
© subbotina, 123RF
Auch PostgreSQL, neben MySQL eine der bekanntesten Open-Source-Datenbanken, kennt mehrere Spielarten der Replikation. Welche schmeckt wann am besten? Und was tun, wenn die Säge einmal klemmt?
Wer an die Hochverfügbarkeit von Maria DB oder MySQL gewöhnt ist, wird von PostgreSQL enttäuscht. Replikationscluster, die im laufenden Betrieb upgradebar sind und die Kommandos der Data Definition Language (DDL) wie auch der Data Control Language (DCL) replizieren, mit Hunderten Maschinen, die sich zusätzlich noch individuell beschreiben lassen – das ist bis jetzt mit dem frei lizenzierten und kostenfreien Community-Angebot unmöglich. Wer PostgreSQL einsetzen will, sollte daher genau prüfen, ob dessen Möglichkeiten den Business-Anforderungen genügen.
PostgreSQL kennt von Haus aus zwei Arten der Replikation: Streaming Replication und Logical Replication, beide lassen sich von asynchron bis synchron konfigurieren (Abbildung 1). Die Streaming Replication überträgt Änderungen im Transaktionslog (WAL) direkt an den Standby. Im Prinzip ist Streaming Replication ein stetig andauernder Point in Time Recovery (PITR).
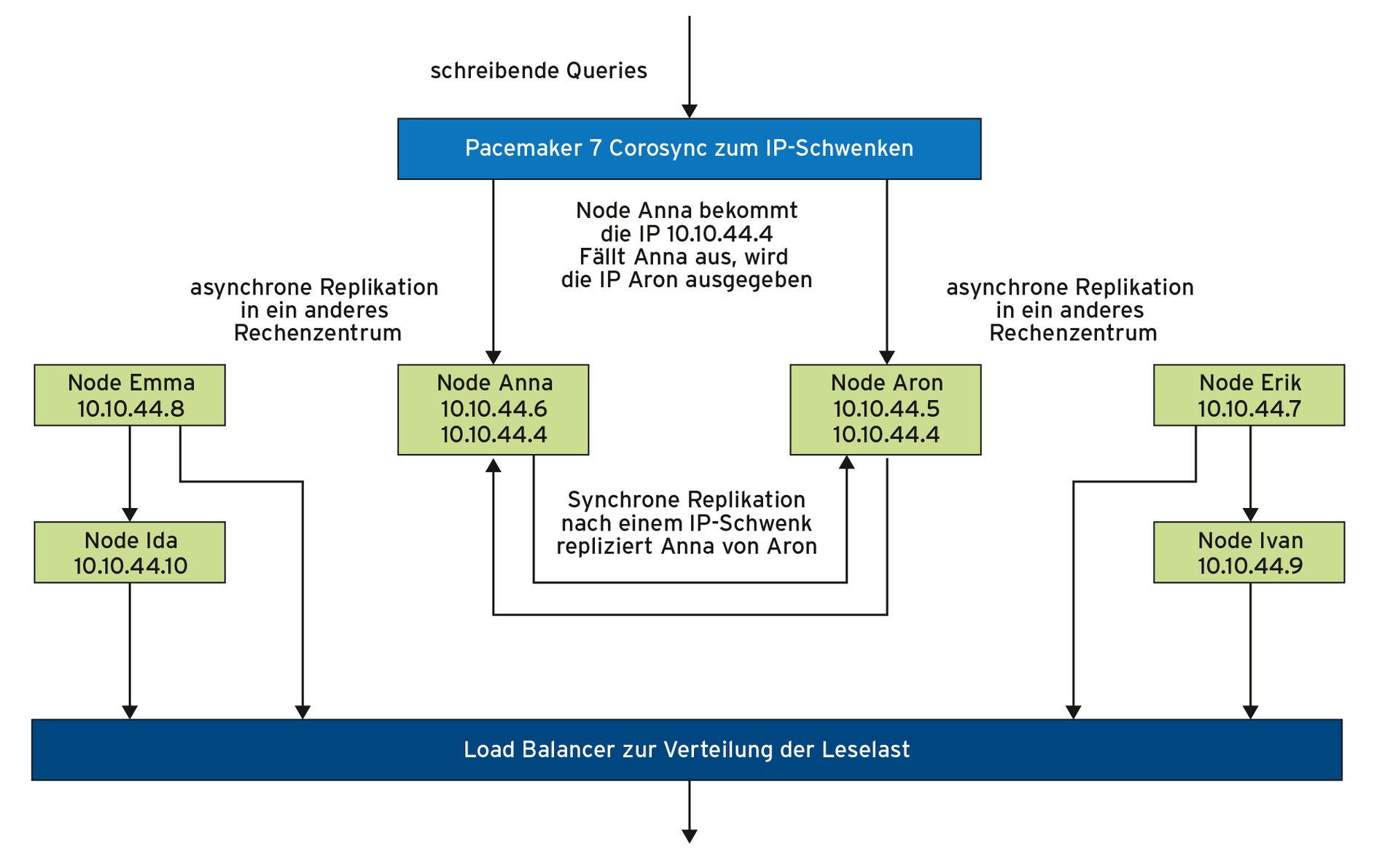
Abbildung 1: Der Einsatz asynchroner und synchroner Replikation in einem Rechenzentrum und darüber hinaus in einem Beispiel.
Bei Logical Replication werden die Informationen der WAL-Dateien zunächst in logische Änderungen decodiert. Diese Spielart existiert vor allem wegen der Kompatibilität zu Oracle-Datenbanken, außerdem kann sie Vorteile bei der versions- und plattformübergreifenden Replikation haben.
Bei der Streaming Replication erhält der Standby die Information, welches Byte sich geändert hat, während bei der Logical Replication der Slave erfährt, welche Daten in welche Tabelle einzufügen, zu löschen oder zu ändern sind.
Streaming Replication
Streaming Replication aufzusetzen ist bei PostgreSQL genauso simpel wie bei Maria DB und MySQL. Nachdem der Admin die »postgresql.conf« der Primary-Seite für Streaming Replication angepasst hat, kann er Standbys mit Hilfe von Hot Backups ohne Downtime des Primary sowohl synchron als auch asynchron einrichten. Der Primary bekommt von der ganzen Aktion quasi nichts mit.
Bevor ein Standby auf den Primary zugreifen kann, ist dort festzulegen, mit welcher Rolle er das darf. Er kann ein Superuser sein, es reicht aber, wenn die Rolle das »REPLICATION«- und das »LOGIN«-Privileg hat. Die Rolle legt entweder der SQL-Befehl
CREATE ROLE Rollenname LOGIN REPLICATION PASSWORD 'Passwort'
oder der Shell-Befehl
createuser --replication -login -pwpromt Rollenname
an. Den Zugriff muss die »pg_hba.conf« erlauben:
host replication Rollenname IP-Adresse md5
Auf dem Primary ist die zentrale Konfigurationsdatei so anzupassen wie in Listing 1 beschrieben. Damit es Systemd-konform ist, sollte der Admin die Änderungen nicht direkt in diese Datei schreiben, sondern eine neue im »conf.d«-Verzeichnis anlegen. Es ist ratsam, auch die Standby-Rechner bereits mit den Konfigurationen als Primary auszustatten, damit bei einem Ausfall des Primary der Standby übernehmen kann, ohne erst die Konfiguration anzupassen.
Listing 1
Änderungen in der postgresql.conf
01 listen_addresses = '*' # Komma-separierte Liste, auf welchen 02 # IP-Adressen gelauscht werden soll 03 # '*' bedeutet alle 04 # (Änderung bedarf restart) 05 wal_level = replica # (Änderung bedarf restart) 06 archive_mode = on # (Änderung bedarf restart) 07 archive_command = 'cd .' # Es muss hier eine Aktion eingetragen 08 # tragen werden, auch wenn nicht 09 # zusätzlich archiviert werden soll. 10 wal_keep_segments = 5000 # Anzahl der WAL-Dateien 11 # die aufgehoben werden sollen. 12 # Eine WAL-Datei hat 16 MB 13 # 5000 bedeutet 80 GB 14 # Je höher die Anzahl, desto länger 15 # kann der Standby ausfallen. 16 hot_standby = on # (Änderung bedarf restart)
Der Standby benötigt im Datenverzeichnis eine »recovery.conf«. Eine »recovery.conf.sample« sollte dem System beiliegen. Die »recovery.conf« muss im Datenverzeichnis liegen und genau so heißen. Sie sollte mindestens das beinhalten, was Listing 2 zeigt.
Listing 2
recovery.conf
01 standby_mode = on 02 primary_conninfo = 'host=10.10.44.4 port=5432 user=Rollenname password=Passwort application_name=Standbyname' 03 04 # application_name wird für synchrone Replikation benötigt 05 # jeder Standby sollte hier einen anderen Namen haben. 06 07 # der primary_slot_name ist später für das Monitoring wichtig 08 primary_slot_name = 'maschine_10.10.44.12'
Ob in einem Replikationscluster alle Standby-Rechner ihre Daten vom Primary beziehen oder von anderen Standbys, bleibt der Business-Logik überlassen. Die Replikation erfolgt über das Transaktionslogging (WAL). Egal ob Data Definition Language (DDL, Befehle: »create«, »alter«, »drop«), Data Control Language (DCL, Befehle: »grant«, »revoke«) oder Data Modification Language (DML, Befehle: »insert«, »update«, »delete«) – jede schreibende Aktion auf dem Primary wird auf die Standbys übertragen. Der Standby ist damit ein kompletter Clone seines Primary.
Damit sich bei einem Switch-over der alte Primary schnell und unkompliziert in einen Standby verwandeln kann, gibt es seit Version 9.5 den Befehl »pg_rewind«. Hierfür ist es wichtig, dass »wal_log_hints« in der »postgresql.conf« eingeschaltet ist.
Streaming Replication hat jedoch ein paar Haken, deren Folgen in jedem Fall im Vorfeld zu bedenken sind:
- Sie ist plattformabhängig. Den Primary auf Linux und einen Standby auf Windows laufen zu lassen oder umgekehrt, ist nicht möglich.
- PostgreSQL ist Prozess-basiert. Das bedeutet, dass jede Standby-Verbindung zum Primary einen Prozess benötigt. Es lassen sich nicht mehr Standbys anlegen, als »max-connections« angibt. Die Standby-Verbindungen konkurrieren hier mit den anderen PostgreSQL-Verbindungen. Um einem Verbindungs-Overhead oder eine Semaphoren-Überlast zu vermeiden, sollte der Datenbank-Admin »max-connection« nicht allzu hoch einstellen und Connection Pooling verwenden. Das bedeutet, dass die maximale Anzahl effektiver Standbys auf relativ wenige Maschinen begrenzt ist.
- Standbys sind zwangsweise read-only, das heißt, dass Master-Master-Systeme ausgeschlossen sind. Darüber hinaus bedeutet es, dass im Falle eines Fail- oder Switch-over der Standby erst zu promoten ist, ehe er schreibende Transaktionen annehmen kann. Da Systemd »promote« nicht unterstützt, lässt sich der Fail- oder Switch-over nicht Systemd-konform ausführen. Bei einem Einsatz von Tools wie Pacemaker und Corosync ist darauf zu achten, dass der Standby zu promoten ist, bevor die IP-Adresse für die Anwendungen schwenkt. In diesen Fällen ist es ratsam, die »postgresql.conf« des übernehmenden Standby schon in Vorfeld so anzupassen, dass er als Primary nach dem Promote ohne erneuten Restart sofort loslegen kann.
- Für den Fall, dass Standbys, die am alten Primary hängen, nach einem Switch-over dem neuen Primary folgen sollen, gibt es im Initskript das Kommando »follow«. Auch hier ist zu bedenken, dass Systemd »follow« nicht unterstützt. Zudem ist bei asynchroner Replikation nicht sicherzustellen, dass der Standby keinen aktuelleren Stand hatte als der neue Primary. Wenn sich im Zuge eines Fail-over die anderen Standbys mit »follow« an den neuen Primary anhängen, geht das oft gut – eine Garantie für das Gelingen gibt es aber nicht. Hier ist eine mögliche Lösung, dass der Standby, der den Primary ersetzen soll, synchron repliziert. Dabei sind jedoch auch die Fallstricke der synchronen Replikation zu bedenken.
- Streaming Replication ist versionsabhängig. Das heißt, dass alle Standbys die gleiche Major-Version haben müssen wie der Primary. PostgreSQL veröffentlicht in der Regel jährlich eine neue Release, und der Community Support endet nach fünf Jahren. Bei einem Versionsupgrade führt das zwangsweise zu Downtime.
Welche Strategie er bei einem Replications-Cluster-Upgrade verfolgt, bleibt dem Admin überlassen. Downtime ist aber in jedem Fall ein Faktor, der zu berücksichtigen ist.
Logical Replication
Mit Logical Replication lässt sich plattformunabhängig und von niedrigeren zu höheren Versionen replizieren. Der Standby ist nebenher beschreibbar, Master-Master-Replikation ist möglich, und man kann frei wählen, welche Tabellen zu replizieren sind. Der große Vorteil gegenüber der Streaming Replication ist zudem, dass sich der Replication-Cluster im laufenden Betrieb upgraden lässt. Es ist möglich, zuerst nach und nach alle Standbys auf die neuere Version zu bringen und zum Schluss die IP des Primary auf einen der Standbys oder des zweiten Masters zu schwenken. Danach lässt sich der alte Primary upgraden.
Logical Replication besitzt jedoch den Nachteil, dass sie nicht DDL- und auch nicht DCL-fähig ist. Das bedeutet, dass im Vorfeld zu prüfen ist, ob die Anwendungen im laufenden Betrieb Create-, Drop- oder Alter-Statements nutzen. Selbst wenn Anwendungen im laufenden Betrieb kein DDL verwenden, ist hier zu bedenken, dass auch für Anwendungssoftware hin und wieder Versions-Updates herauskommen, die dann eventuell Änderungen am Datenbankschema mitbringen. Diese Änderungen muss der Admin dann entweder auf jedem Standby manuell einspielen oder er muss alle Standbys nach Änderung des Primary neu aufsetzen. Ob das Einspielen der Schema-Änderungen auf alle Maschinen on the Fly durchführbar ist, hängt von den Änderungen ab. Möglich, dass der Admin dafür den gesamten Replikations-Cluster anhalten und eine längere Downtime in Kauf nehmen muss.
Logical Replication repliziert Datensätze erst ab dem Zeitpunkt, ab dem die entsprechende Tabelle auf dem Standby für die Replikation eingerichtet ist. Befinden sich auf dem Primary ältere Datensätze in der Tabelle, holt sie die Replikation nicht nach. Um einen konsistenten Datenbestand zu erhalten, muss der Primary während des Setups eines neuen Standby angehalten sein, damit der aktuelle Datenbestand des Primary auf den neuen Standby kopiert werden kann und während der Einrichtung des Standby keine weiteren schreibenden Transaktionen auf dem Primary landen können.
Darüber hinaus ist zu bedenken, was im Falle eines Fail- oder Switch-over erforderlich ist, damit die Standbys dem neuen Primary folgen. Aus Konsistenzgründen sollte bei asynchroner Replikation der neue Primary erst wieder schreibende Transaktionen entgegennehmen, wenn alle Standbys umgehängt sind. Hier kann es also zu einer längeren Downtime des gesamten Replikations-Clusters kommen. Auch sollte man genau wie bei Streaming Replication sicherstellen, dass kein Standby einen aktuelleren Stand hat als der neue Primary.
Die Kriterien für die maximale Anzahl von Standby-Rechnern an einem Primary sind hier keine anderen als bei der Streaming Replication.
Asynchrone Replication
Die asynchrone Replikation ist der Klassiker. Fällt ein Standby oder die Netzwerkverbindung zwischen Primary und Standby aus, holt sich der Standby die in der Zwischenzeit angefallenen Änderungen, sobald er wieder online oder die Verbindung wieder hergestellt ist. Die Ausfallzeit darf dabei so lange sein, wie die Transaktionslog-Dateien (WAL-Files) zurückreichen. Dauert der Ausfall länger, bleibt keine andere Möglichkeit, als den Standby neu aufzusetzen.
Synchrone Replication
Synchrone Replikation bedeutet, dass eine Transaktion erst dann abgeschlossen ist, wenn die Änderungen auf allen Maschinen permanent sind, also auf den Festplatten gespeichert. Bei PostgreSQL lassen sich verschiedene Zwischenstufen zwischen asynchroner und synchroner Replikation konfigurieren. Maria DB und MySQL kennen den Zustand “semi-synchron”. Das bedeutet, die Transaktion ist abgeschlossen, wenn die Änderungen auf allen Maschinen mindestens im Arbeitsspeicher liegen. Das ist nur eine der Zwischenstufen, die sich auch bei PostgreSQL einstellen lässt.
Bei der synchronen Replikation ist die Entfernungen zwischen den Maschinen zu berücksichtigen. Größere Entfernungen sind ein bremsender Faktor. Sind die Maschinen alle im selben Rack, im selben Raum, im selben Rechenzentrum, dann sind die Performanz-Einbußen zu verkraften, befinden sich aber mehrere Hundert Kilometer oder gar ganze Ozeane zwischen den Maschinen, dann sollten Admins eine synchrone Replikation sehr genau überlegen.
Darüber hinaus ist bei synchroner Replikation zu bedenken, dass, wenn das Netzwerk zwischen Primary und Standby ausfällt, Transaktionen so lange nicht abgeschlossen werden, bis das Netzwerk wieder verfügbar ist – es sei denn, es kommt vorher zu einem Time-out.
Für synchrone Replikation muss auf dem Primary »synchronous_standby_names« konfiguriert sein. Hier soll der Admin alle Standby-Namen – durch Komma getrennt – auflisten, die synchron replizieren sollen. »*« bedeutet, dass alle Standbys synchron repliziert werden.
Ob vollsynchron oder semi-synchron lässt sich in der »postgresql.conf« durch »synchronous_commit« steuern.
- Der Default ist »on«. Wenn es eingeschaltet ist, wartet die Transaktion, bis das Transaktionslog auf allen Maschinen auf die Platte geschrieben ist.
- Wird es auf dem Primary auf »off« gesetzt, wartet es nicht, bis die Logs auf die Platte geschrieben sind, auch nicht auf dem Primary.
- Bei »local« wartet es, bis die Änderungen im Transaktionslog sicher auf der Platte des Primary sind.
- Die Einstellung »remote_write« bedeutet, dass der Primary die Transaktion in seinem Transaktionslog auf der Festplatte speichert, aber es reicht, wenn die Änderungen auf dem Standby im RAM angekommen sind.
- Die Einstellung »remote_apply« bedeutet, dass die Replikation wartet, bis die Änderungen im Datenverzeichnis und nicht nur im Transaktionslog auf der Festplatte angekommen sind.
Zudem lässt sich »synchronous_commit« auch noch auf dem Standby einstellen.
Troubleshooting
Um die Ausfallzeit möglichst gering zu halten, ist die Verwendung von Pacemaker und Corosync zu empfehlen, die einfach die IP-Adresse auf den übernehmenden Standby schwenken, wenn der Primary ausfällt. Eine weitere Empfehlung ist, den übernehmende Standby synchron replizieren zu lassen, damit weitere, dem Primary folgende Standbys sicher umgehängt werden können.
Wenn etwa der Kernel des Betriebssystems auf dem Primary ein Update bekommt, lässt sich die IP vor dem Neustart der Maschine auf den Standby schwenken. Ist die Maschine dann wieder oben und alles läuft, lässt sich der alte Primary mit »pg_rewind« an den neuen Primary als Standby anhängen.
Für das Monitoring bringt PostgreSQL für den Primary die Tabellen »pg_stat_replication_slots« sowie »pg_stat_replication« mit. Für den Standby gibt es die Tabelle »pg_stat_wal_receiver« sowie die Funktionen »pg_last_xact_reply_timestamp()«, »pg_last_wal_replay_lsn()« und »pg_last_wal_receive_lsn()«. Die Abkürzung »lsn« steht für Log Sequence Number.
Ist ein Standby kaputt, ist es häufig die schnellste Lösung, ihn mit Hilfe des letzten Hot-Backups des Primary schnell wieder neu aufzusetzen. Dafür ersetzt der Admin einfach das Datenverzeichnis auf dem Standby durch das Datenverzeichnis aus dem Backup des Primary. Die Rechte sind anzupassen – es sollte alles im Datenverzeichnis dem User »postgres« gehören –, die vorher gesicherte »recovery.conf« muss der Admin ins Datenverzeichnis zurücklegen und den Daemon starten.
Fazit
Wenn die Downtime des gesamten Replikations-Clusters während eines Versions-Upgrade tolerabel ist und man nicht Hunderte von Standbys braucht, ist PostgreSQLs Streaming Replication eine sehr gute Sache. Wie bei PostgreSQL üblich, ist der Administrationsaufwand nach dem Aufsetzen gering.
Logical Replication ist mit äußerster Vorsicht zu genießen. Auch wenn die Vorteile verlockend klingen, bleiben die Nachteile doch gravierend. Sinnvoll ist, wenn die Standbys, die bei Fail-over oder Switch-over zu Primaries werden, synchron replizieren und wenn sie bei großen Entfernungen die asynchrone Replikation bevorzugen.





