
© Golubenko, Svetlana, 123RF
Wollte man dem Quicksort-Algorithmus einen Geschmack zuordnen, wäre es süß-sauer. Süß, da er eine sehr elegante Art zu sortieren darstellt; sauer, weil typische Implementierungen mehr Fragen offenlassen als beantworten.
Um es kurz zu machen: Es hat nach meinen ersten Begegnungen mit Quicksort während des Mathematikstudiums einige Jahre gedauert, bis ich lernte, den schnellen Sortieralgorithmus wertzuschätzen. Bevor dieser Artikel meine Reise kompakt Revue passieren lässt, ist ein wenig Grundwissen zu Quicksort notwendig.
Quicksort-ABC
Der schnelle Sortieralgorithmus Quicksort [1] geht auf Tony Hoare [2] zurück, der ihn bereits in den 1960er-Jahren entwickelte. Es handelt sich um einen sogenannten Teile-und-Herrsche-Algorithmus. Er wählt in jeder Iteration ein Pivot-Element aus dem Array und portioniert das Array aufgrund dieses Elements: Alle Elemente, die kleiner sind als das Pivot-Element, werden vor diesem in einem Teil-Array eingruppiert; alle größeren Elemente landen in einem Teil-Array danach. Dieser Prozess der Partitionierung erfasst dann sukzessive auch die Teil-Arrays. Die Länge der Teil-Arrays erreicht in endlich vielen Schritten eins. Damit sind dann die Teil-Arrays – und somit automatisch auch das ganze Array – sortiert.
Zu kompliziert? Abbildung 1 bringt den Algorithmus auf den Punkt. Kästchen, die nur eine rote Zahl enthalten, stehen bereits an der richtigen Position. In der ersten Zeile fungiert die 6 als Pivot-Element. Nun werden alle Elemente relativ zur 6 sortiert. In der zweiten Zeile dienen die 5 und die 9 als neue Pivot-Elemente. Nun werden die Teil-Arrays relativ zur 5 und 9 sortiert. Als Ergebnis erhält man die dritte Zeile, in der beinahe alle Elemente bereits sortiert sind. Lediglich die 8 (das neue Pivot-Element) muss mit der 7 die Plätze tauschen. Wer animierte Clips des Quicksort-Algorithmus einer statischen Grafik vorzieht, dem sei die Quicksort-Seite bei Wikipedia [2] empfohlen.

Abbildung 1: Eine schematische Darstellung des Quicksort-Algorithmus.
Aus der grafischen Darstellung des Quicksort-Algorithmus lassen sich noch weitere Schlüsse ziehen. Wenn das Array n Elemente umfasst, sind im Durchschnitt »n*log(n)« Sortierschritte notwendig. Der Faktor »log(n)« resultiert daraus, dass der Algorithmus in jedem Schritt das Array halbiert. Im schlechtesten Fall benötigt Quicksort »n*n« Sortierschritte. Das lässt sich mit einem kleinen Gedankenspiel veranschaulichen. In Abbildung 1 diente aus optischen Gründen das mittlere Element als Pivot-Element. Es kann aber auch jedes beliebige andere Element sein. Fungiert nun das erste Element als Pivot-Element und ist das Array bereits aufsteigend sortiert, so muss man das Array genau n Mal halbieren. Zur Erinnerung: Im Durchschnitt wird das Array »log(n)« Mal halbiert.
Ist das nicht beeindruckend? Ein paar Zeilen Prosa genügen, um die Idee von Quicksort samt seiner Leistungscharakteristik vorzustellen. Leider sah mein erster Kontakt mit dem Algorithmus ganz anders aus.
Erste Begegnung
Die klassische Quicksort-Implementierung in C besitzt nicht viel Charme und verschleiert erfolgreich ihr elegantes Design, wie Listing 1 demonstriert. Keine Angst, ich werde die Funktion »quickSort()« nicht erklären. Eine Beobachtung ist aber sehr interessant.
Listing 1
Quicksort in C
void quickSort(int arr[], int left, int right) {
int i = left, j = right;
int tmp;
int pivot = arr[abs((left + right) / 2)];
while (i <= j) {
while (arr[i] < pivot) i++;
while (arr[j] > pivot) j--;
if (i <= j) {
tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
i++; j--;
}
}
if (left < j) quickSort(arr, left, j);
if (i < right) quickSort(arr, i, right);
}
In den Zeilen 9 bis 11 überschreibt der Code die bestehenden Elemente. Der Algorithmus arbeitet also in-place und setzt veränderliche Daten voraus. Für das Überschreiben der alten mit den neuen Werten hat sich ein schöner Ausdruck in der funktionalen Programmierung etabliert: Destructive Assignment [3]. Damit wären wir schon mitten im nächsten Thema: In funktionalen Programmiersprachen wie Haskell lässt sich Quicksort viel eleganter darstellen.
Zweites Treffen
In Haskell sind Daten unveränderlich, was eine destruktive Zuweisung per Design ausschließt. In Haskell erzeugt der Quicksort-Algorithmus aus Listing 2 in jeder Iteration eine neue Liste und arbeitet nicht wie in Listing 1 direkt auf dem Array. Zwei Zeilen Quicksort? Ist das schon alles? Ja.
Listing 2
Quicksort in Haskell
qsort [] = [] qsort (x:xs) = qsort [y | y <- xs, y < x] ++ [x] ++ qsort [y | y <- xs, y >= x]
Der Algorithmus »qsort« besteht aus zwei Funktionsdefinitionen. Die erste Zeile wendet den Quicksort an, der auf der leeren Liste definiert ist. Die zweite Zeile stellt den allgemeinen Fall dar, in dem die Liste aus mindestens einem Element besteht: »x:xs«. Dabei bezeichnet per Konvention »x« den Anfang der Liste und »xs« den Rest.
Die eingangs vorgestellte Strategie des Quicksort-Algorithmus lässt sich fast direkt in Haskell umsetzen: @L Verwende das erste Element der Liste »x« als Pivot-Element;
- füge vor der einelementigen Liste »[x]« alle jene Elemente aus »xs« ein (»(++)«), die kleiner als »x« sind (»(qsort [y | y <- xs, y < x])«);
- hänge an die Liste »[x]« alle jene Elemente aus »xs« an, die mindestens so groß wie »x« sind (»(qsort [y | y <- xs, y >= x])«).
Die Rekursion endet dann, wenn Quicksort auf die leere Liste angewendet wird. Zugegeben, die Kompaktheit von Haskell erscheint ungewohnt. Dieser Quicksort-Algorithmus lässt sich aber in jeder Programmiersprache umsetzen, die List Comprehension unterstützt – womit wir mit Listing 3 bei der Mainstream-Programmiersprache Python angekommen wären.
Listing 3
Quicksort in Python
def qsort(L): if len(L) <= 1: return L return qsort([lt for lt in L[1:] if lt < L[0]]) + L[0:1] + qsort([ge for ge in L[1:] if ge >= L[0]])
Die Beschreibung des Haskell-Algorithmus lässt sich fast wortwörtlich auf Python übertragen. Der feine Unterschied besteht darin, dass in Python »L[0:1]« als erstes Element dient und man die Listenkonkatenation in Python durch das »+«-Symbol ausdrückt. Der Algorithmus erfüllt in Abbildung 2 zuverlässig seine Dienste.
Abbildung 2: Anwendung des Quicksort-Algorithmus in Python.
Friedlich vereint
Zugegeben, beide Implementierungsstrategien für Quicksort haben ihre Vor- und Nachteile. Die imperative Strategie in Listing 1 benötigt keinen zusätzlichen Speicher, verschleiert die elegante Struktur des Algorithmus aber fast völlig. Die funktionale Strategie in Listing 2 und Listing 3 wirkt sehr elegant, erzeugt aber bei jeder Rekursion eine neue Liste. Lassen sich die Vorteile beider Welten auch vereinen?
Ja. Die folgende Implementierung in C++ basiert auf »std::partition« [4], einem Algorithmus der Standard Template Library, der einen Bereich anhand eines Elements partitioniert. Damit übernimmt »std::partition« in Listing 4 die Aufgabe der List Comprehension in Listing 2 und Listing 3.
Listing 4
Quicksort in C++
template <typename Forward>;
void quicksort(ForwardIt first, ForwardIt last) {
if(first == last) return;
auto pivot = *std::next(first, std::distance(first,last)/2);
ForwardIt middle1 = std::partition(first, last, [pivot](const auto& em){return em < pivot;});
ForwardIt middle2 = std::partition(middle1, last, [pivot](const auto& em){return !(pivot < em);});
quicksort(first, middle1);
quicksort(middle2, last);
}
Die Gretchenfrage
Die Gretchenfrage in C++ hat dieser Artikel noch gar nicht beantwortet: “Nun sag, wie schnell bist du?”
Seit C++17 unterstützt C++ die sogenannte parallele Standard Template Library (STL). Das heißt, dass rund 70 der gut 100 Algorithmen der STL sich mittels einer Policy sequenziell, parallel oder vektorisiert ausführen lassen. Allerdings unterstützt bislang lediglich der Microsoft-Compiler ein paralleles Ausführen der STL-Algorithmen. Daher beziehen sich die folgenden Leistungswerte auf diesen Compiler. Alle Performance-Zahlen stammen von einem Programm, das maximal optimiert übersetzt und mit acht Kernen ausgeführt wurde. Listing 5 verwendet eine leicht modifizierte Variante des Quicksort-Algorithmus aus Listing 4.
Listing 5
Leistungstest
#include <algorithm>
#include <chrono>
#include <execution>
#include <iomanip>
#include <iostream>
#include <iterator>
#include <numeric>
#include <random>
#include <vector>
template <typename ExecutionPolicy, typename ForwardIt>
void quicksort(ExecutionPolicy&& policy, ForwardIt first, ForwardIt last) {
if(first == last) return;
auto pivot = *std::next(first, std::distance(first,last)/2);
ForwardIt middle1 = std::partition(policy, first, last, [pivot](const auto& em){ return em < pivot; });
ForwardIt middle2 = std::partition(policy, middle1, last, [pivot](const auto& em){ return !(pivot < em); });
quicksort(policy, first, middle1);
quicksort(policy, middle2, last);
}
std::vector<int> getRandomVector(int numberRandom, int lastNumber) {
std::random_device seed;
std::mt19937 engine(seed());
std::uniform_int_distribution<int> dist(0, lastNumber);
std::vector<int> randNumbers;
randNumbers.reserve(numberRandom);
for
(int i=0; i < numberRandom; ++i){
randNumbers.push_back(dist(engine));
}
return randNumbers;
}
int main() {
std::cout << :*\n:*;
constexpr int numberRandom = 100:*000:*000;
constexpr int lastNumber = 100;
std::vector randVec = getRandomVector(numberRandom, lastNumber);
std::cout << numberRandom << " random numbers between 0 and " << lastNumber << "\n\n";
{
std::vector tmpVec = randVec;
std::cout << std::fixed << std::setprecision(10);
auto begin = std::chrono::steady_clock::now();
quicksort(std::execution::seq, tmpVec.begin(), tmpVec.end());
std::chrono::duration<double> last= std::chrono::steady_clock::now() - begin;
std::cout << "Quicksort sequential: " << last.count() << :*\n:*;
}
{
std::vector tmpVec = randVec;
std::cout << std::fixed << std::setprecision(10);
auto begin = std::chrono::steady_clock::now();
quicksort(std::execution::par, tmpVec.begin(), tmpVec.end());
std::chrono::duration<double> last= std::chrono::steady_clock::now() - begin;
std::cout << "Quicksort parallel: " << last.count() << :*\n:*;
}
std::cout << "\n\n";
{
std::vector tmpVec = randVec;
std::cout << std::fixed << std::setprecision(10);
auto begin = std::chrono::steady_clock::now();
std::sort(std::execution::seq, tmpVec.begin(), tmpVec.end());
std::chrono::duration<double> last= std::chrono::steady_clock::now() - begin;
std::cout << "std::sort sequential: " << last.count() << :*\n:*;
}
{
std::vector tmpVec = randVec;
std::cout << std::fixed << std::setprecision(10);
auto begin = std::chrono::steady_clock::now();
std::sort(std::execution::par, tmpVec.begin(), tmpVec.end());
std::chrono::duration<double> last= std::chrono::steady_clock::now() - begin;
std::cout << "std::sort parallel: " << last.count() << :*\n:*;
}
std::cout << :*\n:*;
}
Der Algorithmus in Listing 5 enthält noch eine Ausführungsstrategie (Zeile 12). Damit lässt sich steuern, ob der Algorithmus sequenziell (»std::execution::seq« in den Zeilen 50 und 70) oder parallel (»std::execution::par« in den Zeilen 59 und 79) aufgerufen wird. Vereinfachend gesprochen, sortiert das Programm einen Vektor aus 100 000 000 zufälligen Elementen (Zeile 39) zwischen 0 und 100 (Zeile 40) und misst vier Mal die Performance.
Das Erzeugen der gleichverteilten Zufallszahlen erledigt die Funktion »getRandom« in Zeile 23. Sortiert wird der Vektor sowohl sequenziell (Zeilen 46 bis 53) und parallel (Zeilen 55 bis 62) mit der »quicksort«-Funktion als auch sequenziell (Zeilen 66 bis 73) und parallel (Zeilen 75 bis 82) mit »std::sort« aus der STL. Dabei wendet »std::sort« unter der Decke ein hybrides Verfahren an, bei dem auch Quicksort zu Einsatz kommt. Wer sich für die Details der Microsoft-Implementierung von »std::sort« interessiert, kann diese auf Github [5] nachlesen.
Neben der Ausführungsstrategie kommen in diesem Beispiel noch zwei weitere C++17-Features zum Einsatz. Einerseits lassen sich Zahlen mit Ticks lesbar darstellen (»100’000’000«), andererseits kann der Compiler automatisch den Typ eines Klassen-Templates bestimmen: »std::vector tmpVec = randVec« anstelle von »std::vector<int> tmpVec = randVec«.
Size matters
Nun aber zurück zur Gretchenfrage. Bei 100 000 000 Zufallszahlen aus dem Bereich von 0 bis 100 arbeitet der parallel ausgeführte Quicksort beeindruckend schnell (Abbildung 3). Er schlägt die sequenzielle Variante um den Faktor 5 und ist mehr als doppelt so schnell wie der parallel ausgeführte »std::sort«. Diese Relation ändert sich aber deutlich, wenn der Bereich, aus dem die Zufallszahlen gleichverteilt kommen, deutlich wächst.
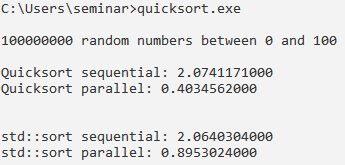
Abbildung 3: Sortierung von 1 000 000 Zufallszahlen zwischen 0 und 100.
Unabhängig davon, ob der Bereich auf 0 bis 10 000 (Abbildung 4) oder 0 bis 1 000 000 (Abbildung 5) steigt, schlägt der parallel ausgeführte »std::sort« den sequenziell ausgeführten um etwa den Faktor 4. Da kann der parallel ausgeführte »quicksort« nicht mithalten. Seine überragende Leistung schrumpft deutlich, wenn sich der Bereich vergrößert. Bei Zufallszahlen zwischen 0 und 1 000 000 ist die parallele Ausführung um den Faktor 5 langsamer als die sequenzielle.
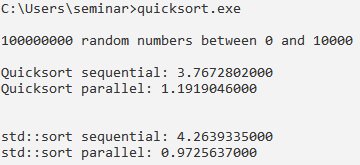
Abbildung 4: Sortierung von 1 000 000 Zufallszahlen zwischen 0 und 10 000.
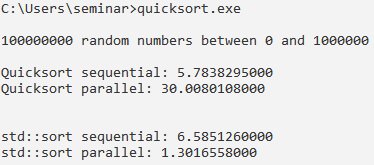
Abbildung 5: Sortierung von 1 000 000 Zufallszahlen zwischen 0 und 1 000 000.
Worauf lassen sich diese gravierenden Leistungsunterschiede zurückführen? Wir analysieren das Problem nicht erschöpfend, sondern wollen nur ein paar Denkanstöße liefern.
Der wesentliche Unterschied zwischen 100 000 000 Zufallszahlen zwischen 0 und 100 sowie zwischen 0 und 1 000 000 besteht darin, dass im ersten Fall im Durchschnitt 1 000 000 gleiche Zahlen (1 000 000 / 100) und im zweiten Fall im Durchschnitt 100 gleiche Zahlen (100 000 000 / 1 000 000) im Zufallsvektor landen. Das heißt insbesondere, dass der Aufruf »std::partition« [4] im ersten Fall deutlich effizienter agieren kann, da er bezogen auf das Pivot-Element deutlich weniger Elemente tauschen muss. Darüber hinaus erfordert dieser schreibende Zugriff eine Synchronisierung zwischen den Threads.
Nun muss ich persönlich werden. Während meiner langen Zeit als C++-Software-Entwickler und nun auch als C++-Trainer hat sich ein Vorurteil in meinem Kopf festgesetzt: “Glaube nicht, dass du die Performance der Algorithmen der STL im Allgemeinen schlagen kannst.” Fast hätte ich nach der ersten Ausführung mit den Zufallszahlen zwischen 0 und 100 mein Vorurteil über den Haufen geworfen; die weiteren Leistungstests haben es dann aber bestätigt.
Fazit
Ist Quicksort mein Lieblingsalgorithmus? Ich bin mir nicht sicher. Auf jeden Fall steht aber fest, dass ein Verständnis dieses Algorithmus zum Pflichtrepertoire jedes professionellen Software-Entwicklers zählt. Ärgerlicherweise verschleiert die klassische Implementierung des Quicksort-Algorithmus dessen elegante Struktur und erschwert damit auch sein Grundverständnis. (jcb/jlu)
Der Autor
Rainer Grimm ist Trainer für C++ und Python. Seine Bücher “C++11 für Programmierer”, “C++”, C+-Standardbibliothek” sowie “The C++ Standard Library”, “Concurrency with Modern C++” und “C++20” sind bei O’Reilly und Leanpub erschienen.
Infos
- Quicksort:: https://en.wikipedia.org/wiki/Quicksor
- Tony Hoare: https://de.wikipedia.org/wiki/Tony_Hoare
- Destructive Assignment: https://en.wikipedia.org/wiki/Assignment_(computer_science)
- »std::partition«: https://en.cppreference.com/w/cpp/algorithm/partition
- Microsofts STL-Implementierung: https://github.com/microsoft/STL





