
© Steve Mann, 123RF
Die Cloud hat mit ihrem Bezahlmodell nach Verbrauch das gute alte Performancemanagement zurück in den Alltag der Sysadmins gebracht. Dieser Artikel erläutert, wie sie mit Hilfe von Modellen das kostengünstigste Deployment in einer Amazon-Cloud finden.
Während die Vorteile einer Off-Premise-Cloud auf der Hand liegen – geringere Fixkosten für die Infrastruktur, nahtlose Migration, flexibel verfügbare Kapazität –, haben Clouds zugleich das Bezahlen nach Verbrauch wieder eingeführt, ein vergessenes Konzept in der Linux-Welt, das einst den Mainframes gut vertraut war. Sobald eine Applikation bereitgestellt ist, redet man ziemlich schnell über echtes Geld. Die Höhe der Kosten für die Grundversorgung in der Cloud kann überraschen, genauso wie eine unerwartet hohe Stromrechnung. Das hat die Notwendigkeit für Sysadmins wiederbelebt, Performance- und Kapazitätsmanagement zu betreiben. Diesmal aber mit Blick auf Cloudapplikationen.
Dieser Artikel zeigt, wie es durch Kombination von Produktionsdaten aus der Java Management Extension (JMX, [1]) mit einem kundenspezifischen Performancemodell möglich wird, für einen Linux-basierten Tomcat-Cluster [2] unter AWS [3] die optimale Konfiguration zu bestimmen. Sobald das Modell etabliert ist, ermöglicht es die fortlaufende Kosten/Nutzen-Analyse verschiedener EC2-Autoscaling-Policies.
Die gesamte Applikation dieses Beispiels läuft in der Amazon-Cloud. Nutzer mit Smartphones lösen dabei Anfragen an Apache Webserver (Versionen 2.2 und 2.4) aus, die Amazons Elastic Load Balancer (ELB) in der Elastic Compute Cloud (EC2) verteilt. Dort arbeiten auch die Tomcat-Server (Versionen 7 und 8), die eine Vielzahl externer Services Dritter aufrufen. Das können beispielsweise Hotelbuchungen oder Anfragen an Autoverleiher sein. Die Anzahl laufender EC2-Instanzen wird durch Autoscaling (A/S) kontrolliert, das sich seinerseits nach dem Umfang des eingehenden Smartphone-Traffic und der konfigurierten A/S-Policies richtet.
Die Architektur der Applikation
Beim Betrachten des Beispiels kann sich der Analyst auf eine einzelne EC2-Instanz konzentrieren. Der Load Balancer sorgt dafür, dass sich die anderen Instanzen identisch verhalten. Abbildung 1 zeigt eine Übersichtsdarstellung. Die wesentlichen Komponenten der Architektur sind dabei (von oben nach unten):
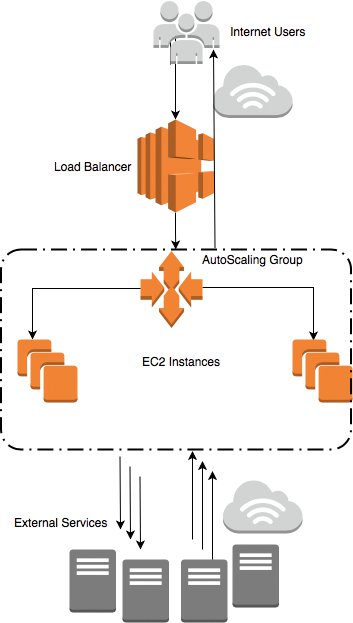
Abbildung 1: Übersichtsdarstellung der Architektur der Applikation.
1. Smartphonenutzer im Internet starten Anfragen an die Cloudapplikation.
2. Eingehende Anfragen verteilt ein Load Balancer im virtuellen AWS-Cluster.
3. Die Autoscaling-Gruppe reguliert die Clustergröße.
4. Tomcat-Server laufen auf EC2-Instanzen innerhalb der Autoscaling-Gruppe.
5. Sie kommunizieren mit externen Services Dritter.
Auf einer individuellen EC2-Instanz behandeln sowohl der Apache Webserver als auch der Tomcat-Server den eingehenden Request eines Smartphonenutzers. Der Tomcat-Server sendet dann seinerseits mehrere Anfragen an die externen Services, je nach dem ursprünglichen Wunsch des Smartphonenutzers. Die externen Services antworten und der Tomcat-Server berechnet daraufhin entsprechend einer Geschäftslogik irgendetwas aus den Antworten und gibt dieses Endresultat schließlich an den Smartphonenutzer zurück.
Performance-Tools
Weil Tomcat eine Java-Applikation ist, kann der Admin ausgiebig Gebrauch vom JMX-Interface machen, um Daten von der JVM zu erhalten. Das geht über:
- Jmxterm
- Visual VM
- Java Mission Control
- Datadog Dd-agent
- Kundenspezifische Skripte
Daneben kommen auch noch andere Open-Source-Performancetools zum Einsatz (Tabelle 1).
|
Tool |
Zweck |
|---|---|
|
Datadog |
Datenmonitoring, das auch die Metriken von AWS Cloud Watch integriert |
|
Collectd |
Sammeln von Performancedaten unter Linux |
|
Graphite |
Sammeln und Speichern von Metriken der Applikation |
|
Grafana |
Interaktive grafische Darstellung der Performancedaten als Zeitreihen |
|
R |
Statistische Analyse |
|
R Studio |
IDE für die Programmierung unter R |
|
PDQ |
Pretty Damn Quick; Bibliothek für die Performance-Modellierung |
Die Ausgangsdaten sammelt hauptsächlich der Datadog Dd-Agent [4]. Daraus leitet sich der Input für das Performancemodell ab, das in PDQ [5] geschrieben ist. Anfragen der Smartphonenutzer behandelt es als homogenen Workload.
JMX [6] beinhaltet ein verwaltetes Bean- oder MBean-Objekt namens »GlobalRequestProcessor«, das zwei Rohmetriken liefert:
- »requestCount«: die Gesamtzahl der Anfragen (C)
- »processingTime«: Gesamtverarbeitungszeit für alle Anfragen (Tproc )
Die durchschnittlichen Anforderungen pro Sekunde, Xdat , werden durch Konvertierung von »requestCount« in eine Rate in der Datadog-Konfiguration ermittelt. Die durchschnittliche Antwortzeit Rdat , leitet sich in jedem Sample-Intervall Tsample ab, und zwar aus:
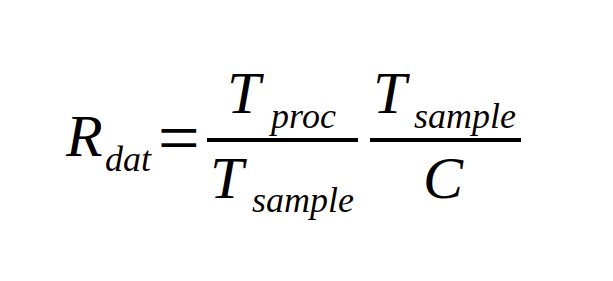
Nun kommen zwei Varianten [7] von Little’s Law zum Einsatz. Little’s Law ist ein wichtiges Gesetz in der Warteschlangentheorie, das besagt: Die Anzahl der Kunden oder Prozesse in einem Warteschlangensystem entspricht der Ankunftsrate multipliziert mit der durchschnittlichen Verweildauer eines Kunden oder Prozesses im System. Die beiden hier verwendeten Varianten sind:
- Die makroskopische Version N=X*R, die definiert ist durch den umfassenderen Begriff der Antwortzeitzeit R.
- Die mikroskopische Version U=X*S, die definiert ist in Bezug auf die kleinteiligere Skala Servicezeit S.
Mit diesen Definitionen ([8], [9]) lassen sich zusätzliche Performance-Metriken aus den Rohdaten wie folgt herleiten. Das makroskopische Gesetz ergibt:
- Die geschätzte Anzahl konkurrierender Requests in Tomcat Nest während eines Messintervalls.
- Die Bestätigung, dass Nest gleich der gemessenen Anzahl von Threads in Tomcat Ndat ist.
Das mikroskopische Gesetz ergibt folgende Ergebnisse:
- Die von Dd-Agent gemessene Prozessorauslastung Udat als dezimalen Anteil, nicht als Prozentwert.
- Die Bestätigung, dass der via JMX erfasste Durchsatz dasselbe ist wie Xdat
- Die geschätzte Servicezeit aus der Beziehung Sest = Udat / Xdat .
Das Ergebnis all dieser Datenextraktionen sind die Performance-Kennzahlen in Tabelle 2, die zur Parametrisierung der Performance-Modelle nötigt sind.
|
Timestamp |
Xdat |
Nest |
Sest |
Rdat |
Udat |
|---|---|---|---|---|---|
|
1486771200000 |
502.171674 |
170.266663 |
0.000912 |
0.336740 |
0.458120 |
|
1486771500000 |
494.403035 |
175.375000 |
0.001043 |
0.355975 |
0.515420 |
|
1486771800000 |
509.541751 |
188.866669 |
0.000885 |
0.360924 |
0.450980 |
|
1486772100000 |
507.089094 |
188.437500 |
0.000910 |
0.367479 |
0.461700 |
|
1486772400000 |
532.803039 |
191.466660 |
0.000880 |
0.362905 |
0.468860 |
|
1486772700000 |
528.587722 |
201.187500 |
0.000914 |
0.366283 |
0.483160 |
|
1486773000000 |
533.439054 |
202.600006 |
0.000892 |
0.378207 |
0.476080 |
|
1486773300000 |
531.708059 |
208.187500 |
0.000909 |
0.392556 |
0.483160 |
|
1486773600000 |
532.693783 |
203.266663 |
0.000894 |
0.379749 |
0.476020 |
|
1486773900000 |
519.748550 |
200.937500 |
0.000895 |
0.381078 |
0.465260 |
Der Zeitraum zwischen Timestamps der Zeilen in Tabelle 2 beträgt 300 Sekunden. Hier bestätigt wiederum Little’s Law die Beziehungen zwischen den Metriken: Nest =Xdat * Rdat gemäß der makroskopischen Version und Udat =Xdat * Sest gemäß der mikroskopischen Version, in beiden Fällen mit Zeiten gemittelt über das Sample-Intervall Tsample =300 Sekunden.
Verschiedene Sichten der Daten
Die Abbildungen 2, 3 und 4 zeigen Performance-Metriken, wie sie ein typisches Monitoringtool ermittelt, in einer zeitabhängigen Sicht mit Nebenläufigkeit oder Parallelität (Concurrency, N), Durchsatz (X) und Antwortzeit (R) auf der y-Achse und der Zeit auf der x-Achse. Diese View zeigt, wie sich die Metriken entwickeln, also zu welchem Zeitpunkt welcher Wert erscheint.
Abbildung 3: Zeitabhängige Kurve des Durchsatzes.
Im Kontrast zu dieser kanonischen Ansicht der gesammelten Daten zeigen die Abbildungen 5, 6 und 7 dieselben Metriken in einer zeitunabhängigen oder Steady-State-Sicht mit Nebenläufigkeit, Durchsatz und Antwortzeit als Funktion der Belastung (Load) auf der x-Achse. Zu dieser Sicht gelangt man durch eine Transformation, die einen bestimmten Zeitpunkt in den gesammelten Daten auswählt und die zugehörigen Werte für X und R ermittelt. Auf diese Weise ist der Faktor Zeit inbegriffen.

Abbildung 5: Zeitunabhängige Kurve der Nebenläufigkeit.
Das Steady-State-Profil der Metrik Durchsatz, X, ist eine konkave Funktion (Abbildung 6). In Bezug zur x-Achse formt die Kurve einen Buckel. Sie startet mit einem fast linearen Anstieg bei kleinen Belastungen und bildet schließlich ein Plateau, wenn die Auslastung einer Schlüsselressource hundert Prozent erreicht und in die Sättigung gelangt. Damit entsteht ein Flaschenhals.
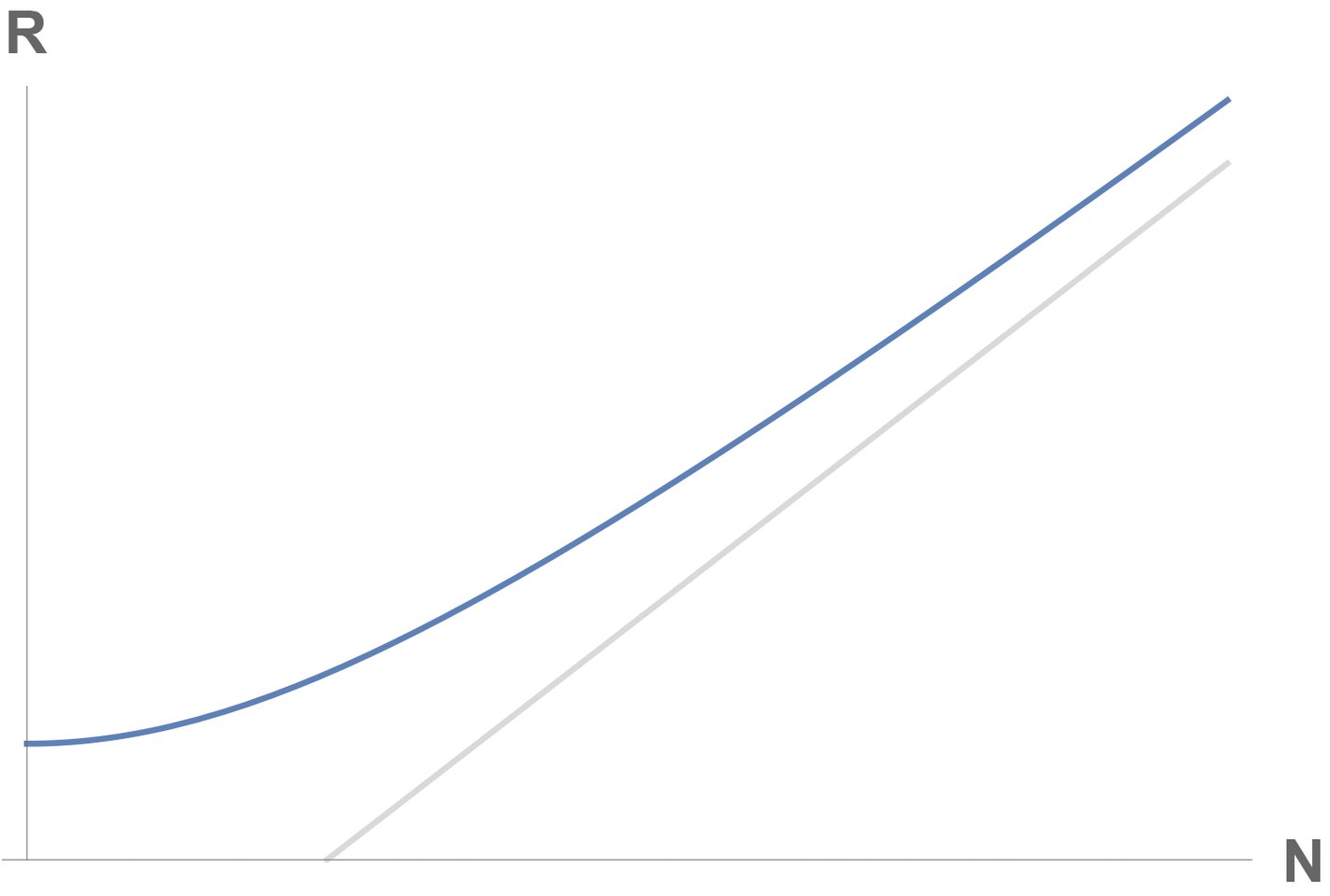
Abbildung 6: Zeitunabhängige Kurve des Durchsatzes.
Im Unterschied dazu ist die Steady-State-Kurve der Antwortzeit, R, konvex. Sie startet mit einem Plateau und steigt dann wegen steigender Queuelängen linear zur Sättigung hin an. Diese Kurve wird wegen ihrer Form oft auch Hockeyschläger-Kurve genannt [9].
In aller Kürze könnte man sagen: Sobald jemand die Steady-State-View der Produktionsdaten hat, kann ihm die Queueing-Theorie verraten, was zukünftig zu erwarten ist.
Performance-Modelle
Im Folgenden soll die Cloudapplikation mit Hilfe des PDQ-Performance-Modelling-Tools und der Sprache R untersucht werden (siehe Kasten “PDQ-Bibliothek in R”).
PDQ-Bibliothek in R
PDQ (Pretty Damn Quick) ist ein Modellierungstool für die Analyse der Performance von Rechner-Ressourcen wie Prozessoren, Platten oder Gruppen von Prozessen, die diese Ressourcen beanspruchen. Ein PDQ-Modell lässt sich mit Hilfe von Algorithmen aus der Queueing-Theorie analysieren. Die aktuelle Release erlaubt das Erstellen solcher Performancemodelle in C, Perl, Python und R. Die Beispiele dieses Artikels benutzen Funktionen wie folgende:
- »pdq::Init()« initialisiert interne PDQ-Variablen.
- »pdq::CreateOpen()« erzeugt einen Workload.
- »pdq::CreateNode()« erzeugt einen Server.
- »pdq::SetDemand()« setzt die Workload-Servicezeit der Server-Ressource.
- »pdq::Solve()« berechnet Performance-Metriken.
- »pdq::Report()« erzeugt einen generischen Report.
Weitere Informationen finden sich auf der Website http://www.perfdynamics.com/Tools Überblick: http://…com/PDQ.html, Download: http://…com/PDQcode.html,Manual:http://…com/PDQman.html
Hinweis: Der Autor dieses Artikels und Paul J. Puglia entwickeln und pflegen PDQ seit 2012.
Hintergrundinformationen und Beispiele, wie PDQ mit Perl oder Python zu verwenden ist, finden sich in früheren Artikeln des Linux-Magazins [8] und der Linux Technical Review [10]. Käufer der DELUG-Ausgabe des Linux-Magazins finden [10] als PDF sowie PDQ für Python auf der beiliegenden DVD.
Für diesen Artikel ist Python für R erste Wahl, weil R verschiedenste Datenformate (entweder als Text oder als Datenbankabfrage) verarbeitet, eine riesige Menge statistischer Funktionen auf diese Daten anwenden und die PDQ-Modellparameter aus ihnen extra extrahieren kann und die numerischen Resultate visualisiert – alles mit einem Skript.
Mit guten Gründen ist zu fragen, ob sich PDQ überhaupt auf moderne Cloudarchitekturen anwenden lässt. Aus Sicht der Queueing-Theorie lässt sich ein Computer als gerichteter Graph aus individuellen Puffern ansehen, in denen Anforderungen darauf warten, dass sich eine geteilte Ressource ihrer annimmt. Ein solcher Puffer könnte etwa eine lokale Festplatte sein. Weil ein Puffer das Gleiche ist wie eine Warteschlange, lässt sich jeder Computer als gerichteter Graph von Warteschlangen (Queues) darstellen. Die Kanten des Graphen bilden Datenflüsse zwischen den Ressourcen. Ein solcher gerichteter Graph aus Queues wird manchmal auch Queueing Network Model genannt.
Aus Sicht der Performance-Modellierung ist die Cloud nur eine Ansammlung von virtualisierten Servern am anderen Ende des Internets ([11], [12], [13]). Darüber hinaus beinhaltet die Virtualisierung meist einen Hypervisor, beispielsweise den Xen-Server in Abbildung 8.
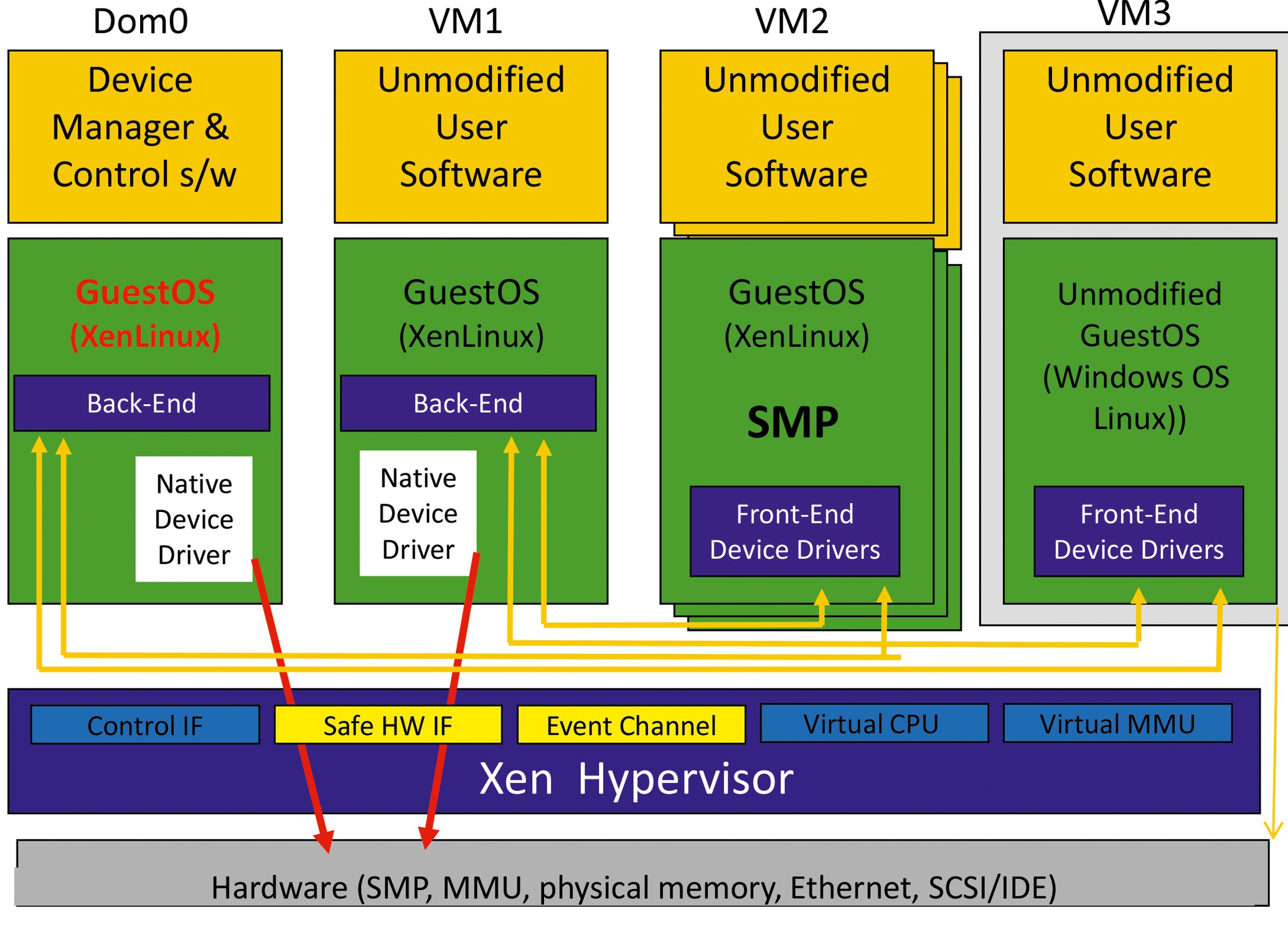
Abbildung 8: Die Architektur eines Xen-Hypervisors in der Übersicht.
Hypervisoren beschäftigen einen Fair-Share-Scheduler (http://14, Kap. 7). Ein solcher Scheduler ist notwendig, um mit allen Instanzen der virtuellen Maschinen, die ihrerseits jeweils eine eigene Instanz von Linux oder einen anderen Betriebssystem-Scheduler enthalten, über den zugrunde liegenden Hardware-Ressourcen zu jonglieren – besonders über Bare-Metal-Prozessoren. AWS Cloud Watch liefert Leistungskennzahlen aus der Sicht des Hypervisors ([15], [16]).
Aus der Perspektive des Betriebssystems rangiert ein Fair-Share-Scheduler irgendwo zwischen einem Batch-Scheduler (wie er in Mainframes zu finden war) und einem Standard-Time-Share-Scheduler (wie ihn Linux benutzt). Ein Batch-Scheduler lässt keine Verarbeitungsunterbrechungen zu. Demgegenüber dreht sich bei einem Time-Share-Scheduler alles gerade um die Unterbrechungen (nach einem bestimmten Quantum Zeit), die jedem Benutzer die Illusion vermitteln, er sei der einzige aktive Benutzer auf dem System [14].
Trotz all dieser verschiedenen Scheduler erweist sich das Performance-Modell der Tomcat-Anwendung letztlich als viel einfacher als erwartet. Obwohl die Autoscalinggruppe in Abbildung 1 aus mehreren EC2-Instanzen besteht, sind alle diese Instanzen nur Replikationen der gleichen Tomcat-Anwendung. Zudem tun sie auch alle das Gleiche. Wäre das nicht der Fall, würde das bedeuten, dass der Load Balancer fehlerhaft arbeitete. Daraus folgt, dass der Analyst nur eine einzelne EC2-Instanz zu untersuchen braucht, um damit herauszubekommen, wie der gesamte AWS-Cluster performt.
Die PDQ-Warteschlangen-Darstellung der Tomcat-Anwendung auf einer einzigen EC2-Instanz zeigt Abbildung 9. Ausgehend vom oberen Teil des Diagramms sind die folgenden symbolischen Komponenten identifizierbar:
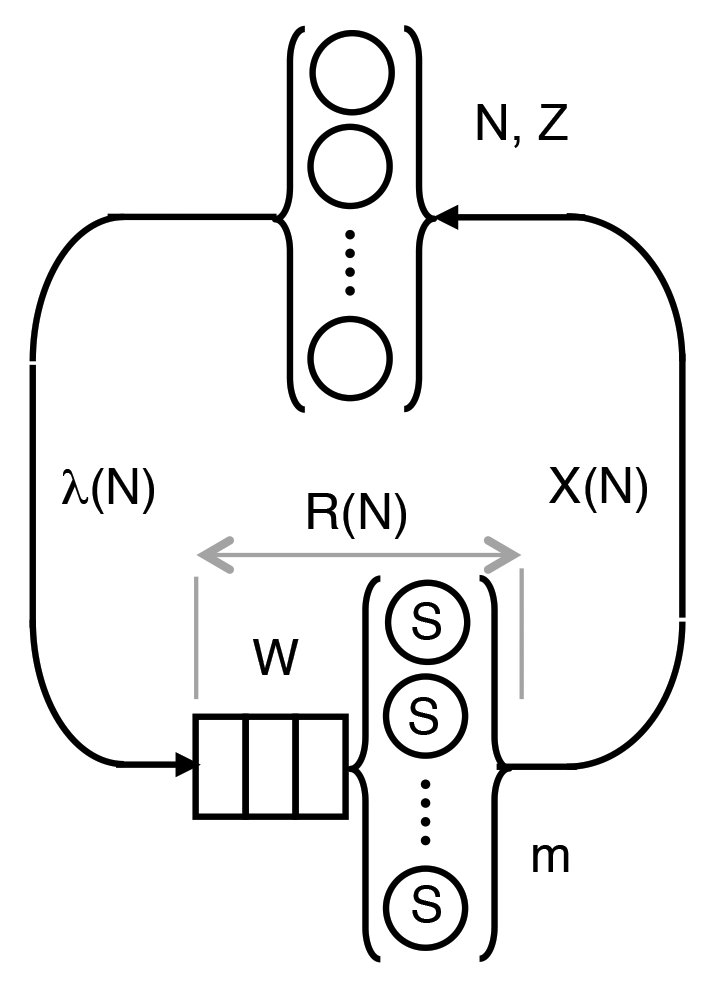
Abbildung 9: Das Queueing-Modell der Tomcat-Threads.
1. N. Benutzeranfragen sind hier schematisch in Form von Kreisen innerhalb der oberen geschweiften Klammern dargestellt. Über einen Zeitraum von 24 Stunden kann N typischerweise Werte zwischen 100 und 500 Anfragen annehmen. N erreicht nie 0, da es aufgrund verschiedener Zeitzonen immer eine gewisse Aktivität gibt. In jedem Stichprobenintervall kann es immer nur eine begrenzte Anzahl von Anforderungen im System geben.
2. Z bezeichnet die Bedenkzeit des Benutzers: die Zeit zwischen der Antwort auf eine vorherige Anfrage und der nächsten. Ein typisches Beispiel ist die Verzögerung bei einem Benutzer, der eine angeforderte Webseite sieht und seinem Klick auf einen Hyperlink auf dieser Webseite. Im Falle der vorliegenden Tomcat-Anwendung sind die Smartphonenutzer außerhalb von Abbildung 9, sodass es in diesem PDQ-Modell von Tomcat-Threads keine formale Bedenkzeit gibt, das heißt also: Z=0.
3. Bei den Kreisen am unteren Rand von Abbildung 9, gibt m die maximale Anzahl der Tomcat-Threads an, die für Serviceanfragen von Benutzern zur Verfügung stehen. Darüber hinaus müssen im Gegensatz zu den Kreisen im oberen Teil der Illustration hier Anfragen auf den Service warten. Diese Wartequeue oder der Puffer ist durch die Rechtecke links neben den Kreisen für die Threads dargestellt. Weitere Informationen zu diesem Thema gibt es im Abschnitt “Wo warten sie?”.
4. Die durchschnittliche Servicezeit für einen Tomcat-Thread wird durch S angegeben.
5. Diese Servicezeit S zusammen mit einer eventuell anfallenden Wartezeit W entspricht der durchschnittlichen Antwortzeit R=W + S.
6. Die Rate der Anfragen, die in die unteren Thread-Warteschlange eingehen, wird durch Lambda spezifiziert.
7. Der Systemdurchsatz wird mit X bezeichnet. Es ist vernünftigerweise davon auszugehen, dass die EC2-Instanz im stationären Zustand – das heißt ohne signifikante Transienten – läuft, sodass Lambda gleich X ist.
Für den Zweck dieses Artikels empfiehlt sich eine Konzentration auf die Performance-Charakteristik von X und R in Bezug auf die Last N. Die funktionale Abhängigkeit von der Last sollen die Schreibweisen X(N) und R(N) kenntlich machen.
Im Allgemeinen erhält jede Benutzeranfrage einen Tomcat-Thread, sobald sie im System ankommt. Da es keine Wartezeit W gibt, ist in diesem Fall die Antwortzeit R gleich der Servicezeit S. Es ist allerdings möglich, dass mehr Anfragen N im System ankommen, als Threads m verfügbar sind.
Kalibrieren des PDQ-Modells
Abbildung 10 zeigt die erste Stichprobe von Produktionsdaten aus dem Jahr 2016: Eine veritable Wolke von Datenpunkten mit N im Bereich von 100 bis 450 Benutzeranfragen. Da es sich um Durchsatzmessdaten handelt, weist der Scatterplot ein konkaves Profil auf, in Übereinstimmung mit den durch Abbildung 6 illustrierten Erwartungen.
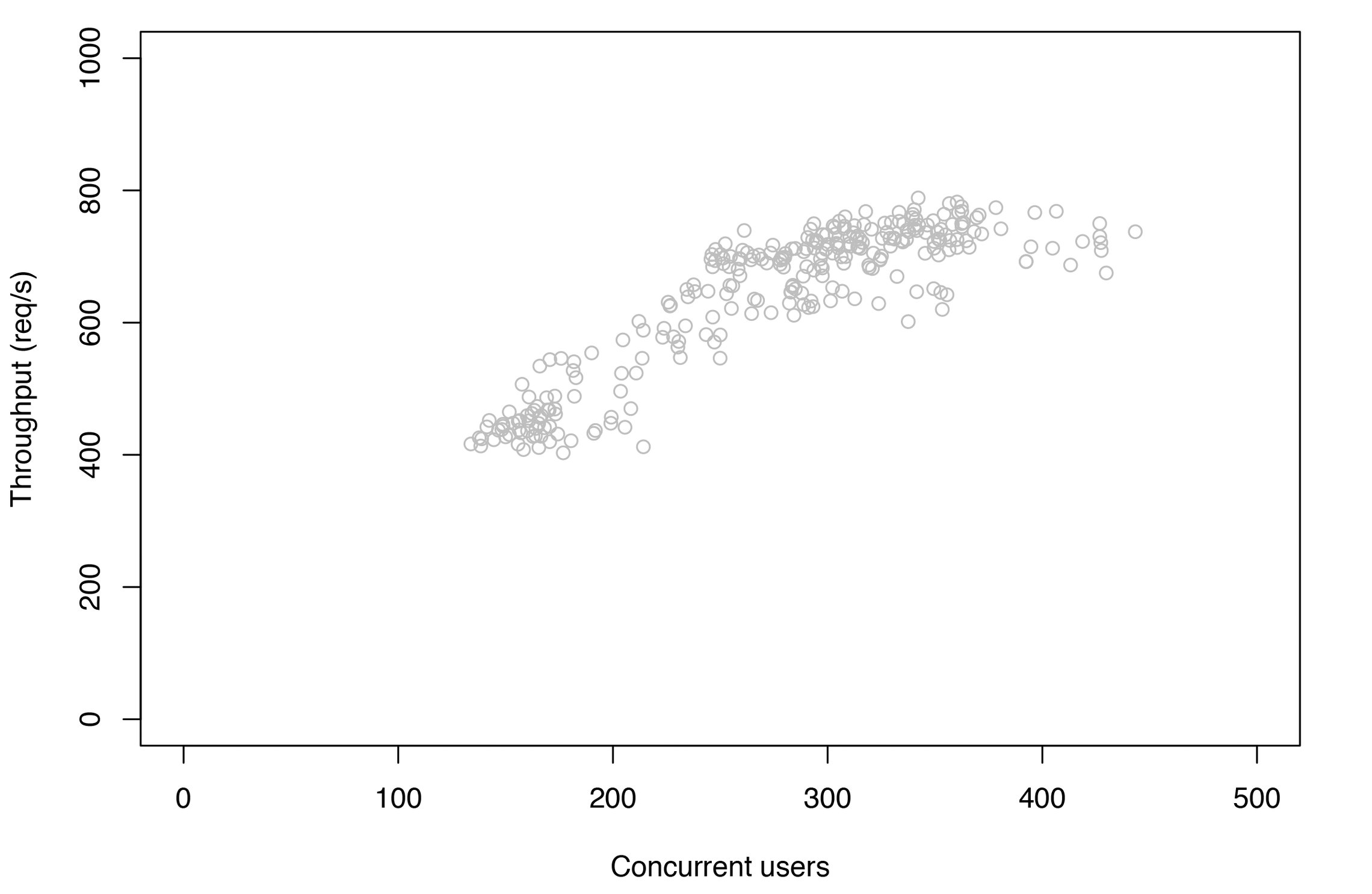
Abbildung 10: Stichprobe von Durchsatzmessdaten aus der Produktion.
Das initiale PDQ-Modell in Abbildung 11 unterstützt diese Vorstellung. Und genauso zeigt das Modell für die korrespondierenden Antwortzeitdaten annähernd die erwartete Hokeyschlägerform.
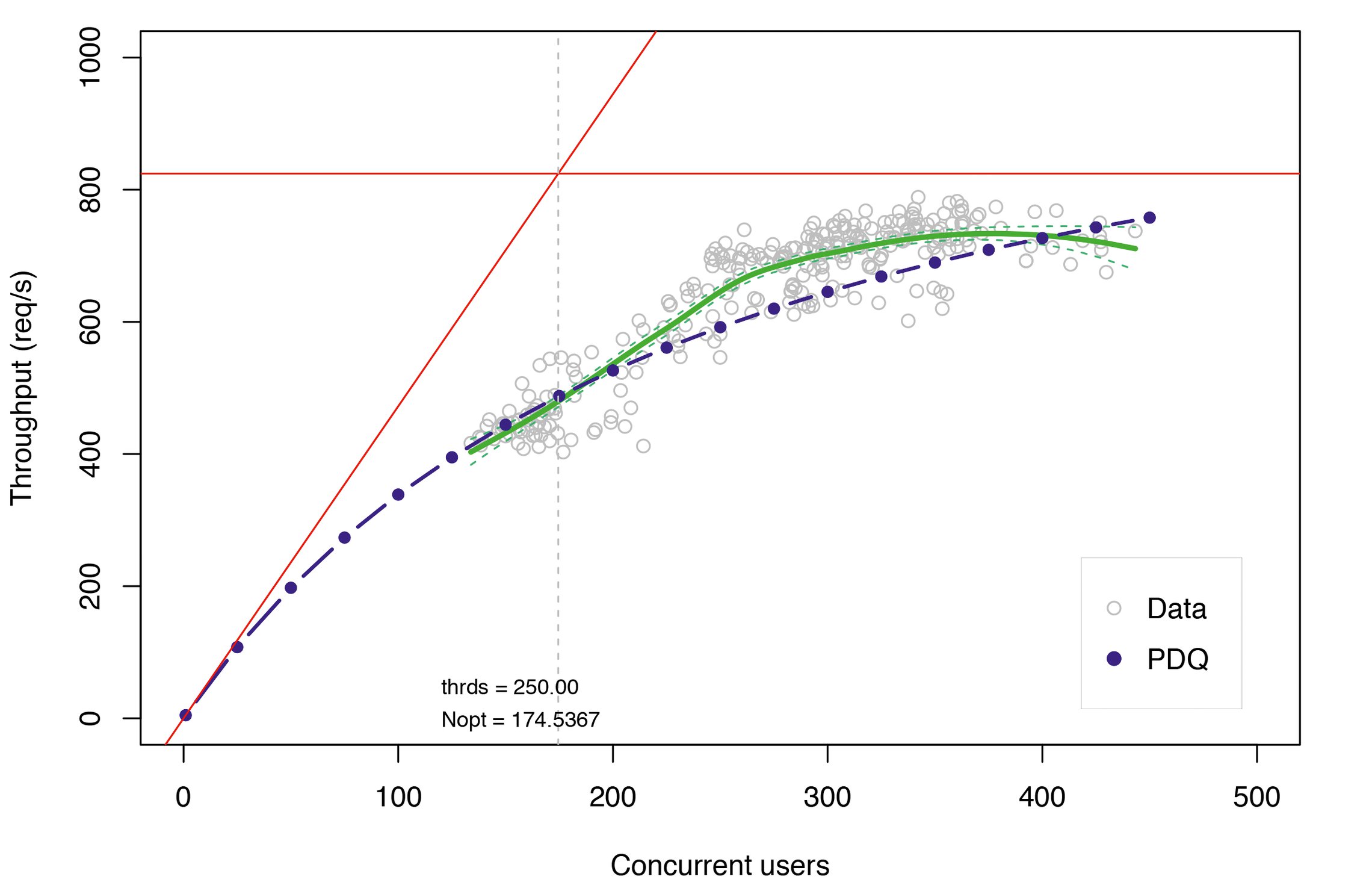
Abbildung 11: Das Durchsatz-Modell. Berechnete Werte sind blau, gemessene Daten grau, Trend grün.
Obwohl das initiale Modell die generellen Erwartungen erfüllt, bleiben ein paar Fragen offen. So entspricht das Modell nicht ganz der Abbildung 9. Tatsächlich benötigte das Modell viele zusätzliche Warteschlangen, um auf die beobachtete minimale Reaktionszeit von Rmin = 0,45 Sekunden zu kommen.
Daraus ergibt sich die Frage, was diese zusätzlichen Warteschlangen im realen Tomcat-Server darstellen. Zwei unterschiedliche Interpretationen scheinen möglich:
- Abfrage externer Dienste
- Verborgene Parallelität
Zum Beispiel kann man die Daten der letzten Zeile in Tabelle 2 betrachten, Die CPU-Auslastung unter Linux beträgt da Udat = 0,4653 (oder 46,53 Prozent), und der korrespondierende Durchsatz ist Xdat = 519,75 Anfragen pro Sekunde. Damit lässt sich die mittlere Bedienzeit unter Zuhilfenahme von Little’s mikroskopischem Gesetz veranschlagen als:
X <- 519.748550 U <- 0.465260 U/X [1] 0.0008951636
Das Ergebnis wird noch aufgerundet auf 0,001, das impliziert SCPU = 1 Millisekunde.
Wenn ein Tomcat-Thread einen externen Service anfragt und jede Antwort ginge nach einer Bedienzeit von einer Millisekunde ein, dann wäre eine Kette von um die 200 zusätzlichen Warteschlangen nötig, um die minimale Reaktionszeit (horizontale rote Linie) in Abbildung 12 zu erreichen.
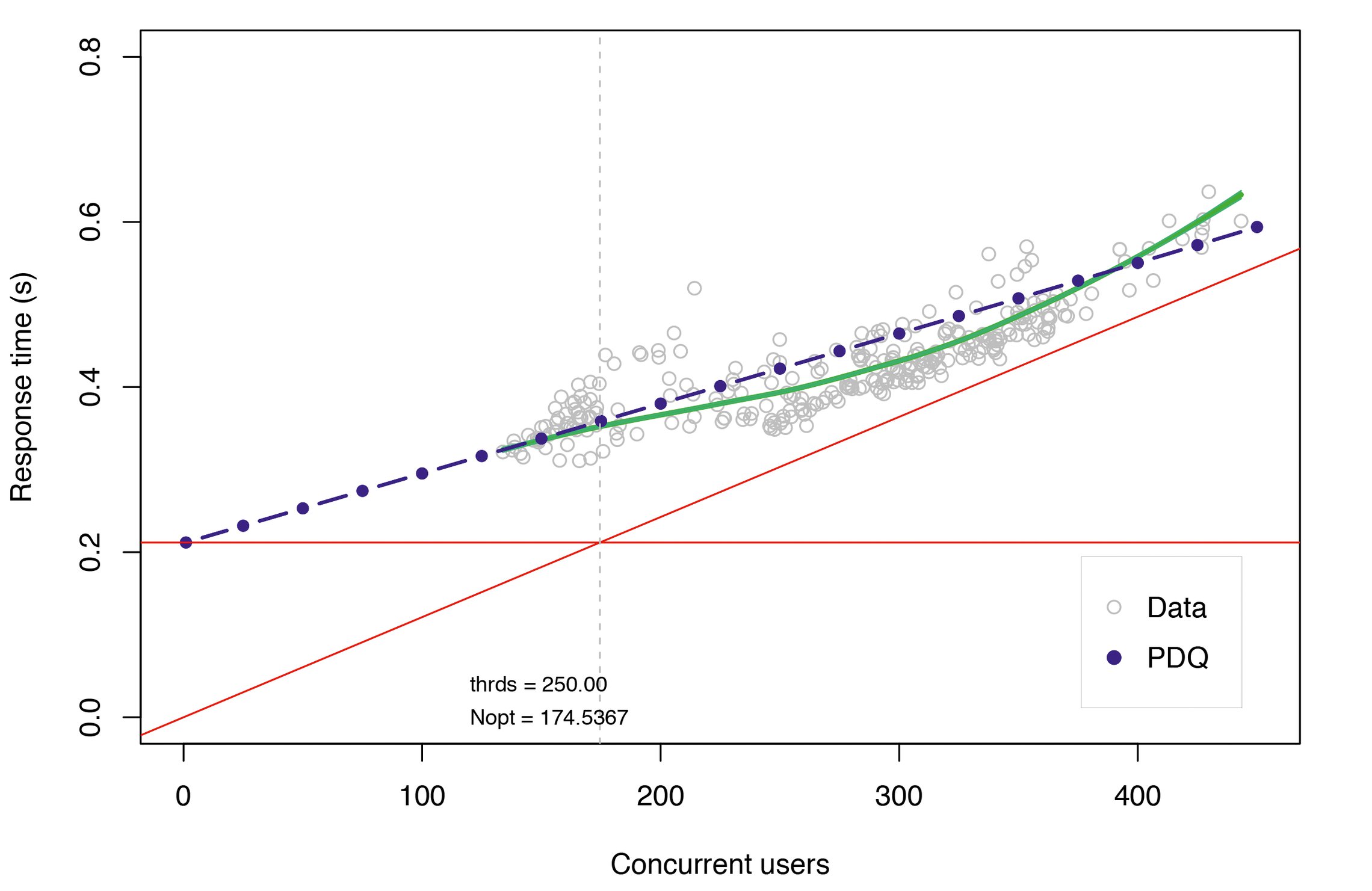
Abbildung 12: Das Antwortzeit-Modell. Berechnete Werte sind blau, gemessene Daten grau, Trend grün.
Die Interpretation als verborgene Parallelität ist um einiges subtiler. Der Kasten “Parallel ist nur seriell in schnell” erklärt die Hintergründe dazu. Die Interpretation gelang erst dann eindeutig, als einige Monate später ein neuer Satz von Leistungsdaten verfügbar war (Abbildungen 13, 14 und 15).
Parallel ist nur seriell in schnell
Aus der Sicht der Warteschlangentheorie lässt sich die Parallelverarbeitung als eine Form der schnellen seriellen Verarbeitung betrachten. Die Abbildung 16 zeigt links ein Paar paralleler Warteschlangen, die Anfragen, die von außen mit der Rate Lambda eingehen, gleichmäßig aufteilen, um mit reduzierter Rate Lambda/2 in eine der beiden Warteschlangen zu gelangen. Nun sei Lambda = 0,5 Anfragen/Sekunde und S = 1 Sekunde.
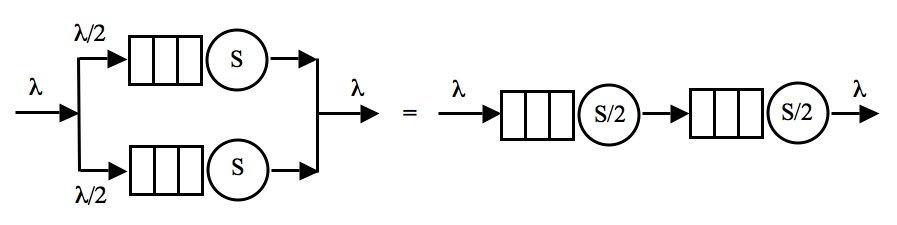
Abbildung 16: Beispiel paralleler und serieller Queue-Konfigurationen, die sich auf der numerischen Ebene in ihrem Effekt entsprechen
Wenn eine Anforderung das linke Ende einer der parallelen Warteschlangen erreicht, wird die erwartete Durchlaufzeit durch diese Warteschlange (Warte- + Service-Zeit) durch Gleichung (1) aus dem Artikel “Berechenbare Performance” [10] angegeben, nämlich mit:
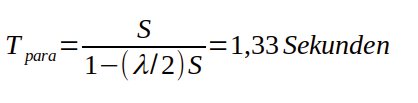
Die rechte Seite der Abbildung 16 zeigt zwei Queues in Reihenschaltung, jede doppelt so schnell wie die parallelen Queues. Weil die eingehenden Anforderungen nicht aufgeteilt werden, ist die benötigte Zeit für das Passieren beider Queues gleich der Summe der Zeiten, die in jeder einzelnen Queue verbracht werden:
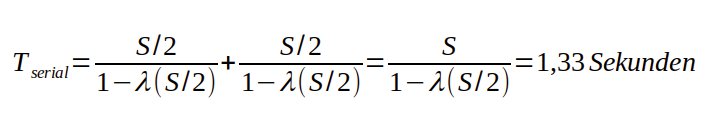
Tserial aus Gleichung 2 ist damit genauso groß wie Tpara in Gleichung 1. Umgekehrt bedeutet das, dass man die mehrstufige Serienverarbeitung in eine gleichwertige Form der Parallelverarbeitung umwandeln kann ([6], [8]). Diese Erkenntnis trug dazu bei, die versteckte Parallelität der Leistungsdaten von Juli und Oktober 2016 zu identifizieren, die zur Korrektur des ursprünglichen PDQ-Tomcat-Modells führte.
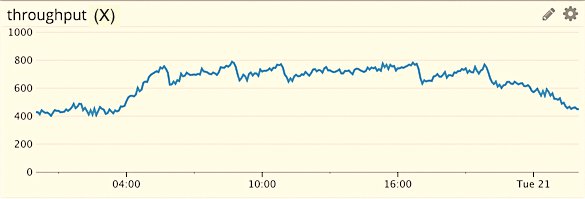
Abbildung 4: Zeitabhängige Kurve der Antwortzeit.
Validierung des Modells
Ohne hier zu sehr ins Details zu gehen, lässt sich sagen, dass ein Teil des oben beschriebenen Problems aus der ansonsten natürlichen Annahme herrührt, dass die CPU-Auslastung Udat eines Thread seine Servicezeit bestimmt.
Die neuen Durchsatzzahlen in Abbildung 13 sind ausgedünnter gegenüber denen in Abbildung 10 und deuten darauf hin, dass die Smartphone-Anfragen in diesem Zeitraum weniger zahlreich waren. Dank dieser Spärlichkeit wird deutlicher, dass die zusätzlichen Warteschlangen tatsächlich ein Zeichen für versteckte Parallelität waren. Und noch etwas deutet darauf hin: Serielle Queues würden die Durchsatzkurve unter einen linearen Anstieg fallen lassen. Parallele Queues hätten diesen Effekt nicht.
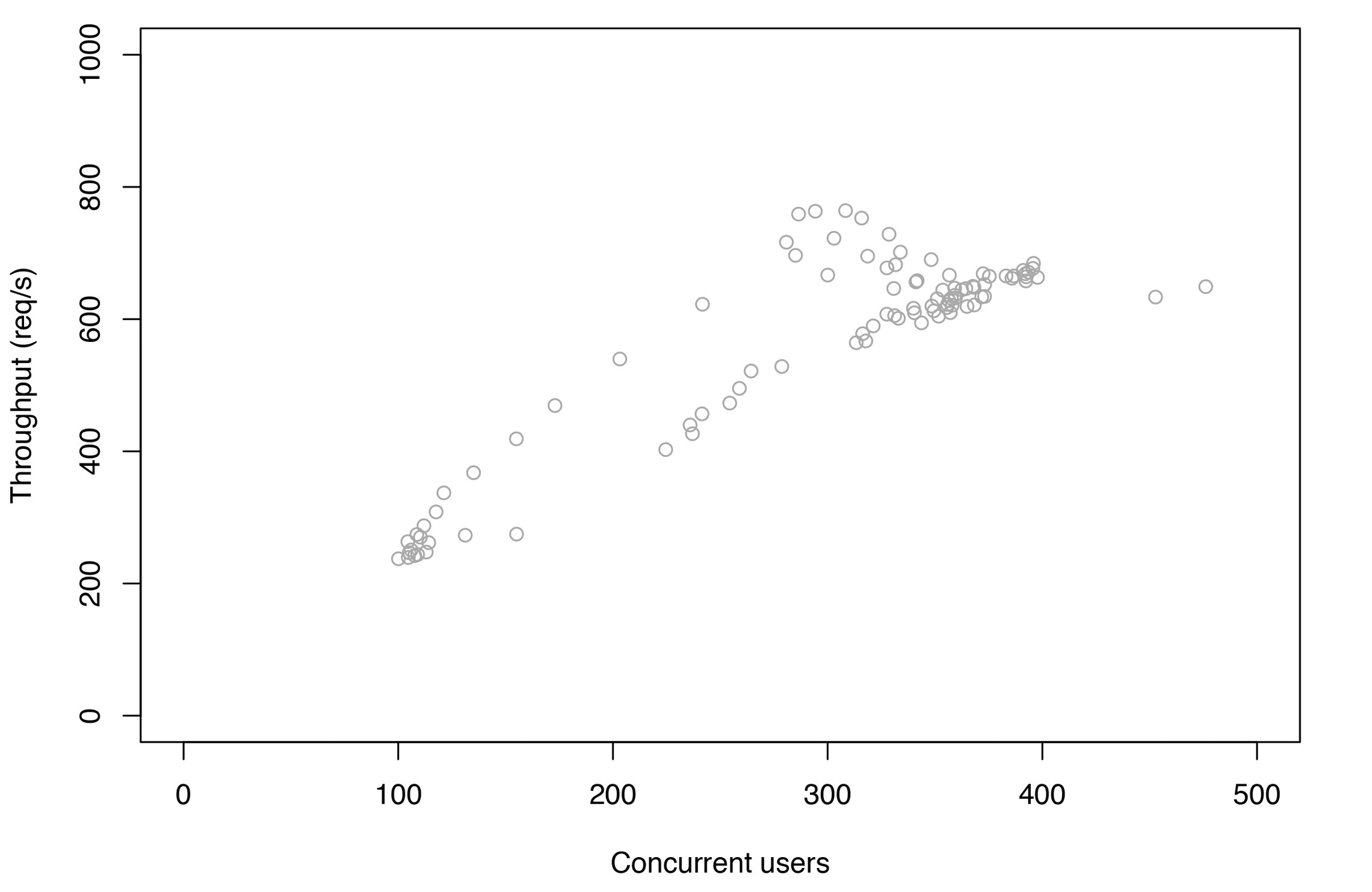
Abbildung 13: Durchsatzdaten aus der Produktion.
Weil nun der Anstieg in den neuen Daten klar linear verläuft (Abbildung 14), muss es sich um parallele Queues handeln, die hier im Spiel sind. Und die Quelle dieser Parallelität sind die Tomcat-Threads selbst. So wird ein Schuh draus!
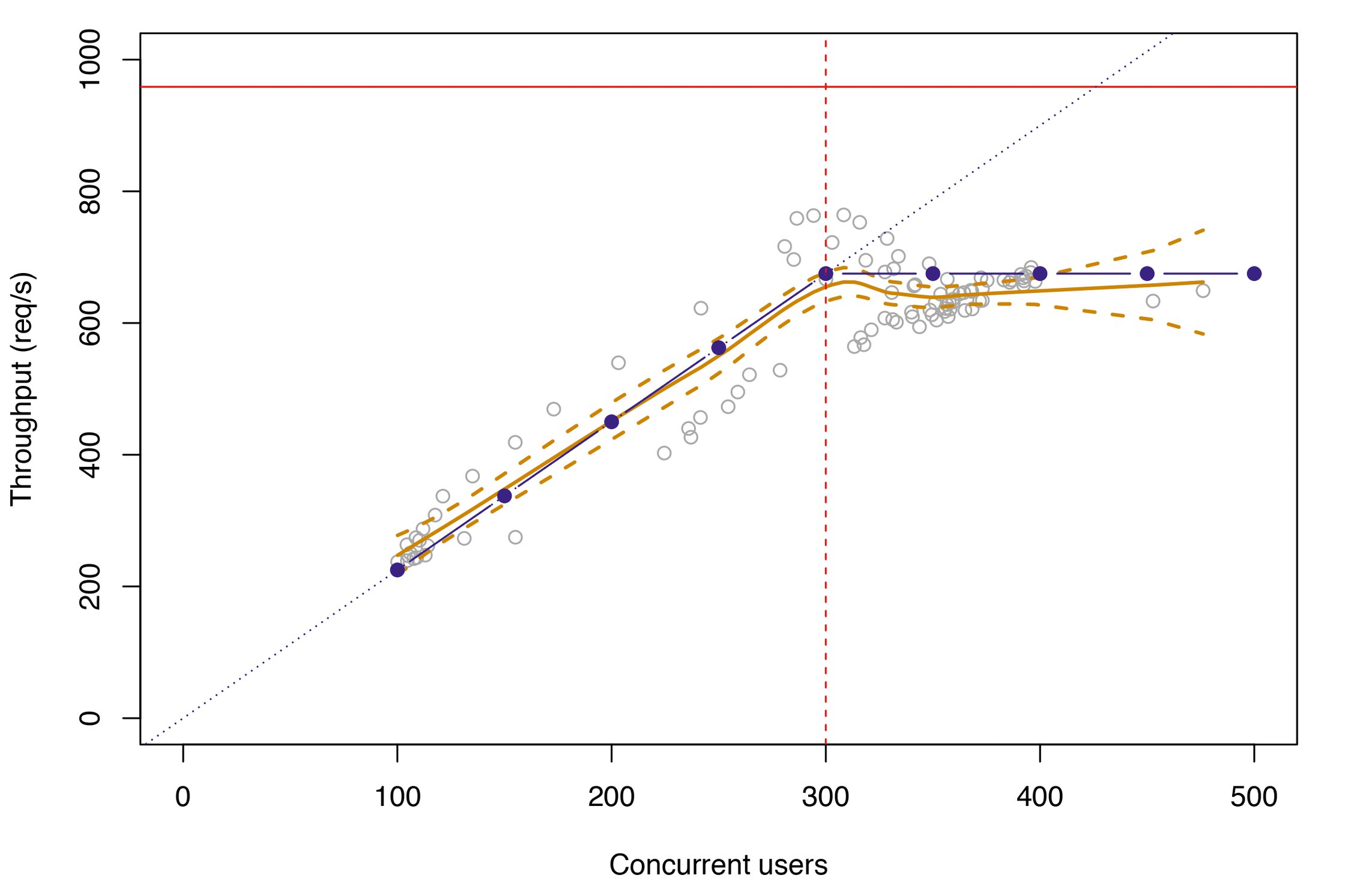
Abbildung 14: PDQ Durchsatz-Modell. Berechnete Werte blau, gemessene Daten grau, Trend grün.
Bis zu einem bestimmten Schwellenwert (auf den der Artikel gleich eingeht) bekommt jeder eingehende Smartphone-Request sofort einen Tomcat-Thread zugeordnet, und alle laufen gleichzeitig, also parallel. Diese Dynamik bewirkt eine subtile Veränderung des Steady-State-Profils des Durchsatzes.
Der parallele Durchsatz ist ein Sonderfall von Abbildung 6, bei dem die Form der Kurve von X zwar noch konkav ist (wie zuvor beschrieben), aber nicht gerundet. Stattdessen ist es ein linearer Anstieg bis zur Sättigung, der dann sofort in ein Plateau übergeht. Dieser Unterschied lässt sich gut in Abbildung 14 ablesen. Der Knickpunkt liegt bei diesen Daten bei rund NKnick = 300 Threads. Das anschließende Plateau korrespondiert mit konstantem Durchsatz.
Noch wichtiger ist, dass die blauen Punkte in Abbildung 14 mit dem Modell in Abbildung 9 berechnet sind und nun präzise das Verhalten der durchschnittlichen Durchsatzwerte vorhersagen. In gleicher Weise erkennbar wird nun im PDQ-Modell der Antwortzeit in Abbildung 15 die Hockeyschlägerform.
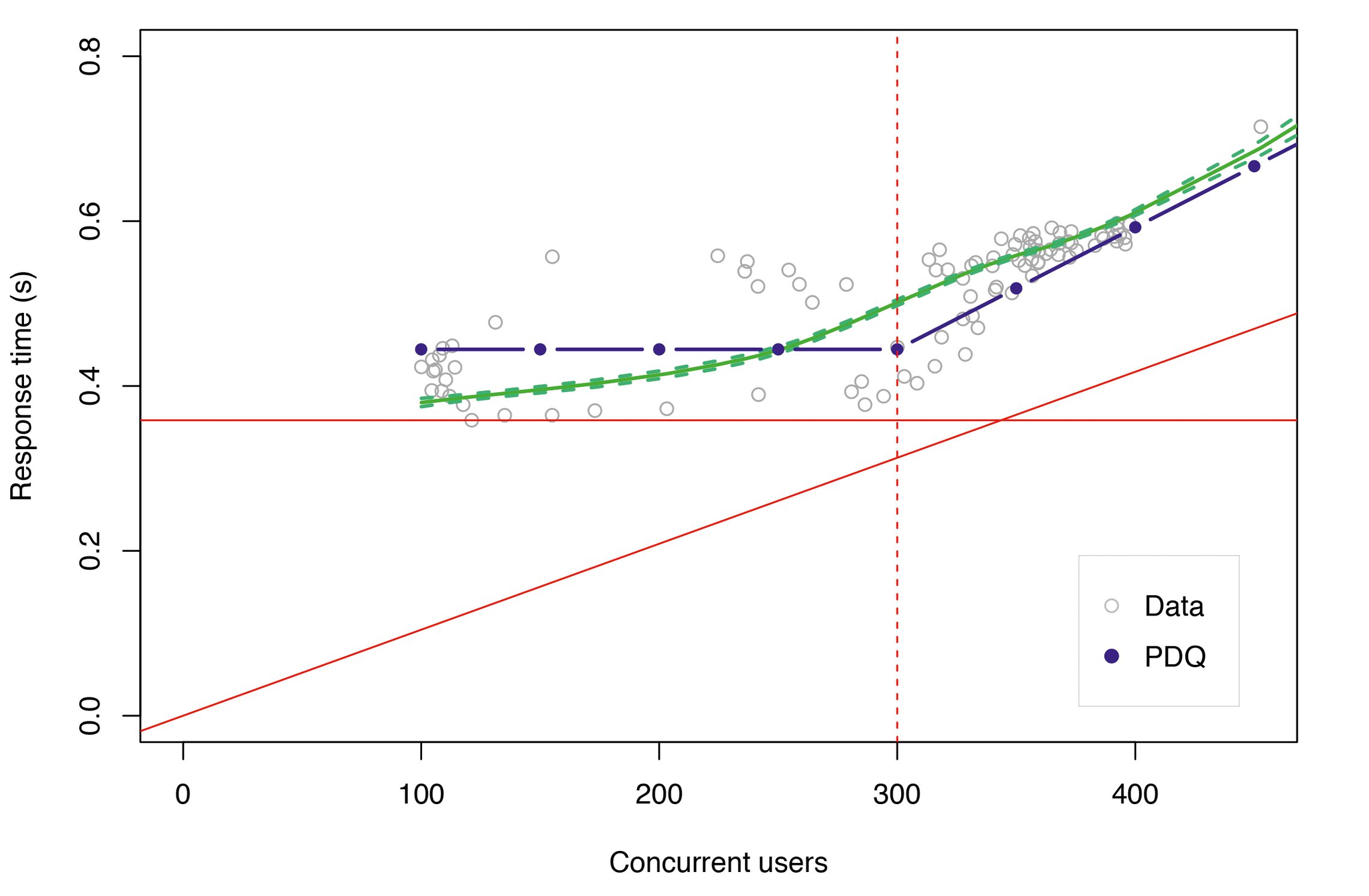
Abbildung 15: PDQ Antwortzeit-Modell. Berechnete Werte blau, gemessene Daten grau, Trend grün.
Das alles führte zu folgenden Änderungen am PDQ-Modell, das ausschnittsweise in Listing 1 zu sehen ist:
Listing 1
Ausschnitt aus dem PDQ-Modell
01 library(pdq)
02
03 usrmax <- 500
04 mknee <- 350
05 smean <- 0.4444 # Rmin seconds
06 srate <- 1 / smean
07 arate <- 2.1 # per user
08 users <- seq(100, usrmax, 50)
09 tp <- NULL
10 rt <- NULL
11 pdqr <- TRUE # issue PDWQ report
12
13 for (i in 1:length(users)) {
14 if (users[i] <= mknee {
15 Arate <- users[i] * arate # total arrivals
16
17 pdq::Init/"Tomcat Submodel")
18 pdq::CreateOpen("requests", Arate)
19 pdq::CreateMultiNode(users[i], "TCthreads")
20 pdq::SetDemand("TCthreads", "requests", smean)
21 [...]
- Die korrekte Bedienzeit STC wird nicht mehr aus der CPU-Auslastung abgeleitet. Stattdessen ist es die gesamte Zeit, in der Tomcat eine Anforderung abarbeitet, und diese Zeit dominieren die externen Services komplett. Daher gilt Rmin = STC .
- Aus den neuen Daten entnommen ist Rmin = 444,4 Millisekunden in Abbildung 17.
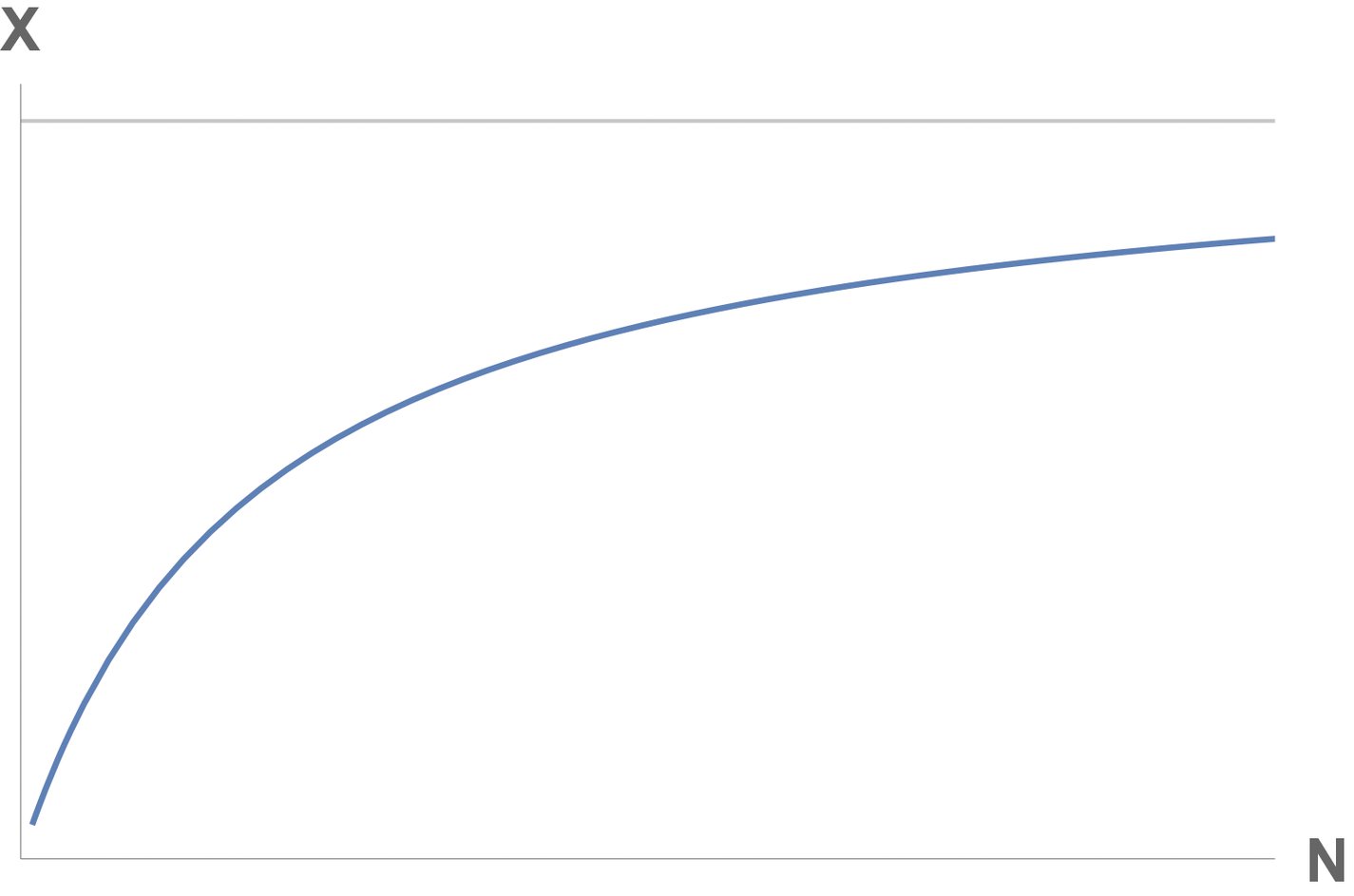
Abbildung 7: Zeitunabhängige Kurve der Antwortzeit.
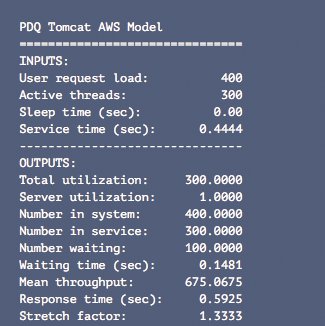
Abbildung 17: PDQ-Parameter für die 2016er Daten.
- Die parallele Ausführung der Tomcat-Threads wird durch das Modell aus Abbildung 9 korrekt abgebildet.
Natürlich könnten die bisherigen Leistungsdaten vom Juli 2016 mit diesem überarbeiteten PDQ-Modell neu bewertet werden, aber aus Platzgründen entfallen diese Details hier. Es hat eine gewisse Ironie, dass die Entwicklung des ersten PDQ-Modells eine falsche Wendung nahm, weil zu viele Daten vorhanden waren, die die Profile X(N) und R(N) getrübt haben. Der Leser sollte beachten, dass diese Art der Verwirrung bei dieser Art der Leistungsanalyse eher die Regel als die Ausnahme ist. Es gibt kein Richtig oder Falsch, sondern nur Fortschritte.
Voraussagen des PDQ-Modells
Mit dem validierten PDQ-Modell lässt sich die Leistung verschiedener AWS-Cloud-Konfigurationsoptionen untersuchen. Das ist im Allgemeinen ein mühsamer Prozess, weil er anwendungsabhängig ist. Der Artikel beschränkt sich daher auf die wichtigsten Ergebnisse.
Wie eingangs bereits erwähnt, waren A/S-Gruppen Teil der ursprünglichen Architektur in Abbildung 1. Insbesondere wird die A/S-Policy ausgelöst, wenn eine Tomcat-Instanz die CPUs zu mehr als 75 Prozent auslastet, das heißt Ucpu >=0,75 A/S. Dann starten automatisch zusätzliche EC2-Instanzen, um dem zunehmenden Smartphone-Verkehr über den Load Balancer zu begegnen.
Um dem UCPU -Schwellenwert zu entsprechen, starten keine zusätzlichen Tomcat-Threads oberhalb es Schwellenwerts neu, was NKnick = 254 Threads in Abbildung 14 und NKnick = 300 Threads in Abbildung 15 bedeutet. Wie schon beschrieben, führt das dazu, dass der Durchsatz der Instanzen in die Plateauphase oberhalb der Knicklinie übergeht.
Der Leser sollte beachten, dass diese Sättigung kein Effekt des nativen Linux ist. Der Linux-Timeshare-Scheduler ist nicht darauf ausgelegt, die Prozessorauslastung auf einen Wert unter 100 Prozent zu begrenzen. Stattdessen ist es einzig und allein das Autoscaling, also die A/S-Gruppe, die einen Knickpunkt bei einer Pseudo-Sättigung erzeugt. Wie ebenfalls weiter oben bereits diskutiert, ist das ein Feature eines Fair-Share-Schedulers, und das heißt, es lässt sich nur über einen Hypervisor erreichen (Abbildung 8) oder durch verwandten Code in AWS oder unter Linux durch so etwas wie die Control Groups [17].
Es gibt eine Vielzahl von versteckten Kosten, die mit A/S verbunden sind. Der Schwellenwert der A/S-Richtlinie, der auf der Prozessorauslastung basiert, ist nicht unbedingt das effizienteste Kapazitätskriterium. Zudem gibt es typischerweise eine Verzögerung von etwa 10 Minuten, bis zusätzliche EC2-Instanzen in Betrieb gegangen sind.
Basierend auf dem validierten PDQ-Modell kann sich der Admin überlegen, eine präventive EC2-Planung einzusetzen. Diese Richtlinie für geplante Skalierung (S/S) wird durch die Uhr in Abbildung 19 symbolisiert. S/S ist billiger als A/S mit einer typischen Einsparung von rund 10 Prozent an AWS-Gebühren.
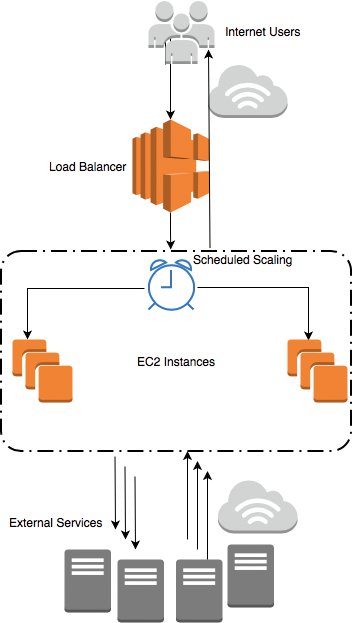
Abbildung 19: Gruppenbildung mit Scheduled Scaling.
Bei S/S sollte man die Anzahl der gleichzeitigen Tomcat-Dienst-Threads (N) verwenden, um die Anzahl der EC2-Instanzen zu ermitteln, die der eingehende Smartphone-Verkehr benötigt. Die Verwendung von S/S beseitigt auch beobachtete Spitzen – sowohl beim ankommenden Verkehr einer EC2-Instanz als auch bei der damit verbundenen EC2-Spin-up-Verzögerung.
Eine noch kostengünstigere Lösung stellen Amazons Spot Instances (S/I) dar, die Abbildung 20 schematisch darstellt. S/Is sind mit 90 Prozent Rabatt auf die On-Demand-Preise zu haben. Das S/I-Angebot ist motiviert durch den Versuch von Amazon, die Kosten für die eigene Infrastruktur zu decken [18].
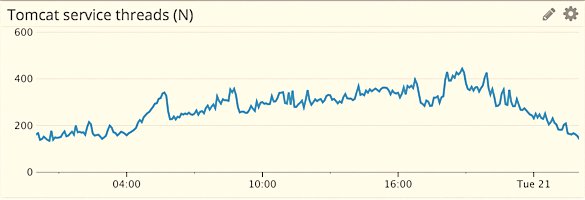
Abbildung 2: Zeitabhängige Kurve der Nebenläufigkeit.
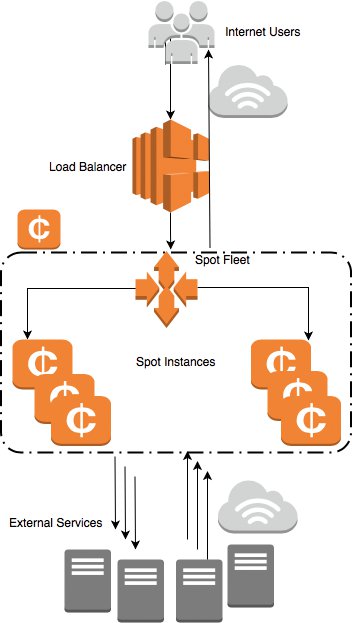
Abbildung 20: Gruppenbildung mit Spot Instance Grouping.
Wie Abbildung 21 zeigt, stellen reservierte Instanzen die einfachste Planbarkeit für Amazon dar. Die benötigte Kapazität ist bekannt. On-Demand-Kapazität stellt für Amazon ein höheres Risiko dar, da nicht alles davon auf die erwartete Art und Weise abgerufen werden mag.
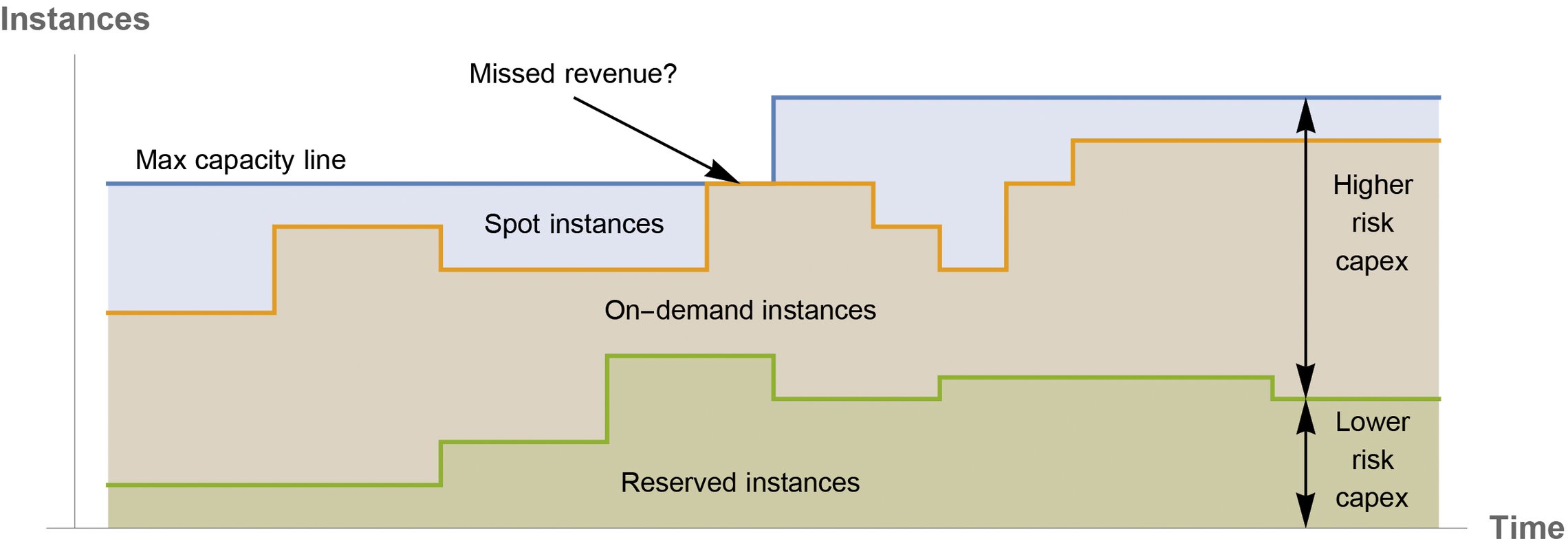
Abbildung 21: Die Kapazitätslevel der AWS-Infrastruktur haben unterschiedliche Preise.
S/I-Kapazität ist das, was zwischen der erwarteten Nachfrage und der maximalen physischen Kapazität übrig bleibt, und bildet somit das höchste Risiko für Amazon. Die Nachfrage nach diesem ungenutzten Spielraum schafft Amazon dadurch, dass es ihn den Kunden mit einem extrem hohen Rabatt anbietet.
Andererseits kann es für den Systemadministrator eine Herausforderung sein, die Instanztypen und -größen innerhalb einer Gruppe zu diversifizieren. So kann beispielsweise der Standardinstanztyp »m4.10xlarge« sein, während der S/I-Markt nur den kleineren »m4.2xlarge«-Instanztyp anbietet. Diese Situation kann eine manuelle Neukonfiguration der Anwendung erzwingen.
Schließlich ist der Gewinn dieser Art der Performance-Modellierung in den Abbildungen 22 und 23 zu sehen. Der Bereich der gleichzeitigen Anfragen wurde auf 200 bis 300 reduziert. Über den pseudo-sättigenden Knickpunkt hinaus, der sich nun leicht nach unten auf NKnick = 254 Threads bewegt hat, gibt es nur noch wenige Abweichungen. Zusätzlich reduziert sich die minimale Reaktionszeit auf Rmin = 0,2236 Sekunden und der damit verbundene Systemdurchsatz erhöht sich auf Xmax = 1135,96 Anfragen pro Sekunde. Diese Änderungen spiegeln sich in den in Abbildung 18 dargestellten Ausgaben des PDQ-Modells wider.
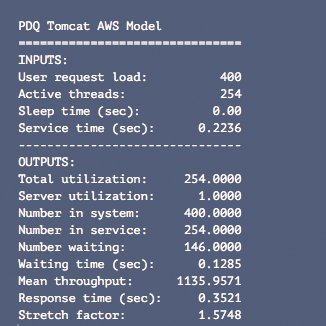
Abbildung 18: PDQ-Parameter für die 2018er Daten.
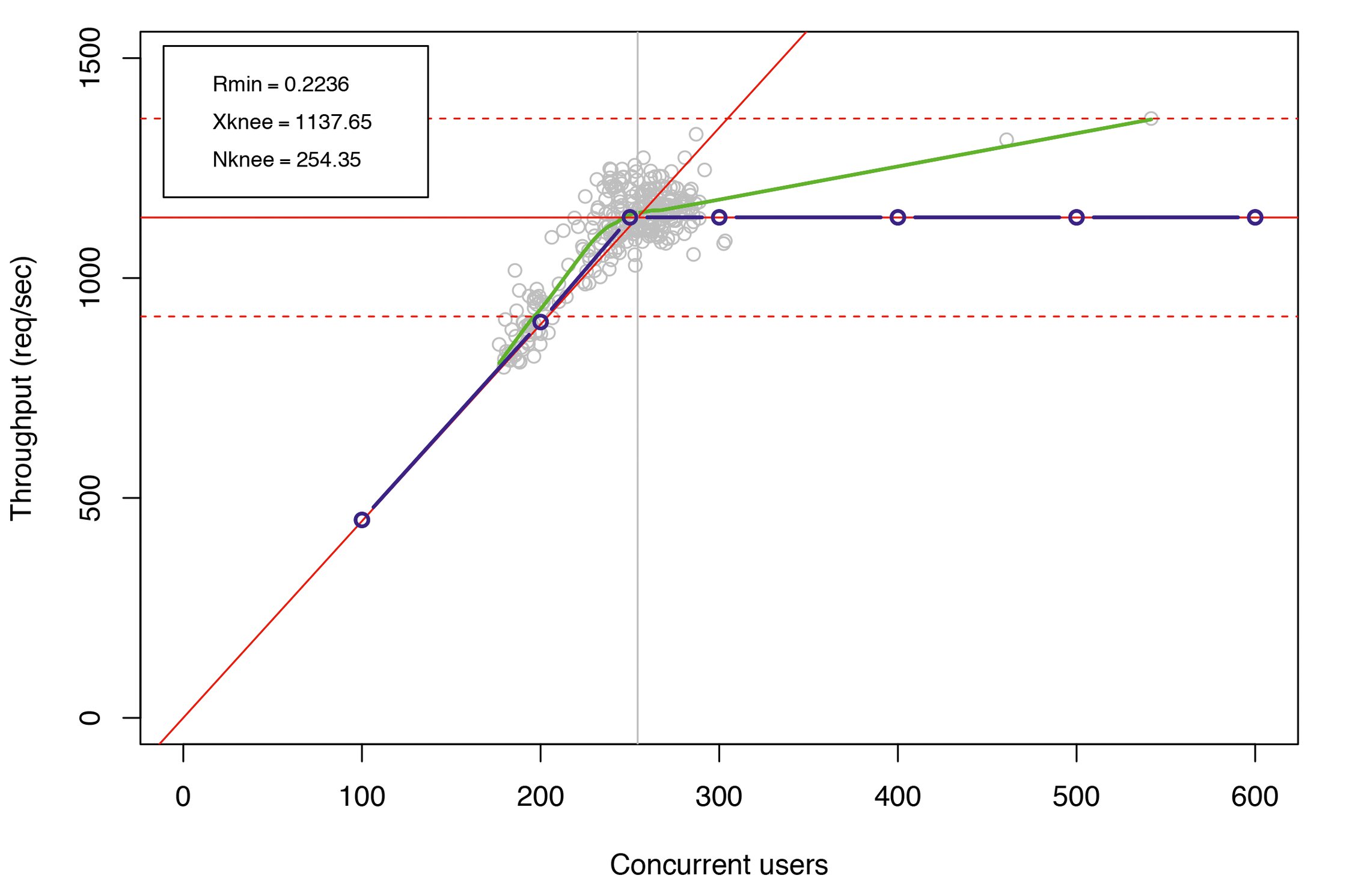
Abbildung 22: PDQ-Modell, März 2018: Durchsatz in der Produktion.
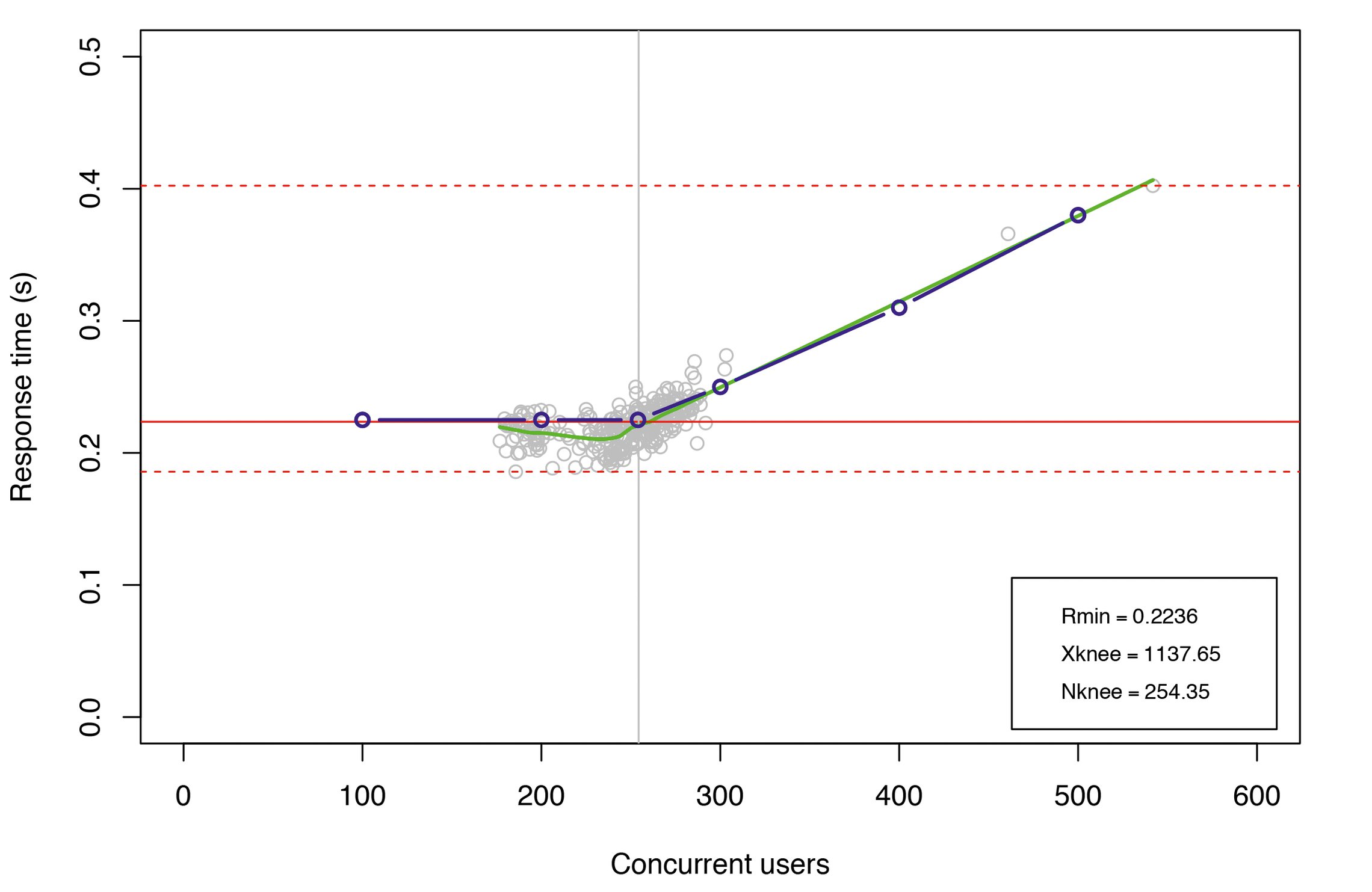
Abbildung 23: PDQ-Modell, März 2018: Latenz in der Produktion.
Wo warten sie?
Die ständige Überprüfung der Konsistenz ist ein wesentlicher Bestandteil jeder Leistungsanalyse. Eine noch offene Frage im vorliegenden Artikel ist: Wo warten Benutzeranfragen, wenn ihre Zahl über dem A/S-Knickpunkt liegt? Mit anderen Worten, wo befinden sich die Kästchen aus der Abbildung 9 im eigentlichen Tomcat-System? Es ist bekannt, dass Anfragen warten müssen, weil PDQ das sagt. Wenn N den N-Knick überschreitet, bekommen Requests keine Tomcat-Threads mehr zugewiesen, sodass eine neue Anforderung warten muss, bis ein bereits belegter Service-Thread verfügbar wird. Aber wo warten sie?
Weitere Unterstützung für diese Frage bieten die Produktionsdaten in den Abbildungen 7 und 23. Der Griff des Hockeyschlägers ist gut sichtbar, und die Warteschlangen-Theorie sagt aus, dass der Griff einer wachsenden Warteschlange in Abbildung 9 entspricht. Ein JVM-Thread kann sich jederzeit in einem der folgenden Zustände befinden [19]:
- Runable: Ein Thread, der in der virtuellen Java-Maschine im Moment ausgeführt wird, befindet sich in diesem Zustand.
- Blocked: Ein Thread, der blockiert ist, befindet sich in diesem Zustand.
- Waiting: Ein Thread, der unbegrenzt darauf wartet, dass ein anderer Thread eine bestimmte Aktion ausführt, befindet sich in dem so benannten Zustand.
- Timed_Waiting: Ein Thread, der darauf wartet, dass ein anderer Thread eine Aktion bis zu einem bestimmten Zeitpunkt ausführt, befindet sich in diesem Zustand.
- Terminated: Ein Thread, der beendet wurde, befindet sich in diesem Zustand.
Die Stichproben in Tabelle 3 deuten darauf hin, dass Threads immer warten. Das scheint im Widerspruch zum PDQ-Modell zu stehen, das besagt, dass es unterhalb des Knickpunkts N kein Warten geben sollte. Weitere Untersuchungen dieses Widerspruchs förderten schließlich einen Konflikt zwischen den Nomenklaturen zu Tage.
|
Timed_Waiting |
Running |
|---|---|
|
138 |
301 |
|
111 |
306 |
|
173 |
519 |
|
108 |
286 |
|
65 |
152 |
|
68 |
185 |
|
72 |
119 |
Die JVM-Wartezustände haben nämlich eine gänzlich andere Bedeutung als die Wartezustände in der Queueing-Theorie. Im Kontext von JVM-Threads bezieht sich Warten nämlich immer auf einen Thread, der seinerseits auf Arbeit wartet [20], während in den hier betrachteten PDQ-Modellen Anfragen auf den Service warten, und ein Thread-Server, der selbst auf Arbeitet wartet, gilt in diesem Zusammenhang als idle.
Das würde erklären, warum Werte ungleich null unterhalb des N-Knicks zu finden sind. Sobald ein Thread seine Ausführung im Auftrag einer Benutzeranfrage beendet hat, kann es aber eine kleine Verzögerung geben, bis dieser Thread neu initialisiert ist und eine neue Anforderung eines Users annehmen kann. In Anbetracht dessen ist die beste Antwort, dass Anfragen, die im PDQ-Modell warten, tatsächlich auf einen Service warten. Und das tun sie in der normalen CPU-Run-Queue des Linux-Kernels.
Fazit
Bei Clouddiensten geht es mehr um den wirtschaftlichen Nutzen für den Dienstleister als um technologische Innovationen für den Nutzer. Es handelt sich nicht nur um ein Plug&Play, sondern auch um ein Pay&Pay! Daher ist es für Anwendungsarchitekten und Systemadministratoren von zentraler Bedeutung, die Kosten für Cloudservices für ihr Unternehmen zu minimieren.
Sinnvolle Kosten/Nutzen-Entscheidungen lassen sich nur mit Hilfe einer kontinuierlichen Leistungsanalyse und Kapazitätsplanung treffen. Dieser Artikel wollte zeigen, wie PDQ-Modelle einen fundierten Einblick in das Cloud-basierte Sizing und in die Performance vermitteln können.
Die Einführung von AWS Lambda [18] wird voraussichtlich neue Modifikationen künftiger PDQ-Modelle erfordern. Auch ist es hier bewusst unterblieben, so genannte Grey-Failure-Leistungsanomalien zu berücksichtigen [21]. Das könnte Teil einer künftigen Arbeit sein. (jcb)
Infos
-
Oracle Java Management Extensions (JMX) Technology: http://www.oracle.com/technetwork/articles/java/javamanagement-140525.html
-
Apache Tomcat (Initial Release 1999): http://tomcat.apache.org
-
Amazon Web Services, launched on March 2006: https://en.wikipedia.org/wiki/Amazon_Web_Services
-
Datadog Dd-Agent: https://github.com/DataDog/dd-agent
-
JMX: https://en.wikipedia.org/wiki/Java_Management_Extensions
-
N. Gunther, “A Little Triplet”: http://perfdynamics.blogspot.com/2014/07/a-little-triplet.html
-
N. Gunther: “Load Average enträtselt und erweitert”: Linux-Magazin 07/07, S. 84-91
-
N. Gunther, “Analyzing Computer System Performance with Perl::PDQ”: Springer, 2011
-
N. Gunther, “Berechenbare Performance”: Linux Technical Review, 02 – Monitoring, S. 112-126, März 2007
-
P. Barham, B. Dragovic, K. Fraser, S. Hand, T. Harris, A. Ho, R. Neugebauery, I. Pratt, A. Wareld, “Xen and the Art of Virtualization”: Proc. 19th ACM Symposium on Operating
-
D. Clinton, “AWS just announced a move from Xen towards KVM. So what is KVM?”: https://medium.com/@dbclin/aws-just-announced-a-move-from-kvm-xen-towards-kvm-so-what-is-2091f123991
-
VMware, “ESX server performance and resource management for CPU-intensive workloads”: https://www.vmware.com/pdf/ESX2_CPU_Performance.pdf
-
N. Gunther, “Guerrilla Capacity Planning: A Tactical Approach to Planning for Highly Scalable Applications and Services”: Springer, 2007
-
M. Anand, H. Lin, D. S. Osborne, “Amazon CloudWatch Metric Math Simplifies Near Real-Time Monitoring of Your Amazon EFS File Systems and More”:https://aws.amazon.com/blogs/mt/amazon-cloudwatch-metric-math-simplifies-near-real-time-monitoring-of-your-amazon-efs-file-systems-and-more
-
C. Quinn, “CloudWatch Is of the Devil, But I Must Use It”: Linux Journal, October ’18
-
P. Koutoupis, “Everything You Need to Know about Linux Containers, Part I: Linux Control Groups and Process Isolation”: Linux Journal, August 21, 2018
-
J. Mills, “Amazon Lambda and the Transition to Cloud 2.0”: SF Bay ACM Meetup, May 16, 2018
-
Oracle Corp., “Java Lang – Enum Thread State”: https://docs.oracle.com/javase/7/docs/api/java/lang/Thread.State.html
-
“Difference between wait and blocked thread states”: https://stackoverflow.com/questions/15680422/difference-between-wait-and-blocked-thread-states
-
P. Huang, C. Guo, L. Zhou, J.R. Lorch, Y. Dang, M. Chintalapati, R. Yao, “Gray Failure: The Achilles Heel of Cloud-Scale Systems”: Hot OS ’17 Workshop on Hot Topicsin Operating Systems, Whistler, BC, Canada, May 8-10, 2017





