
© Olga Yastremska / 123RF.com
Mit dem Open-Source-Tool Weka wenden Sie bequem verschiedenste Analysemethoden auf Daten an, ohne zum Programmierer werden oder auch nur die Umgebung wechseln zu müssen.
Von maschinellem Lernen hat wohl jeder schon einmal gehört. Aber wie genau funktioniert es? Trifft da eine intelligente Maschine Entscheidungen im Auftrag des Menschen? In gewisser Weise ja, streng genommen aber auch wieder nicht: Besser tauscht man den Begriff intelligente Maschine gegen effizienter Algorithmus aus und ergänzt, dass dieser Algorithmus mit Daten arbeitet. Dabei liefert er eine Darstellung, die das Wesentliche der Daten erfasst. Vereinfacht gesagt, konzentriert sich das maschinelle Lernen auf den Aufbau von Modellen, die aus den vorhandenen Daten lernen und diese Modelle dann verwenden, um logische Entscheidungen zu treffen, ohne ein menschliches Eingreifen zu erfordern. Die zum Erlernen dieser Modelle verwendeten Methoden sind die Algorithmen.
Es existiert eine Vielzahl derartiger Algorithmen, aber keiner davon eignet sich immer und überall. Ein Algorithmus, der sich bei der einen Datensammlung bestens bewährt, kann bei einer anderen versagen. Deshalb wendet ein Forscher verschiedene Algorithmen auf gegebene Daten an, um zu sehen, welche funktionieren. Müsste er alle diese Verfahren erst selbst programmieren, wäre das sicher eine zu schwierige Aufgabe. Es ist jedoch auch nicht so einfach, eine Plattform zu finden, die die Algorithmen bereits fertig implementiert bereitstellt. An dieser Stelle kommt Weka ins Spiel, das dem Forscher nicht nur eine große Zahl fertiger Algorithmen des maschinellen Lernens anbietet, sondern darüber hinaus auch noch Features wie Visualisierung oder Preprocessing.
Weka-Grundlagen
Die Open-Source-Software Weka steht unter der GPL und entstand an der University of Waikato in Hamilton, Neuseeland. Interessanterweise ist Weka keine Abkürzung oder entstammt dem Technik-Jargon: Es handelt sich um den Namen eines flugunfähigen Vogels, der auf den Inseln Neuseelands lebt.
Das in Java geschriebene Weka läuft auf allen Betriebssystemen und Hardwareplattformen und wird ständig weiterentwickelt. Jedes Update enthält neue Features und sortiert weniger populäre wieder aus. Momentan gilt die Version 3.8.6 als aktuell, die am 21. Februar 2022 erschien. Auch die Version 3.9 ist bereits verfügbar, könnte jedoch noch Bugs enthalten, sodass Sie sie vorerst besser meiden. Die Einzigartigkeit des Tools liegt in der Verfügbarkeit einer Vielzahl verschiedener Methoden, die fast alle Aspekte des maschinellen Lernens über eine gemeinsame Schnittstelle abdecken.
Das Weka-Wiki [1] hält eine Fülle von Informationen über Weka bereit. Dort finden Sie auch Installationsanleitungen für Linux, MacOS und Windows. Nach der Installation lässt sich Weka entweder direkt über die Weka-GUI benutzen oder über API-Calls in Java-Code. Dieser Artikel behandelt nur die grafische Oberfläche. Das erste Fenster, dem Sie begegnen, ist der Weka GUI Chooser (Abbildung 1), über den Sie eine von fünf Ansichten aufrufen:
- Über den Explorer lesen Sie die zu verwendenden Daten ein. Er bietet Optionen für die Vorverarbeitung und erste Datenanalysen (Abbildung 2).
- Im Experimenter richten Sie gezielt Experimente ein, führen sie aus und analysieren die Resultate. Er dient dazu, die Eignung verschiedener Methoden für gegebene Datensammlungen zu vergleichen (Abbildung 3).
- Bei KnowledgeFlow handelt es sich um eine grafische Benutzeroberfläche, die den Informationsfluss darstellt und eine prozessorientierte Sicht auf die angewandten Methoden bietet. Sie verwenden dieses Werkzeug, um eine Pipeline für maschinelles Lernen von der Dateneingabe bis zur Ergebnisausgabe zu entwerfen, die Sie dann in Weka ausführen und auswerten.
- Die Workbench kombiniert alle bereits aufgeführten Ansichten in einem Fenster (Abbildung 4).
- Die SimpleCLI eröffnet die Möglichkeit, Kommandos einzugeben, mit denen sich Weka alternativ zur GUI steuern lässt.
Abbildung 1: Der Weka GUI Chooser ist das erste Fenster, auf das Sie treffen.
Abbildung 2: Der Explorer ermöglicht in Weka das Einlesen der Daten sowie eine Vorverarbeitung und eine erste Analyse.
Abbildung 3: Der Experimenter eignet sich für den Vergleich verschiedener Methoden der Statistik oder des maschinellen Lernens.
Abbildung 4: All in one: Möchten Sie alles in einem Fenster haben, wählen Sie die Workbench-Ansicht.
Der Weka Explorer, das am meisten benutzte Interface, bietet Registerkarten für eine ganze Reihe von Funktionen. Dazu zählen Preprocess (Vorverarbeiten von Daten), Classify (Klassifizierungsalgorithmen), Cluster (Clustering-Algorithmen), Associate (Assoziationsregeln), Select attributes (Feature-Auswahl) und Visualize (Datenvisualisierung).
Im Preprocess-Reiter lesen Sie die Daten aus einer Datei, einer Datenbank oder über einen Link ein. Dateien sind normalerweise tabellarisch aufgebaut, bestehen also aus Spalten und Zeilen. Jede Zeile steht für ein Objekt (in Weka Instanz genannt), jede Spalte repräsentiert eine Eigenschaft des Beobachtungsobjekts (ein Attribut).
Weka unterstützt die Datentypen Real (Fließkommazahlen), Integer, String und Nominaldaten (etwa Ja und Nein). Daneben kennt Weka ein spezielles, erweitertes CSV-Format namens ARFF (Attribute-Relation File Format). ARFF-Dateien haben einen Header, der Informationen über die Namen und Datentypen der Attribute enthält.
@:Nach Installation des Weka-Doc-Pakets findet sich unter »/usr/share/doc/weka/« ein Unterordner »examples/«. Er enthält Beispieldatensets in Form von ARFF-Files, die Sie zum Experimentieren mit dem Tool verwenden können. Listing 1 zeigt einen Ausschnitt aus »diabetes.arff«. Diese Datei laden Sie im Explorer über die Schaltfläche Open file.
Listing 1
diabetes.arff
@relation pima_diabetes
@attribute 'preg' numeric
@attribute 'plas' numeric
@attribute 'pres' numeric
@attribute 'skin' numeric
@attribute 'insu' numeric
@attribute 'mass' numeric
@attribute 'pedi' numeric
@attribute 'age' numeric
@attribute 'class' { tested_negative, tested_positive }
@data
6,148,72,35,0,33.6,0.627,50,tested_positive
1,85,66,29,0,26.6,0.351,31,tested_negative
8,183,64,0,0,23.3,0.672,32,tested_positive
1,89,66,23,94,28.1,0.167,21,tested_negative
[...]
Auf dieselbe Weise könnten Sie auch eine CSV-Datei laden, nachdem Sie diesen Datentyp im Dateidialog ausgewählt haben. Allerdings ergeben sich dabei häufig Probleme, die in Fehlermeldungen wie Data values neither numeric nor nominal münden. Deshalb ist ARFF das präferierte Dateiformat für Weka. CSV-Dateien lassen sich in das ARFF-Format konvertieren, indem Sie einen entsprechenden Header ergänzen.
Dazu benennen Sie zunächst die Relation, die das Daten-File widerspiegelt (im Beispiel »@relation pima_diabetes«). Dann ergänzen Sie Angaben zu allen Feldern und deren jeweiligen Datentypen (etwa »@attribute ‘age’ numeric«). Abschließend fügen Sie das Attribut »class« hinzu – zumindest in diesem Fall. Für Anwendungen, die etwas klassifizieren wollen, muss das Attribut vom Typ »nominal« sein; um eine Regression zu berechnen, benötigen Sie den Datentyp »real«. Die eigentlichen Daten beginnen nach der »@data«-Direktive als kommaseparierte Attributwerte in Zeilen.
Nach dem Laden der Datei zeigt der Explorer einige Informationen zu den Daten an. In Abbildung 5 sehen Sie auf der linken Seite die Anzahl der Instanzen und die Namen der Attribute. Auf der rechten Seite liefert Weka statistische Kennzahlen für die Daten, zum Beispiel Maximum, Minimum, Mittelwert und so weiter. Außerdem zeigt das Tool ein Histogramm für das links ausgewählte Attribut.
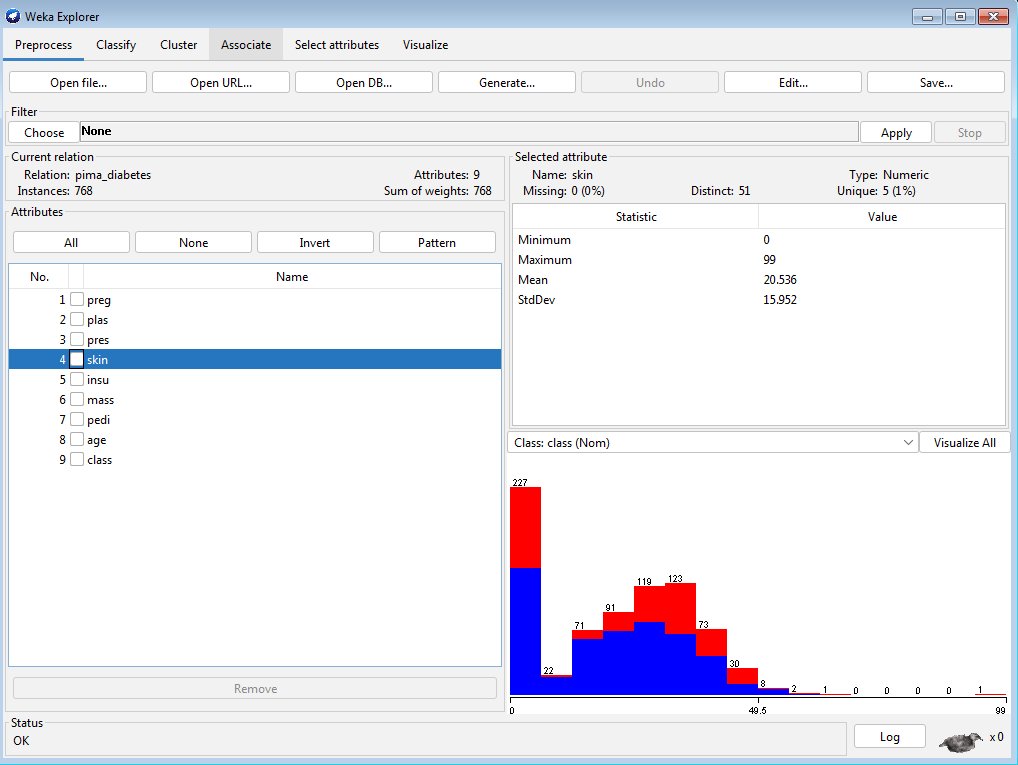
Abbildung 5: Die Diabetes-Beispieldaten nach dem Einlesen im Weka Explorer.
Vorverarbeitung
Bevor Sie Algorithmen des maschinellen Lernens anwenden, sollten Sie die Daten bereinigen. Im ersten Schritt entfernen Sie überflüssige Attribute. Oft benötigen Sie nicht alle davon zur Analyse des Problems. So würde zum Beispiel der Name der Person nichts zur Diabetes-Diagnose beitragen. Solche Attribute entfernen Sie am besten, um die Last für den Algorithmus zu verringern und so eventuell die Performance zu verbessern. Dazu markieren Sie die fraglichen Attribute und klicken auf Remove.
Weka stellt eine große Anzahl an Filtern bereit, die Sie auf das Dataset anwenden können. Falls Sie sich etwa nur für bestimmte Werte eines Attributs interessieren, blenden Sie alle anderen per Filter aus. Ein anderes Beispiel wäre der Wunsch, bestimmte Variable wie Alter oder Einkommen zu normalisieren. Auf jeden Fall erfordert dieser Schritt ein Verständnis sowohl der Daten als auch des Algorithmus, um zu entscheiden, welche Filter infrage kommen.
Filter wählen Sie durch einen Klick auf den Choose-Button unter dem Label Filter aus. Es gibt zwei Arten von Filtern: Supervised- und Unsupervised-Filter. Erstere benutzen Klassenwerte und kommen verglichen mit Unsupervised Filtern sehr selten vor. Außerdem unterscheidet man zwischen Klassen- und Instanzfiltern. Mit der Option Allfilter beziehungsweise Multifilter lassen sich Filter auch kombinieren.
Abbildung 6 zeigt, wie ein Normalisierungsfilter auf das Attribut »preg« des Beispieldatensatzes angewendet wurde. Die Parameter des Filters stellen Sie in der weißen Textbox rechts neben dem Choose-Button ein. Übrigens gibt es im Explorer auch einen Undo-Button, mit dem sich jede Änderung wieder zurücknehmen lässt, sowie einen Save-Button, der die aktuellen Werte in eine Datei speichert.
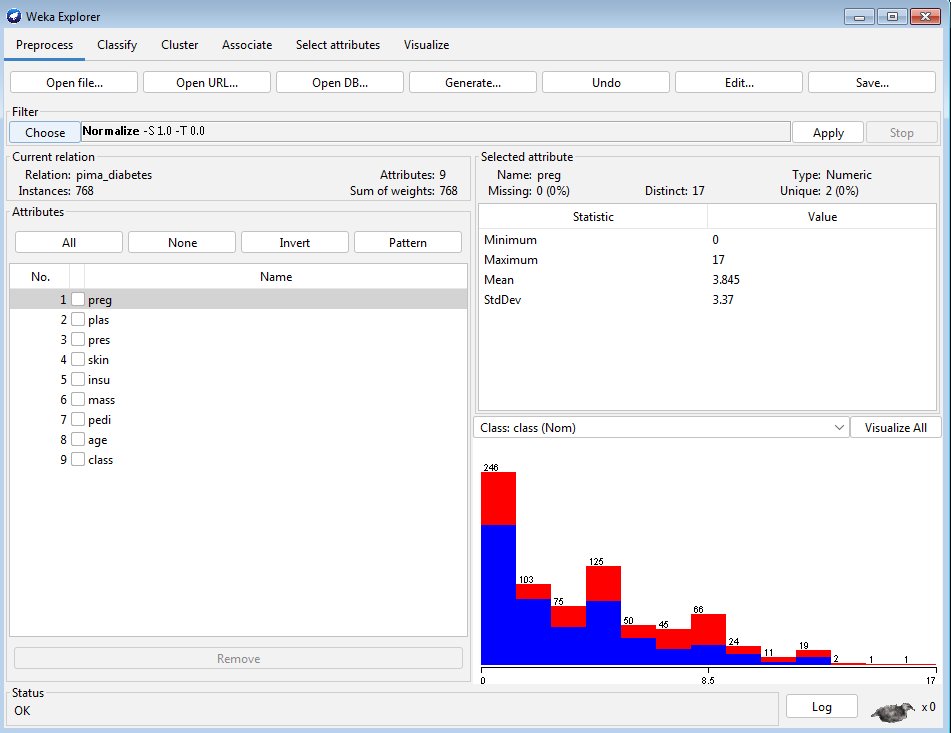
Abbildung 6: Hier wurde ein Normalisierungsfilter auf ein Attribut des Beispieldatensatzes angewendet.
Maschinelles Lernen
Nach der Vorverarbeitung können Sie mit einer beliebigen Aufgabe des maschinellen Lernens fortfahren, sei es Klassifikation, Regressionsberechnung, Clusterung oder die Ermittlung von Assoziationsregeln. Die Registerkarte Classify dient als Interface zu vielen, sehr bekannten Klassifikationsalgorithmen, darunter Entscheidungsbäume, Support Vector Machines, Naive Bayes, Multi-Layer Perceptrons oder logistische Regression, um nur einige zu nennen. Auch Meta-Learning mit Bagging, Boosting und Stacking ist mit Weka möglich. Zur Bewertung des Klassifikators stehen eine Kreuzvalidierung und die Hold-out-Methode zur Verfügung. Bei allen Algorithmen lassen sich deren Parameter anpassen. Metriken wie Genauigkeit, Präzision oder Wiedererkennungswert können Sie nutzen, um die Vorhersageleistung eines Klassifizierers zu bewerten.
Das folgende Beispiel soll zeigen, wie sich ein Entscheidungsbaum-Klassifizierer auf den Beispieldatensatz »diabetes.arff« anwenden lässt. Dabei kommt der Algorithmus J48 zum Einsatz, die in Java programmierte Open-Source-Version von C4.5, die einen Decision-Tree-Classifier generiert. Im Explorer wählen Sie zunächst in der oberen Menüleiste Classify aus und betätigen dann den Choose-Button, um in der Liste der Klassifizierungsalgorithmen J48 auszuwählen. Daraufhin erscheint der Algorithmus nebst einigen Vorgabeparametern in der Textbox rechts neben dem Choose-Button (Abbildung 7). Sie können die Parameter jederzeit editieren, sofern Sie das notwendige Wissen um die Funktion des Algorithmus und die Bedeutung seiner Parameter mitbringen.
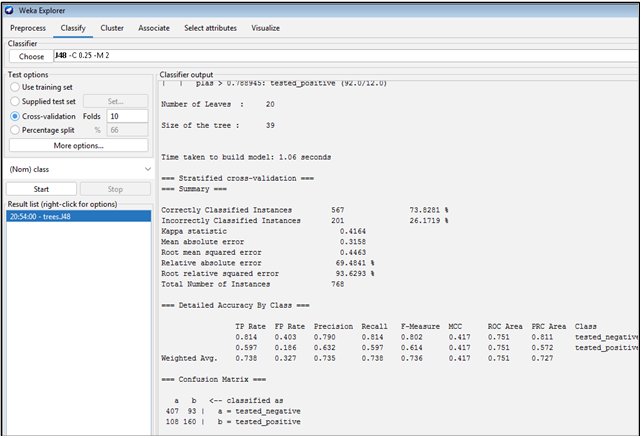
Abbildung 7: In diesem Fenster wird der Decision-Tree-Algorithmus J48 konfiguriert und angewendet.
Der Classifier kann die Daten auf verschiedene Weise nutzen. Entweder behandelt er den gesamten Datensatz als Trainingsset und generiert daraus ein Modell, das sich speichern und später wieder laden lässt, um neue Testdaten zu prognostizieren. Alternativ nutzen Sie die Daten in einer Kreuzvalidierung oder mit der Hold-out-Methode und teilen die Daten prozentual in ein Trainings- und ein Testset auf. Das geschieht in der Regel, um die Leistung des Klassifikators für den gegebenen Datensatz zu bewerten.
Klicken Sie auf More Options, können Sie neben einigen anderen Optionen die zu verwendenden Bewertungsmetriken auswählen. Dabei handelt es sich aber um einen fakultativen Schritt, den Sie anfangs auch überspringen können. Ein anschließender Klick auf die Schaltfläche Start führt den gewünschten Task mit dem ausgewählten Klassifikator aus. Im rechten Teil des Fensters werden die vom Classifier vorgenommenen Schritte und die Ergebnisse mit den Werten der ausgewählten Metriken angezeigt. Sie haben nun die Möglichkeit, denselben Klassifikator immer wieder mit denselben oder anderen Parametern beziehungsweise Optionen auszuführen. Stellt die Leistung eines Klassifizierers Sie nicht zufrieden, wechseln Sie zu einem anderen.
Auf diese Weise probieren Sie mit einem Tool und in einer grafischen Oberfläche verschiedene Algorithmen durch, um den am besten geeigneten zu finden. Möchten Sie sich auf einen einzigen Klassifikator konzentrieren, kann die automatische Parameterabstimmung mittels Kreuzvalidierung erfolgen, um die optimalen Werte zu ermitteln. Nach genau demselben Schema können Sie auch Cluster-Algorithmen wie SimpleKMeans, FarthestFirst oder HierachicalCluster im entsprechenden Tab verwenden. Association Rule Mining lässt sich auf der Registerkarte Associate ausführen, und der Apriori-Algorithmus hilft beim Mining häufiger Muster.
Zu guter Letzt unterstützt Sie der Tab Visualize dabei, die Daten visuell zu untersuchen. So lassen sich etwa automatisch Scatter-Plots aller Attributkombinationen ausgeben (Abbildung 8). Die verschiedenen Farben stehen dabei für unterschiedliche Klassenzugehörigkeiten. Das ist sehr hilfreich, um Beziehungen zwischen den Attributen zu entdecken, was wiederum beim Filtern und bei der Analyse unterstützt.
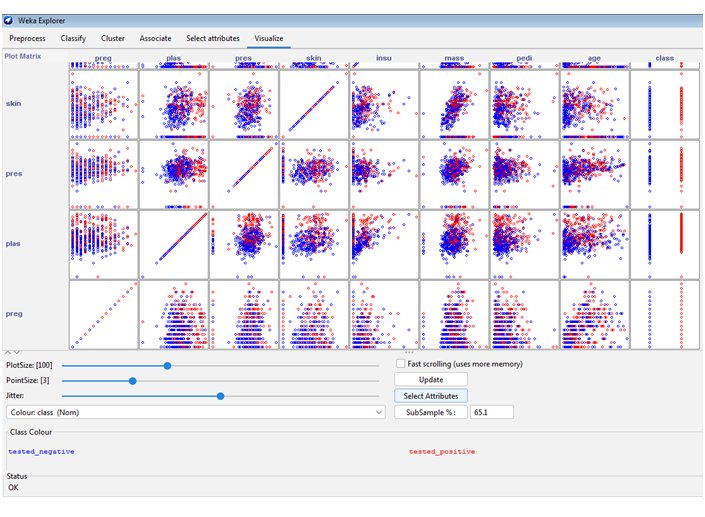
Abbildung 8: Im Tab Visualize untersuchen Sie die Daten visuell, etwa mithilfe eines Scatter-Plots.
Fazit
Dieser Artikel zeigt, wie Weka Ihnen helfen kann, Ihre Aufgaben im Bereich maschinelles Lernen zu vereinfachen. Auf wenigen Seiten lässt sich Weka nicht vollständig vorstellen. Die Stärke des Tools liegt zudem gerade in der praktischen Anwendung. Je vertrauter der Benutzer mit den Begriffen und Aufgaben des maschinellen Lernens ist, desto besser kommt er mit Weka zurecht. Neulinge im Bereich des maschinellen Lernens werden sicherlich die Leichtigkeit und Flexibilität bewundern, die Weka bietet. Damit verhindert das Werkzeug, dass sich Forscher bei schwierigen Programmieraufgaben verzetteln. Die Autorin hat Weka sowohl in der Lehre als auch in der Forschung ausgiebig genutzt und kann es nur jedem empfehlen. (jcb/jlu)
Die Autorin
Dr. Manju Bhardwaj, Associate Professor am Department of Computer Science des Maitreyi College der University of Delhi, hat mehr als 25 Jahre Lehrerfahrung. In ihrer Doktorarbeit beschäftigte sie sich mit Klassifizierungsensembles. Sie hat an zahlreichen Konferenzen teilgenommen und Vorträge gehalten sowie Beiträge in renommierten internationalen Zeitschriften veröffentlicht. Zudem ist sie als Gutachterin für IEEE-Journale aktiv.
Infos
- Weka-Wiki: https://waikato.github.io/weka-wiki/





