
© Nattanan Srisut / 123RF.com
Ceph ist heute zwar nicht mehr die neuartige, hippe Software wie vor einer Dekade, doch tut sich beim verteilten Objektspeicher noch immer eine Menge. Die neueren Releases setzen immer stärker auf Container.
An wenigen Stellen in der modernen IT galt in den vergangenen Jahren der Grundsatz “Des einen Leid, des anderen Freud” so sehr wie beim Thema Speicher. Einerseits führt der Umstand, dass Internet-Anbieter immer häufiger Plattform-Provider sind, zu riesigen Installationen, denen die etablierten Hersteller eigentlich viel Speicher verkaufen könnten. Andererseits hat sich das Geschäftsmodell der klassischen Storage-Hersteller aber zumindest zum Teil in Luft aufgelöst, denn gerade in skalierbaren Umgebungen funktionieren klassische SAN- und NAS-Anwendungen nur bedingt: Sie skalieren nicht gut genug. Wer aber mehrere solcher Geräte betreibt, dem geht ihr zentraler Vorteil des Single Point of Administration verloren. Obendrein erscheint es aus Sicht des Admins auch nicht sehr attraktiv, sich dauerhaft an einen Anbieter zu binden, dessen sündhaft teure Ersatzteile er dann kaufen muss.
Das Leid der Storage-Hersteller ist zugleich die Freude von Lösungen für Software Defined Storage. Sehr zum Verdruss manches Hardwareherstellers tauchte Ende der 2010er-Jahre eine Storage-Lösung auf, die komplett in Software gegossen war und obendrein nahtlose Skalierbarkeit versprach: Ceph. Dass Ceph physik- und designbedingt manchen Nachteil hat, tat seiner Popularität in Umgebungen mit hohen Ansprüchen an die Skalierbarkeit keinen Abbruch. Zwischenzeitlich verleibten sich die roten Hüte aus Raleigh Ceph ein, stellten es aber auf die Füße einer eigenen Stiftung unter Ägide der Linux Foundation.
Bis heute erfreut sich Ceph in Clouds großer Beliebtheit. Obwohl die Lösung inzwischen viel reifer ist als 2010, legt sie weiterhin beachtliche Entwicklungssprünge hin. Das Linux-Magazin berichtet in regelmäßigen Abständen von den jüngsten Neuerungen im Ceph-Land – und nach über zwei Jahren [1] ist es dafür jetzt wieder höchste Zeit.
Ein neuer Stern: Cephadm
Die Ceph-Entwickler gewähren für ihre Releases üblicherweise zwei Jahre Support, manchmal aber auch mehr. Ceph Nautilus etwa, die Major-Version 14, hätte eigentlich Anfang Juni 2021 bereits aus dem Support fallen sollen. Allerdings stand es bei Redaktionsschluss Anfang Oktober noch immer auf der Liste aktiver Releases. Das dürfte auch damit zusammenhängen, dass ein großer Teil der aktuell laufenden Ceph-Cluster – jene, die Red Hat Storage nutzen – auf Ceph Nautilus setzen. Das bedeutet allerdings auch, dass die Admins solcher Setups der Ceph-Entwicklung fast zwei Jahre hinterherhinken und sich absehbar mit einem Berg an Neuerungen zu befassen haben. Die für den Alltag des Admins bedeutsamste davon dürfte Cephadm sein – ein Werkzeug, mit dem sich ein gesamter Ceph-Cluster in kürzester Zeit ausrollen lässt.
Passionierte Ceph-Systemverwalter rümpfen darüber wahrscheinlich die Nase. Wer sich seit Jahren mit Ceph beschäftigt und es betreibt, der findet zunächst nichts Aufregendes an der Meldung, es gebe ein neues Deployment-Werkzeug dafür. Zu viele Tools haben Ceph-Veteranen zwischenzeitlich kommen und gehen sehen: Mkcephfs, Ceph-deploy, Ceph-install, Suse Crowbar und so weiter. Keine dieser Lösungen entpuppte sich als sonderlich dauerhaft, alle sind heute nur noch Fußnoten in der Ceph-Geschichte. Zudem kann man ja auch noch Automationslösungen zusammen mit Ceph einsetzen, etwa die Ansible-Playbooks, die teilweise Funktionen früherer Deployment-Werkzeuge nachrüsten.
Bei Cephadm liegen die Dinge allerdings etwas anders, und es scheint, als bleibe das Tool Ceph-Verwaltern langfristig erhalten. Es handelt sich nicht nur um ein einfaches Binary zum Ausrollen von Ceph. Cephadm fußt vielmehr auf dem Ceph Manager Ceph-mgr, und der wiederum ist nicht weniger als eine Mini-Automationslösung exklusiv für Ceph.
Kontrollinstanz
Overengineering mag der erste Begriff sein, der dem einen oder anderen Beobachter dabei in den Sinn kommt. Ganz so einfach liegt die Sache aber nicht, denn der Ceph-Manager dient in Ceph längst nicht nur zum Deployment. Er erfüllt im Kontext des Ceph-Dashboards (dazu später mehr) viele weitere wichtige Funktionen. Zudem beherrscht er das Ausführen von Befehlen auf entfernten Systemen, und eben diese Funktion macht Cephadm sich zunutze.
Für Admins ist das vor allem dann praktisch, wenn sie einen neuen Ceph-Cluster an den Start bringen. Dafür gilt es zunächst sicherzustellen, dass ein System in der Umgebung als Deployment-Host fungiert, von dem aus Cephadm sein Werk verrichtet. Von diesem System aus muss sich ein festgelegter Benutzer, etwa der User Ceph, per SSH auf den anderen Knoten des Systems einloggen können, ohne dass die Abfrage eines Passworts den Vorgang unterbricht (Abbildung 1). Das Deployment passender öffentlicher SSH-Schlüssel automatisiert der Systemverwalter idealerweise per Ansible oder einer anderen Lösung.
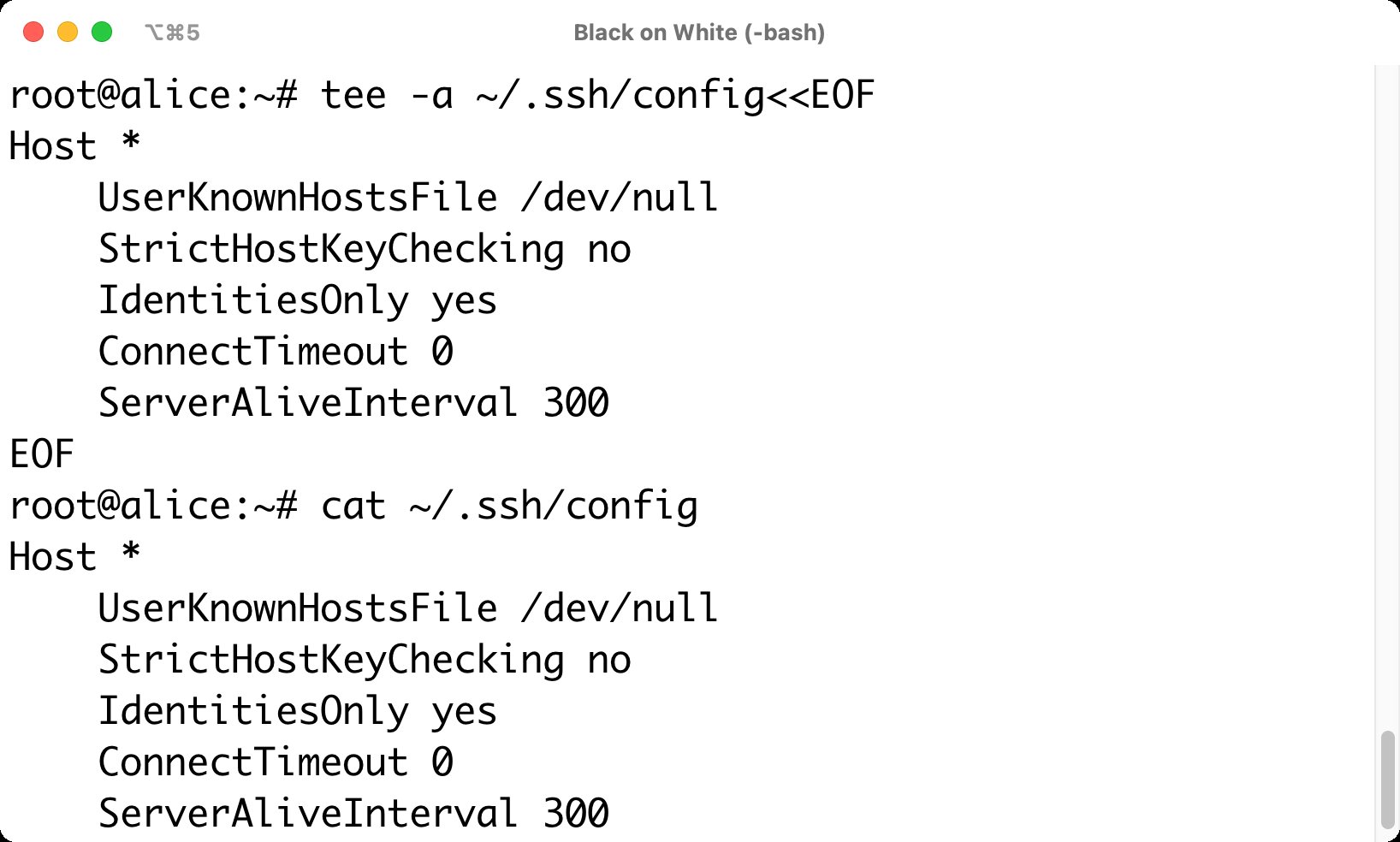
Abbildung 1: Damit Cephadm zwischen den Hosts hin und her springen kann, muss der Admin SSH entsprechend konfigurieren und die passenden Schlüssel hinterlegen.
Nach dem Festlegen des Deployment-Hosts geht es ans Eingemachte. Mittels Cephadm weist der Admin den Ceph-Manager dann an, die für den Ceph-Betrieb nötigen Komponenten auf dem Zielsystem zu installieren. Zur Erinnerung: Ceph besteht im Kern aus RADOS, einem verteilten Objektspeicher. Der wiederum braucht zumindest drei Instanzen der sogenannten Monitoring-Server (MON) sowie drei Object Storage Daemons (OSDs) in den einzelnen Systemen, damit er funktioniert. Ein theoretischer Ceph-Cluster wäre auch mit weniger Hardware möglich, doch ergibt solch ein Setup in der Praxis kaum Sinn.
Wenn zum Beispiel die drei Ceph-Knoten Ceph-1, Ceph-2 sowie Ceph-3 heißen, legt der Admin den ersten MON-Server auf Ceph-1 als Bootstrap-Knoten an (Listing 1, Zeile 1 bis 4), sorgt für eine Grundausstattung (Zeile 5 und 6) und nimmt die anderen beiden Knoten in die Orchestrierung auf (Zeile 7 und 8) – dazu müssen sich die Hostnamen allerdings per DNS auflösen lassen. Dann folgt das Deployment der MON-Server (Zeile 9 bis 11). Es fehlen nur noch die OSDs, die der Admin für die drei Knoten mit dem Befehl aus Zeile 12 hinzufügt, wobei er Name durch den per DNS auflösbaren Hostnamen ersetzt.
Listing 1
MON-Server anlegen
# cephadm bootstrap --mon-ip 192.168.122.112 \ --initial-dashboard-user admin \ --initial-dashboard-password Str0ngAdminP@ssw0rd \ --dashboard-password-noupdate # cephadm add-repo --release pacific # cephadm install ceph-common # ceph orch host add ceph-2 # ceph orch host add ceph-3 # ceph orch apply mon 3 # ceph orch host label add ceph-2 mon # ceph orch host label add ceph-3 mon # ceph orch daemon add osd Name [...]
Cephadm findet auf den drei Hosts die für Ceph nutzbaren Platten automatisch und macht OSDs daraus. In unserem Beispiel sollte das Kommando »ceph -w« einen laufenden Ceph-Cluster im Status »HEALTH_OK« mit drei MON-Servern und drei OSDs zeigen. Stehen mehr Speicherlaufwerke zur Verfügung, schlägt sich das auch in der Ausgabe von » ceph -w« nieder (Abbildung 2).
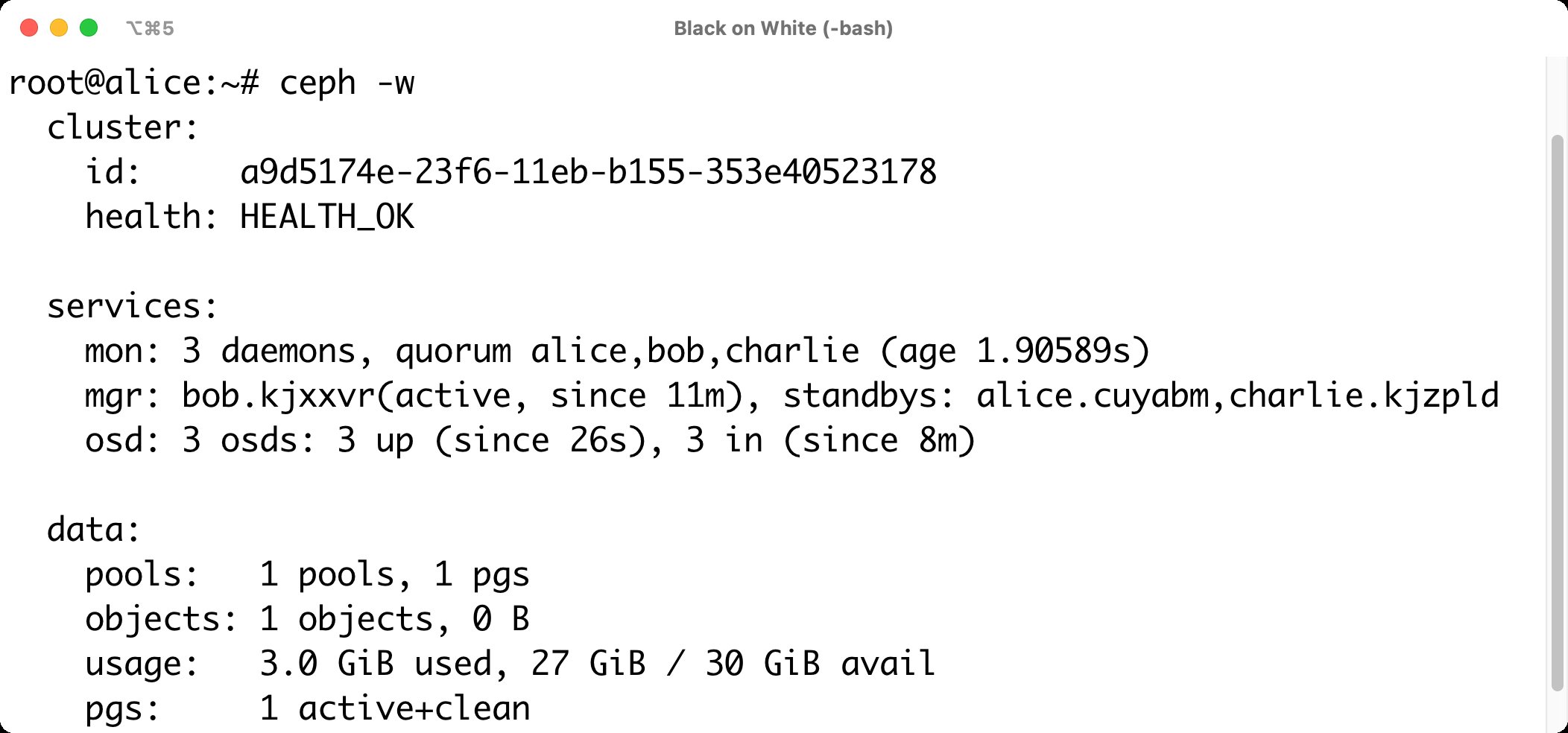
Abbildung 2: Cephadm stampft in Windeseile einen Ceph-Cluster aus dem Boden, der unter der Haube auf in Container verpacktes Ceph setzt.
Wie das Exempel verdeutlicht, ist Cephadm in der Tat hilfreich, um schnell Ceph-Cluster an den Start zu bringen.
Es containert heftig
Manchem aufmerksamen Beobachter mag möglicherweise bereits dämmern, wieso Cephadm so viel schneller und komfortabler ans Werk geht als mancher seiner Vorgänger: Es containert, und zwar heftig. Wer nach dem Ceph-Deployment mit Cephadm laufende Ceph-Prozesse oder Mounts im Host-System sucht, wird enttäuscht: Die aktuelleren Ceph-Releases setzen nach dem Willen von Anbieter Red Hat mittlerweile praktisch ausschließlich auf Container.
Wer möchte, erhält weiterhin RPM- oder DEB-Pakete. Auf die sollte man sich jedoch nicht allzu lange verlassen: Red Hat hat diesen Deployment-Weg bereits als “deprecated” gebrandmarkt, passende Pakete wird es wohl nicht bis in alle Ewigkeit geben. Aus Sicht des Anbieters ergibt das durchaus Sinn, denn für die roten Hüte ist es viel einfacher, einen Satz Ceph-Container für jede Major-Version von Ceph zu pflegen. Die müssen lediglich mit Docker oder Podman kompatibel sein und lassen sich schließlich auf allen Systemen mit einer Laufzeitumgebung für Container anstandslos betreiben. Um die Unterschiede zwischen Distributionen kümmert sich Cephadm notfalls selbst.
Für Admins, die sich in Sachen Container noch nicht ganz sattelfest fühlen, bringt der neue Deployment-Mechanismus allerdings manche Herausforderung mit sich. Umparken im Kopf ist angesagt: Durch die Installation von Ceph-common (Listing 1, Zeile 6) stehen die meisten Ceph-Befehle zwar auch auf der Kommandozeile des Ceph-Host-Systems zur Verfügung. Wer aber Logdateien sucht oder einzelne Instanzen von MON oder OSD-Servern debuggen möchte, der steigt in den Container hinab. Auch das Handling der einzelnen Daemons ändert sich: Systemctl muss nicht mehr nur eine Instanz von Ceph-OSD in die ewigen Jagdgründe befördern, sondern einen ganzen Container samt zugehörigem Workload.
Das macht in Summe ein Ceph-Setup aus Sicht des Systemverwalters etwas komplexer. Die Entwickler steuern dagegen und wollen dem Admin das neue Modell für Ceph-Deployments mit Vereinfachung und Automation schmackhaft machen. So soll Cephadm in Zukunft etwa hauptverantwortlich für das Update von Ceph-Clustern bei neuen Major-Releases sein. Zwischen Ceph Octopus und Ceph Pacific klappt das schon ganz gut: Es genügt ein einzelner Befehl in Octopus, wo Cephadm bereits mit deutlich weniger Features zur Verfügung stand, und nach etwas Rödelei präsentiert sich dem Admin ein frisch aktualisierter Cluster.
Dashboard kann mehr
Insbesondere bei so elementaren Diensten wie Ceph mögen Admins keine Veränderung. Den Ceph-Machern ist klar (und sie sagen das auch offen), dass die Änderungen beim Deployment von Ceph für viele Systemverwalter eher harter Tobak sind. Fast schon wie zur Entschuldigung betrieben die Entwickler daher in den vergangenen anderthalb Jahren enormen Aufwand, um das Ceph-Dashboard (Abbildung 3) von einem Eye Candy in ein wirklich nützliches Werkzeug zu verwandeln.
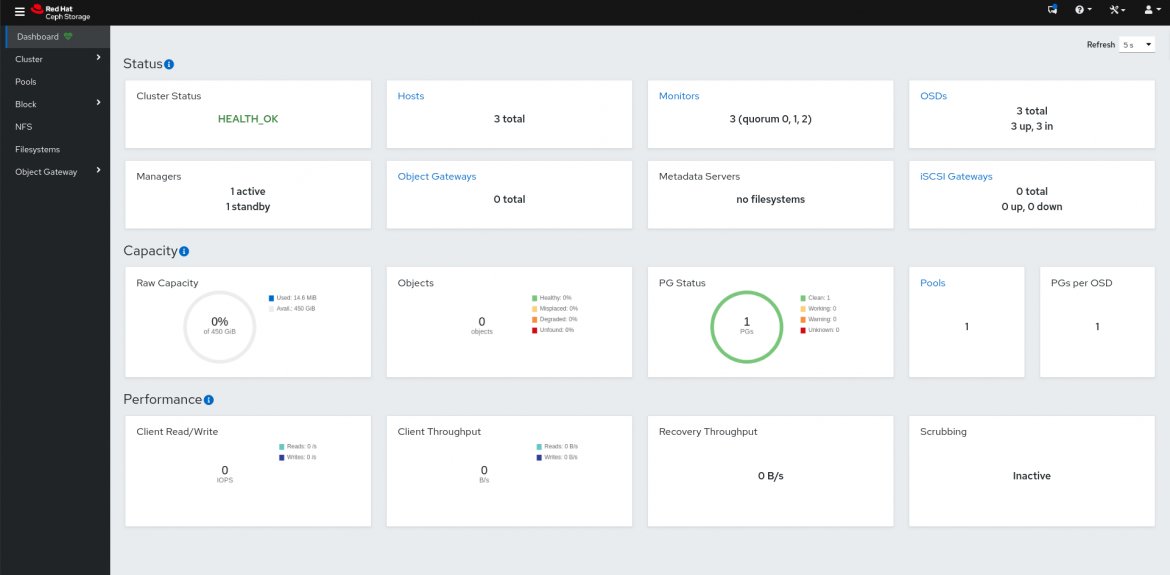
Abbildung 3: Das Ceph-Dashboard legte in den vergangenen Jahren massive Entwicklungssprünge hin. Das multifunktionale Interface lässt sich per Thema an die Optik eines Herstellers anpassen. Quelle: Inktank
Das Dashboard ging ja bekanntlich aus OpenAttic hervor, das Suse vor etlichen Jahren von IT-Novum erwarb. Seinerzeit zeigte das Tool nur wenige Details eines Ceph-Clusters an, mittlerweile ist es eng mit dem Ceph-Manager und mithin auch mit Cephadm verzahnt. Das macht sich im Alltag deutlich bemerkbar. In der aktuellen Ceph-Version Pacific (Abbildung 4) ist es etwa möglich, einzelne Hosts per Mausklick in den Wartungsmodus zu schicken. Die Informationen zu einzelnen OSDs kann man nun detailliert anzeigen. Wer etwa wissen will, ob ein Gerät auffällige SMART-Warnungen produziert, sieht das im Dashboard künftig auf den ersten Blick.
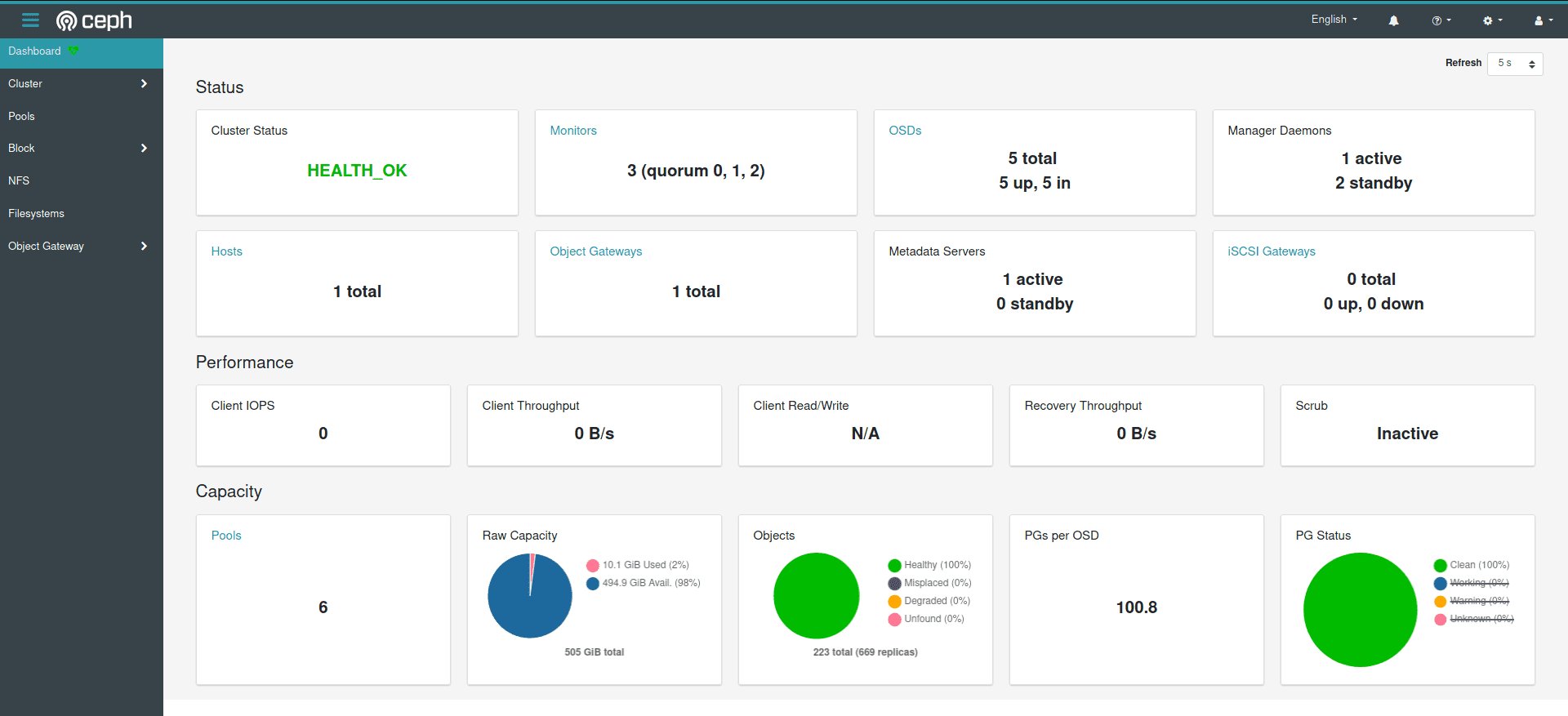
Abbildung 4: Neu im Dashboard in Ceph Pacific ist eine verbesserte Übersicht über den Zustand des Clusters. Quelle: Inktank
Obendrein lassen sich per Dashboard nun OSDs anlegen und auch wieder löschen (Abbildung 5). Einige Teilbereiche wie die Darstellung von Placement Groups oder den Statistiken zu CephFS zeigt das Dashboard deutlich genauer an als zuvor. Zudem lassen sich Instanzen des RADOS Object Gateways (RGW) per Dashboard so zusammenschließen, dass die Datensynchronisation ohne weitere Konfiguration als Feature von RGW funktioniert.
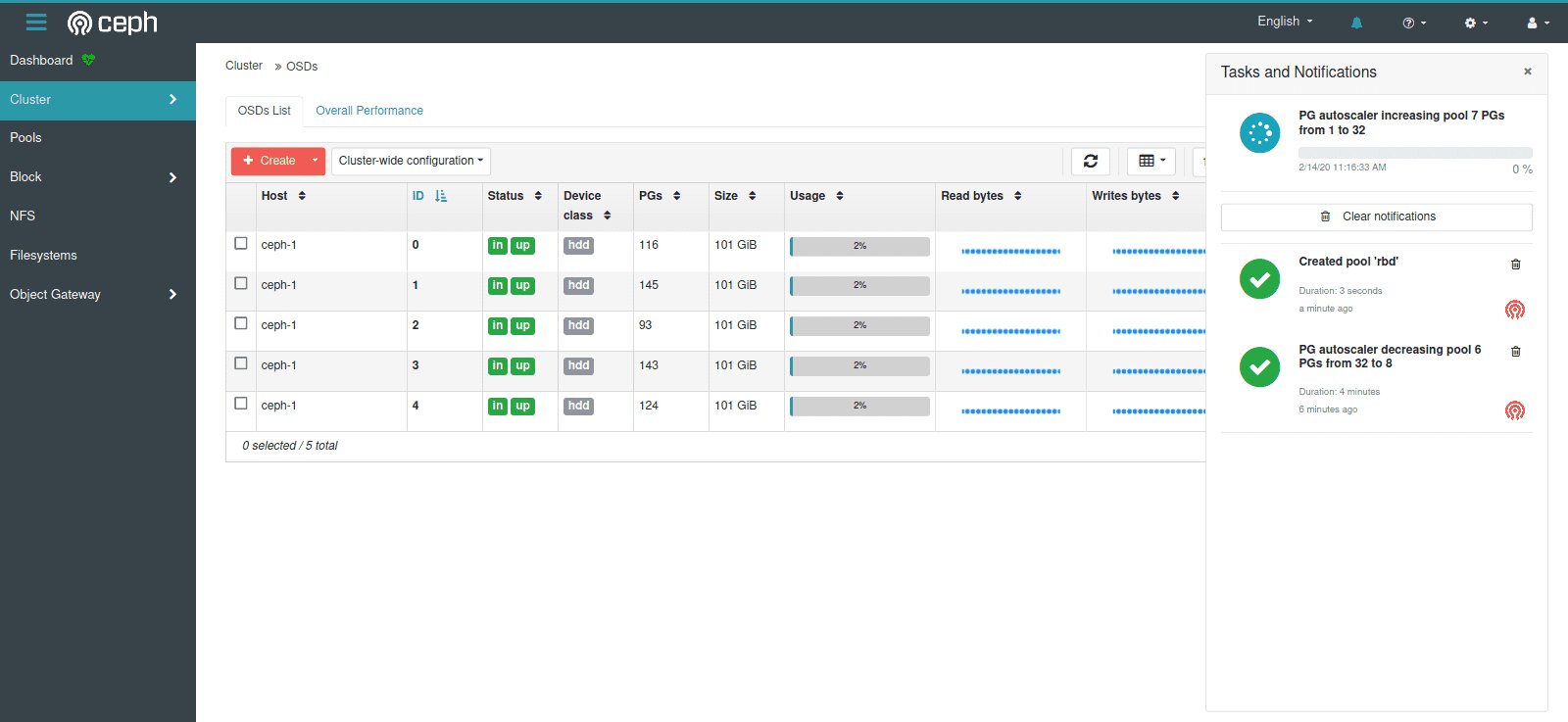
Abbildung 5: Das Dashboard bietet nun die Ansicht über einzelne Hosts und einzelne OSDs, die sich von hier aus auch starten, stoppen oder entfernen lassen. Quelle: Inktank
In Summe erweist sich das Ceph-Dashboard in Pacific damit als alltagstauglicher Helfer, der den Vergleich mit der Management-GUI mancher kommerziellen Speicherlösung nicht zu scheuen braucht. Das verleiht Ceph gerade im Business-Kontext einen echten Schub, denn das Fehlen einer Enterprise-tauglichen UI war bis dato einer der Hauptkritikpunkte an der SDS-Umgebung.
Unter der Haube
Auch bei den Kernkomponenten von Ceph ergaben sich in den vergangenen Monaten und insbesondere im Zug des Pacific-Releases viele Neuerungen. Nicht ganz so frisch ist eine Änderung, die bereits in Ceph Octopus Einzug hielt: das Balancer-Modul für den Ceph Manager, das allerdings erst Ceph Pacific standardmäßig aktiviert. Unter der Haube weist Ceph die binären Objekte ja sogenannten Placement Groups (PGs) zu. Die Anzahl der Placement Groups pro Pool spielt eine wesentliche Rolle für die Performance des Clusters. In früheren Ceph-Versionen war es die Aufgabe des Admins, die Zahl der PGs pro Pool zu definieren. Das kann Ceph dank des Scaling-Moduls mittlerweile automatisch, und zwar sowohl im Hinblick auf die Zahl der PGs im Cluster als auch im Hinblick auf die dynamische Verteilung der PGs auf einzelne OSDs.
Ebenfalls in die Performance-Kerbe schlägt eine Veränderung in BlueStore, dem Ceph-eigenen On-Disk-Format. Hier kommt eine RocksDB genannte Datenbank zum Einsatz, die diverse Werte im Hinblick auf die Ablage von binären Objekten auf dem Datenträger verzeichnet. Bis Ceph 15 nutzten die OSDs dafür in der RocksDB lediglich eine einzelne Spalte, die sämtliche Objekte mit ihrer physischen Adresse aufnahm. Das bedeutete logischerweise auch, dass Ceph beim Zugriff auf Objekte auf einem bestimmten OSD die gesamte RocksDB lesen und verarbeiten musste. Je mehr Objekte es auf einem OSD gab, desto länger dauerte das. In Ceph Pacific teilt das OSD die RocksDB in mehrere Spalten auf, die sich am Präfix der einzelnen Objekte orientieren. Dadurch durchsucht ein OSD beim Zugriff auf Objekte deutlich kleinere Tabellenbereiche, was wesentlich weniger Zeit in Anspruch nimmt.
Nicht zuletzt haben die Ceph-Entwickler auch an der Heuristik geschraubt, die die möglichen Ursachen für Datenkorruption erkennt. MTU-Unterschiede zwischen den Systemen etwa generieren zum Teil skurrile Effekte. Erkennt Ceph solche Divergenzen, schlägt es nun – anders als vorher – Alarm.
Blockspeicher wird erwachsen
Viel Liebe seitens der Entwickler erfährt zudem das Ceph Block Device, auch RADOS Block Device oder kurz RBD genannt. Grundlegender Support für verschlüsselte Volumes auf der Client-Seite steht etwa seit Ceph 16 zur Verfügung. Weil neue Räder oft nicht runder ausfallen als ihre Vorgänger, erfinden die Ceph-Entwickler kein neues Rad, sondern setzen auf LUKS. Reif für den Produktionseinsatz dürfte das Feature allerdings erst in der nächsten Ceph-Version sein; hier heißt es also, sich noch etwas zu gedulden.
Für die Nutzer von Windows-Systemen hingegen hat das Warten endlich ein Ende: Mittels eines Wrappers (»librbd.dll«) bindet RBD in Ceph Pacific endlich Rbd-wnbd an, eine Implementierung des Network Block Devices (NBD) für Windows. Dadurch lassen sich auf Windows-Systemen RBD-Abbilder wie lokale Blockspeichergeräte ins Dateisystem einhängen.
Was lapidar klingt, kommt faktisch einer Revolution gleich: Zwar lesen Sie den Artikel im Linux-Magazin, aber wie fast jeder Admin weiß, der einen Ceph-Cluster betreibt, kommt man gelegentlich nicht umhin, Ceph-Geräte an VMware- oder Hyper-V-Systeme anzubinden. Bis dato funktionierte das lediglich über hässliche Krücken wie iSCSI, was zusätzliche Hardware bedingt und mehr Wartungsaufwand generiert. Hyper-V-Festplatten lassen sich dank RBD for Windows nun aber nativ anbinden und in Hyper-V auch nutzen [2]. Wer damit aus technischer Sicht leben kann, wird damit iSCSI & Co. also künftig los (Abbildung 6).
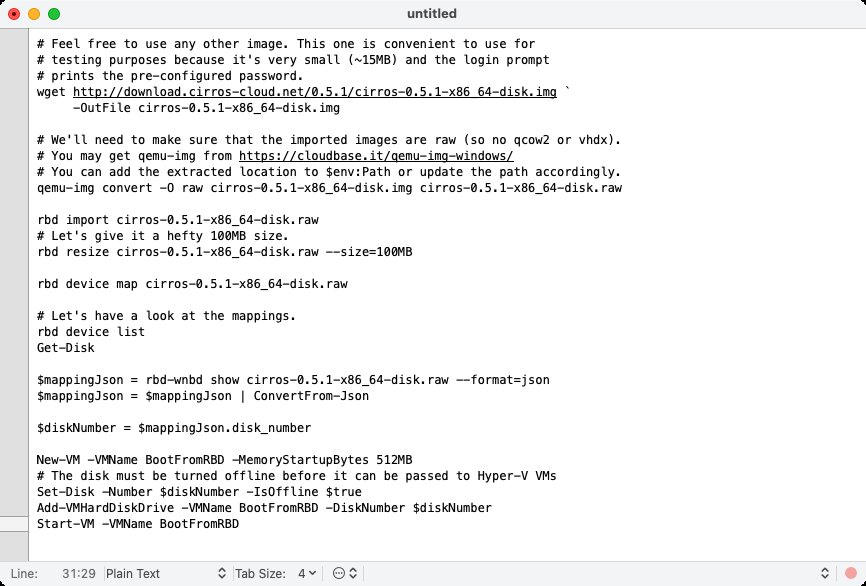
Abbildung 6: RBD-Images lassen sich nun auch unter Windows einhängen. Das ermöglicht es, Hyper-V-VMs unter Windows zu starten und zu betreiben.
S3-Support und LUA-Skripte
Das RADOS Object Gateway (RGW) hat sich in den vergangenen Jahren vom Nischenprodukt zu einem wichtigen Umsatzbringer für Red Hat gemausert. Zwar unterstützt Ceph nicht das volle S3-Protokoll – das kann es auch gar nicht, weil S3 kein offenes Protokoll ist und Ceph daher auf Reverse Engineering angewiesen ist. Grundsätzlich ist ein RADOS mit vorgeschaltetem RGW aber so kompatibel, dass die am Markt etablierten S3-Clients damit kooperieren. Und weil es immer mehr in Mode kommt, S3-basierten Speicher als Asset-Store und Quasi-CDN zu nutzen, wächst auch der Bedarf an leistungsstarken S3-Implementierungen.
RGW wird diesem Bedarf durch kontinuierliche Erweiterung gerecht. Seit Ceph Pacific kennt es etwa grundlegenden Support für den Select-Befehl. Der erlaubt es, besonders große Dateien im S3-Speicher zu durchsuchen, ohne die gesamte Datei herunterzuladen. Das reduziert Datentransfers, funktioniert allerdings nur für Formate wie SQL oder CSV.
Ebenfalls neu in Pacific ist die Fähigkeit des Object Gateways, LUA-Skripte für den Zugriff auf Buckets zu speichern und sie wahlweise vor oder nach dem Zugriff auszuführen. Der Fantasie, was sich per LUA-Skript umsetzen lässt, sind dabei kaum Grenzen gesetzt, denn das RADOS Object Gateway unterstützt alle LUA-Funktionen.
Liebe auch für CephFS
Von allen Ceph-Komponenten hat CephFS in den vergangenen Jahren wohl die erstaunlichste Transformation durchlaufen. Früher galt das POSIX-kompatible Dateisystem, das im Hintergrund auf RADOS zugreift, als hässliches Entlein, das nicht fertig werden wollte. Heute ist es eine zuverlässige Ceph-Komponente, die eine stetige Weiterentwicklung erfährt.
Beispielsweise ließ sich bis Ceph Octopus nur ein einziges CephFS pro RADOS-Cluster betreiben. Wer Separation of Concern implementieren wollte, musste das über POSIX-Zugriffsberechtigungen erledigen. Damit macht Pacific Schluss: CephFS unterstützt mittlerweile den Betrieb mehrerer paralleler CephFS-Instanzen. Mittels CephX lässt sich wie gewohnt der Zugriff auf die einzelnen Dateisysteme beschränken. Apropos beschränken: Wenn Ceph wegen zu vieler Zugriffe in Sachen Performance in den Seilen hängt, verrät das neue Werkzeug Cephfs-top, wer für die Last in welchem Umfang verantwortlich ist. Zudem lassen sich CephFS-Dateisysteme nun mit Ceph nativ per NFS exportieren; CephFS fungiert dann als NFS-Gateway.
Praktisch für Nutzer, die Disaster Recovery brauchen: Ceph Pacific liegt ein neues Werkzeug namens Cephfs-mirror bei, das ein CephFS aus Cluster 1 in ein CephFS von Cluster 2 spiegeln kann. Die Ceph-Entwickler folgen hier einmal mehr dem Mantra, Mirror-Funktionalität nicht auf der RADOS-Ebene zu implementieren, sondern das Thema Client-seitig abzuwickeln. RBD (Rbd-mirror) und das Objekt Gateway (mit eigenem Spiegel-Daemon) haben vorgemacht, wie es geht; CephFS schlägt nun denselben Weg ein. Dabei kopiert die Mirror-Funktion nie den gerade aktuellen Zustand hin zu einer anderen Location, sondern nutzt die CephFS-Snapshot-Funktionalität. Nur so lässt sich sicherstellen, dass sich der transferierte Datensatz nicht on the fly ändert.
Daneben erfreuen mehrere neue Komponenten mit CephFS-Bezug die Anwender. Auch CephFS lässt sich jetzt, man mag es kaum glauben, mit Windows verbinden. Möglich macht das Ceph-dokan, das die Dokan-API unter Windows nutzt und dort ähnliche Features wie Fuse unter Linux zur Verfügung stellt. Dafür, dass die Funktionalität komplett im Userspace arbeitet und noch recht neu ist, schlägt sie sich im Performance-Test schon sehr passabel.
Community-Aspekte
Fernab von aller Technik und diversen Deployment-Methoden tut sich auch innerhalb der Ceph-Community weiterhin viel, aus mehreren Gründen. Zunächst hat Red Hat Ceph einen großen Dienst erwiesen, als man das geistige Eigentum am Produkt erwarb, es dann jedoch in eine Stiftung nach dem Vorbild der Linux Foundation auslagerte. Streng genommen handelt es sich bei der Ceph Foundation [3] sogar nur um eine Abteilung der Linux Foundation, weil man in Raleigh keine Lust hatte, den Papierkram für eine eigene Stiftung nach amerikanischem Recht zu erledigen. Letztlich war das wohl auch nicht nötig, denn im Vordergrund stand das Ziel, Ceph als freie Software zu schützen und langfristig zu erhalten – das klappt unter dem Dach der Linux Foundation ganz hervorragend.
Auf ihrem Online-Auftritt Ceph.io organisiert die Ceph Foundation diverse Community-Events, bedingt durch Corona noch immer online. Jeden vierten Donnerstag im Monat etwa findet um 18 Uhr MEZ ein Tech Talk statt, bei dem diverse Granden aus der Ceph-Gemeinde (zum Teil auch Core-Entwickler wie Ceph-Erfinder Sage Weil persönlich) Einblicke in die aktuelle Entwicklung geben oder aus dem Nähkästchen plaudern, was den sicheren und effizienten Ceph-Betrieb angeht. Wer beruflich mit Ceph zu tun hat und etwa einen Ceph-Cluster betreibt, der findet hier oft interessante Anregungen und Informationen.
Ebenso hostet die Community mittlerweile ihre Mailing-Listen auf Ceph.io. Diese dienen nach wie vor als zentrale Anlaufstelle für Nutzer, die Fragen zu Ceph haben oder beim eigenen Cluster Probleme beobachten. Was die Ceph-Community bis heute dabei auszeichnet: Die Ceph-Mailing-Listen dienen tatsächlich als Forum für Hilfe und Feedback, nicht etwa als verkappter Lead-Generator für Support-Verträge. Hier ist auch willkommen, wer Ceph nicht in Form des Red Hat Storages aus Raleigh bezieht.
Fazit
Der Umstieg von Ceph auf durchgehende Containerisierung erfreut sicherlich nicht jeden Admin, war aber zu erwarten. Aus Red-Hat-Sicht fällt es viel leichter, Ceph zu pflegen und für unterschiedliche Distributionen zur Verfügung zu stellen, wenn es in Form von Containern vorliegt. Die Verfügbarkeit von Cephadm als Werkzeug für das Deployment einerseits sowie das heftig aufgebohrte Ceph-Dashboard andererseits erleichtern dem Admin den Umstieg und die Wartung von Ceph. In Summe zeigen die Änderungen, dass Ceph noch lange nicht fertig ist und man auch in Zukunft mit Entwicklungssprüngen rechnen muss. ((jcb)/jlu)
Der Autor
Der freie Journalist Martin Gerhard Loschwitz beschäftigt sich vorrangig mit Themen wie OpenStack, Kubernetes und Ceph.
Infos
- Neues bei Ceph: https://www.linux-magazin.de/ausgaben/2019/06/neues-bei-ceph<
- RBD mit Hyper-V: https://docs.ceph.com/en/latest/rbd/rbd-windows/
- Ceph-Foundation: https://ceph.io/en/foundation/





