
C++-Experte Rainer Grimm soll für einen Kunden ein Telefonbuch entwickeln und er will nicht bei null anfangen. Wozu gibt es schließlich praktische Helfer in Form von Bibliotheken?
Das Syndrom “Not invented here” dürfte die wohl schlimmste Krankheit sein, die einen Software-Entwickler befallen kann. Die Symptome sind eindeutig: Hartnäckig sträubt sich der daran leidende Programmierer bestehende Bibliotheken zu verwenden und erfindet das Rad sprichwörtlich neu. Dabei ist die Medizin so süß, denn modernes C++ bringt schicke Bibliotheken mit. Beweise gefällig?
Fast am Ziel
Die liefert der Artikel, mit dem die Serie zu den Geboten für moderne C++-Entwickler bereits ihre vorletzte Etappe erreicht. Diesmal lautet das Motto: “Kenne deine Bibliotheken” (Abbildung 1).

Abbildung 1: “Kenne deine Bibliotheken” lautet das neunte von zehn Geboten für C++-Entwickler.
Einer der charakteristischen Unterschiede zu klassischem C++ besteht darin, dass modernes C++ einen reichen Satz an Bibliotheken im Schlepptau hat. Dank diesen ist es recht einfach, etwa ein performantes Telefonbuch in C++ zu implementieren. Die Zutaten für das Rezept bestehen im Wesentlichen aus Bibliotheken für reguläre Ausdrücke [1], Zufallszahlen [2], Zeit [3] sowie sequenzielle und assoziative Container [4].
Die Anforderungen
Die ersten Anforderungen des Kunden X an eine geplante Telefonbuch-Anwendung klangen noch einfach – verdächtig einfach. Er würde lediglich ein digitales Telefonbuch brauchen, das ihm auf Anfrage die Telefonnummer zu einem Familiennamen zurückliefert.
Eine zweite, ausführlichere Diskussion schärfte dann das Anforderungsprofil. Das Telefonbuch soll gut 80000 Einträge besitzen, in Zukunft noch deutlich wachsen und alle Anfragen, unabhängig von seiner Größe, in der gleichen Zeit beantworten.
Lediglich eine Anforderung ließ sich vor Projektstart nicht endgültig klären: Soll das Telefonbuch die enthaltenen Namen von A bis Z sortieren oder nicht?
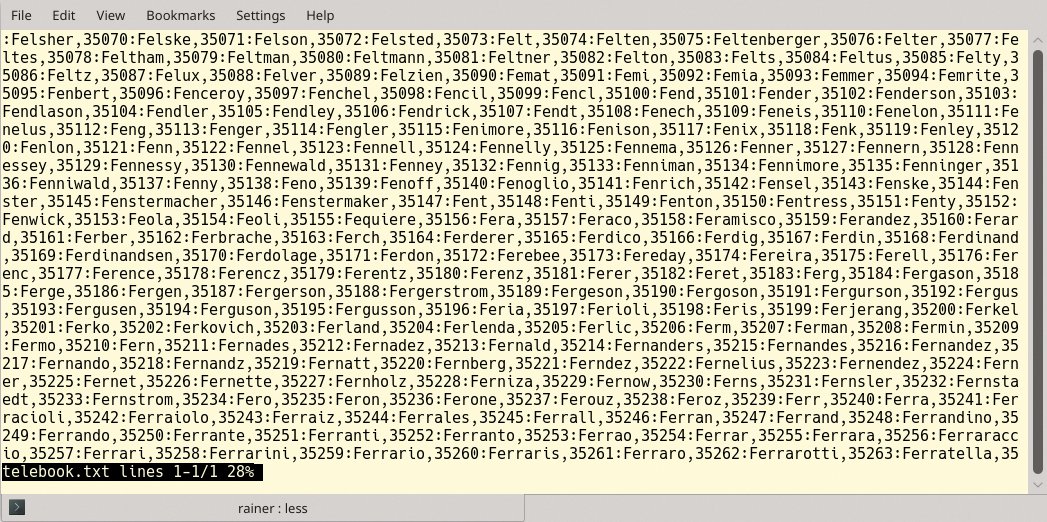
Abbildung 2: Die Textdatei mit den Familiennamen-Telefonnummer-Paaren.
Zum Glück stellte Kunde X eine Textdatei mit 80000 Dummy-Einträgen zur Verfügung. Abbildung 2 zeigt einen kleinen Auszug, das Datenformat lässt sich leicht erkennen. Ein Doppelpunkt trennt die Paare aus Familiennamen und Telefonnummer. Den Familiennamen separiert wiederum ein Komma von der Telefonnummer. Diese Struktur besitzen zum Beispiel die beiden ersten Einträge
:Felsher,35070:Felse,35071:[...]
aus Abbildung 2. Um für die Zukunft gerüstet zu sein, sollte das Telefonbuch zudem deutlich mehr als die verfügbaren 80000 Telefonnummern speichern. Das Projekt kann beginnen.
Die Implementierung
Die Anforderungen des Kunden geben die ersten Schritte der Implementierung vor. Der Code muss die Daten der Testdateien zunächst parsen und in eine passende Datenstruktur einlesen. Diese Datenstruktur ist das Telefonbuch. Ist dies vollbracht, gilt es, einen Performance-Test mit dem Telefonbuch zu absolvieren. Schließlich macht der Entwickler das Telefonbuch zukunftsfest, indem er dessen Größe deutlich erweitert. Listing 1 zeigt das fertige Programm.
Listing 1
Telefonbuch nach Kundenanforderung
001 #include <chrono>
002 #include <fstream>
003 #include <iostream>
004 #include <map>
005 #include <random>
006 #include <regex>
007 #include <sstream>
008 #include <string>
009 #include <unordered_map>
010 #include <vector>
011
012 using map = std::unordered_map<std::string, int>;
013
014 std::ifstream openFile(const std::string& myFile){
015
016 std::ifstream file(myFile, std::ios::in);
017 if ( !file ){
018 std::cerr << "Can't open file "+ myFile + "!" << std::endl;
019 exit(EXIT_FAILURE);
020 }
021 return file;
022
023 }
024
025 std::string readFile(std::ifstream file){
026
027 std::stringstream buffer;
028 buffer << file.rdbuf();
029
030 return buffer.str();
031
032 }
033
034 map createTeleBook(const std::string& fileCont){
035
036 map teleBook;
037
038 std::regex regColon(":");
039
040 std::sregex_token_iterator fileContIt(fileCont.begin(), fileCont.end(), regColon, -1);
041 const std::sregex_token_iterator fileContEndIt;
042
043 std::string entry;
044 std::string key;
045 int value;
046 while (fileContIt != fileContEndIt){
047 entry = *fileContIt++;
048 auto comma = entry.find(",");
049 key = entry.substr(0, comma);
050 value = std::stoi(entry.substr(comma + 1, entry.length() -1));
051 teleBook[key] = value;
052 }
053 return teleBook;
054
055 }
056
057 std::vector<std::string> getRandomNames(const map& teleBook){
058
059 std::vector<std::string> allNames;
060 for (const auto& pair: teleBook) allNames.push_back(pair.first);
061
062 std::random_device randDev;
063 std::mt19937 generator(randDev());
064
065 std::shuffle(allNames.begin(), allNames.end(), generator);
066
067 return allNames;
068 }
069
070 void measurePerformance(const std::vector<std::string>& names, map& m){
071
072 auto start = std::chrono::steady_clock::now();
073 for (const auto& name: names) m[name];
074 std::chrono::duration<double> dur= std::chrono::steady_clock::now() - start;
075 std::cout << "Access time: " << dur.count() << " seconds" << std::endl;
076
077 }
078
079 int main(int argc, char* argv[]){
080
081 std::cout << std::endl;
082
083 // get the filename
084 std::string myFile;
085 if ( argc == 2 ){
086 myFile= {argv[1]};
087 }
088 else{
089 std::cerr << "Filename missing !" << std::endl;
090 exit(EXIT_FAILURE);
091 }
092
093 std::ifstream file = openFile(myFile);
094
095 std::string fileContent = readFile(std::move(file));
096
097 map teleBook = createTeleBook(fileContent);
098
099 std::cout << "teleBook.size(): " << teleBook.size() << std::endl;
100
101 std::vector<std::string> randomNames = getRandomNames(teleBook);
102
103 measurePerformance(randomNames, teleBook);
104
105 std::cout << std::endl;
106
107 }
Zunächst liest es in den Zeilen 84 bis 93 die Datei ein. Dabei leistet die Funktion »openFile()« (Zeilen 14 bis 23) wertvolle Dienste. Die Funktion »readFile()« (Zeilen 25 bis 32) gibt den Inhalt der Datei als String zurück, aus dem »createTeleBook()« ein Telefonbuch erzeugt. In diesem Fall ist das Telefon eine »std::map<std::string, int>« (Zeile 12). Der Schlüssel der Map steht für den Familiennamen, der Wert für die Telefonnummer.
Die Funktion »createTeleBook()« verdient eine Erläuterung. Weil Doppelpunkte die Einträge der Textdatei trennen, kommt auch ein Doppelpunkt in Zeile 40 zum Einsatz, um den »std::regex_token_iterator« zu erzeugen. Wie ist der Ausdruck zu lesen? Der Token-Iterator erhält sowohl den Anfangs-Iterator »fileCont.begin()« als auch den End-Iterator »fileCont.end()« als Eingabe und wendet den regulären Ausdruck »regColon« an.
Was aber bedeutet die »-1« in diesem Aufruf? Dieser Wert bewirkt, dass der Iterator nicht die Kommazeichen in dem String ermittelt, sondern genau das Gegenteil: den Text zwischen den Kommazeichen. Dies sind dann genau die gesuchten Paare aus Familienname und Telefonnummer.
In der Schleife innerhalb der Zeilen 46 bis 52 kommt der Token-Iterator dann zum Einsatz. Er läuft, bis er das Ende (»fileContEndIt«) des Strings erreicht. In jeder Iteration extrahiert er dabei ein Pärchen aus Familienname und Telefonnummer und speichert es in dem Eintrag »entry« in Zeile 47. Danach trennt das Programm diesen Eintrag beim Komma (Zeile 48) und extrahiert den Schlüssel (Zeile 49) sowie den Wert als Ganzzahl (Zeile 50). Ist das geschafft, lässt sich das Paar aus Familienname und Telefonnummer in dem Telefonbuch speichern:
teleBook[key] = value
In Zeile 99 ermittelt das Programm abschließend die Länge des verwendeten Telefonbuchs.
Die Performance-Tests
Ohne die Performance-Anforderung wäre das Projekt hiermit bereits erfolgreich abgeschlossen. Um die Leistungsfähigkeit beim Datenabruf zu testen, muss der Programmierer zunächst einen Testvektor erzeugen. Das ist einfach. Mit Hilfe der Funktion »getRandomNames()« (Zeilen 57 bis 68) zieht die Anwendung alle Schlüssel aus dem Telefonbuch und verschiebt sie auf einen Vektor (Zeile 60). Anschließend nimmt der Zufall seinen Lauf und erzeugt in Zeile 65 eine zufällige Permutation des Vektors.
Genau dieser Vektor kommt dann in der Funktion »measurePerformance()« zum Einsatz. Er erledigt für alle Schlüssel (Zeile 73) die Abfragen und beantwortet in Zeile 75 die entscheidende Frage: Wie lange hat es gedauert? Bei dem Performance-Test verwende ich dabei die »std::chrono::steady_clock«, da diese sich im Gegensatz zur »std::chrono::system_clock« nicht neu stellen lässt.
Der Screenshot in Abbildung 3 zeigt die Performance-Zahlen für die vier verschieden großen Telefonbücher, die zwischen 89000 und 89000000 Einträge besitzen. Ein sezierender Blick auf die Nummern bringt allerdings einige Ernüchterung: Wächst das Telefonbuch um den Faktor 10, benötigen die Abfragen ungefähr 13- bis 19-mal mehr Zeit. Damit erfüllt das Programm nicht mehr die ursprünglichen Anforderungen, denn die Abfragen sollten sich lediglich um den Faktor 10 verlangsamen.
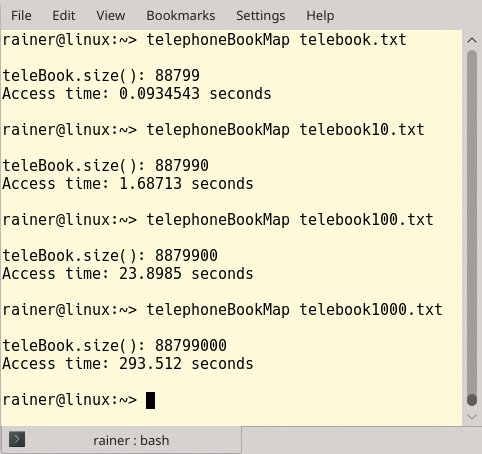
Abbildung 3: Für den eingebauten Performance-Test liefert »std::map« Zahlen.
Das wirft die Frage nach potenziellen Optimierungsmöglichkeiten auf. Natürlich hat der Entwickler das Programm mit maximaler Optimierung kompiliert. Nach intensiven Gesprächen mit dem Kunden verzichtet dieser darauf, die Schlüssel zu sortieren. Das erlaubt es, in der Zeile 12 die »std::map« durch eine »std::unordered_map<std::string, int>« zu ersetzen.
Letztere bringt einen Vorteil mit, denn sie sichert dem Entwickler amortisierte konstante Zugriffszeiten zu. Darüber hinaus erweist es sich als äußerst praktisch, dass die »std::unordered_map« auch das Interface von »std::map« unterstützt. Schnell ist das Programm übersetzt. Die Performance-Zahlen in Abbildung 4 sprechen eine eindeutige Sprache – der Umbau lohnt sich.
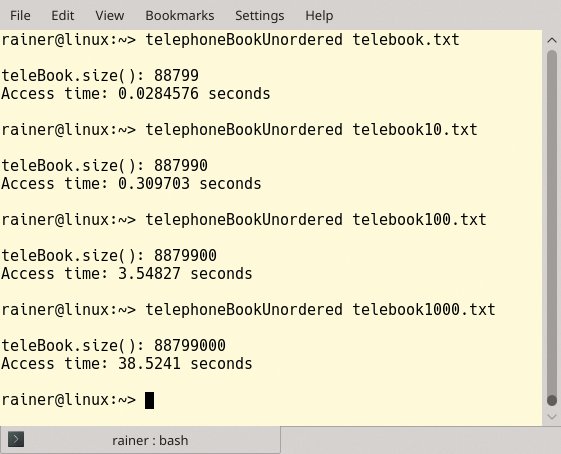
Abbildung 4: Die Performance-Zahlen verbessern sich nach dem Umstieg auf »std::unordered_map«.
Wächst das Telefonbuch um den Faktor 10, verlangsamt das die Zugriffe lediglich um etwa den Faktor 11. Das bringt den Entwickler schon nahe an den optimalen Fall, in dem die Zugriffszeit auf einen Familiennamen unabhängig von der Größe des Telefonbuchs ist.
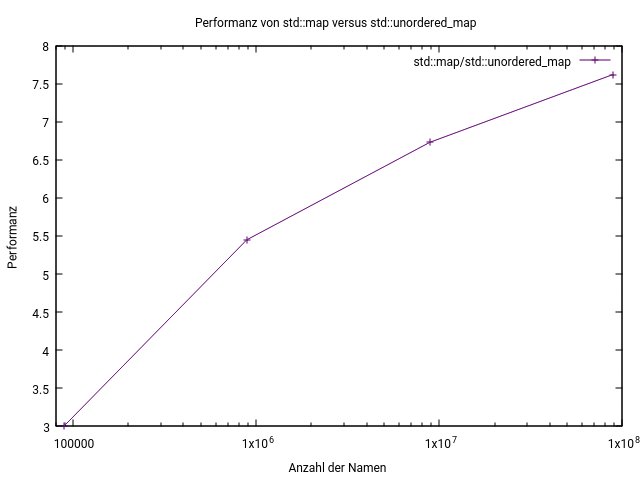
Abbildung 5: Die Bibliotheken »std::map« und »std::unordered_map« im direkten Performance-Vergleich.
Dabei spielt der assoziative Container »std::unordered_map« in einer anderen Liga, weil er die Zugriffe um den Faktor 3- bis 8-mal schneller erledigt als der Container »std::map«. Die Abbildung 5 bringt es auf den Punkt.
Mit dem bestandenen Performance-Test lässt sich das Projekt rund abschließen.
Wie geht’s weiter?
Einen runden Abschluss liefert auch der nächste Artikel, der bereits den zehnten und letzten Tipp zu gutem C++-Code gibt: “Strebe nach Einfachheit”. Wenn das keine schöne Aussicht ist.
Infos
-
Bibliothek für reguläre Ausdrücke: http://en.cppreference.com/w/cpp/regex
-
Bibliothek für Zufallszahlen: http://en.cppreference.com/w/cpp/numeric/random
-
Bibliothek für Zeitmessungen: http://en.cppreference.com/w/cpp/chrono
-
Container-Bibliothek: http://en.cppreference.com/w/cpp/container
Der Autor

Rainer Grimm ist Trainer für C++ und Python. Seine zahlreichen C++-Bücher, zuletzt “The C++ Standard Library” und “Concurrency with modern C++”, sind bei O’Reilly und Leanpub erschienen.





