
© sinenkiy, 123RF
Große Cloudbetreiber wie Amazon, IBM, Google und Microsoft machen Entwicklern ein verlockendes Angebot: Eine Funktion kostet nur dann, wenn sie auch läuft. Obendrein skaliert sie automatisch und darf die übrigen Dienste des Konzerns nutzen. Der Test zeigt: Serverless-Offerten sind meist eine Geschmacksfrage.
Das Konzept hinter dem verschwurbelten Begriff Function as a Service (FaaS) ist simpel: Entwickler laden den Quellcode einer Funktion in die Cloud und bestimmen, wann diese starten soll. Um den Rest kümmert sich die Cloud. Das spart Servermiete, denn Kosten fallen nur an, wenn die Funktion auch läuft. Das für FaaS häufig verwendete Synonym Serverless verwirrt eher. Nicht nur, weil eben doch Server zum Einsatz kommen, sondern auch wegen des gleichnamigen Serverless Framework [1].
Alle großen Cloudanbieter bieten FaaS-Dienste an. Zu den Ersten zählte Amazon AWS mit Lambda. Es folgten Google Cloud Functions, IBM Cloud Functions und Microsoft Azure Functions.
Gemeinsam verschieden
Alle vier Dienste arbeiten analog: Upload und Verwaltung des Quellcodes erfolgen wahlweise über spezielle Kommandozeilen-Werkzeuge oder eine Weboberfläche, die meist etwas missverständlich “Console” heißt. Sie fällt bei allen Diensten eher unübersichtlich aus, wobei nicht hilft, dass alle Anbieter eigene Terminologien verwenden. Die Einarbeitung erfordert also Zeit (Abbildung 1).
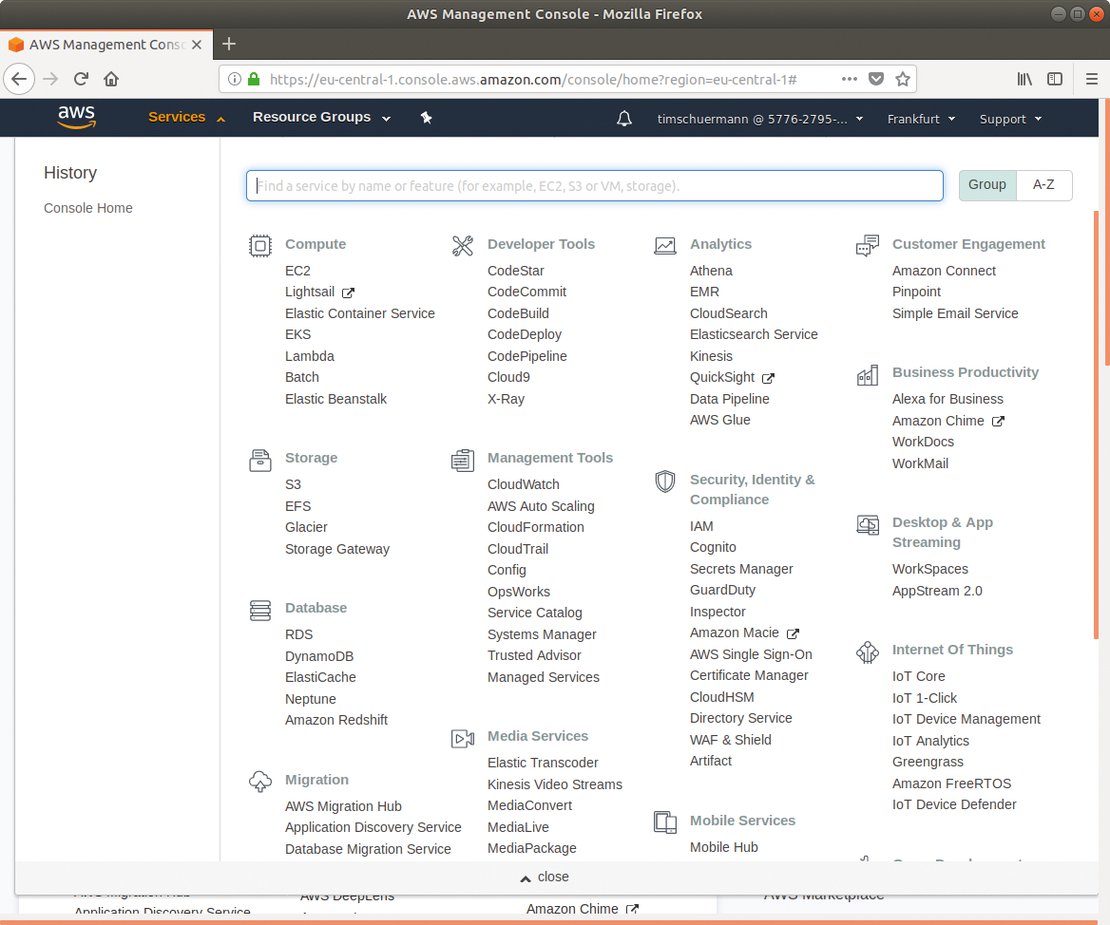
Abbildung 1: Kleines Suchbild: Amazon erschlägt seine Nutzer mit den verfügbaren Clouddiensten. Den Link zu AWS Lambda findet der Anwender erst bei genauerem Hinsehen.
Die vom Entwickler hochgeladene Funktion kann über spezielle APIs auf andere Clouddienste zugreifen. Das gelingt aber durchweg nur mit den Diensten des jeweiligen Betreibers selbst. Wer seinen Code etwa Amazon anvertraut, kann ohne größere Verrenkungen lediglich die von Amazon bereitgestellten Speicherlösungen wie S3 oder Dynamic DB nutzen. Google sieht seine Cloud Functions sogar explizit als Verbindungsglied zwischen seinen übrigen Diensten.
Da er mit jedem weiteren eingesetzten API oder Dienst den Wechsel zur Konkurrenz erschwert, sollte der Nutzer vorher gut überlegen, an welchen FaaS-Dienst er sich langfristig binden möchte.
Intern stimmen die Unternehmen ihre Clouddienste gut aufeinander ab. Sie trimmen etwa ihre Datenbanken darauf, große Informationsmengen zu verarbeiten, die Entwickler dann performant durch ihre Funktionen leiten.
Anstoß
Starten lässt sich eine Funktion manuell über die Weboberfläche oder die Kommandozeilentools. Alternativ läuft sie beim Aufruf einer vom FaaS-Dienst generierten URL an. Auf diese Weise lassen sich recht einfach REST-Schnittstellen implementieren.
Auf Wunsch stoßen auch einige der übrigen Clouddienste die Funktion an. Lädt jemand eine neue Datei in Amazons S3-Speicher, ruft der Dienst automatisch eine AWS-Lambda-Funktion auf, die ihrerseits die Datei verarbeitet.
Der Quellcode einer Funktion darf dabei zusätzliche (Hilfs-)Funktionen enthalten, die sich gegenseitig aufrufen. Die Clouddienste starten aber stets nur eine Funktion, die der Entwickler jeweils explizit benennen muss. Außerdem hinterlegt er auf Wunsch Umgebungsvariablen (teils Parameter genannt), welche die Funktion dann auswertet. Das hilft besonders beim Debugging.
Alle vier Clouddienste würgen eine laufende Funktion nach einer vorgegebenen Zeitspanne ab. Entwickler dürfen dieses Intervall in Grenzen selbst herunter- und heraufsetzen.
Preisvergleich
Solange die Funktion nicht läuft, fallen bei allen vier Diensten keine Kosten an. Die genauen Preise hängen von mehreren Faktoren ab, die von Dienst zu Dienst variieren (siehe Kasten “Quanta Costa”). Bei Amazon ändern sich etwa die anfallenden Kosten mit dem benötigten Hauptspeicher. Obendrauf kommen in jedem Fall noch Gebühren für alle weiteren von der Funktion genutzten Clouddienste, darunter Zugriffe auf die Datenbank.
Quanta Costa
Die Berechnung der Kosten für die einzelnen Dienste kann schnell die Hirnwindungen verdrehen. Wer es dennoch probieren möchte, für den folgen hier die bei Redaktionsschluss gültigen Kostenstrukturen der vier Dienste.
Bei Amazon erhalten Entwickler pro Monat eine Million Aufrufe und 400000 GByte/s Datenverarbeitungszeit gratis. Für die übrigen Amazon-Dienste wie die Datenbank Dynamo DB gibt es ebenfalls kostenlose Kontingente, die sich aber wie im Fall von Amazon S3 teilweise auf zwölf Monate nach der Registrierung beschränken. Darüber hinaus verlangt Amazon für eine Million Aufrufe 0,20 US-Dollar.
Hinzu kommen weitere Kosten, die vom ausgewählten Hauptspeicher abhängen. Dessen Wahl bestimmt auch über die verfügbare kostenlose Rechenzeit. So sind die beworbenen 3,2 Millionen Sekunden Rechenzeit nur dann umsonst, wenn sich die Funktion mit 128 MByte RAM begnügt. Bei 3 GByte gibt es beispielsweise nur noch 136170 freie Sekunden. Auch die Kosten für zusätzliche Rechenzeiten hängen vom Hauptspeicher ab. Jeder angefangene 100-Millisekunden-Takt kostet bei 128 MByte Hauptspeicher 0,000000208 US-Dollar, bei 3 GByte hingegen schon 0,000004897 US-Dollar. Die Abrechnung erfolgt in jedem Fall in 100-Millisekunden-Schritten.
Bei Google fallen für 1 Million Aufrufe 0,4 US-Dollar an, zudem sind pro GHz-Sekunde Rechenzeit 0,00001 US-Dollar fällig. Hinzu kommen noch 0,0000025 US-Dollar pro GByte-Sekunde. Wer Daten aus der Google-Cloud herausschickt oder aus dem Internet empfängt, zahlt zusätzlich pro übertragenem GByte 0,12 US-Dollar. Neue Nutzer erhalten nach dem Anmelden 300 US-Dollar Startguthaben. Das müssen sie innerhalb von zwölf Monaten verbraten, und es gilt für alle Google-Dienste, die der Internetkonzern unter dem Begriff Google Cloud Platform bündelt. Dazu gehört eine NoSQL-Datenbank (Google Cloud Database).
Kostenlos spendiert Google zudem 2 Millionen Aufrufe und 1 Million Sekunden Rechenzeit pro Monat. Die übrigen Dienste sind bei der kostenlosen Nutzung ebenfalls limitiert, die NoSQL-Datenbank nimmt zum Beispiel nur 1 GByte an Daten auf. Google behält sich zudem die Änderung dieser Angebote explizit vor.
Die Preismodelle von IBM und Microsoft sind demgegenüber recht übersichtlich: Bei IBM zahlen Entwickler 0,000017 US-Dollar pro Ausführungssekunde pro GByte zugeordnetem Hauptspeicher. Wie Amazon rundet auch IBM auf jeden angefangenen 100-Millisekunden-Takt. Die ersten 5 Millionen Ausführungen pro Monat sind kostenlos, sofern der Entwickler seiner Funktion nur den kleinsten Speicherausbau zugesteht.
Microsoft verlangt pro GByte-Sekunde 0,000014 Euro, 1 Million Funktionsaufrufe kosten 0,169 Euro. Microsoft berechnet dabei eine Mindestlaufzeit von 100 Millisekunden. Entwickler dürfen jeden Monat 1 Million Anforderungen und 400000 GByte-Sekunden gratis verbraten. Wer sich neu bei Azure anmeldet, darf zwölf Monate kostenlos auf einige Azure-Dienste zugreifen und bekommt obendrauf noch 170 Euro Guthaben, das aber nach 30 Tagen verfällt. Zahlreiche Dienste bieten zudem wie die Functions dauerhaft kostenlose Kontingente an.
Dieser Kostendschungel erschwert den Preisvergleich für ein konkretes Projekt. IBM, Google und Microsoft stellen immerhin einen Preisrechner bereit, mit dem Entwickler die wahrscheinlichen Kosten für ihre Anwendung überschlagen können (Abbildung 2).
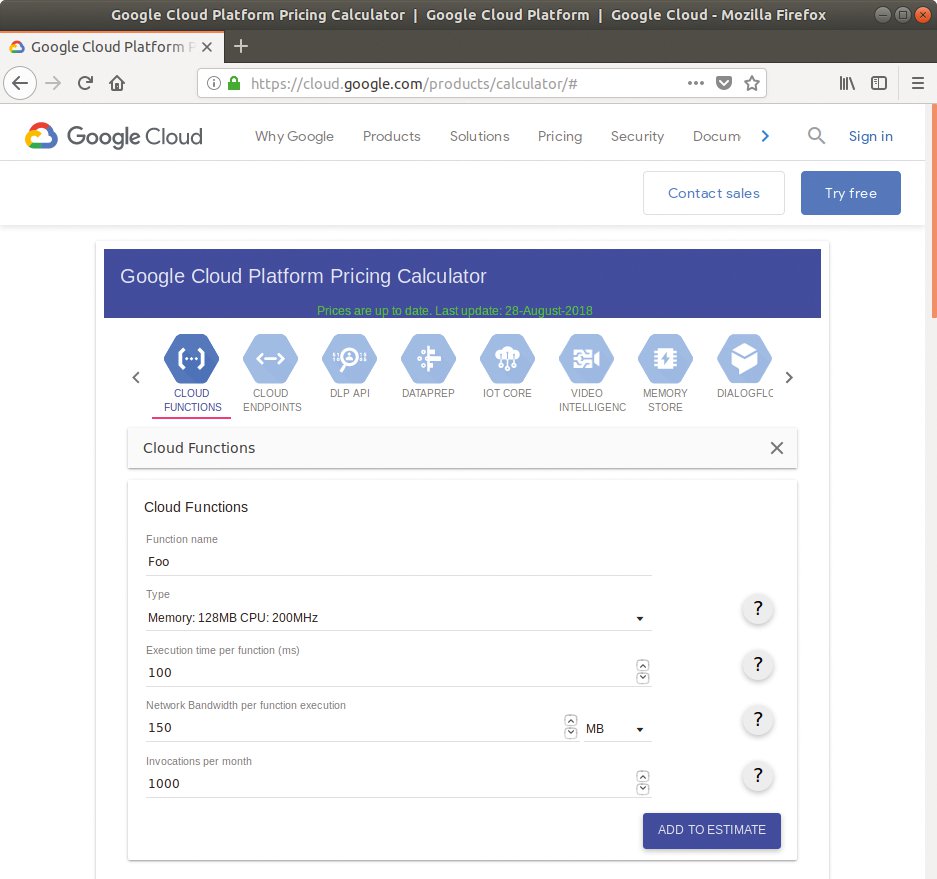
Abbildung 2: Googles Preisrechner gehört noch zur komfortableren Sorte. Hier lassen sich sogar unterschiedliche Szenarien zu einem Gesamtbetrag addieren.
Die vier FaaS-Dienste kennen nur wenige, dafür weitverbreitete Programmiersprachen. Dazu zählt bei allen Javascript. Der Programmcode selbst muss zustandslos sein. Wer Daten (zwischen-)speichern möchte, muss dazu andere Clouddienste einspannen. Im Gegenzug skalieren alle Dienste die Funktionen automatisch, jeder Aufruf startet dann eine eigene Instanz der Funktion.
Alle Betreiber pflegen eine ausführliche Dokumentation, die mit Tutorials und Praxisbeispielen den Einstieg erleichtert. Ihre Gliederung und der didaktische Aufbau sind durchweg verbesserungsbedürftig, bei Microsoft verwirrt zusätzlich die etwas holprige deutsche Übersetzung.
Alle Dienste bewerben ihre Angebote zugleich mit mehreren bekannten Kunden. Die Seattle Times und Coca-Cola nutzen etwa Amazon, der Medienkonzern Turner und die Internetfirma Meetup setzen auf Google. IBM zählt unter anderem den Aufzugspezialisten Kone zu seinen Kunden, während Microsoft mit Zeiss und Fujifilm kokettiert.
Amazon AWS Lambda
Amazon berechnet die Kosten für seinen Dienst AWS Lambda aus der Anzahl der Funktionsaufrufe, der tatsächlichen Laufzeit und dem benötigten Hauptspeicher [2]. Der Quellcode darf in den Programmiersprachen Java, Javascript (mit Node.js), Go, C# oder Python vorliegen. C#-Funktionen sind auf Dotnet Core beschränkt. Für Visual Studio und Eclipse bietet Amazon Erweiterungen an, mit denen Entwickler den Quellcode in die Amazon-Cloud hochladen.
Neben der Weboberfläche stellt Amazon gleich zwei Kommandozeilentools bereit: Die fertige Lambda-Funktion testet der Entwickler zunächst lokal mit dem Sam CLI. Das AWS CLI lädt die Funktion in die Cloud und kümmert sich um die übrigen Verwaltungsaufgaben. In jedem Fall müssen Entwickler vor dem Upload einen IAM-Benutzer anlegen, der über administrative Rechte verfügt. Der Entwickler gibt dann beim Zugriff auf die Amazon-Dienste die Zugangsdaten des IAM-Benutzers an.
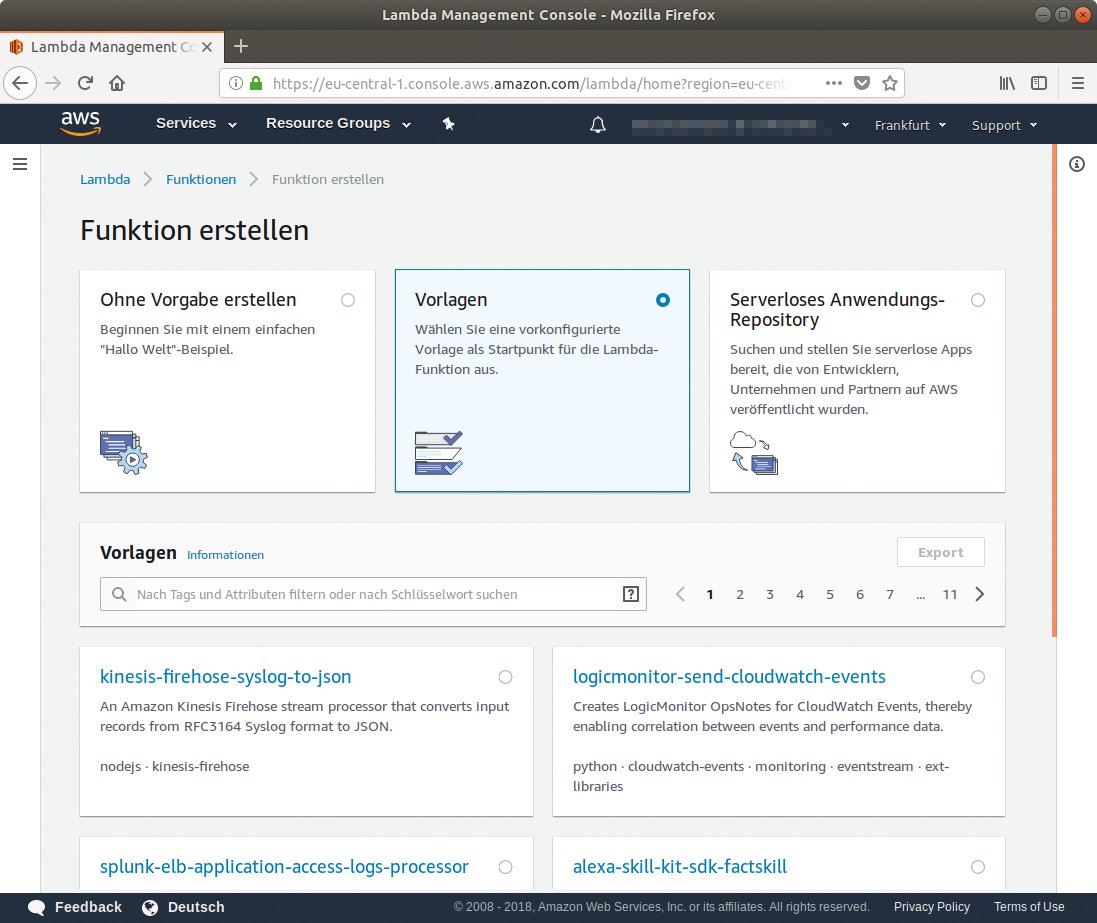
Abbildung 3: In AWS erleichtern es Vorlagen, Funktionen zu erzeugen, die häufige Anwendungsfälle abdecken.
Die Weboberfläche offeriert neben dem Anlegen einer einfachen »Hallo Welt«-Funktion auch zahlreiche Vorlagen (Abbildung 3). Den in ihnen enthaltenen Programmcode passt der Entwickler nur noch an seine eigenen Bedürfnisse an (Abbildung 4). Darüber hinaus erhält er Zugriff auf von Drittentwicklern bereits vorgefertigte Funktionen.
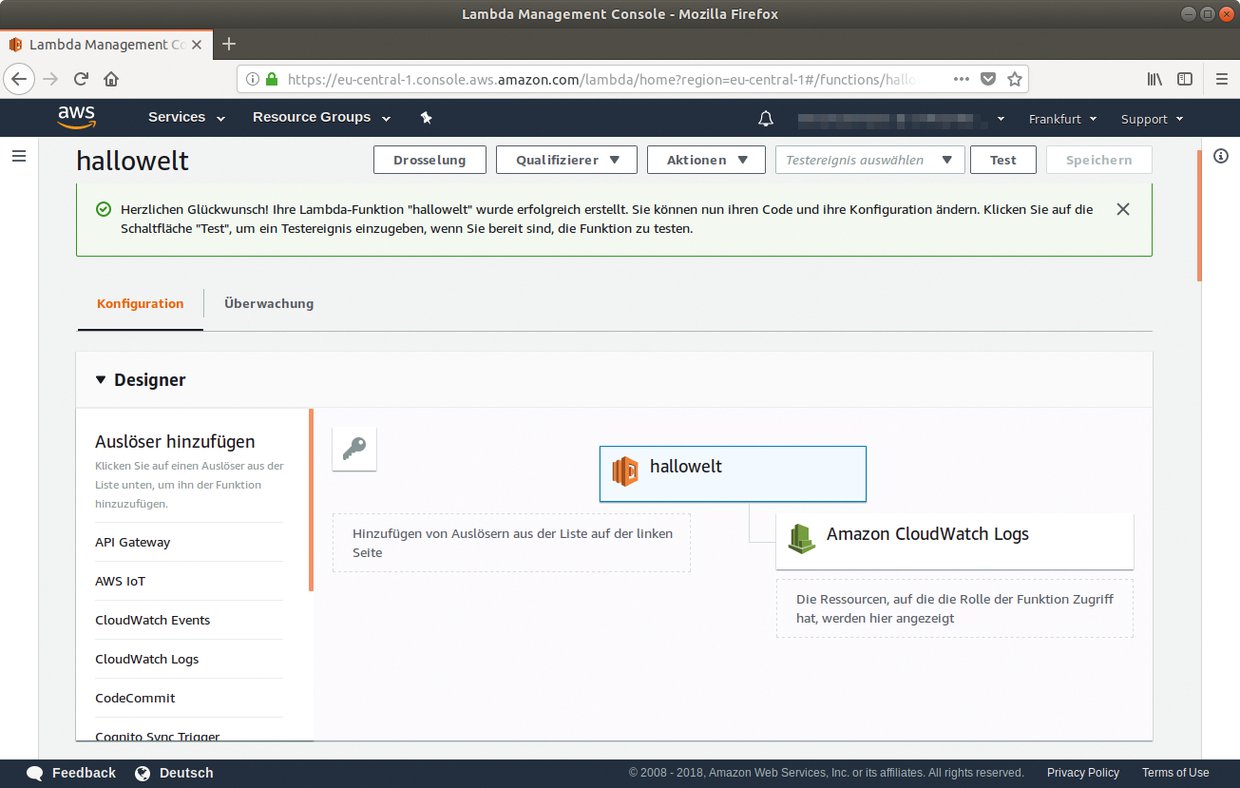
Abbildung 4: Der Designer zeigt an, welche Dienste die Funktion auslösen und auf welche weiteren Clouddienste sie zugreifen darf. Weitere Auslöser ergänzt der Entwickler per Drag & Drop.
Seiner neuen Funktion muss der Entwickler immer eine so genannte Rolle zuweisen, sie fasst alle notwendigen Berechtigungen zusammen. Zudem legt er fest, wie lange die Funktion maximal laufen darf, begrenzt bei Bedarf die Anzahl der parallel ausgeführten Instanzen und weist ihrer Funktion zwischen 128 MByte und 3 GByte Speicher zu. Über den Dienst AWS Step Functions lässt sich die Funktion zudem in einen Workflow einbinden.
Die Weboberfläche von Amazon stellt zur Eingabe des Quellcodes eine IDE bereit, die auf dem Code-Editor Ace basiert (Abbildung 5, [3]). Sie bringt sogar eine kleine Dateiverwaltung mit, mehrere Quellcode-Dateien lassen sich parallel in Tabs öffnen. Wer den Code vorbereitet hat, kann ihn als Zip-Archiv hochladen oder aus einem S3-Speicher holen. Amazon bietet eine einfache Versionsverwaltung, die sich auf Knopfdruck ältere Fassungen der Funktion merkt.
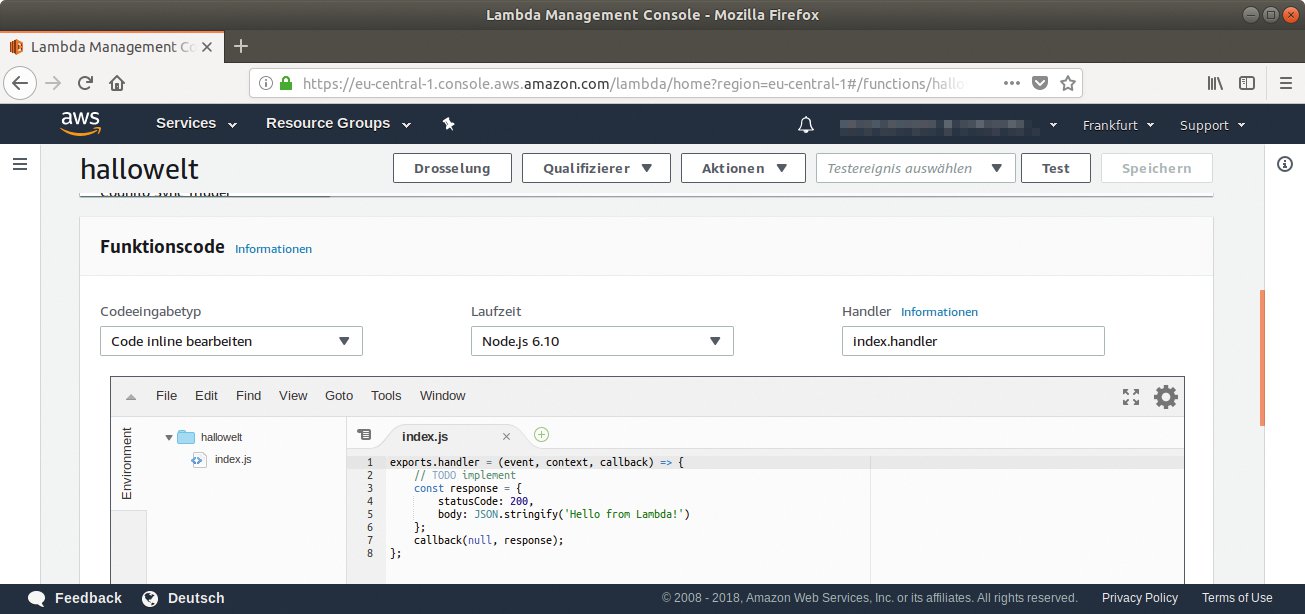
Abbildung 5: Amazon stellt in seiner Weboberfläche die umfangreichste IDE bereit, die aber dennoch nicht an den Komfort von bekannten lokalen Entwicklungsumgebungen heranreicht.
Eine Lambda-Funktion darf der Entwickler mit Tags versehen, wodurch er die Funktionen gruppiert und filtert. Ein einfaches Beispiel in Javascript zeigt Listing 1. Der Funktion übergibt Amazon in »event« Informationen über den Auslöser und in »context« über die Laufzeitumgebung. So verrät etwa »context.getRemainingTimeInMillis()«, wie lange die Funktion noch laufen darf. Die »callback()«-Funktion reicht die Ausgaben an den Aufrufer zurück. Diesen Weg beschreiten Entwickler insbesondere dann, wenn ihre Funktion eine Internetseite montiert und zurückliefert. Wer mit seinen Lambda-Funktionen ein eigenes REST-API aufbauen möchte, muss dazu den Amazon-Dienst API Gateway einspannen.
Listing 1
Beispielfunktion für Amazon Lambda
01 exports.hallowelt = (event, context, callback) => {
02 callback(null, 'Hallo Welt');
03 };
Wer die Lambda-Funktion direkt aus dem Web-UI starten möchte, richtet dazu zunächst einen Test ein. Dieser merkt sich etwa die an die Funktion zu übergebenden Parameter. Entwickler hinterlegen pro Funktion bis zu zehn Tests und rufen diese später schnell ab.
Deren Resultate zeigt unter anderem die IDE, zudem protokolliert AWS die Ausführung über seinen Dienst Cloudwatch. Aus den Daten erzeugt Amazon zugleich mehrere Diagramme, die unter anderem die Anzahl der Aufrufe in den letzten Stunden visualisieren.
Die AWS-Funktionen laufen auf Wunsch in einem Rechenzentrum in den USA, Kanada, Asien, Australien, Südamerika sowie Europa, darunter auch eines in Frankfurt.
AWS CLI
Das AWS CLI setzt Python ab Version 2.6.5 oder 3.3 voraus, seine Installation erfolgt über den Python-Paketmanager Pip. Für die folgende Konfiguration der Tools muss der Entwickler in der Weboberfläche eine Access Key ID und einen Secret Access Key erzeugen. Nur mit diesen beiden kryptischen Schlüsseln erhalten die Kommandozeilenwerkzeuge Zugriff auf die Amazon-Dienste.
Sofern noch keine Rolle für die Lambda-Funktion existiert, muss der Entwickler sie ebenfalls vorab anlegen – wahlweise über die Weboberfläche oder den Kommandozeilenbefehl »aws iam«. Anschließend lassen sich Funktionen über das Tool »aws« erzeugen und aufrufen.
Das Beispiel aus Listing 2 lädt zunächst die Funktion namens »hallowelt()« hoch, wobei der Quellcode im Zip-Archiv »hallowelt.zip« liegt. Die zuvor angelegte Rolle besitzt den internen Bezeichner »arn:aws:iam::577627958015:role/service -role/halloweltRolle«.
Listing 2
Funktion in Lambda anlegen und aktivieren
01 aws lambda create-function \ 02 --function-name hallowelt \ 03 --zip-file file://hallowelt.zip \ 04 --role arn:aws:iam::577627958015:role/service-role/halloweltRolle \ 05 --handler index.hallowelt \ 06 --runtime nodejs6.10 \ 07 --region eu-central-1 08 aws lambda invoke --function-name hallowelt \ 09 --region eu-central-1 output.txt
Amazon soll zudem im Quellcode die Funktion »hallowelt()« aus der Quellcodedatei »index.js« aufrufen (»–handler index.hallowelt«). Bei ihr handelt es sich um eine Javascript-Funktion, die wiederum die Laufzeitumgebung Node.js 6.10 voraussetzt. Als Rechenzentrum soll »eu-central-1« fungieren. In ihm startet der zweite Befehl die Funktion »hallowelt()«, die Ausgaben landen in der Datei »output.txt«.
Sam CLI
Das Sam getaufte Kommandozeilen-Interface startet die Funktion in einem Docker-Container, der wiederum die Lambda-Umgebung simuliert. Folglich setzt Sam eine Docker-Umgebung voraus. Das Tool selbst landet ebenfalls per Pip auf dem Rechner.
Listing 3
Yaml-Konfigurationsdatei für Amazons Sam CLI
01 AWSTemplateFormatVersion: '2018-09-01' 02 Transform: AWS::Serverless-2016-10-31 03 Resources: 04 hallowelt: 05 Type: AWS::Serverless::Function 06 Properties: 07 Handler: index.hallowelt 08 Runtime: nodejs6.10
Entwickler beschreiben die notwendigen Amazon-Dienste und die entsprechende Umgebung in einer entsprechenden Datei im Yaml-Format. Listing 3 zeigt ein zu Listing 2 passendes Beispiel für eine solche Konfiguration. Anschließend lässt sich die Funktion aufrufen. Die ihr zu übergebenden Parameter stecken in der Datei »event.json«:
sam local invoke "hallowelt" -e event.json
Neben dem normalen AWS Lambda offeriert Amazon noch den Dienst Lambda@Edge. Dabei führt Amazon die Funktion in einem Rechenzentrum möglichst nahe bei dem Kunden aus und verspricht so sehr niedrige Latenzen. Die Kosten für die Anfragen erhöhen sich dann allerdings, zudem gibt es kein kostenloses Kontingent.
Google Cloud Functions
Google Cloud Functions befand sich zu Redaktionsschluss noch im Betastadium [4]. Die Gebühren berechnen sich aus der Anzahl der Aufrufe sowie der verbrauchten GHz-Sekunden und der GByte-Sekunden Rechenzeit. Weitere Kosten fallen an, wenn die Funktion Daten aus der Google-Cloud verschickt oder von außen empfängt.
Den Quellcode geben Entwickler direkt wie in Abbildung 6 in ein einfaches Eingabefeld ein oder laden ihn als Zip-Archiv hoch, das auch in einem Cloud Storage liegen darf. Alternativ holt Google den Quellcode aus einem Cloud-Quellrepository.
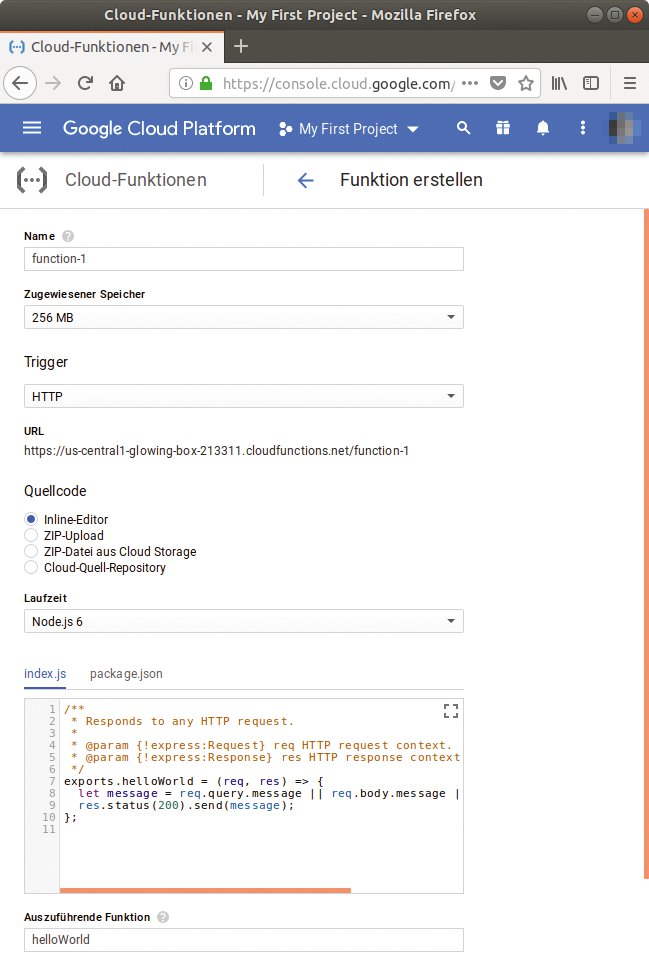
Abbildung 6: Google gibt automatisch ein einfaches »Hello World«-Beispiel vor, das Entwickler als Ausgangspunkt verwenden.
Google unterstützt derzeit nur Javascript und Python. Nutzern stehen zudem nur fünf Rechnerkonfigurationen zur Wahl. Die kleinste bietet ein System mit 128 MByte Speicher und einem 200-MHz-Prozessor. Am Ende des Leistungsspektrums steht ein System mit 2 GByte Speicher und 2,4 GHz Taktfrequenz.
Eine einfache Funktion in Javascript zeigt Listing 4. Google übergibt zwei Objekte, welche die Anfrage und die Antwort kapseln. Deren Aufbau gibt das von Google verwendete Javascript-Framework Express [5] vor. Wer ein REST-API braucht, wählt als Auslöser eine HTTP-Anfrage (von Google als HTTP-Trigger bezeichnet). Der Dienst erzeugt dann eine URL, über die der Entwickler die Funktion bequem aktiviert.
Listing 4
Beispielfunktion für Google Cloud Function
01 exports.hallowelt = (req, res) => {
02 res.status(200).send('Hallo Welt');
03 };
Zusätzlich zum Quellcode muss der Entwickler ein paar Metadaten im Json-Format hinterlegen. Lädt er den Quellcode hoch, verstaut er die Metadaten in der Datei »package.json«, in der Weboberfläche hinterlegt er ihren Inhalt auf einem eigenen Register. Im einfachsten Fall enthält die Datei wie in Listing 5 den Namen des Pakets und die Versionsnummer.
Listing 5
Beispiel für die package.json
01 {
02 "name": "hallowelt",
03 "version": "0.0.1"
04 }
Die Funktion darf in einem von vier Rechenzentren laufen, zur Wahl stehen zwei in den USA sowie jeweils eines in Asien und Europa. Während Google die Funktion ausführt, protokolliert es dies ausführlich in einem Log und visualisiert die Ausführungsdauer in einem Diagramm (Abbildung 7).
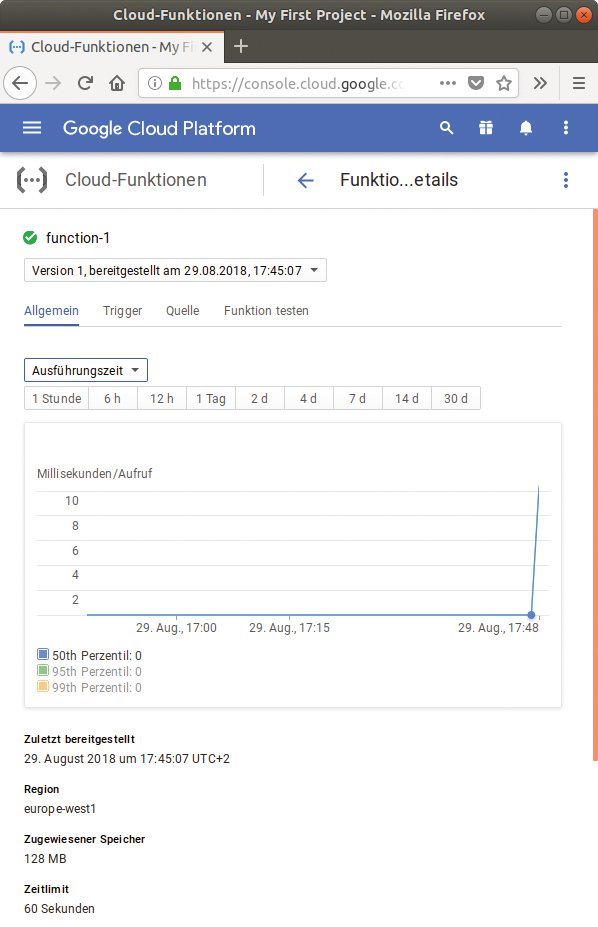
Abbildung 7: Google hält für jede Funktion ein einfaches Diagramm bereit, das die Ausführungsdauer visualisiert.
Kommandozeile
Alternativ zur Weboberfläche ziehen Entwickler ein Kommandozeilen-Programm aus dem Google Cloud SDK heran. Das setzt auf Linux-Systemen Python ab Version 2.7.9 voraus. Das SDK steht als Tar.gz-Archiv für 64- und 32-Bit-Systeme bereit. Ist das SDK auf der Festplatte korrekt eingerichtet, muss sich der Entwickler nur anmelden und den Quellcode hochschieben:
gcloud auth login gcloud functions deploy hallowelt --trigger-http --project mein-projekt-123456
In diesem Beispiel lädt das Tool den Quellcode aus dem aktuellen Verzeichnis hoch, wobei Google später die Funktion »hallowelt« aufruft und diese bei einer HTTP-Anfrage startet, die Funktion landet im Projekt mit der ID »mein-projekt-123456«. Dann spuckt das Tool alle relevanten Informationen aus, darunter die benötigte URL. Die ruft der Entwickler etwa mittels Curl auf, um so die Funktion zu aktivieren.
IBM Cloud Functions
Der FaaS-Dienst von IBM basiert auf dem quelloffenen Apache Open Whisk ([6], [7]). Wie bei der Konkurrenz legen Entwickler selbst fest, wie viel Hauptspeicher ihre Funktion nutzen darf – maximal möglich waren bei Redaktionsschluss 512 MByte. Die anfallenden Kosten hängen vom Speicherausbau und der Anzahl der Funktionsaufrufe ab.
IBMs Dienst bringt einen eigenen Editor mit (Abbildung 8). Entwickler schreiben ihren Quellcode wahlweise in Javascript (mit Node.js), Swift, Java, Go, PHP und Python. Auf Wunsch zündet IBMs Dienst beliebige Docker-Container. Über diesen Umweg setzen Programmierer nahezu alle Sprachen ein.
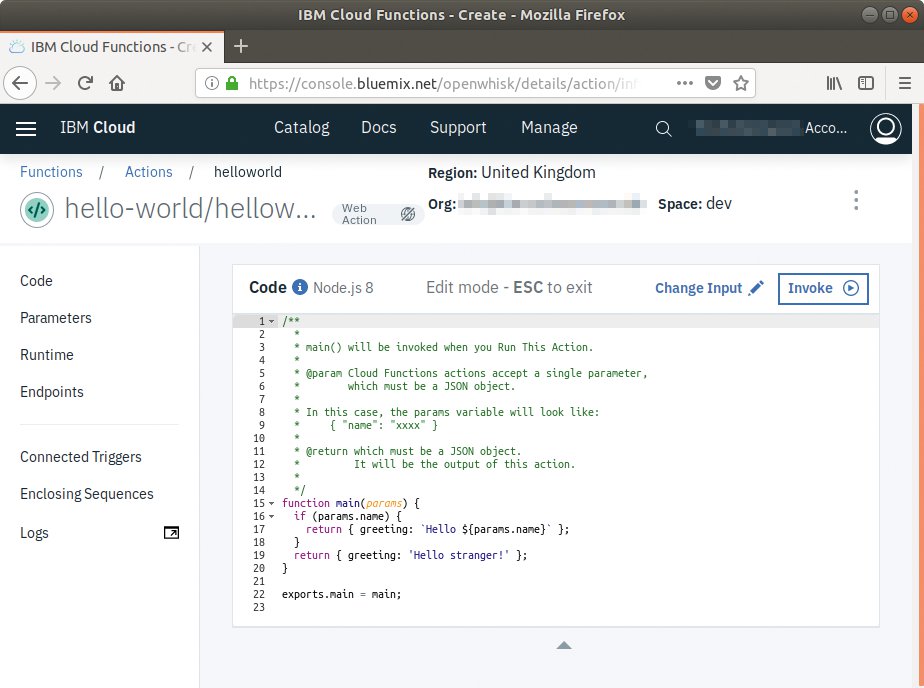
Abbildung 8: Bei IBM erfolgt die Eingabe des Programmcodes in einem einfachen Editor. Der bietet Syntax Highlighting an, blendet Codeteile aus und nummeriert die Zeilen.
IBM hält einige Vorlagen mit vorgefertigten Funktionen bereit, die als Ausgangspunkte für eigene Exemplare dienen können. Eine einfache Funktion in Javascript zeigt Listing 6. Der FaaS-Dienst verlangt zwingend eine Funktion »main()«, die er beim Start der Funktion aufruft. Ihr übergibt er dann ein Json-Objekt mit allen Parametern, die der Entwickler in der Weboberfläche hinterlegt hat. Eventuelle Rückgabewerte müssen ebenfalls als Json-Objekt verpackt sein.
Listing 6
Beispiel einer Funktion für IBM Cloud Functions
01 function main(params) {
02 return { payload: 'Hallo Welt!' };
03 };
04
05 exports.main = main;
Als Auslöser für eine Funktion dienen auch die externen Dienste Github und Slack. Entwickler binden sogar weitere eigene externe Dienste an. Sie dürfen mehrere Funktionen nacheinander ausführen, wobei die Ausgabe einer Funktion der jeweils nächsten als Eingabe dient. Auf diese Weise definieren sie Workflows, setzen aus einzelnen Aufgaben komplexere zusammen und verwenden Funktionen erneut.
Für jede Funktion generiert IBM automatisch eine URL, über die sich diese aktivieren lässt. HTTP-Anfragen verarbeitet die Funktion aber nur, wenn der Entwickler dies explizit gestattet. Wer mit seinen Funktionen ein REST-API aufbauen möchte, spannt dazu einen entsprechenden Auslöser ein.
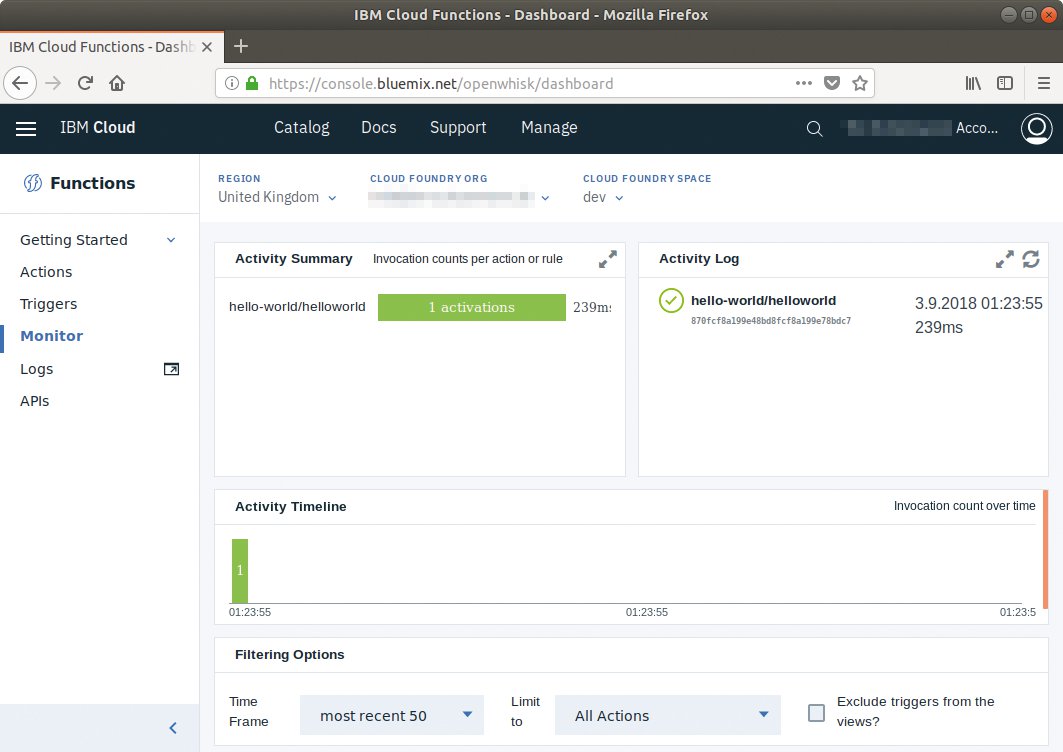
Abbildung 9: Bei IBM zeigt das Monitoring als Zusatzinformation die Ausführungszeiten in Millisekunden an.
Der Start einer Funktion gelingt per Knopfdruck, die Ausgaben der Funktion erscheinen direkt in der Weboberfläche. Ein dabei erzeugtes Ausführungsprotokoll wertet der Clouddienst Kibana aus, das Monitoring zeigt die Anzahl der Aufrufe der einzelnen Funktionen in einem Diagramm an (Abbildung 9). Die Funktionen laufen in einem von vier Rechenzentren in Großbritannien, Deutschland oder Amerika (Ost und Süd).
Auf Kommando
Über die Weboberfläche lassen sich nur Funktionen in Javascript, Python, Swift oder PHP einrichten. Java-Funktionen und Docker-Container müssen Entwickler über die Kommandozeilen-Werkzeuge verwalten. Letztere bezeichnet IBM als Bluemix CLI (teilweise auch inkonsistent als IBM Cloud CLI). IBM stellt die Tools wahlweise als Installationspaket oder als fertiges Binärprogramm in einem TGZ-Paket bereit. Das Bluemix CLI gibt es für 32- und 64-Bit-Systeme mit x86-Architektur sowie 64-Bit-Power-PC-Prozessoren.
ibmcloud fn action create hallowelt hallowelt.js ibmcloud fn action invoke hallowelt --blocking --result
Nach der Installation müssen Anwender noch ein Plugin installieren, das dem CLI die Kommunikation mit den IBM Cloud Functions beibringt. Anschließend meldet sich der Entwickler über einen separaten Befehl an und lädt seine Funktion hoch. Das folgende Beispiel hievt den Code aus der Datei »hallowelt.js« in die Cloud, wobei die Funktion den Namen »hallowelt« trägt. Der zweite Befehl startet diese Funktion:
Die beiden Parameter am Ende bewirken, dass der Aufruf die Ausgabe der Funktion auf der Kommandozeile anzeigt.
Microsoft Azure
Im Rahmen seiner Azure Cloud bietet Microsoft die Azure Functions [8] an, die sich auch von Linux aus nutzen lassen. Die Kosten berechnen sich aus der Anzahl der Ausführungen und dem Ressourcenverbrauch in GByte-Sekunden. Azure fasst mehrere Funktionen in einer so genannten Funktionen-App zusammen. Diese erhält auch eine eigene Subdomain unter ».azurewebsites.net«. Den Namen der App und somit der Subdomain dürfen Entwickler frei wählen, er muss allerdings eindeutig sein. Aus der Subdomain bildet Microsoft auch alle URLs, deren Aufruf eine Funktion auslösen.
Neben der URL und Microsoft-Diensten wie der Azure Cosmos DB dienen auch Github-Webhooks als Auslöser für Funktionen. Zu jeder Funktions-App gehört zwingend ein Storage-Konto in Azure. Den dortigen Speicher benötigt Microsofts Dienst, um unter anderem die Ausführungsprotokolle zu lagern.
Azure unterstützt offiziell die Programmiersprachen C#, F# und Javascript. Experimentelle Unterstützung gibt es für Java, Python, PHP, Typescript, Windows-Batch-Dateien, Bash-Skripte und Powershell. Die Hauptspeichergröße wählen Entwickler selbst, mindestens stehen einer Funktion 128 MByte zu, maximal sind 1,5 GByte möglich. Microsoft stellt die meisten Rechenzentren zur Auswahl, darunter mehrere in Australien, Brasilien, Kanada, Indien, USA, Asien, Japan, Großbritannien und Europa.
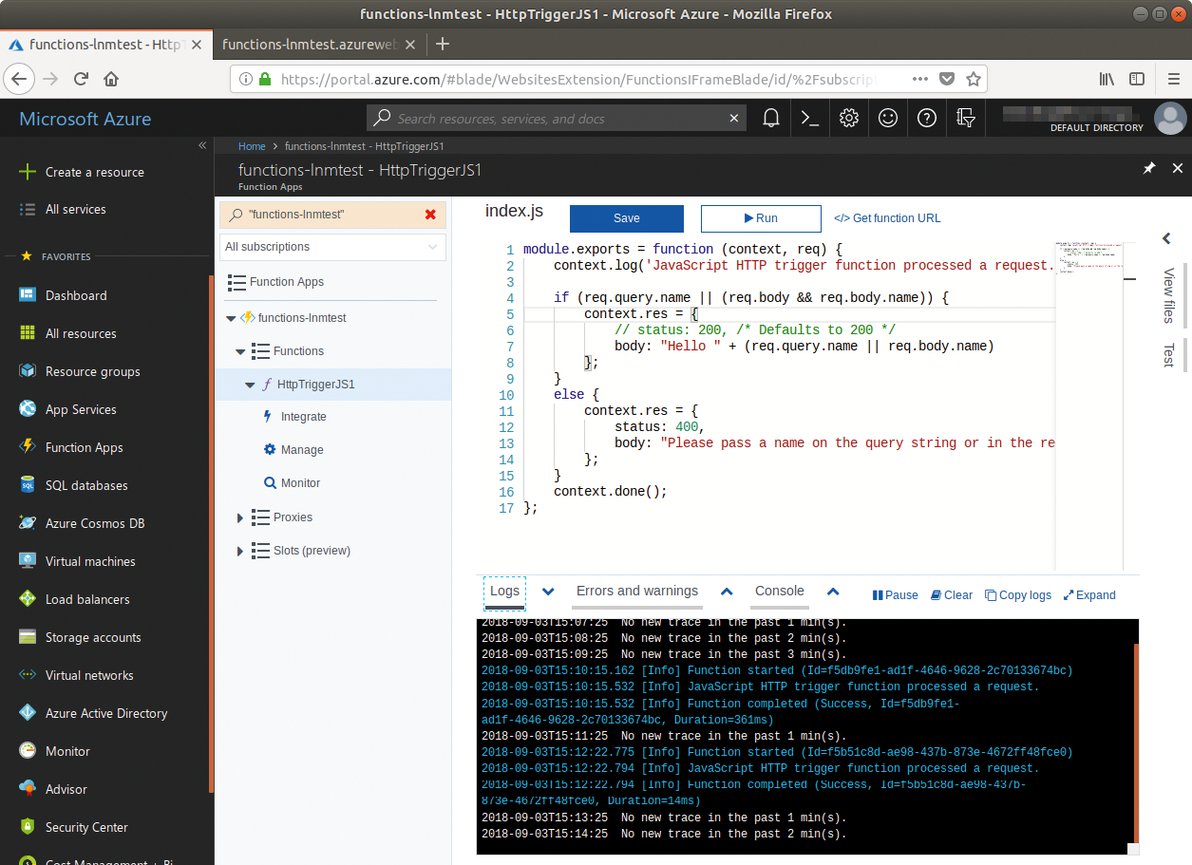
Abbildung 10: Die IDE von Microsofts Azure verwaltet mehrere Dateien, nummeriert die Zeilen durch und erleichtert die Navigation mit einer Minimap am rechten Seitenrand.
Listing 7 zeigt ein Beispiel für eine Azure-Funktion in Javascript. Ähnlich wie bei der Konkurrenz übergibt Azure an die Funktion ein Objekt, das Informationen über die Laufzeitumgebung kapselt. »context.res« nimmt zudem die Antwort bei einer HTTP-Anfrage auf, während »context.done()« der Laufzeitumgebung das Ende der Funktion mitteilt.
Listing 7
Beispiel-Funktion in Microsoft Azure
01 module.exports = function (context) {
02 context.res = {
03 body: "Hallo Welt"
04 };
05 context.done();
06 };
Den Quellcode gibt der Entwickler innerhalb der Weboberfläche in einer simplen IDE ein (Abbildung 10). Startet er die Funktion per Knopfdruck aus der Weboberfläche, wählt er sogar bequem aus, welche HTTP-Methode die Aufrufe nutzen und welche Daten im Header der Anfrage stehen sollen (Abbildung 11).
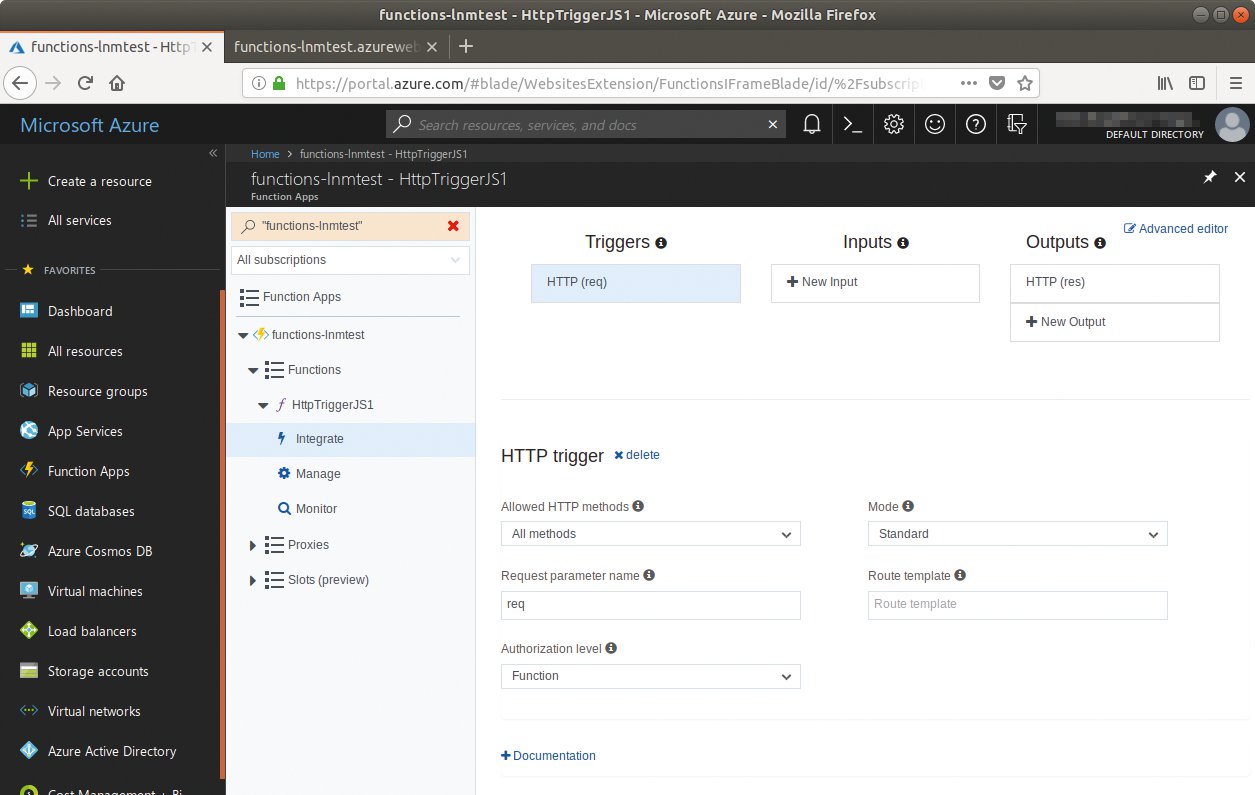
Abbildung 11: In der Weboberfläche von Azure Functions lässt sich mit ein paar Klicks regeln, dass die Funktion ausschließlich bei einer »GET«-Anfrage anspringt.
Die Ausführung protokolliert ein Log, das sich in der Weboberfläche am unteren Rand aufklappen lässt. Dort sammelt ein weiteres Register die Fehlermeldungen, während ein drittes Tab sogar den Zugriff auf die Dateien in einer Windows-Eingabeaufforderung ermöglicht. Für jede Funktion kann der Entwickler eine Liste mit allen bisherigen Ausführungszeitpunkten und der jeweiligen Ausführungsdauer abrufen.
Detaillierteren Einblick in die Ausführung gestattet der Dienst Application Insights. Für die lokale Entwicklung stehen Plugins für die hauseigene Entwicklungsumgebung Visual Studio 2017 bereit, zudem unterstützt Microsoft im Rahmen der Java-Entwicklung das Tool Maven.
Konsole am Steuer
Seine Azure CLI getauften Kommandozeilen-Werkzeuge stellt Microsoft auch für Linux bereit. Besitzer von Debian, Ubuntu, RHEL, Fedora, Centos, Open Suse und SLE holen die Tools aus entsprechenden Repositories. Auf anderen Distributionen gelingt die Installation über ein Shellskript. Voraussetzungen sind in jedem Fall die Programmiersprache Python ab Version 2.7, die Bibliothek Libffi und Open SSL ab Version 1.0.2. Alternativ offeriert Microsoft das Azure CLI in einem Docker-Image.
Um mit dem Azure CLI eine neue Funktion anzulegen, braucht der Entwickler die Befehle aus Listing 8: Zunächst meldet er sich an und erzeugt eine neue Ressourcen-Gruppe, die alle Funktionen-Apps sowie weitere Azure-Ressourcen logisch zusammenfasst. Im dritten Schritt des Listings ist ein Azure-Speicherkonto anzulegen, während der vierte Befehl eine Funktionen-App samt einer ersten Funktion erstellt. Für Letzteres sorgt maßgeblich der Parameter »–deployment-source-url«, der in Listing 8 den Beispiel-Quellcode aus einem von Microsoft bereitgestellten Github-Repository (»https://github.com/Azure-Samples/functions-quickstart«) holt.
Listing 8
htdist/lib/distr.ex
01 az login 02 az group create --name limaressourcegroup \ 03 --location westeurope 04 az storage account create \ 05 --name linuxmagazinstorage \ 06 --location westeurope \ 07 --resource-group limaressourcegroup \ 08 --sku Standard_LRS 09 az functionapp create \ 10 --deployment-source-url https://github.com/Azure-Samples/functions-quickstart \ 11 --resource-group limaressourcegroup \ 12 --consumption-plan-location westeurope \ 13 --name linuxmagazinapp \ 14 --storage-account linuxmagazinstorage
Welche Ereignisse die Funktionen dann auslösen, erfährt die Azure Cloud über entsprechende Konfigurationsdateien im Json-Format. Listing 9 zeigt die Konfigurationsdatei aus Microsofts Beispiel-Repository. Über die Allzweckwaffe Curl lässt sich dann beispielsweise die Funktion »HttpTriggerJS1()« der »linuxmagazinapp« aufrufen:
curl http://linuxmagazinapp.azurewebsites.net/api/HttpTriggerJS1?name=tim
Wie bei der Konkurrenz fallen nur dann Gebühren an, wenn eine Funktion läuft. Dieses Abrechnungsmodell bezeichnet Microsoft als Verbrauchsplan. Alternativ dazu nutzen Entwickler einen so genannten App-Service-Plan [9]. Unter ihm laufen alle Funktionen aus einer Funktions-App in einem eigenen virtuellen Container.
Listing 9
Beispieldatei functions.json für Azure
01 {
02 "disabled": false,
03 "bindings": [
04 {
05 "authLevel": "anonymous",
06 "type": "httpTrigger",
07 "direction": "in",
08 "name": "req"
09 },
10 {
11 "type": "http",
12 "direction": "out",
13 "name": "res"
14 }
15 ]
16 }
Für Linux-Anwender stellt Microsoft einen Standardcontainer bereit, Entwickler dürfen aber auch eigene Docker-Container nutzen. Das Ganze nennt Microsoft Azure Functions on Linux [10], die sich zu Redaktionsschluss noch in einem Vorschau-Stadium befanden.
Anders als beim Verbrauchsplan dürfen die Funktionen im Container beliebig lange laufen. Im Gegenzug fallen auch im Leerlauf Gebühren an. Der App-Service-Plan lohnt sich also vor allem dann, wenn die Funktionen über einen längeren Zeitraum gefordert sind.
Abschließend stellt Microsoft mit der Azure Functions Runtime eine Laufzeitumgebung [11] bereit, über die Entwickler lokal Funktionen programmieren und ausprobieren. Die ursprüngliche Version der Runtime läuft nur unter Windows. Microsoft arbeitet jedoch bereits an einer neuen ([12], [13]). Anders als der Vorgänger baut diese auf dem Framework Dotnet Core auf und läuft somit auch unter Linux. Die neue Runtime unterstützt jedoch nur die Programmiersprachen C#, Javascript und Java. Auch sie liegt nur als Preview vor und ist somit noch nicht bereit für den produktiven Einsatz.
Einer für alle
Jeder der hier vorgestellten Dienste bietet zwar eigene Kommandozeilentools an. Deren Bedienung und Parameter unterscheiden sich jedoch recht drastisch. Zudem erfordern sie teilweise mehrere Befehle, um eine Funktion in der Cloud zu erzeugen. Das erhöht insbesondere während der Entwicklungsphase den Arbeitsaufwand.
Genau den möchte das Serverless Framework reduzieren [1]. Das Projekt stellt ein Kommandozeilentool bereit, das selbst die Funktionen verwaltet. So genügt ein »serverless deploy -v«, um eine Funktion in die Cloud zu hieven.
Das Tool vereinheitlicht den Zugriff auf die FaaS-Dienste aber nur. Wer eine neue Funktion entwickelt, muss sich weiterhin für eine Cloud entscheiden. Die Konfiguration der dortigen Laufzeitumgebung wandert dann in eine spezielle Konfigurationsdatei im Yaml-Format. Ein einfaches Beispiel für die Amazon-Cloud könnte wie in Listing 10 aussehen.
Listing 10
AWS-Yaml-Konfiguration
01 service: my-service 02 03 provider: 04 name: aws 05 runtime: nodejs8.10 06 07 functions: 08 hallo: 09 handler: handler.hallo
Hier entsteht ein Dienst namens »my-service«, der in Amazon AWS eine Laufzeitumgebung für Node.js 8.10 einrichtet und dann eine Funktion namens »hallo()« erzeugt, die Amazon über einen Aufruf von »handler.hallo« aktivieren soll. Diese Informationen wertet das Serverless Framework aus und richtet die Cloud selbstständig passend ein.
Auch das Serverless Framework erlaubt es Entwicklern folglich nicht, Funktionen zu schreiben, die dann auf allen Diensten laufen. Das Projekt führt zudem eine eigene Terminologie ein, die sich stark an der von Amazon orientiert.
Seine Vorteile spielt das Serverless Framework vor allem bei der Entwicklung aus: Hat der Programmierer seine Funktion »hello()« zum Beispiel leicht verändert, genügt der kurze Kommandozeilenbefehl »serverless deploy function -f hello«, um sie auch in der Cloud zu aktualisieren.
Ruf nach Standards
Auch die Cloud Native Computing Foundation (kurz CNCF, [14]), ein Unterprojekt der Linux Foundation, hat das Potenzial der FaaS-Dienste erkannt. Eine eigens gegründete Serverless Working Group möchte ein offenes Ökosystem mit interoperablen APIs etablieren (hier das Whitepaper: [15]).
Unter anderem arbeitet die Organisation an einem standardisierten Format für Ereignisse und an Open-Source-Tools, welche die Arbeit der Entwickler und das Debuggen vereinfachen. Entwurfsmuster, Referenzarchitekturen und eine einheitliche Terminologie sollen neuen Anwendern den Einstieg erleichtern.
Zu den inzwischen zahlreichen CNCF-Mitgliedern zählen auch die im Artikel getesteten Firmen Amazon, Google, IBM und Microsoft. Wie weit sie ihre hier vorgestellten FaaS-Plattformen tatsächlich öffnen und vereinheitlichen, bleibt abzuwarten – schließlich sollen die zahlenden Kunden möglichst im Ökosystem des jeweiligen Unternehmens verharren. Die von der CNCF geforderte Interoperabilität könnte die Abwanderung zu anderen FaaS-Diensten erleichtern und somit die Gewinne schmälern.
Selbst bei der Terminologie gehen Amazon, Google & Co. derzeit ihre eigenen Wege. Aus diesen Gründen dürften Entwickler auch in naher Zukunft ihre eigenen Funktionen anpassen müssen, um sie auf einer anderen FaaS-Plattform in Betrieb zu nehmen.
Fazit
Alle vier FaaS-Dienste arbeiten nach dem gleichen Prinzip und ähneln sich. Die Unterschiede liegen in den bereitgestellten APIs und den Zusatzdiensten. Die Wahl des FaaS-Dienstes hängt somit maßgeblich von den eigenen Anforderungen ab, eine allgemeingültige Empfehlung lässt sich nicht aussprechen.
Wer zum Beispiel bereits Amazon S3 nutzt, kann direkt zu Amazon Lambda greifen. Sofern die Funktionen nicht nur Rechenzeit verbraten, sondern die APIs des entsprechenden Cloudbetreibers verwenden, macht sich der Entwickler vom gewählte Konzern abhängig. Eine Entscheidung für einen der FaaS-Dienste fällt folglich langfristig.
Infos
-
Serverless Framework: https://serverless.com/framework
-
Amazon AWS Lambda: https://aws.amazon.com/de/lambda
-
Ace: https://ace.c9.io
-
Google Cloud Functions: https://cloud.google.com/functions
-
Express: https://expressjs.com
-
IBM Cloud Functions: https://console.bluemix.net/openwhisk
-
Apache Open Whisk: https://openwhisk.apache.org
-
Microsoft Azure Functions: https://azure.microsoft.com/de-de/services/functions
-
App-Service-Plan: https://docs.microsoft.com/de-de/azure/azure-functions/functions-scale
-
Preview der Azure Functions on Linux: https://blogs.msdn.microsoft.com/appserviceteam/2017/11/15/functions-on-linux-preview
-
Azure-Functions-Runtime: https://docs.microsoft.com/de-de/azure/azure-functions/functions-runtime-overview
-
Versionen der Azure-Functions-Runtime: https://docs.microsoft.com/de-de/azure/azure-functions/functions-versions
-
Azure-Functions-Runtime 2.0: https://github.com/Azure/azure-functions-host/wiki/Azure-Functions-Runtime-2.0-Overview
-
Cloud Native Computing Foundation: https://www.cncf.io
-
Serverless Working Group Whitepaper: https://github.com/cncf/wg-serverless/tree/master/whitepapers/serverless-overview






