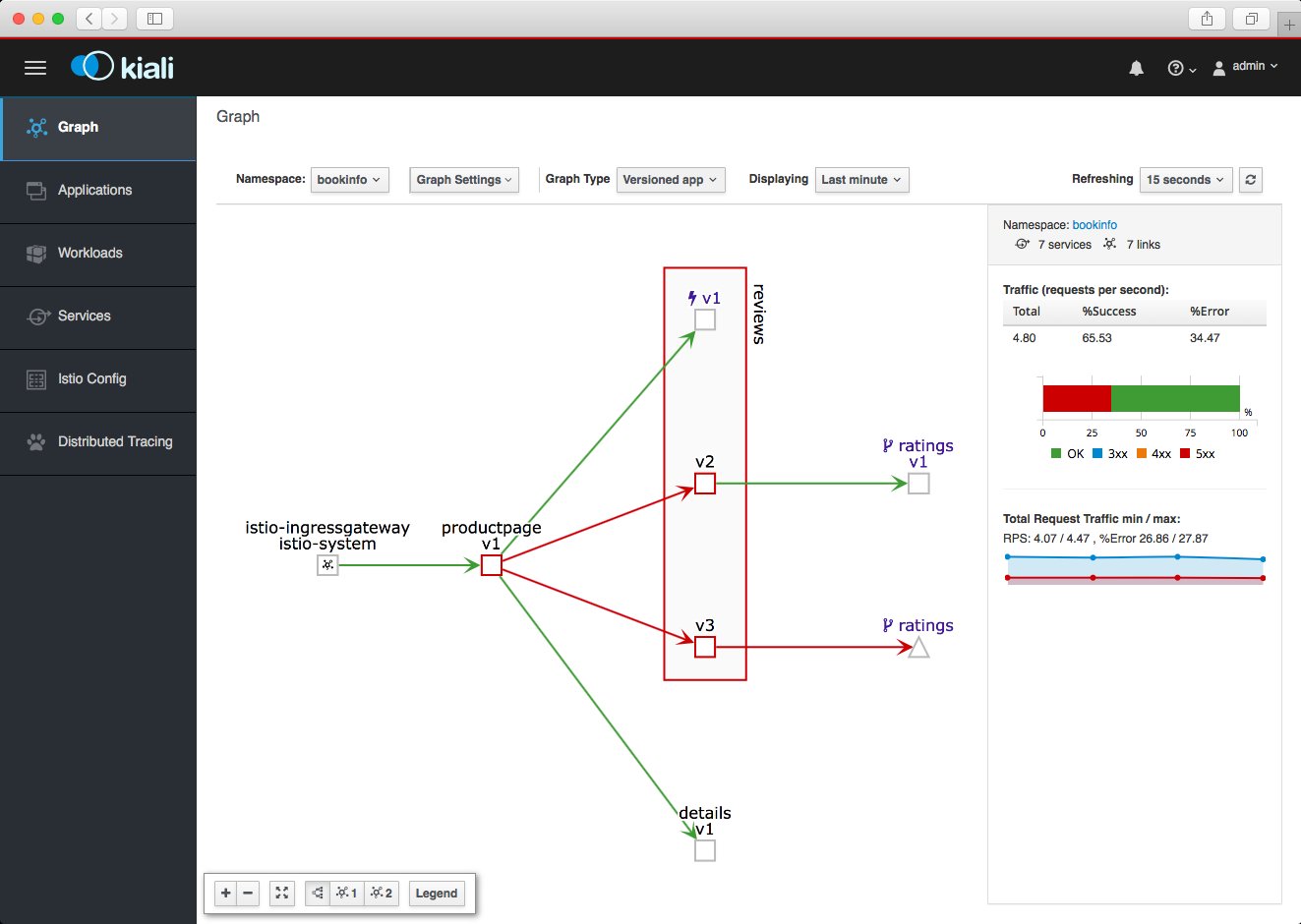
Abbildung 5: Istio (hier mit seinem Frontend Kiali) erstellt dynamische Netzwerk-Meshes in Kubernetes und erleichtert so die Implementierung des Cloud-ready-Prinzips erheblich. Quelle: Kiali
Gerade weil Lösungen dieser Art sich recht leicht in Kubernetes integrieren lassen, sind sie am Markt besonders beliebt, und viele Unternehmen versuchen den Einstieg in die Welt der K8s-Produkte genau damit. Schließlich fehlt die Abhängigkeit zu einer externen Stelle. Ein in Rook gebauter Ceph-Cluster lässt sich etwa ausschließlich aus Kubernetes heraus steuern. Will ein Admin stattdessen einen externen Ceph-Cluster an ein Kubernetes ankoppeln, erfordert das Plugins, eine Storage Class und administrativen Zugriff auf mehrere Systeme.
Helm auf
Zu guter Letzt darf ein Begriff aus der Kubernetes-Welt nicht fehlen, der regelmäßig in der Debatte rund um die Lösung auftaucht: Helm [7]. Dabei geht es nicht etwa um eine schmucke Kopfbedeckung für Baustellen oder zum Einsatz auf Motorrädern, sondern um einen Paketmanager im Kubernetes-Kontext.
Wer Rook oder Istio zum Einsatz bringt, rollt damit implizit etliche Container aus, die verschiedene Abbilder verwenden. Obendrein gilt es, einen Satz von CRDs in Kubernetes zu hinterlegen, gegebenenfalls fallen auch Custom Controller an. Wollte ein Admin all diese Aufgaben händisch erledigen, müsste er eine lange To-do-Liste abarbeiten.
Hier kommt ihm Helm zur Hilfe: Ein Helm Chart definiert alle notwendigen Ressourcen, Eigenschaften und Details und lässt sich mit wenigen Befehlen unmittelbar in Kubernetes ausrollen. Die zum Dienst gehörenden Ressourcen erstellt Helm durch Kubernetes dabei gleich mit. Das Prinzip ähnelt also jenem von klassischen Paketmanagern wie Rpm oder Dpkg, setzt aber auf Container-Abbilder und bringt eine Menge an Steuerungsinformationen mit (Abbildung 6).
Abbildung 6: Der Kubernetes-Paketmanager Helm hinterlegt im Flottenmanager fertige Definitionen für Custom Resources und Custom Controllers, was deren Deployment erheblich erleichtert.
Fazit
Der komplizierteste Teil des Kennenlernens bei Kubernetes besteht darin, dessen alles andere als intuitive, von etlichen Spezialbegriffen und Abkürzungen durchzogene Fachsprache zu erlernen. Selbst wer nicht unmittelbar ein Kubernetes-Setup plant, weiß dann zumindest, wovon in etwa die Rede ist. Ein Crashkurs wie dieser Artikel vermag dabei freilich nur die Grundbegriffe aufzugreifen. Wer selbst Kubernetes ausrollen möchte, sollte also entsprechende Vorbereitungszeit für das Lernen einplanen. (jcb)
Der Autor
Der freie Journalist Martin Gerhard Loschwitz beschäftigt sich vorrangig mit Themen wie OpenStack, Kubernetes und Chef.
Infos
- Docker: Kristian Kißling, Martin Gerhard Loschwitz, “Nachhaltig wachsen”, LM 11/2014, S. 70, https://www.lm-online.de/33287
- Podman: Martin Gerhard Loschwitz, “Wachablösung”, LM 09/2020, S. 56, https://www.lm-online.de/44855
- Yugabyte: https://www.yugabyte.com
- Kubernetes-Monitoring: Michael Kraus, “Passgenau”, LM 08/2017, S. 24, https://www.lm-online.de/39251
- Rook: Martin Gerhard Loschwitz, “Integrierte Speicherplätze”, LM 12/2019, S. 58, https://www.lm-online.de/43385
- Istio: Martin Gerhard Loschwitz, “Vermittlungsstelle”, LM 10/2019, S. 76, https://www.lm-online.de/43383
- Helm: Martin Gerhard Loschwitz, “Rudergänger”, LM 12/2021, S. 62, https://www.lm-online.de/46945





