
© belchonock, 123RF
Wer eine Cloud betreibt, will deren Hardware möglichst effizient nutzen – und so früh wie möglich wissen, wann er aufrüsten muss. Mit den richtigen Ansätzen und Werkzeugen ist beides kein Problem.
Früher war das Planen für die Betreiber von Rechenzentren ein langwieriges Geschäft: Von der ersten Idee, die Kunden an sie herantrugen, bis zu dem Zeitpunkt, an dem die dafür nötigen Server im Rack hingen, produktiv waren und der Kunde sie abgenommen hatte, verging einige Zeit.
Heute verkürzt sich diese Zeitspanne drastisch – Schuld daran ist die Cloud. Cloudumgebungen verringern den administrativen Overhead so stark, dass der Betreiber in Sekunden zur Verfügung stellen kann und muss, was einst wochenlangen Vorlauf bedeutete. Der Cloudanbieter muss seinen Kunden versprechen, dass sie auf nahezu unbegrenzte Ressourcen zugreifen können. Das wiederum bedeutet für ihn einiges an Aufwand – operativ wie finanziell. Nur wenn er in seinem Rechenzentrum einen gewissen Puffer an Reservehardware vorhält, funktioniert das Konzept.
Schließlich soll es für den Kunden genügen, sich beim Anbieter zu registrieren und seine Kreditkartendaten dort zu hinterlegen, um sofort Infrastruktur nutzen zu können. Der Provider rechnet letztlich anhand des tatsächlichen Verbrauchs ab. Dabei kann er aber nicht wissen, welcher Kunde wann Ressourcen in seinem Setup beansprucht. Die Frage, wie sich Cloudkapazitäten verwalten und planen lassen, ist deshalb eine der wichtigsten für Cloudprovider.
Weitsichtig agieren
Die offensichtlichste Variante, mit dieser Herausforderung umzugehen, ist das Vorhalten großer Reserven in der Hoffnung, dass ein Kunde kommt, der sie nutzt. Das wäre allerdings nur eine Scheinlösung. Auf der einen Seite verbrät der Anbieter auf diese Weise bares Geld, weil er beträchtliche Mengen toten Kapitals anhäuft. Auf der anderen Seite stellt sich die Frage, wie groß diese Ressourcenpolster denn sein müssen. Reichen 10 Prozent der Gesamtkapazität? Oder lieber 20 Prozent? Man merkt schnell: Planung à la Pi mal Daumen reicht nicht.
Sinnvolles Capacity Management innerhalb einer Cloudumgebung funktioniert anders und ist ein Konzept aus mehreren Komponenten. Schon die Frage, wie die zur Verfügung stehende Kapazität im Rechenzentrum möglichst effizient genutzt werden kann, ist sehr wichtig. Kritisch ist überdies die Frage, wie die Admins der Cloud möglichst effizient viele Metrikdaten ihrer Plattform sammeln und korrekt interpretieren, um den Bedarf an zusätzlichen Ressourcen früh zu erkennen. Nur so lässt sich die nötige Erweiterung gut planen und durchführen.
Relevant ist schließlich auch, ob der Anbieter die Infrastruktur im Rechenzentrum so gut im Griff hat, dass schnelles Skalieren ohne großen Aufwand möglich ist. Der Begriff Hyperscalability macht hier die Runde – die Plattform soll sich so leicht und schnell erweitern lassen, dass dafür kaum Kosten entstehen.
Dieser Artikel beleuchtet die Zutaten zu effizienter Kapazitätsplanung in der Cloud und erklärt, wie sie sich im Alltag bestmöglich umsetzen lassen.
Schon bevor Admins überhaupt den ersten Server installieren, tun sie gut daran, über verschiedene Faktoren der Skalierbarkeit nachzudenken. Das betrifft einerseits die Art und Weise, wie Kunden später die Ressourcen einer Cloud nutzen wollen, andererseits auch die umsichtige Planung der Infrastruktur, um effektive Kapazitätserweiterung zu ermöglichen.
Auf die Software-Anforderungen geht der Artikel später noch ausführlich ein. Damit Skalierbarkeit in die Breite einfach wird, braucht es passende Hardware.
Klassisches Netz taugt nicht
Eine zentrale Rolle nimmt das Thema Netzwerk ein. Im klassischen Setup ist jede Umgebung sorgfältig geplant, ihre Skalierbarkeitsgrenzen stehen von Anfang an fest. Das hat ganz banale Gründe. Wer etwa ein Webserver-Setup plant, rechnet damit, dass er die gesamte Plattform ohnehin nach fünf Jahren austauschen muss, weil die Garantie der verbauten Server dann ausläuft. Diese Installationen planen die Admins also mit einer fixen Maximalgröße und konzipieren benötigte Infrastruktur wie das Netzwerk dazu passend.
Admins von Clouds kennen diesen Luxus nicht. Eine Cloud muss in der Lage sein, binnen Tages- oder Wochenfrist massiv zu wachsen, und zwar auch über die Grenzen der ursprünglichen Planung hinweg. Außerdem hat eine Cloud kein Ablaufdatum: Weil die Cloudsoftware in aller Regel nahtlos in die Breite skalieren kann, lassen sich alte Server laufend durch neue ersetzen.
Wer sich das in konventionellen Setups vorhandene Netzwerk anschaut, trifft meist auf eine klassische Baum- oder Sternstruktur. Es gibt also einen oder – im Interesse der Ausfallsicherheit – zwei Switche, an die weitere Switche mittels entsprechend dicker Leitungen angebunden sind. An ihnen hängen dann die eigentlichen Knoten des Setups. Dieses Netzwerkdesign eignet sich kaum für Scale-out-Installationen, denn je weiter der Admin die Baumstruktur nach unten hin ausdehnt, desto weniger Netzwerk kommt bei den einzelnen Knoten an.
L3-Netze skalieren besser
Wer eine Cloud plant, sollte deshalb wegen der Skalierbarkeit von Anfang an auf eine Layer-3-Architektur im Leaf-Spine-Layout setzen. Die unterscheidet sich vom klassischen Ansatz vorrangig dadurch, dass die Switche zu dummen Paketweiterleitern ohne eigene Managementfunktionen mutieren.
Physisch unterteilt sich das Netzwerk in mehrere Ebenen: Die Leaf-Ebene stellt über entsprechende Router die Verbindung zur Außenwelt her. Die Spine-Switche sind in jedem Rack verbaut und auf beliebig vielen Pfaden mit den Leaf-Switchen verbunden.
Pakete suchen sich in diesem Szenario ihren Weg durch das Netzwerk nicht mehr auf Basis der Layer-2-Protokolle, sondern werden zwischen den Hosts über BGP ausgetauscht. Jeder Switch fungiert als BGP-Router und jeder Host spricht ebenfalls das BGP-Protokoll.
Der Clou: Steht das Skalieren in die Breite an, lassen sich alle Ebenen des Setups problemlos um neue Switche erweitern. Und das sogar im laufenden Betrieb. Neue Knoten teilen anderen einfach per BGP die Route mit, über die sie erreichbar sind. Das Routing der Switche führt dazu, dass selbst Hosts, die nicht im selben Netz hängen, ganz problemlos miteinander kommunizieren.
Wer ad hoc also 30 neue Racks in seiner Cloud ausrollen möchte, kann das auf Basis eines solchen Netzwerklayouts ohne Probleme tun. Klassische Designs des Netzwerks stießen hingegen hier schnell an ihre Grenzen.
Noch gibt es allerdings einiges bei dem Konzept zu beachten: BGP lässt sich aktuell nur auf Switchen betreiben, die das Feature als teuren Teil der eigenen Firmware anbieten – oder Cumulus Linux unterstützen. Mellanox geht mit gutem Beispiel voran und bietet zukunftssichere 100-GBit-Switche mit Cumulus-Support (Abbildung 1). Eine detaillierte Beschreibung des Layer-3-Prinzips hat übrigens das Linux-Magazin bereits geliefert [1].

Abbildung 1: 100-GBit-Switches sind Pflicht für zukunftssichere Cloudsetups.
CPU und RAM
Aus einer ganz anderen Ecke gerät der Admin bei der Kapazitätsplanung der Cloud unter Beschuss, wenn es um die Ressourcen CPU und RAM geht. Gleich vorweg sei festgehalten, dass das Thema Overcommitting im Bezug auf diese beiden Faktoren ausgesprochen heikel ist. Beim RAM verbietet sich jedes Überbuchen von vornherein: Zwar bietet KVM diese Option, doch unter keinen Umständen will der Admin, dass der Out-of-Memory-Killer des Linux-Kernels beliebige VMs innerhalb der Cloud abschießt, weil ihm der RAM ausgeht. Besser funktioniert das Überbuchen verfügbarer CPUs. Aber auch hier nicht übertreiben – ein einfaches Überbuchen gilt meist als die beste Variante.
Von viel größerer Bedeutung für die Kapazitätsplanung in der Cloud ist jedoch das Verhältnis von CPU und RAM zueinander. Wer sich das Angebot für die meisten Clouds anschaut, wird feststellen, dass dabei oft eine feste Anzahl von CPUs einer bestimmten Menge an RAM zugeordnet ist. Wer etwa eine virtuelle CPU bucht, muss für diese mindestens 4 GByte RAM dazunehmen, weil das die kleinste verfügbare Variante ist.
Die Cloudanbieter sind zu diesem System nicht etwa übergegangen, weil sie ihre Kunden gängeln wollen. Viel eher geht es darum, den Verschnitt auf Seiten des Anbieters so gering wie möglich zu halten. Ein Beispiel: Ein aktueller Server mit zwei Xeon-E5-2690-Prozessoren bietet in Summe 14 CPU-Kerne und 28 Threads. Entsprechende Systeme sind meist mit 256 oder 512 GByte RAM ausgestattet. Durch das beschriebene Überbuchen der Ressource CPU stehen insgesamt 56 virtuelle CPU-Kerne zur Verfügung, von denen der Anbieter im Normalfall 50 an seine Kunden weitergibt.
Nimmt er das zuvor beschriebene Verhältnis von CPU und RAM mit 1:4 an und gibt es durch entsprechende Hardwareprofile vor, muss ein Kunde, der zwölf virtuelle CPU-Kerne nutzt, mindestens 48 GByte Speicher dazubuchen. Laufen fünf dieser VMs auf dem System, bleibt ein kleiner Rest aus CPU und RAM übrig, der sich auf etwaige kleinere Profile aufteilt.
Folgt der Admin dem Verhältnis von 1:4 nicht und bietet stattdessen eine beliebige Aufteilung an, könnte ein Kunde mit besonders CPU-lastigen Tasks eine virtuelle Maschine buchen, die 32 virtuelle CPU-Kerne hat, jedoch nur 16 GByte RAM benötigt. Findet sich parallel dazu nicht auch ein Kunde, der zwar viel RAM, aber nur wenige CPUs braucht, dann läge auf diesem System verfügbarer RAM einfach brach. Denn zusätzliche VMs könnte die Cloud dort aufgrund des Mangels an verfügbaren virtuellen CPUs kaum noch starten.
Eben jenen Verschnitt muss der Cloudanbieter aus ureigenem Interesse so gering wie möglich halten, weil er sonst wieder totes Kapital im Rechenzentrum stehen hat. Das Verhältnis von 1:4 für CPU und RAM eignet sich dafür in den meisten Fällen gut – ist jedoch nicht in Stein gemeißelt. Kann der Admin für die eigene Cloud absehen, dass andere Work-loads regelmäßig vorkommen, kann er die Werte natürlich entsprechend anpassen. Wichtig ist am Ende jedoch, dass er Hardware bestellt, die zum absehbaren Workload passt (Abbildung 2).

Abbildung 2: Wer auf moderne Mehrkern-CPUs und große Mengen RAM setzt, muss auf das richtige Verhältnis der Komponenten zueinander bei VMs achten.
Daten erheben
Wenn die Cloud gut geplant und aufgebaut ist, kommt nun der kniffligste Teil in Sachen Kapazitätsplanung in der Cloud – nämlich der Blick in die Glaskugel, um den Bedarf an neuer Hardware frühzeitig zu erkennen. Seriös betrachtet ist es unmöglich, jeden Ressourcenbedarf rechtzeitig abzusehen. Mietet sich von heute auf morgen ein Kunde auf der Plattform ein, der kurzfristig 20 000 virtuelle CPUs braucht, würde das die meisten Cloudanbieter dieses Planeten zumindest kurzzeitig ins Schwitzen bringen.
Solche Ereignisse sind allerdings eher die Ausnahme als die Regel. Und das Wachstum einer Cloud lässt sich durchaus dann zumindest grob voraussagen, wenn der Admin die passenden Metriken dazu erhebt und adäquat auswertet. Welche Werkzeuge stehen dafür zur Verfügung, welche Metriken sollen verantwortliche Planer eigentlich erheben und wie funktioniert deren Auswertung?
Klar ist: Das Erheben von Metriken funktioniert in Clouds anders als in den konventionellen Setups. Das machen allein die Zahlen deutlich. Gegeben sei etwa eine Cloud aus 2000 physischen Knoten und eine Anzahl von 200 Werten pro System, die der Admin alle 15 Sekunden erheben möchte. In Summe sind das 1 600 000 Messwerte pro Minute, also eine erwähnenswerte Menge.
An Monitoring-Systeme angeklebte Metering-Lösungen wie zum Beispiel PNP4Nagios kommen mit solchen Datenmengen kaum zurecht, schon gar nicht in den Fällen, in denen im Hintergrund eine klassische Datenbank wie MySQL für das Speichern der Metrikdaten verantwortlich ist.
Deutlich besser funktionieren Lösungen wie Prometheus oder Influx DB, deren Design auf dem Konzept der Time Series Database basiert. Ein sehr angenehmer Effekt ist, dass sich quasi als Nebenprodukt der Messwertesammlung auch das Monitoring abhandeln lässt. Ist etwa die Zahl der Apache-Prozesse auf einem Host 0, kann das Metriksystem einen Alarm auslösen, wenn es dafür konfiguriert ist. Sowohl Prometheus als auch Influx DB bieten entsprechende Funktionen.
Das Richtige erheben und deuten
Wer auf Prometheus oder Influx DB für Monitoring und Trending setzt, steht vor der nächsten Herausforderung: Welche Daten soll er erheben? Die gute Nachricht vorweg: Sowohl Prometheus als auch Influx DB bieten grundsätzlich einen Monitoring-Agent, der die grundlegenden Vitalwerte eines System schon in der Standardkonfiguration regelmäßig ausliest. Bei Prometheus ist das der Node Exporter, bei Influx DB Telegraf. Diese Werkzeuge ermöglichen es dem Admin ohne Mehraufwand, Werte wie die CPU-Last, die RAM-Nutzung oder den Netzwerkverkehr zu erheben.
Für die Cloud existieren in den meisten Fällen zusätzliche Agents: Der Open Stack Exporter für Prometheus http://2 etwa hängt sich an die verschiedenen API-Schnittstellen von Open Stack und erhebt so die Open Stack bekannten Daten (etwa die Menge an virtuellen CPUs, die insgesamt in Nutzung sind), die ihren Weg ebenfalls in den zentralen Datentresor finden.
In Summe gilt: Wer auf Monitoring auf Grundlage einer Zeitreihen-Datenbank setzt, erhält sowohl bei Prometheus als auch bei Influx DB die für Metering benötigten Werte ohne große Mehrarbeit (Abbildung 3). Cloud-spezifische Metriken lesen entsprechende Agents ein, zu den wichtigsten Parametern gehört hier etwa die Zeit, die die APIs der Cloud zum Antworten benötigen.
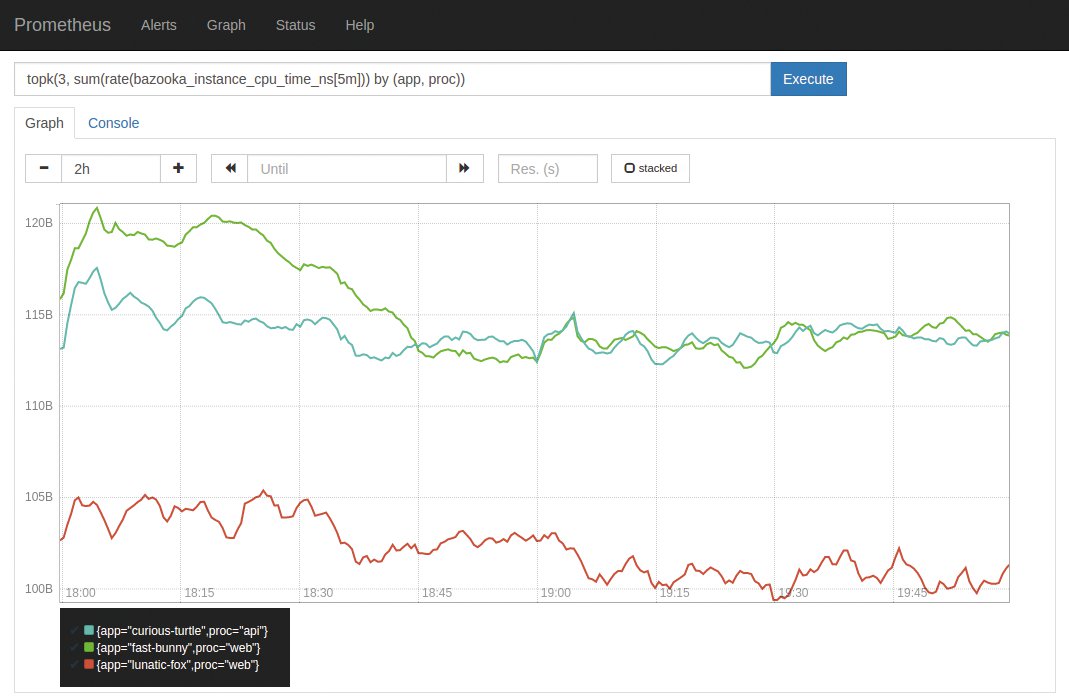
Abbildung 3: Prometheus fußt auf dem Konzept der Time Series Database (TSDB) und kommt auch mit vielen Millionen Einträgen in kurzer Zeit gut zurecht.
Womit der Artikel beim schwierigsten Teil des Themas Metering angekommen ist: Der schönste Datenschatz nützt nichts, wenn die darin befindlichen Informationen nicht auch adäquat ausgewertet werden. Aus Gewohnheit neigen viele Admins zur goldenen Mitte. Wenn API-Requests im Durchschnitt in 50 Millisekunden abgearbeitet sind, so die Überlegung, ist die Situation ja durchaus zufriedenstellend.
Die Annahme unterliegt aber dem Irrglauben, dass die Nutzung des Setups gleichmäßig über 24 Stunden des Tages verteilt sei. Erfahrungsgemäß ist das nicht so. Tagsüber ist auf einer Plattform meist viel mehr los als nachts. Wenn API-Anfragen also nachts sehr schnell abgearbeitet werden, dafür aber tagsüber ewig dauern, steht am Ende immer ein zufriedenstellender Durchschnittswert – der aber ganz nutzlos ist.
Ähnlich verhält es sich mit den Werten für CPU- sowie RAM- und Netzwerkkapazität: Wenn nachts besonders viele CPUs frei sind, dafür die Plattform tagsüber jedoch am Anschlag läuft, bringt das den Kunden nichts, die tagsüber virtuelle Maschinen starten wollen. Ist nachts genug Bandbreite verfügbar, das Netz tagsüber aber komplett saturiert, steigt der Frust auf der Kundenseite.
Die Arbeit mit Perzentilen
Viel hilfreicher ist bei der Kapazitätsplanung das Hantieren mit so genannten Perzentilen. Streng genommen ist auch der Median ein solches, eben das 50. Perzentil der Summen-Häufigkeitsverteilung. Perzentile funktionieren so: Zunächst erstellt der Admin eine Tabelle aus allen Werten, die er für ein bestimmtes Ereignis hat. Geht es etwa um die benötigte Zeit, um eine API-Anfrage abzuarbeiten, und es liegen 100 Messwerte für diesen Parameter vor, so erstellt er eine Tabelle mit allen 100 Werten in aufsteigender Reihenfolge. Will er nun das 90. Perzentil wissen, so nimmt er die ersten 90 Prozent der Einträge und von denen wiederum den höchsten Wert. Der ist das 90. Perzentil. Analog funktioniert es mit allen Perzentilen.
Monitoring-Lösungen wie Prometheus oder Influx DB bieten ab Werk eine Funktion, mit der sich die Perzentile eines Datensatzes berechnen lassen. Der Clou dabei: Etwa das 99. Perzentil einer Erhebung ist für den Admin viel aussagekräftiger als ein Mittelwert. Denn damit weiß er, dass 99 Prozent aller Requests mit dieser Geschwindigkeit oder sogar besser laufen. Entsprechend kann er die Plattform so tunen, dass sich dieser Wert verbessert.
Zur Darstellung der Werte aus Prometheus oder Influx DB empfiehlt sich übrigens Grafana [3], das Queries direkt in der Datenbank aufrufen und damit auch die eingebaute Perzentil-Funktion nutzen kann (Abbildung 4).
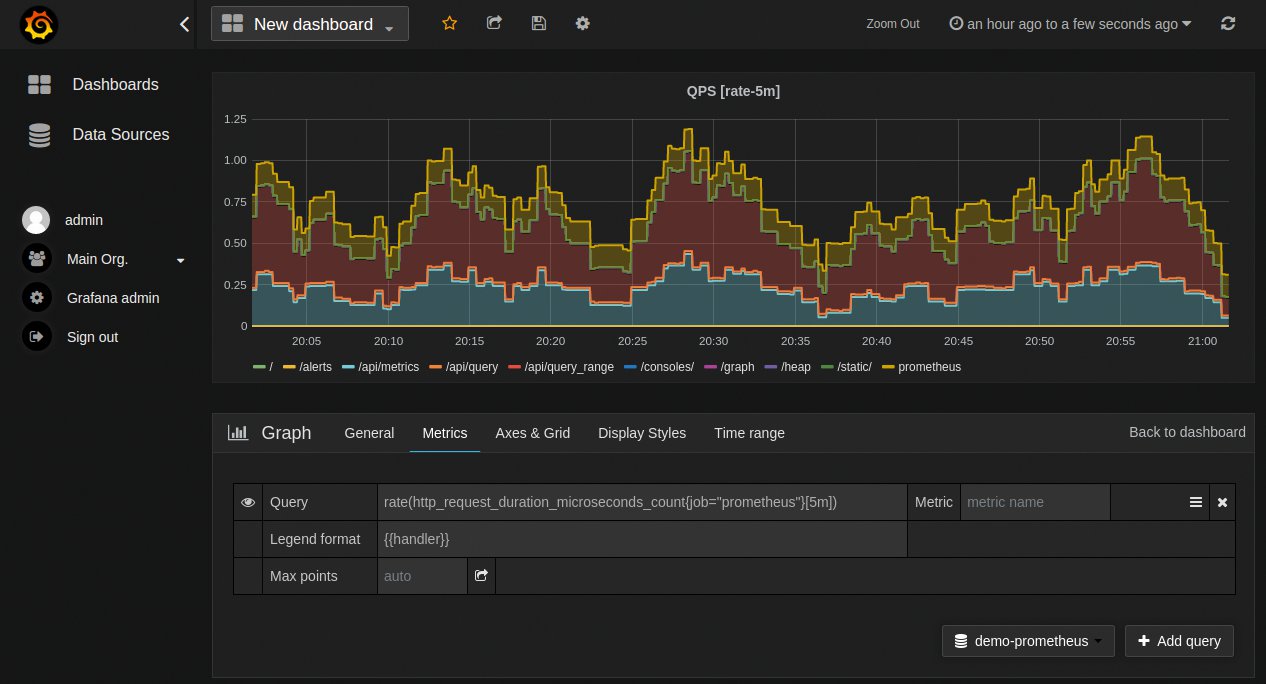
Abbildung 4: Grafana ist das Werkzeug der Wahl zur Virtualisierung von Daten – auch Perzentile lassen sich hier anzeigen.
Indirekt spielen die Perzentile auch beim Thema Kapazität mit. Auf Basis der Perzentile für bestimmte Faktoren wie der Bandbreite, die einer VM im Durchschnitt zur Verfügung steht, der Zeit für die Abwicklung von API-Aufrufen oder dem verfügbaren RAM lässt sich ablesen, wie weit am Anschlag die Cloud bereits läuft. Jeder mag hier eigene Minimal- und Maximalwerte definieren. Es hat sich jedoch als vorteilhaft erwiesen, für CPU und RAM wenigstens 25 Prozent der Kapazität als Reserve vorzuhalten, um etwaige Großkunden abfertigen zu können.
Hyperscalability erreichen
Der dritte und letzte Aspekts des Themas Kapazitätsplanung betrifft die Frage, wie gut sich ein Setup im Rechenzentrum überhaupt skalieren lässt. Es hilft aus Sicht des Administrators schließlich nichts, wenn er zwar rechtzeitig erkannt hat, dass er mehr Hardware braucht, aber diese dann in einer akzeptablen Frist nicht bereitstellen kann.
Das Nachstecken von Ressourcen in einer Cloud ist meist ein Prozess, der aus mehreren Phasen besteht. Phase 0 ist der formulierte Bedarf – also die Feststellung, dass mehr Kapazität nötig ist und in welchem Umfang. Danach geht es an die konkrete Planung der Hardware: Auch auf Basis der Fragen, die beim ersten Themenkomplex in Sachen Kapazitätsmanagement eine Rolle gespielt haben, definiert der Admin konkret, welche Server er in welcher Konfiguration braucht und bestellt diese schließlich. Schon hier entstehen gerade in größeren Firmen beträchtliche Verzögerungen – denn wenn es um Hunderttausende oder Millionen Euro geht, sind meiste lange Genehmigungsketten einzuhalten.
Das sprichwörtliche Heft in der Hand hat der Admin erst wieder, wenn die ersehnte Hardware tatsächlich eingetroffen ist. Zu diesem Zeitpunkt muss bereits feststehen, welcher Server wo in welchem Rack montiert werden soll, sodass die dafür verantwortlichen Personen im Rechenzentrum unmittelbar mit der Montage der Server samt entsprechender Verkabelung beginnen können.
Dabei spielen freilich auch Themen wie Redundanz und die Verfügbarkeit von Strom eine wichtige Rolle. Besonders effizient lässt sich ein solches Setup planen und gestalten, wenn dem Admin ein kombiniertes Werkzeug aus Datacenter Inventory Management (DCIM) und IP Address Management (IPAM) zur Verfügung steht: Aus dieser zentralen Wissensquelle entnimmt das RZ-Personal bei Bedarf alle Informationen, die es braucht. Netbox [4] ist ein Beispiel für eine sehr gut zu dieser Anforderung passende Lösung – kein Wunder, denn es ist für genau diesen Einsatzzweck entwickelt worden (Abbildung 5).
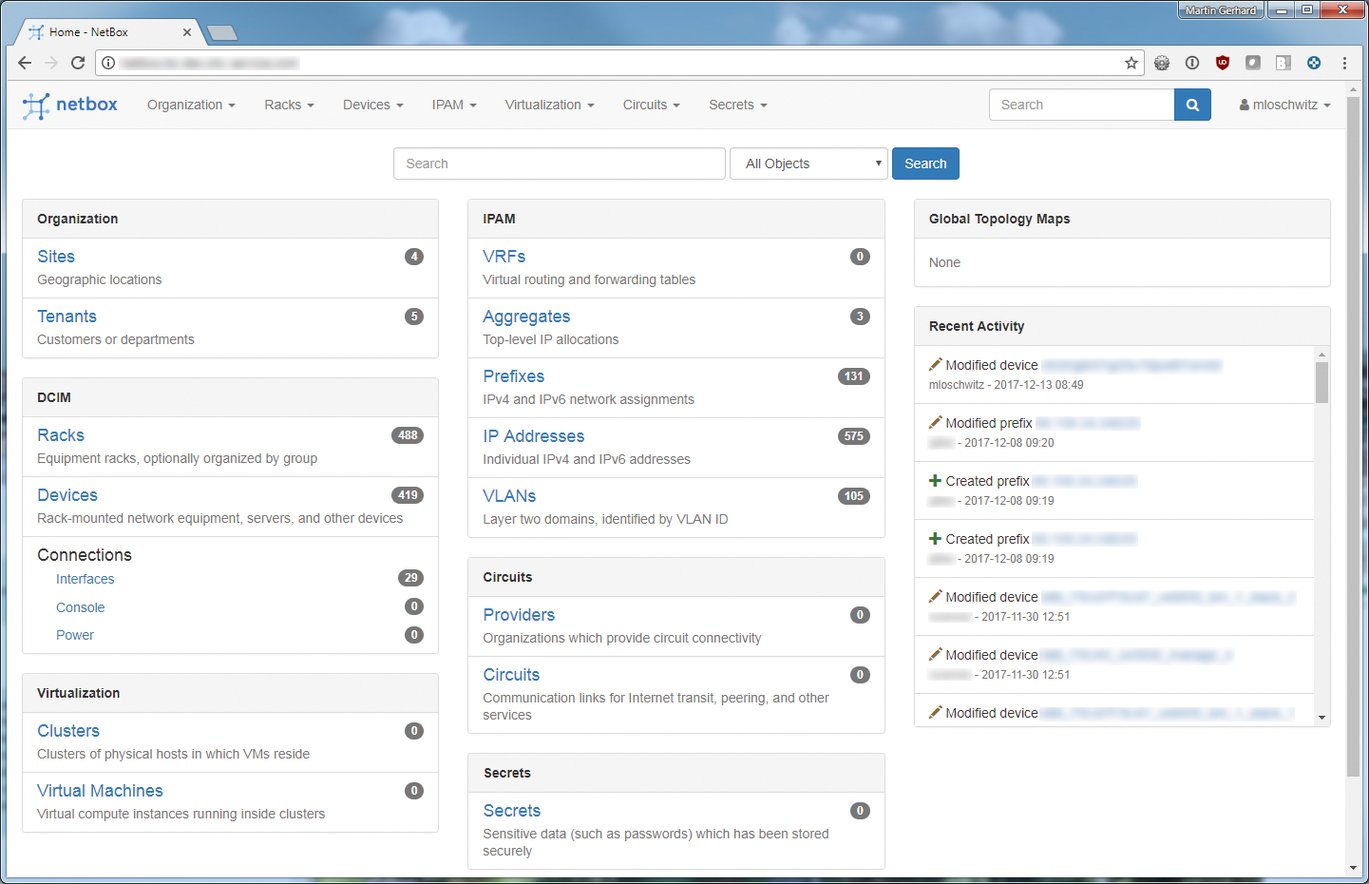
Abbildung 5: Netbox kann in Scale-Out-Setups als DCIM- und IPAM-Komponente das Bindeglied zwischen Hardware und Automation sein.
Automation ist unumgänglich
Nach dem Einbau der zusätzlichen Hardware im Rack steht die Installation von Betriebssystem und Cloudlösung auf den neuen Systemen an. Hier zeigt sich, wie deutlich sich ein konventionelles Setup von einer modernen Cloud unterscheidet: In der alten Welt hat man die Installation des Betriebssystems oft noch händisch abgewickelt, weil der Aufwand dafür vermeintlich nicht in Relation zu jenem Aufwand stand, den die Entwicklung einer komplett automatischen Installationsroutine verschlungen hätte.
In der Cloud funktioniert dieser Ansatz jedoch offensichtlich nicht mehr. Denn die Erweiterung einer Plattform kann leicht auch 300 oder 400 neue Server gleichzeitig bedeuten, deren manuelle Installation nutzlose und ausgesprochen langwierige Fleißarbeit wäre. In Clouds ist daher der Ansatz, dass nach dem ersten Drücken des Einschaltknopfes eines neuen Systems sämtliche Arbeiten im Anschluss komplett automatisiert ablaufen. Am Ende, so der Anspruch, wird der neue Server automatisch zum Mitglied im bestehenden Cloudverbund, und die genutzte Cloudlösung kümmert sich automatisch darum, ihn mit neuen VMs der Kunden zu versorgen.
Infrastruktur richtig planen
Damit das Konzept aufgeht, sind einige Vorarbeiten nötig, die schon ganz am Anfang der Konstruktion einer Cloud erledigt werden sollten. Dazu gehört, dass der Admin zentrale Komponenten in seiner Infrastruktur bereitstellt, die für die automatische Installation von Knoten nötig sind. Typische Dienste, die zu dieser Boot-Infrastruktur gehören, sind NTP, DHCP, TFTP und HTTP für das lokale Anbieten eines Paketspiegels der eigenen Standard-Distribution sowie DNS für die lokale Namensauflösung.
DHCP mag hier Stirnrunzeln verursachen, die Erfahrung zeigt jedoch, dass DHCP in großen Setups praktisch ist, weil es im Notfall auch die flächendeckende Rekonfiguration des Netzwerks ermöglicht, ohne jeden Host einzeln zu verändern. Wer Netbox nutzt, kann hier auch einen Trick anwenden: Per Definition steht in Netbox ja für jedes Gerät der Plattform mindestens eine IP-Adresse, sonst wäre die IPAM-Komponente der Plattform schließlich nutzlos.
Weil Netbox ein eigenes API mitbringt und obendrein auch eine Python-Bibliothek für das direkte Ansprechen des Netbox-API liefert, lassen sich Netbox und DHCP gut miteinander verbinden: Ein auf Pynetbox [5] basierendes Skript holt sich aus Netbox die Liste aller Netzwerkschnittstellen samt ihrer MAC-Adressen und die zugehörigen IP-Adressen und generiert eine Konfigurationsdatei für DHCPd.
Am Ende steht eine Pseudo-DHCP-Lösung: Jedes Gerät bekommt seine IP-Adressen zwar per DHCP, doch weil die Konfiguration des DHCP-Servers auf den statischen Daten aus Netbox basiert, ist diese IP nicht dynamisch.
Die Installation automatisieren
Netbox lässt sich vortrefflich auch bei der Automation der Installation des Betriebssystems nutzen: Wer etwa Host-spezifische Kickstart-Dateien generieren möchte, kann das ebenfalls auf Basis der Informationen aus Netbox tun, die per Pynetbox leicht erhältlich sind.
Durch geschickte Kombination aus Features, die viele Distributionen schon seit Jahren anbieten, und den Aufbau der benötigten Infrastruktur entsteht ein funktionierender Automatismus, der die gleichzeitige Installation Hunderter Server zum Kinderspiel macht. Alle Arbeiten, die sich automatisieren lassen, wickelt die Plattform automatisch ab.
Selbst in diesem Szenario ergibt sich noch Optimierungspotenzial: Wer sich etwa vom Hersteller die Informationen über neue Server vorab zukommen lässt, kann sie per Pynetbox automatisch in Netbox integrieren – vorausgesetzt, dass sie in maschinenlesbarer Form vorliegen. Je weniger manuelle Schritte nötig sind, um neues Blech in funktionierende Server für die Cloud zu verwandeln, desto günstiger ist deren Inbetriebnahme – und desto näher rückt der erwähnte Zustand des Hyperscale. Wer Clouds skalieren möchte, kommt nicht umhin, diesem Pfad zu folgen – denn effiziente Kapazitätsplanung für eine Cloud ist andernfalls kaum möglich.
Infos
- Martin Loschwitz, “Wachstumsschub”: Linux-Magazin 07/17, S. 74
- Open Stack Exporter für Prometheus: https://github.com/CanonicalLtd/prometheus-openstack-exporter
- Grafana: https://grafana.com
- Netbox: https://github.com/digitalocean/netbox
- Pynetbox: https://github.com/digitalocean/pynetbox






“Die Spine-Switche sind in jedem Rack verbaut und auf beliebig vielen Pfaden mit den Leaf-Switchen verbunden”
irgendwie ist leaf/spine halt mal genau falschrum beschrieben.
Das waere besser im Lektorat schon gerichtet worden.