
© Maciej Bledowski, 123RF
Der Albtraum vieler Admins ist der Anwender im eigenen Netzwerk, der trotz zahlreicher Warnungen am Ende doch auf das Attachment “Bewerbung.exe” klickt. Der Artikel zeigt anhand eines realen Beispiels, wie Admins infizierte Systeme mit Linux-Bordmitteln am Netzwerk-Gateway aufspüren.
Trotz Schulungen, Appellen und Virenscannern feiern bösartige Attachments immer wieder Erfolge. Fällt die Malware im Monitoring auf, muss der Admin die betroffenen Systeme identifizieren und den Schaden eindämmen.
Im konkreten Fall zog ein Kunde den Autor des Artikels zu Rate. In seiner Microsoft-lastigen Umgebung tummelten sich viele mit Malware infizierte Clients. Weil die Angreifer auf eine selbst geschriebene und recht ausgefeilte Schadsoftware setzten, half auch der Virenscanner nicht. Also ging es darum, alle infizierten Clients zu finden.
Um die Sache noch spannender zu machen, tauchten im Netzwerk mehrere Versionen der Malware auf. Diese ließ sich also nicht einfach über ein Muster aufspüren (etwa über einen Dateisystemscan). Zum Glück stellte sich heraus, dass die Angreifer zwar gut im Eindringen waren, jedoch nicht gerade geschickt darin, eine Rückverbindung zu ihrem Command-&-Control-Server (C&C) aufzubauen. Dies zeigte sich schnell in der Analyse des mit Tcpdump [1] mitgeschnittenen Netzwerktraffic.
First Generation
Die erste Generation der Malware versuchte sich über den TCP-Port 23 mit Telnet-Servern in Asien zu verbinden. Da aber das Telnet-Protokoll in den 2010er Jahren kaum noch eine Rolle spielte, vor allem in einem Microsoft-Büronetzwerk, fiel dies schnell auf. Ein einfaches »tcpdump -i eth0 tcp port 23« auf dem Gateway lieferte erste Treffer.
Die Pakete wiesen zudem Merkwürdigkeiten in den Feldern des Telnet-Headers auf, die eine Analyse mit Wireshark [2] ans Licht brachte. Die Header dienen gewöhnlich dazu, Dinge wie die Terminalemulation oder sogar X-Forwarding auszuhandeln. Bei der Malware stand in den Headern nur Unsinn, der aber stets die gleiche 4-Byte-Sequenz am Anfang des Pakets enthielt.
Next Generation
Die zweite Generation versuchte sich als DNS-Paket zu tarnen. Dieses Mal nutzte sie den UDP-Port 53, wollte aber wieder Server im selben Netz in Asien kontaktieren. Der gewollte DNS-Traffic im Netzwerk wanderte zwischen Clients und dem Active Directory Controller hin und her, weil Letzterer den Clients per DHCP als DNS-Server zugewiesen war. Ungewollter Traffic ließ sich über
tcpdump -i eth0 port 53 and not host IP-Adresse-des-AD-Controllers
herausfiltern. Hier spürte Tcpdump also jenen Traffic auf, der an Port 53 ging, aber nicht an den Active-Directory-Server. Die Analyse mit Wireshark ergab zudem, dass die bereits aus den Telnet-Paketen bekannte Sequenz wieder am Anfang der Pakete auftauchte. Hinzu kam, dass die Pakete auch hier keine gültigen DNS-Pakete waren.
Last Generation
Die letzte Version der Malware versuchte es schließlich auf dem HTTP-Port 80, ging aber auch wieder aufgrund ungültiger HTTP-Pakete ins Netz. Ergänzend fielen bereits ab Version 2 der Malware DNS-Anfragen auf unterschiedliche Hosts in drei verschiedenen Subdomains auf. Das Opfer des Angriffs besaß mehrere Standorte, daher gab es mehrere Übergänge ins Internet.
Trotz der Microsoft-Dominanz liefen die Gateways und DNS-Server glücklicherweise auf Linux-Basis. So konnte der Autor schnell auf Spurensuche gehen. Da sich die infizierten Systeme in der konkreten Situation jedoch in einem produktiven Netzwerk tummelten, blieb ihm allerdings nur eine Live-Analyse als Handlungsoption.
Sicherheitsarchitekturen
Viele Firmen erlauben ihren Mitarbeitern ausgehende Zugriffe auf das Internet über das Firmen-Gateway. In der Regel protokollieren sie den erlaubten Verkehr an der Firewall auch nicht mit. Dieses Vorgehen hat auch Nachteile: Wären die Logs durch eine Log-Management-Lösung wie ELK [3] oder Splunk [4] gelaufen, hätten sich die Rechner sehr einfach eingrenzen lassen, denn der Traffic über die Ports 23 oder 53 ist eher atypisch.
Läuft der Webzugriff zuerst über einen firmeninternen Proxy, sind zumindest all jene Rechner verdächtig, die nicht diesen Proxy anlaufen, sondern eine direkte Verbindung auf die Ports 80 oder 443 nach außen suchen.
Blockiert zudem die Firewall ausgehende Verbindungen, die nicht von Rechnern mit bekannten Diensten (Proxy, DNS-Server, Mailserver und so weiter) stammen, kann der Analyst auch einfach nach verworfenen Paketen fahnden, die eine Adresse außerhalb als Zielort verwenden. In einer perfekten Welt sollte es kaum solche Pakete geben.
Clients, die doch welche senden, sind in diesem Fall entweder (abhängig von Ziel und Port) falsch konfiguriert oder müssten eben vom Admin näher in Augenschein genommen werden.
Wireshark: Freund der Forensiker
Wireshark [2] ist das Standardtool der Industrie, wenn es darum geht, aus mitgeschnittenen Paketen auf das Netzwerkgeschehen zu schließen. Im Gegensatz zu Tcpdump erlaubt die große Anzahl an Protokollmodulen für Anwendungsprotokolle wie HTTP oder SMTP eine viel tiefer gehende Analyse.
Zugleich unterstützt Wireshark den Admin massiv darin, die Nadel im Heuhaufen zu finden. Die Software macht es möglich, Filter auf jedes Protokollfeld zu setzen. Abbildung 1 zeigt einen Wireshark-Displayfilter für alle HTTP-Pakete, die die »POST«-Methode verwenden und an den Zielhost »192.168.1.1« gehen.
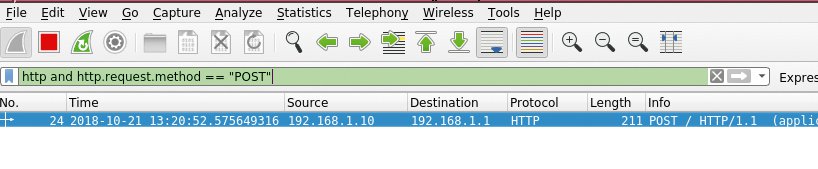
Abbildung 1: Wireshark mit Displayfilter für HTTP-Pakete, die auf die »POST«-Methode setzen.
Über Bande
Grundsätzlich raten Security-Experten davon ab, Wireshark mit Rootrechten zu betreiben. In den Paketanalyse-Modulen der Software stecken immer wieder Fehler. Die könnten Angreifer dazu nutzen, bösartige Pakete in den untersuchten Verkehr zu schmuggeln, die dann nicht nur bei Wireshark zu unerwünschtem Verhalten führen.
Empfohlen wird vielmehr, erst mit Tcpdump eine ».pcap«-Datei zu erzeugen und diese dann über eine unprivilegierte Benutzerkennung oder über eine Named Pipe auszuwerten. Dazu legt der Nutzer zuerst eine Pipe mit dem Kommando »mkfifo /tmp/wirepipe« an. Dann ruft er Wireshark über das Kommando »wireshark -k -i /tmp/wirepipe« auf. Nun lassen sich in diese Pipe Pakete unter Root-Kennung einfüttern. Das lässt sich wahlweise mit dem Befehl »tcpdump -w /tmp/wirepipe« erledigen, dem der Nutzer auf Wunsch noch einen Filter für Pakettypen mit auf den Weg gibt.
Alternativ verwendet er das Kommando »dumpcap -w /tmp/wirepipe«. Auch Dumpcap [5] versteht einige Optionen, um etwa das Interface, von dem die Pakete kommen sollen, auszulesen. Die Option »-f« erlaubt es dabei, einen Filter in »tcpdump«-Syntax anzugeben.
Neben den Protokollanalysatoren bietet Wireshark auch Statistikfunktionen, die bei der Analyse helfen. Für die Suche nach den infizierten Systemen dient hier der Menü-Eintrag »Conversations« als ein erster Anlaufpunkt. Darüber findet der Admin gegebenenfalls Endpunkte außerhalb seines Netzes, die verdächtig sind. Ist die IP-Adresse eines Kontrollservers im Idealfall bekannt, finden sich so schnell sämtliche Systeme, die mit diesem kommunizieren.
Konsolenhai
Das grafische Frontend von Wireshark eignet sich sehr gut zur Offline-Analyse. Sind viele Daten im Spiel, wird das aber mitunter sehr speicherintensiv. Hier kann der Kommandozeilen-Bruder T-Shark [6] in die Bresche springen, er unterstützt dieselben Protokoll-Analysatoren wie Wireshark. Wie Tcpdump kann auch T-Shark eine Ausgabe aller HTTP-Pakete auf der Konsole liefern, deren Request-Methode »SEARCH« ist. Abbildung 2 setzt T-Shark auf ein Capture-File mit dem genannten Filter an.
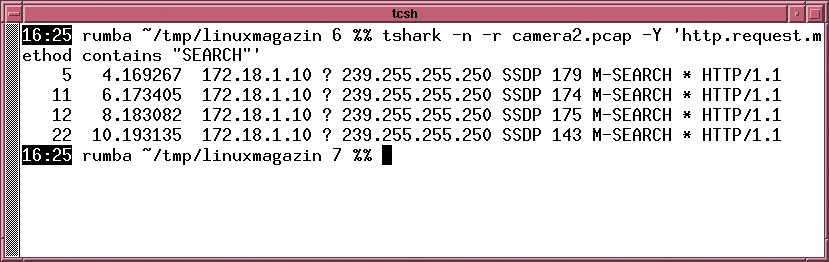
Abbildung 2: Mit einem Displayfilter macht sich T-Shark über ein Capture-File (»camera2.pcap«) her.
Ist die Suche zu Beginn der Analyse noch etwas unscharf, nutzt der Admin danach den vollen Umfang üblicher Linux-Tools wie Grep, Awk, Perl oder Python.
Es gibt mehrere Möglichkeiten fürs Filtern. Die allgemeinste Option lautet »-Y«. Über die Option »-e« zeigt T-Shark hingegen nur ausgewählte Felder an. Dadurch enthält die Ausgabe nur die relevanten Informationen zur Suche (zum Beispiel die Quell- und Ziel-IP-Adresse) und vergrößert den ohnehin schon großen Heuhaufen nicht noch unnötig.
Zur Option »-e« gehört auch die Option »-T«, die das Ausgabeformat definiert. Ein Aufruf kann dann etwa so aussehen:
tshark -T json -e ip.addr -r Capture-File
Dank des Parameters »-T json« gibt T-Shark die Daten strukturiert in Json aus, sodass eine weiterverarbeitende Software keinen Parser mehr braucht, sondern die Standardbibliothek nutzt.
Verdächtige Namen
Im anfangs vorgestellten Fall gingen spätere Versionen der Malware dazu über, ihren C&C-Server per DNS zu finden. Dazu verwendeten sie den lokalen DNS-Server. Das lässt dem Admin zwei Optionen: Er kann den gesamten DNS-Traffic auswerten oder beim Einsatz von Bind als rekursivem Resolver erst einmal einen Blick in die Datenbank werfen. Hier schaut er, ob er auf verdächtige Einträge stößt.
Das Kommando »rndc dumpdb« erzeugt einen Abzug aller gecachten Einträge in der Datei »named_dump.db«. Die landet in dem Verzeichnis, das in der »named.conf« für den Nameserver unter »options« | »directory« eingetragen ist. Diese Datei enthält in einem großen Zonefile sämtliche Records, die der Nameserver zu diesem Zeitpunkt kennt. Der Admin sollte hier am ehesten die A-Records herauspicken.
Gehen die Angreifer etwas trickreicher vor, sollte er prüfen, ob das lokale Netzwerk in Richtung Internet eher ungewöhnliche Record-Typen abfragt. Ein wenig Analyse mit Grep & Co. hilft hier weiter. Der folgende Befehl liefert eine einfache Liste aller abgefragten Hostnamen (aber auch anderer Records):
egrep '^[a-zA-Z0-9]' /var/lib/bind/named_dump.db | grep -v PTR | sort | less
Die Sortierung hilft dabei der manuellen Analyse. Jedoch ist eine Suche nach verwendeten Domains ebenfalls sinnvoll. Das nächste Kommando fahndet nach den gecachten SOA-Records:
grep SOA /etc/bind/dns/named_dump.db | awk '{print $2}' | sort
Leider enthält diese Datei keine Informationen darüber, wer eine gegebenenfalls verdächtige Anfrage gestellt hat. Aber das Ergebnis der Analyse kann der Admin verwenden, um mit T-Shark die DNS-Anfragen nach dem Fragesteller zu filtern. Da Angreifer, die DNS-Namen für ihre C&C-Server verwenden, deren Gültigkeit häufig auf einen kurzen Zeitraum beschränken und ihre Server immer wieder bewegen, kann diese Analyseform zielführend sein. Die Frage ist aber, ob überhaupt DNS zum Einsatz kommt.
Angeln im Datenfluss
Eine Alternative zu T-Shark und Tcpdump ist das Einsammeln von Netflow-Daten. Das Netflow-Protokoll [7] stammt ursprünglich von Cisco und kursiert auch unter anderen Namen (etwa J-Flow bei Juniper). Die Technologie sammelt Verbindungsdaten und exportiert diese in einem UDP-Strom an einen Netflow-Collector, der sie dann verarbeitet.
Es gibt verschiedene Iterationen des Protokolls. Version 9 ist als RFC 3954 standardisiert. Viele Hersteller unterstützen es, der Linux-Kernel bringt ein entsprechendes Kernelmodul mit. Unter dem Namen Ipfix ist auch Version 10 des Protokolls verbreitet.
Konkret sendet der Exporter Daten über IP-Verbindungen. Darin steht konkret, welche IP-Adresse auf welchem Quellport mit welcher Ziel-IP-Adresse auf welchem Zielport kommuniziert. Zusätzlich übermittelt der Exporter Daten über die Menge der gesendeten Pakete sowie der übermittelten Bytes in jeder Richtung.
Sammeldienst
Der Netflow Collector hilft bei der Analyse. Er steckt in einer Reihe verschiedener Tools, da Forensiker oft mehrere Datenquellen zusammenführen müssen. Der Artikel betrachtet den Netflow Collector im ELK-Stack.
ELK steht für eine Kombination aus Elasticsearch, Logstash und Kibana. Unter [8] beschreibt die Webseite von Elastic das einfache Setup für einen Single Host, bei dem alle drei ELK-Komponenten auf einer Maschine laufen. Der Aufruf
bin/logstash --modules netflow --setup -M netflow.var.input.udp.port=XXXX
initialisiert die Dashboards in Kibana und legt auch ein paar Mappings an. Gleichzeitig startet der Aufruf Logstash mit einer Instanz, die auf Port XXXX Netflow-Pakete annimmt. Listing 1 zeigt eine Ergänzung des »conf.d«-Verzeichnisses, die den Netflow-Dienst beim regulären Start von Logstash aktiviert. Laut Input-Block in Zeile 4 ist auch Version 10 (Ipfix) aktiviert, was im vorher genannten Aufruf nicht der Fall war.
Listing 1
Logstash mit Netflow
01 input {
02 udp {
03 port => 2055 codec => netflow {
04 versions => [5, 9, 10]
05 } type => netflow tags => "netflowdata"
06 }
07 }
08
09 output {
10 if "netflowdata" in [tags] {
11 elasticsearch {
12 hosts => "127.0.0.1" index => "netflow-%{+YYYY.MM.dd}"
13 }
14 }
15 }
Mit Linux-Gateway
Kommen Linux-Gateways zum Einsatz, gibt es zwei Möglichkeiten, wie diese Netflow-Daten produzieren: Open Vswitch [9] erlaubt es, für jede Bridge Netflow-Daten zu exportieren. Alternativ existiert ein »ipt_NETFLOW«-Kernelmodul, das im Zusammenspiel mit IPtables-Regeln Flow-Daten exportiert. Der Admin installiert das Paket entweder aus der Distribution oder aus dem Git-Archiv unter [10]. Beim Selberbauen muss er zuvor natürlich die zum Bauen notwendigen Pakete installieren.
Das Kernelmodul benötigt die Information, wohin es die Daten senden soll. Der Aufruf zum Installieren sieht also folgendermaßen aus:
modprobe ipt_NETFLOW destination=172.25.1.117:2055,protocol=10
Den zweiten Parameter darf der Admin auch weglassen, da Version 10 Standard ist. Die »2055« ist die zur Logstash-Konfiguration passende Portnummer.
Noch aber fängt der Linux-Rechner nicht an Daten zu senden. Erst IPtables-Regeln mit dem Target »NETFLOW« sorgen dafür. Im einfachsten Fall setzt der Admin auf einem Linux-Router das Kommando
iptables -I FORWARD -j NETFLOW
ab. Fällt die Regel spezieller aus, sendet das Gateway nur bestimmte Pakete weiter. Als Forensiker sollte der Admin die Suche auf jene Pakete einschränken, die durch das Gateway laufen und nicht im internen Netz bleiben wollen. Die Aufgabe besteht ja darin, verdächtige Verbindungen nach außen zu finden.
Netzwerkhardware
Klassische Netzwerkhardware beherrscht das Netflow-Protokoll oft ohne zusätzliche Module, wobei Admins bei manchen Herstellern womöglich eine Zusatzlizenz brauchen. Bei Netzwerkhardware sollten sie jedoch darauf achten, dass nicht die meist schwache CPU der Managementeinheit die Aufgabe des Flow-Sammelns übernimmt. Einen Router, der in Hardware mehrere 100-GBit/s-Schnittstellen bedient, überfordert dies schnell.
Hier ist die Sample-Rate der Schlüssel, um das Gleichgewicht zwischen Datensammeln und Überlastung des Systems zu steuern. Das erlaubt eine Datensammlung auch auf Netzwerkgeräten, denen Tcpdump fehlt.
Hier müsste der Admin andernfalls erst einen Spiegelport aufsetzen und dort einen Linux-Rechner installieren. Die Installation sammelt im ersten Schritt Daten, dann kommt Kibana (Abbildung 3) zum Zuge, um diese zu sichten. Die Dashboards »NetFlow: Conversation Partners« beziehungsweise »NetFlow: Traffic Analysis« bieten Überblicke.
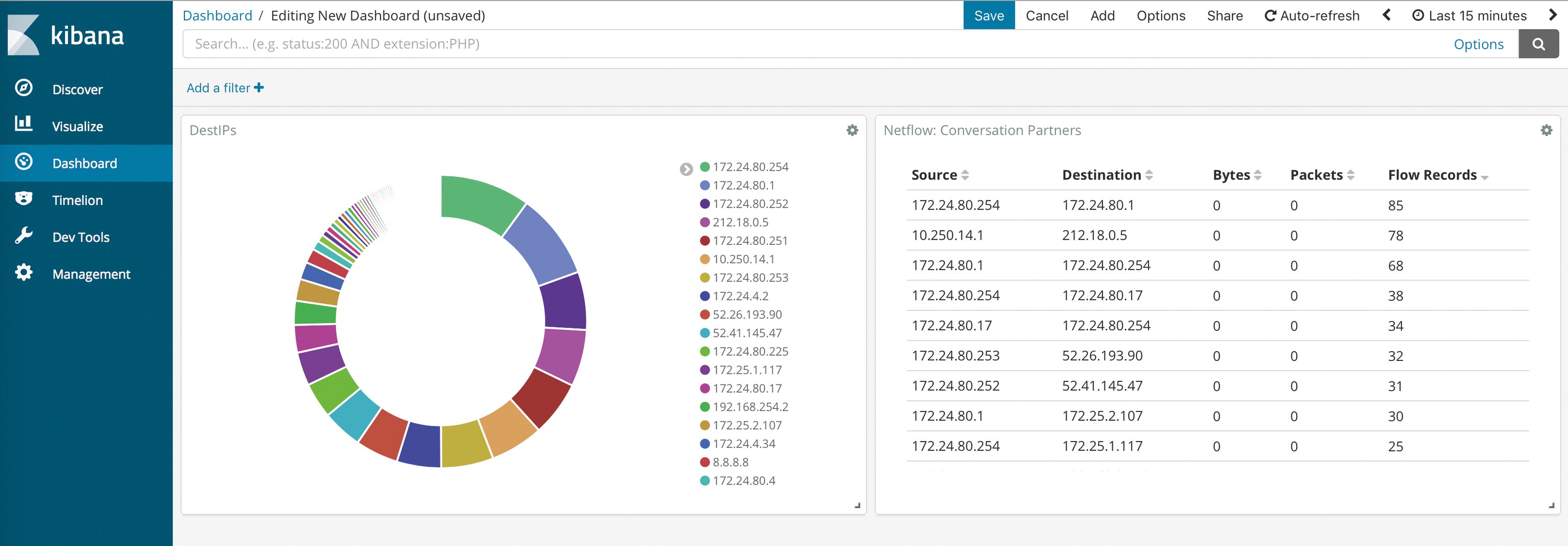
Abbildung 3: Das Kibana-Dashboard lässt sich an verschiedene Bedürfnisse anpassen.
Auf der Suche nach der oder den Nadeln im Heuhaufen verwendet der Admin nun die Filterfunktion oben auf der Webseite. Im Wesentlichen geht es darum, Bekanntes großflächig auszusortieren.
Die Timeline-Visualisierungen nach dem Ziel, die über die Zeit sammeln, wie viele Pakete oder Bytes aus dem Netzwerk an welches Ziel gehen, können im normalen Bürobetrieb auffälliges Verhalten anzeigen. Selbst ohne Proxy sollten Admins in den Nebenzeiten maximal Updates einspielen und die Spitzen in der Nebenzeit untersuchen. Auch hierbei schließt der Netzwerker dann wieder bekannte Verbindungen aus und beobachtet den restlichen Traffic (Abbildung 4).
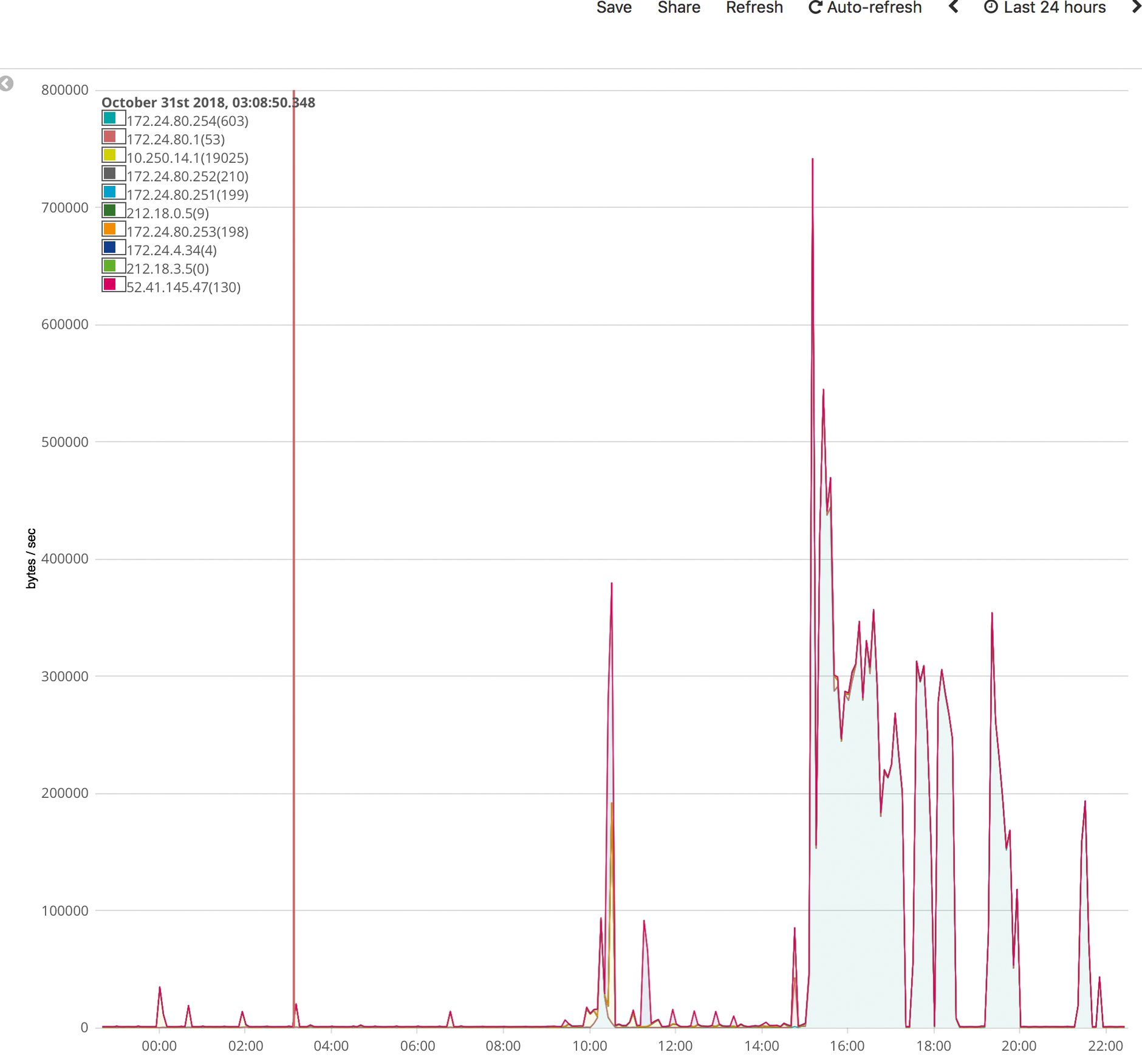
Abbildung 4: Im 24-Stunden-Graphen sollte der Admin die Spitzen in der Nacht im Drill-down untersuchen.
Suchen, die Kibana nicht direkt abbilden kann, etwa komplexere statistische Auswertungen, ermöglicht in dieser Konstellation das Elasticsearch-API.
Wonach suchen?
Eine pauschale Antwort, die sich technisch einfach umsetzen ließe, gibt es hier nicht. Wichtig ist es, den bekannten und gewollten Traffic auszusortieren, damit sich Detailuntersuchungen auf die relevanten Verbindungen konzentrieren. Das Zählen von Verbindungspaaren ist etwa ein simpler statistischer Ansatz.
Im Endeffekt sucht der Admin das Ungewöhnliche – getreu dem Sherlock-Holmes-Motto: “Once you eliminate the impossible, whatever remains, no matter how improbable, must be the truth.” Auf Netzwerkebene kann das Traffic sein, den es normalerweise nicht geben sollte. Der äußert sich vielleicht darin, dass Systeme auf ungewöhnlichen Ports mit ungewöhnlichen Zielen kommunizieren (oder dies versuchen).
Die andere Achse, um ungewöhnliches Verhalten festzumachen, ist die Zeitachse. Immer wieder findet sich Malware, die sehr regelmäßig nach Hause telefoniert. Hier ist ein Herzschlagmuster auf der Zeitachse ein guter Indikator. Arbeiten die Mitarbeiter von 9 bis 17 Uhr im Büro, sollten die Desktops höchstens gegen Mitternacht Updates einspielen. Existiert ein lokaler Updateserver, sollte Traffic nach außen ganz fehlen.
Auch die geografische Verteilung des Traffic in Richtung Internet ist interessant. Fehlen Geschäftsbeziehungen zu ehemaligen Sowjetrepubliken und stammen auch keine Mitarbeiter von dort, lässt sich der Traffic dorthin als ein Warnzeichen deuten.
Kommt ein Webproxy zum Einsatz, ziehen Admins auch dessen Logs als Datenquelle heran. Zusätzlich zur Analyse unbekannter Domainnamen und Ziel-IPs in ungewöhnlichen Ländern trägt hier auch der HTTP-Returncode zur Klärung der Situation bei. Häufig verschwinden C&C-Server wieder, ohne dass die Malware dies bemerkt. Zugriffe über den Proxy schlagen dann fehl, hinterlassen aber eine Spur. Ein unbekannter Host sorgt bei Squid als Proxy für den Fehlercode 503:
1541025318.775 32 10.10.10.10 TCP_MISS/503 4040 GET http://www.skjhskshdf.sfkhskfshf/ - HIER_NONE/- text/html
Der Code allein ist noch kein Indikator, reduziert aber die Menge der zu durchsuchenden Logs massiv.
Wer suchet, der findet
Fördert eine der vorgestellten Methoden eine Auffälligkeit zutage, sei es einen Domainnamen, einen Netzwerkbereich im Internet oder Ähnliches, sollte der Admin alle Quellen nach dem Auftreten des Indikators abklopfen. Nicht selten bleibt nur ein Indikator unverändert (etwa nur der Port bei wechselnden Adressen oder Domainnamen).
Um die Arbeit zu erleichtern, erweisen sich Lösungen wie ELK als nützlich, denn die Suche nach den infizierten Systemen ist sprichwörtlich die im Heuhaufen. Je größer das Netzwerk, desto größer der Heuhaufen.
Gesunder Menschenverstand gepaart mit dem Wissen, was im eigenen Netzwerk als normal gilt, helfen dem Admin in der Regel, mit den vorgestellten Datenquellen den normalen Traffic auszufiltern, um die Nadel zu finden.
Infos
-
Tcpdump: http://www.tcpdump.org
-
Wireshark: http://www.wireshark.org
-
ELK-Stack: https://www.elastic.co/de/elk-stack
-
Splunk: https://www.splunk.com
-
Dumpcap: https://www.wireshark.org/docs/man-pages/dumpcap.html
-
T-Shark: https://www.wireshark.org/docs/man-pages/tshark.html
-
Netflow-Modul für Logstash: https://www.elastic.co/guide/en/logstash/current/netflow-module.html
-
Open Vswitch: http://www.openvswitch.org
-
»ipt_NETFLOW«-Kernelmodul: https://github.com/aabc/ipt-netflow





