
© Aliaksandr Barysenka, 123RF
Seit Jahren sorgen Container in der IT für Furore. Die Frage, ob diese Technologie sicher ist, halten viele für unzureichend beantwortet. Es gibt mehrere Ansätze, um diese Sicherheitslücke zu schließen. Der Artikel stellt dafür verschiedene Ansätze mit Hypervisoren und Pufferzonen vor.
Container-Technologie ist inzwischen ein fast omnipräsenter Bestandteil moderner IT. Das zugehörige Ökosystem wächst und macht sowohl Anwendung als auch die Integration immer einfacher. Für manche sind Container quasi die nächste Evolutionsstufe von virtuellen Maschinen: Sie starten schneller, sind flexibler und nutzen die vorhandenen Ressourcen besser.
Eine Frage bleibt jedoch unzureichend beantwortet: Sind Container genauso sicher wie virtuelle Rechner? Dieser Artikel beschreibt zunächst kurz den aktuellen Stand. Danach gibt er Einblick in verschiedene Ansätze, die Sicherheitsbedenken endgültig zu beseitigen. Dabei beschränken sich die Betrachtungen auf Linux als zugrunde liegendes Betriebssystem. Das ist aber keine Einschränkung, denn das Container-Ökosystem sieht hier vielfältiger aus als bei den Mitbewerbern.
Wie sicher können Container sein?
Woher kommen eigentlich die Fragen nach der Container-Sicherheit? Fairerweise sollten hier nur die Spezifika dieser Technologie Gegenstand der Untersuchung sein. Das Ausnutzen einer SQL-Sicherheitslücke einer Datenbank oder einer Schwachstelle in einem Webserver gehören nicht dazu. Dafür dienen klassische virtuelle Maschinen als das Maß der Dinge. Die Frage lautet also: Bieten Container die gleiche Sicherheit? Das lässt sich sogar noch präziser formulieren: Bieten Container eine vergleichbare oder gar bessere Abschirmung der einzelnen Instanzen voneinander? Und: Wie angreifbar ist der Host durch die darauf laufenden Dienste?
Hier ist ein kurzer Rückblick auf die grundlegende Funktionsweise von Containern unerlässlich (Abbildung 1). Als fundamentale Bestandteile dienen Kontrollgruppen und Namensräume, die der Betriebssystemkern bereitstellt. Dazu kommen noch einige Prozesse und Zugriffsberechtigungen. Letztere erteilt wiederum der Kernel. Damit fällt eine wesentliche Sicherheitsherausforderung bei Containern sofort ins Auge: Gelingt ein Ausbruch aus einer Instanz, führt das entweder in den Bereich des Betriebssystemkerns oder zumindest gefährlich nahe. Der Bösewicht befindet sich damit in einer Umgebung, die mit umfassenden, weitreichenden Rechten ausgestattet ist. Zudem bedient meist ein Kernel mehrere Container-Instanzen. Im Falle eines erfolgreichen Angriffs sind damit alle gefährdet.
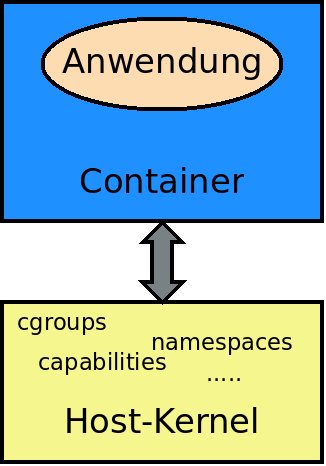
Abbildung 1: Vereinfachter schematischer Aufbau von Containern.
Die offensichtliche Gegenmaßnahme: das Verhindern eines solchen Ausbruchs. Das ist allerdings einfacher gesagt als getan. Allein 2019 gab es zwei [1] schwerwiegende Sicherheitslücken [2]. Glücklicherweise blieben 2020 solche Nachrichten aus. Diese Ruhe dürfte allerdings trügen: Der Betriebssystemkern ist ein komplexes Konstrukt mit vielen Systemaufrufen und internen Kommunikationskanälen. Die Erfahrung sagt, dass es immer wieder zu unerwünschten Nebeneffekten oder gar Fehlern kommt. Manchmal bleiben diese über Jahre unentdeckt. Gibt es also keine Chance auf eine Verbesserung der Sicherheit von Containern? Ist das Vertrauen in die harte Arbeit der Entwicklergemeinde die einzige Möglichkeit?
Neuer Ansatz: Flucht nach vorne
Das eben beschriebene Szenario basiert auf einer bestimmten Annahme beziehungsweise Denkweise: Es gilt, den Ausbruch aus der Container-Instanz zu verhindern. Die ist aber nur ein möglicher Aspekt des Themas Container-Sicherheit. Das Vermeiden des Ausbruchs soll den darunterliegenden Betriebssystemkern schützen. Lässt sich das auch anders erreichen? Genügt es eventuell schon, den Schaden nach einem solchen Ausbruch zu minimieren?
Dieser Denkansatz ist in der IT überhaupt nicht neu. Ein bekanntes Beispiel kommt aus dem Bereich Netzwerk, beim Absichern einer Webseite mit Applikation und Datenbank. Hier hat sich schon lange eine Pufferzone etabliert, die sogenannte DMZ (Demilitarisierte Zone [3]). Das Konzept lässt sich auch auf Container übertragen (Abbildung 2).
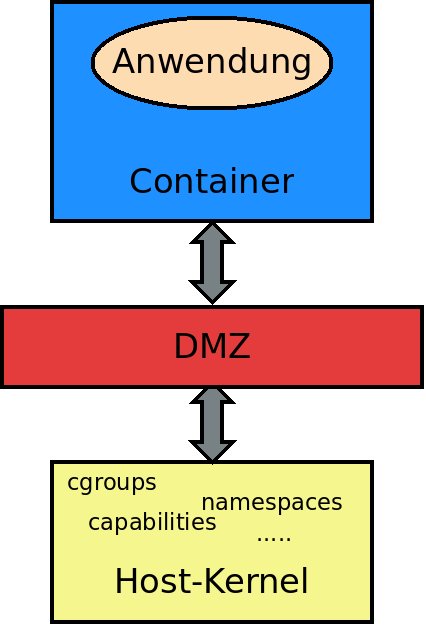
Abbildung 2: Eine Pufferzone sichert die Container.
Bei den im Folgenden vorgestellten drei Ansätzen für diese Pufferzone besteht der wesentliche Unterschied darin, wie “dick” beziehungsweise “umfangreich” diese ausfällt.
Vertrauen auf griechisch mit Kata
Der erste Ansatz nimmt starke Anleihen bei der klassischen Virtualisierung mittels eines Hypervisors. Ein prominenter Vertreter ist das seit 2017 aktive Projekt Kata Containers [4]. Als dessen Schirmherr fungiert die Open Infrastructure Foundation, die viele wohl noch unter dem Namen OpenStack Foundation kennen [5].
Die eigentlichen Wurzeln von Kata Containers reichen aber weiter zurück als 2017. Das Projekt führt Bemühungen aus den Häusern Intel und Hyper zusammen: Clear Container [6] beziehungsweise RunV [7]. Bei Kata Containers dient ein sogenannter Hypervisor des Typs II mit einem abgespeckten Linux als Pufferzone (Abbildung 3). In den ersten Versionen kam eine etwas abgespeckte Version von Qemu [8] zum Einsatz, neuere Versionen unterstützen den Micro-Hypervisor Firecracker [9] aus dem Hause AWS.
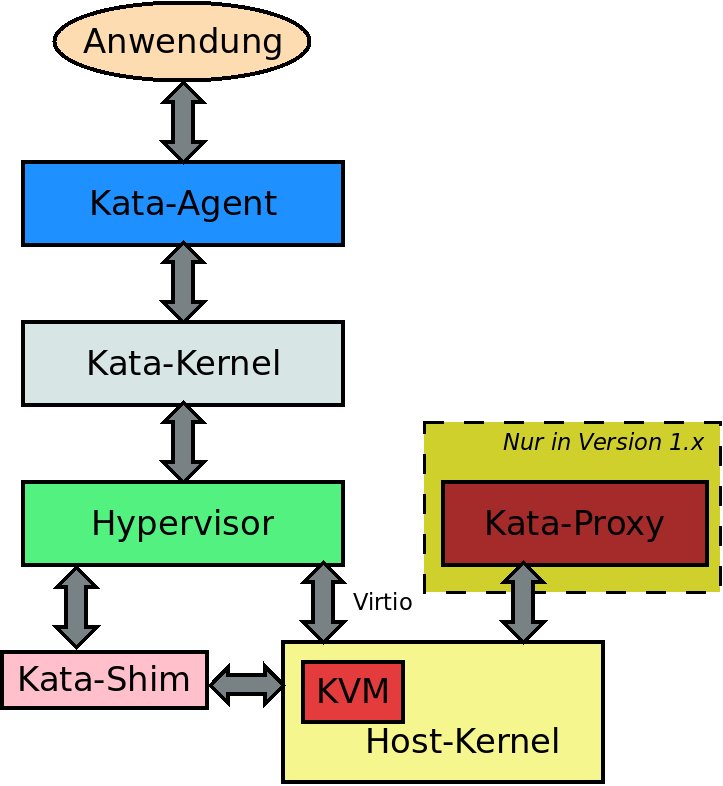
Abbildung 3: Der schematische Aufbau von Kata Containers.
Als dieser Artikel entstand, veröffentlichte das Kata-Containers-Projekt eine neue Version, die die Anzahl der notwendigen Komponenten reduziert. In Abbildung 3 sieht man noch einen Proxy-Prozess, der in der aktuellen Version komplett wegfällt. Außerdem läuft nun nur noch ein einziger Shim-Prozess für alle Container-Instanzen.
Der eigentliche Clou ist aber nicht die Verwendung von Qemu und Co., sondern vielmehr die Integration in die Verwaltungswerkzeuge für Container. Anders ausgedrückt: Das Starten, die Interaktion und das Stoppen von Container-Instanzen soll analog zu herkömmlichen Containern funktionieren. Dafür kommen beim Kata-Ansatz zwei Prozesse zum Einsatz.
Der erste, der Kata-Shim, ist eine Erweiterung der standardisierten “Unterlegscheibe” der Container-Welt. Er ist quasi der Teil der Brücke, die in die virtuelle Maschine reicht. Dort übernimmt Prozess Nummer zwei, der Kata-Agent. Er läuft als normaler Prozess innerhalb der virtuellen Instanz. In der Standardinstallation übernimmt diesen Part ein abgespecktes Betriebssystem aus dem Hause Intel namens Clear Linux [10]. Damit erhält der Kernel des darunterliegenden Betriebssystems gleich einen doppelten Schutz, durch den Kernel des Gastbetriebssystems sowie durch die Virtualisierungsschicht.
Ebenfalls auf der Habenseite steht eine hohe Kompatibilität. Prinzipiell sollte jede Anwendung funktionieren, die sich mit Qemu und Co. virtualisieren lässt; Analoges lässt sich für bereits angelegte Container-Abbilder sagen. In Labortests gab es keinerlei Auffälligkeiten. Die Verwendung von bekannten Technologien erleichtert auch die Problemanalyse und Fehlersuche.
Nachteile des Hypervisor-Puffers
Erhöhte Sicherheit mit weitgehender Kompatibilität hat auch ihren Preis. Da wäre zum einen der höhere Bedarf an Hardware-Ressourcen: Pro Container-Instanz muss ein Virtualisierungsprozess laufen, außerdem erfordert die Software dahinter ebenfalls Wartung und bietet eine zusätzliche Angriffsfläche. Letzteres war auch der Grund, dass Kata Containers eine abgespeckte Version von Qemu verhindert. Apropos Wartung: Das Gastbetriebssystem muss sich ebenfalls auf einem aktuellen Stand befinden. Zumindest sollten kritische Lücken und Sicherheitslöcher adressiert sein.
Alles in allem resultieren aus der erhöhten Container-Sicherheit eine vergrößerte Angriffsfläche auf der Host-Seite und ein deutliches Mehr an Verwaltungsaufwand. Zur Linderung dieses Problems könnte man auf sogenannte Micro-Hypervisoren ausweichen. Dann stellt sich aber erneut die Frage nach der Kompatibilität. Schließlich hängt diese von der konkreten Implementation des Micro-Hypervisors ab. Wer hier praktische Erfahrung sammeln möchte, kann Kata Containers mit Firecracker (Listing 1) betreiben [11].
Listing 1
Kata und Firecracker in Aktion
$ docker run --runtime=kata-fc -itd --name=kata-fc busybox sh d78bde26f1d2c5dfc147cbb0489a54cf2e85094735f0f04cdf3ecba4826de8c9 $ pstree|grep -e container -e kata |-containerd-+-containerd-shim-+-firecracker---2*[{firecracker}] | | |-kata-shim---7*[{kata-shim}] | | `-10*[{containerd-shim}] | `-14*[{containerd}] $ $ $ docker exec -it kata-fc sh / # / # uname -r 5.4.32
Hinter den Kulissen von Kata Containers
Eine Installation von Kata Containers besteht aus einer Reihe von Komponenten, die sich grob in zwei Klassen unterteilen lassen. Da sind zunächst die Prozesse, die auf dem Host-System laufen, wie der Kata-Shim und der Kata-Hypervisor. In älteren Versionen kommt noch ein Proxy dazu. Dann gibt es noch Prozesse, die innerhalb von Kata Containers laufen. Das beginnt mit dem Betriebssystem innerhalb des Hypervisors und reicht über den Kata-Agenten bis hin zur eigentlichen Anwendung. Im Extremfall ist der Anwender also mit mehr als einer Handvoll Komponenten konfrontiert, die es aktuell und sicher zu halten gilt. Der typische Anwendungsfall sieht hier aber nicht mehr als drei Teile vor.
Die Prozesse und Entwicklungszyklen für das Host-Betriebssystem sowie die eigentliche Anwendung sind unabhängig von Kata Containers. Die verbleibenden Komponenten lassen sich als ein Gesamtkonstrukt verwalten. Sprich: Für die gängigen Linux-Distributionen gibt es Software-Verzeichnisse, die das einfache Installieren, Aktualisieren und Entfernen der notwendigen Komponenten ermöglichen. Dazu gehören der Hypervisor, der Gastkern, das gesamte Gastbetriebssystem sowie Kata-Shim und Kata-Agent. Übrigens lassen sich Container nach Kata-Art ohne Weiteres parallel zu herkömmlichen Containern betreiben.
Doppel-Kernel ohne Virtualisierung
Wie bereits erwähnt, kommt der eben beschriebene Hypervisor-Ansatz gleich mit zwei Isolationsschichten daher – einmal das Gastbetriebsystem beziehungsweise dessen Kernel, zum Zweiten die Virtualisierung an sich. Es stellt sich die Frage, ob es nicht auch einfacher geht. Wie wäre es etwa mit nur einem zusätzlichen Kernel als Pufferzone? Gute Idee, aber wie startet man einen Linux-Kernel auf der Basis eines schon laufenden?
Wer schon ein paar Tage in der IT unterwegs ist, der kennt sicherlich User-mode Linux (UML [12]). Die notwendigen Anpassungen sind schon seit Jahren Bestandteil des Kernels. Aber bereits eine erste Recherche zeigt, dass dieses Projekt wohl eher ein Nischendasein fristet – keine gute Startposition, um die Container-Welt zu bereichern.
Ein zweiter Gedanke führt zum Systemaufruf »kexec()«. Dessen typisches Einsatzgebiet ist das Sammeln von Daten, die zu einem Fehlverhalten des primären Linux-Kernels geführt haben. Das entspricht recht wenig dem Ausführen von Containern, die man mehrfach und gleichzeitig ausführt und die deutlich länger laufen.
Egal, ob UML oder »kexec()« – ohne umfangreiche Zusatzarbeiten lassen sich diese Projekte nicht für erhöhte Container-Sicherheit nutzen. Eine abgeschwächte Variante des Startens eines zweiten Kernels hat Google im Projekt gVisor [13] verwirklicht.
Linux mit und im Visier durch Google
Es gibt zwei große Herausforderungen, um einen zusätzlichen Betriebssystemkern als Pufferzone zu etablieren. Die erste liegt darin einen oder gar mehrere zusätzliche Kernel auszuführen. Die zweite betrifft die transparente Integration in die vorhandene Welt der Werkzeuge und Methoden für die Container-Verwaltung.
Das Projekt gVisor liefert eine recht pragmatische Lösung für diese Aufgaben. Die Software ist kein echter Linux-Kernel, sondern gibt sich nur als solcher aus. Als Programmiersprache kommt mit Golang ein recht moderner Vertreter zum Einsatz. Das Resultat ist eine normale ausführbare Datei, die alle notwendigen Funktionen des Betriebssystemkerns abbildet; die Herausforderung des Ladens oder gar mehrfachen Ausführens ist damit vom Tisch.
Das Nachahmen eines Linux-Kernels ist sicherlich schwierig, aber nicht unmöglich. Zur Minimierung der zusätzlichen Angriffsfläche lässt sich der Funktionsumfang entsprechend reduzieren – es müssen ja “nur” Container laufen. Der gVisor-Kernel besteht aus zwei Komponenten (Abbildung 4). Sentry mimt dabei den Linux-Unterbau und fängt die entsprechenden Systemaufrufe ab.
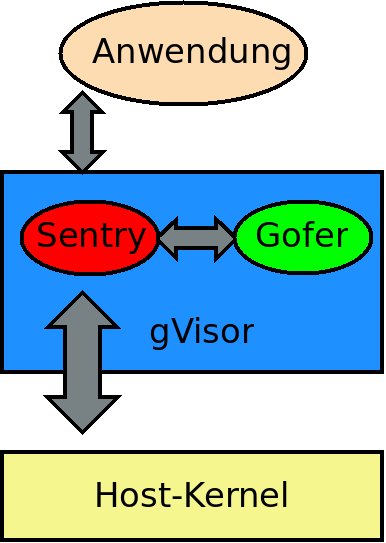
Abbildung 4: Der schematische Aufbau von gVisor.
Der kritische Leser fragt sich sofort, was bei diesem Konzept möglicherweise nicht funktioniert. Tatsächlich war der Start etwas holprig, Freunde der Postgres-Datenbank hatten anfangs das Nachsehen. Grund war die fehlende Unterstützung für den Systemaufruf »sync_file_range()« [14]. Inzwischen ist das längst Geschichte. Selbst unerfahrene Programmierer können sich in der Datei »gvisor/pkg/sentry/syscalls/linux/linux64.go« einen Überblick über die unterstützten Systemaufrufe verschaffen. Der Interessent muss aber nicht so sehr ins Detail gehen: Auf der Webseite der Entwickler gibt es eine Verträglichkeitsliste [15].
Doch zurück zur zweiten Komponente des gVisor-Kernels: Gofer regelt den Zugriff auf die Datenträger des Host-Systems. Dabei dient es als eine Art Proxy und interagiert mit der anderen gVisor-Komponente, Sentry. Wer es genauer wissen will, muss einen Blick auf ein recht altes Protokoll werfen: Die Rede ist von 9P [16], das seinen Ursprung in den späten 1980-ern in den legendären Bell Labs hat.
Dem gVisor auf die Finger geschaut
Vergleicht man Kata Containers und gVisor, dann wirkt Letzterer einfacher. Statt mehrerer Software-Komponenten muss man nur eine einzelne ausführbare Datei verwalten. Die Angriffsfläche durch zusätzliche Bestandteile im Gesamtsystem ist ebenfalls kleiner. Auf der Schattenseite steht der Mehraufwand in Sachen Kompatibilität. Ohne Eigenaufwand ist der Anwender hier auf die Arbeit und das Engagement der gVisor-Entwickler angewiesen.
Sichere Container mit gVisor im Selbstversuch
Die ersten Schritte mit gVisor gestalten sich einfach. Man muss nur eine einzige Binärdatei herunterladen und platzieren. Ein typischer Fallstrick (neben nicht unterstützten Systemaufrufen) ist die Version des gVisor-Kernels, in der Voreinstellung 4.4.0 (Listing 2). In der Welt der quelloffenen Software ist dies aber oft wenig mehr als eine Zeichenkette – so auch hier.
Die Versionsnummer ist in der Datei »gvisor/pkg/sentry/syscalls/linux/linux64.go« hinterlegt. Das Erzeugen einer angepassten Binärdatei fällt dank (traditioneller) Container-Technologie leicht. Listing 2 zeigt übrigens auch, wie sich gVisor parallel neben anderen Laufzeitumgebungen installieren und betreiben lässt. Der Anwender muss nur den Pfad zur Binärdatei und eventuell notwendige Argumente angeben.
Listing 2
Container mit gVisor-Kernel-Pufferzone
$ cat /etc/docker/daemon.json { "runtimes": { "oci": { "path": "/usr/sbin/runc" }, "runsc": { "path": "/usr/local/bin/runsc", "runtimeArgs": [ "--platform=ptrace", "--strace" ] } } } $ uname -r 5.8.16-300.fc33.x86_64 $ docker run -ti --runtime runsc busybox sh / # / # uname -r 4.4.0
Harfen als Minimalisten
Zum Schluss sei noch ein dritter Ansatz vorgestellt. Er übernimmt die Ideen der ersten beiden und treibt den Minimalismus auf die Spitze. Wieder übernimmt eine Art Micro-Hypervisor den Dienst, hinzu kommt ein super-minimalistischer Betriebssystemkern. Bei Letzterem handelt es sich um einen alten Bekannten aus der Familie der Unikernels. Treue Leser erinnern sich eventuell an einen Artikel des Autors zu diesem Thema aus dem Jahr 2015 [17]. Das dort vorgestellte MirageOS stand auch bei Nabla Containers [18] Pate – doch dazu gleich mehr.
Bei den Unikernels gibt es sehr verschiedene Implementationen. So wahrt beispielsweise OSv [19] noch eine gewisse Linux-Kompatibilität, wobei sich Parallelen zum hier vorgestellten gVisor-Kernel erkennen lassen. Am anderen Ende des Spektrums der Wiederverwendbarkeit steht MirageOS: Hier baut man Anwendung und Kernel komplett neu und komplett aufeinander angepasst. Als Resultat erhält man dann auch nur eine einzige ausführbare Datei. Anders gesagt: Die Anwendung ist der Kernel und umgekehrt. Eine Schicht darunter befindet sich der bereits erwähnte Micro-Hypervisor, der sich auf die Ausführung von Unikernels spezialisiert. Damit weist er wenig Gemeinsamkeiten mit seinen Kollegen Firecracker, Nova [20] oder Bareflank [21] auf.
Eine Implementierung dieses Ansatzes ist Nabla Containers. Die Wurzeln des Projekts liegen in den Forschungslaboren von IBM, als Micro-Hypervisor kommt Solo5 zum Einsatz. Ursprünglich war es nur als Erweiterung von MirageOS für KVM [22] gedacht. Inzwischen ist es ein Gerüst zum Ausführen verschiedener Unikernel-Implementationen. Trotz der Nähe zu MirageOS hat sich bei Nabla Containers eine gewisse Vorliebe für die sogenannten Rumprun-Kerne entwickelt [23].
Den schematischen Aufbau zeigt Abbildung 5; aus dessen Struktur leitet sich der Name Nabla ab. An der Spitze steht der Micro-Hypervisor mit dem Unikernel, die eigentliche Anwendung bildet die Basis. Die Größe der Komponenten entspricht deren Wichtigkeit aus dem Blickwinkel des Geschäftsmanns, die Reihenfolge entspricht dem Aufbau des Technologiestapels. So entsteht ein auf dem Kopf stehendes Dreieck, das dem Symbol Nabla aus der Vektoranalysis stark ähnelt.
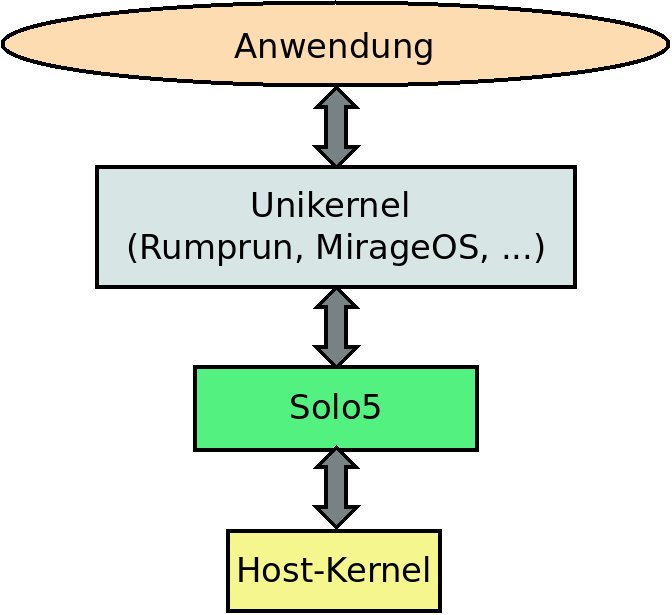
Abbildung 5: Der schematische Aufbau von Nabla Containers.
Ein paar Vorteile von Nabla Containers liegen auf der Hand. Es gibt analog zum Kata-Ansatz zwei Isolationsschichten, Betriebssystemkern und Virtualisierung. Diese sind stark minimiert und beanspruchen deutlich weniger Ressourcen als die Kombination von Clear Linux und Qemu-Lite. Hinzu kommt, dass bei Nabla Containers fast alle Systemaufrufe verboten sind. Die Software benutzt dabei die Seccomp-Funktionen des Kernels [24]. Am Ende stehen die folgenden Systemaufrufe zur Verfügung: »read()«, »write()«, »exit_group()«, »clock_gettime()«, »ppoll()«, »pwrite64()« und »pread6()«.
Auf der Schattenseite steht ganz klar die quasi nicht vorhandene Kompatibilität. Anders als bei Kata Containers oder gVisor lassen sich vorhandene Container-Abbilder nicht direkt mit dem Nabla-Ansatz verwenden. Tests der Redaktion zeigten, dass der Migrationsaufwand selbst bei kleinen Anwendungen immens ausfällt.
Wohin soll die Reise gehen?
Die Container-Gemeinde nimmt das Thema Sicherheit sehr ernst. Prinzipiell gibt es zwei parallele Strömungen; die eine beschäftigt sich mit der Verbesserung der eigentlichen Container-Software. Dieser Artikel dagegen beschäftigte sich mit Methoden, um weitere Verteidigungslinien außerhalb aufzubauen. Dabei erlebt die Idee einer DMZ aus dem Netzwerk-Bereich einen neuen Frühling. Als Pufferzone zwischen der Anwendung und dem Host dient ein weiterer Betriebssystemkern und bisweilen sogar eine Virtualisierungsschicht.
Eine grundlegende Kompatibilität mit den bekannten Verwaltungswerkzeugen für Container ist gegeben, sie lassen sich sogar komplett parallel betreiben (siehe auch Listing 2). Es gibt allerdings große Unterschiede hinsichtlich der Wiederverwendbarkeit bestehender Anwendungen und Container-Abbilder. Mit Kata Containers stehen dem Anwender die geringsten Hürden im Weg, am anderen Ende des Spektrums rangiert Nabla Containers. So oder so: Die Idee der Pufferzone ist ebenso einfach wie famos. Dank der verschiedenen Implementationen sollte für jeden Geschmack etwas dabei sein. (uba)
Der Autor
Dr. Udo Seidel ist eigentlich Mathe-Physik-Lehrer und seit 1996 Linux-Fan. Nach seiner Promotion arbeitete er als Linux/Unix-Trainer, Systemadministrator, Senior Solution Engineer und Linux-Stratege. Heute ist er als IT-Architekt und Evangelist bei der Amadeus Data Processing GmbH in Erding beschäftigt.
Infos
- Container Breakout: http://seclists.org/oss-sec/2019/q1/119
- Docker Schwachstelle: http://www.cert-bund.de/advisoryshort/CB-K19-0456
- DMZ –Demilitarisierte Zone: http://de.wikipedia.org/wiki/Demilitarisierte_Zone_(Informatik)
- Projekt Kata Containers: http://katacontainers.io
- Openstack: http://www.openstack.org/
- Clear Containers: http://github.com/clearcontainers/runtime/wiki
- RunV: http://github.com/hyperhq/runv
- Qemu: http://www.qemu.org/
- Firecracker: http://firecracker-microvm.github.io/
- Clear Linux: http://clearlinux.org/
- Kata Containers mit Firecracker: http://github.com/kata-containers/documentation/wiki/Initial-release-of-Kata-Containers-with-Firecracker-support
- User-mode Linux: http://user-mode-linux.sourceforge.net/
- Googles gVisor: http://gvisor.dev/
- gVisor-Probleme: http://github.com/google/gvisor/issues/88
- Verträglichkeitsliste: http://gvisor.dev/docs/user_guide/compatibility/
- 9P: http://9p.cat-v.org/
- Cloud-Systeme: Dr. Udo Seidel, “Lift in die Wolken”, LM 02/2015, S. 70, https://www.lm-online.de/33816
- Nabla Container: http://nabla-containers.github.io/
- OSv: http://osv.io/
- Nova: http://hypervisor.org/
- Bareflank: http://github.com/Bareflank/MicroV
- KVM: http://linux-kvm.org/
- Rump Kernel: http://rumpkernel.org/
- Seccomp: http://man7.org/linux/man-pages/man2/seccomp.2.html





