
© bowie15, 123RF
Amazon & Co. bieten gegen Bares mehr Performance. Möchte man ähnliche Effekte auf eigener Hardware erreichen, ist das viel komplizierter. Das Linux-Magazin zeigt, wie sich Datenbanken tunen lassen – und wo die Beschleunigung an die Grenzen der Technik stößt.
Der Vergleichstest zwischen einer Amazon-AWS-Datenbank und einer selbst betriebenen auf sehr potenter Hardware in diesem Heft belegt: Es kann bequem und funktionssicher sein, eine Datenbank in der Cloud zu betreiben – aber es ist nicht unbedingt billig. Wer sich vom Anbieter zudem IOPS-Werte garantieren lässt, bringt es schnell auf Rechnungen im hohen vierstelligen Bereich.
Dennoch: Die Einfachheit, mit der sich bei Amazon IOPS hinzuklicken lassen, besticht zweifellos: Wem die angebotenen 40000 IOPS bei gleichzeitiger Abnahme von 800 GByte reichen, der kommt leichter kaum an ein vergleichbares Setup.
Abgesehen von den Kosten gibt es aber Szenarien, in denen die Migration der Daten in eine Public Cloud keine Option ist. Ganz gleich, ob Compliance-Themen oder Privacy-Fragen eine Rolle spielen: Ist die Option AWS verwehrt, kommt der Admin kaum umhin, selbst Hand anzulegen. Möchte er ein neues Setup für IOPS-sensible Workloads bauen oder ein bestehendes Setup entsprechend tunen, ist das im Vergleich mit den wenigen Mausklicks bei AWS allerdings alles andere als leicht – und auch nicht komfortabel.
Dieser Artikel macht sich auf die Suche nach Möglichkeiten, Datenbanken zu tunen, die der Admin auf eigener Hardware betreibt. Eine große Rolle dabei wird auch die Frage spielen, wie die Datenbank provisioniert ist: Wurde sie auf einem Server manuell ausgerollt, sodass sie auf nacktem Blech läuft, oder existiert eine Abstraktionsschicht wie etwa eine Cloudumgebung?
Wie in dem berühmten Song von Daft Punk gilt auch im Hinblick auf Dienste in der IT bekanntlich das Prinzip “Harder, better, faster, stronger”. Konkret bedeutet das, dass jeder Admin ein natürliches Interesse daran hat, die unter seiner Obhut stehenden Dienste so performant wie möglich zu machen. Was aber ist Performance? Das ist gar nicht so leicht zu beantworten – und unterscheidet sich von Fall zu Fall.
Zwei Seiten
Einigkeit besteht allerdings darin, dass sich Performance in zwei große Subthemen aufteilt: Durchsatz und Latenz. Beim Thema Durchsatz steht die Frage im Mittelpunkt, wie viele Daten sich innerhalb eines definierten Zeitraums mit Hilfe der zur Verfügung stehenden Bandbreite übertragen lassen. Bei Latenz ist hingegen die Frage, wie lange es dauert, eine einzelne Information von Endpunkt zu Endpunkt zu übertragen.
Herausfordernd ist, dass Performance-Tuning immer die beiden Punkte Durchsatz und Latenz verbindet. Wie, das hängt maßgeblich davon ab, welchen Workload das Setup meistern soll. Optimiert man eine Installation im Hinblick auf ihre Bandbreite, ist das für Applikationen sehr nützlich, die in kurzer Zeit hohe Datenmengen transferieren müssen. Hohe Bandbreiten lohnen sich deshalb für Aufgaben, die sich gut in einzelne Jobs aufteilen und anschließend (teilweise) parallel abarbeiten lassen.
Von dieser Art Tuning haben Anwendungen, die sequenziell arbeiten, allerdings gar nichts – und Datenbanken fallen in diese zweite Kategorie. Denn Datenbankzugriffe, ganz gleich ob lesend oder schreibend, haben in der Regel das Ziel, einen einzelnen Wert oder die Werte einer einzelnen Zeile aus der Datenbank auszulesen oder sie dort zu aktualisieren. Dass dabei keine riesigen Datenmengen übertragen werden, liegt auf der Hand – und dass die Länge eines einzelnen Lese- oder Schreibvorgangs viel relevanter ist als die insgesamt verfügbare Bandbreite, ist offensichtlich.
Keine falschen Schlüsse
Das bedeutet freilich nicht, dass das Thema Durchsatz im Kontext von Datenbanken vollkommen egal ist. Wie bereits im Artikel eben beschrieben, wirkt sich die verfügbare Bandbreite auf die Datenbank durchaus aus, wenn es nämlich um die Anzahl der Anfragen geht, die die Datenbank zu einem bestimmten Zeitpunkt höchstens abarbeiten kann. Das genutzte Setup mit Raid 5 auf Basis mehrerer SSDs geriet hier eher unerwartet früh ins Stocken, was – wie die Nachforschungen bewiesen – aber auf mangelnde Bandbreite und nicht auf zu hohe Latenz zurückzuführen ist.
Gerade beim Storage-Tuning für Datenbanken gilt also, dass sowohl der verfügbare Durchsatz als auch die Latenz relevante Faktoren sind. Das Problem: Wer beide Eigenschaften tunen möchte, hat es mit zwei stark unterschiedlichen Problemfeldern zu tun – während es eine eher leichte Aufgabe ist, den Durchsatz zu tunen, ist das Tuning der Latenz signifikant schwieriger. Zunächst geht es allerdings darum, die Voraussetzungen der jeweiligen Umgebung zu klären.
Datenbank direkt auf Blech
Die erste Variante entspricht den Vorgaben des Vergleichsartikels in diesem Linux-Magazin. Die Aufgabenstellung besteht also darin, eine einzelne Datenbank auf einem Server so mit Hardware auszustatten, dass sie möglichst viele Clients gleichzeitig bedienen kann und dabei niedrige Latenzen aufweist. Der im Vergleichsartikel identifizierte Engpass war der Raid-Controller, an dem die SSDs hingen: Dieser war ab einer bestimmten Anzahl gleichzeitiger Connections nicht mehr in der Lage, mehr Bandbreite zu den SSDs hin zu liefern.
Hier existieren mehrere Möglichkeiten, sich des Problems anzunehmen. Der Storage-Controller gehört mit hoher Wahrscheinlichkeit aber nicht dazu. In den vergangenen Jahren hat es auf dem Gebiet der Raid-Controller nur noch sehr marginale Fortschritte gegeben, die außerdem in engem Zusammenhang mit Veränderungen in der Peripherie der Controller standen, etwa bei der Einführung neuer PCI-Express-Busse, deren vergrößerte Bandbreite neuere Controller nutzen können.
Klar ist aber: Raid 5 bedingt einige Rechnerei auf der Controller-Seite, und selbst Raid 10 bringt, wie beschrieben, keine signifikanten Vorteile im ganz alltäglichen Betrieb – reduziert dafür allerdings die Nettokapazität ganz erheblich.
Ein radikal anderer Ansatz setzt auf komplett andere Hardware: Nicht aus Versehen verbeugt sich mancher Admin in Ehrfurcht, wen er Fusion-IO hört. Der Hardware des vormals eigenständigen und nun zu Sandisk gehörenden Herstellers eilt der Ruf voraus, die schnellsten Storage-Geräte zu erlauben, die im Markt überhaupt verfügbar sind. Und in der Tat geizt Sandisk nicht: Bei der aktuell größten IO-Memory-Karte http://1 – so heißt Fusion-IO bei Sandisk mittlerweile – verspricht der Hersteller bis zu 2,2 GByte/s lesend wie schreibend und bis zu 385000 IOPS bei einer maximalen Größe von derzeit 2,6 TByte.
Das Schmuckstück hat aber auch seinen Preis: 25000 Euro will Sandisk haben. Und setzt der Interessent voraus, dass er eigentlich zwei braucht, weil er über die Grenzen eines Servers hinweg ein redundantes Setup bauen möchte, stellt er sich mal eben den Gegenwert eines Fahrzeugs der oberen Mittelklasse in Form dieser Karten ins Rack (Abbildung 1).

Abbildung 1: Storage-Performance zum Preis eines gut ausgestatteten Autos: IO-Memory-Karten von Sandisk.
Die Sache mit der Wartbarkeit
Der Vergleichstest in diesem Linux-Magazin-Schwerpunkt stellt auf die Frage ab, welche Performance-Werte sich bei der Nutzung einer Datenbank unter Idealbedingungen maximal erreichen lassen. Administrative Aspekte lässt der Artikel zunächst außen vor: Raid innerhalb eines Servers ist zwar schön und gut, wird der Admin mit dieser Art des Setups jedoch bei einem IT-Zertifizierer vorstellig, bekäme er wegen der mangelnden Hochverfügbarkeit vermutlich eins auf den Deckel.
Auch die Provisioned IOPS bei Amazon sind da nicht das Gelbe vom Ei: Zwar hat man die Möglichkeit, bei RDS Provisioned IOPS sowie Redundanz miteinander zu kombinieren. Die 40000 IOPS garantiert Amazon dann aber nicht mehr, stattdessen ist laut diverser Messungen im Netz bei deutlich geringerem Durchsatz und deutlich weniger IOPS Schluss. Von den Performance-Werten einer einzelnen Instanz kann man im diesem Szenario jedenfalls nur träumen.
Was tut wirklich not?
Was zu einer sehr wichtigen Grundsatzfrage führt, die der Admin sich immer zuerst stellen sollte: Wie viel Performance tut wirklich not? Klar macht sich eine IO-Memory-Karte von Sandisk im Rack gut, natürlich sind IOPS-Werte im Bereich von 100000 und mehr schön. Letztlich sind das aber Luftschlösser – schon ein ordentliches HA-Setup wird prinzipbedingt die auf der Storage-Seite verfügbare Performance einschränken.
Wer sich etwa einen klassischen Replikationscluster auf Basis von DRBD mit Ethernet als dem Medium zwischen beiden Knoten baut, der handelt sich als Flaschenhals für sequenzielle Writes die maximal verfügbare Anzahl an Operationen auf der Ethernet-Ebene ein. Bei stark parallelisierten Workloads ist das okay. Dient jedoch ein klassischer Datenbank-Workload als Referenz, bleibt von der schönen schnellen Hardware gar nicht mehr so viel übrig. In einem solchen Setup wäre die Hardware aus dem Vergleichstest völlig ausreichend und obendrein signifikant billiger als die beschriebenen IO-Memory-Karten.
Der Admin sollte sich deshalb sehr genau fragen, ob er die hohen Werte für Durchsatz und IOPS wirklich braucht. Es schadet nicht, das eigene Trending-System zu konsultieren und die tatsächlich anliegende IOPS-Last genauer unter die Lupe zu nehmen. Stellt sich heraus, dass ein Webshop selbst unter Volllast nicht auf mehr als ein paar Tausend IOPS kommt, lohnt sich der Aufwand mit extrem teurer Monsterhardware nicht. Stattdessen sollte der Admin lieber vernünftige HA-Funktionalität in das Setup integrieren.
Private Clouds
Zugegeben: Bis hierhin war der Artikel ein klein wenig anachronistisch und altbacken unterwegs. Denn die Zahl der Datenbanken, die eigenes Blech und eine erwähnenswerte Hardware-Ausstattung haben, sinkt seit Jahren kontinuierlich. Der direkte Vergleich einer Amazon-RDS-Instanz mit einer lokalen Kiste hinkt in diesem Sinne denn auch ein bisschen: Wer seine Daten nicht auf AWS ablegen möchte, wird diese Taktik nicht nur bei Datenbanken verfolgen und sich eher mit dem Aufbau einer privaten Cloud befassen. Die kann dann nicht nur DBaaS, sondern auch IaaS und andere Dinge, die sich in einem solchen Setup als sehr praktisch erweisen können.
Baut der Admin sich allerdings eine eigene Wolke und plant seine Datenbanken als virtuelle Instanzen in dieser Wolke zu betreiben, ändern sich die Spielregeln im Hinblick auf die erreichbare Performance merklich – zumindest dann, wenn dem Admin etwas an der Wartbarkeit seiner Umgebung liegt.
Das Linux-Magazin ist auf dieses Thema bereits etliche Male eingegangen: Cloud heißt ja am Ende nichts anderes als “Jeder Workload zu jeder Zeit auf jedem System”. Damit das klappt, verbieten sich bestimmte Ansätze von vornherein. Ein solcher Ansatz ist lokaler Speicher.
Liegen die Daten einer virtuellen Maschine, die eine Datenbank beheimatet, nur auf einem Host der Plattform vor, ist das ein klassischer Single Point of Failure – und aus Sicht des Admin obendrein ein Wartungs-Alptraum. Denn die meisten Vorteile einer Cloud entfallen: Schießt Intel etwa mal wieder einen kapitalen Sicherheitsbock und es stehen Reboots der Server an, lässt sich die Datenbank-Instanz dann nicht problemlos zu einem anderen Ort hin migrieren. Stattdessen beginnt der übliche Limbo mit Wartungsfenster und Nachteinsätzen, die im Cloudkontext eigentlich keine Daseinsberechtigung mehr haben.
Zentral, verteilt – und langsam
Weil Clouds aus den genannten Gründen auf lokalen Speicher eigentlich komplett verzichten sollten, haben sich hier neue Ansätze herausgebildet. Einer davon ist verteilter Speicher, der durch eine zentrale Instanz portioniert und den einzelnen virtuellen Instanzen zugeschustert wird. Die bekannteste Implementierung dieses Prinzips ist zweifellos Ceph: Der Objektspeicher dient vielen großen Cloudumgebungen als Storage-Rückgrat, und die großen Disitributoren wie Suse und Red Hat propagieren ihn entsprechend offensiv.
Doch hat die Sache einen kleinen Schönheitsfehler: IOPS-Werte in der Dimension lokaler Hardware sind mit Ceph völlig illusorisch. Mehr noch: Wer auf hohe IOPS-Zahlen angewiesen ist, bekommt mit Ceph so ziemlich das Schlimmste, was aus Anwendersicht passieren kann. Zunächst repliziert Ceph im normalen Betriebsmodus nämlich synchron. Eine schreibende Anwendung erhält das Okay für den erfolgreichen Schreibvorgang also erst, wenn die Information innerhalb des Clusters so oft repliziert ist, wie es die Replikationsrichtlinie vorgibt.
Weil Ceph im Hintergrund jedoch ausschließlich auf Ethernet für die Replikation zwischen den Knoten setzt, bekommt der Client an dieser Stelle zumindest die doppelte Ethernet-Latenz als Latenz für seinen Schreibzugriff ab – letztlich auch, weil in den vergangenen Jahren praktisch alle Ethernet-Optimierungen vorrangig auf höhere Bandbreiten abzielten, nicht jedoch auf geringere Latenz. Ethernet hat quasi eine inhärente Latenz, die sich seit Jahren kaum geändert hat.
Allein dadurch ist im Ceph-Kontext nicht von IOPS-Werten im fünstelligen Bereich die Rede, sondern eher im niedrigen dreistelligen Bereich. Die verfügbare Bandbreite ist bei Ceph hingegen kein Problem: Weil das Funktionsprinzip eingehende Daten auf alle im Cluster verfügbaren Speichergeräte verteilt, steht deren Bandbreite gebündelt zur Verfügung.
SSDs statt Platten
Freilich gibt es gewisse Stellschrauben, an denen der Admin drehen kann, um mehr Performance aus einem Ceph-Cluster zu quetschen. Der erste Ansatzpunkt sind die Speichergeräte selbst: Wer rotierenden Rost statt SSDs nutzt, wird keine befriedigenden IOPS-Werte erreichen, gerade nicht bei Lesevorgängen – und die meisten Datenbank-Workloads sind stark leselastig. Es empfiehlt sich also, in Ceph auch SSDs zu nutzen – zumindest im kleinen Maßstab: Die in Ceph vorhandene Pooling-Funktionalität bietet auch die Möglichkeit, teuren SSD-Storage anders zu provisionieren und zu verrechnen als billigen Storage auf Festplatten (Abbildung 2). Setzt man statt auf HDDs zumindest teilweise auf SSDs, hilft das in Sachen IOPS merklich.
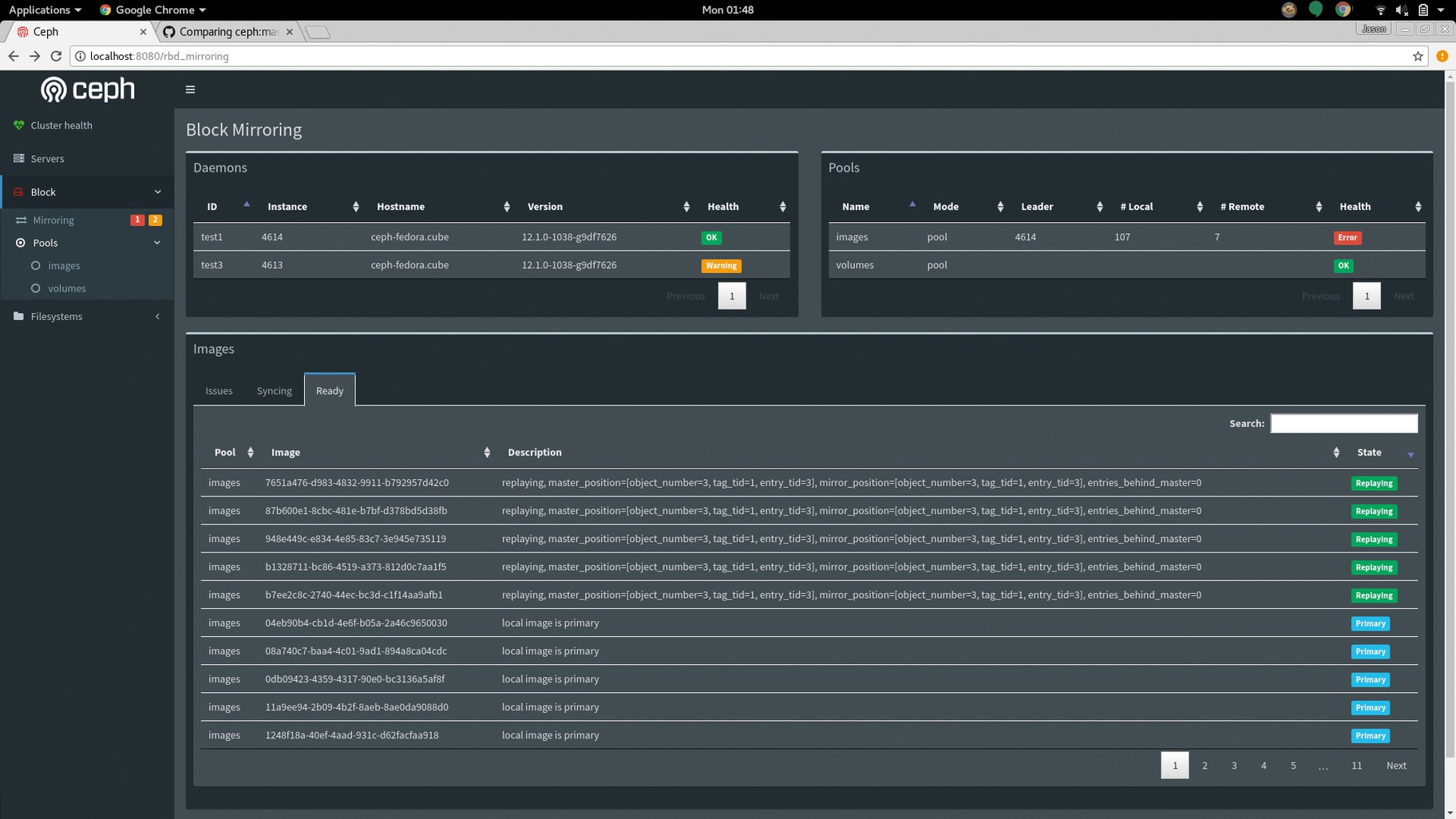
Abbildung 2: In einem Ceph-Cluster lassen sich Pools aus schnellen SSDs bauen, die der Betreiber auch separat verrechnen kann.
Crush crasht die Party
Wunder sind von einem Ceph-Cluster aber selbst dann nicht zu erwarten, wenn dieser ausschließlich SSDs nutzt. Denn selbst die IOPS-Werte, die Ethernet zulässt, sind mit Ceph kaum zu erreichen – was an Crush liegt, also jenem Algorithmus, der in Ceph die Zielknoten für Daten errechnet.
Eigentlich ist Crush genial: Der Algorithmus gilt als pseudo-zufälliger Hashalgorithmus der zuverlässigsten Sorte. Pseudo-zufällig deshalb, weil die Antwort auf die Frage “Welcher Knoten erhält diese eingehenden Bits?” zwar tatsächlich zufällig ist, aber reproduzierbar identisch ausfällt, solange sich das Layout des Clusters nicht ändert. Crush kommt in Ceph sowohl beim Client als auch zwischen den Storage-Knoten zum Einsatz, wenn Replikation passiert.
Das Problem: Crush ist ausgesprochen Latenz-lastig und führt oft zu IOPS-Werten, die selbst niedrigsten Ansprüchen nicht mehr genügen. Und leider lässt sich dieses Problem praktisch auch nicht umgehen, denn die Tuning-Möglichkeiten für Crush sind eng begrenzt. Wer Datenbanken also in einer Cloud betreiben will, deren Storage auf Ceph basiert, wird dabei aller Voraussicht nach nicht glücklich werden. Denn während Ceph für die kleine Datenbank zwischendurch sicher ausreicht, geht ihm bei großen Setups insbesondere dann die Luft aus, wenn es zu vielen sequenziellen Lese- oder Schreibvorgängen kommt.
Komplizierter Workaround
Spätestens an dieser Stelle dürfte dem Admin schmerzlich klar werden, wie praktisch die bei Amazon verfügbare “IOPS per Mausklick”-Option ist: Will er ein Cloud-kompatibles, hochverfügbares Datenbank-Setup mit hohem Durchsatz und hohen IOPS-Werten bauen, ist das mit den Bordmitteln der meisten Umgebungen wie etwa Open Stack kaum möglich. Stattdessen heißt es, selbst Hand anzulegen und in der Cloud ein Replikationssetup so nachzubauen, dass es der eingangs beschriebenen Variante auf echtem Blech zumindest ähnelt.
Dazu erweitert der Admin seine Cloud zunächst um Server mit schnellem, aber vor allem lokalem Speicher. Seine Cloudumgebung richtet er so ein, dass er VMs danach spezifisch auf eben jenen Systemen starten kann, etwa durch den Einsatz von Zonen oder Zellen in Open Stack. Welche Hardware er zum Einsatz bringt, ist letztlich der eigenen Fantasie und dem eigenen Geldbeutel überlassen: Sogar die eingangs erwähnten IO-Memory-Karten sind denkbar, wenn auch im Kontext mit der folgenden Replikation vermutlich übertrieben.
Im nächsten Schritt gilt es also, in der Cloud eine Replikation einzurichten, um die erwähnten Probleme bei der Wartung des Setups zu umgehen. Dafür startet der Admin im nächsten Schritt zwei VMs auf jeweils anderen Servern mit schnellem, lokalem Storage. Danach richtet er die Replikation zwischen den beiden VMs mittels eines Werkzeugs wie DRBD (Abbildung 3) ein, sodass der gesamte Datensatz des schnellen Volume zum jeweils anderen Knoten des Clusters repliziert wird. Danach erfolgt das Setup der Applikation, im Beispiel etwa eine Datenbank. Und schließlich sollte ein Clustermanager wie Pacemaker nicht fehlen, der das DRBD steuert und im Falle eines Falles auch den Betrieb der Datenbank sicherstellt.
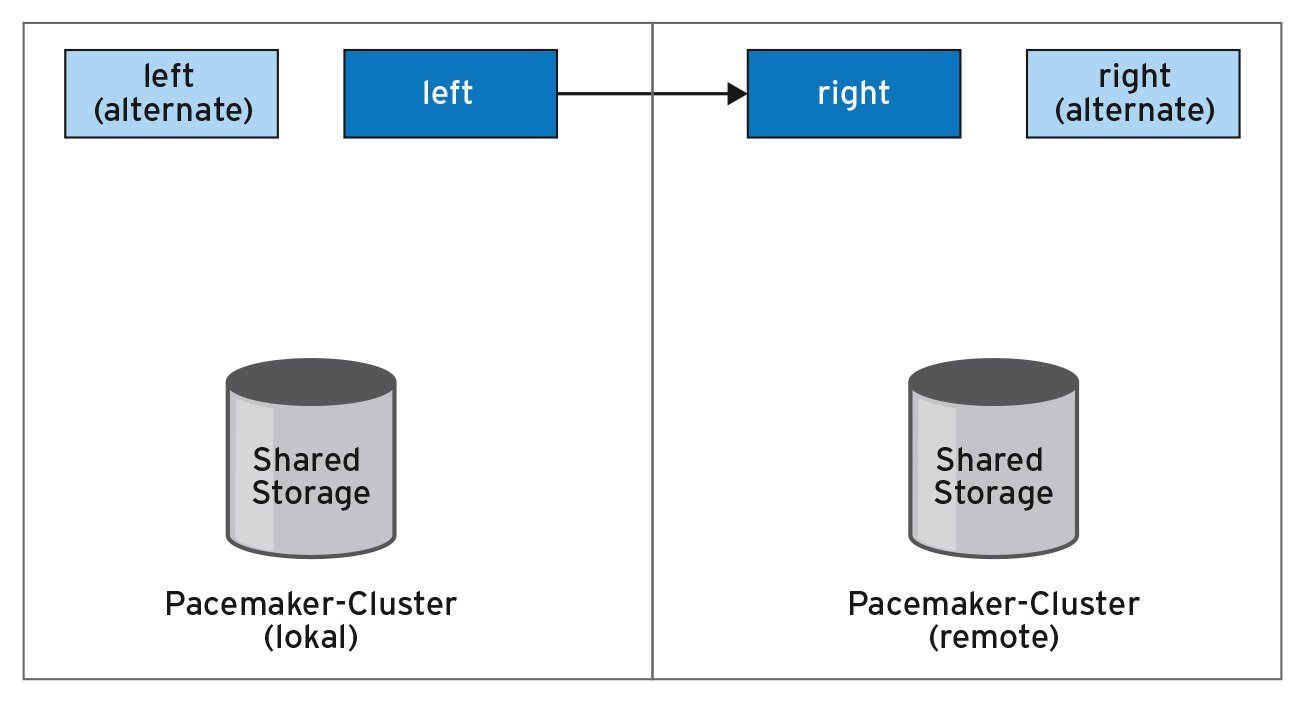
Abbildung 3: DRBD lässt sich innerhalb von VMs in Clouds verwenden, um lokalen Speicher ohne große Performance-Einbußen hochverfügbar zu machen.
Der eine oder andere Admin wird an dieser Stelle völlig zu Recht fragen, ob diese Art des Setups nicht eher ein konventionelles HA-Setup ist, das in eine Cloudumgebung gezwängt wird? Ja, das ist so, aber anders sind hohe IOPS-Werte besonders für sequenzielle Operationen innerhalb einer Cloud nicht zu erreichen. Die Mittel und Wege, die Amazon bei Provisioned IOPS für RDS in Multi-RZ-Setups nutzt, dürften unter der Haube kaum anders funktionieren, auch wenn der Hersteller zu Details der konkreten Implementierung schweigt.
Immerhin: Das vorgestellte Setup lässt sich zumindest so konstruieren, dass der Cloudadmin seinen (firmeninternen) Kunden die HA-Setups mit hohen IOPS- und Durchsatzraten nicht komplett selbst bauen muss. Besteht die Möglichkeit, per Webinterface VMs auf unterschiedlichen Servern mit schnellem, lokalem Speicher zu starten, lässt sich der Rest teilweise automatisieren, etwa in Form entsprechender Cloudimages.
Alternativ wäre auch denkbar, seinen Nutzern eine entsprechende Dokumentation anzubieten. In Sachen Performance muss ein Setup wie das beschriebene sich jedenfalls vor Amazon sicher nicht verstecken – für sequenzielle wie parallele Datenbankoperationen lassen sich vergleichbare und bessere Durchsatz- und IOPS-Werte erreichen.
Viel Schein, wenig Sein
Die Praxis zeigt: An garantierte IOPS-Werte per Mausklick kommt der Admin bequem nur bei Amazon. Wer entsprechende Funktionalität im eigenen Rechenzentrum nachbauen möchte, sieht sich einem komplexen Problem gegenüber, dessen Lösung vermutlich ein paar graue Haare mehr verursacht. Geht es nur um eine Datenbank auf nacktem Blech, deren Performance nicht ausreicht, sind Werkzeuge wie IO-Memory eine gute, wenn auch keine billige Wahl. Wer auf die Wartbarkeit seines Setups Wert legt, muss vermutlich Abstriche bei der Performance in Kauf nehmen.
Wichtig ist aber auch, sich von den Amazon-Versprechungen nicht allzu sehr ins Bockshorn jagen zu lassen. Denn was in den Werbeprospekten des Anbieters fluffig und bequem aussieht, entpuppt sich bei genauerem Hinsehen als Kiste mit vielen Wenn und Aber. Bucht man für seine Datenbank etwa Redundanz in Form der Multi-RZ-Option hinzu, reduziert das die Zahl der verfügbaren IOPS beträchtlich. Die Wahl zwischen “unwartbares, schnelles Setup” und “langsames, aber hochverfügbares Setup” ist eigentlich auch keine, denn im Falle eines Falles wird der Admin mit hoher Wahrscheinlichkeit der Stabilität den Vorrang geben müssen.
Bevor der Admin viel Geld in Hardware steckt, sollte er deshalb unbedingt den eigenen Bedarf checken und die Ziele für die Performance festlegen. Wer lediglich ein paar Hundert Requests pro Sekunde verarbeiten muss, braucht dafür vermutlich keine Hardware aus dem High-End-Segment (Abbildung 4).
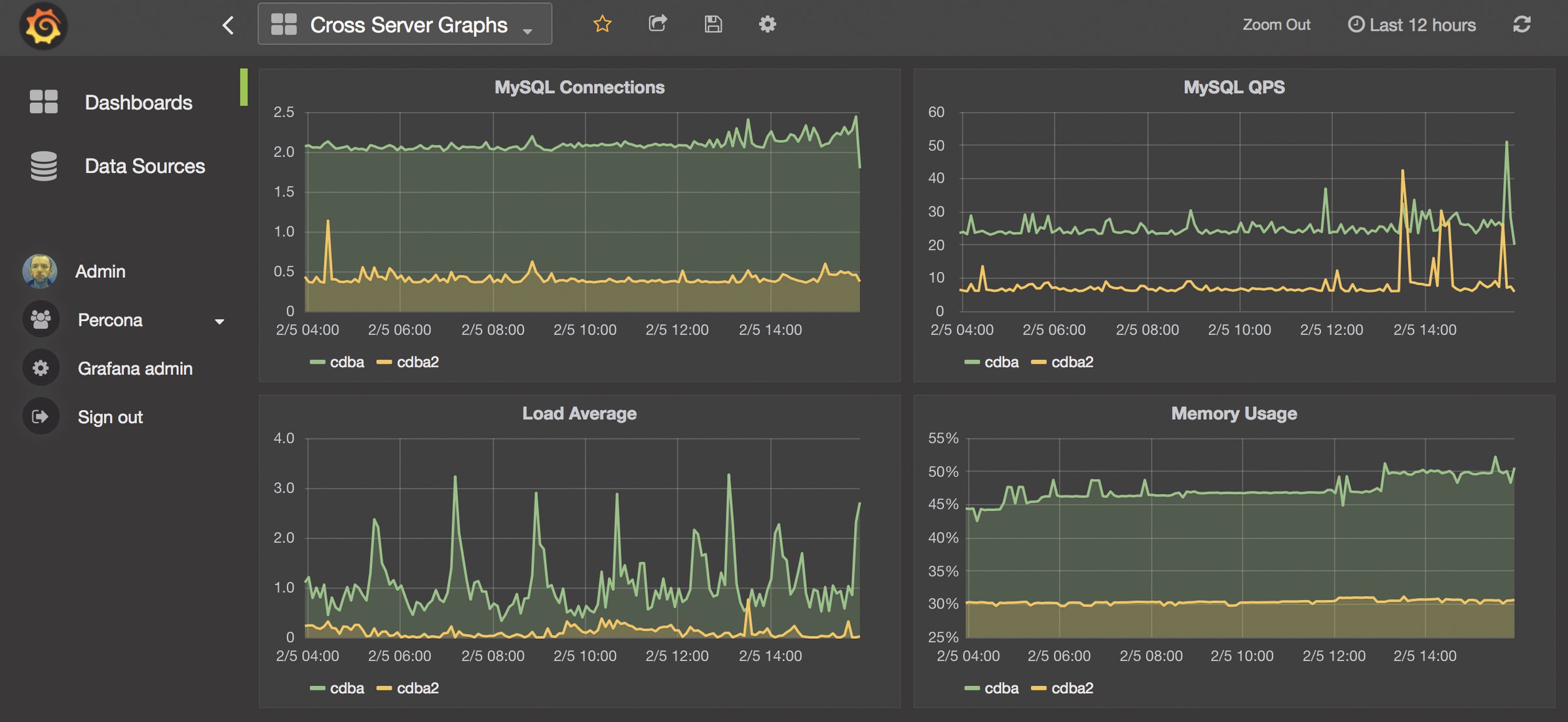
Abbildung 4: Das eigene Trending-System verschafft dem Admin einen Überblick über die regelmäßig anliegende Last.
Liegt zwischen dem eigenen Storage und den Daten eine Cloud als Abstraktionsschicht, wird die Sache noch komplizierter. Verteilte Storage-Lösungen wie Ceph, die im Rahmen solcher Setups häufig zum Einsatz kommen, sind für hochperformante Datenbanksetups nicht zu gebrauchen. Hier wird stattdessen eine Bastelstunde fällig, und VMs mit lokalem Speicher, der repliziert wird, sind die beste Wette des Admin – wenn auch nicht komfortabel einzurichten.
Ein Auge auf die Datenbank
Zum Abschluss ein Rat, den der Autor in seiner Consulting-Karriere Kunden immer wieder gegeben hat und damit meist mehr erreichte als mit Hardware möglich gewesen wäre. Regelmäßig kommt es vor, dass die Performance der Datenbank augenscheinlich zu gering ist – und in der Mehrzahl der Fälle reagieren die Betreiber solcher Systeme durch Skalieren in die Höhe, vulgo: Neue Server mit mehr Rumms. Regelmäßig stammen aber das Design der Datenbank sowie der Code, der sie ausliest oder mit Daten füttert, aus grauer Vorzeit. Oft genug ist er obendrein ineffizient und komplex, sodass Datenbankabfragen viel länger dauern, als sie eigentlich müssten.
Wer zu dem Eindruck gelangt, dass selbst mit Tausenden IOPS und sehr hoher Bandbreite seiner Datenbank deren Performance nicht ausreicht, sollte also im ersten Schritt gar nicht unbedingt nach neuer Hardware Ausschau halten, sondern eher nach einem Consultant, der das eigene Datenbankschema prüft und auf die systematische Jagd nach langsamen Queries geht, um deren Laufzeit zu optimieren (Abbildung 5). In nicht wenigen Fällen war der durch Datenbankoptimierungen erreichte Effekt viel größer als jedes Hardware-Upgrade es zu leisten vermocht hätte.
Abbildung 5: Ist die Datenbank zu langsam, muss der Admin das Problem nicht unbedingt direkt mit neuer Hardware bewerfen – Optimierungen der Datenbank können echte Wunder bewirken.
Infos
Der Autor

In seiner Freizeit Debian-Entwickler arbeitet Martin Gerhard Loschwitz beruflich als Telekom Public Cloud Architect bei T-Systems und beschäftigt sich beruflich vorrangig mit Themen wie Open Stack, Ceph und Kubernetes.





