
© Martina Unbehauen, 123RF
Schon seit einem halben Jahr kann man die Maria-DB-Release 10.3 installieren. Die unreifen Früchte sind aussortiert, was kann der Admin jetzt ernten?
Wer sich heute auf einer modernen Linux-Distribution ohne weiteres Dazutun eine MySQL-Datenbank installieren will, bekommt bereits in über der Hälfte der Fälle Maria DB. Centos kennt das Paket »mysql-server« schon gar nicht mehr und installiert stattdessen »mariadb-server«. Debian liefert eine Maria DB 10.1 aus und nur Ubuntu verwendet noch ein originales MySQL 5.7.
Wer es nicht glauben mag, soll es selber testen:
SQL> SHOW GLOBAL VARIABLES WHERE Variable_name IN ('version','version_comment');
+-----------------+-----------------+
| Variable_name | Value |
+-----------------+-----------------+
| version | 10.3.9-Maria DB |
| version_comment | Maria DB Server |
+-----------------+-----------------+
Das ist ja auch nicht weiter schlimm, soll Maria DB doch ein Drop-in-Replacement für MySQL sein. Aus technischer Perspektive hieße das: Datenbankserver stoppen, Binaries austauschen, Datenbankserver wieder starten, fertig! Ob das auch in der Realität so klappt, steht auf einem anderen Blatt. Aber der Reihe nach.
Was bisher geschah
Im Jahre 2008 wurde MySQL von Sun Microsystems gekauft – nur ein Jahr später wurde Sun von Oracle übernommen. Dies wiederum passte dem Gründer von MySQL, Monty Widenius, nicht und er gründete eine neue Firma namens Maria DB, in der er mit ein paar Ex-MySQL-Entwicklern einen Branch von MySQL weiterpflegt. Das geschah zu Zeiten von Maria DB 5.5, und zu diesem Zeitpunkt konnte man noch getrost von einem Drop-in-Replacement sprechen.
Aber die Zeit ging ins Land, neue Features kamen hinzu. Maria DB und MySQL fingen an, sich auseinanderzuentwickeln. Fast unmerklich änderte sich das Wording jetzt von “Drop-in-Replacement” in “compatible”. Und heute sind die beiden Datenbanken nicht einmal mehr hundertprozentig kompatibel. Beim Wechsel heißt es jetzt aufpassen!
Welche Neuerungen sind bei den einzelnen Maria-DB-Releases der letzten Zeit hinzugekommen? Auf die Maria-DB-Version 5.5 folgte 10.0. Dieser Versionssprung soll verdeutlichen, dass Maria DB jetzt doch schon ein bisschen anders als MySQL ist. Mit Maria DB 10.0 sind hinzugekommen: User-Rollen, ein Audit-Plugin, ein Volltextsuche-Plugin für CJK-Sprachen (Chinesisch, Japanisch und Koreanisch), paralleles Replizieren, Replikation mit Global Transaction ID (GTID) und die Multi-Source-Replikation sowie zahlreiche neue Storage Engines wie Cassandra, Connect, Spider oder Toku DB sowie Sequenzen.
Maria DB 10.1 hat sich als erste MySQL-Variante zu “Galera ready by default” erklärt, kann also ohne weitere Änderungen in einem Galera-Cluster arbeiten. Weiter wurde viel Arbeit in Data-at-rest-Verschlüsselung investiert: Die Tabellen, Tablespaces, Redo Logs und Binary Logs lassen sich jetzt verschlüsselt auf Platte schreiben. Weiter kam der Maria DB Column Store hinzu, eine Storage Engine, die die Daten nicht zeilenweise, sondern spaltenweise speichert. Dies erlaubt schnelleren Zugriff auf bestimmte Daten für Reporting- und Business- Intelligence-Abfragen.
In der Version Maria DB 10.2 wurde die bisher genutzte Xtra DB Storage Engine der Firma Percona durch die Inno DB 5.7 Storage Engine von MySQL ausgetauscht. Dies ermöglicht die Nutzung praktisch sämtlicher in MySQL 5.7 verfügbarer Inno-DB-Features. Das wichtigste davon sind wohl die Inno DB Spatial Indices (GIS-Indices, mit denen man geographische Abfragen performant ausführen kann (Abbildung 1). Außerdem wurden Module für Mongo DB und My Rocks hinzugefügt.
Abbildung 1: Seit Version 10.2 enthält Maria DB die Inno DB Storage Engine und kann damit auch GIS-Abfragen performant abarbeiten. Quelle: Knut Hebstreit, 123RF
Auf der Seite der SQL-Erweiterungen sind Window Functions (Abfragen über Wertebereiche), rekursive und nicht-rekursive Common Table Expressions (eine Art explizite Subqueries) und Check Constraints neu hinzugekommen. Zudem haben die Entwickler im Bereich GIS, Json und Geo-Json neue Funktionen hinzugefügt und beim Thema Sicherheit und Verschlüsselung kamen weitere Verbesserungen hinzu.
Nicht zuletzt bietet Maria DB jetzt eigene Konnektoren (C/C++, JDBC, ODBC) unter einer neuen Lizenz (LGPL) an. Das ermöglicht es, diese Konnektoren ohne Verletzung der GPL-Lizenz auch zu kommerziellen Zwecken einzusetzen. Zudem wurde ein neues Tool fürs Backup – das Mariabackup – entwickelt, das in etwa dem MySQL Enterprise Backup entspricht und ein Branch des bekannten Tools Xtrabackup ist. Auch ist es jetzt möglich, mit den Binary Logs ein Flashback der Daten durchzuführen, also Datenänderungen rückgängig zu machen. Zu guter Letzt wurden erste Vorbereitungen für die Kompatibilität zur Datenbank von Oracle in die Wege geleitet.
Die wichtigsten Neuerungen in der Version 10.3
Wie bereits angedeutet, liefern die Distributionen meist eine etwas ältere Maria-DB-Version aus. An die neueste Maria DB 10.3 heranzukommen ist jedoch kein Hexenwerk. Man bindet einfach das Repository des Herstellers in die Distribution ein und installiert. Die Listings 1 und 2 zeigt dies exemplarisch für Ubuntu 18.04 und Centos.
Listing 1
Maria DB 10.3 unter Ubuntu installieren
01 # sudo apt-get install software-properties-common 02 # sudo apt-key adv --recv-keys --keyserver hkp://keyserver.ubuntu.com:80 0xF1656F24C74CD1D8 03 # sudo add-apt-repository 'deb [arch=amd64,arm64,ppc64el] http://mirror.mva-n.net/mariadb/repo/10.3/ubuntu bionic main' 04 # sudo apt update 05 # sudo apt install mariadb-server
Wer in den letzten Jahren die Maria DB Release Notes aufmerksam verfolgt hat, wird festgestellt haben, dass immer wieder das Stichwort Oracle-Kompatibilität gefallen ist. Es scheint so zu sein, dass Maria DB versucht Oracle das Wasser abzugraben. Neben den zahlreichen kleinen Details, die implementiert wurden, fallen hier besonders die Oracle Style Sequences auf.
Listing 2
Maria DB 10.3 unter Centos imstallieren
01 # sudo cat > /etc/yum.repos.d/mariadb.repo << _EOL 02 [mariadb] 03 name = Maria DB 04 baseurl = http://yum.mariadb.org/10.3/centos7-amd64 05 gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-Maria DB 06 gpgcheck=1 07 _EOL 08 # sudo yum install Maria DB-server Maria DB-client
Sequenzen sind Datenbankobjekte, die auf Anfrage eine Zahl zurückliefern, die die Datenbank nach einem bestimmten Muster bildet. Typischerweise handelt es sich um eine aufsteigende Integer-Zahlenfolge, die Lücken aufweisen darf. Bei Maria DB wurde das bisher verwirklicht, indem der Anwender die Funktion »AUTO_INCREMENT« auf eine Unique-Spalte angewandt hat. Das war jedoch weder besonders flexibel noch Oracle-kompatibel.
Im Unterschied dazu lässt sich eine Sequenz nun so beschreiben, wie es das Listing 3 zeigt. Listing 4 zeigt, wie sich das Ergebnis nutzen lässt.
Listing 3
Eine Sequenz anlegen
01 SQL> CREATE SEQUENCE demo_seq 02 INCREMENT BY 3 03 MINVALUE = 8 04 MAXVALUE = 99 05 START with 10 06 ENGINE = Inno DB 07 COMMENT = 'Demo Sequence';
Listing 4
Eine Sequenz nutzen
01 SQL> INSERT INTO test 02 VALUES (NEXTVAL(demo_seq), 'Some data', NULL); 03 04 SQL> SELECT * FROM test; 05 +----+-----------+---------------------+ 06 | id | data | ts | 07 +----+-----------+---------------------+ 08 | 10 | Some data | 2018-09-10 17:19:13 | 09 +----+-----------+---------------------+
Die aus Oracle hinlänglich bekannte Form
SELECT demo_seq.nextval;
funktioniert aber nur, wenn Maria DB in den Oracle-Modus umgestellt wurde. Dazu später mehr. Mit der Funktion »lastval« lässt sich der letzte vergebene Wert für die aktuelle Verbindung abfragen:
SELECT lastval(demo_seq);
Zusätzlich lässt sich mit »setval« der Wert der Sequenz ändern:
SELECT SETVAL(demo_seq, 42);
Mit den Befehlen »ALTER SEQUENCE« und »DROP SEQUENCE« ist es möglich, die Sequenz zu modifizieren oder wieder zu löschen. Und mit den Anweisungen aus Listing 5 lässt sich schlussendlich noch abfragen, wie häufig eine bestimmte Sequenz erstellt, geändert oder gelöscht worden ist.
Listing 5
Informationen zu einer Sequenz
SQL> SHOW GLOBAL STATUS LIKE '%seq%'; +--------------------+-----------------+ | Variable_name | Value | +--------------------+-----------------+ | com_alter_sequence 0 | | com_create_sequence 2 | | com_drop_sequence 1 | +--------------------------------------+
Die Variable »sql_mode« gibt es schon seit Längerem in Maria DB und sie hat sicher auch schon das eine oder andere Mal für Verwirrung oder gar Ärger gesorgt. Nun gibt es auch da Neuigkeiten.
Mehr Oracle-Kompatibilität
Mit Version 10.3 versteht die Datenbank ein Subset der Oracle-PL/SQL-Sprache zusätzlich zum traditionellen MySQL-SQL/PSM-Sprachschatz für Stored Routines, wenn der Admin zuvor den SQL-Mode auf »Oracle« gesetzt hat. Das Feature zielt klar drauf ab, Oracle-DB-Nutzern die Migration auf Maria DB zu erleichtern. Es soll von einer großen asiatischen Bank gesponsert worden sein.
Den SQL-Mode kann der DBA auch ad hoc auf der Kommandozeile ändern. Für den produktiven Betrieb empfiehlt es sich aber, sich pro Maria DB-Instanz entweder für den alten Maria-DB- oder den neuen Oracle-Modus zu entscheiden. Als kleines Beispiel zeigt Listing 6 einen anonymen Oracle-PL/SQL-Block in Maria DB. Weitere Beispiele finden sich unter [1].
Listing 6
PL/SQL-Block in Maria DB
01 SQL> SELECT @@session.sql_mode INTO @old_sql_mode; 02 SQL> SET SESSION sql_mode=ORACLE; 03 04 SQL> DELIMITER / 05 06 SQL> BEGIN 07 SQL> SELECT 'Hello world from Maria DB anonymous PL/SQL block!'; 08 SQL> END; 09 SQL> / 10 11 SQL> DELIMITER ; 12 SQL> SET SESSION sql_mode=@old_sql_mode;
Stored Aggregate Functions
Aggregate Functions sind Funktionen, die Berechnungen über eine Gruppe von Zeilen anstellen und anschließend nur ein Resultat für die ganze Gruppe zurückliefern. Beispiele von bereits vorhandenen Aggregate Functions sind »COUNT()«, »AVG()« oder »SUM()«. Mit den Stored Aggregate Functions bietet Maria DB jetzt die Möglichkeit, eigene Funktionen nach diesem Vorbild zu implementieren (Listing 7).
Listing 7
Eigene Aggregatfunktionen
01 SQL> CREATE TABLE marks (
02 `student` VARCHAR(17)
03 , `grade` TINYINT UNSIGNED
04 );
05
06 SQL> INSERT INTO marks VALUES ('Alena', 6), ('Milva', 4), ('Marino', 5), ('Pablo', 5), ('Leo', 6);
07 INSERT INTO marks VALUES ('Alena', 5), ('Milva', 4), ('Pablo', 6), ('Leo', 2);
08 INSERT INTO marks VALUES ('Alena', 4), ('Milva', 3), ('Marino', 6), ('Pablo', 5), ('Leo', 4);
09
10 SQL> SELECT * FROM marks;
11
12 SQL> DELIMITER //
13
14 SQL> CREATE AGGREGATE FUNCTION agg_count(x INT) RETURNS INT
15 BEGIN
16 DECLARE count_students INT DEFAULT 0;
17 DECLARE CONTINUE HANDLER FOR NOT FOUND
18 RETURN count_students;
19
20 LOOP
21 FETCH GROUP NEXT ROW;
22 IF x THEN
23 SET count_students = count_students + 1;
24 END IF;
25 END LOOP;
26 END;
27 //
28
29 SQL> DELIMITER ;
30
31 SQL> SELECT student, agg_count(5) AS 'tests'
32 FROM marks GROUP BY student;
33 +---------+-------+
34 | student | tests |
35 +---------+-------+
36 | Alena | 3 |
37 | Leo | 3 |
38 | Marino | 2 |
39 | Milva | 3 |
40 | Pablo | 3 |
41 +---------+-------+
Die Abfrage in diesem Beispiel ließe sich natürlich wesentlich einfacher über ein simples »COUNT(*)« abbilden. Doch lassen sich mit den aggregierten Stored Functions wesentlich komplexere Konstrukte bilden (beispielsweise ein geometrisches Mittel).
Neues in Sachen SQL
Auch bei den SQL-Befehlen hat sich Maria DB weiter den Standards angenähert. Neuerdings kann sie bei »DELETE«-Statements, die auf sich selbst referenzieren, Zeilen löschen. Was früher noch zu dem Fehler
ERROR 1093 (HY000): You can't specify target table 'customer' for update in FROM clause
führte, funktioniert jetzt einwandfrei (Listing 8). Dasselbe gilt auch für »UPDATE«-Statements. Neuerdings sind außerdem »ORDER BY«- und »LIMIT«-Klauseln bei Multi-Table-Updates zulässig. Neben den bisher bestehenden »UNION«- und »UNION ALL«-Mengen-Operatoren kennt Maria DB jetzt auch »EXCEPT (MINUS)« und »INTERSECT«. Das illustriert Listing 9.
Listing 8
Löschen selbstreferenzierter Zeilen
01 SQL> CREATE TABLE customer ( 02 id INT UNSIGNED 03 , year SMALLINT UNSIGNED 04 , revenue DECIMAL(11, 2) 05 , customer_class CHAR(1) 06 ); 07 08 SQL> INSERT INTO customer 09 VALUES (1, 2016, 100.0), (2, 2016, 0.0), (3, 2016, 999.99); 10 SQL> INSERT INTO customer 11 VALUES (1, 2017, 500.0), (2, 2017, 0.0), (3, 2017, 100.00); 12 SQL> INSERT INTO customer 13 VALUES (1, 2018, 400.0), (2, 2018, 0.0), (3, 2018, 0.0); 14 15 SQL> SELECT * FROM customer; 16 +------+------+---------+ 17 | id | year | revenue | 18 +------+------+---------+ 19 | 1 | 2016 | 100.00 | 20 | 2 | 2016 | 0.00 | 21 | 3 | 2016 | 999.99 | 22 | 1 | 2017 | 500.00 | 23 | 2 | 2017 | 0.00 | 24 | 3 | 2017 | 100.00 | 25 | 1 | 2018 | 400.00 | 26 | 2 | 2018 | 0.00 | 27 | 3 | 2018 | 0.00 | 28 +------+------+---------+ 29 30 SQL> DELETE FROM customer 31 WHERE id IN (SELECT id FROM customer GROUP BY id HAVING SUM(revenue) = 0.0);
Listing 9
Neue Mengenoperatoren
01 SQL> CREATE TABLE customer (
02 first_name VARCHAR(33)
03 , last_name VARCHAR(55)
04 );
05
06 SQL> CREATE TABLE user (
07 first_name VARCHAR(33)
08 , last_name VARCHAR(55)
09 );
10
11 SQL> INSERT INTO customer VALUES ('Hans', 'Meier'), ('Sepp', 'Müller'),
12 ('Fritz', 'Huber');
13 SQL> INSERT INTO user VALUES ('Oman', 'Klept'), ('Hans', 'Meier'), ('Getfor',
14 'Free');
15
16 # Im ersten Fall wollen wir alle Nutzer ermitteln, welche nicht Kunden sind:
17
18 SQL> SELECT first_name, last_name FROM user
19 EXCEPT
20 SELECT first_name, last_name FROM customer
21 ;
22 +------------+-----------+
23 | first_name | last_name |
24 +------------+-----------+
25 | Oman | Klept |
26 | Getfor | Free |
27 +------------+-----------+
28
29 # Und im zweiten Fall wollen wir wissen wer Nutzer und Kunde ist:
30
31 SQL> SELECT first_name, last_name FROM user
32 INTERSECT
33 SELECT first_name, last_name FROM customer
34 ;
35 +------------+-----------+
36 | first_name | last_name |
37 +------------+-----------+
38 | Hans | Meier |
39 +------------+-----------+
Mit etwas komplizierteren »JOIN«-Konstrukten hat man das zwar bisher auch hingekriegt, mit den beiden neuen Klauseln sieht das Ganze aber wesentlich sprechender und einfacher aus. Das nicht standardkonforme »MINUS«, das dem »EXCEPT« entspricht und bei Oracle-Entwicklern bekannt ist, wird von Maria DB leider noch nicht unterstützt.
System Versioned Tables
Neben zahlreichen weiteren kleinen Verbesserungen im SQL-Layer sticht vor allem noch das neue Feature System Versioned Tables hervor. Dieses Feature wurde mit dem Standard SQL:2011 definiert und speichert die gesamte Historie einer Zeile vom Erstellen bis hin zum Löschen ab. Das ermöglicht die Datenanalyse für einen bestimmten Zeitpunkt oder das Rückverfolgen von Änderungen bei einem Audit. So wird eine versionierte Tabelle angelegt:
SQL> CREATE TABLE accounting ( name VARCHAR(55), amount DECIMAL(11, 2), `date` DATE ) WITH SYSTEM VERSIONING;
Nun trägt der Anwender einige Werte in die Tabelle ein und ändert sie. Darunter beispielsweise im März:
SQL> UPDATE accounting SET amount = amount + 500.0, `date` = '2018-03-13' WHERE name = 'Übeltäter';
Irgendwann später lässt sich dann jederzeit genau nachvollziehen, wie der Kontostand des Kollegen »Mitarbeiter« zu einem bestimmten Zeitpunkt, zum Beispiel dem 1. März, ausgesehen hat (Listing 10).
Listing 10
Zugriff auf versionierte Daten
01 SQL> SELECT * FROM accounting FOR SYSTEM_TIME AS OF TIMESTAMP'2018-03-01 00:00:00'; 02 +-------------+---------+------------+ 03 | name | amount | date | 04 +-------------+---------+------------+ 05 | Mitarbeiter | 600.00 | 2018-02-25 | 06 | Chef | 1200.00 | 2018-02-25 | 07 | Übeltäter | 600.00 | 2018-02-25 | 08 +-------------+---------+------------+
Es gibt noch weitere Möglichkeiten, den Zeitbereich einzuschränken mit »FROM …TO… « oder »BETWEEN …AND… «. Darüber hinaus bietet Maria DB die Möglichkeit, über den Marker »trxid« die Zeilen Transaktions-genau abzufragen. Eine bereits bestehende Tabelle ist wie folgt auf System-Versioning umstellbar:
SQL> ALTER TABLE accounting ADD SYSTEM VERSIONING;
Vorsicht ist beim Backup geboten: Wenn mit »mysqldump« gesichert wird, geht die gesamte Historie verloren. Es empfiehlt sich daher, eine physische Backup-Methode wie Maria Backup zu nutzen.
Weitere Neuerungen
Hinzugekommen ist außerdem die von der Storage Engine unabhängige Spaltenkomprimierung. Dieses Feature verringert besonders den Fußabdruck von sehr großen Spalten (etwa »BLOB«, »TEXT«, »VARCHAR«, »VARBINARY« oder auch »JSON«):
SQL> CREATE TABLE mail ( subject VARCHAR(255) , body VARCHAR(255) , attachment LONGBLOB COMPRESSED , metadata JSON COMPRESSED );
Das Indexieren von komprimierten Spalten ist nicht möglich.
Rocks DB
Die Default Storage Engine ist auch bei Maria DB die Inno DB, und zwar in der (MySQL-)Version 5.7. Somit stehen die meisten Features auch unter Maria DB zur Verfügung. Mit der Version 10.3 sind kleinere Verbesserungen und zahlreiche Bugfixes hinzugekommen.
My Rocks ist eine Maria DB Storage Engine basierend auf Rocks DB, der Open Source Storage Engine, die ursprünglich von Facebook entwickelt wurde und wahrscheinlich immer noch wird. Rocks DB basiert auf einem Log Structured Merge Tree (LSM), der gegenüber B-Tree-Indexen bei schreibintensiven Workloads im Vorteil und zudem für Flashspeicher (SSD) optimiert ist.
Rocks DB hat ein gutes Kompressionsverhältnis, zirka doppelt so gut wie die Komprimierung unter Inno DB, und ist daher besonders Speicher-effizient (Abbildung 2). Rocks DB schneidet beim Schreiben verglichen mit Inno DB beim selben Workload besser ab, beschleunigt das Laden von Daten und verringert Engpässe bei der Replikation. Es soll aber nicht verschwiegen werden, dass bei leselastigem Workload Rocks DB etwas schlechtere Resultate liefert als Inno DB.

Abbildung 2: Besonders bei der Datenkompression sammelt die Storage Engine My Rocks Pluspunkte.
Um Rocks DB zu konfigurieren, stehen 129 Variablen zur Verfügung und es lassen sich 105 Statusinformation abfragen. Die Ausgabe des Befehls
SHOW ENGINE ROCKSDB STATUS;
ist ähnlich komplex wie bei Inno DB. Die Konfiguration von Rocks DB scheint um einiges komplizierter zu sein als die von Inno DB. Daher wird für einen akzeptablen Start die Vorgabe der Rocks-DB-Entwickler bei Facebook nützlich sein [2].
OQ Graph
Die Open Query Graph Computation Engine ist keine eigentliche Storage Engine, sondern sie simuliert eine Graphen-Datenbank [3] basierend auf relationalen Tabellen (Inno DB). Sie erlaubt es, Abfragen über Hierarchien (Baumstrukturen, Abbildung 4) und komplexe Graphen durchzuführen.
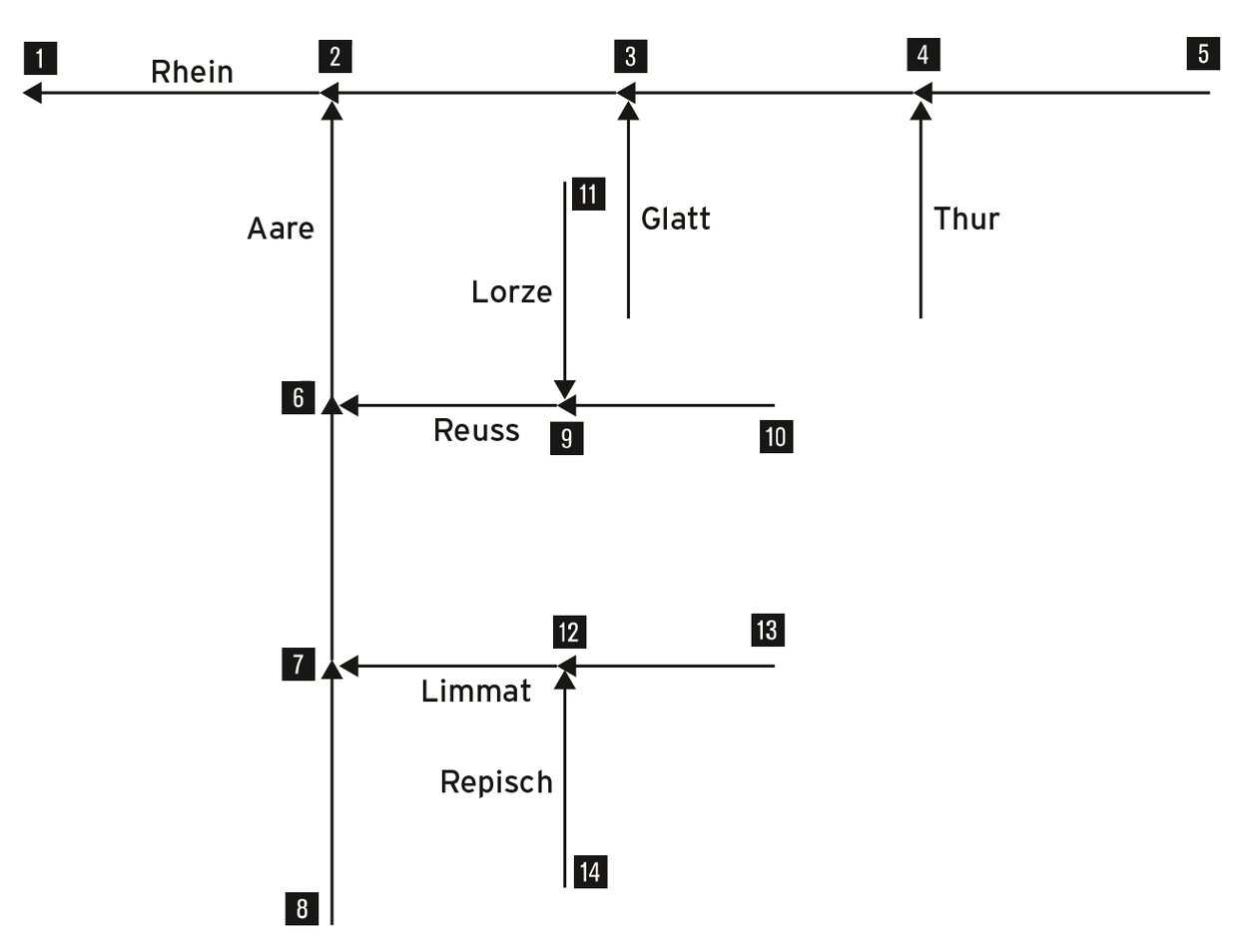
Abbildung 4: Ein solches baumartiges Modell des Systems der Flüsse der Schweiz lässt sich mit OQ Graph modellieren und dann später via SQL abfragen.
Die OQ Graph Computation Engine in Maria DB 10.3 hat noch immer den Gamma-Status, ist also für den produktiven Einsatz noch nicht empfohlen. Neu wurde der Leaves-Algorithmus implementiert. Im Gegensatz zur Rocks DB Storage Engine braucht der Anwender die OQ Graph Computation Engine nicht nachzuinstallieren, aktivieren reicht.
Spider SE
Eine weitere, ebenfalls etwas exotische Storage Engine ist die Spider Storage Engine. Auch sie ist eigentlich keine echte Storage Engine, sondern eine Art Sharding Layer, der Daten von verschiedenen Instanzen zusammenführt (Abbildung 3). Konkret: Werden eine Tabelle partitioniert und die einzelnen Partitionen auf jeweils eigene Instanzen auf unterschiedlichen Servern ausgelagert, so verhält sich das ganze Konstrukt damit wie eine einzelne große Instanz.
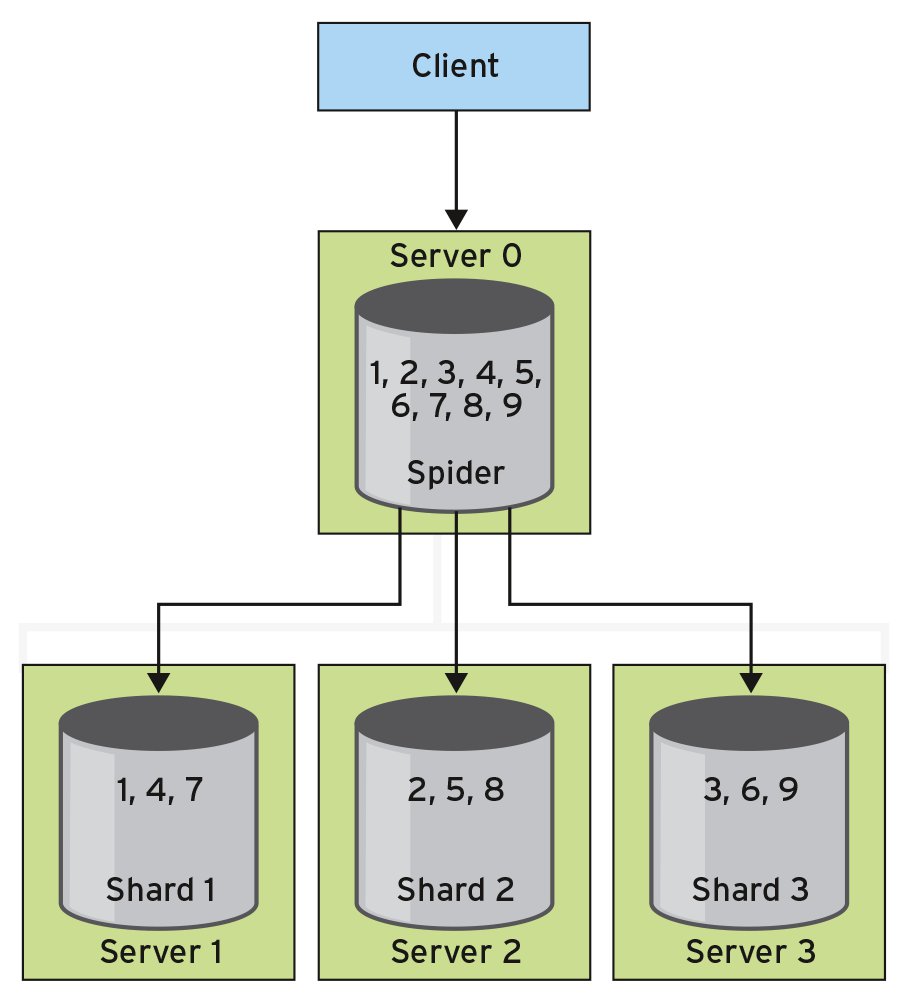
Abbildung 3: Die Spider Storage Engine verteilt Daten über verschiedene Instanzen, bietet sie gegenüber dem Client aber als Einheit an.
Die Spider Storage Engine wurde in Maria DB 10.3 inzwischen als für den Produktionseinsatz verfügbar markiert. Gleichzeitig wurde auch die Partition Engine erweitert, sie unterstützt jetzt Condition Pushdown (»WHERE«-Klausel wird bereits in der Partition ausgewertet), Multi Range Read, Volltextsuche, Aggregate Pushdown sowie Bulk-Update- und Delete-Operationen.
Für den Admin
Während die bisherigen Neuerungen mehrheitlich Entwicklern zugutekommen, gibt es auch für den Admin Neues zu entdecken, etwa das Fast Fail bei DDL-Befehlen auf Inno-DB-Tabellen. Wenn eine lange laufende offene Transaktion eine Tabelle mit einem Meta Data Lock (MDL) sperrt und gleichzeitig ein DDL-Befehl auf diese Tabelle abgesetzt wird, muss der DDL-Befehl im Status »Waiting for table metadata lock« warten, und zwar bis zu einen Tag lang (Timeout nach 86400 Sekunden).
Dank des Community-Beitrags von Alibaba gibt es jetzt die Möglichkeit, dem DDL-Befehl zu sagen, dass er in einem solchen Fall gar nicht (»NOWAIT«) oder nur eine bestimmte Anzahl Sekunden warten soll:
SQL> ALTER TABLE test WAIT 5 ADD COLUMN bla INT; ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
Dieses Verhalten wird mit dem Begriff Fast Fail bezeichnet.
Eine ähnliche Änderung betrifft auch den »TRUNCATE-TABLE«-Befehl. Bisher hat er die Meta Data Locks einfach ignoriert, was streng genommen zu einer Verletzung der ACID-Bedingungen führte. Jetzt beachtet der »TRUNCATE TABLE«-Befehl den Meta Data Lock und lässt sich entsprechend auch mit »NOWAIT« oder »WAIT« ausstatten.
Früher hat ein »ALTER TABLE«-Befehl bei Maria DB immer ein komplettes Umkopieren der Tabelle erforderlich gemacht. Seit Maria DB 10.0 können viele »ALTER TABLE«-Befehle in-place ohne Kopieren der Daten erfolgen. Mit der »ALGORITHM«-Klausel lässt sich steuern, ob das alte Verfahren (»COPY«) oder das neue In-place-Verfahren (»INPLACE«) zu verwenden ist.
Das In-place-Verfahren hat allerdings einen negativen Effekt: Es kann extrem lange dauern und die Datenbankinstanz dramatisch ausbremsen. Aus diesem Grund wurden die beiden neuen Optionen »INSTANT« und »NOCOPY« eingeführt. »INSTANT« verweigert den »ALTER«-Befehl, wenn Datenfiles zu modifizieren wären, und »NOCOPY« verweigert den Dienst, wenn der geclusterte Index (Primary Key) und somit die gesamte Tabelle umzubauen wäre:
SQL> ALTER TABLE test ADD INDEX (data), ALGORITHM = INSTANT; ERROR 1846 (0A000): ALGORITHM=INSTANT is not supported. Reason: ADD INDEX. Try ALGORITHM=NOCOPY
Dies erlaubt es dem Admin, ohne genauere Kenntnisse des internen Verhaltens mehr Sicherheit bei diesen Befehlen zu erlangen.
Zwei weitere, sehr praktische Features sind »Instant ADD COLUMN« und »HIDDEN COLUMN«. Das erste dieser beiden Features erlaubt das Anlegen einer neuen Spalte, ohne dass dabei die teure Operation des Tabellen-Umkopierens erfolgen muss. Das Anlegen einer neuen Spalte dauert nicht viel länger als das Einfügen einer Zeile.
Ein paar Einschränkungen sind allerdings zu beachten: »Instant ADD COLUMN« funktioniert nicht auf Tabellen mit einem Volltext-Index, zudem muss die neue Spalte an letzter Stelle stehen. Auch diese Features wurden von der Maria-DB-Community beigesteuert, und zwar von Alibaba und Tencent.
Die umgekehrte Operation – ein »DROP COLUMN« – setzt aber ein komplettes Umkopieren der Tabelle in Gang, was sehr lange dauert. Aus einem Google-Summer-of-Code-Projekt sind hierzu Invisible Columns (unsichtbare Spalten) entstanden. Statt eine Spalte zu löschen, kann der Anwender sie einfach für unsichtbar erklären (Listing 11) und bei einer späteren Gelegenheit löschen, wenn er die Tabelle sowieso umbauen muss.
Listing 11
Spalte unsichtbar machen
01 SQL> ALTER TABLE test MODIFY COLUMN bla int INVISIBLE, ALGORITHM = INSTANT; 02 Query OK, 0 rows affected (0.001 sec) 03 04 SQL> SELECT * FROM test LIMIT 1; 05 +----+-----------+---------------------+ 06 | id | data | ts | 07 +----+-----------+---------------------+ 08 | 3 | Some data | 2018-09-11 17:47:04 | 09 +----+-----------+---------------------+
Wer die Spalte explizit referenziert, kann sie aber trotzdem noch anzeigen oder auch füllen. Ein genaues Sichten des Applikationscodes bleibt dem Admin also dennoch nicht erspart, wenn er Spalten entfernen will:
SQL> SELECT * FROM test LIMIT 1; +---+-----------+-------------------+-----+ | 3 | Some data |2018-09-11 17:47:04|NULL | +---+-----------+-------------------+-----+
Lange laufende, offene Transaktionen sind für eine Datenbank ein Problem, weil sie gegebenenfalls Locks aufrechterhalten muss, die andere Anwendungen blockieren, und weil sie alle Datenänderungen bis zurück zur ältesten offenen Transaktion vorhalten muss, um gegebenenfalls diese Daten noch zur Verfügung stellen zu können. Erfahrene Datenbankentwickler sind sich des Problems bewusst und arbeiten vorsichtig. Wer das aber nicht berücksichtigt, der trägt zu Blockaden oder im schlimmsten Fall zum völligen Kollaps der Datenbank bei.
Für dieses Szenario gibt Maria DB 10.3 dem Admin neuerdings die Möglichkeit an die Hand, bei lange laufenden, idelnden Transaktionen die Verbindung zu schließen. Dies erfolgt durch die Variablen »idle_readonly_transaction_timeout«, »idle_readwrite_transaction_timeout« sowie für beide zusammen »idle_transaction_timeout« (Listing 12).
Listing 12
Idle Timeouts
01 SQL> SET SESSION idle_readonly_transaction_timeout = 5; 02 SQL> START TRANSACTION READ ONLY; 03 SQL> do sleep(6); 04 Query OK, 0 rows affected (6.000 sec) 05 06 SQL> do sleep(6); 07 ERROR 2006 (HY000): MySQL server has gone away
Häufig wird Maria DB zusammen mit HA-Proxys verwendet. Verbindungen, die über einen TCP/IP-Proxy eintreffen, haben oft die Eigenschaft, dass sie die IP-Adresse des Proxys ausweisen und nicht die IP-Adresse des ursprünglichen Servers, der die Anfrage abschickte. Das macht es schwierig, bei Problemen eine Verbindung einer Applikation oder einem bestimmten Server zuzuordnen. Zudem ist der Maria-DB-Sicherheitsmechanismus, der auf IP-Adressen beruht, in diesem Fall ausgehebelt.
Neues für Proxy und Netz
Um diese Probleme in den Griff zu kriegen, hat HA Proxy das Proxy-Protokoll [4] definiert, das Maria DB nun sowohl Client- als auch Server-seitig unterstützt. Damit sind bei einem Server wieder die ursprünglichen IP-Adressen zu sehen. Server-seitig erfolgt das Aktivieren des Proxy-Protokolls durch eine Variable:
[mysqld] proxy_protocol_neworks = localhost,192.168.2.0/24
Außerdem ist es jetzt möglich, die Default-TCP-Keepalive-Parameter des Betriebssystems für Maria DB zu übersteuern. Das erreicht der Admin mit den Maria-DB-Systemvariablen »tcp_keepalive_time«, »tcp_keepalive_interval« und »tcp_keepalive_probes«, die analog zu den Betriebssystemvariablen zu verwenden sind.
Diskmanagement
Maria DB ist durch Plugins (Module) erweiterbar und ermutigt die Community, solche auch zu entwickeln und beizusteuern. Ein solches Plugin ist das Disks-Plugin, das es erlaubt, über die Datenbank den Füllgrad der eingesetzten Platten abzufragen. Das ist vor allem dann von Bedeutung, wenn der Datenbank-Admin keinen direkten Zugriff auf das Betriebssystem hat, und erleichtert das Überwachen der für die Datenbank relevanten Platten. Das Disks-Plugin liefert Maria DB standardmäßig mit aus, man braucht es nur zu laden:
SQL> INSTALL SONAME 'disks'; ERROR 1126 (HY000): Can't open shared library 'disks.so' (errno: 1, Loading of beta plugin DISKS is prohibited by --plugin-maturity=gamma)
Da taucht plötzlich ein unerwartetes Problem auf: Das Plugin scheint noch nicht ganz ausgereift zu sein (Beta-Qualität). Der Server erlaubt aber nur Plugins, die mindestens Gamma-Qualität aufweisen (eine Stufe niedriger als die Qualität des Servers selbst: Stable).
Die Abstufung lautet wie folgt: Unknown, Experimental, Alpha, Beta, Gamma, Stable. Leider lässt sich diese Variable, die den Server davor schützen soll, Plugins von noch ungenügender Qualität zu laden, nicht online ändern. Ein Datenbank-Restart ist dazu erforderlich. Wer die Datenbank dann schließlich wieder gestartet hat, kann die Disk mit SQL-Bordmitteln abfragen (Listing 13).
Listing 13
Freien Plattenplatz abfragen
01 SQL> SELECT Disk, Path 02 , ROUND(Total/1024/1024, 0) AS Total_GB 03 , ROUND(Used/1024/1024, 0) AS Used_GB 04 , ROUND(Available/Total*100, 1) AS Free_Pct 05 FROM information_schema.disks 06 WHERE disk LIKE '/dev/%'; 07 +-----------+----------------------+----------+---------+----------+ 08 | Disk | Path | Total_GB | Used_GB | Free_Pct | 09 +-----------+----------------------+----------+---------+----------+ 10 | /dev/sdb1 | / | 183 | 23 | 82.4 | 11 | /dev/sdb3 | /home | 704 | 485 | 26.0 | 12 | /dev/sda1 | /home/mysql/database | 164 | 75 | 49.4 | 13 +-----------+----------------------+----------+---------+----------+
Systemvariablen und Statusinformationen
Maria-DB-Systemvariablen und Statusinformationen sind so eine Sache: Laufend kommen neue hinzu, manchmal fallen ein paar alte weg. Was sie genau bedeuten, ist nicht immer so ganz klar, aber man bräuchte sie eigentlich fürs Monitoring und das Überwachen der Datenbank. Hier ein kurzer Überblick über noch nicht besprochene Systemvariablen und Statusinformationen, die sich mit Maria DB 10.3 geändert haben.
Die Systemvariable »secure_timestamp« beeinflusst, wie und ob eine Verbindung ihren lokalen Session Timestamp ändern kann. Folgende Inno-DB-Systemvariablen wurden entfernt und dürfen daher nicht mehr in der Maria-DB-Konfigurationsdatei vorkommen: »innodb_file_format«, »innodb_file_format_check«, »innodb_file_format_max«, »innodb_large_prefix«, »innodb_mtflush_threads«, »innodb_use_mtflush«. Falls der Admin diese Variablen nicht aus der »my.cnf« entfernt, startet die Maria-DB-Instanz nach dem Upgrade nicht mehr.
Die Feature-Statusinformationen zeigen, welche Features Maria DB wie oft verwendet hat. Neu sind: »Feature_system_versioning«, »Feature_invisible_columns«, »Feature_json« und »Feature_custom_aggregate_functions«.
Beim Table Open Cache (TOC) wurden sämtliche Statusinformationen implementiert, die bereits in MySQL 5.7 zur Verfügung standen: »Table_open_cache_active_instances«, »Table_open_cache_hits«, »Table_open_cache_misses« sowie »Table_open_cache_overflows«, um das Verhalten des TOC besser überwachen zu können.
Die Statusinformation »innodb_buffer_pool_load_incomplete« zeigt schließlich an, ob das Laden des Inno-DB-Buffer-Pools nach dem Neustart der Instanz bereits vollendet ist oder noch läuft.
Logging
Maria DB verfügt über zwei mächtige Logfiles: das General Query Log für alle Abfragen und das Slow Query Log für die per Definition langsamen Abfragen. Neu hinzugekommen sind Ausschlusskriterien für beide Logfiles, die festlegen, welche Arten von Statements nicht zu loggen sind. Für das General Query Log ist hierfür die Variable »log_disabled_statements« zuständig mit den möglichen Werten »slave« und »sp« (Stored Procedures) und für das Slow Query Log die Variable »log_slow_disabled_statements« mit den möglichen Werten »admin«, »call«, »slave« und »sp«.
Eine weitere Möglichkeit, Filter auf das Slow Query Log einzustellen, bietet die Variable »log_slow_filter«. Neu lassen sich auch Abfragen, die die Priority-Queue-Optimierung bei Filesort-Operationen nutzen, mit der Variablen »filsort_priority_queue« loggen. Auch diese Abfragen sind dann potenzielle Kandidaten fürs Query Tuning.
Auch beim Information-Schema (I_S) hat sich das eine oder andere verbessert. Seine Tabellen wurden optimiert und sollen jetzt wesentlich weniger Speicher verbrauchen. System Versioned Tables und Columns sind jetzt in den entsprechenden »I_S.COLUMNS«- und »I_S.TABLES«-Tabellen ersichtlich, und für die bereits mit Maria DB 10.2 eingeführten Check Constraints gibt es jetzt ebenfalls eine eigene Tabelle im I_S.
Replikation
Auf der Seite der semisynchronen Replikation hat sich seit Längerem wieder mal etwas getan. Alibaba hat das Semisync-Plugin in ein Built-in umgebaut. Somit ist jetzt die Funktionalität direkt in den Server-Code gewandert. Diese Maßnahme soll Performance-Verbesserungen bewirken.
Bei der asynchronen Replikation sind noch zwei neue Variablen hinzugekommen, mit denen der Admin steuern kann, bei welchen Fehlern (»slave_transaction_retry_errors«) und nach wie viel Zeit (»slave_transaction_retry_interval«) das System es nochmals versuchen soll, den Befehl auszuführen. Diese Änderung kommt aus der Ecke der Spider-Entwickler.
Mit den drei Statusvariablen »Rpl_transactions_multi_engine«, »Transactions_gtid_foreign_engine« und »Transactions_multi_engine« lässt sich feststellen, ob Transaktionen über verschiedene transaktionale Storage Engines (Inno DB, Rocks DB, Toku DB) durchgeführt wurden und ob es eventuell sinnvoll wäre, mit der Variablen »gtid_pos_auto_engines« je eine Tabelle pro Storage Engine zu verwenden, die die Global Transaction ID (GTID) nachführt.
Auf der Seite des Galera-Clusters wurde das Plugin auf die neueste Version gebracht. Bei der SST-Methode »rsync« lässt sich, wenn vorhanden, Stunnel verwenden, um eine Data-in-Transit-Verschlüsselung zu erreichen. Und mit der neuen Variablen »wsrep_reject_queries« ist es möglich, Anfragen mit einer Fehlermeldung zurückzuweisen, während ein Knoten gewartet wird.
Ein Blick voraus
Maria DB 10.3 ist seit rund einem halben Jahr für die Produktion zugelassen (GA). Nun kann sich Otto Normalverbraucher langsam daran wagen, die Datenbank selber in der Produktion einzusetzen. Was kommt als Nächstes? Auf der Maria-DB-Roadmap für 10.4 [5] stehen zwei Punkte auf dem Programm: Security und Oracle-Kompatibilität. Ferner scheint Kentoku Shiba weiter an seiner Spider Storage Engine zu entwickeln.
Bei Inno DB folgt nach dem »Instant ADD COLUMN« jetzt das »Instant DROP COLUMN«, invisible scheint nicht genug zu sein. Wie MySQL wird auch bei Maria DB aufs Schreiben hin optimiert. Möglichkeiten dafür scheinen noch vorhanden zu sein. Query-Parallelisierung sowie Server-verwaltete Konfiguration (»my.cnf«) stehen auch noch auf der Liste. Ein weiterer Punkt ist Galera 4. Den Leuten bei Maria DB gehen die Ideen nicht so schnell aus, was noch alles zu verbessern wäre.
Maria DB 10.3 bietet zahlreiche neue Features, die Admins testen oder sogar einsetzen sollten. Jetzt ist dafür ein guter Zeitpunkt, nachdem die ersten praktischen Erfahrungen mit der neuen Release vorliegen. Dass die Distributionen veraltete Maria-DB-Versionen ausliefern, ist kein Hindernis, da Maria DB selber gute Repositories für alle gängigen Distributionen anbietet.
Infos
-
Select Hello World Fromdual with Maria DB PL/SQL: https://fromdual.com/select-hello-world-fromdual-with-mariadb-pl-sql
-
My Rocks configuration example: https://github.com/facebook/mysql-5.6/wiki/my.cnf-tuning
-
Graph database: https://en.wikipedia.org/wiki/Graph_database
-
Proxy Protokol: https://www.haproxy.org/download/1.8/doc/proxy-protocol.txt
-
Plans for Maria DB 10.4; https://mariadb.com/kb/en/library/plans-for-mariadb-104





