
©visivasnc , 123RF
Lokal – beziehungsweise neuhochdeutsch: on premise – oder in der Cloud: Wo betreibt man am besten seine Datenbank? Das Linux-Magazin hat beide Varianten in einer vergleichbaren Ausgestaltung probiert und dabei jede Menge spannende Erfahrungen gesammelt.
Sowohl für den Server im eigenen Rechenzentrum wie für die Cloud fallen einem Vor- und Nachteile ein. Bei der On-premise-Variante behält der Anwender die Zügel in der Hand und auch die absolute Hoheit über seine Daten. Er kann jede technisch mögliche Konfiguration wählen und teilt Rechenleistung, Storageperformance und Netzwerkbandbreite mit niemanden. Über das Maß an Ausfallsicherheit oder Security entscheidet er in allen Details selbst. Und schaut er nur auf die Hardware-Investitionen, sind die laufenden Kosten deutlich geringer als bei einem Cloud-Monatsabo.
Dafür muss der Anwender einer lokalen Installation auch jedes Detail selbst verantworten und managen können. Das setzt eine Infrastruktur und gut ausgebildetes Personal voraus, was großen Einfluss auf eine realistische Kostenrechnung hat. Der Cloudanwender auf der anderen Seite muss sich um viele Fragen des täglichen Betriebs – Updates, Backups, Ausfälle, die nötige Redundanz – nicht selbst kümmern und kann die Ressourcen zudem leichter dem Bedarf anpassen, indem er sie (auch zeitweilig) aufstockt oder verringert und nur die tatsächlich beanspruchten Betriebsmittel bezahlt. Dafür gibt er seine Daten aus der Hand und schränkt seine Konfigurationsmöglichkeiten ein. Er begibt sich in eine Abhängigkeit vom Cloudprovider, aus der er sich womöglich nicht wieder so einfach befreien kann.
Aber wie schwer wiegen in der Praxis Performance oder Bedienkomfort, Skalierbarkeit oder Sicherheit? Um darauf eine Antwort zu finden, haben die Tester des Linux-Magazins beides ausprobiert: Zum einen eine PostgreSQL-Datenbank auf einem starken physischen Server im Rechnerraum der Redaktion, zum anderen eine gleichartige Datenbank “as a Service” in der Amazon-Cloud.
Beide Installationen unterzogen sie einem Benchmark, bei beiden konnten sie die Handhabbarkeit, die Einstellmöglichkeiten und die Kosten studieren. Los ging es mit der lokalen Installation.
Elephant Shed
Die PostgreSQL-Datenbank betrieben die Tester nicht pur und solo, sondern unter einer von der Firma Credativ entwickelten Open-Source-Managementumgebung namens Elephant Shed [1]. Dadurch ist das Handling eher mit einer Cloudanwendung vergleichbar. Das frei und kostenlos verfügbare Web-GUI – kostenpflichtig sind mögliche Integrations- und Supportleistungen durch den Hersteller – vereint eine ganze Reihe von Open-Source-Komponenten für die Datenbank-Verwaltung und -Überwachung: Die Administration unterstützt Pgadmin 4 [2], die Loganalyse Pgbadger [3].
Das Backup übernimmt Pgbackrest [4], das Monitoring realisiert Prometheus [5] und für die Visualisierung ist Grafana [6] im Einsatz. Die Linux-Server-Administration bewerkstelligt der Admin schließlich mit Cockpit [7] und Shell-in-a-Box [8]. Das Ergebnis ist eine sehr komfortable und einfach bedienbare zentrale Stelle, an der sich so gut wie alles erledigen lässt, was ein DBA zu erledigen hat.
Serverleistung
Der für die Tests verwendete Server (siehe Kasten “Der Server”) steckte die Belastungen des Benchmarks (siehe Kasten “Der Benchmark”) lange ohne Murren weg. Kleinere Benutzerzahlen quittierte er mit einem müden Lächeln. Bei 50 Benutzern erreichte er erstmals in einem Durchlauf eine Million Transaktionen pro Minute, musste seine CPU-Reserven aber erst zu ungefähr einem Viertel einsetzen (Load Average um 20), der Hauptspeicher blieb gut zur Hälfte noch unbenutzt (Abbildung 2).
Der Server
Die Testhardware, die der Hersteller freundlicherweise dem Linux-Magazin lieh, war ein Dell EMC Poweredge R740 [9], eine recht universelle Maschine im 19-Zoll-Format mit zwei Höheneinheiten, die für viele Arten digitaler Workloads taugt (Abbildung 1). Ihre beiden CPU-Sockel waren im vorliegenden Fall bestückt mit zwei Intel-CPUs, Typ Xeon Gold 6148, die je 20 Rechenkerne vorweisen können. Da sie auch das Hardware-gestützte Multithreading beherrschen (Hyperthreading), erscheinen sie dem Betriebssystem als insgesamt 80 logische CPUs.

Abbildung 1: Der Dell-EMC-Server Poweredge R740, mit dem das Linux-Magazin getestet hat.
Der Hauptspeicher belief sich auf 768 GByte. In die 24 ECC-DDR4-DIMM-Slots des Servers würden maximal 3 TByte RAM passen. In den von der Frontseite aus erreichbaren Diskslots (maximal 16-mal 2,5 Zoll oder 8-mal 3,5 Zoll) steckten sechs SSDs, von denen die Tester des Magazins mit Hilfe des eingebauten Raid-Controllers Dell H740P [10] zwei zu einem Spiegelpaar für das Betriebssystem konfigurierten und die restlichen vier zu einer 2,6 TByte großen Raid-5-Gruppe für die Datenbank zusammenbanden.
Apropos Raid-Controller: Das Modell ist für etliche Linux-Varianten zu neu. So braucht es bei SLES 12 mindestens das Service Pack 3, mit Debian 9 (alias Stretch) funktioniert es gar nicht. Die Tester wichen deshalb auf die Unstable-Version Debian 10 (Buster) aus, die den Controller erkennt.
Der Server verfügt über je zwei USB-2.0- und 3.0-Ports, was auch wichtig ist, weil er kein eingebautes optisches Laufwerk hat, für die Betriebssysteminstallation also ein externes DVD-Drive braucht. In Sachen Netzwerk bietet der Rechner diverse Anschlussoptionen: 4-mal 1 oder 10 GBit/s (oder eine Mischung aus beiden) oder 2-mal 25 GBit/s. Als Betriebssysteme unterstützt er offiziell neben Windows, VMware ESXi und Citrix Xenserver die Linux-Distributionen Ubuntu LTS, RHEL oder Suse SLES, wobei jeweils die neuesten Ausgaben empfehlenswert sind. Der Server würde in der getesteten Konfiguration über 40000 Euro kosten.
Der Benchmark
Als Benchmarktool haben die Tester das weitverbreitete Open-Source-Werkzeug Hammer DB [11] benutzt, das auch namhafte Hard- und Softwarehersteller wie Oracle, IBM, Intel, Dell EMC, HPE oder Lenovo verwenden. Es implementiert einen OLTP-Benchmark in C (Datenbankoperationen) und TCL (GUI), der das Bestellsystem eines Großhändlers simuliert, bei dem eine wählbare Anzahl virtueller Nutzer bestimmte Datenbanktransaktionen in einer wählbaren Anzahl von Lagerhäusern (Warehouses) auslöst. Dazu gehören die Eingabe von Bestellungen, das Verbuchen der Auslieferung, die Aufzeichnung von Bezahlvorgängen, die Überprüfung des Warenbestands und des Order-Status. Alle diese Transaktionen sind in Stored Procedures kodiert, sie laufen in verschiedenen Threads parallel zueinander ab. Gemessen werden die Transaktionen pro Minute (TPM) und – als Wert für den Vergleich verschiedener Datenbanksysteme untereinander – die New Order Transactions per Minute (NOTPM).
Hammer DB ahmt dabei den Mechanismus des Standard-Benchmarks der Datenbankindustrie für Online Transaction Processing (OLTP) namens TPC-C [12] nach. Die Messwerte sind jedoch mit Werten, die TPC-C berechnet, nicht direkt vergleichbar. Dafür ist der Hammer-DB-Benchmark Open Source und kostenlos – wogegen für eine volle Mitgliedschaft im Transaction Processing Performance Council (TPC), einer Non-Profit-Organisation, die auch den TPC-C-Benchmark betreut, 15000 Dollar Jahresgebühr anfallen.
Zudem kann jeder Ergebnisse des Hammer-DB-Benchmarks veröffentlichen – beim TPC gibt es dagegen strenge Meldevorschriften. Ein dafür nötiger so genannter Full Disclosure Report ist ein rund hundertseitiges Papier. Jede Meldung kostet außerdem auch Mitglieder noch einmal über 1000 Dollar Gebühren. Dafür weisen TPC-C-Resultate nicht nur Leistungswerte, sondern auch Preis/Performance-Werte aus.
Das Linux-Magazin nutzte für die meisten der hier veröffentlichten Messungen des physischen Servers die GUI-Version Hammer DB 2.20 im Modus Timed Test Driver Script, der im Unterschied zum Standard-Modus nicht durch eine bestimmte Anzahl Transaktionen begrenzt ist, die pro Worker zu absolvieren sind, sondern durch eine Zeitvorgabe. Die AWS-Tests liefen unter dem CLI der Version 3.0. Alle Werte wurden während einer fünfminütigen Messperiode nach einer zweiminütigen Einschwingphase ermittelt. Für jede Konfiguration aus Anzahl virtueller User und Warehouses berechneten die Tester einen Mittelwert aus drei Messungen.
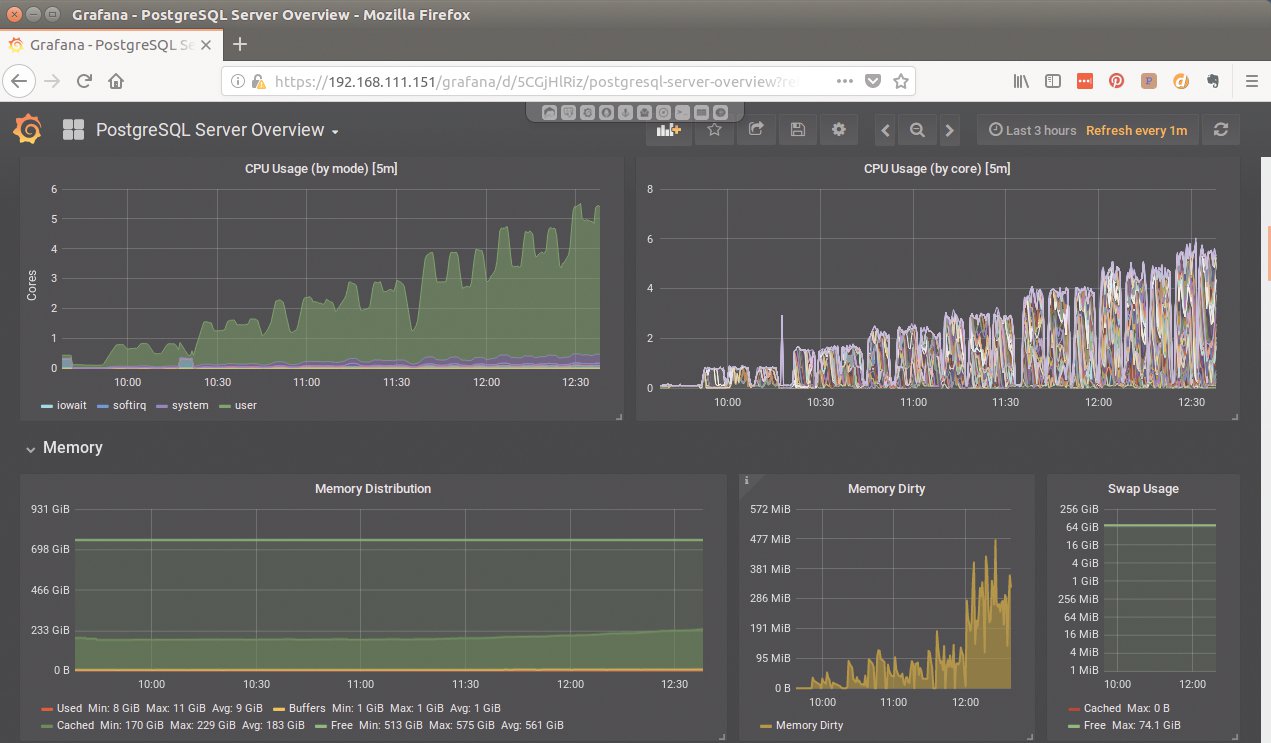
Abbildung 2: Im unteren Lastbereich steigt die CPU-Auslastung des Poweredge R740 mit den Nutzerzahlen. Allerdings ist sie hier noch meilenweit von einem möglichen Maximum entfernt. Die Kurve für den Speicherverbrauch fällt dagegen kaum.
Mit dem Monitoring-Dashboard in Elephant Shed ließ sich das gut nachvollziehen. Auf dem Massenspeicher, einer Raid-5-Gruppe aus vier SSDs, landeten dabei aber offenbar so viele Schreiboperationen, dass das von diesem Zeitpunkt an zum limitierenden Faktor wurde. Die nackte SSD kann unter optimalen Bedingungen sicher mehr I/O verkraften, das logische Laufwerk als Raid-5-Gruppe kann das nicht.
Bei dem Benchmark erzeugt jeder virtuelle Nutzer eine Datenbank-Connection. Mehr Nutzer sollten eigentlich zu mehr I/O führen. Ab etwa 50 Nutzern kam es aber wegen des ausgelasteten Massenspeichers zu keinem Anstieg des I/O-Volumens mehr, wobei CPU und Hauptspeicher jeweils noch über freie Kapazitäten verfügten (Abbildung 3).
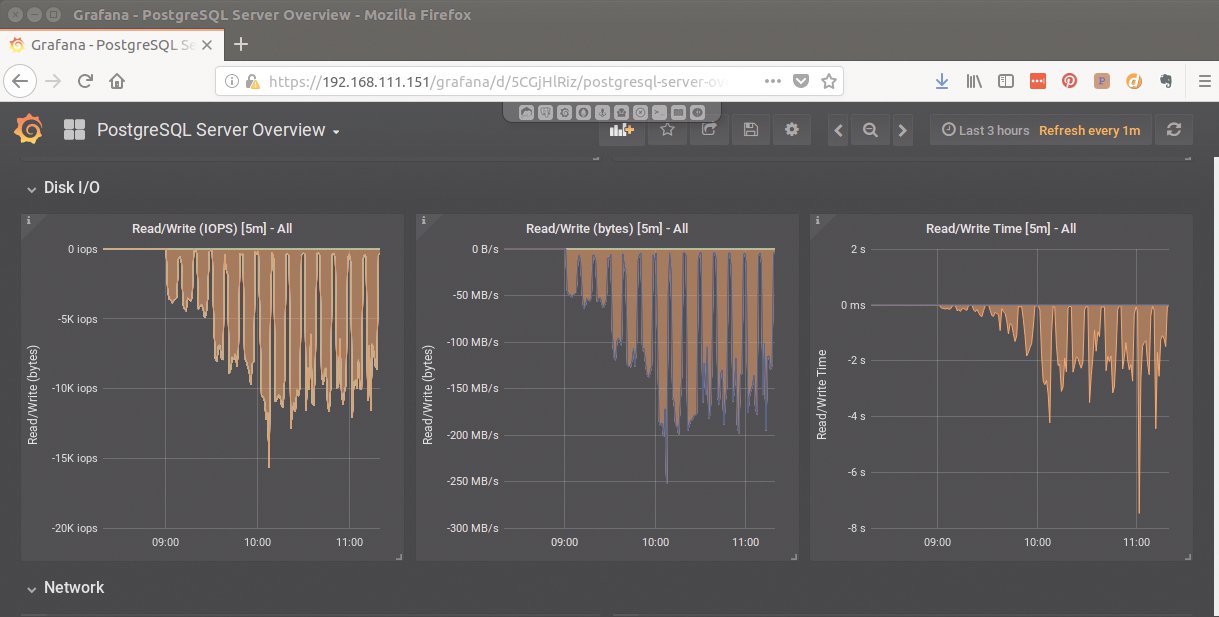
Abbildung 3: Trotz steigender Nutzerzahlen stagniert die I/O-Leistung und damit auch die Anzahl möglicher Datenbanktransaktionen. Der Massenspeicher stößt hier an eine Grenze.
Dass die SSDs bei diesem schreibintensiven Benchmark zum Engpass mutierten, wurde noch deutlicher, als die Tester schrittweise die Anzahl der CPUs verringerten. Das geht am einfachsten, indem der Admin unter »/sys/devices/system/cpu/cpunr/online« für jede CPU eine Null einträgt, die offline sein soll. Am besten schreibt er sich dafür ein einfaches Skript wie in Listing 1.
Listing 1
CPUs abschalten
01 echo 0 > /sys/devices/system/cpu/cpu79/online 02 echo 0 > /sys/devices/system/cpu/cpu78/online 03 echo 0 > /sys/devices/system/cpu/cpu77/online 04 echo 0 > /sys/devices/system/cpu/cpu76/online 05 echo 0 > /sys/devices/system/cpu/cpu75/online 06 echo 0 > /sys/devices/system/cpu/cpu74/online 07 echo 0 > /sys/devices/system/cpu/cpu73/online 08 echo 0 > /sys/devices/system/cpu/cpu72/online 09 echo 0 > /sys/devices/system/cpu/cpu71/online 10 echo 0 > /sys/devices/system/cpu/cpu70/online 11 12 echo 0 > /sys/devices/system/cpu/cpu69/online 13 echo 0 > /sys/devices/system/cpu/cpu68/online 14 echo 0 > /sys/devices/system/cpu/cpu67/online 15 [...]
Zur Kontrolle schaut er entweder in die Dateien »/sys/devices/system/cpu/online« und »/sys/devices/system/cpu/offline«, die ein- beziehungsweise ausgeschalteten CPUs aufführen, oder nutzt das Kommando »lscpu«, das dieselbe Information liefert (Listing 2). Eine »1« statt der »0« in der erwähnten Datei schaltet die CPU wieder ein. Ein Reboot bewirkt am Ende das Gleiche. Soll die Abschaltung dauerhaft gelten, sind Boot-Parameter dafür besser geeignet.
Listing 2
lscpu
01 root@rocket:/sys/devices/system/cpu# lscpu 02 Architecture: x86_64 03 CPU op-mode(s): 32-bit, 64-bit 04 Byte Order: Little Endian 05 CPU(s): 80 06 On-line CPU(s) list: 0-19 07 Off-line CPU(s) list: 20-79 08 [...]
Ein Blick auf das Chart in Abbildung 4 zeigt: Für Nutzerzahlen unter zehn ist die Anzahl aktiver CPUs nahezu irrelevant, was dabei an Rechenpower nötig ist, bewältigen auch zehn CPUs noch gut. Im Bereich zwischen 40 und 60 Usern, wo sich die Leistungsunterschiede am besten ausdifferenzieren, ist der Unterschied zwischen 80 CPUs und der Hälfte davon nicht groß.
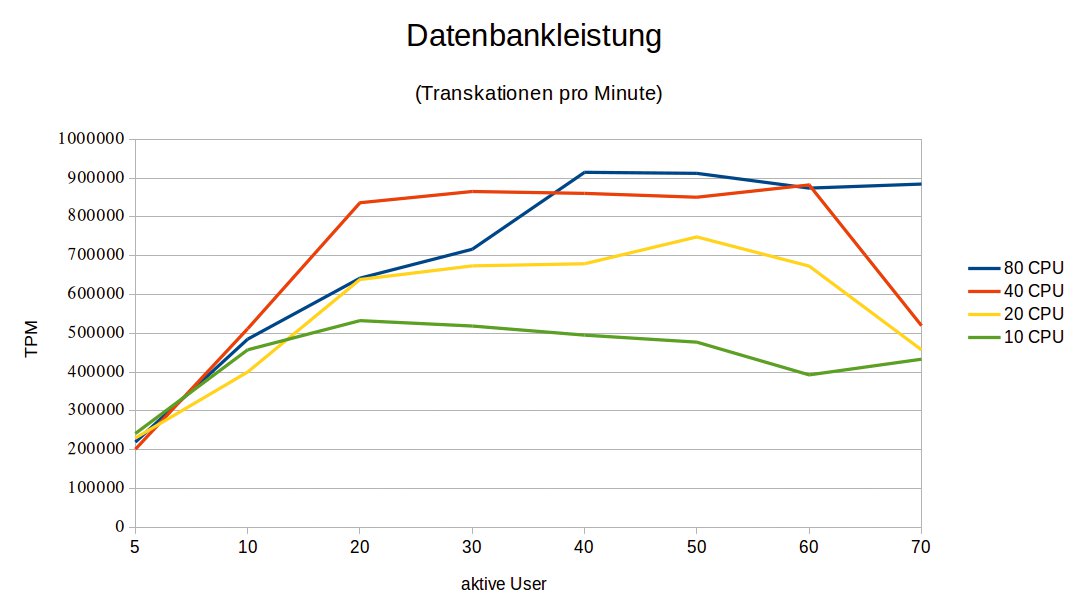
Abbildung 4: Die Benchmarkergebnisse bei unterschiedlich vielen aktiven CPUs auf einen Blick.
Das unterstreicht ein weiteres Mal, dass die Ressource CPU in diesem Fall nicht der Engpass gewesen ist, der die Gesamtleistung beschnitten hat. Das ändert sich erst bei noch höheren Userzahlen. Die beeindrucken zwar den voll bestückten Server mit 80 CPUs auch noch nicht, machen sich bei den kleineren Konfigurationen aber schon bemerkbar.
Nachdem sich herausgestellt hat, dass der Admin den Hebel beim I/O ansetzen müsste, wenn er noch mehr Leistung bräuchte, drängt sich die Überlegung auf, ob die Raid-5-Gruppe, die die Datenbank nutzt, wirklich die optimale Konfiguration für diese Anwendung ist. Ein Raid-Setup, das ohne die Paritätsberechnung von Raid 5 auskommt, also Raid 0 (Striping) oder Raid 1 (Mirroring) oder eine Kombination aus beiden (Raid 10), wäre unter Umständen schneller.
Allerdings sind moderne Hardwarecontroller für die hier benötigten Paritätsrechnungen optimiert, und die zusätzlichen Lese- und Schreiboperationen fangen Caches ab. Das könnte den vermeintlichen Vorteil der Raidlevel ohne Paritätsberechnung wieder relativieren.
Ein Raid 10 brächte allerdings noch andere Pluspunkte. Zum einen wäre es etwas sicherer, weil bei ihm unter günstigen Bedingungen zwei Platten ausfallen dürften (eine in jeder Spiegelhälfte) – Raid 5 verkraftet dagegen nur einen Ausfall. Zum anderen ist ein Raid 10 nach einem Ausfall viel schneller wiederhergestellt, weil lediglich die Daten einer Spiegelhälfte auf die Ersatzplatte zu kopieren wären, wogegen bei Raid 5 die Daten der ausgefallenen Platte mit Hilfe der Paritätsinformationen neu zu errechnen sind.
Diese Vorteile haben allerdings ihren Preis: Das Raid-5-Volume im Beispiel bietet Platz für 2,6 TByte, auf die Raid-10-Version passen nur noch 1,75 TByte. Man bezahlt also Ausfallsicherheit und Geschwindigkeit mit Platz.
Den Vergleich illustriert Abbildung 5. Bei geringer Belastung liegen Raid 5 und Raid 10 ziemlich genau gleichauf. Bei hoher Belastung scheint Raid 10 zunächst etwas ins Hintertreffen zu geraten, hat aber dann am letzten Punkt vor dem Abknicken der Leistungskurve doch leicht die Nase vorn. Groß ist der Unterschied nicht, man müsste sich gut überlegen, ob dieser Effekt plus etwas mehr Sicherheit und kürzere Zeit für das Recovery einen Verlust von einem Drittel der Speicherkapazität gegenüber Raid 5 wettmacht.
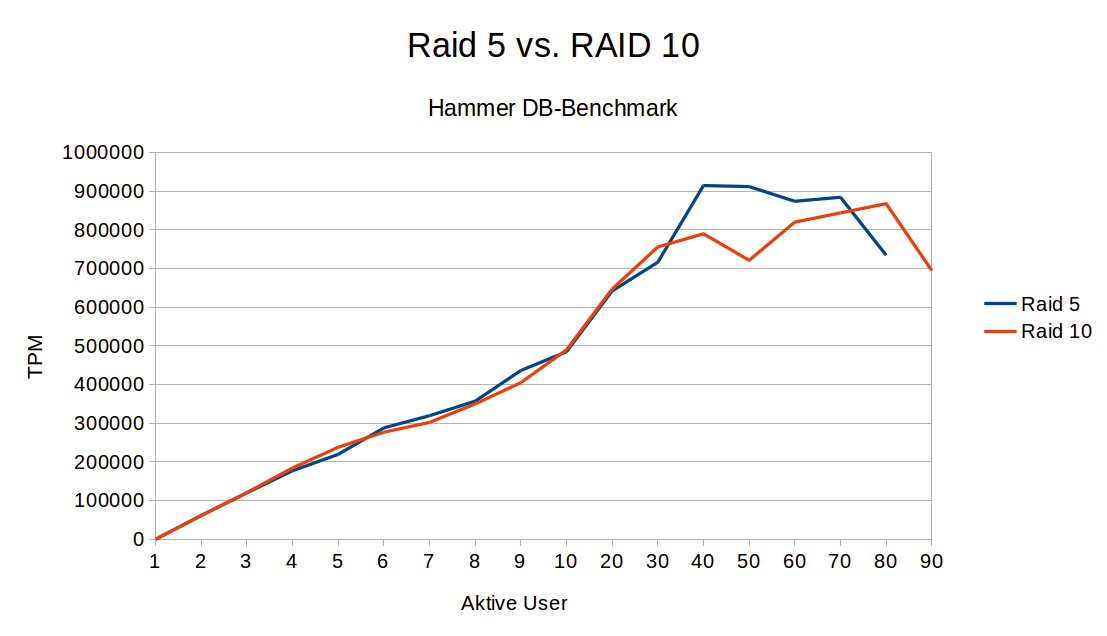
Abbildung 5: Raid 5 oder Raid 10? Groß sind die Unterschiede nicht.
Start mit Amazon RDS
Über solche Details wie die Wahl eines Raid-Levels braucht man beim Relational Database Service (RDS) in Amazons Cloud (AWS, [13]) nicht nachzudenken – der Anwender hat schlicht keinen Einfluss darauf. Nach Auswahl der zu verwendenden Datenbankengine (Aurora, Oracle, MySQL, Maria DB, PostgreSQL oder MS SQL Server) entscheidet er sich für eine produktive oder eine Testinstanz.
Danach kann er im Lauf eines einfachen, menügestützten Konfigurationsprozesses (beziehungsweise via CLI oder SDK) nur bestimmte Optionen in vorgegebener Stückelung auswählen. Dabei decken die über 20 angebotenen so genannten Instanzklassen mit verschiedenen Konfigurationen von einer virtuellen CPU und 1 GByte RAM bis zu 64 V-CPUs und 488 GByte RAM sicherlich die allermeisten Anwendungsfälle ab
Aber völlige Freiheit bei der Kombination der Parameter gibt es nicht, die Vorgaben sind standardisiert und die Auswahl ist begrenzt. Das liegt vor allem auch daran, dass der Cloudprovider seine Ressourcen einigermaßen gleichmäßig auslasten möchte und nicht daran interessiert ist, Konfigurationen anzubieten, bei denen von einer Ressource extrem viel, von anderen sehr wenig enthalten ist.
Neben der Instanzklasse, die die Anzahl virtueller CPUs und die Größe des Hauptspeichers festlegt, lässt sich noch eine ganze Reihe anderer Parameter einstellen. Darunter beispielsweise die Größe des Massenspeichers (zwischen 100 und 16384 GByte). In Bezug auf dessen Performance kann man sich eine bestimmte Menge I/O-Operationen pro Sekunde (IOPS) garantieren lassen – gegen Aufpreis versteht sich (Abbildung 6).
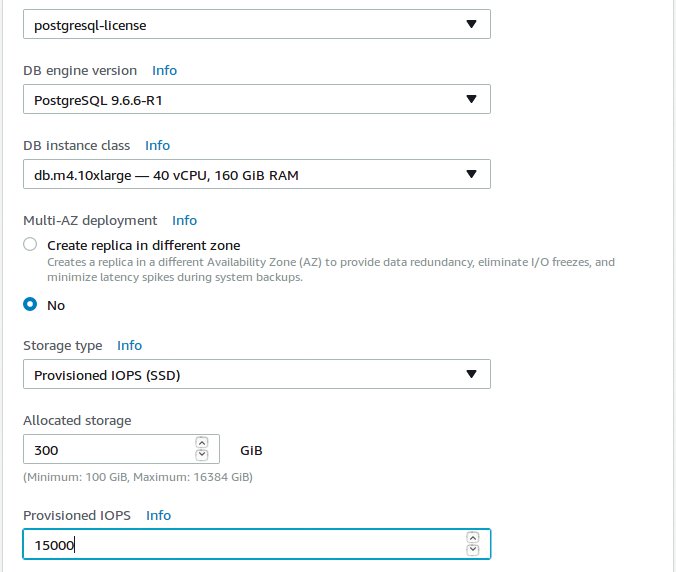
Abbildung 6: Neben der Größe des Massenspeichers kann der Anwender auch die Menge IOPS vorgeben, die dieser bewältigen soll.
Ohne diese Zusicherung darf der Kunde mit drei I/O-Operationen pro Sekunde und GByte Massenspeicher rechnen, was nicht viel ist. Hinzu kommt noch eine kleine Reserve für Burst-Workloads. Wer mehr braucht, zahlt 0,1 Dollar pro IOPS zusätzlich – auch wenn die Instanz gestoppt ist. Für mehr IOPS ist zudem auch mehr Massenspeicher zu wählen, das Minimum liegt ohne Zusicherung bei 100 GByte, bei 10000 IOPS sind es minimal 200 GByte, bei 15000 IOPS mindestens 300 GByte und so fort.
Weiter ist zu bestimmen, ob die Datenbank eine öffentliche IP-Adresse erhalten soll, um von außen zugänglich zu sein, oder ob sie nur für andere VMs in AWS, genauer in einer von Amazon so getauften Virtual Private Cloud (VPC) sichtbar ist. Ein Datenbankname, ein Hauptbenutzer und sein Passwort sind vorzugeben, und auch ein Backup-Intervall ist verpflichtend. Zusätzlich kann der Anwender jederzeit einen Snapshot der Datenbank erzeugen und später wieder einspielen.
Als weitere Option für die Ausfallsicherheit lässt sich festlegen, dass die Datenbank in einem zweiten Rechenzentrum zu hosten ist, was natürlich wiederum teurer ist. In diesem Fall wird die Datenbank repliziert, sodass sie sich am zweiten Standort mit den Daten nutzen lässt, die vor einem Ausfall des ersten vorhanden waren. Darüber hinaus ist einstellbar, ob kleinere Updates automatisch einzuspielen sind, und wenn ja, in welchem Zeitfenster. Schließlich darf sich der Anwender auch noch ein erweitertes Monitoring auswählen.
Übrigens: Auch die Konfigurationsparameter der Datenbank selbst sind einstellbar. Sie lassen sich allerdings nicht wie üblich über das Konfigurationsfile setzen, denn das ist nicht erreichbar, weil es keinen Shellzugang zum Server gibt. Stattdessen bietet AWS sie in Form einer so genannten Parameter Group in tabellarischen Strukturen an, mit denen sich die Werte ändern lassen.
Dabei ist besondere Aufmerksamkeit geboten, denn der Admin muss manche Parameter in anderen Einheiten angeben als im Konfigurationsfile. So verlangt die Parameter Group zum Beispiel für Shared Buffers eine Anzahl Puffer bestimmter Größe, wogegen der Wert im Konfigurationsfile in MByte zu konfigurieren ist. Hinweise finden sich in der Tabelle, sichtbar werden sie aber erst nach ausgiebigem Scrollen in der letzten Spalte.
RDS in der Praxis
Ist alles eingerichtet, kann es losgehen. Auf die Datenbank kann ihr Admin von außen mit den üblichen grafischen oder Kommandozeilen-Utilities zugreifen (Pgadmin, »psql«). Applikationen erreichen die Datenbank über ihre Datenbankschnittstelle. Die bei der Installation automatisch erzeugte so genannte Security Group, die Firewallregeln enthält, beschränkt jedoch den Zugriff auf die Datenbank und erlaubt ihn im Falle einer öffentlichen IP-Adresse nur von jenem Rechner aus, von dem die Instanz eingerichtet wurde. Wem das nicht reicht, der muss eben diese Regel editieren.
Weil kein Shell-Login möglich ist, lassen sich auch keine Tools für die Instrumentierung aktivieren wie etwa der System Activity Reporter (Sar). Der RDS-Service enthält aber ein voreingestelltes Dashboard fürs Monitoring, das mit dem Prometheus/Grafana-Dashboard in Elephant Shed durchaus vergleichbar ist (Abbildung 7). Einzig das nötige manuelle Refreshen per Button nervt etwas.
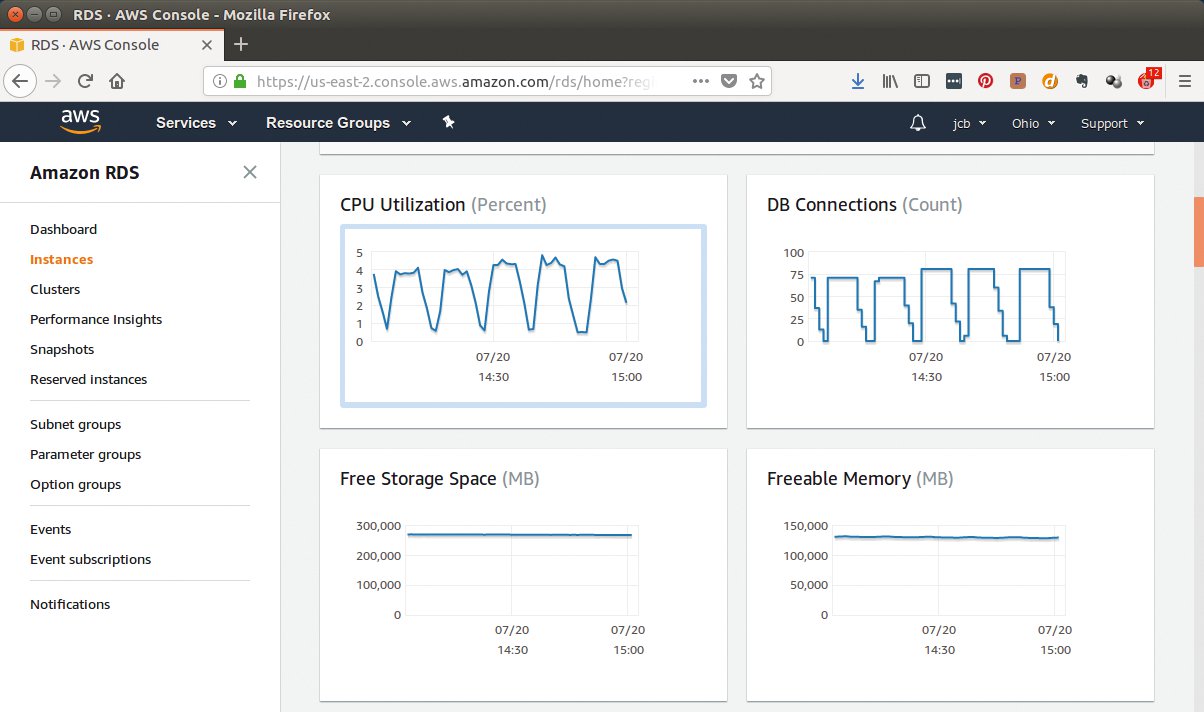
Abbildung 7: Das Monitoring-Dashboard ist mit dem von Elephant Shed vergleichbar.
Das Dashboard bietet Charts für CPU-Auslastung, Anzahl DB-Connections, freien Plattenplatz und freien RAM, Lese- und Schreib-IOPS, Lese- und Schreib-Durchsatz, Lese- und Schreib-Latenz, Swap-Nutzung, Netzwerkdurchsatz oder Transaction-Log-Erzeugung sowie ein paar andere Leistungswerte.
Schwieriger wird es, wenn der Admin die Monitoringdaten mit Daten aus der Applikation oder früher gewonnenen Messwerten korrelieren will. In diesem Fall braucht er zusätzlichen Platz auf Amazons Speicherdienst S3. Nur dorthin lassen sich die Messwerte exportieren und dann weiterverarbeiten.
Eine andere, noch weiter gehende Möglichkeit offeriert der Dienst Amazon Cloud Watch. Hier kann sich der Anwender aus einer großen Liste überwachbarer Parameter selber Charts zusammenklicken und daraus ein eigenes Dashboard bauen.
Dabei kann allerdings ein Unterschied zum zuvor beschriebenen Monitoring wichtig werden: Cloud Watch sammelt seine Messwerte vom Hypervisor für eine DB-Instanz, und Enhanced Monitoring erfasst seine Metriken durch einem Agent in der Instanz. In den Cloud-Watch-Werten mag deshalb also ein kleiner Overhead für die Arbeit des Hypervisors selbst enthalten sein.
Die Resultate
Die ersten Testergebnisse mit einem via Internet erreichbaren PostgreSQL-Server waren ernüchternd. Der 40-CPU-Server erreichte kaum das Niveau eines Laptops mit vier CPUs und einem Zwanzigstel des RAM. Der Grund ist in der extremen Latenz der Netzwerkverbindung in die USA zu suchen. Eine Datenbank mit öffentlicher IP-Adresse ist also schon aus diesem Grund keine gute Idee: Die Performance ist erbärmlich.
Stattdessen müssen sich die Konsumenten des Datenbankservice eine virtuelle Cloud mit der Datenbank teilen und sie über das interne Netzwerk ansprechen. Das hat allerdings zur Folge, dass man von vornherein das Konzept verfolgen sollte, alles oder nichts in die Amazon-Cloud zu verlagern, sofern keine ausgezeichnete Internetverbindung zur Verfügung steht. Wird die Datenbank beispielsweise von einem Webshop benutzt, müssen auch die Webserver und das CMS dorthin umziehen.
Jedenfalls konfigurierten die Tester nun in derselben virtuellen Cloud, in der sich die Datenbank befand, eine weitere virtuelle Maschine unter Ubuntu (Server Edition, 16.04), die die Datenbank über ein internes Subnetz erreichen konnte, das bis zu 10 GBit/s verkraften können soll. Auf dieser VM installierten sie den Benchmark-Client, wobei sie allerdings jetzt von der Version 2.2 zur neuesten Version 3.0 wechseln mussten, weil erst die über ein Kommandozeilen-Interface verfügt. Das GUI des Benchmark-Clients ist über die SSH-Verbindung zur VM nicht nutzbar.
Nun kann der Clouddienst zwar etwas besser mithalten, reicht aber dennoch an den physischen Server nicht heran. Der Unterschied ist deutlich: Beide Varianten erreichen die maximale Anzahl Transaktionen pro Minute bei 30 Usern, mit mehr Nutzern stagniert die Leistung oder geht leicht zurück. Während der physische Server aber bei gut der dreifachen Anzahl Transaktionen beginnt und beim Schritt von zehn auf 20 User seine Leistung noch einmal deutlich steigert, startet die RDS-Instanz auf einem viel niedrigeren Level und hat nicht mehr viel zuzusetzen.
Das Monitoring verrät auch hier, woran das liegt (Abbildung 8). Nicht an der Rechenleistung – die CPU-Auslastung pendelt unter der 30-Prozent-Marke. Nicht am Arbeitsspeicher – noch immer sind 100 von 150 GByte frei. Nicht an der Netzwerkverbindung – die Gigabit-Schnittstelle hat mit etwa 300 MBit/s aktuellem Durchsatz noch Reserven. Auch Plattenplatz gibt es noch reichlich.
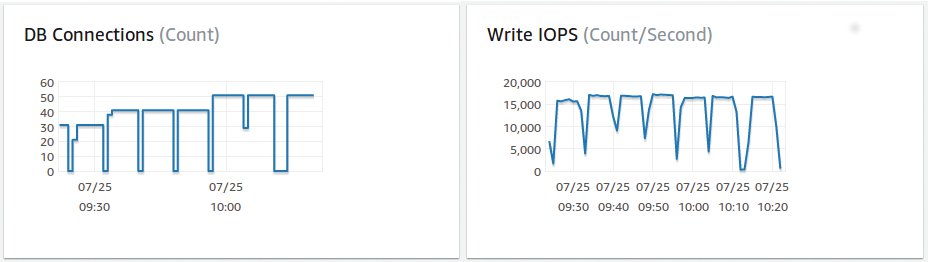
Abbildung 8: Steigende Userzahlen können zu keiner Zunahme beim I/O führen, weil das gebuchte Limit erreicht ist. IOPS lassen sich zukaufen, aber nicht unbegrenzt und nicht billig.
Aber während die Anzahl der Datenbankverbindungen mit jedem dritten Durchlauf um zehn ansteigt, was eigentlich zu mehr I/O führen müsste, hängt die Statistik der IOPS bei den gebuchten 15000 IOPS fest. Mehr wurden schließlich nicht bezahlt. Das IOPS-Limit wird bei 30 Usern erreicht, deshalb bremsen mehr User nun das System aus.
Nun kann der Anwender mit der Cloudversion etwas tun, was mit der physischen Hardware zwar nicht unmöglich, aber nicht ganz so einfach wäre: Man bucht sich einfach mehr I/O pro Sekunde, die der Storage liefern können soll. Allerdings wachsen die Bäume dafür nicht in den Himmel – für PostgreSQL lassen sich maximal 40000 IOPS reservieren, und dafür sind außerdem mindesten 800 GByte Storage zu kaufen. Mittlerweile sind SSDs auf dem Markt, die schreibend fast das Vierfache schaffen.
Die Linux-Magazin-Tester haben also die maximale Anzahl IOPS zugekauft und dann eine weitere Benchmarkrunde gedreht. Die Datenbankinstanz lässt sich jederzeit auf diese Weise aufbohren, ist aber währenddessen unter Umständen lange nicht verfügbar, weshalb die Modifikation per Default ins Wartungsfenster gelegt wird, was jedoch vielleicht erst am nächsten Wochenende fällig ist.
Der Admin kann aber eine sofortige Durchführung erzwingen, wenn er die Downtime verkraften kann. Während der zeitraubenden Änderungen – vermutlich werden die vorhandenen Daten auf einen neu erzeugten Storage kopiert – wünscht sich der DBA eine Fortschrittsanzeige, die es aber nicht gibt.
Ausgestattet mit 40000 IOPS ist die Cloudversion halbwegs konkurrenzfähig (Abbildung 9). An die Leistung der On-premise-Variante kommt sie zwar immer noch nicht annähernd heran, steigert sich aber auf ein gutes Drittel. Allerdings kostet selbst dieser kleinere Schritt richtig Geld, dazu weiter unten mehr.
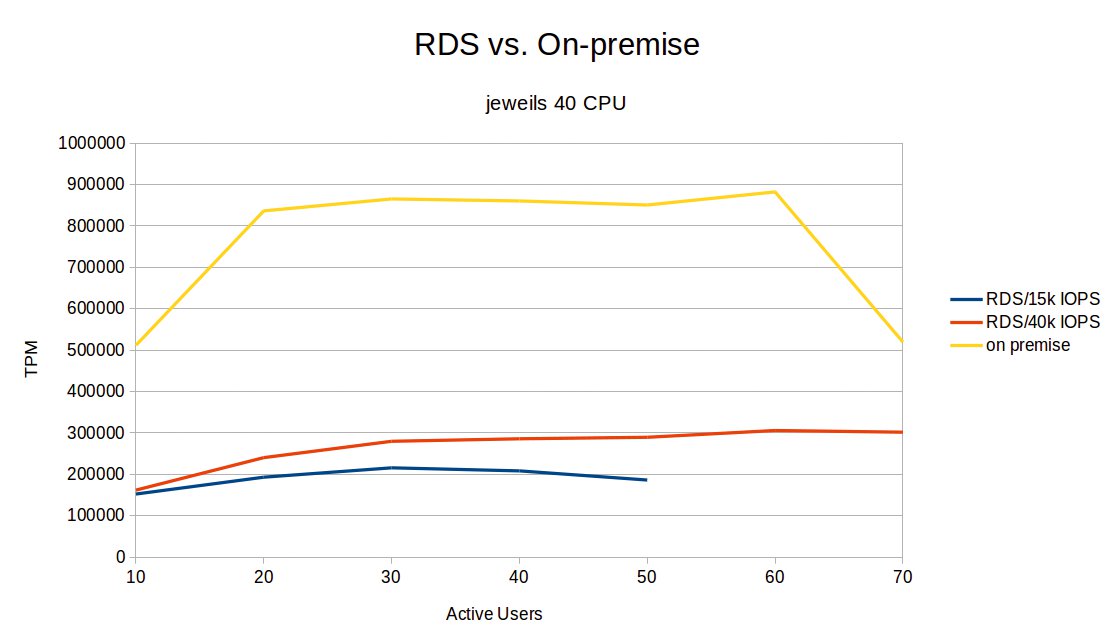
Abbildung 9: Mit der maximal möglichen Zusicherung von 40000 IOPS kommt die Cloudversion immerhin auf ein Drittel der Performance der On-premise-Variante.
Hier wirkt sich auch aus, dass nicht nur die I/O-Leistung beschränkt ist, sondern auch die virtuellen CPUs langsamer sind als ihr handfestes Pendant aus Silizium. Beim physischen Server erzeugten wesentlich weniger virtuelle User mehr Transaktionen.
Reden wir übers Geld
Bei der Entscheidung über die Datenbank in der Cloud oder im eigenen Rechenzentrum sind die Kosten ein entscheidender Faktor. Der Dell-EMC-Server hätte in der vom Linux-Magazin getesteten Konfiguration über 40000 Euro gekostet, das ist eine Stange Geld. Der exakte Preis hängt natürlich von einer Vielzahl an Konfigurationsoptionen ab, auch mag ein guter und/oder großer Kunde Rabatte erhalten. Auf den Cent soll es hier aber gar nicht ankommen. Der getestete Server bot eine gewisse inhärente Redundanz (Raid, mehrere Netzwerkkarten, zwei Netzteile) – aber ein Totalausfall, etwa durch Wasser oder Feuer, wäre nicht zu kompensieren gewesen. Dazu hätte es mindestens eines zweiten Servers in einem anderen Brandabschnitt oder Gebäude bedurft. Dazu kämen noch die Stromkosten, Kosten für Raummiete und Kühlung und (anteilige) Personalkosten für wenigstens zwei Administratoren, um die Betreuung auch bei Urlaub oder Krankheit zu sichern.
Andererseits wird auch die Cloudvariante nicht verschenkt. Die größte wählbare Instanzklasse für den PostgresSQL-Server (64 virtuelle CPUs, 488 GByte RAM), die immer noch kleiner gewesen wäre als das physische Modell in unserem Test (80 CPUs, 768 GByte RAM) würde bei Zusicherung von 15000 IOPS im Dauerbetrieb über 7700 Dollar im Monat kosten. Die schließlich hier getestete 40-CPU-Konfiguration bringt es immer noch auf 4200 Dollar/Monat bei 15000 IOPS beziehungsweise sogar auf 13535 Dollar mit maximal 40000 IOPS, wovon allein 8000 Dollar für die IOPS-Zusicherung zu zahlen sind. Das ist auch nicht billig.
Fast könnte man meinen, die Mietkosten eines halben Jahres wögen die Anschaffung der Hardware auf. Aber ganz so einfach ist es leider nicht. Denn in dieser Rechnung fehlen neben den nicht unerheblichen Betriebs- und Personalkosten und den nötigen Aufwendungen für die Hochverfügbarkeit auch die indirekt geldwerten Vorteile der hohen Bequemlichkeit in der Anwendung.
So bräuchte sich der Anwender über Administration und Ausfallschutz keine Gedanken machen und könnte die Kapazität in Grenzen jederzeit erweitern. Zudem bräuchte er auch nichts darüber zu wissen, wie genau er ein anvisiertes Performanceziel etwa beim Storage erreichen kann – er braucht einfach nur kundzutun, was er haben will. Um die Sicherheit der Datenbank kümmert sich ebenfalls Amazon. Urlaub oder Krankheit beim Betreuungspersonal brauchen den Anwender nicht zu interessieren, Ausfälle des Servers oder der Infrastruktur, Updates oder Reparaturen gehen ihn nichts an – er kann immer 7×24 über die gebuchte Leistung verfügen.
Fazit
Bei der Frage, welches die günstigere Variante ist, wird sicher mitentscheidend sein, ob der Nutzer bereits über eigene Infrastruktur und über Admins verfügt, die den Datenbankserver betreuen könnten. Controller sprechen hier scherzhaft von EDA-Kosten (“eh da”). Wo Rechenzentrum und Know-how fehlen, ist das Angebot verlockend, alles dem Cloudprovider zu überlassen.
Auch zu überlegen wäre, ob die Cloudlösung dauerhaft gebraucht wird oder vielleicht nur Lastspitzen abfedern soll, für die eigene Hardware zu teuer wäre, weil sie die meiste Zeit nicht ausgelastet ist. Daneben kann der Datenschutz als Argument ins Gewicht fallen – die Testinstanz lief in der Region Amerika/Ost von Amazon. Dort will oder darf nicht jeder seine Daten lagern.
Ein K.o.-Kriterium kann auch die Performance sein. An die Leistung potenter Hardware reichte die Cloud im Test nicht heran. Zwar ließ sie sich tunen, nur ist das teuer. Andererseits: Nicht jeder Anwendungsfall erfordert die Leistung eines Server-Boliden. Oft wird man mit einer durchschnittlichen Performance auskommen und muss dann keine Zusatzkosten kalkulieren.
Was außerdem besonders mit der Cloud möglich wird, ist ein Skalieren in die Breite. Statt die Leistung eines einzelnen Servers in die Höhe zu schrauben, nimmt der Nutzer dann lieber zehn kleinere Instanzen und stellt sie hinter einen Load Balancer. Das bringt gleichzeitig eine optimale Ausfallsicherheit. Nur ist das mit einer Datenbank nicht so einfach, weil alle Instanzen von Datenänderungen erfahren müssen. Alternativ lässt sich die Datenbank partitionieren (Sharding), was Zugriffe zeilenweise auf eine Anzahl Teil-Datenbanken verteilt.
Allerdings ist PostgreSQL wie viele relationale Datenbanksysteme (RDBMS), eher auf das vertikale Skalieren ausgerichtet, wie es die Tester hier demonstriert haben. Für das horizontale Skalieren kommt am ehesten eine Replikation auf mehrere Knoten in Frage, von denen Nutzer parallel lesen können. Geschrieben würde aber immer nur auf einen Master. Daher wäre das beim vorliegenden Benchmark keine Hilfe, bei dem schreibende Transaktionen dominieren. Da hätte nur eine Multimaster-Replikation geholfen.
Für eine bessere Verteilung einer PostgreSQL-Datenbank auf mehrere Knoten gibt es Third-Party-Lösungen wie Citus Data [14] oder Postgres-XL [15]. Die bietet Amazon jedoch nicht als RDS-Komponente an, man müsste sie in der Cloud selbst installieren und warten. Verteiltes SQL ist aber generell kompliziert, in der Regel erkauft sich der Nutzer Vorteile durch Nachteile an anderer Stelle. Eine Entscheidung dafür sollte gründlich überdacht und durchgerechnet werden.
Infos
-
Elephant Shed: https://www.credativ.de/postgresql-competence-center/elephant-shed-postgresql-appliance
-
Pgadmin 4: https://www.pgadmin.org
-
Pgbackrest: https://pgbackrest.org
-
Prometheus: https://prometheus.io
-
Grafana: https://grafana.com
-
Cockpit: https://cockpit-project.org
-
Shell-in-a-Box: https://github.com/shellinabox
-
Dell Poweredge R740: https://www.dell.com/de-de/work/shop/povw/poweredge-r740
-
Hammer DB: http://www.hammerdb.com
-
TPC-C: http://www.tpc.org/tpcc
-
Citus Data: https://www.citusdata.com
-
Postgre-XL: https://www.postgres-xl.org





