
© Kittipong Jirasukhanont, 123RF
Nicht alles ist in der schönen neuen Container-Welt einfacher als zuvor. Wo Admins früher ein paar Pakete installierten, sehen sie sich heute einer Armada von Containern gegenüber. Hier können Operatoren in Kubernetes helfen.
Die Container-Revolution beseitigt konventionelle IT quasi im Vorbeigehen. Sie räumt mit alten Problemen auf und erlaubt es dem Admin, sich lässig in die Hängematte zu fläzen. Neue Software etwa rollt sich ganz von allein aus, sobald ein Entwickler eine Änderung am Quelltext der Anwendung vorgenommen hat. Alle Probleme althergebrachter IT gehören der Vergangenheit an. Oder doch nicht? Die Behauptung, mit Containern sei alles viel besser, hält sich zwar hartnäckig, stimmt aber mit der Realität nur bedingt überein. Das macht ein einfaches Beispiel schnell deutlich.
Vor ein paar Jahren war die Frage, wie eine Applikation den Weg auf den eigenen Server findet, schnell beantwortet: als Paket über einen Paketmanager. Es war ein grundlegendes Verdienst der Linux-Distributoren, die im Netz oft nur in Form des Quelltextes vorliegende Software zu kompilieren und so abzustimmen, dass sie im Kontext eines Gesamtsystems nutzbar wurde. Darauf bauen praktisch alle gängigen Paketmanager auf. Hält man sich zudem vor Augen, dass sowohl die Paketverwaltung von Red Hat als auch jene von Debian über 20 Jahre auf dem Buckel hat, darf man feststellen: So blöd ist das Konzept offensichtlich nicht.
Höhere Komplexität
Nun haben allerdings in den vergangenen Jahren die Container das Kommando übernommen und für viele Verbesserungen gesorgt. Agiles Arbeiten und agile Entwicklung zum Beispiel gelingen mit Containern deutlich leichter als mit klassischen monolithischen Applikationen. Viele Beobachter glauben im ersten Moment außerdem, dass Container auch die Komplexität eines Setups deutlichen reduzieren würden. Dabei handelt es sich jedoch um einen Trugschluss: Die Komplexität nimmt nicht ab, sie verschiebt sich nur.
Wo früher ein monolithischer Service in ein Paket wanderte, hat der Admin es heute in einer Microservice-Architektur mit einer Vielzahl kleiner Dienste zu tun. Applikationen gelten nur dann als Cloud ready, wenn sie in möglichst viele Mikrodienste aufgeteilt sind – und die müssen grundsätzlich in autarker Weise miteinander funktionieren. Wo der Admin früher also den Zustand lediglich eines Programms überwachen musste, hat er es heute mit etlichen, oft Dutzenden Tools zu tun.
Obendrein geht es ja nicht nur um die Frage, ob Dienste laufen: Auch das Ausrollen vieler Container gleichzeitig stellt eine echte Herausforderung dar. Dabei ist nicht nur wichtig, ob der Rollout wie gewünscht funktioniert hat. Vielmehr möchte der Admin auch wissen, ob die unterschiedlichen Komponenten einer Mikroarchitektur-Applikation miteinander kommunizieren können. Innerhalb der Umgebungen kommen dafür heute üblicherweise Mesh-Lösungen wie Istio zum Einsatz, die noch ein Scherflein Komplexität hinzufügen.
States sind eine Herausforderung
Das Ausrollen großer Mikroarchitekturanwendungen stellt daher nicht selten ganze DevOps-Abteilungen vor ernsthafte Herausforderungen. Orchestrierer wie das mittlerweile fast omnipräsente Kubernetes räumen zumindest mit einem Teil der Komplexität auf: Sie ermöglichen es, Container auf Basis einer standardisierten Syntax über viele Compute-Knoten auszurollen. Das macht das Leben von Kubernetes-Admins zumindest punktuell bedeutend einfacher, weil ein großer Brocken Arbeit dadurch bereits entfällt.
Um die Aspekte, die nicht unmittelbar etwas mit dem Starten von Containern zu tun haben, kümmern sich die Container-Orchestrierer nur teilweise – hier stoßen die Automatismen von Kubernetes & Co. an Grenzen. Das zeigt sich besonders deutlich bei Anwendungen, die in Kubernetes laufen sollen, aber einen eigenen Zustand haben – also “stateful” sind. Eine Datenbank bietet dafür ein simples Beispiel: Bei ihr kommt es nicht nur darauf an, dass sie läuft, sondern auch, dass sie ihre Daten verfügbar hat. Das wiederum bedingt, dass der Admin sich um Dinge wie Hochverfügbarkeit und Redundanz Gedanken machen muss, falls das auf Applikationsebene nicht abgebildet ist. Und gerade bei älteren Anwendungen ist es das oft genug nicht.
Wer Kubernetes & Co. ausschließlich als Werkzeug sieht, das moderne, hippe Cloud-Anwendungen verwaltet, täuscht sich: Auch für den Betrieb von MySQL & Co. in Containern gibt es gute Gründe.
Operatoren als Rettung
Während der Betrieb von Stateless-Anwendungen in Containern nur selten Probleme verursacht, lassen sich Stateful-Anwendungen in Kubernetes nur bedingt abbilden: Das dafür nötige operative Wissen war in Kubernetes technisch lange schlicht nicht abbildbar. 2016 sorgte CoreOS für eine kleine Revolution in Kubernetes: Es stellte das Konzept der Operatoren vor.
Hier ist der Name Programm: Es geht um eine technische, auf Standards fußende Methode, um operatives Wissen zum Betrieb einer Applikation in Kubernetes-Sprech abzubilden. Gelegentlich ist bei Operatoren von einem Paketformat die Rede – das greift jedoch viel zu kurz, weil Informationen zum Betrieb auch in althergebrachten Paketen schlicht fehlen. Ein Software-Bundle kann Teil eines Operators, aber theoretisch – in welchem Format auch immer – auch allein einen Operator verkörpern. Die Regel ist das aber nicht.
Heute sind Operatoren aus der Kubernetes-Fangemeinde nicht mehr wegzudenken, zumal die großen Anbieter sie mittlerweile auch systematisch kommerzialisieren. Der folgende Artikel stellt einige Operatoren beispielhaft vor und zeigt an ihnen auf, welche Möglichkeiten sie dem Admin in Kubernetes eröffnen.
Kubernetes-Basiswissen
Möchte man verstehen, wie Operatoren sich in Kubernetes einfügen, befasst man sich idealerweise zunächst mit den grundlegenden Funktionsmechanismen, die dem Container-Orchestrierer zugrundeliegen. Kubernetes orientiert sich bei seinen internen Funktionen stark an Objekten, die sich wiederum in Typen aufteilen.
Im Prinzip ist ein Objekt immer eine maschinelle Anweisung an Kubernetes, die den vom Admin gewünschten Zustand der Installation beschreibt. Die Kombination verschiedener Objekttypen miteinander ermöglicht es, selbst komplexe Ziel-Setups im Kubernetes-Sprech zu beschreiben. Der Controller-Manager kümmert sich im Namen des Admins dann darum, die Realität dem Wunsch anzupassen: Er erstellt in Kubernetes das Setup, das der Admin in seinen Objektbeschreibungen vorgegeben hat.
Operatoren in Kubernetes folgen letztlich demselben Konzept. Sie setzen in den allermeisten Fällen aber nicht nur auf die Objekttypen, die Kubernetes ihnen vorgibt. Regelmäßig machen sie stattdessen von der Möglichkeit Gebrauch, eigene Objekttypen zu definieren. Die Kubernetes-API sieht das explizit vor: Unter dem Label der Custom Resource Definitions (CRD) lassen sich eigene Objekttypen nach festen Regeln definieren (Abbildung 1). Dann erzeugen sie auf Basis der neu geschaffenen Objekttypen eigene Objekte (Abbildung 2), um die der Controller-Manager sich im Nachgang ebenso kümmert wie um die nativen Objekte in Kubernetes.
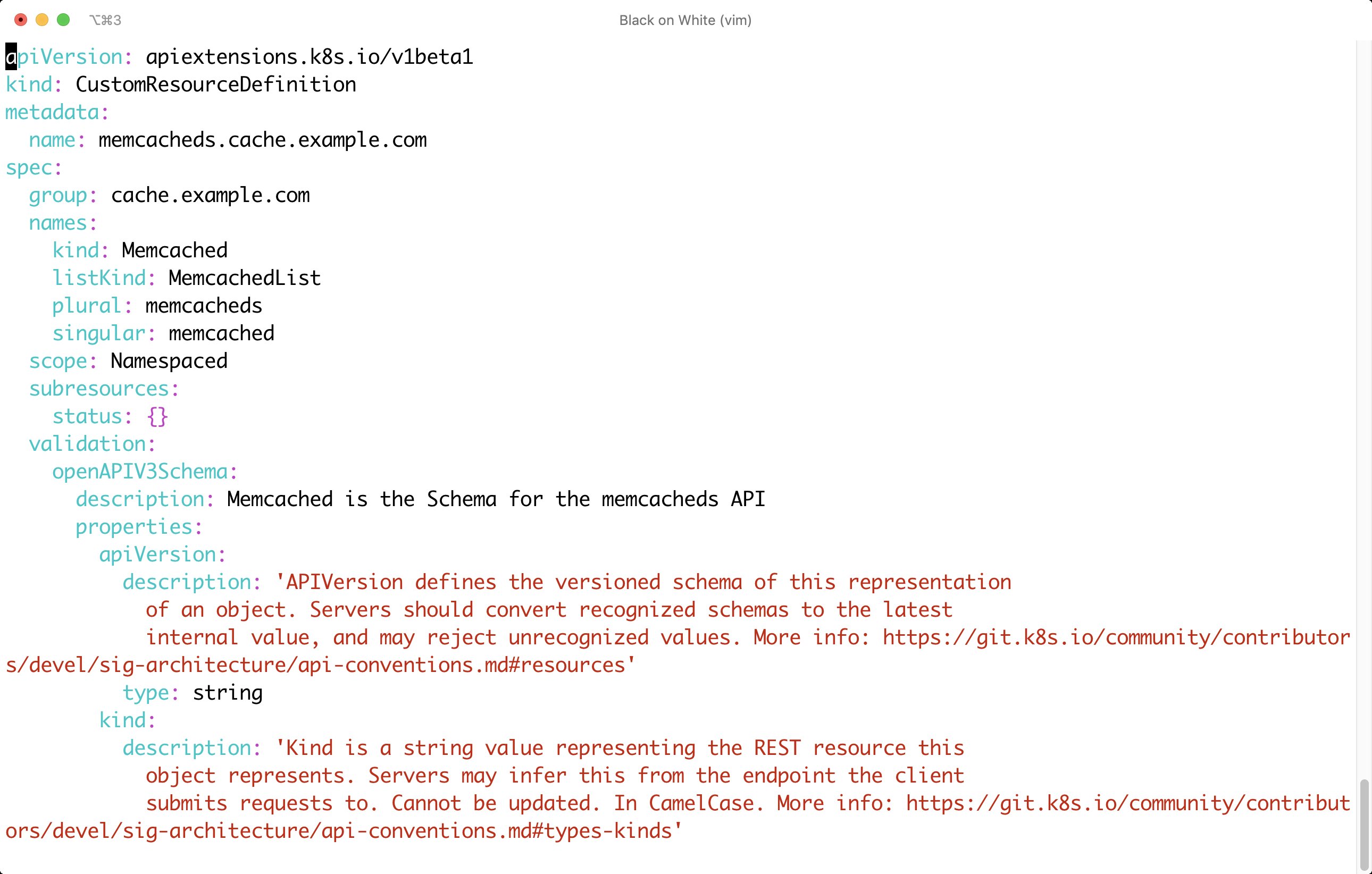
Abbildung 1: Operatoren in Kubernetes nehmen dem Admin Arbeit ab. Einer ihrer Hauptbestandteile ist eine Custom Resource Definition (CRD).
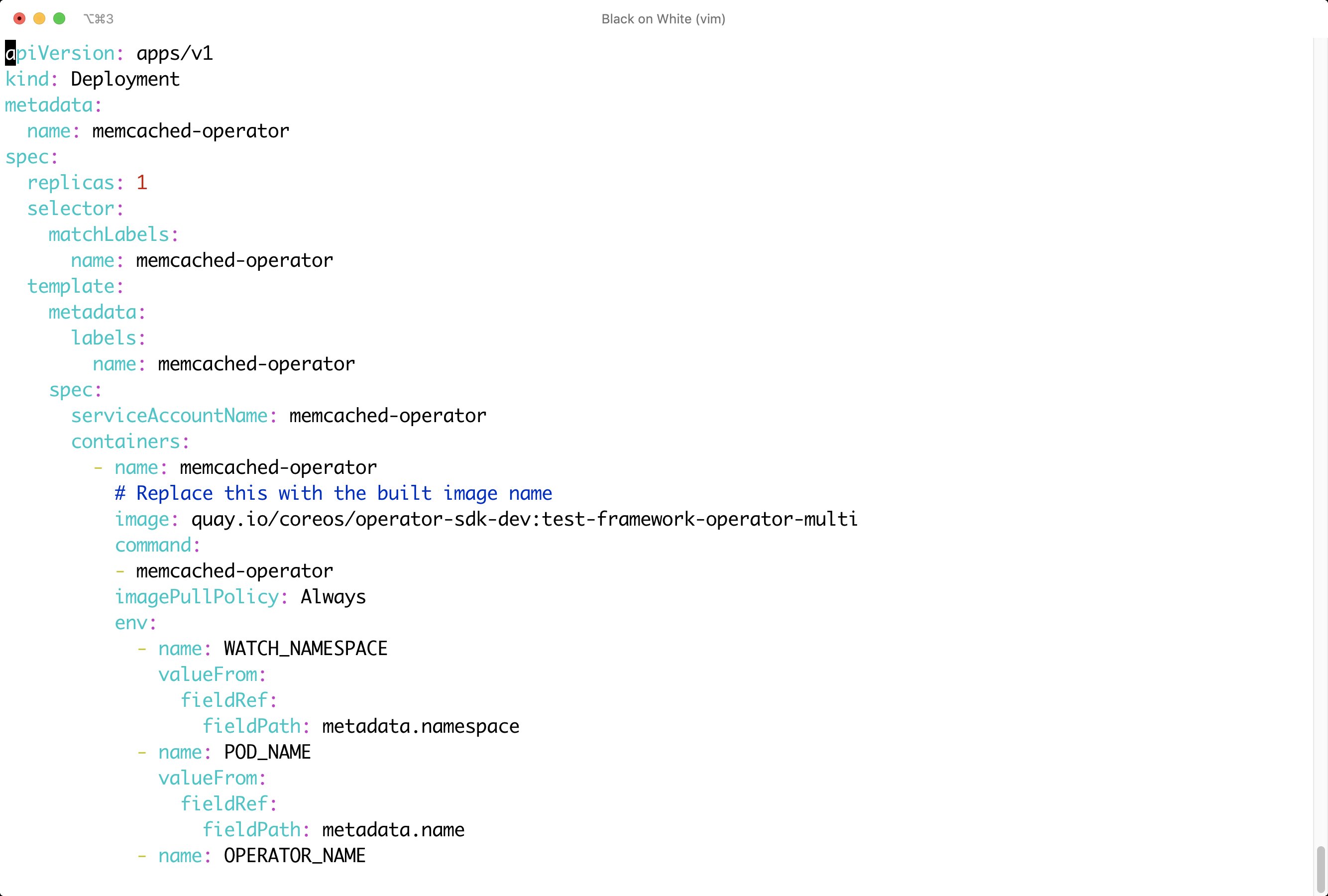
Abbildung 2: Eine Liste von Objekten, die auf Basis CRD zu erstellen sind, gehört ebenso zum Operator.
Wachsames Auge
Operatoren leisten allerdings noch mehr. Hinterlegt ein Operator eine CRD in Kubernetes, beinhaltet diese in aller Regel den Watch-Parameter. Der sieht die Möglichkeit vor, alle Objekte eines bestimmten Typs zentral zu überwachen. Treten bei den überwachten Objekten bestimmte, in der CRD definierte Ereignisse ein, fungieren diese für den Operator als Trigger. Im Regelfall legt er dann weitere Ressourcen an, konfiguriert zusätzliche Ressourcen oder rollt andere Kubernetes-Objekttypen aus, wie Replica-Sets.
Editiert der Admin eine Custom-Ressource später, sorgt der Operator dafür, dass die Änderungen automatisch an alle Unterobjekte durchpropagiert werden. Ein einmal sinnvoll verfasster Operator mit CRDs entfaltet durch diese Technik große Wirkung: Er kann auf diverse Vorkommnisse automatisch reagieren und die virtuelle Container-Umgebung so robuster und effizienter machen.
Operatoren, ganz praktisch
Was in der Theorie etwas sperrig klingt, wird am praktischen Beispiel leicht greifbar. Man stelle sich einen Operator für die bereits erwähnte MySQL-Datenbank vor. MySQL stellt Kubernetes gleich vor mehrere Herausforderungen: Ab Werk ist das Datenbanksystem unter anderem nicht in der Lage, so in die Breite zu skalieren, dass ein echtes Multi-Knoten-Setup mit multiplen aktiven Instanzen gelingt. Dafür braucht es Galera, das – einmal auf MySQL aufgepropft – dieses Feature nachrüstet. Bis ein MySQL mit einem Galera allerdings läuft, fällt einige Konfigurationsarbeit an. Container dafür händisch zu konfigurieren, wäre eine mühselige, zeitraubende Aufgabe. Mit Operatoren wird sie aber lösbar, denn sie sind genau darauf ausgelegt.
Im ersten Schritt würde der Admin in Kubernetes die Definition von Custom Resources hinterlegen, etwa eine CRD für laufende MySQL-Instanzen mit aufgepfropftem Galera-Modul. Die CRD würde umfassen, dass es Replica-Sets für MySQL ebenso anzulegen gilt wie eine entsprechende knotenbasierte Konfiguration. Auch Objekte, die der Verifikation dienen, lassen sich auf diese Art und Weise implementieren.
Der zweite Schritt auf dem Weg zum Operator besteht darin, Ressourcen auf Basis der CRD zu erstellen. Wer nur die CRD in Kubernetes einspielt, gibt sie der API zwar mit auf den Weg, setzt sie aber nicht praktisch um. Erst durch das Erstellen der entsprechenden Objekte erwachen die Ressourcen zum Leben – entstehen also Container mit MySQL und Galera so, wie der Admin es in seinem Operator vorgegeben hat.
Die Reconciliation: Totale Überwachung
Die allermeisten Operatoren enthalten, wie beschrieben, eine Watch-Anweisung für die Objekttypen (Abbildung 3), die sie selbst erstellen. Ändern sich diese Objekte, schickt der Controller-Manager in Kubernetes dem jeweiligen Operator eine entsprechende Notiz. Der Operator ist dafür zuständig, den Soll-Zustand mit dem Ist-Zustand abzugleichen und gegebenenfalls Alarm zu schlagen. Dieser Alarm würde den Controller-Manager letztlich dazu bringen, Änderungen vorzunehmen, um Soll und Ist wieder in Einklang zu bringen. Der gesamte Vorgang nennt sich im englischen Kubernetes-Jargon Reconciliation.

Abbildung 3: Mit Watch-Objekten überwacht der Controller-Manager in Kubernetes den Zustand eines Setups automatisch.
Eine große Stärke des Operator-Frameworks besteht darin, dass die zahlreichen Abschnitte des Lebenszyklus einer Applikation sich mit verschiedenen Tools in Operatoren abbilden lassen. Die Reconciliation kann etwa in Go implementiert sein, aber ebenso gut dürfen Operatoren zum Umsetzen ihrer Ziele auch auf erprobte Automatisierer wie Ansible zurückgreifen.
Das kommt insbesondere jenen Admins entgegen, die in Go nicht sattelfest sind und werden möchten – zumal Go nicht ganz trivial ist. Die einfachste Methode, Operatoren zu schreiben, dürfte aktuell tatsächlich Ansible bieten: Dessen Rollen dokumentieren sich nicht nur selbst, sie folgen auch einer einfachen Syntax. Obendrein ist Ansible hervorragend dokumentiert.
Ähnlichkeiten und Unterschiede zu Helm
Gelegentlich begegnet man im Kubernetes-Kontext der Behauptung, dass in den meisten Fällen das Paketieren eines Containers mit Helm ausreiche und Operatoren eigentlich überflüssig seien. Diese Aussage übersieht allerdings einen elementaren Unterschied zwischen den Ansätzen.
Helm-Charts definieren lediglich einen Ist-Zustand, der bei Einspielen eines Charts einmalig herbeizuführen ist. Alle Parameter einer Helm-Definition sind determiniert, Abweichungen vom Helm-Standardprozess für das Ausrollen von Containern nicht vorgesehen. Insofern vermag Helm auch nicht mit der von ihm verwalteten Applikation zu interagieren. Das wiederum führt dazu, dass sich manche Applikationen mit Kubernetes erst gar nicht verwenden lassen.
Auch hierfür ist MySQL mit Galera ein gutes Beispiel. Die Lösung hat einen etwas spezielleren Setup-Prozess: Auf dem ersten Knoten eines Clusters startet der Admin MySQL und Galera im Bootstrap-Modus, der anzeigt: Hier entsteht ein neuer Cluster. Weitere Cluster-Nodes starten mit der normalen Konfiguration eines Galera-Knotens.
Krux Nummer 1: Fällt der ursprüngliche Bootstrap-Knoten eines Galera-Clusters aus und wird neu gestartet, muss er auf die Konfiguration des Bootstrap-Modus verzichten – sonst würde er einen neuen Cluster starten. Krux Nummer 2: Geht der gesamte Galera-Cluster offline, fällt der Bootstrap-Mechanismus erneut an – aber eben nur auf dem ersten Knoten.
Mittels eines individuell gebauten Operators lässt sich dieser Zirkus gut abbilden; mit Helm wäre das praktisch unmöglich. Um zu verdeutlichen, was mit dem oben erwähnten operativen Wissen gemeint ist, eignet sich dieses Galera-Beispiel also hervorragend.
Red Hat im Operatoren-Fieber
Red Hat hat sich in den vergangenen Jahrzehnten einen Namen damit gemacht, jedes Konzept, das die Firma besonders überzeugt, mit aller Konsequenz zu verfolgen. Bei Containern ist das zweifelsohne der Fall: Während man den OpenStack-Hype vor ein paar Jahren jovial verschlief und erst später groß in OpenStack einstieg, waren die roten Hüte in Sachen Container von Anfang an dabei.
Der Kauf von CoreOS im Jahr 2018 sorgte dafür, dass diverse hippe Technologien in den Schoß von Red Hat wanderten, eben auch die von CoreOS erfundenen Operatoren. Entsprechend offensiv bewirbt Red Hat Operatoren in Kubernetes – und gibt sich zudem größte Mühe, rund um das Operatoren-Angebot von OpenShift quasi ein eigenes Ökosystem zu bauen. OpenShift ist bekanntlich Red Hats eigene Kubernetes-Distribution, und die Marschrichtung scheint klar zu sein: Mit Operatoren möchte man auch jene Admins von Containern und Kubernetes auf den Geschmack bringen, die die Technik bisher für Teufelszeug hielten.
Ein Element von Red Hats Charme-Offensive für Operatoren ist der vom Unternehmen als Container Hub bezeichnete Dienst. Dabei handelt es sich um eine Art öffentlichen Marktplatz für Operatoren, und der Anbieter lädt jeden herzlich zur Mitarbeit ein. Freilich weiß auch Red Hat, dass sich eine Community auf solch einer Plattform nur bildet, wenn es schon einen Grundstock funktionaler Werkzeuge gibt. Deshalb steuert das Unternehmen kurzerhand gleich einige Operatoren für beliebte Programme bei und ermöglicht so den Betrieb einer Vielzahl bekannter Applikationen in Kubernetes – und dadurch auch in OpenShift (Abbildung 4).
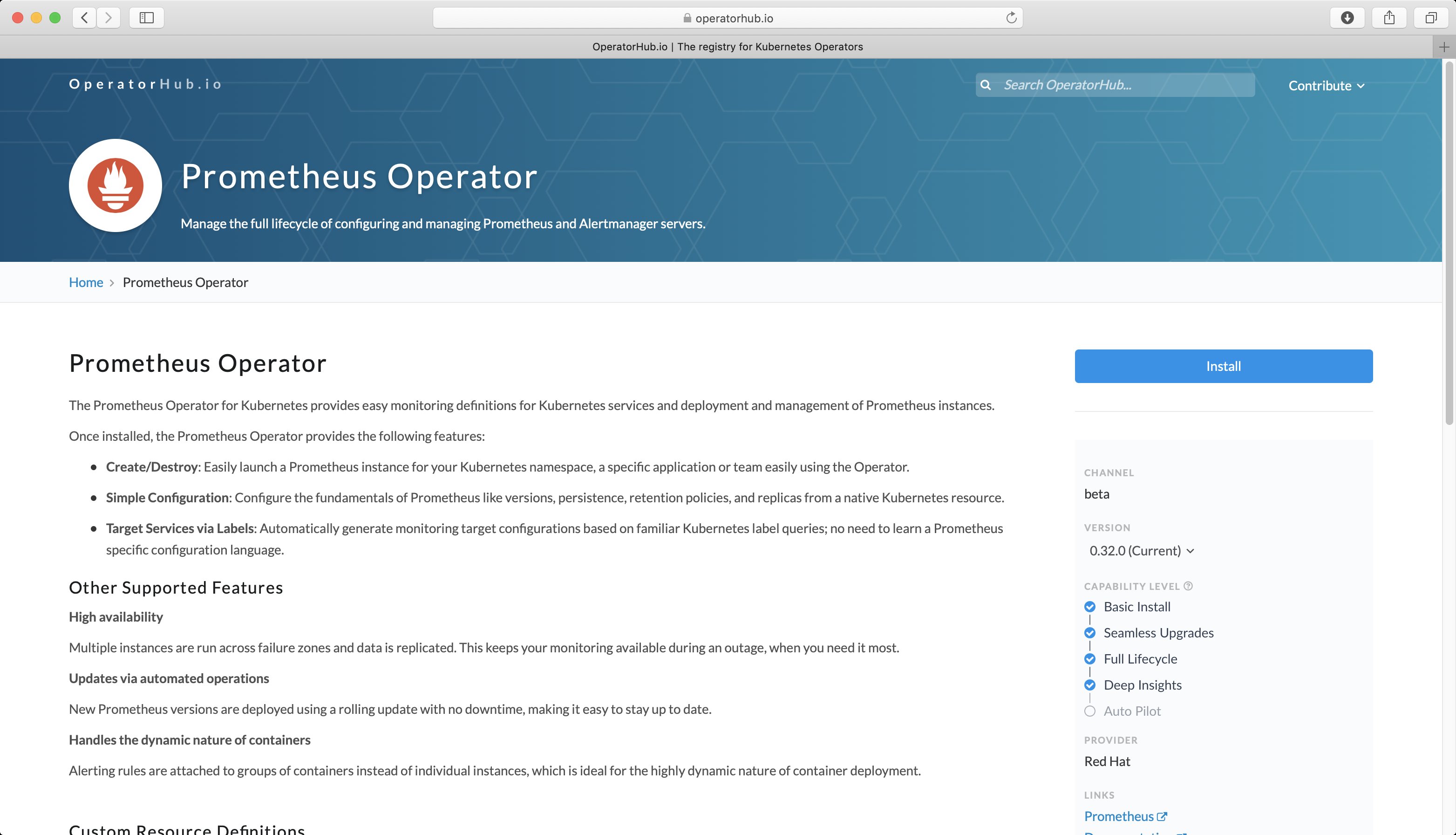
Abbildung 4: Der Operator Hub listet von Red Hat handverlesene Operatoren auf, die viele gängige Programme in Kubernetes abdecken.
Das Monitoring-Werkzeug Prometheus
Ein typisches Beispiel dafür ist Prometheus. Das Programm kümmert sich bekanntlich um Monitoring, Alerting und Trending. Aus Kubernetes-Sicht stellt es vor allem deshalb eine Herausforderung dar, weil es eine eigene Datenbank mitbringt, die Stateful-Daten enthält. Mit einem Schlag hat der Admin dadurch die Themen Replikation, Redundanz und Skalierbarkeit auf der Storage-Ebene am Hals. Würde man das mit bestehenden Kubernetes-Operatoren implementieren wollen, wäre das zumindest mühsam – und letztlich nicht zufriedenstellend zu erreichen.
Red Hat eilt dem leidgeplagten Prometheus-Admin deshalb per Operator zur Seite und liefert einen Vorschlag zur Lösung des Problems [1]. Hier wird schnell deutlich, dass auch Operatoren mit einiger impliziter Komplexität daherkommen, die es aus Sicht des Admins erst einmal zu meistern gilt. So zeigt Red Hat in seinem Operator Hub deutlich an, was zu einem Operator alles dazugehört: Im Prometheus-Beispiel sind das gleich fünf CRDs für ganz verschiedene Aufgaben.
Eine startet und betreibt Prometheus selbst, eine zweite konfiguriert Alarm- und Metrikdatenregeln für den Dienst. Eine dritte CRD ermöglicht es, Kubernetes-Dienste anhand festgelegter Regeln automatisch durch das in Kubernetes betriebene Prometheus zu überwachen. In dasselbe Horn stößt der Pod-Monitor, der nicht spezifische Dienste überwacht, sondern ganze Pods. Die letzte CRD des Prometheus-Operators widmet sich dem Alert-Manager, über den Prometheus verkündet, wenn etwas nicht so läuft, wie es im Normalfall soll.
Qualitätsangabe in fünf Stufen
Praktisch im Operator Hub ist, dass Red Hat den Reifegrad eines Pods anhand eines fünfstufigen Systems angibt. Die jeweils nächsthöhere Stufe umfasst dabei auch den Funktionsumfang sämtlicher Stufen unter ihr.
Basic Install kennzeichnet Operatoren, die nur grundsätzliche Funktionalität liefern. Nimmt ein Operator automatisch Updates der ihm unterstellten Ressourcen vor, erreicht er die Stufe Seamless Upgrades. Überwacht er den Lebenszyklus einer Applikation, fällt er in die Full-Lifecycle-Kategorie. Die umfasst daneben auch die Fähigkeit, einzelne Teile einer Applikation automatisch redundant zu machen und neu zu starten, falls Hosts ausfallen und Dienste fehlen.
Deep Insights, die vierte Stufe, bietet zusätzlich umfassende Metrikdatenhaltung zu einem bestimmten Dienst, wie die Auswertung von Lastanalysen und dergleichen. Den Ritterschlag erhält ein Operator durch die Auto-Pilot-Auszeichnung: Mit diesem Label versehene Operatoren funktionieren weitestgehend autark, wenn der Admin sie einmal installiert und die passenden Ressourcen angelegt hat.
Große Auswahl
Dafür, dass es den Operator Hub noch gar nicht so lange gibt, besticht die von Red Hat dort feilgebotene Menge an Möglichkeiten durchaus. Einen Operator für den Percona XtraDB Cluster (im Wesentlichen MariaDB samt Galera) stellt etwa Percona selbst im Reifegrad Full Lifecycle zur Verfügung.
Wer auf der Suche nach einer Alternative zu Slack oder Hipchat ist, findet Mattermost, das Mattermost selbst in der Stufe Seamless Upgrades bereitstellt. Daneben reihen sich verschiedene Datenbanken wie MongoDB, CouchDB oder Cassandra in die Liste der fertigen Operatoren ein; auch PostgreSQL und Redis sind abgedeckt.
Wer ein Ceph in Kubernetes betreiben möchte, nutzt den von den Rook-Entwicklern angebotenen Rook-Ceph-Operator, der immerhin die Stufe Full Lifecycle erreicht. Bei Redaktionsschluss standen nicht weniger als 110 Operatoren online zur Verfügung. Bei Erscheinen des Hefts dürfte die Zahl schon wieder gestiegen sein, denn der Operator Hub entwickelt sich prächtig – auch zur Freude von Red Hat.
Weitere Quellen im Netz
Allerdings haben nicht alle verfügbaren Operatoren ihren Weg in den Operator Hub von Red Hat gefunden. Im Github-Verzeichnis des Operator-Frameworks findet sich deshalb eine Liste [2] guter Operatoren außerhalb des Hubs (Abbildung 5).
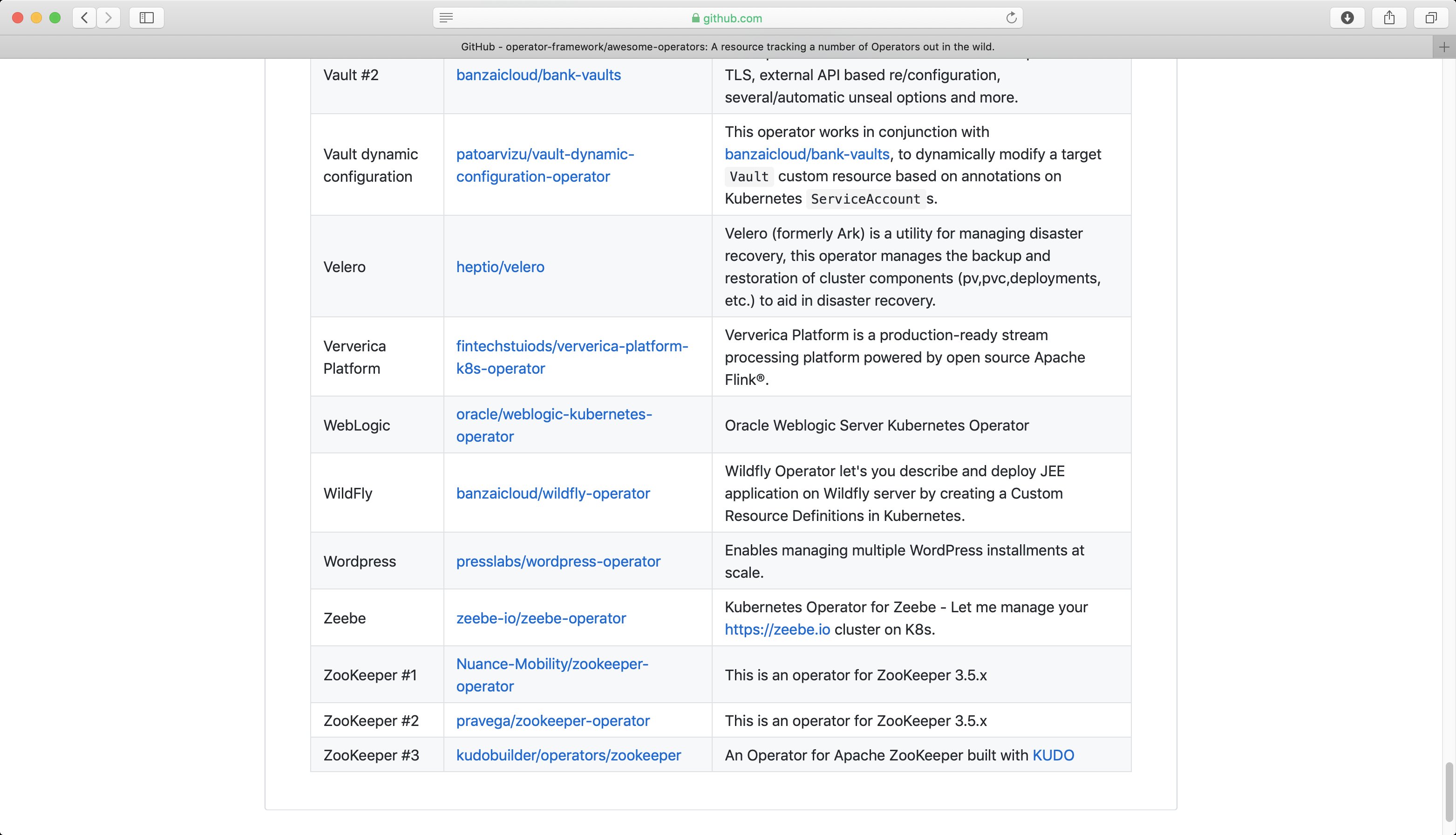
Abbildung 5: Auch außerhalb des Operator Hub finden sich viele Operatoren für bekannte Tools wie WordPress, die dem Admin bei Bedarf sehr nützlich werden.
Auch hier gibt es einige Hochkaräter: Die verteilten Konsensmechanismen Consul und Etcd gehören im Container-Umfeld beinahe schon zur Grundausstattung. Wer den Prometheus-Operator aus dem Operator Hub nutzt, findet auf Github gleich den passenden Grafana-Operator dazu, der die Daten aus Prometheus aufbereiten und grafisch darstellen kann. Memcached, die AI-Bibliothek Tensorflow und das CMS WordPress lassen sich über die verlinkten Operatoren ebenfalls schnell an den Start bringen.
Dabei machen verschiedene Faktoren klar, dass es sich bei Operatoren eben keineswegs nur um vorbereitete Container-Images handelt. Gerade der operative Kleber, der den Container-Images meist beiliegt, dient hier als das, was im Business-Sprech so schön Unique Selling Proposition heißt. Container-Images zu bauen ist schließlich nicht sonderlich kompliziert; die operativen Bedürfnisse der in Container verpackten Apps abzubilden hingegen sehr.
Operatoren für Selbermacher
Braucht man einen Operator für weniger bekannte Produkte oder für selbst verfasste Software, findet sich im Operator Hub dafür vermutlich kein brauchbarer Operator. Kein Grund zur Panik: Wer ein paar Brocken Go beherrscht oder zu lernen bereit ist, findet in Form des Operator-SDKs ein äußerst praktisches Helferlein.
Das SDK versorgt den Admin einerseits mit einfachen Vorlagen für das Erstellen von Operatoren und liefert andererseits viele Beispiele sowie eine gute Dokumentation zu deren Verwendung. Der zum SDK gehörende Arbeitsablauf folgt dabei immer demselben Schema: Zunächst erstellt der Admin die benötigten Beschreibungen für die CRDs und die Objekte, die daraus entstehen. Dann entstehen die Watch-Anweisungen und die Reaktionen, die beim Eintreten bestimmter Ereignisse greifen sollen. Wie schon erwähnt, unterstützt das Operator-Framework hier eine Vielzahl von Technologien, um die Watch-Anweisungen zu implementieren, etwa Go oder Ansible.
Hat der Admin seine Watch-Anweisungen in Code gegossen, geht es mit dem Bau der möglicherweise benötigter Container-Abbilder weiter. Zu guter Letzt konstruiert das SDK aus allen Elementen einen fertigen Operator, der sich auf Kubernetes-Clustern per Operator-Framework betreiben lässt.
Viel Licht, etwas Schatten
In Summe stellt sich das von CoreOS erfundene Operator-Framework für Kubernetes als äußerst nützlich für Admins heraus, die in ihren Kubernetes-Setups schnell brauchbare Resultate erreichen wollen. Logisch, dass gerade Red Hat bei quasi seinem gesamten Kubernetes-Workload in OpenShift auf Operatoren setzt: OpenShift erledigt ab Werk mittlerweile fast alles per Operator, um möglichst viele Fehlerquellen auszuschließen. Denn auch das ist ein äußerst nützlicher Nebeneffekt von Operatoren: Standardisierung und Automation eliminieren Fehlerquellen und erhöhen die Zuverlässigkeit.
Das schmeckt allerdings nicht jedem in der Community. Einzelne Kritiker monieren, durch den flächendeckenden Einsatz von Operatoren ginge faktisch Flexibilität verloren, man zwinge Admins also in ein relativ enges Korsett. Der Widerspruch lässt sich nicht sinnvoll auflösen: Was die einen als Hauptverkaufsargument betrachten, ist für die anderen Kernpunkt der Kritik. Nun muss man freilich Operatoren in OpenShift nicht nutzen, wenn man nicht möchte, wie in jeder anderen Kubernetes-Distribution auch. Wer sich auf diesen Weg begibt, bekommt allerdings viel Funktionalität und erspart sich einiges an Entwicklungsarbeit und operativem Aufwand. (jcb)
Infos
-
Operator Hub: https://operatorhub.io/
-
Operatoren außerhalb des Hubs: https://github.com/operator-framework/awesome-operators





