
© Diego Vito Cervo / 123rf.com
Mit GPS lässt sich eine Position zentimetergenau bestimmen – aber nur im Freien. Dieser Artikel erläutert verschiedene Verfahren, die die Orientierung auch in Gebäuden möglich machen. Im ersten Teil kommen unter anderem Verfahren des überwachten Maschinenlernens zum Einsatz.
Das hier vorgestellte System zur Orientierung in einem Gebäude findet im Unterschied zur Satellitennavigation nicht direkt Ortskoordinaten, stattdessen berechnet es die Wahrscheinlichkeit, dass sich der Gesuchte in einem der vorgegebenen Räume aufhält. Die Werkzeuge dafür liefert die Programmiersprache Python. Im Vordergrund des Artikels steht die prinzipielle Herangehensweise, auf Details der verwendeten Bibliotheken geht er weniger ein.
Befragen der Daten
Zur Demonstration stützen wir uns auf einen Datensatz, den die Universität UCI in Irvine (Kalifornien, USA) frei im Internet bereitstellt [1]. Dieser Datensatz besteht aus acht Spalten: den Signalstärken von sieben WLAN-Hotspots, gemessen mit einem Handy, und dem Ort der Messung. Nach 500 Messungen an festen vier Orten stehen 2000 Einträge bereit.
Der Protagonist unseres Experiments ist Tom. Tom hat sich verlaufen. Zum Glück hat er sein Handy dabei, das ihm die Signalstärke von sieben Hotspots aus seiner Umgebung (Abbildung 1) anzeigt. Maja sucht ihn. Sie weiß, dass er nur an einem von vier Orten sein kann (Kreuze in Abbildung 2). Da Tom sich öfter verläuft, hat sie vorsorglich die vier Räume kartiert (Abbildung 2). Mithilfe künstlicher Intelligenz und überwachtem Lernen will Maja Tom finden.
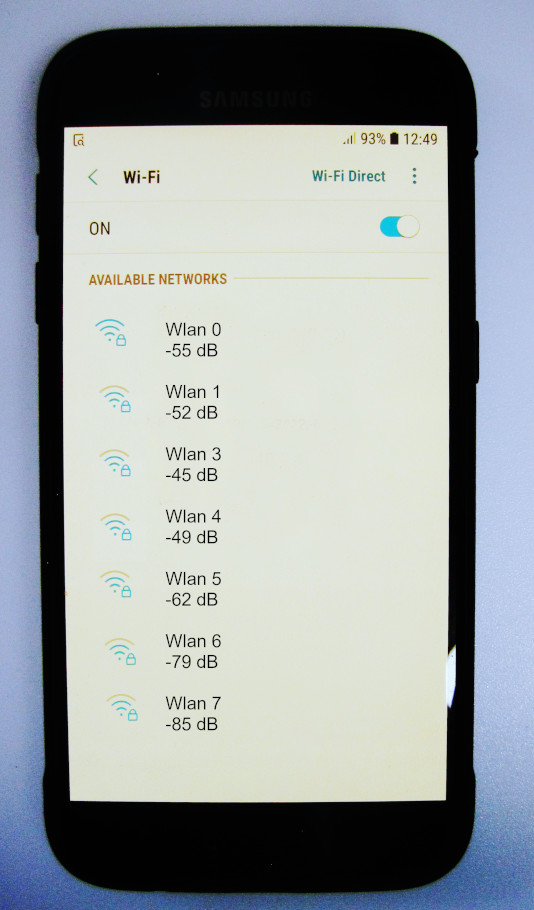
Abbildung 1: Toms Handy zeigt an, mit welcher Stärke er an seinem Standort die Signale der WLANs in den einzelnen Räumen empfängt.
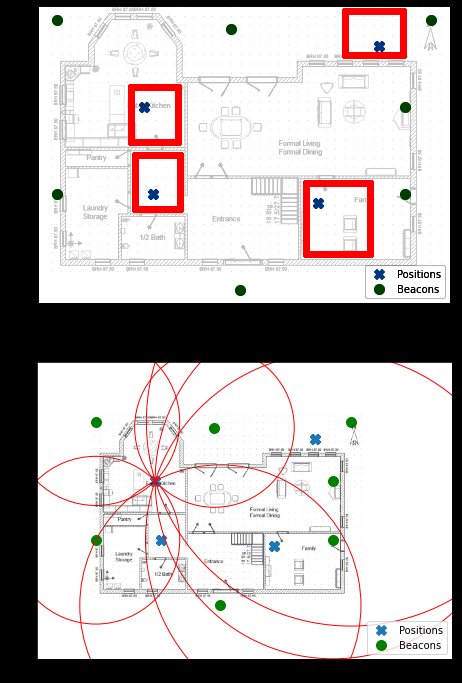
Abbildung 2: Mögliche Anordnung von Baken (Punkte) und Positionen (Kreuze).
Was ist, wenn Maja zwar weiß, dass Tom sich im Haus aufhält, aber nicht die Zahl der Räume kennt? Hier klärt nichtüberwachtes Lernen die Situation. Davon handelt ein zweiter Teil in der nächsten Ausgabe. Teilüberwachtes Lernen hilft Maja, Fehler zu finden, die ihr bei der Zuordnung der Räume unterliefen.
In unserem Beispiel sind zunächst alle Koordinaten unbekannt, sowohl die der möglichen Positionen als auch die der Sendebaken. Gemessen wird die Signaldämpfung. Im Freiraum könnte daraus auf die Entfernung geschlossen werden. In Innenräumen verfälscht jedes Hindernis die Abschätzung. Hier geht es nicht darum, die exakte Position in geografischer Länge und Breite zu finden. Lediglich das richtige Zimmer soll erkannt werden.
Würde trotzdem eine analytische Lösung helfen, wie es die satellitengestützte Positionsbestimmung vormacht? Zum Schluss werden wir das versuchen, aber um es vorwegzunehmen: Mit diesen Daten gelingt es nicht.
Explorative Datenanalyse
Den größten Teil ihrer Zeit verwendet die Datenexpertin Maja für die Bereinigung der Daten (Listing 1). Glücklicherweise ist der Demo-Datensatz vorprozessiert. Er ist ausgewogen, enthält keine ungültigen Werte und auch keine Ausreißer.
Listing 1
Vorbereiten der Daten
# read data
import numpy as np
import pandas as pd
fn = "https://archive.ics.uci.edu/ml/machine-learning-databases/00422/wifi_localization.txt"
colnames = [0, 1, 2, 3, 4, 5, 6, 'Target']
df = pd.read_csv(fn, header = None, names=colnames, comment = "#", sep = '\t')
rooms = {1:'Küche', 2: 'Diele', 3:'Wohnzimmer', 4:'Terrasse'}
df['Target'] = df['Target'].map(rooms)
print(df[:2])
df.describe()
Listing 1 importiert zunächst die Bibliothek Pandas, die das Datenhandling unterstützt. Die Funktion »read_csv()« liest lokale Dateien oder wie hier, Ressourcen aus dem Internet. »colnames« fügt die Spaltennamen hinzu, Nr. 0 bis 6 als Bezeichner für die Beacons, »target« für die Räume. Mit »sep = ‘\t’« setzen wir das Trennzeichen für die Eingabewerte auf Tabulator.
Wer zum ersten Mal mit Pandas arbeitet, stolpert über die Indexspalte. Sie wird automatisch generiert und stammt nicht etwa aus den Daten. Deshalb fehlt ihr bei der Druckausgabe auch eine eigene Spaltenüberschrift (Abbildung 3). Die Funktion »describe()« generiert die Daten, die Abbildung 4 zeigt: Alle Spalten sind mit jeweils 2000 Werten vollständig besetzt. Die Signalstärken bewegen sich zwischen -10 dB und -98 dB. Die Zielgröße Target nimmt vier diskrete Werte an, die das Dictionary »rooms« durch Raumbezeichnungen Küche, Diele, Wohnzimmer und Terrasse ersetzt.
Abbildung 3: Die ersten vier Zeilen von Pandas Dataframe.
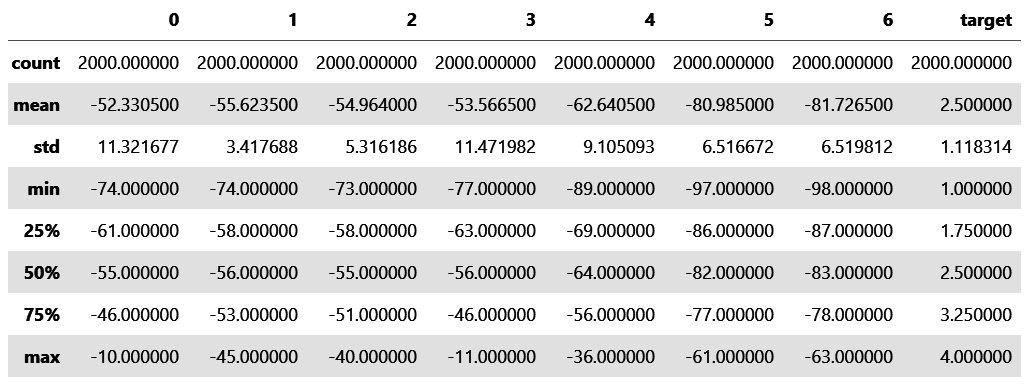
Abbildung 4: Die statistische Beschreibung der Daten.
Die Angaben der Quantile 25 bis 75 Prozent sagen zu wenig aus über die Verteilung der Daten. Gesucht ist eine grafische Darstellung. Listing 2 beschränkt den Datensatz mit der Abfrage ‘[‘target’] == Küche’ zunächst auf den ersten Raum. Der Befehl ‘drop()’ löscht anschließend die Target-Spalte, um sie aus der Auswertung herauszunehmen. Das Histogramm erscheint in zwölf Abstufungen. Auch bei einer Transparenz von 0.5 überdecken sich die Werte.
Listing 2
Signalstärkenverteilung plotten
dh = df[df['Target'] == 'Küche']
dh = dh.drop('Target' ,axis = 1)
dh.plot.hist(bins=12, alpha=0.5)
dh.plot.kde()
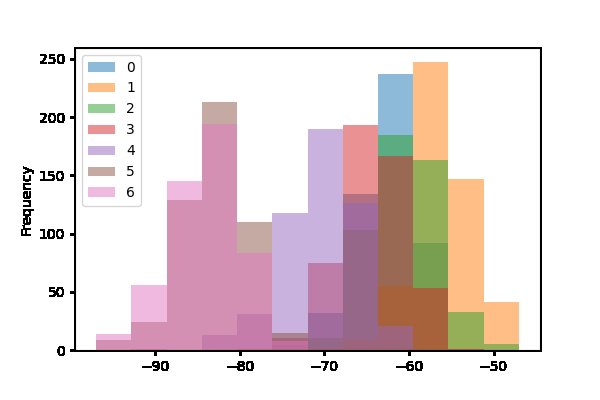
Abbildung 5: Streuung der Signalstärken der sieben WLAN-Hotspots im ersten Raum.
Die Darstellung wird klarer, wenn die Histogramme durch eine stetige Funktion angenähert werden, den Kerneldichteschätzer (Kernel Density Estimation, KDE). Der Parameter Bandbreite steuert die Glättung, eine Anpassung ist aber nur selten erforderlich. Das Ergebnis in Abbildung 6 ist leichter zu interpretieren als die Histogrammdarstellung.
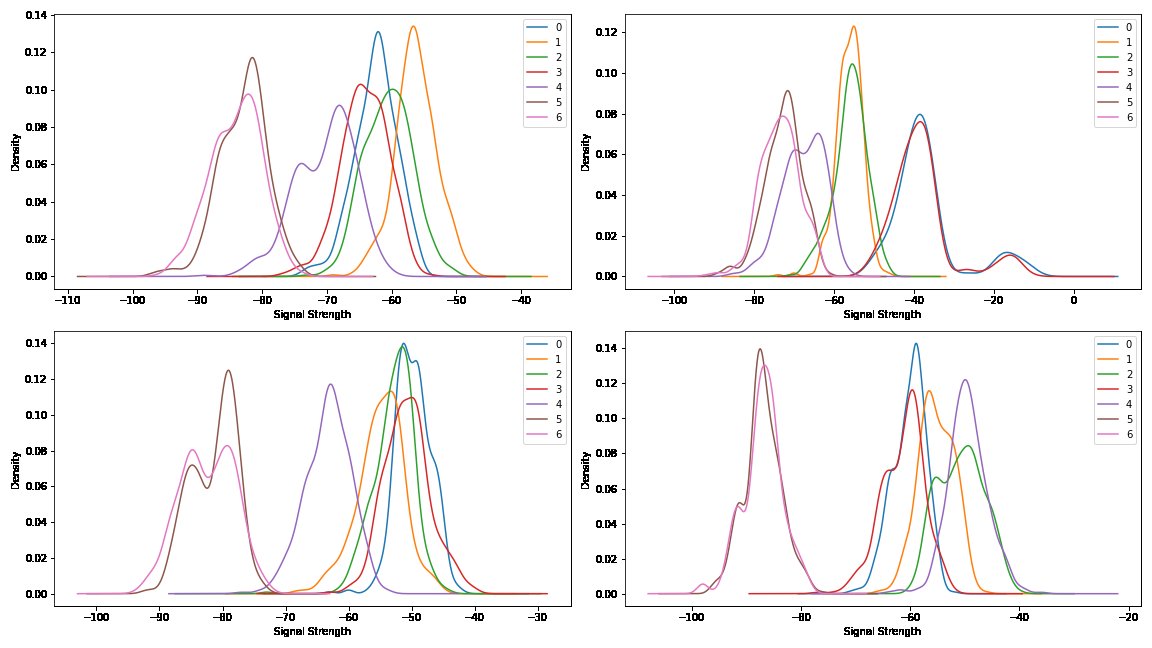
Abbildung 6: Ähnlich wie vorige Abbildung, aber Verteilung als Dichtefunktionen für alle vier Räume.
Jetzt wird auch deutlich, dass auf die Messungen womöglich nicht die größte Sorgfalt verwandt wurde. Manche Baken liefern teilweise identische Signale und deshalb keine neue Information über den Standort. Einige Kurven weichen von einer einfachen Verteilung ab. Möglicherweise wurden die Daten an mehr als vier verschiedenen Positionen aufgezeichnet. Die hohe Überdeckung ist auch einer der Gründe, warum ein analytischer Ansatz hier nicht funktioniert.
Überwachtes Trainieren
In jedem der vier Räume wurden jeweils 500 Mal die Signalstärke der WLAN-Hotspots vermessen. Eine Mittelung verdeckt zu viele Details, um die Räume eindeutig zu charakterisieren. Beispielsweise könnte eines der messenden Handys grundsätzlich schwächere Pegel aufzeichnen und es würde immer den Mittelwert verfehlen. Hier greifen die Methoden des maschinellen Lernens, die die Gesamtheit der Daten in einen Zusammenhang stellt.
Aus dem großen Angebot an Verfahren für das Klassifizieren beschränken wir uns auf ein Verfahren, es heißt Random Forest. Die Methode Support Vector Machine (SVM) liefert zwar manchmal bessere Werte, erwartet aber eine Anpassung der Rohdaten. Auch Decision-Tree-Klassifizierer erfordern Anpassungen zahlreicher Hyperparameter und bleiben hinter den Ergebnissen der Random-Forest-Methode zurück.
Ein Random Forest lässt viele Entscheidungsbäume geringer Tiefe gegeneinander antreten und optimiert interne Hyperparameter. Ein Entscheidungsbaum startet bei den Eigenschaften, die die höchste Trennschärfe haben. Um beispielsweise Kirschen, Pflaumen und Äpfel voneinander zu trennen, teilt die Frage nach der Größe das Obst weitgehend auf, auch wenn es große Kirschen und kleine Pflaumen gibt. Die nächste Abfrage nach der Rundheit des Steins verfeinert die Unterteilung. Mit zunehmender Tiefe verbessert sich die Vorhersage. Am Ende gibt es für jede Frucht genau eine Abfragenschachtelung. Das Problem: Der Entscheidungsbaum lernt auswendig. Dieses Overfitting ist ein generelles Problem beim Maschinenlernen.
Boosting-Algorithmen gehören zu den besten Klassifizierern. Ihre Erläuterung sprengt den Rahmen dieses Artikels. Neuronale Netze schneiden bei dieser Fragestellung nicht viel besser ab und sind aufgrund der unübersichtlich vielen Parameter schwer zu interpretieren.
Maschinenlernen vollbringt keine Wunder. Sind die Ausgangsdaten widersprüchlich, ist auch die Vorhersagewahrscheinlichkeit begrenzt, unabhängig von der Wahl des Maschinenlernverfahrens. Die Python-Bibliothek »scikit-learn« beziehungsweise »sklearn« kennt alle diese Verfahren. In vielen Fällen genügt der Austausch einer Codezeile, um die Daten nach einem anderen Verfahren zu klassifizieren. Um eine Überanpassung an einen Datensatz zu erkennen, werden die Daten geteilt. Der größere Teil trainiert den Algorithmus. Getestet wird ganz zum Schluss mit den Restdaten. Die Abweichung der Vorhersage bei den Testwerten ist ein Maß für die Güte des Schätzers.
Listing 3
Vorbereiten des Klassifiziereres
# split data into features and target # (change colunm number) X = df.iloc[:, 0:-1].to_numpy() y = df.iloc[:, -1].to_numpy() # split into training and test data from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y) # select model and fit # (change row number) from sklearn.ensemble import RandomForestClassifier classifier = RandomForestClassifier() classifier.fit(X_train,y_train)
Nach dem Einlesen der Daten gemäß Listing 1 teilt Listing 3 den Dataframe »df« in Eigenschaften X und Zielgröße y auf. Die Umwandlung in ein Numpy-Array ist optional und geschieht andernfalls später durch den Klassifizierer. Die Funktion »train_test_split()« teilt die Daten in Trainings- und Testdaten. An sich ist es eine einfache Aufgabe. Aber die Routine achtet darauf, dass die Zielgrößen gleichmäßig in beiden Datensätzen auftauchen. Sonst lernt das System Diele und Küche, wird aber erst beim Testen mit dem Wohnzimmer konfrontiert.
Der Befehl »RandomForestClassifier()« wählt den Klassifizierer RandomForest. In der Zeile »classifier.fit(X_train,y_train)« lernt der Algorithmus schweigend seine internen Parameter. Die Rechenzeit steigt mit der Zahl der Daten und Parameter. Gerade bei neuronalen Netzen ist es schneller, nur einmal zu trainieren und anschließend die inneren Parameter zu speichern. Die Gesichtserkennung bei OpenCV oder auch in Kameras funktioniert nach diesem Verfahren. Die früher gelernten Parameter werden in den Speicher geladen und präsentieren ein austrainiertes System.
Je nach Verfahren können die internen Parameter mehrere MByte umfassen. Kleine Datensätze sind aber schnell prozessiert, deshalb gehen wir auf die Auslagerung nicht weiter ein.
Leistungsbewertung
Wenn nach dem Aufruf des Fits in Listing 3 keine Fehlermeldung erscheint, war das Training erfolgreich. Das allein genügt aber nicht. Listing 4 bewertet, wie gut der Algorithmus die Daten klassifiziert. Im Objekt »classifier« stecken alle durch das Training angepassten Daten. Die Methode »classifier.predict()« berechnet Zielwerte zu Eingabesequenzen. Sie ist das Werkzeug, mit dem Maja weiter unten Tom finden wird. Um die Qualität der Methode zu bestimmen, vergleichen wir die Testwerte »y_test« mit »y_pred«, also den von »predict()« vorhergesagten Werten. Die Abweichungen sind ein Maß für die Qualität des Klassifizierers.
Listing 4
Leistungsbewertung
# predict and evaluate from sklearn.metrics import confusion_matrix y_pred = classifier.predict(X_test) labels = classifier.classes_ cm = confusion_matrix(y_test, y_pred, labels=labels) print(np.trace(cm)/y_test.shape[0]) pd.DataFrame(cm, index=labels, columns=labels)
Die Konfusionsmatrix (Abbildung 7) stellt die Werte gegenüber. Die Bezeichnung der Zielwerte und ihre Reihenfolge entnimmt sie aus dem Attribut »classes_«. Der Unterstrich am Ende des Klassenattributs folgt einer allgemeinen Konvention der Scikit-Learn Bibliothek, alle aus den Daten abgeleiteten Werten so zu markieren. In Abbildung 7 wird die Diele 114 Mal richtig verortet, aber achtmal als Wohnzimmer. Umgekehrt wird das Wohnzimmer zweimal als Diele angesehen. Wir greifen das Problem unten erneut auf.
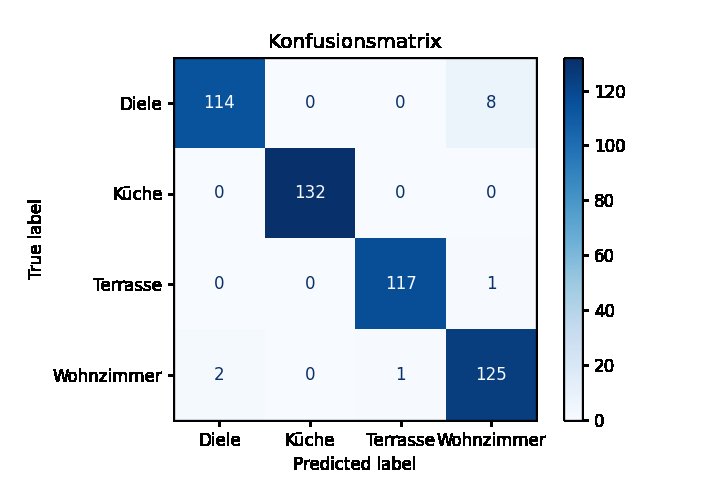
Abbildung 7: Die Konfusionsmatrix verdeutlicht die Qualität der Vorhersagen.
Häufig werden die Werte aus der Konfusionsmatrix zu einer Zahl aggregiert: Bei 500 Werten wurden zwölf falsch zugeordnet, entsprechend einer Genauigkeit von ‘1-12/500 = 0.976’. Wären es 13 gewesen, käme man auf 0.974? Kleine Zahlen sind mit einem großen Fehler behaftet. Die Angabe der dritten Nachkommastelle mag im konkreten Fall rechnerisch richtig sein, statistisch ist sie falsch. Bestenfalls könnte man den Fehler auf 0.97 +- 0.02 eingrenzen.
Listing 5
Aufenthaltsort von Tom
pTom = [-55, -52, -45, -49, -62, -79, -85]
print('Hier ist Tom: ', classifier.predict([pTom]))
print('Fehler: ', classifier.predict_proba([pTom]))
# output:
# Hier ist Tom: ['Wohnzimmer']
# Fehler: array([[0. , 0.05, 0.18, 0.77]])
Jetzt ist Maja fast am Ziel. Abbildung 1 nennt ihr die Feldstärken der sieben WLAN-Netze aus Toms Umgebung. Nach dem Training leitet der Decision-Tree-Classifier daraus die Position ab: Tom ist im Wohnzimmer (Listing 6).
Die Funktion »predict()« findet nicht nur das Zimmer heraus: »predict_proba()« verrät darüber hinaus, wie sicher sich der Algorithmus mit seiner Entscheidung ist, hier zu 77 Prozent. In der Voreinstellung des Klassifizierers RandomForestClassifier treten 100 Entscheidungsbäume gegeneinander an. 77 entscheiden sich für Wohnzimmer, 18 für Terrasse. Würde man mit »n_estimators=1000« die Zahl auf 1000 erhöhen, erhielte man die Werte von 789/1000 und 163/1000.
Bewertung der Eigenschaften
Nicht ohne Grund stützen sich viele Ensemble-Learning-Verfahren auf Entscheidungsbäume. Sie sind robust gegen Ausreißer. Sie verarbeiten kategoriale Daten, die in keinem metrischen Zusammenhang stehen müssen. Eine Skalierung der Daten erübrigt sich. Und nebenbei priorisieren sie die Eigenschaften. Listing 6 findet für das zweite Attribut, also WLAN-1, eine relative Bedeutung von 9.0 Prozent, für WLAN-6 7.7 Prozent. Die Abfrage »feature_importances_<0.1« ordnet diese beiden Indizes der Variablen ‘csel’ zu, die anschließend die Ausgangsdaten um genau diese beiden Spalten reduziert. Wiederholt man die Rechnungen oben mit den angepassten Daten, kommt man zu einem ähnlichen Ergebnis: Tom ist im Wohnzimmer mit einer Wahrscheinlichkeit von 89 Prozent.
Redundante Daten haben keinen Einfluss auf die Genauigkeit des Trainings von Maschinenlernverfahren. Denn dies zu erkennen ist Teil des Trainings. Anders sieht es aus, wenn sie das Lernen allein durch ihre Menge ausbremsen oder Attribute widersprüchliche Daten beisteuern. Später werden wir weitere Verfahren kennenlernen, die Attribute nicht einfach löschen, sondern versuchen sie zusammenzufassen.
Listing 6
Priorisierung der Eigenschaften.
fi = classifier.feature_importances_
print('Feature importance: ', fi)
csel = np.where(fi<0.09)
df.drop(df.columns[csel], axis=1, inplace=True )
df
# output:
# Feature importance:
# array([0.25384511, 0.00911624, 0.09055321,
# 0.21282642, 0.24906961, 0.1073945, 0.07719491])
Analytische Lösung?
Satellitengestützte Systeme wie GPS oder Galileo bestimmen die Position über Multilateration, wobei sie die Entfernung linear aus der Signallaufzeit ableiten.
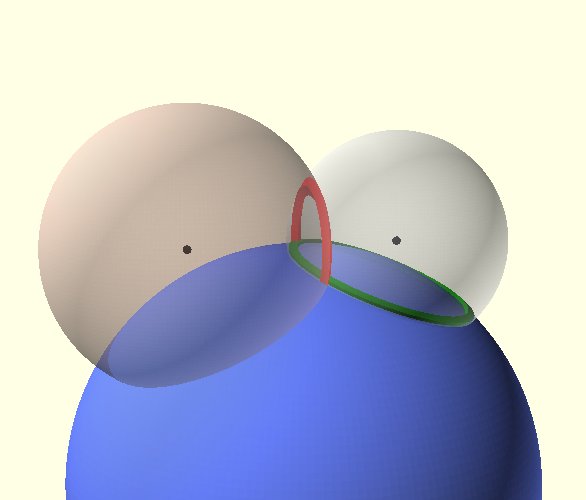
Abbildung 8: So funktioniert Multilateration im Prinzip.
Kennt ein Beobachter die Position eines Satelliten (schwarzer Punkt in Abbildung 8) und seinen Abstand (rechte graue Kugelkalotte), kennt er in etwa seinen Ort. Der Schnitt der Kugelkalotte schränkt seinen Standort auf den grünen Kreis ein, wenn er sich auf der Oberfläche der blauen Kugel befindet.
Ein zweiter Satellit reduziert die möglichen Positionen auf die Schnittpunkte zwischen grünem und rotem Kreis. Kommt noch ein dritter Satellit hinzu, ist der Beobachter nicht mehr auf die Oberfläche beschränkt. Er misst seine Höhe als Schnitt mit der – nicht eingezeichneten – Kalotte eines dritten Satelliten. Der vierte Satellit ist nötig, um die Signallaufzeiten zu synchronisieren. Der Empfang der Signale weiterer Satelliten verbessert die Positionsgenauigkeit. Moderne GNSS-Empfänger verrechnen 30 Kanäle und mehr.
Im unserem Fall messen wir keine Laufzeiten, sondern die Signalstärke. Sie nimmt mit dem Quadrat des Abstands ab, siehe Listing 7. Unbekannt ist die Sendeleistung, aber gravierender ist die Dämpfung. Jedes Hindernis schwächt das Signal und täuscht eine – ortsabhängige – variierende Entfernung vor. Die Umrechnung berücksichtigt, dass statt einer quadratischen Dämpfung eine Zahl größer als 2 angenommen wird, beispielsweise 4. Wegen dieser Unsicherheiten sind folgende Überlegungen theoretischer Natur.
Unser Beispiel stützt sich auf die Signalstärken von sieben Sendebaken. Anders als bei GPS-Satelliten sind ihre Positionen unbekannt. Dafür liegen ihre Signalstärken an vier unterschiedlichen Orten vor, wobei diese Koordinaten ebenfalls unbekannt sind. Bei den Überlegungen bleibt die Höhe außen vor. Dann ist jeder Punkt durch seine x- und y-Koordinate bestimmt. Die Berechnung der euklidischen Entfernung zu einer Bake erfolgt gemäß Listing 7.
Listing 7
Umrechnung in Entfernungen
def dbm2DistanceConverter(rssi, db0 = -20, N = 4):
'''
RSSI to distance converter
Input: mesured power RSSI in dBm; db0 power in 1m distance; N attenuation exponent
Output: distance in meter
formula: Distance = 10 ** ((db0 - RSSI)/(10 * N))
'''
# free space path loss: N=2
# reduced path loss: N>2
return 10 ** ((db0 - rssi )/(10 * N))
def eucV(p,b):
"""Euclidean distance between two points squared"""
return (p[0]-b[0])**2 + (p[1]-b[1])**2
Wir haben vier unbekannte Positionen für den Standort und sieben für die Baken. Darüber hinaus versuchen wir auch, die Signalstärken der sieben Baken abzuschätzen, insgesamt 29 Unbekannte. Gleichzeitig kennen wir die Signalstärken und – bei dieser abstrakten Betrachtung – die Entfernungen zu den sieben Baken, also 28 Gleichungen. Um das System eindeutig zu lösen, brauchen wir für jede Unbekannte mindestens eine Gleichung. Noch besser wäre ein überbestimmtes Gleichungssystem, um durch einen Fit die Fehler auszugleichen
Einen Standort legen wir fest, indem wir ihn in den Ursprung legen. Weiterhin nehmen wir an, dass eine Bake in y-Richtung liegt und die x-Koordinate entsprechend den Wert Null annimmt. Schließlich legen wir die Signalstärke des Senders 0 so fest, dass die Entfernungen zwischen den Positionen in der Größenordnung von Metern liegen.
Dann verbleiben 25 Unbekannte und 27 Gleichungen. Wir werden etwas ausrechnen. Das Ergebnis ist aber wegen der wenigen Informationen und des großen Fehlers bei der Entfernungsschätzung nicht belastbar. Zum Vergleich: GPS benötigt Signale von nur vier Satelliten, bei einer linearen Abhängigkeit der Entfernung von der Zeit und nahezu ungestörter Sicht zu den Satelliten.
Beispiele für die Lösung der nichtlinearen Optimierung zeigt Abbildung 9. Es verortet alle Räume und Baken. Um die Übersicht zu behalten, sind die in Entfernung umgerechneten Signalstärken als Kreise nur für das *Wohnzimmer* eingezeichnet. Die anderen 21 Entfernungskreise für die verbleibenden drei Räume fehlen.
Die Sendeleistung des Hotspots 0 ist fixiert, hier entsprechend einem Radius von 5 Metern. Wären die Werte belastbar, hätte man eine Lösung erwartet wie oben in Abbildung 2. Alle Radien schneiden sich in einem Punkt. Hier erkennt man nur mit gutem Willen, wo das Wohnzimmer optimal liegen sollte.
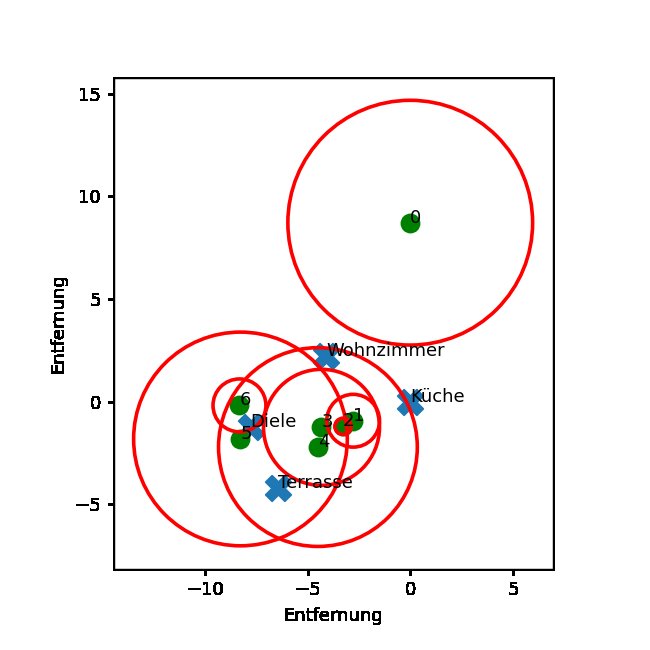
Abbildung 9: Beispiel einer analytischen Lösung.
So weit die Versuche, Toms Aufenthaltsort aus den WLAN-Daten zu bestimmen. In einer zweiten Folge in der nächsten Ausgabe gehen wir das hier vorgestellte Problem mit Verfahren des unüberwachten Lernens an.
Infos





