
© Michael Hirschka, Pixelio
Statt hochgezüchteter Prozessoren helfen oft schon simple Tricks, um Programme zu beschleunigen. Profiler können Engpässe entdecken, in die es sich lohnt, Entwicklungszeit zu investieren.
Wer nicht den ganzen Tag mit Videospielen verplempert, kommt auch ohne die allerschnellste CPU klar und spart so nicht nur Hardwarekosten, sondern auch noch Strom und schont die Umwelt. Sollte ein Perl-Programm dann doch zu betulich zu Werke gehen, lässt es sich meist mit geringem Aufwand durch Optimierung des Code an entscheidenden Stellen beschleunigen. Meist reichen ein, zwei gezielte Eingriffe, um 90 Prozent der überhaupt möglichen Verbesserungen zu erzielen. Die restlichen 10 Prozent erfordern oft weitreichende architektonische Umbauarbeiten, die zehnmal so lange dauern und anschließend die Wartung erschweren, sodass erfahrene Entwickler dankend abwinken.
Flaschenhälse zuerst
Die Bottlenecks oder Hot Spots finden Profiler. Sie zeigen, wo ein Programm die meiste Zeit verbringt, und erlauben es dem Entwickler, solche Bereiche gezielt zu verbessern. Perl hat etliche Tools für diesen Zweck in seiner Werkzeugkiste. Setzt ein Modul beispielsweise das Logging-Framework Log4perl ein, ist es einfach, verstrichene Sekunden zusammen mit den Lognachrichten anzuzeigen und so einen zeitlichen Überblick zu erhalten.
Das simple Testskript »amzntest« (Listing 1) holt zum Beispiel mit Hilfe des CPAN-Moduls Net::Amazon Buchinformationen über das Web-API bei Amazon ab. (Sofern im Skript ein gültiges Token eingetragen ist, das es bei [2] gibt.) Ein Request dauert ungefähr eine Sekunde. Aber wo genau verbrät das Skript diese Zeit? Schon beim Einholen der Daten oder erst während der anschließenden XML-Analyse? Ein am Kopf des Skripts eingefügtes
use Log::Log4perl;
Log::Log4perl->init("timer.l4p");
aktiviert das in Net::Amazon eingebettete Log4perl-Framework und lädt die Konfigurationsdatei »timer.l4p«, derzufolge zu jeder geloggten Nachricht auch noch das Datum (»%d«) sowie die Zahl der verstrichenen Millisekunden seit dem Programmstart (»%r«) auszugeben ist. Da der Loglevel mit »DEBUG« relativ hoch und damit die ausgegebenen Nachrichten recht lang sein können, definiert Listing 2 auch noch einen so genannten Custom Cspec mit dem Kürzel »%S«.
Dieser erscheint dann statt des sonst üblichen »%m« (für die Lognachricht) im Layout und schickt eine auf 25 Zeichen verkürzte Nachricht an den Screen-Appender. Das Layout schließt mit einem plattformunabhängigen Newline-Zeichen ab, das als »%n« erscheint.
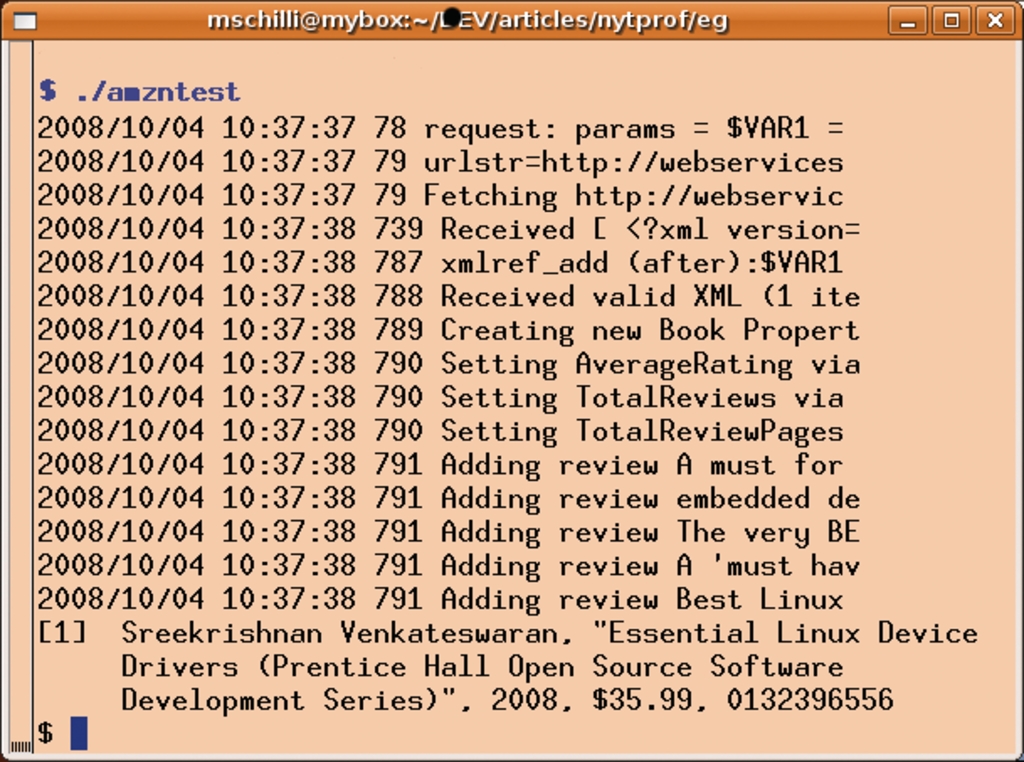
Abbildung 1: Log4perl gibt die Uhrzeit und die verstrichenen Millisekunden seit dem Programmstart an.
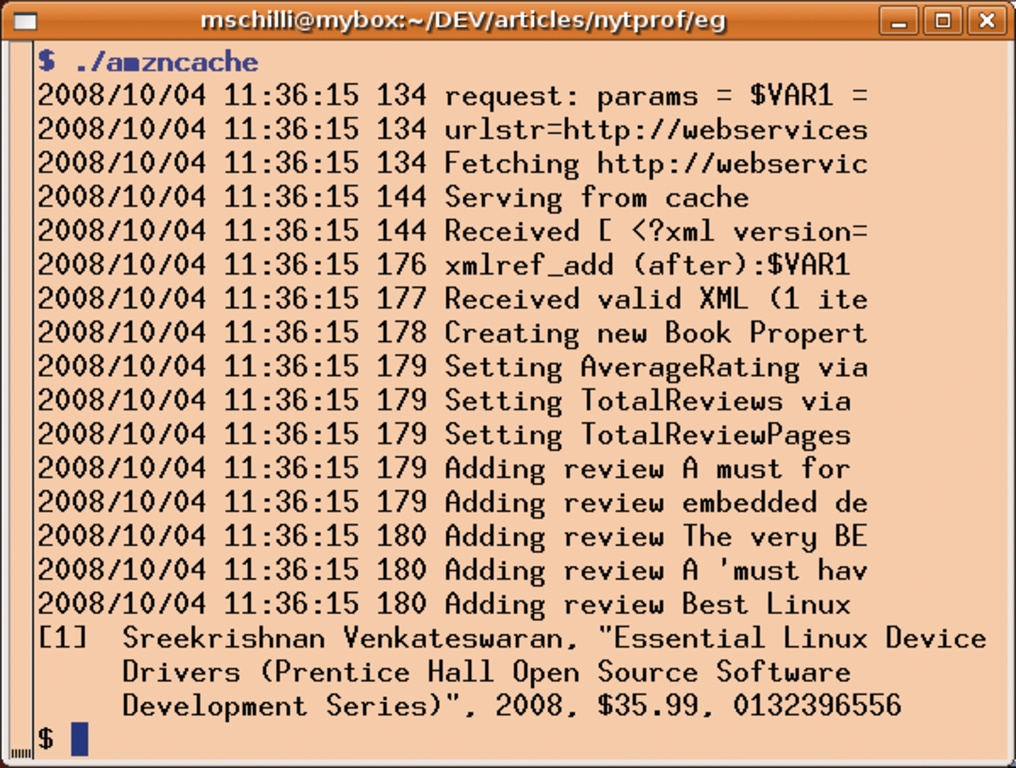
Abbildung 2: Bei einem eingesetzten Webcache entfällt der Webrequest für Wiederholer, das reduziert die Laufzeit um 75 Prozent.
Abbildung 1 zeigt, dass Net::Amazon bereits 79 Millisekunden nach dem Programmstart einen Webrequest an Amazon absetzt, der XML-Parser aber erst zum Zeitpunkt 739 Millisekunden seine Arbeit beginnt. Von den insgesamt vom Skript verbrauchten 800 Millisekunden nimmt also 75 Prozent der Webrequest in Anspruch.
|
Listing 1: |
|---|
01 #!/usr/bin/perl
02 use warnings;
03 use strict;
04 use Net::Amazon;
05 use Net::Amazon::Request::ASIN;
06
07 my $asin = "0132396556";
08
09 my $ua = Net::Amazon->new(
10 token => 'XXXXXXXXXXXXXXX',
11 );
12
13 my $req = Net::Amazon::Request::ASIN->new(
14 asin => $asin,
15 );
16
17 my $resp = $ua->request($req);
18
19 if($resp->is_success()) {
20 print $resp->as_string(), "n";
21 } else {
22 print "Error: ",
23 $resp->message(), "n";
24 }
|
|
Listing 2: |
|---|
1 log4perl.logger = DEBUG, App
2 log4perl.appender.App = Log::Log4perl::Appender::Screen
3 log4perl.appender.App.layout = PatternLayout
4 log4perl.appender.App.layout.ConversionPattern = %d %r %S%n
5 log4perl.PatternLayout.cspec.S = sub { substr($_[1], 0, 25) }
|
Schneller Fix
Folglich bietet es sich an, für häufig eingeholte ASIN-Nummern einen Cache einzusetzen, den Net::Amazon – wie Listing »amzncache« (Listing 3) zeigt – standardmäßig unterstützt. In der Tat reduziert sich die Skriptlaufzeit mit File::Cache als persistentem Zwischenspeicher bei Wiederholern auf 180 Millisekunden, wie in Abbildung 2 zu sehen.
|
Listing 3: |
|---|
01 use Cache::File; 02 my $cache = Cache::File->new( 03 cache_root => '/tmp/mycache', 04 default_expires => '30 min', 05 ); 06 07 my $ua = Net::Amazon->new( 08 token => 'XXXXXXXXXXXXXXX', 09 cache => $cache, 10 ); |
|
Listing 4: |
|---|
01 #!/usr/local/bin/perl -w
02 use strict;
03
04 use Log::Log4perl qw(:easy);
05 Log::Log4perl->easy_init($INFO);
06
07 for(1..100_000) {
08 DEBUG "waah!";
09 }
|
Nun lässt sich freilich argumentieren, dass derlei Tricks nicht immer möglich sind. Aber entscheidend ist doch, dass fünf Zeilen Code und eine Minute Nachdenken eine Geschwindigkeitsverbesserung um den Faktor 4 erzielen.
Line-Profiler »SmallProf«
Nicht jedes Modul verfügt über derlei ausgeklügelte Loggingmechanismen, deswegen steht in Perl eine Reihe von Profilern zur Verfügung, die messen, welche Sourcecode-Zeile wie viel Zeit verbrät. Tabelle 1 zeigt die wichtigsten CPAN-Profiler, aufgeschlüsselt nach Funktionen und Entstehungsjahr.
|
Tabelle 1: |
|
|---|---|
|
Name |
Jahr |
|
Subroutine-Level-Profiler |
|
|
Devel::DProf |
1995 |
|
Devel::AutoProfiler |
2002 |
|
Devel::Profiler |
2002 |
|
Devel::Profile |
2003 |
|
Devel::DProfLB |
2006 |
|
Devel::WxProf |
2008 |
|
Statement-Level-Profiler |
|
|
Devel::SmallProf |
1997 |
|
Devel::FastProf |
2005 |
|
Devel::NYTProf |
2008 |
|
Devel::Profit |
2008 |
Der Line-Profiler Devel::SmallProf vom CPAN ermittelt selbstständig die Laufzeiten und formatiert die Daten anschließend für eine Analyse. Das zu messende Skript startet der Admin mit »perl -d:SmallProf ./amzn« und der Profiler erzeugt die Datei »smallprof.out«, die zu jeder Zeile in jedem benutzten Modul die verstrichene Zeit angibt. Bei einem recht komplexen Vorgang wie einem Webrequest und anschließender XML-Analyse der zurückkommenden Daten nimmt diese Datei natürlich monströse Ausmaße an, im vorliegenden Fall ist sie glatt 25792 Zeilen lang.
Schlimmste Zeitfresser
Es ist gar nicht so einfach, die schlimmsten Zeitfresser herauszufinden. Aber das Shellkommando
sort -k 2,2 smallprof.out | less
sortiert die Datei nach dem zweiten Feld von links, und zwar numerisch. Dort stehen die von einer Sourcecode-Zeile in Anspruch genommenen Wall-Time-Sekunden, also die tatsächlich verstrichene Zeit, egal ob die Task aktiv CPU beanspruchte oder nur untätig herumhing, weil sie auf externe Ereignisse wie eintrudelnde Netzwerkpakete warten musste. Zusätzlich enthält das dritte Feld auch noch die CPU-Sekunden, also die tatsächlich genutzte Rechenzeit.
Scrollt man dann, wie in Abbildung 3 zu sehen, in der Datei »smallprof.out« zur Zeile 17104, zeigt sich, dass die für das Warten verantwortliche Zeile einen »select«-Befehl absetzt. Die Funktion »can_read()« im Modul LWP::Protocol::http::SocketMethods ist dafür verantwortlich.
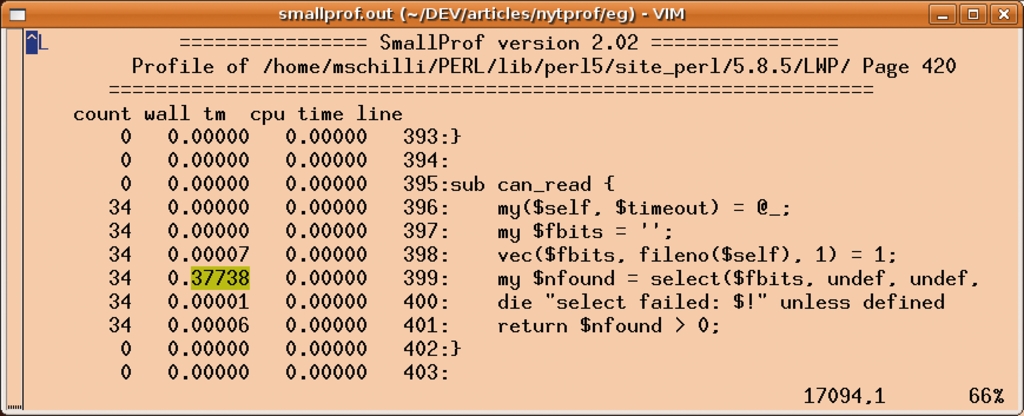
Abbildung 3: Die 25000 Zeilen lange Ausgabe von »SmallProf« enthüllt, dass das Warten auf den Amazon-Server die meiste Zeit in Anspruch nahm.
NYTProf
Eine relativ neue Entwicklung ist Devel::NYTProf vom CPAN. Der etwas merkwürdige Name rührt daher, dass das Modul im Auftrag der “New York Times” auf Grundlage der Codebasis von Devel::FastProf entstand. Die IT-Abteilung der Zeitung entschloss sich den Sourcecode freizugeben.
Dieser hervorragende Profiler wird heute von DBI-Erfinder Tim Bunce gepflegt, der ihn auf der OSCON 2008 der Perl-Community vorstellte. Im Publikum saß auch der Autor des Artikels, der allerdings unruhig auf seinem Hosenboden hin und her rutschte, da er gleich danach mit seinem Log4perl-Vortrag auf die Bühne musste!
Nach der CPAN-Shell-gestützten Installation mit »perl -MCPAN -e\’install Devel::NYTProf\’« ruft man den Profiler mit »perl -d:NYTProf amzn« auf und wandelt dessen binäre Logdatei »nytprof.out« mit dem ebenfalls beiliegenden Skript »nytprofhtml« in professionell formatiertes HTML um.
Wer anschließend einem Browser die Datei »index.html« im neu erzeugten Verzeichnis »nytprof« (URL: »file:///…nytprof/index.html«) übergibt, kann schön erkennen, was soeben ablief. Die Tabelle in Abbildung 4 listet die Hotspots auf. Sie zeigt die Anzahl der Aufrufe (Calls), die Zahl der Aufrufstellen (»P«, Places) und -dateien (»F«, Files) sowie die in der jeweiligen Funktion verstrichene Zeit. Hierbei unterscheidet sie zwischen »Exclusive Time« und »Inclusive Time«, wobei der erste Wert die ausschließlich im Code der Funktion verbrachte Zeit anzeigt und der zweite die Gesamtzeit einschließlich der von der Funktion aufgerufenen Unterfunktionen.
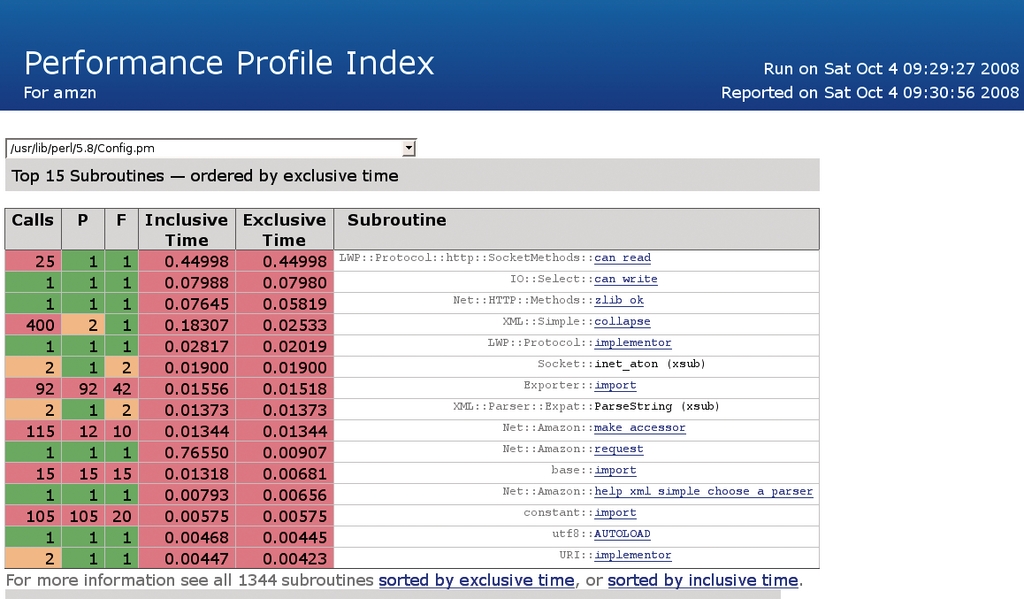
Abbildung 4: Der Profiler präsentiert übersichtlich die 15 Funktionen des gesamten Code, auf deren Konto die meiste Laufzeit geht. Das offenbart lohnende Angriffspunkte für Verbesserungen.
Analyse per Klick
Das HTML verlinkt Funktionsnamen praktischerweise mit weiteren HTML-Seiten, auf denen Details zum Funktionscode stehen. So kann der Anwender schnell hin und her manövrieren, was die Analyse erheblich vereinfacht. In Abbildung 5 ist zum Beispiel zu sehen, was mit »SmallProf« vorher nur mühsam ermittelt werden konnte, nämlich dass der »select«-Befehl in der Funktion »can_read()« eines LWP-Moduls für die Zeitverzögerung verantwortlich ist. Er lauscht auf einem offenen Network-Socket auf das erste Anzeichen der von Amazon eintrudelnden Antwort.
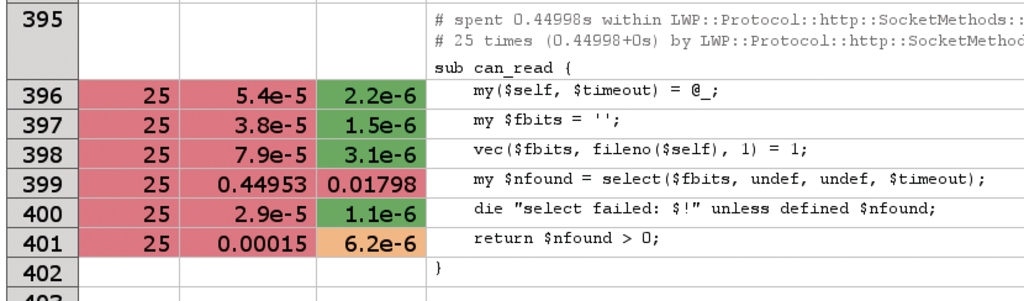
Abbildung 5: Das Select-Kommando im LWP-Code wartet auf eine Antwort von Amazon und zeichnet dadurch für einen Großteil der Programmlaufzeit verantwortlich.
NYTProf unterstützt drei verschiedene Report-Modi, um die verstrichene Zeit anzuzeigen, und zwar »line« (eine Zeitraumangabe pro Zeile), »block« (pro Perl-Block) und »sub« (pro Funktion). Per Mausklick schaltet der Performance-Detektiv zwischen den verschiedenen Displayvarianten hin und her.
Auch die in Abbildung 6 gezeigte Sicht des Profilers auf der Modulebene enthüllt interessante Tatsachen. Die XML-Analyse der Webantwort von Amazon nahm ganze 9963 Codezeilen und 400 Aufrufe der XML::Simple-Funktion »collapse()« in Anspruch! Da sie mit voller Geschwindigkeit liefen, war der Fall bereits in 35 Millisekunden erledigt, aber hier zeigt sich, wie aufwändig XML zu parsen ist.
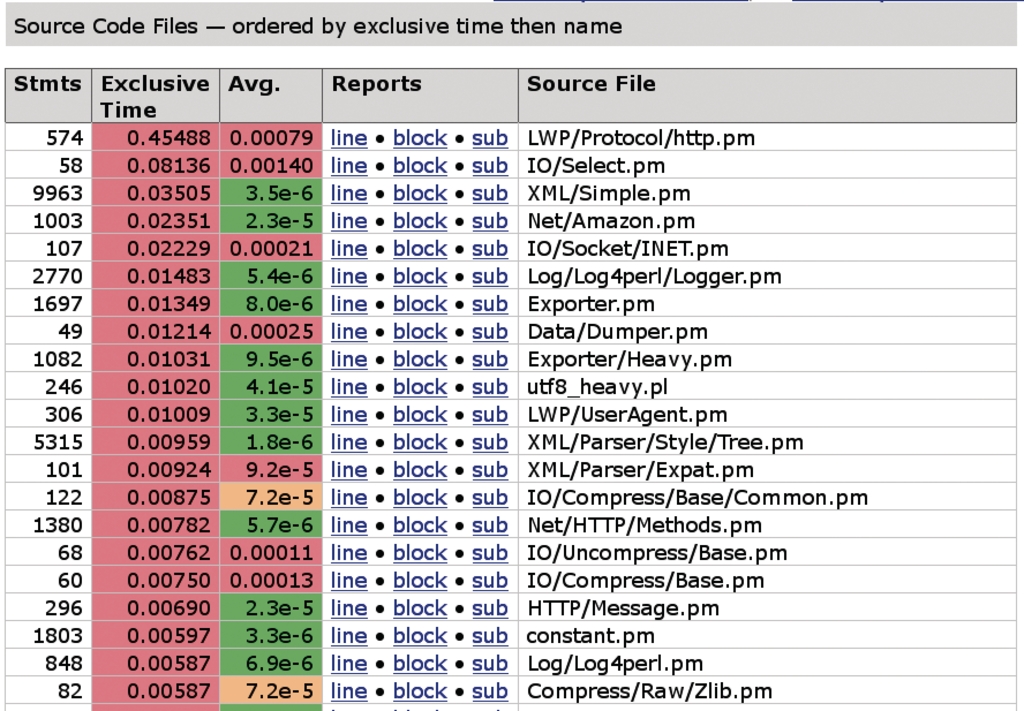
Abbildung 6: Die Modulebene zeigt an, wie viel Zeit der Code in welchem Modul verbrachte und wie viele Statements dort abgearbeitet wurden.
Wie jeder andere Profiler erzeugt auch Devel::NYTProf einen gewissen Overhead, der die Messergebnisse teils erheblich verfälscht. Besonders wenn ein Program nicht auf externe Ereignisse wartet, die um Größenordnungen langsamer sind, spielen die Aktivitäten des Profilers eine merkliche Rolle. Bei voller CPU-Geschwindigkeit kann sich die Programmlaufzeit mit dem eingeschalteten Profiler durchaus verzehnfachen.
Abbildung 7 zeigt zum Beispiel die Auswirkungen des NYT-Profilers auf das kurze Testprogramm »l4ptest« (Listing 4). Es konfiguriert Log4perl auf die Logpriorität »$INFO« und arbeitet dann Logbefehle der niedrigeren Priorität »$DEBUG« ab, die Perl naturgemäß allesamt unterdrückt. Log4perl hat diesen Fall stark optimiert, denn ein deaktiviertes Logsystem sollte keinen messbaren Einfluss auf die Software haben, in die es integriert ist. Ohne Profiler schafft das Skript dann auch 100000 Aufrufe in etwa 100 Millisekunden, aber mit aktiviertem NYTProf erhöht sich die Laufzeit auf mehr als das Zehnfache. Das tut der Qualität des Profilers keinen Abbruch, wichtig ist es nur, daran zu denken.
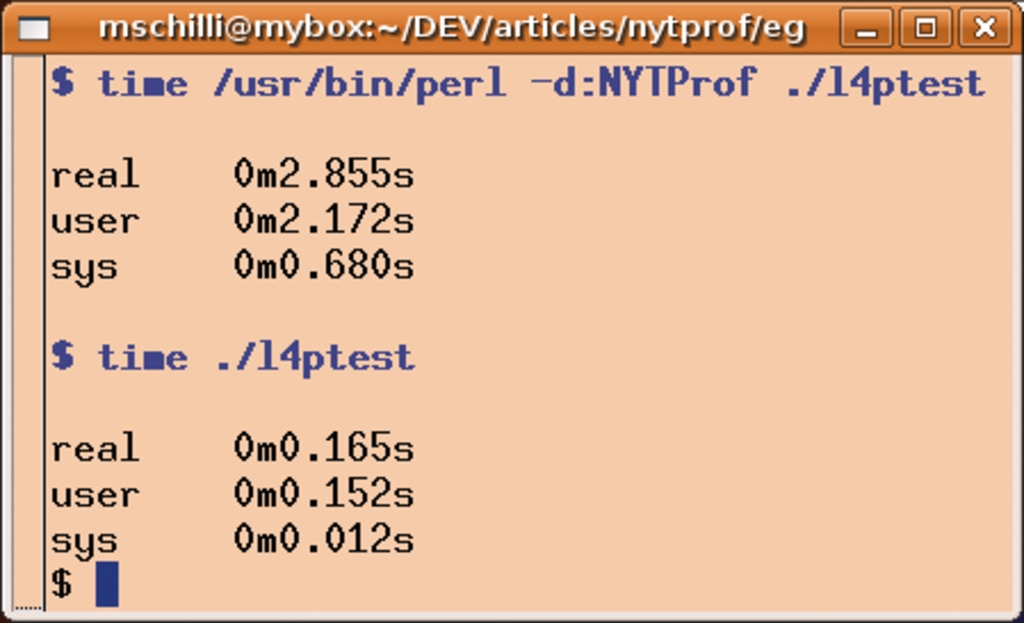
Abbildung 7: NYTProf verlangsamt schnelle Programme teilweise extrem.
Auch im Apache-Server unter »mod_perl« findet sich das Modul zurecht. Die Konfigurationszeile »PerlModule Devel:: NYTProf::Apache« lädt es und lässt es bei eingehenden Requests Profilerdaten an »/tmp/nytprof.$$.out« anhängen, wobei »$$« die PID des zuständigen Apache-Prozesses ist. Auch hier erzeugt das anschließend aufgerufene Skript »nytprofhtml« eine Kollektion von Webseiten, die die Performance des Webservers detailliert darstellen. (jcb)
|
Infos |
|---|
|
[1] Listings zu diesem Artikel: [ftp://www.linux-magazin.de/pub/listings/magazin/2008/12/Perl] [2] Amazon Web Service (Entwicklertoken abholen): [http://amazon.com/soap] [3] Tim Bunce, “NYTProf v2 – the background story”: [http://blog.timbunce.org/2008/07/16/nytprof-v2-the-background-story/] |
|
Der Autor |
|---|
|
|






