
© sattapapan-tratong, 123RF
Die Community-Edition von Datafari ist eine der wenigen kostenlosen Open-Source-Volltextsuchmaschinen, die sich ohne Programmierung sofort für den produktiven Einsatz eignen. Wenige Anpassungen genügen, um im gemeinsamen Artikelarchiv diverser Fachmagazine zu recherchieren.
Im Open-Source-Umfeld gibt es viele Komponenten, die sich für den Aufbau einer Volltextsuchmaschine eignen. Es erfordert aber einigen Aufwand, sie miteinander zu verkuppeln. Hier sieht das französische Startup France Labs seine Nische: Es hat die verstreuten Zutaten gesammelt und um eine Javascript-basierte Oberfläche nach Google-Vorbild ergänzt. Die erlaubt etwa eine Facettennavigation, Autovervollständigung und alternative Suche nach ähnlichen Begriffen.
Datafari [1] positioniert sich als zuverlässige, sichere und skalierbare Enterprise Search Engine. Die Entwickler greifen vorwiegend auf bewährte Apache-Technologie (Solr [2], Manifold CF [3], Zookeeper [4], Tomcat [5], Cassandra [6]) zurück. Zudem runden sie das Ganze durch PostgreSQL [7] und den ELK-Stack [8] (Elasticsearch, Logstash und Kibana [9]) ab. Letzterer hilft nicht direkt beim Suchen im Datenbestand, sondern implementiert eine Standardlösung, um analytische (Meta-)Daten zu gewinnen. Nicht zuletzt setzt die Lösung ein installiertes Java JRE ab Version 8 und Python 2.7 voraus.
Datafari liegt aktuell in Version 4.2 vor. Dabei gibt es neben einer freien Community-Ausgabe mehrere kostenpflichtige Varianten [10]. Diese ergänzen die reine Suche um Big-Data- und Security-Optionen, aber auch um Support. Dabei begrenzen sie aber auch die Menge der durchsuchbaren Dokumente, was für die Community-Variante nicht gilt.
Bunte Mischung
Die üppige Sammlung von Einzelkomponenten verwaltet der Admin mit mehreren grafischen Oberflächen aus unterschiedlichen Quellen. Entsprechend bunt und variantenreich fallen die Bedienelemente aus, mit denen er dabei hantieren muss. Trotzdem gelingt die Integration der Einzelprodukte letzten Endes bemerkenswert reibungslos (Abbildung 1).
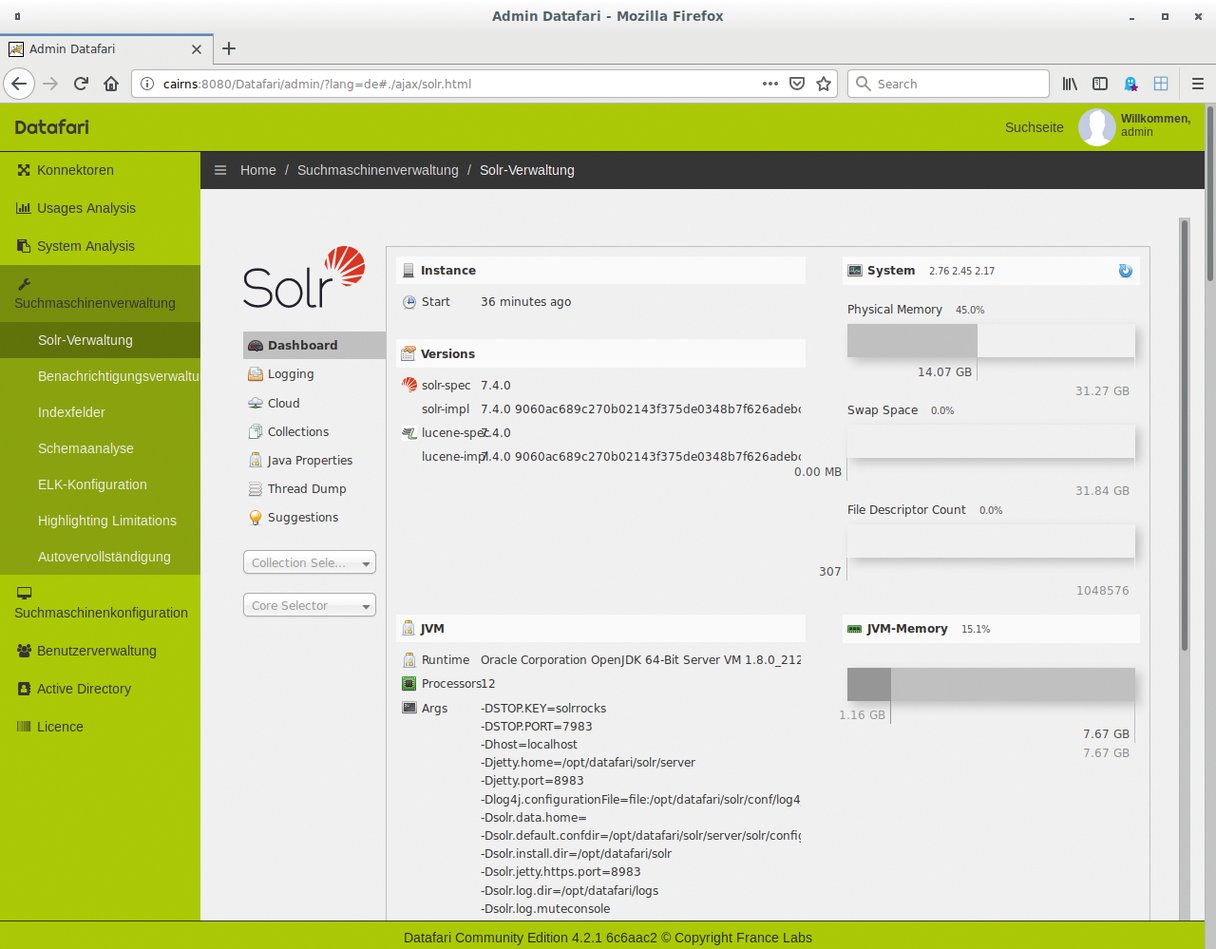
Abbildung 1: Datafari integriert auch fremde GUI-Komponenten, hier die Solr-Verwaltung.
Dem Suchenden bleibt diese Vielfalt zum Glück verborgen, weil er nur je eine Seite zur Standardsuche und eine zur erweiterten Suche findet. Die Suchseiten nutzen das hauseigene Framework Ajax France Labs [11], das sich am altbekannten Ajax-Solr [12] orientiert. Während im Browser die Resultate mit Paginierung, Inhaltsvorschau und allen Facetten erscheinen, präsentiert sich Datafari auf Smartphone-Displays als endlos scrollende Single-Page-Implementierung mit Hamburger-Menü zur Facettenauswahl.
Datafari unterliegt dem Schutz der Apache-2.0-Lizenz und steht als Debian-Paket, Docker-Image oder Virtual Appliance zum Download [13] bereit. Auf Anfrage gibt es sogar Installer für diejenigen, die nicht auf Linux setzen. Der Quellcode liegt auf Github [14], sodass einem problemlosen Selbstbau nichts im Wege steht. Hinweise dazu liefert das Wiki [15], Hilfe wartet im Forum [16].
Vorarbeiten
Nun ein Beispiel: Als treue Leser von Fachmagazinen horten Abonnenten des Linux-Magazins womöglich auch Berge von älteren Ausgaben im Keller. Zwar ist eine vernünftige Suche in diesem Papierhaufen kaum möglich, doch der Verlag liefert erfreulicherweise einen Ausweg: Jahrgangs- und Jubiläums-DVDs archivieren die Artikel vieler Jahrgänge. Zwar bringen diese Datenträger eigene Suchwerkzeuge mit, aber eine umfassendere Lösung wäre noch angenehmer.
Diese Artikelreihe beschreibt Verfahren, um die Inhalte von Fachartikeln einer Volltextsuche zugänglich zu machen. Verschiedene Ansätze helfen die dabei auftauchenden Probleme zu lösen. Nach und nach entsteht so ein verlagsübergreifendes Archiv gängiger Fachmagazine – nicht nur zum Thema Linux.
Zum Kreis der theoretisch erreichbaren Zeitschriften gehören neben Linux-Magazin und LinuxUser auch mehrere englischsprachige Linux-Magazine sowie die Linux- und IT-Publikationen von Heise oder IDG. Der vorliegende Teil dieser kurzen Reihe schildert zunächst, wie die internen Suchmechanismen allgemein arbeiten; die weiteren Teile widmen sich dann den praktischeren Details.
Die jüngst erschienene Jubiläums-DVD zum Thema “25 Jahre Linux-Magazin” (Ausgabe 10/2019) dient im Artikel als Quelle. Die Recherche im Archiv soll sich hier auf die Artikel selbst beschränken, Listings und übrige Inhalte bleiben links liegen. Zum Einsatz kommt ein auf einem NAS installierter Apache-Webserver ohne weitere Besonderheiten, der die Dokumente ausliefert. Als Testplattform dient ein Server unter Debian 9.
Die Artikeldateien des Linux-Magazins liegen, mit Ausnahme einiger PDFs der ersten Jahrgänge, im HTML-Format vor, in hierarchisch nach Jahrgang, Monat und Artikel strukturierten Verzeichnissen. Diese Struktur kopiert der Admin fein säuberlich auf den Webserver. Auf jeder Ebene existieren Indexdateien (»index.html«), die nicht nur eine Browser-Navigation im Archiv erlauben, sondern auch den Crawling-Prozess der Suchmaschine erheblich vereinfachen.
Eine Hauptindexdatei im Ordner »/html/index.html« präsentiert tabellarisch Links auf alle Jahrgänge und die monatlich erschienenen Ausgaben. Dieser Datei kommt besondere Bedeutung zu, denn sie liefert den Einstiegspunkt – gleichermaßen für Mensch und (Such-)Maschine.
Datafari
Vereinfacht gesprochen sammelt zunächst ein Crawler die Dokumente der Datenquelle. Eine Document Processing Pipeline extrahiert Daten beziehungsweise Metadaten und reicht sie an den Suchserver durch. Der zerlegt die Informationen in Felder, indexiert deren Inhalt und speichert sie. Ajax France Labs bereitet die Suchergebnisse auf und präsentiert sie im Webbrowser des Benutzers. Eine zentrale und vermittelnde Rolle in diesem Prozess spielt Manifold CF (MCF [3]), das als Bindeglied zwischen Dokumentenablage und Suchserver auftritt (Abbildung 2).
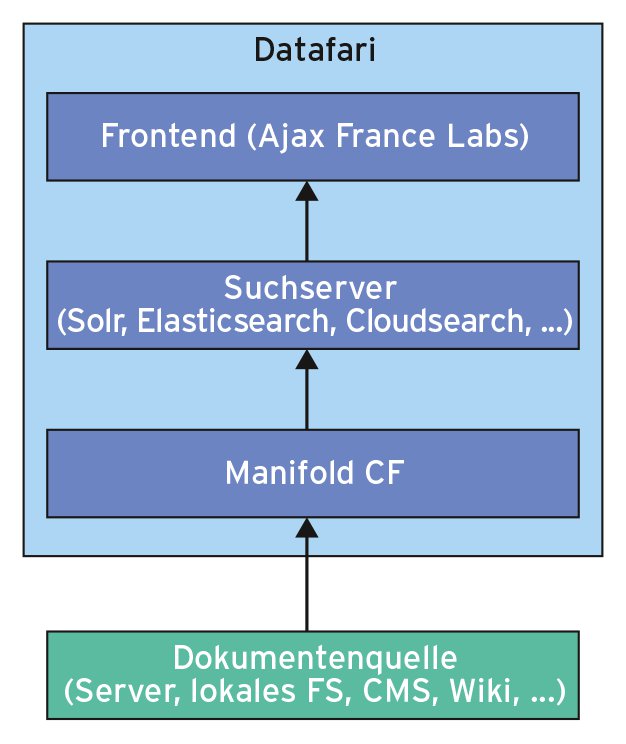
Abbildung 2: Manifold holt die Daten von einem Speichermedium und reicht sie an Solr weiter.
MCF ermöglicht den Zugriff auf eine Vielzahl von Datenquellen wie lokalen Dateisystemen, Network Shares, Webserver, Content-Management-Systemen, Wikis, Datenbanken und E-Mail-Server. Wer trotzdem keinen passenden Zugang zu seinem Repository findet, strickt sich einfach selbst eine auf dem MCF-Framework basierende Lösung.
Sammelstelle
Der Webcrawler von MCF benötigt mindestens einen Startpunkt, eine so genannte Seed-URL, etwa die Homepage eines Internetauftritts. Im vorliegenden Beispiel handelt es sich um die Adresse der schon angesprochenen Indexdatei im HTML-Wurzelverzeichnis des Archivs (»html/index.html«).
Diverse URL-Listen legen dabei per Include-Exclude-Verfahren sehr genau fest, welchen Weg der Crawler nehmen soll und welche Dateien im Index landen. Für alle Parameter ist der Einsatz regulärer Ausdrücke erlaubt.
Datafari unterstützt dank MCF mehrere gängige Suchserver-Backends. Dazu zählen neben Solr auch Elasticsearch [17], Open Search Server [18] und Amazons Cloudsearch [19]. Das Installationspaket bringt einen vorkonfigurierten Solr-Server in Version 7.4 mit – eine gute Wahl, denn Solr gilt neben Elasticsearch als State of the Art in Sachen Suchsoftware.
Dokumentenverarbeitung
In MCF dienen Jobs dazu, Datenquellen (Repositories) und Suchserver-Backend zuzuordnen (Abbildung 3). Sie legen alle erforderlichen Daten für das Crawling und den Indexierungsprozess fest. Ein optionales Ausführungsprofil regelt, ob der Admin den Job unmittelbar, zu bestimmten Zeitpunkten oder periodisch starten möchte.
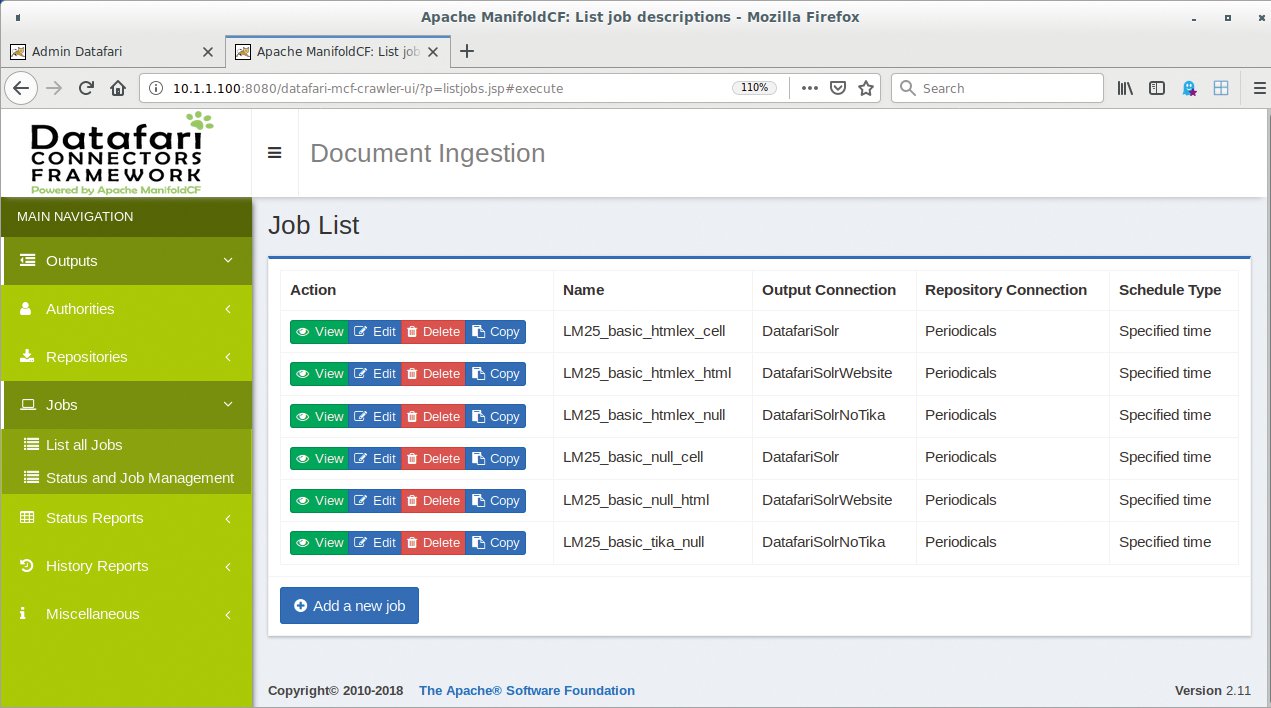
Abbildung 3: Die Jobübersicht im Web-UI zur Manifold-CF-Administration.
Die Document Processing Pipeline ist eine wesentliche Komponente jedes Suchservers und dient nicht nur dazu, Texte zu extrahieren, sie hilft auch dabei, Metadaten zu gewinnen und zu transformieren. Sie umspannt bei Datafari sowohl Manifold CF als auch Solr. Dabei gibt es nicht nur eine Möglichkeit, eine Pipeline zu bilden, sondern mehrere (Abbildung 4). Hier ergeben sich aber gewisse Überschneidungen der Funktionen.
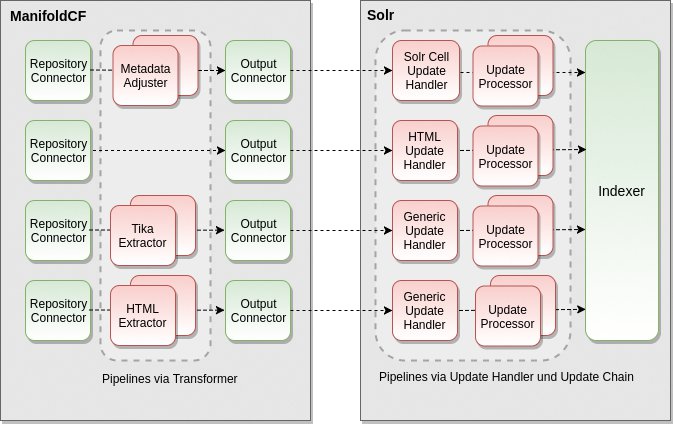
Abbildung 4: Datafari ermöglicht mehrere Document Processing Pipelines. Abhängig vom Use Case ist mal die eine sinnvoll, mal die andere.
So lassen sich auf Seiten von Manifold verschiedene Extractors mit unterschiedlichen Fähigkeiten einsetzen. Auf Seite des Suchservers Solr warten diverse Update-Handler, die wiederum eigene Update-Chains nutzen. Letztere bestehen aus Prozessoren. Dabei handelt es sich um konfigurierbare Programmmodule der Solr-Dokumenten-Pipeline, die kleine Transformationen der Dokumentendaten (etwa String-Verarbeitung) erledigen. Sie lassen sich in Reihe schalten.
Welcher Extractor oder welcher Update-Handler seine Aufgabe am besten erfüllt, hängt unter anderem vom Format ab, in dem das Quellenmaterial vorliegt.
Datafari installieren
Beim Installieren des Debian-Pakets von Datafari landen rund 5 GByte unter »/opt/datafari/«. Skripte für das Starten und Stoppen aller Komponenten liegen dann im Verzeichnis »/opt/datafari/bin/«. Einen automatischen Start während der Systeminitialisierung rüstet der Admin selbst nach. Für einen reibungslosen Start muss er zudem die Umgebungsvariablen »JAVA_HOME« und »JRE_HOME« korrekt setzen. Um flüssig zu laufen, benötigt das Suchsystem ausreichend Arbeitsspeicher; Das Entwicklerteam empfiehlt dafür mindestens 8 GByte.
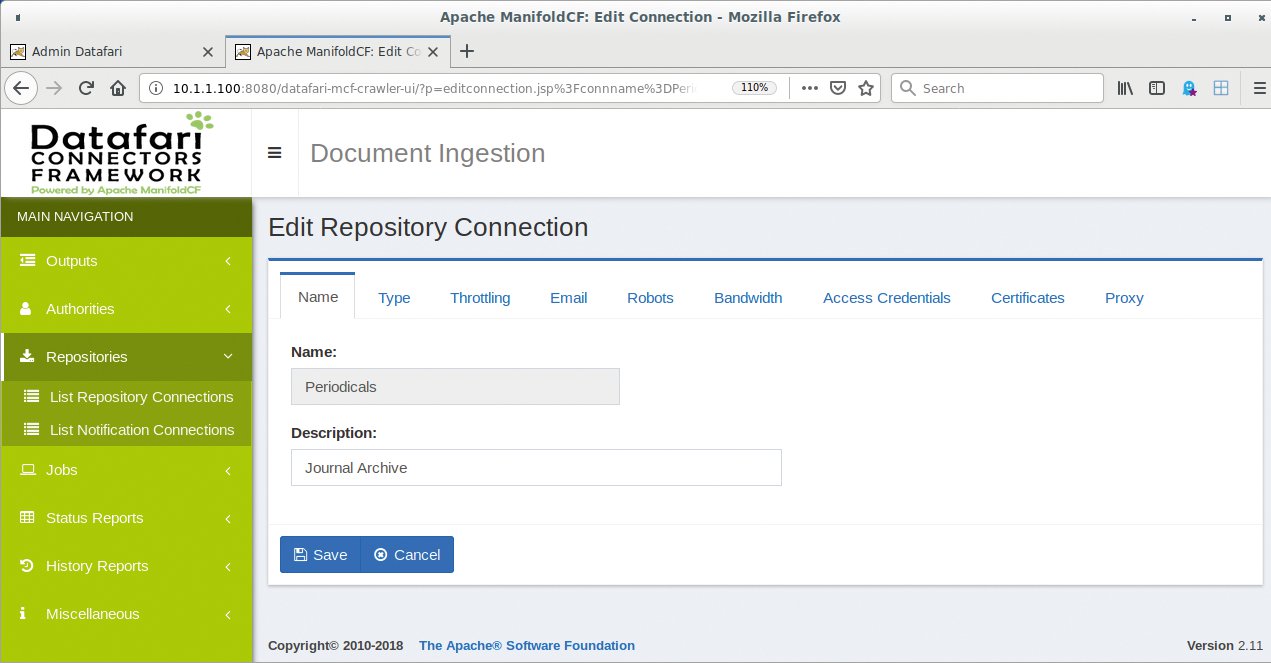
Abbildung 5: Die Repository-Definition legt die Datenquelle fest, aus der Datafari sich bedient – in diesem Beispiel das Linux-Magazin-Archiv auf dem Server.
Im Auslieferungszustand lässt Datafari die Wahl zwischen Deutsch, Englisch, Französisch, Russisch, Italienisch und Portugiesisch als Dialogsprachen. Diese Unterstützung beschränkt sich aber auf die Datafari-eigenen Dialogtexte, die übrigen GUIs der integrierten Fremdkomponenten oder die zu indexierenden Texte deckt sie nicht ab. Die Übersetzung der Dialogtexte ist zwar unvollständig, aber durchaus brauchbar.
Datafari hat viele weitere Features. Erschöpfende Auskunft über die gebotenen Funktionen geben das Projekt-Wiki [15], die Entwickler- und Anwenderdokumentation von MCF [3] sowie das Manuskript von Karl Wright [20].
Auf zur Quelle
Zunächst schafft der Admin einen Zugang zur Dokumentenquelle und zum Backend. Beides gelingt über das MCF-Admin-UI, das unter der Adresse http://localhost:8080/datafari-mcf-crawler-ui/index.jsp wartet. Hier legt er neben der Repository Connection, die auf die Dokumentenquelle verweist (Abbildung 5), auch einen Output-Connector an – im Beispiel ist das Solr (Abbildung 6).
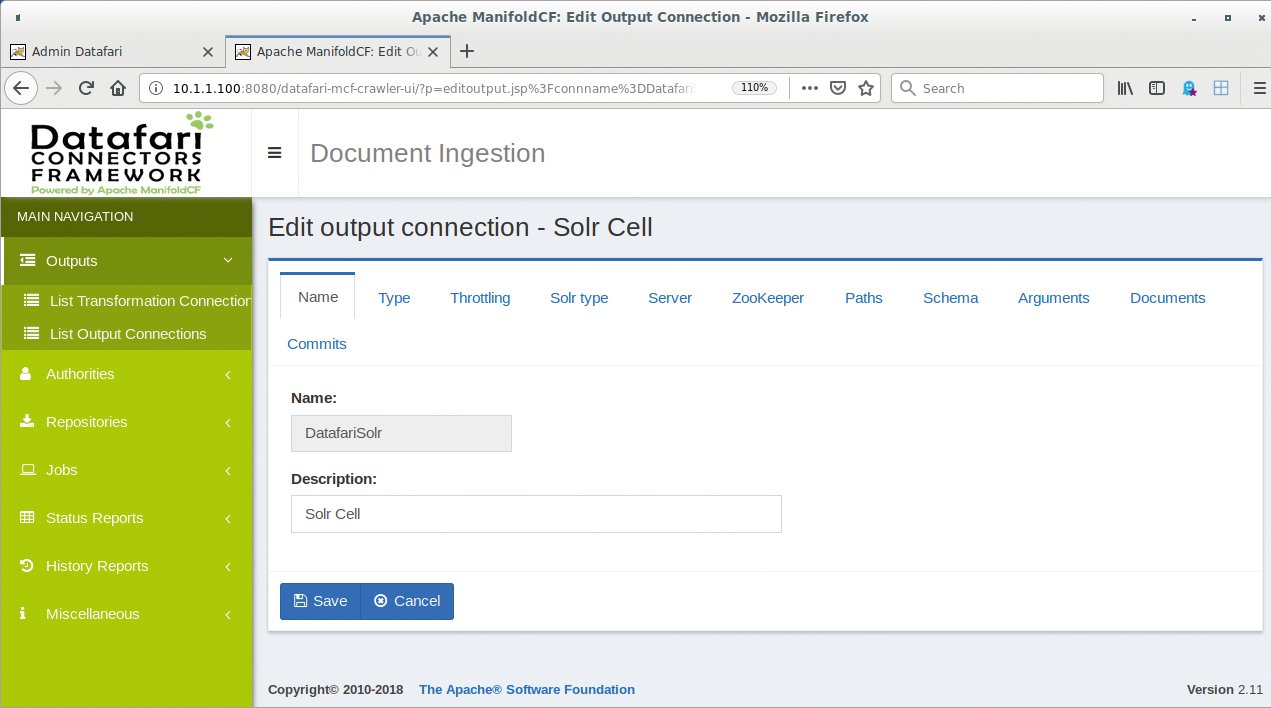
Abbildung 6: Die Output-Connector-Definition weist auf die verwendete Suchmaschine hin. Hier handelt es sich dabei um Solr, doch es gibt weitere Alternativen.
Gewöhnlich muss der Admin sich selbst um die Konnektoren und die Job-Konfiguration bemühen, also um die Zugangsdaten, Seed-URLs auf dem Webserver, Ein- und Ausschlüsse sowie weitere Parameter. Zwei allgemein verwendbare Solr-Konnektoren sind im Paket bereits vorkonfiguriert (siehe Kasten “Solr anpassen”). In der Standardkonfiguration kommt Tika als Kernkomponente zur Extraktion der Textinhalte und Metadaten zum Einsatz, entweder als Verarbeitungsstufe in MCF (als Tika Transformer) oder direkt im Solr-Backend als Solr Cell (Extracting Update Request Handler).
Solr anpassen
Die Konfigurationsdateien von Solr stecken in drei Tar-Archiven [22]. Wie und in welcher Reihenfolge der Admin sie einspielt, beschreibt die zugehörige README-Datei. Doch gibt es trotz aller Automatisierungshilfen keine Lösung, um den ursprünglichen, nicht lokalisierten Search Handler auszutauschen. Der Admin kommt also nicht umhin, ihn in der »solrconfig.xml« per Editor zu entfernen oder umzutaufen. Dazu ersetzt er dessen Namen »select« durch einen anderen, etwa »select_x«:
<requestHandler class="solr.SearchHandler" name="/select_x" useParams="mySearch">
Der für »solrconfig.xml« beschriebene Include-Mechanismus übernimmt die umfangreichen Änderungen, um Solr an die deutsche Sprache anzupassen und die Request Handler in der Datei zu erweitern. Zookeeper erreicht der Admin über Datafaris Admin-UI unter »Search Engine Configuration | System Configuration Manager«. Ein Klick auf »Push« lädt die soeben modifizierte Konfiguration in Zookeeper, ein Klick auf »Apply« verteilt sie auf die Solr-Cores. Danach startet der manuelle Aufruf des Skripts »addCustomSchemaInfo.sh« im Unterverzeichnis »conf/customs-schema/« die notwendige Anpassung des Solr-Schemas.
Vorsicht: Neuere Datafari-Versionen bieten die Möglichkeit, die »SearchHandler«-Parameter via »useParams« zu überschreiben. Da der referenzierte, höher priorisierte Parametersatz »mySearch« nicht existiert (Version 4.2.1), greifen die Default-Parameter in der Deklaration nicht. Das fällt nicht unbedingt sofort auf. Unruhe entsteht erst, weil die Volltextsuche nur mit Angabe der Solr-Felder funktioniert. Bedauerlicherweise haben die Datafari-Entwickler diese eigentlich essenzielle Schnittstelle nicht dokumentiert.
Tika kommt mit Objektformaten aus vielen Bereichen zurecht und verarbeitet praktisch alle gängigen Markup-, PDF-, Office- und Multimediadateien. Es packt Archive aus und expandiert komprimierte Dateien, eine Texterkennung erweitert das Angebot. Für erste Versuche eignet sich die Standardlösung, in der Solr Cell die Dokumente in Text und Metadaten zerlegt.
Wühlmaus
Nun kann das Crawling mit dem Start eines passenden MCF-Jobs beginnen (siehe Kasten “MCF-Jobs anpassen”). Die im Linux-Magazin-Archiv gefundenen Indexdateien gehören allerdings nicht in den Index, da sie keine Artikeltexte enthalten. Datafari sollte sie den Anwendern aus diesem Grund auch nicht als Fundstellen präsentieren.
MCF-Jobs anpassen
Der Folgeartikel (also Teil 2 der Reihe) erklärt im Detail, wie der Admin die eingesetzten Jobs für das Linux-Magazin-Beispiel konfiguriert. Unter anderem muss er »mcf_conf.tar« einspielen und die passenden MCF-Jobs starten. Er darf zudem nicht vergessen, die Seed-URLs der Jobs an seinen Webserver anzupassen, und muss nicht benötigte Jobs löschen und erwünschte starten.
Hilfreich ist ein Schalter, um das Crawling auf die Hosts der Seed-URLs zu begrenzen. Bei dieser Standardeinstellung erübrigt es sich, Hostnamen in den Listen anzugeben. Das verhindert zusätzlich, fremde Webserver in Mitleidenschaft zu ziehen. Aus der Anfangszeit des Linux-Magazins in den Jahren 1994 bis 1996 liegen 16 Ausgaben nur im PDF-Format ohne Bookmarks vor, das sich auch nur umständlich indexieren ließe. Der Artikel ignoriert diese Ausgaben daher.
Die Last, die der Crawler für den Webserver produziert, lässt sich begrenzen, indem der Admin Verbindungszahl und Datendurchsatz reguliert. Unbedingt beachtenswert ist die standardmäßig konfigurierte Bandbreitenbeschränkung der zwei voreingestellten Verbindungen zum Webserver auf 64 KByte pro Sekunde und zwölf Seitenzugriffe pro Minute. Das mag zwar gegenüber fremden Servern rücksichtsvoll und angebracht erscheinen, bremst den Vorgang aber aus.
Die vom Crawler auf dem Webserver gefundenen Indexdateien referenzieren ärgerlicherweise nicht alle Artikeldateien des Dateisystems, es gibt einige mit falschen Pfadangaben. Ein Crawl-Vorgang über die Indexdateien, der die enthaltenen Links extrahiert, liefert im Suchindex daher nicht alle vorhandenen Artikel. Wegen der geringen Anzahl der Ausfälle soll dies hier jedoch keine Rolle spielen.
Deutschstunde
Um Dokumente mit deutschen Inhalten sinnvoll einzulesen, muss der Admin vorab die sprachabhängige Textanalyse während der Indexierung und Suche über die erweiterte Konfiguration anpassen. Die korrekte Textanalyse hat entscheidenden Einfluss auf die Brauchbarkeit der Suchergebnisse.
Support für zusätzliche Sprachen erhält der Admin, indem er Felddefinitionen im Solr-Schema ergänzt und Bestandteile der Document Processing Pipeline sowie Search-Handler in »solrconfig.xml« anpasst (siehe Kasten “Solr anpassen”). Er sollte aber der Versuchung widerstehen, die Schemadatei »schema.xml« direkt zu bearbeiten, denn jede Änderung geht bei einer Neuinstallation verloren. Die Entwickler stellen vielmehr ein Skript bereit, um das Schema dynamisch über das Solr-Schema-API zu ergänzen. So grenzen sie Voreinstellungen von Domain-spezifischen Parametern ab.
Für die Analyse deutscher Texte sorgt ein weiterer Feldtyp »text_de« samt passenden Analyser-Komponenten. Das Schema erhält dann neue Felder (»content_de«, »title_de«) dieses Typs. Bei multilingualen Setups sieht die Sache etwas anders aus (siehe Kasten “Multilingual”).
Multilingual
Das von den Entwicklern gewählte Verfahren mit sprachenspezifischen Suchfeldern stößt in einer multilingualen Umgebung schnell an seine Grenzen, denn die Suchanfrage muss zwangsläufig alle sprachabhängigen Felder mitschleppen. Andere Konzepte beschreibt das Buch “Solr in Action” [21].
Um die Spracherkennung besser zu kontrollieren, verwendet dieses Projekt eine Pseudosprache »xx« mit entsprechenden Schemadefinitionen und konfiguriert »xx« als Fallschirmlösung (»langid.fallback«) der Spracherkennung in der Update-Chain. Alle unbekannten Sprachen erhalten dann das Kürzel »xx«, um die zugehörigen Dokumente schnell zu identifizieren.
Feldversuch
Doch nicht nur die Sprache passt der Admin bei dieser Gelegenheit an: Weitere Schemafelder dienen der Aufnahme von Artikeleigenschaften, die später dabei helfen, ein Minimum von Publikationsdaten anzuzeigen, etwa Magazinname, Erscheinungsjahr, Ausgabennummer und Seitenzahlen. Die bereits von Datafari vorbereiteten und neu hinzukommenden Felder stecken in der Tabelle 1.
|
Bedeutung |
Typ |
Facette |
Anmerkung |
|
|---|---|---|---|---|
|
»title« |
Artikeltitel |
S |
– |
Ressourcenname, falls Titel nicht verfügbar |
|
»content« |
Inhalt |
S |
– |
extrahierter Text |
|
»language« |
Sprache |
S |
x |
»xx« falls nicht ermittelbar |
|
»title_Sprachkürzel« |
Artikeltitel |
S |
– |
sprachspezifisches Feld |
|
»content_Sprachkürzel« |
Inhalt |
S |
– |
sprachspezifisches Feld |
|
»headline« |
Dachzeile |
P |
– |
optional |
|
»publication« |
Magazinname |
P |
x |
erforderlich (etwa »Linux-Magazin«) |
|
»year« |
Erscheinungsjahr |
P |
x |
erforderlich |
|
»issue« |
Ausgabe |
P |
– |
optional |
|
»pageno« |
Seite Artikelanfang |
P |
– |
optional |
|
»pagend« |
Seite Artikelende |
P |
– |
optional |
|
»section« |
Rubrik/Hauptthema |
P |
x |
optional |
|
»subject« |
Schlüsselbegriff |
P |
x |
optional |
|
»comments« |
Kommentare |
S |
– |
optional |
|
S = Datafari-Standard, P = projektspezifisch |
Die Metadaten eines Dokuments eignen sich oft als Facetten, um gefundene Dokumente mit gleichen Eigenschaften zu gruppieren. Indem der Nutzer bestimmte Facettenwerte auswählt, schränkt er die Suchergebnisse ein (etwa: Linux-Magazin, Jahrgang 2014 und 2015). Für die Volltextsuche in einem Zeitschriftenarchiv erweisen sich Magazinname und Erscheinungsjahr als sinnvoll. Um die zugehörigen Bildschirmausgaben und Steuerelemente anzuzeigen, muss der Admin die grafische Oberfläche minimal erweitern.
Linux-Magazin-Artikel umfassen gewöhnlich einen Titel, eine Dachzeile, einen Vorspann, den Text mit eingestreuten Zwischenüberschriften sowie beschriftete Grafikelemente. Das Suchergebnis soll den Titel später um die Dachzeile ergänzen, da diese den Artikelinhalt in der Regel zutreffender beschreibt als der eher fantasievolle Titel. Da die Dachzeile zum Artikeltext gehört, ist eine sprachenspezifische Auswertung wie beim Titel nicht erforderlich; es genügt, ein neues Feld zu definieren, das den Inhalt aufnimmt (»headline«).
Die Konfigurationsdatei »solrconfig.xml« enthält Direktiven zum Einbinden Datafari-fremder Bestandteile. Es ist sinnvoll, diesen Weg zu nutzen, um alle für den Artikel angepassten und eigenen Modifikationen in externe Komponenten (Request- und Search-Handler, Update-Processor und Search-Components) auszulagern und auf dem im Wiki vorgesehenen Weg einzubinden. Eine Neuinstallation sollte dann höchstens leicht feuchte Hände verursachen. Alle modifizierten Dateien bietet der Listing-Server des Verlags [22] zum Download an. Der Admin spielt sie so ein, wie es das dort ebenfalls vorhandene README erläutert.
Enttäuschende Resultate
Eine spartanische Eingabemaske in bekannter Edismax-Syntax [23], erreichbar über »http://localhost:8080/Datafari/Search«, erlaubt die Suche mit zahllosen Features wie logisch verknüpften Begriffen, Wildcards sowie einer Autovervollständigung des Suchbegriffs.
Eine erweiterte Suchseite gibt Hilfestellung beim Zusammenklicken komplexer Suchanfragen als Mischung von Wortphrasen, mehreren logisch verknüpften Begriffen, Feldinhalten, Bereichsdefinitionen und Ausschlusskriterien.
Die Ergebnisseite bietet dem Suchenden fünf Standardeigenschaften (Facetten) zum Filtern der Treffer nach Sprache, Quelle, Dokumententyp, Dateigröße und Datum der letzten Änderung. Ähnliche Suchbegriffe erscheinen, falls der Suchende keine Treffer landet.
Die Suchresultate des ersten Testlaufs mit Solr Cell enttäuschen aus mehreren Gründen (Abbildung 7). Datafari verfügt intern über Mechanismen, um die Sprache der indexierten Texte zu erkennen, stuft aber nicht alle Dokumente korrekt als deutschsprachig ein. Viele Artikel weist es als englischen, französischen oder nicht klassifizierbaren Text aus. Obwohl die HTML-Dateien im »title«-Tag einen vernünftigen Titel mitbringen, taucht zudem nur der Dateiname auf.
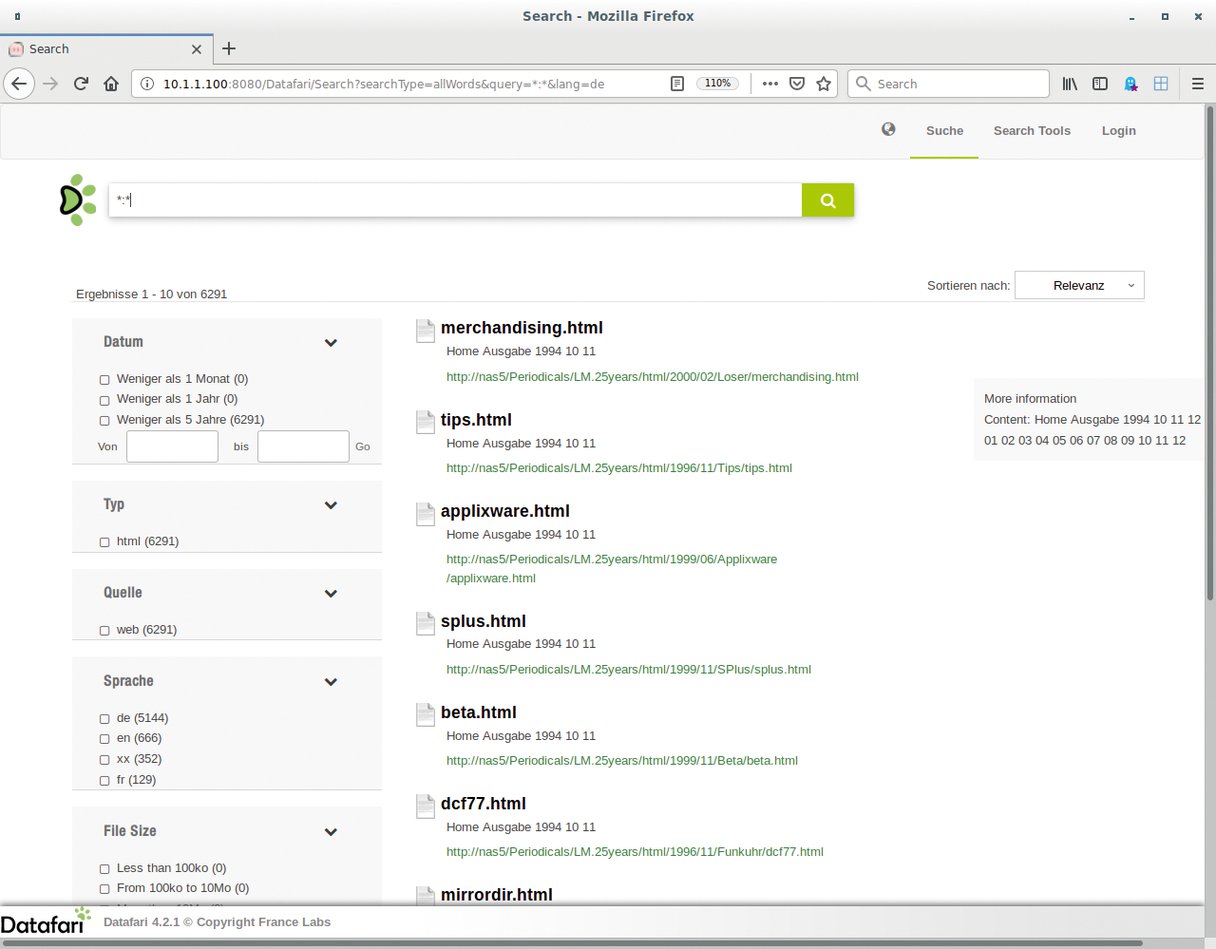
Abbildung 7: Erste ernüchternde Suchergebnisse zeigen, dass noch Feintuning ansteht.
Jede Artikeldatei enthält am Seitenanfang Navigationselemente, über die sich Leser bequem innerhalb des Archivs bewegen. Doch stören die Texte der Querverweise das maschinelle Auswerten via Suchmaschine. Ohne weiteres Filtern enthalten die Artikelschnipsel der Treffer oft Textfragmente oder hässliche Leerzeilen und Zahlenkolonnen. Die Lösung bringt eine angepasste Document Processing Pipeline. Fährt der Nutzer mit dem Mauszeiger über einen bestimmten Suchtreffer, erscheint rechts daneben eine Vorschau auf den Dokumenteninhalt. Hier stören die unerwünschten Bestandteile des Textes besonders (Abbildung 7).
Das Fehlen des Artikeltitels geht auf die besondere Dokumentenverarbeitung von Datafari zurück. Offenbar favorisieren die Entwickler eine Kombination aus dem eigenen HTML-Extractor als MCF-Transformer mit dem Solr-Cell-Update-Handler, was die angeführten Probleme auslöst. Eingeweihte setzen in der Konfiguration von Solr Cell einfach im Update-Prozessor für die Spracherkennung das Flag »langid.map.keepOrig« auf »true«, und schon zeigt das GUI wenigstens Titel an.
Des Weiteren genügt bei Artikeln des Linux-Magazins die Textextraktion mit Solr Cell alleine nicht, da sie störende Bestandteile der Navigationselemente nicht ausfiltert. Solche Fragmente fallen in den Suchergebnissen nach einer Wildcard-Suche (»*:*«) am Anfang der Textschnipsel oder in der Dokumentenvorschau auf. Die Reste der Seitennavigation beeinflussen auch die Spracherkennung negativ, denn über 15 Prozent der Texte sind ungeachtet der Lokalisierung der Solr-Textanalyse weiterhin falsch klassifiziert.
Die Standardlösung für die Textextraktion mit Solr Cell basiert auf Tika [24]. Dafür sollte der Admin nach der Installation den Heap-Space der Solr-JVM in der Konfigurationsdatei »/opt/datafari/solr/bin/solr.in.sh« auf mindestens 6 GByte für die maximale Heap-Größe (Option »-Xmx6144m«) erhöhen. Die entsprechende Option mit 8 GByte für die Manifold-CF-JVM (»-Xmx8192m«) findet er in »/opt/datafari/mcf/mcf_home/options.env.unix«. Das Wiki [15] liefert weitere Hinweise sowie eine Liste mit den Stellschrauben aller Komponenten.
Tika erlaubt es zwar, den eigentlichen, zur Extraktion gewünschten Textbereich des Originaldokuments mit Hilfe eines XPath-Ausdrucks einzuschränken. Allerdings implementiert Solr Cell diesen Mechanismus nur rudimentär. Es fehlt bedauerlicherweise der Support für die in den Linux-Magazin-Artikeln zur Strukturierung eingesetzten HTML5-Tags »<article>«, »<aside>« und »<section>«. Folglich fehlt, je nach XPath-Anweisung, Text beim Extrahieren oder verbleiben störende Textfragmente.
Über Solr Cell wird im Detail noch ein Folgeartikel sprechen: Solr erwartet eine UTF-8-Kodierung, doch ältere Jahrgangs-DVDs des Linux-Magazins bis 2010 und die Archiv-DVDs der Schwesterzeitschrift LinuxUser verwenden den Zeichensatz ISO-8859-15. In der Folge führen deutsche Umlaute bei der Anzeige zum bekannten diakritischen Zeichensalat. Die passend kodierten Linux-Magazin-Artikel auf der Archiv-DVD betrifft dies nicht.
Der von Datafari beigesteuerte HTML Update Request Handler erweist sich für die hier verwendeten strukturierten HTML-Dokumente als die bei Weitem bessere Wahl. Er schließt, allgemein betrachtet, eine große Lücke der Solr-Implementierung für ein Standard-Dokumentenformat, indem er die Text-Extraktion durch einen »jsoup«-Parser [25] statt des simplen XPath-Ausdrucks entschieden verbessert.
Oberflächenanpassung
Eventuell erhält Datafari eines Tages eine komfortable Möglichkeit zur Konfiguration und Anzeige von Facetten. Bis dahin, oder wenn es weitere Metadaten auf dem Bildschirm auszugeben gilt, muss der Admin den Javascript-Quellcode anfassen. Die entsprechende Vorgehensweise beschreibt die Dokumentation [15].
Sie beschränkt sich hier auf das Erfassen der neuen Facettenobjekte und einige minimale Erweiterungen, um die Dachzeile und die bibliografischen Daten anzuzeigen. Davon betroffen sind die Quelldateien »main.js«, »search.js«, »searchView.jsp«, »SubClassResult.widget.js« und bei Bedarf die sprachspezifischen Textdateien (».json«). Der entsprechend angepasste Quellcode wartet als Patch-Datei auf dem Listing-Server des Linux-Magazins.
Ausblick
Das Datafari-Entwicklerteam hat also mit der Integration aller notwendigen Bestandteile viel Vorarbeit geleistet. Eine große Hilfe ist die gute Dokumentation der verwendeten Standardkomponenten. Hoffentlich behebt eine spätere Release die kleineren Defizite im Umgang mit anderen Sprachen. Wer Hilfestellung beim Sichern seiner Daten sucht, steht aber im Regen: In der freien Variante bringt Datafari weder passende Backup-Skripte mit noch eine Beschreibung der sicherungswürdigen Daten. Dafür müssen Nutzer zur Enterprise Edition greifen.
Ein Folgeartikel steigt in die Praxis ein und knöpft sich den HTML Update Request Handler zur fachgerechten Indexierung der Ausgaben des Linux-Magazins vor. Weitere Themen: Integration der Archive anderer Publikationen, Zeichensätze, die Indexierung von PDF-Dateien und das Generieren ergänzender Metadaten.
Infos
-
Datafari: https://www.datafari.com/en
-
Manifold: https://manifoldcf.apache.org
-
Zookeeper: https://zookeeper.apache.org
-
Tomcat: https://tomcat.apache.org
-
Cassandra: https://cassandra.apache.org
-
PostgreSQL: https://www.postgresql.org
-
ELK-Stack: Christian Rohmann, Heike Jurzik, “Elasticsearch, Logstash & Kibana”, LM 02/2016, S. 58, https://www.linux-magazin.de/ausgaben/2016/02/elk-stack/
-
Preisliste Datafari: https://www.datafari.com/en/pricing.html
-
Ajax France Labs: https://www.francelabs.com/en/ajaxfrancelabs.html
-
Datafari herunterladen: https://www.datafari.com/en/download.html
-
Datafari-Quellcode: https://github.com/francelabs/datafari
-
Datafari-Wiki: https://datafari.atlassian.net/wiki/
-
Datafari-Forum: https://groups.google.com/forum/#!forum/datafari
-
Elasticsearch: https://www.elastic.co/products/elasticsearch
-
Open Search Server: http://open-search-server.com
-
Amazon Cloudsearch: https://aws.amazon.com/de/cloudsearch/
-
“ManifoldCF in Action”: https://github.com/DaddyWri/manifoldcfinaction/tree/master/pdfs
-
Buch zu Solr: Trey Grainger, Timothy Potter, “Solr in Action”, Manning 2014, ISBN 9781617291029
-
Dateien zum Artikel: http://www.linux-magazin.de/static/listings/magazin/2019/11/datafari/
-
Edismax: https://lucene.apache.org/solr/guide/7_4/the-extended-dismax-query-parser.html
-
Tika: https://tika.apache.org
-
Jsoup: https://jsoup.org





