
© milkos / 123RF.com
Fuzzing gilt heute als wichtigstes Verfahren, um Software auf Robustheit zu testen und Sicherheitslücken zu finden. Dieser Artikel erläutert, was es damit auf sich hat und welche Methoden dabei heute gebräuchlich sind.
Es war eine dunkle und stürmische Nacht. Bart Miller – am Ende unseres Themenschwerpunkts finden Sie ein Interview mit ihm – arbeitete zu Hause und war per 1200-Baud-Modem mit dem Großrechner der Universität Wisconsin verbunden. Doch mit jedem Donnern ging etwas schief: Die Blitzeinschläge störten die Datenübertragung über die Telefonleitung und verstümmelten einzelne Zeichen, sodass Miller immer wieder von vorn beginnen musste.
Dabei fiel ihm auf, wie viele Programme mit gestörten Daten nicht zurechtkamen – sie stürzten ab, hängten sich auf oder stellten auf andere Weise unkontrolliert die Arbeit ein. Sollten die Programme nicht sehr viel besser mit ungültigen oder gestörten Eingaben klarkommen? Miller beschloss, dies von seinen Studenten systematisch untersuchen zu lassen und ihnen eine entsprechende Programmieraufgabe zu geben.
Diese Nacht im Herbst 1988 gilt als Geburtsstunde des Fuzz Testing, des heute mit Abstand wichtigsten Verfahrens, Programme auf Robustheit zu testen und auf Sicherheitslücken zu prüfen. Was Fuzzing ist, lässt sich direkt aus Bart Millers Programmieraufgabe herauslesen: “Das Ziel dieses Projekts ist es, die Robustheit verschiedener Unix-Hilfsprogramme zu prüfen, wenn sie einen unvorhersehbaren Eingabestrom erhalten. Als Erstes bauen Sie einen Fuzz-Generator. Das ist ein Programm, das eine zufällige Folge von Zeichen erzeugt. Dann nehmen Sie diesen Fuzz-Generator und nutzen ihn, um möglichst viele Unix-Hilfsprogramme anzugreifen, mit dem Ziel, sie zu zerstören.”
Diese Programmieraufgabe fasst die Grundidee des Fuzzings zusammen: Man erzeugt automatisch zufällige Eingaben, prüft, ob die damit beschickten Programme dann unvorhergesehene Dinge tun und wiederholt diese beiden Schritte sehr oft und sehr schnell.
Dabei nutzen Fuzzer verschiedene Techniken, um Fehler zu finden. Reine Zufallseingaben lassen sich einfach generieren und finden Fehler in der Eingabeverarbeitung wie etwa Pufferüberläufe. Modellbasierte Fuzzer nutzen Grammatiken und andere Sprachmodelle, um gültige und gezielte Eingaben zu erzeugen. Evolutionsbasierte Fuzzer mutieren Testeingaben, um Varianten zu finden, die möglichst viel Code abdecken. Constraint-basierte Fuzzer können komplexe Bedingungen im Programmcode lösen, brauchen dafür aber viel Zeit.
Spaß mit dem Zufall
Fuzzing mit reinen Zufallseingaben ist eine sehr einfache Sache: Wenige Zeilen Programmcode genügen, um die nötigen Eingaben zu erzeugen. Die Funktion »fuzzer()« aus Listing 1 generiert beispielsweise Zeichenketten aus zufälligen Zeichen, die in etwa so aussehen:
!7#%"*#0=)$;%6*;>638:*>80"=</>(/*:-(2<4 !:5*6856&?""11<7+%<%7,4.8+
Listing 1
Einfacher Fuzzer in Python
import random
def fuzzer(max_length=100, char_start=32, char_range=32):
"""Erzeuge eine Zeichenkette von bis zu `max_length` Zeichen
im Bereich [`char_start`, `char_start` + `char_range` - 1]"""
string_length = random.randrange(0, max_length + 1)
out = ""
for i in range(0, string_length):
out += chr(random.randrange(char_start, char_start + char_range))
return out
Solche Eingaben nannte Bart Miller Fuzz (deutsch: Flaum), als einen Begriff für unstrukturierte, zufällige Daten. Was kann ein solcher Fuzz anrichten? Stellen wir uns vor, dass wir diese Zeichenkette an ein Programm geben, das eine fünfstellige Postleitzahl erwartet. Hält es einen Puffer von fünf Zeichen für die Eingabe vor, dessen Kapazität die tatsächliche Eingabe aber überschreitet (der obige Fuzz ist über 60 Zeichen lang), dann kann es zu einem Pufferüberlauf kommen. Speicherbereiche hinter dem Fünf-Zeichen-Puffer werden von der Eingabe auf mehr oder weniger zufällige Art und Weise überschrieben, was wiederum ein mehr oder weniger zufälliges Verhalten des Programms nach sich zieht. Es kann abstürzen oder beim Versuch fünf Ziffern einzulesen in eine Endlosschleife geraten.
Erhält das Programm seine Eingaben über eine Webseite, könnten Angreifer etwa eine Zeichenkette wie die obige in ein Formular eintragen und so versuchen, das Programm zu stören oder es unbrauchbar zu machen. Da man jede Minute Millionen solcher Fuzz-Eingaben erzeugen kann, hätten die Angreifer auch viele Versuche frei. Sie brauchen sich nur zurückzulehnen und den Fuzz-Generator seine Arbeit machen zu lassen; nach Stunden oder Tagen kommt ja vielleicht ein Absturz zustande.
Beim Absturz muss es jedoch nicht bleiben. Da Pufferüberläufe auch kritische Daten wie Passwörter oder gar Programmcode überschreiben können, lässt sich die Eingabe möglicherweise so gestalten, dass der Angreifer die Kontrolle über das Programm oder sogar den Rechner erlangt. Dieser Teil der Arbeit ist noch nicht so automatisiert wie das Fuzz-Testen; bei Erfolg winken aber hohe Prämien für die gefundene Sicherheitslücke.
Schutz vor Falscheingaben
Heutige Programme sind gegen solche Angriffe geschützt. Grundsätzlich gilt es, keinen Daten zu trauen, die unter Kontrolle eines Dritten stehen, die also etwa von Anwendern, anderen Rechnern oder anderen Programmen kommen. Eine Webanwendung, die eine fünfstellige Postleitzahl erwartet, sollte also sichergehen, dass die Eingabe auch tatsächlich aus fünf Ziffern besteht, indem bereits das Eingabeformular prüft, ob die Eingabe korrekt ist. Der Server muss die übermittelten Daten auf Korrektheit prüfen, und dasselbe sollten alle Programme tun, die sie weiterverarbeiten. Zu guter Letzt dürfen Programme im Netz nur eine begrenzte Anzahl von Fehlversuche erlauben, bevor sie den Zugriff sperren.
1988 waren solche Mechanismen noch kaum verbreitet, und was Millers Studenten herausfanden, war alarmierend: Mehr als ein Drittel aller Unix-Hilfsprogramme konnten sie innerhalb von Sekunden zum Absturz bringen, indem sie sie mit Zufallseingaben traktierten. Man stelle sich vor, was heute passierte, wären ein Drittel aller Webanwendungen auf so triviale Weise verwundbar – das Internet, wie wir es kennen, wäre in Sekunden übernommen.
1988 jedoch steckte das Internet noch in den Kinderschuhen, und jeder Administrator kannte die Benutzer auf seinem Rechner persönlich. Tatsächlich hatte Miller anfangs Probleme, seine Erkenntnisse zu veröffentlichen. Die typische Antwort lautete: “Ja und? Warum sollte ich mich darum kümmern, was bei ungültigen Daten geschieht? Meine Anwender schicken mir gültige Daten!” Die Open-Source-Entwickler dieser Zeit sahen das anders und passten ihre Programme schnell so an, dass sie ungültige Eingaben erkannten und kontrolliert ablehnten. Auf diese Weise entwickelten die meisten GNU-Programme und der Linux-Kernel schnell eine Resistenz gegen Fuzz-Eingaben, und der so gesetzte Standard etablierte sich langsam auch im Rest der Programmierwelt.
Automatisch testen
Hat man ein Programm einmal gegen zufällige Zeichenketten im Miller-Stil gehärtet, fällt es einem Fuzz-Generator sehr schwer, noch Fehler zu finden. Das liegt daran, dass die meisten zufällig erzeugten Eingaben ungültig sind. Nehmen wir einmal an, unser Programm, das eine Postleitzahl verarbeitet, zeigt bei der Postleitzahl 00000 einen Fehler, etwa, weil diese Zahl für eine besondere Adresse steht. Wie groß ist die Chance, diese Eingabe zufällig zu erhalten?
Erzeugt unser Fuzz-Generator (vereinfacht) Eingaben zwischen einem und hundert Zeichen, dann liegt die Chance, dass es fünf Zeichen werden, bei 1:100. Nehmen wir außerdem an, dass der Generator hundert verschiedene (druckbare) Zeichen erzeugt, darunter zehn Ziffern. Dann ist die Chance, dass fünf Ziffern herauskommen, 1:105, also 1:100 000. Die Chance für fünf Nullen liegt sogar nur bei 1:1005, also bei 1 zu 10 Milliarden. Multipliziert mit der Chance, dass wir überhaupt Eingaben der Länge 5 erhalten, ergibt das 1 zu 1 Billion. Moderne Webanwendungen arbeiten schnell, aber selbst, wenn wir 1 Millisekunde pro Interaktion ansetzen, bräuchten wir im schlimmsten Fall 31 Jahre durchgehenden Rechnens, um den Fehler zu entdecken. Da bringt es mehr, Bitcoins zu schürfen.
Wissen wir allerdings, wie eine Eingabe aufgebaut ist, können wir die Chance drastisch erhöhen, indem wir dieses Wissen dem Fuzz-Generator verfügbar machen. Hier kommt eine leistungsfähigere Klasse von Generatoren ins Spiel, deren Funktionsprinzip auf das Jahr 1972 zurückgeht. Modellbasierte Fuzzer nutzen eine Spezifikation des Eingabeformats, um von vornherein gültige Eingaben zu erzeugen und so die zahlreichen Fehlversuche mit rein zufälligen Zeichenketten zu umgehen.
Ein bekanntes und gut verstandenes Verfahren zum Spezifizieren von Eingabeformaten sind Grammatiken, die den Aufbau einer Eingabe definieren. Die Grammatik aus dem Kasten “Aufbau einer Postleitzahl” beschreibt etwa den Aufbau einer PLZ. Eine solche Grammatik besteht aus Regeln, die für ein einzelnes Eingabeelement dessen Aufbau angeben: Eine <Postleitzahl> besteht aus fünf direkt aufeinanderfolgenden Ziffern; eine Ziffer ist eine von zehn durch »|« getrennten Alternativen.
Aufbau einer Postleitzahl
<Postleitzahl> := <Ziffer><Ziffer><Ziffer><Ziffer><Ziffer>
<Ziffer> := 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Ein modellbasierter Fuzzer nutzt nun diese Grammatik, um daraus Eingaben zu erzeugen. Dazu startet er mit einem Eingabeelement auf der linken Seite (etwa <Postleitzahl>) und ersetzt es durch den Text auf der rechten Seite (hier <Ziffer><Ziffer><Ziffer><Ziffer><Ziffer>). Das Ganze wiederholt er so lange, bis alle symbolischen Eingabeelemente ersetzt sind. Stehen auf der rechten Seite mehrere Alternativen zur Auswahl, greift er eine davon zufällig heraus. Somit ersetzt der Fuzzer jedes <Ziffer>-Eingabeelement durch eine der Ziffern 0 bis 9, sodass er etwa die Zufallsfolge 43672 erzeugt. Es kann auch 34829 oder 12456 sein – wichtig ist, dass es sich um fünf Ziffern handelt.
Mithilfe dieser Grammatik lässt sich die Chance, die problematische Postleitzahl 00000 zu finden, auf 1:100 000 reduzieren. Das hört sich immer noch nach vielen Tests an, aber auch modellbasierte Fuzzer erzeugen binnen Minuten Millionen von Eingaben. Und im Gegensatz zu reinen Zufallseingaben sind ihre Eingaben stets gültig, können so tiefer ins Programm vordringen und somit auch logische Fehler jenseits der Eingabeverarbeitung finden.
Wo Fuzzer Fehler finden
Während eine Eingabeverarbeitung reine Zufallseingaben in der Regel zurückweist, dringen modell- und evolutionsbasierte Fuzzer leichter bis zur Programmlogik vor. Constraint-basierte Fuzzer legen noch eine Schippe obendrauf (Abbildung 1). Tatsächlich lassen sich modellbasierte Fuzzer einfach einsetzen, um auch komplexe Eingaben zu erzeugen. Die Grammatik aus dem Kasten “Grammatik für Adressen” etwa erzeugt Adressdaten.
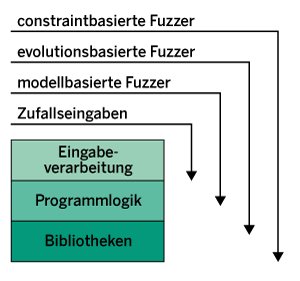
Abbildung 1: Verschiedene Fuzzer-Typen vermögen unterschiedlich tief in die Software einzudringen.
Grammatik für Adressen
<Adresse> := <Vorname> <Name>, <Straße> <Hausnummer>, <Postleitzahl> <Stadt>
<Vorname> := Anton | Berta | … | <Zufallsname>
<Name> := Müller | Schmidt | … | <Zufallsname>
<Stadt> := Berlin | München | <Zufallsname>
<Straße> := Hauptstraße | Putzbrunner Straße | <Zufallsname>-Straße
<Hausnummer> := <Ziffer> | <Hausnummer><Ziffer>
<Zufallsname> := <Buchstabe> | <Zufallsname><Buchstabe>
<Buchstabe> := A | B | C | … | Z
Hier entsteht aus der <Adresse> ein Datensatz wie »Berta Müller, Hauptstraße 10, 43679 München« erzeugt. Die Regeln für <Hausnummer> und <Zufallsname> erzeugen dabei eine Folge aus Ziffern beziehungsweise Buchstaben, woraus auch ungewöhnlichere Datensätze wie »Anton GJK, EIUYLHK-Straße 00, 23165 Berlin« resultieren.
Da der Benutzer Grammatiken erstellen und erweitern kann, ermöglichen sie, den Fuzzer gezielt zu steuern. So könnte ein Sicherheitstester etwa die obige Grammatik um eine sogenannte SQL-Injektion ergänzen, also einen Angriff, der Datenbank-Befehle in eine Eingabe einschleust (siehe Kasten “SQL-Injektion per Grammatik”).
SQL-Injektion per Grammatik
<Stadt> := Berlin | München | <Zufallsname> | <SQL-Injektion>
<SQL-Injektion> := ‘); DROP TABLE Adressen;
Das ergänzt die Adressen um SQL-Befehle, die bei mangelnder Prüfung der Eingaben zum Löschen von Daten führen können. Spätestens hier zeigt sich, dass man Fuzzing-Experimente nur in einer kontrollierten Umgebung auf dem eigenen Rechner ausführen sollte. Wer einen Dritten mit Fuzzing-Eingaben traktiert, der riskiert, sich wegen Datenveränderung (§303a StGB) oder Computersabotage (§303b StGB) strafbar zu machen.
Grammatikbasiertes Testen ist in der Praxis weitverbreitet, dient aber vornehmlich zum Testen eigener Programme – nicht zuletzt auch, da sich die Grammatik stets an konkrete Testziele anpassen lässt. Mozilla und Google etwa haben mit dem grammatikbasierten Langfuzz [1], das Javascript-Programme erzeugt, Tausende Probleme in Javascript-Interpretern gefunden und behoben. Csmith [2], ein Programm zum Erzeugen gültiger C-Programme, kommt in Compilertests umfassend zum Einsatz. Der modellbasierte Formatfuzzer [3] ist auf Binäreingaben wie etwa Bilddateien oder Archive spezialisiert.
Sollten Sie nach dem Lesen dieses Texts in einen Browser wechseln, dann können Sie sich auf dessen Sicherheit verlassen – nicht zuletzt dank des modellbasierten Fuzzing.
Mit Mutation zum Erfolg
Bei aller Leistungsfähigkeit haben modellbasierte Fuzzer doch einen entscheidenden Nachteil: Man muss für sie erst einmal eine Grammatik schreiben. Für seltene oder anwendungsspezifische Eingabeformate bedeutet das einen nicht unerheblichen Aufwand, gerade wenn man das Format erst einmal verstehen muss. Gibt es aber Beispiel-Eingabedaten, schlägt die Stunde der jüngste Klasse von Testgeneratoren, den evolutionsbasierten Fuzz-Generatoren.
Evolutionsbasierte Fuzz-Generatoren haben ebenfalls das Ziel, möglichst gültige Eingaben zu erzeugen, um tief in das Programm vorzudringen. Sie erreichen dieses Ziel aber nicht, indem sie eine Eingabebeschreibung wie etwa eine Grammatik nutzen, sondern indem sie bestehende Eingaben systematisch verändern (mutieren). Als Beispiel soll die Adresse des Linux-Magazins dienen: »Putzbrunner Straße 71, 81739 München«. Eine Mutation kann etwa darin bestehen, zwei Zeichen zu vertauschen: »Putzbrunner Strßae 71, 81739 München«. Alternativ kann man ein Zeichen durch ein anderes ersetzen (»Putzbrunner Strafe 71, 81739 München«) oder ein zufälliges Zeichen löschen (»Putzbrunner Straße 71, 8173 München«).
Jede Mutation liefert somit eine neue Eingabe zum Testen. Die Variationsbreite liegt zwar nicht so hoch wie bei rein zufälligen Eingaben oder beim modellbasierten Testen, aber dafür ist die Wahrscheinlichkeit einer gültigen Eingabe immer noch hoch. In obigen Beispielen etwa führt nur das Löschen einer Ziffer aus der Postleitzahl zu einer ungültigen Adresse.
Der eigentliche Clou bei evolutionsbasierten Fuzzern ist aber, dass sie Mutationen nutzen, um eine Menge erfolgreicher Eingaben systematisch weiterzuentwickeln, Das Ziel besteht darin, möglichst viel Programmverhalten abzudecken. Zu diesem Zweck unterhalten Fuzzer eine Menge (Population genannt) besonders erfolgversprechender Eingaben. Sie beginnen dazu mit einer Menge bekannter und gültiger Eingaben, die sie mutieren, was die Population vergrößert.
Der Fuzzer misst nun, welche Stellen im Programm die jeweiligen Eingaben erreichen (abdecken). Eingaben, die bisher nicht abgedeckte Stellen erreichen, gelten als besonders erfolgversprechend, werden beibehalten und dienen als Grundlage weiterer Mutationen. Dagegen fallen Eingaben, die keine neuen Stellen erreichen, aus der Population (Auslese). Auf diese Weise entwickelt sich die Population immer weiter im Hinblick auf das Ziel, möglichst viele Programmstellen zu erreichen und somit möglichst viele Programmverhalten abzudecken.
In unseren obigen Beispielmutationen würde etwa die letzte Mutation (»8173«) als erfolgversprechend klassifiziert, da sie mit der vierstelligen Postleitzahl als erste den Code zur Fehlerbehandlung und somit neues Programmverhalten erreicht. Die Mutation von »Straße« zu »Strafe« hingegen dürfte keinen neuen Code abdecken; sie würde langfristig aus der Population entfernt.
Und wie sieht es mit der Chance aus, die spezielle Postleitzahl 00000 zu erzeugen? Ist der Code so strukturiert, dass er Stück für Stück der Postleitzahl abfragt wie in Listing 2 dann wird tatsächlich mit jeder erfüllten Teilbedingung ein weiteres Stück Code ausgeführt, das die jeweils nächste Ziffer prüft. Nach zahlreichen Durchläufen mutiert 81739 erst zu 01739, dann zu 00739, dann zu 00039 und schließlich zu 00000, sodass wieder weiterer Code entdeckt wird. Tatsächlich vermögen evolutionsbasierte Fuzzer bei Vergleichen von Zeichenketten und Zahlen auch Teilerfolge zu erkennen, sodass sie sich über immer weitere Mutationen langsam an ein Ziel heranarbeiten.
Listing 2
Schrittweiser PLZ-Test
if (len(plz) == 5 and plz[0] == '0'
and plz[1] == '0' and plz[2] == '0'
and plz[3] == '0' and plz[4] == '0'):
tue_etwas_besonderes()
Evolutionsbasierte Fuzzer ähneln der natürlichen Evolution – viele Fehlversuche, aber auf lange Sicht effektiv. Vor allem jedoch sind sie genügsam: Testeingaben liegen oft vor oder lassen sich aus konkreten Abläufen herauslesen; die Abdeckung eines Tests ist leicht zu messen. Zudem benötigen evolutionsbasierte Fuzzer kein weiteres Wissen über Eingabeformate. Ihr großer Nachteil liegt in ihrer Abhängigkeit von guten Starteingaben: Enthalten die ein bestimmtes Feature nicht, ist es unwahrscheinlich, dass das Feature jemals erzeugt wird.
Als Klassiker der evolutionsbasierten Fuzzer gilt American Fuzzy Lop (AFL [4]), ein hochgradig optimierter Fuzzer, der schon zahlreiche Fehler in existierenden Programmen aufspüren konnte. Der Großteil der sicherheitskritischen Linux-Programme wird mittlerweile rund um die Uhr von AFL und seinen Ablegern getestet, etwa in Googles OSS-Fuzz-Projekt.
Während AFL und seine Ableger vornehmlich in “feindlichen” Szenarien zum Einsatz kommen, in denen man keine Kooperation der Programmautoren erwartet, handelt es sich bei Sapienz [5] um einen evolutionsbasierten Fuzzer, den Facebook einsetzt, um die eigenen Programme und Anwendungen zu testen. Wer auf einem Linux-System die Kommandozeile benutzt oder auf seinem Handy die Facebook-App öffnet, profitiert von der Arbeit evolutionsbasierter Fuzzer.
Bedingungen erkennen
Die vierte Klasse von Fuzz-Generatoren zielt ebenfalls darauf ab, möglichst viele Stellen im Programmcode zu erreichen. Statt des Prinzips Versuch und Irrtum, das evolutionsbasierte Fuzzer nutzen, setzen sie auf systematisches Erkennen und Lösen von Pfadbedingungen. Darunter versteht man Bedingungen, unter denen die Ausführung einen bestimmten Pfad im Programm nimmt und somit eine bestimmte Codestelle erreicht.
In diesen Constraint-basierten Fuzzern kommen spezialisierte Constraint Solver zum Einsatz – Programme, die für eine gegebene Menge an Bedingungen automatisch eine Lösung suchen. Für eine Postleitzahl-Bedingung wie die oben angegebene produziert ein Constraint Solver innerhalb von Hunderstelsekunden die Lösung 00000.
Ihre wahre Stärke spielen Constraint Solver aber bei komplexen arithmetischen Berechnungen aus. Lautet die Bedingung etwa so wie in Listing 3, bestimmt ein Constraint Solver ebenfalls in kürzester Zeit passende Werte für »x« und »y«. Grammatikbasierte Fuzzer dagegen bleiben hier nach wie vor auf den Zufall angewiesen, und evolutionsbasierte Fuzzer müssen hoffen, dass ihre Startpopulation geeignete Werte für »x« und »y« enthält. Solche Stärken sind insbesondere dann interessant, wenn es gilt, tief liegende Bedingungen der Programmlogik zu erfüllen. Aber auch nicht triviale Eigenschaften von Eingabedateien wie etwa Prüfsummen können Constraint Solver schnell lösen.
Listing 3
Constraint-Bedingung
if x * x + y * y > 3
and x * x * x + y < 5:
tue_etwas_interessantes()
Constraint Solver sind stark, aber nicht allmächtig. Gilt es, aus einem verschlüsselten Text das Original wiederherzustellen, kann auch ein Constraint Solver nicht mehr tun, als sehr, sehr oft den Schlüssel zu raten. Zudem arbeiten Constraint Solver langsam. Während sie noch nach einer Lösung suchen, können grammatik- oder evolutionsbasierter Fuzzer Tausende von Eingaben testen und so – je nach Komplexität der Bedingungen – am Ende durch schlaues Raten doch schneller zum Erfolg kommen.
KLEE [6], ein sehr populärer Constraint-basierter Fuzzer, hat Hunderte von Programmfehlern in C-Programmen gefunden. Microsoft setzt einen eigenen Constraint-basierten Fuzzer namens SAGE [7] ein, der Grammatiken für Office-Dokumente nutzt, um systematisch in Bürosoftware nach Fehlern zu suchen. Er hat Microsoft und seinen Nutzern Hunderte Millionen Dollar an Schäden erspart. Und auch die NASA setzt auf Constraint-basierte Fuzzer, um wirklich jede Situation durchzutesten, in die ein Raumfahrzeug geraten könnte [8]. Auch hier gilt: Fuzzing ist effektiv und spart Geld.
Ausblick
Moderne Fuzzer setzen längst nicht mehr nur auf eine Technik, sondern greifen zu pragmatischen Kombinationen. Letzten Endes hat der Recht, der am schnellsten die schlimmsten Fehler findet. So ist es etwa sinnvoll, mit einfachen zufälligen Zeichenketten zunächst nach Fehlern in der Eingabeverarbeitung zu suchen, bevor eine Grammatik oder mutierte Testeingaben auf tieferliegende Fehler zielen.
Grammatiken, Evolution und Constraints lassen sich auf verschiedenste Weise kombinieren. Welche Kombination unter welchen Bedingungen am meisten Erfolg verspricht, ist Gegenstand hitziger Debatten unter Fuzzing-Forschern und Entwicklern. Den Anwender interessiert dabei weniger, welche Variante welchen Werkzeugs zum Einsatz kommt – am wichtigsten ist, überhaupt mit Fuzzing zu beginnen. Software, die noch nie einem Fuzzer ausgesetzt war, weist mit hoher Sicherheit Fehler auf, die sich durch zufällige Eingaben auslösen lassen.
Für C-Programme versprechen Fuzzer wie AFL oder KLEE schnelle Ergebnisse; eine Grammatik für einfache Eingaben ist im Handumdrehen erstellt. Doch für Entwickler wie für Angreifer gilt: Wer selbst kein Fuzzing nutzt, riskiert, dass andere es tun und die gefundenen Fehler schnell ausnutzen. Hat man einen Fuzzer jedoch erst einmal aufgesetzt, kann man sich entspannt zurücklehnen: Ab hier übernimmt der Fuzzer die Arbeit und testet unermüdlich mit immer neuen Eingaben, bis die rote Lampe aufleuchtet, die einen gefundenen Fehler anzeigt. Dann beginnt die Fehlersuche und -korrektur – aber wie man die automatisiert, ist eine andere Geschichte. (jcb/jlu)
Der Autor
Andreas Zeller ist leitender Forscher am CISPA Helmholtz-Zentrum für Informationssysteme und Professor für Softwaretechnik an der Universität des Saarlands. Für seine Arbeiten zu Programmanalyse und Fehlersuche wurde er mit zahlreichen Preisen geehrt. Seine Lehrbücher “The Fuzzing Book” und “The Debugging Book” vermitteln die Grundtechniken des automatischen Testens und der automatischen Fehlersuche mit direkt im Browser ausführbaren Codebeispielen.
Infos
- Langfuzz: https://github.com/mozilla/JSBugMon/blob/master/langfuzz.py
- Csmith: https://embed.cs.utah.edu/csmith/
- Formatfuzzer: https://github.com/uds-se/FormatFuzzer
- AFL: https://github.com/google/AFL
- Sapienz: https://engineering.fb.com/2018/05/02/developer-tools/sapienz-intelligent-automated-software-testing-at-scale/
- KLEE: https://klee.github.io
- SAGE: https://patricegodefroid.github.io/public_psfiles/ndss2008.pdf
- “Fuzzing NASA Core Flight System Software”: https://www.youtube.com/watch?v=D5yiIlMy2Lg





