
© Maxim-Zarya, 123RF
Wenn Unterfunktionen massenweise Goroutinen zur Erledigung von Teilaufgaben erzeugen, möchte das Hauptprogramm die Fäden in der Hand behalten. Dafür nutzt Mike Schilli gern ein sogenanntes Context-Konstrukt.
Gos Goroutinen sind so billig, dass Programmierer sie auch gern im Dutzend abfeuern. Aber wer räumt das Durcheinander am Ende wieder auf? Im Grunde bieten sich Go-Channels zur Kommunikation an, und da ein Hauptprogramm eventuell die Kontrolle über viele gleichzeitig laufende Goroutinen behalten muss, aber eine Nachricht in einem Channel immer nur bei einem Empfänger ankommt, verlassen sich die Kommunikationspartner in diesem Szenario auf einen Sonderfall.
Versuchen nämlich ein oder mehrere Empfänger in Go, aus einem Channel zu lesen, blockieren aber, weil dort nichts vorliegt, dann kann der Sender auf einen Schlag alle Empfänger benachrichtigen, indem er den Channel schließt. Das weckt alle Empfänger auf, ihre blockierenden Lesefunktionen kehren mit einem Fehlerwert zurück.
Genau dieses Verfahren nutzt das Hauptprogramm, um noch laufende Unterprogramme zu stoppen: Es öffnet einen Channel und übergibt ihn an jedes aufgerufene Unterprogramm, das dann seinerseits eine Leseklette daran hängt. Schließt das Hauptprogramm später den Kanal, lösen sich die Kletten, und die Unterfunktionen tut das Vereinbarte – im Regelfall gibt es alle Ressourcen frei und beendet sich.
Reißleine bei drei
Listing 1 zeigt als illustratives Beispiel ein Hauptprogramm, das drei Mal hintereinander die Funktion »work()« aufruft. Die kehrt zwar praktisch sofort wieder zurück, feuert aber jeweils intern eine Goroutine ab, die im Sekundentakt bis zehn zählt und den aktuellen Zählerwert jeweils auf der Standardausgabe druckt. Jede dieser Goroutinen liefe nun zehn Sekunden lang weiter, auch nach Abschluss der sie aufrufenden Funktion, würde das Hauptprogramm nicht in Zeile 15 nach drei Sekunden mit »close()« die Reißleine ziehen.
Listing 1
grtest.go
package main
import (
"fmt"
"time"
)
func main() {
done := make(chan interface{})
work(done)
work(done)
work(done)
time.Sleep(3 * time.Second)
close(done)
time.Sleep(3 * time.Second)
}
func work(done chan interface{}) {
go func() {
for i := 0; i < 10; i++ {
fmt.Printf("%d\n", i)
select {
case <-done:
fmt.Printf("Ok. I quit.\n")
return
case <-time.After(time.Second):
}
}
}()
}
Den zur Synchronisation genutzten Channel »done« erzeugt Zeile 9. Den darin transportierten Datentyp legt »interface{}« als generisch an, da das Programm später gar keine Daten in den Channel schickt oder aus ihm ausliest, sondern nur die propagierte »close«-Anweisung auswertet.
Wie genau bekommen nun zu diesem Zeitpunkt die Arbeiter das Ertönen der Werkssirene mit? Sie sind ja noch damit beschäftigt, ihren Job zu machen und Ergebnisse zusammenzutragen oder einfach nur geschäftig Zeit verstreichen zu lassen, wie im vorliegenden Fall.
Dieses “busy waiting” implementiert das Select-Konstrukt ab Zeile 24. Mit zwei verschiedenen Case-Anweisungen wartet es gleichzeitig auf eines von zwei möglichen Ereignissen: Entweder versucht es mit »<-done«, Daten aus dem »done«-Channel zu lesen, respektive einen Fehler zu kassieren, falls »main« den Channel schließt. Oder aber der in Zeile 28 mit »time.After()« gestartete Timer läuft nach einer Sekunde ab und beschert dem Select-Konstrukt einen Anlass, den entsprechenden Case-Fall anzuspringen.
In den ersten drei Sekunden des Beispielprogramms läuft jedes Mal nur der Timer ab, aber nach dem dritten Mal schnackelt es, denn das Hauptprogramm hat den Channel »done« geschlossen, und das löst im ersten »case« in Zeile 25 einen Fehler aus, worauf der Arbeiter die Meldung Ok. I quit. ausgibt und mit »return« die Goroutine verlässt. Abbildung 1 zeigt den Ablauf.
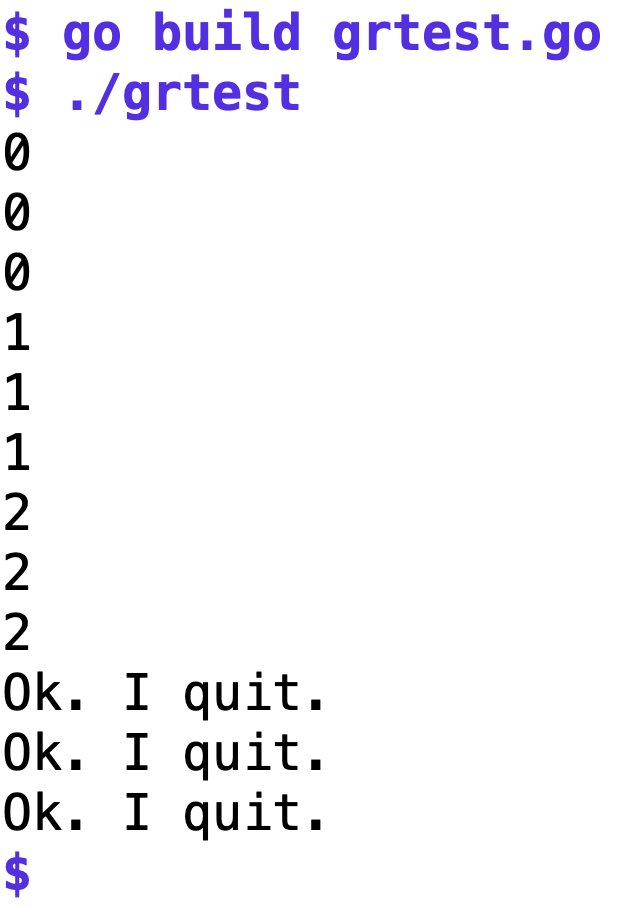
Abbildung 1: Im Testprogramm aus Listing 1 ertönt für alle drei Arbeiter nach drei Durchgängen die Werkssirene.
Jetzt mal in echt
Statt bis zehn zu zählen und zwischen den einzelnen Schritten immer eine Sekunde zu warten, würde eine »work()«-Funktion in der realen Welt zum Beispiel zeitverschlingende Aufgaben erledigen, wie eine Webseite übers Netzwerk einzuholen oder mit einer »tailf«-ähnlichen Technik Zuwächse in einer oder mehreren lokal überwachten Dateien festzustellen. Doch auch in diesen Situationen muss ein Server-Programm unter Umständen die Notbremse ziehen – sei es, dass der anfragende User die Geduld verloren hat oder die Datenaufbereitung im Backend dem Hauptprogramm einfach zu lange dauert und es sich anderen Requests zuwenden möchte.
Am Ende eines eigenständigen »main«-Programms wie in Listing 1 räumt zwar das Betriebssystem noch laufende Goroutinen ab und gibt die zugeordneten Ressourcen wie Speicher oder File-Handles automatisch frei. Ein Server-Programm darf sich jedoch nicht auf diesen Luxus verlassen, denn ein – aus welchen Gründen auch immer – abgebrochener Request beendet das Programm nicht. Es muss unter Umständen noch Wochen weiterlaufen, ohne dass herumlungernde Funktionsleichen den verbrauchten Speicher mehr und mehr zumüllen, bis der Out-of-Memory-Killer einschreitet und den Gnadenschuss abfeuert.
Grenzbereiche
Funktionen, die sich untereinander über Channels Daten zuschicken, müssen übrigens zwei Grenzfälle vermeiden. Senden sie eine Nachricht an einen Kanal, der bereits wieder geschlossen wurde, geht das Go-Programm in den Panikmodus und bricht mit einem Fehler ab. Liest eine Funktion aus einem Channel, in den niemand mehr etwas senden kann, weil alle Verdächtigen den Geist aufgegeben haben, hängt der Programmfluss für immer fest. Im vorliegenden Fall ist das allerdings einerlei: Durch den verwendeten Channel fließen keine Daten, da das Programm nur die Tatsache ausnutzt, dass das Lesen aus einem geschlossenen Kanal einen Fehler erzeugt.
Einfacher mit Kontext
Um dem Programmierer solcher doch recht gängiger Funktionen die Arbeit zu erleichtern, bietet die Go-Standard-Bibliothek Objekte vom Typ »Context« [1]. Sie kommen in den Google-Rechenzentren bei Servern zum Einsatz, die für hereinkommende User-Anfragen oft viele Goroutinen aufrufen müssen, die das Ergebnis zusammentragen. Dauert das zu lange, muss die Hauptfunktion, die den Request bearbeitet, die Möglichkeit haben, alle noch laufenden Goroutinen zu kontaktieren, sie zum sofortigen Aufgeben ihrer angefangenen Arbeiten zu veranlassen, eventuell belegte Ressourcen freizugeben und den Programmfluss einzustellen.
Das Interface eines Contexts liefert deshalb mit »Done()« einen offenen Channel zurück, aus dem die Arbeiterbienen zu lesen versuchen. Allerdings kommt im Channel (wie schon im vorigen Beispiel) niemals eine Nachricht an. Vielmehr schließt das Hauptprogramm zum Abpfiff mittels der dem Context eigenen »cancel()«-Funktion intern den Channel mit »close()«, was den lesenden Bienchen plötzlich einen Fehlerwert beschert. Den fangen sie ab und verstehen dies als Signal, den Laden dichtzumachen.
Listing 2 holt in Zeile 4 mit »context« das gleichnamige Paket der Standardbibliothek herein. Die Funktion »context.WithCancel()« setzt auf einem mit »context.Background()« erzeugten Standard-Context auf und gibt zwei Dinge zurück: ein Context-Objekt in »ctx« und eine »cancel()«-Funktion, die der Programmierer später (im Beispiel in Zeile 17) aufruft, um das Signal zum Ende der Party und dem allgemeinen Aufbruch zu senden.
Arbeiterbienen extrahieren aus dem Context mit »ctx.Done()« den zu überwachenden Kanal und fügen eine »case«-Anweisung mit einer Leseoperation darauf in ihre Select-Schleifen ein, mit denen sie die Kommunikation mit Subsystemen arrangieren. Die Ausgabe des kompilierten Listings 2 sieht genauso aus wie in Abbildung 1 und zeigt exakt dasselbe Verhalten. Das ist kein Wunder, nutzt die Context-Implementierung doch die gleiche interne Infrastruktur.
Listing 2
context.go
package main
import (
"context"
"fmt"
"time"
)
func main() {
ctx, cancel := context.WithCancel(context.Background())
work(ctx)
work(ctx)
work(ctx)
time.Sleep(3 * time.Second)
cancel()
time.Sleep(3 * time.Second)
}
func work(ctx context.Context) {
go func() {
for i := 0; i < 10; i++ {
fmt.Printf("%d\n", i)
select {
case <-ctx.Done():
fmt.Printf("Ok. I quit.\n")
return
case <-time.After(time.Second):
}
}
}()
}
Im Gehirn von Google
In Googles Rechenzentren nutzen alle Arbeiterfunktionen als ersten Parameter eine Context-Variable, die einen eventuell notwendigen vorzeitigen Abbruch kontrolliert. Sie hilft aber auch dabei, Nutzdaten eingegangener Requests nach unten durchzureichen, wie etwa den Namen des authentifizierten Users oder Credentials für Subsysteme. So unterstützen sämtliche Subsysteme über alle API-Grenzen hinweg bestimmte Standardfunktionen wie Timeouts, Aufräumsignale wegen unlösbarer Probleme oder auch einfach bequemen Zugriff auf globale Key/Value-Werte.
Wer bremst, verliert
Listing 3 zeigt, wie eine solche Server-Funktion im Prinzip aussehen könnte. Sie holt vier URLs ein: die Startseiten von Google, Facebook und Amazon sowie die künstlich gebremste Website »deelay.me«. Zeile 23 zeigt, dass sie die AOL-Website mit einer Verzögerung von 5000 Millisekunden abruft, um dem Client auf diese Weise eine lahme Internet-Verbindung vorzugaukeln.
Listing 3
delay.go
package main
import (
"context"
"fmt"
"net/http"
"time"
)
type Resp struct {
rcode int
url string
}
func main() {
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
defer cancel()
urls := []string{
"https://www.google.com",
"https://www.facebook.com",
"https://www.amazon.com",
"https://deelay.me/5000/www.aol.com",
}
results := make(chan Resp)
for _, url := range urls {
chkurl(ctx, url, results)
}
for _ = range urls {
resp := <-results
fmt.Printf("Received: %d %s\n", resp.rcode, resp.url)
}
}
func chkurl(ctx context.Context, url string, results chan Resp) {
fmt.Printf("Fetching %s\n", url)
httpch := make(chan int)
go func() {
// async url fetch
go func() {
resp, err := http.Get(url)
if err != nil {
httpch <- 500
} else {
httpch <- resp.StatusCode
}
}()
select {
case result := <-httpch:
results <- Resp{
rcode: result, url: url}
case <-ctx.Done():
fmt.Printf("Timeout!!\n")
results <- Resp{
rcode: 501, url: url}
}
}()
}
Das Hauptprogramm »main« rangiert nun in der For-Schleife ab Zeile 28 durch diese URLs und übergibt jede der Funktion »chkurl()«, zusammen mit einer Context-Variablen und einem Kanal »results«. Letzterer liefert die Ergebnisse der Arbeiter in Form von »Resp«-Strukturen zurück ans Hauptprogramm. Dieser ab Zeile 10 definierte Datentyp speichert die eingeholte URL sowie den HTTP-Return-Code des Requests.
Dabei arbeitet »chkurl()« die Anfragen asynchron ab. Es startet ab Zeile 42 eine Goroutine zum zeitaufwendigen Einholen übers Netz und kehrt deswegen flugs wieder zum Hauptprogramm zurück. Ergebnisse blubbern später über den »results«-Channel hoch, wo die For-Schleife ab Zeile 32 die Ergebnisse einsammelt und die URLs samt ihrer numerischen Ergebniscodes ausgibt.
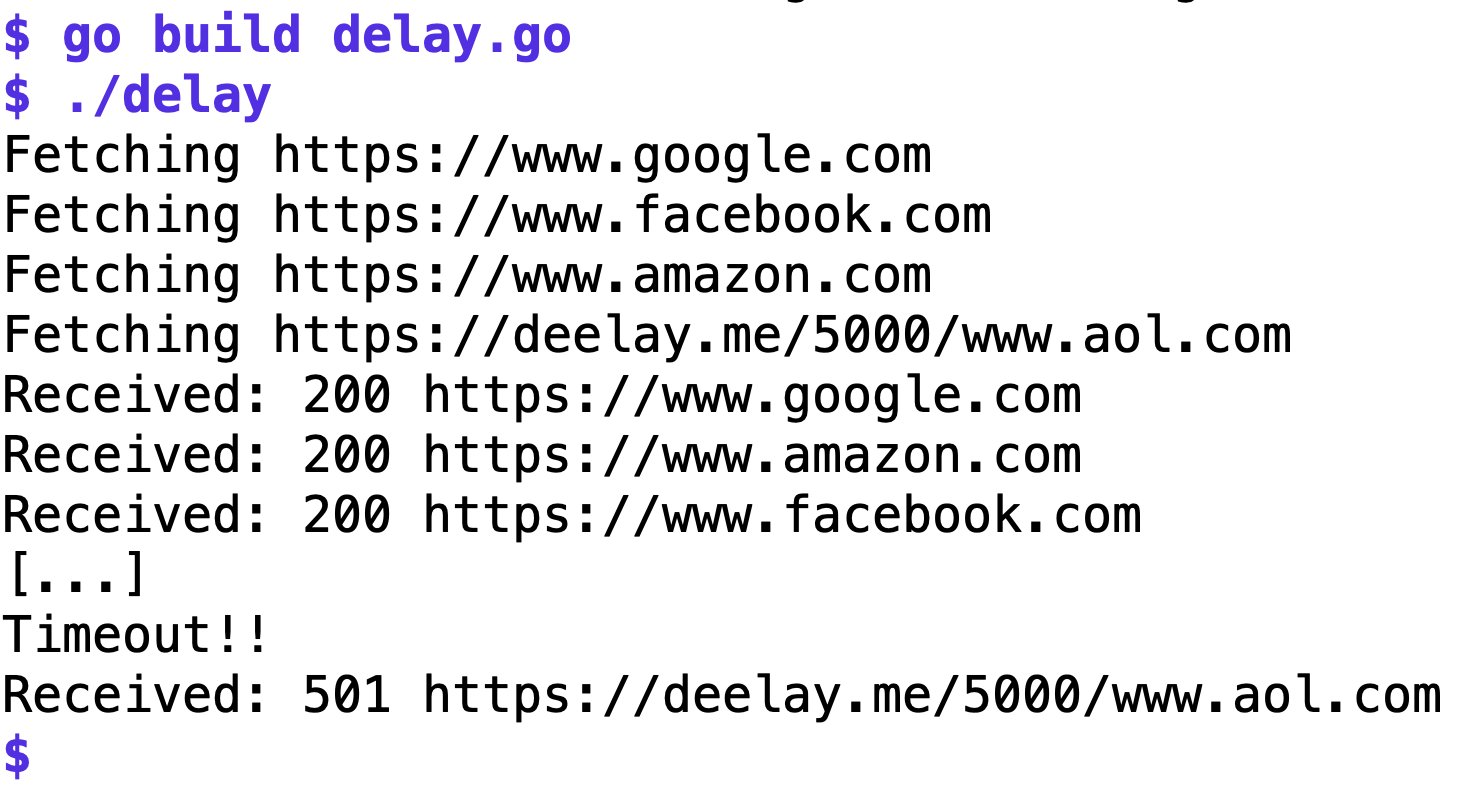
Abbildung 2: Die Ergebnisse der drei ersten Webseiten kommen schnell, das vierte jedoch zu langsam. Der Context löst deshalb den Timeout aus.
Trödeln wird bestraft
Damit der Worker »chkurl()« nicht zu lange herumtrödelt, setzt Zeile 16 einen Context mit Timeout, den sie in der Variablen »ctx« an die Arbeitsbiene weiterreicht. Die holt in einer inneren Goroutine (ab Zeile 44) innerhalb einer äußeren Goroutine mit dem Standardpaket »net/http« die Webseite aus dem Netz und schiebt den vom Webserver gelieferten Statuscode in den lokalen Channel »httpch«.
Damit hängt die innere Goroutine fest, bis jemand am anderen Ende des Channels »httpch« zu lesen anfängt. Das erfolgt auch im nachfolgenden Select-Konstrukt ab Zeile 53, das bei einem von zwei Ereignissen anspringt: Entweder kommt aus dem Channel »httpch« eine Antwort des Web-Requests, oder aber das Hauptprogramm hat mittlerweile die Geduld verloren und »ctx.Done()« kommt mit einem Fehler zurück. Im letzteren Fall gibt die Funktion Timeout!! aus und setzt den HTTP-Code auf 501. Klappt dagegen alles, schiebt Zeile 56 den Code und die zugehörige URL in den Ergebnis-Channel »results«.
Abbildung 2 zeigt den Ablauf des kompilierten Binaries. Die ersten drei Anfragen kommen relativ schnell zurück. Nach einer Pause schießt das Hauptprogramm die geschlagene fünf Sekunden trödelnde Unterfunktion ab, und der Statuscode kommt in der Tat, wie in Zeile 60 vorgegeben, als 501 zum Vorschein.
Die Kombination aus zwei verschachtelten Goroutinen in »chkurl()« ist übrigens erforderlich, weil das Senden von Daten in einen Channel und die Extraktion am anderen Ende synchronisiert erfolgen müssen. Sendet ein Programm einfach erst in den Channel, um anschließend daraus zu lesen, funktioniert das nicht: Der Sendeauftrag hängt ewig, wenn noch kein Empfänger lauscht. Damit das Ganze in Listing 3 denn auch flutscht, schickt der Sender seine Werte in einer asynchron laufenden Goroutine in den Channel. Der Empfänger kann sich hinterher in aller Ruhe andocken, und sobald er das tut, kommen die Daten durch den Kanal angewanzt.
Präzision statt Sekundenschlaf
Listing 3 verlässt sich übrigens beim Einsammeln der von den Arbeiterbienen erzeugten Daten nicht wie die vorherigen Programme auf unzuverlässige Sleep-Kommandos zur Synchronisation. Trudeln die Daten ungewöhnlich langsam ein, was im Internet ohne Weiteres möglich ist, kann es passieren, dass das Programm sich schon beendet, bevor die letzte Goroutine ihr Ergebnis über den Kanal hochgeschickt hat.
Listing 3 nutzt deshalb in den Zeilen 28 und 32 zwei For-Schleifen, die jeweils bis drei zählen: Einmal, um drei Mal »chkurl()« aufzurufen, und später, um drei Mal Ergebnisse über den Rückgabekanal einzusammeln. Die Reihenfolge von Anfragen und Ergebnissen gerät so zwar eventuell durcheinander, aber der Programmlauf garantiert, dass alle Ergebnisse komplett vorliegen und nicht etwa eines außen vor bleibt.
Nach diesem Muster stellen Go-Programme Code bereit, dessen Bestandteile theoretisch gleichzeitig laufen könnten. Richtig parallel läuft der Code aber nur, falls die Plattform das unterstützt, etwa durch einen Prozessor mit mehreren Cores. Der Unterschied zwischen Concurrency und Parallelism ist also durchaus relevant, wie Go-Guru Rob Pike in einem sehenswerten Video [2] eindrucksvoll erklärt.
Infos
- Go Context: https://blog.golang.org/context
- “Concurrency is not parallelism”: https://blog.golang.org/waza-talk





